






Data is an important asset for every organization and empowers leaders to make fully informed business decisions. However, it has also become a major barrier for those who analyze the health of their organization and seek opportunities to improve business. In part one of my two-part series, I will detail how SnapLogic overcame these barriers to become data-driven with cloud data lake and self-service analytics.
Data barriers
Pulling insights from data can be easily derailed due to multiple factors, including:
- No single source of truth: Data is siloed, buried in various sources and across different departments
- No standardization: Data exists in many forms, such as structured, semi-structured, and unstructured
- Unclean data: Data needs to be trusted, and therefore requires extra work such as removing data duplication, finding missing values, etc. to make it a higher quality
- Missing data versioning: Data can be exponentially growing and difficult to keep track of
Organizations have also faced various challenges with rigid internal processes, adoption of long-running legacy technologies, no cross-collaboration between departments to share data, all resulting in a manual and error-prone approach.
The above factors, combined with a lack of digital transformation initiatives (cloud adoption, culture change, agile process, etc.) can limit organizations from deriving meaningful 360-degree insights. In today’s economy, bad data can impact customer experience, top line and bottom line revenue growth, increase customer churn, and prevent potential opportunities.
Initiating change with data first at SnapLogic
We had similar issues at SnapLogic – we made decisions based on insights from data married from disparate systems and siloed data sets. The efforts to gain insights were less than ideal, requiring many hours to manually stitch together batch-oriented data. Colleagues from separate departments, including myself, would run periodic and one-off reports requiring specific data that was not always readily available. In some cases, we neither had a holistic view of how our customers were using our product nor did we understand customer sentiment in order to innovate our portfolio.
After creating an endless number of reports but generating very little insight, we realized that we needed a common unified framework to overcome our data access barriers, so we could derive actionable insights and drive decisions based on data.
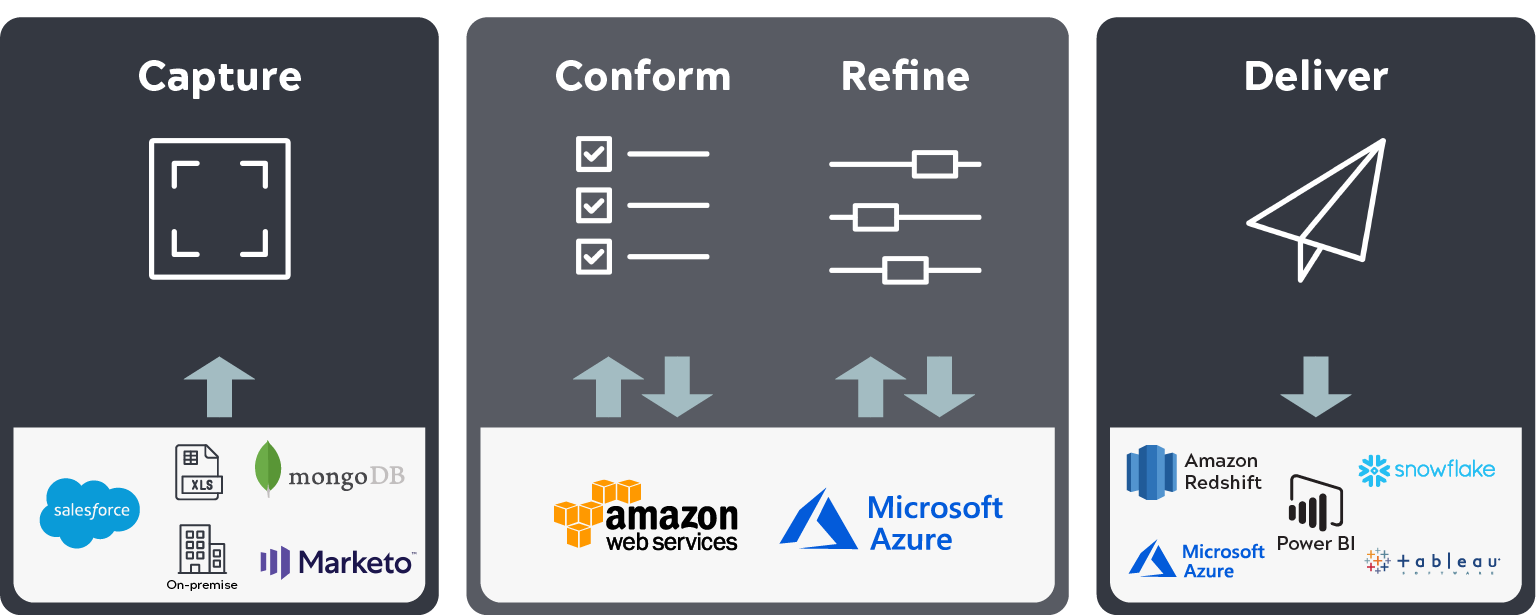
SnapLogic invests in a data lake
Based on my earlier observations on our data limitations, SnapLogic sought to become more data-driven by investing in a cloud data lake analytics initiative. I spearheaded this initiative and brought in stakeholders to understand their business requirements and then created a data framework that would meet those requirements. After weeks of fine-tuning the business requirements and formulating our data strategy, we built a multi-terabyte cloud data lake solution to provide a single source of truth. The goal was to empower key internal users with “self-service analytics” to uncover new opportunities, identify gaps, etc. We based our data framework on SnapLogic’s needs and what we wanted to accomplish. While our needs are unique to us, all companies require a set of principles for a common data framework in order to be data-driven.
Below is a series of steps that SnapLogic went through to define our data lake strategy and gain stakeholders’ buy-in. These steps are applicable to any company undergoing a data lake initiative.
1. Identifying the challenge
First realize and embrace the fact that there is a barrier in getting the right data, which means that you’ve experienced ineffective daily operations and the inability to drive key decisions. Once data problems are identified, the leadership team must come together to define key data initiatives that drive the organization’s business goals. These types of initiatives may be pushed by catalysts or organizational changes, including culture and leadership changes, operational changes, cross-team collaboration improvement, and agile processes. We also made some basic, but necessary operational changes in how the data can be made available among different teams including Engineering, Sales, Finance, and Marketing.
2. Creating a vision for the data lake
Deeper analysis and research was done to understand our business challenges. Creating a vision of SnapLogic’s data strategy was critical in helping us focus on a set of important business objectives:
- Provide enterprise-wide visibility
- Influence product roadmap, pricing, and investment
- Make informed decisions based on data and not on opinions
- Expand or uncover sales opportunities, thereby increasing revenue
- Reduce customer churn by being proactive
- Understand customer journey and identify potential gaps
- Improve product positioning
Goals were then defined to communicate why building a data lake is important and how it can benefit various departments. At SnapLogic, we clearly defined what data we needed to understand and visualize, including data points to paint the customer journey, to measure user consumption or usage, to learn about the distinct user personas, to correlate usage against industries, geographies, and sizes, etc. By mapping these types of information with various lines of businesses (LOBs) in the organization, we were able to benefit from the data that has always been previously available but out-of-reach.
3. Obtaining executive approval
Obtaining feedback on our vision from our champions and stakeholders helped us early on. Listening to feedback often times means several iterations, but it’s worth it to fine-tune data vision and strategy. By understanding stakeholders’ business objectives, I created a shared vision and evangelized how our strategy could help them realize various business benefits, including predictive analytics.
Once I was ready with our findings, I presented the following topics to the leadership team:
- Vision and strategy
- Current data limitations and its impact on decision making
- Business drivers
- Goals
- Benefits to lines of business
- Architecture proposal and the plan
- Cost and budget
4. Collaborating with teams to obtain the right KPIs
The execution plan is critical once the data lake analytics initiative is approved. By working with managers from multiple departments, I was able to uncover essential metrics they needed from this project. Not only did I understand these managers’ pain points and goals, but I also uncovered many key performance indicators (KPIs) that we did not identify in our initial execution plan. I believe that working closely with each team contributed to our success, so I continually followed up with them on our progress so they knew we were accountable.
In-depth preparation was also key to our success. I created a list of questions for our stakeholders to respond with the right information. Below are some questions I asked them:
- What do you want to know about your customers? How often?
- What would you like to know about individual users, specific groups, and the entire customer base?
- How do you measure success with your team? What key metrics do you monitor for success?
- What type of outliers you would like to see?

We also observed common patterns and questions, including:
- What needs to be done to grow our business?
- What percentage of prospects converted into customers? Why did others not convert?
- How can we ensure retention?
- How many support cases are opened and resolved per customer?
- What is the average customer acquisition cost (CAC)?
Understanding KPIs around these important questions, coming up with a list, and prioritizing them were all part of the next steps. At SnapLogic, some of the KPIs were to understand customer usage patterns, adoption, whether a trend is increasing or decreasing, and provide proactive alerts to the right teams.
5. Hire the right skill set
When building and evolving data lake, it is important to understand what skill sets are required.
At SnapLogic, we created a separate analytics team that I lead and manage. I carefully vetted out candidates to ensure that their skills would complement our vision and requirements. Our analytics team is comprised of an experienced architect that has built many enterprise data lakes in the past, a handful of developers to build integration pipelines and workflows in the SnapLogic Intelligent Integration Platform (IIP), QA to validate data, and a Tableau expert to build reports.
6. Iterate to refine our data lake
For the data lake to be successful, it may need to go through multiple iterations before it is made available to all employees. Our company goal was to have a baseline architecture that can be scalable, flexible, secure, and pluggable so tools can be easily replaced in the future. We used a number of databases and applications to create the data lake.
For instance, we used the Snaplogic IIP to capture and conform multi-terabyte data in AWS S3, SnapLogic eXtreme for processing large data set, Snowflake to store processed data using SnapLogic, and Tableau to visualize reports.
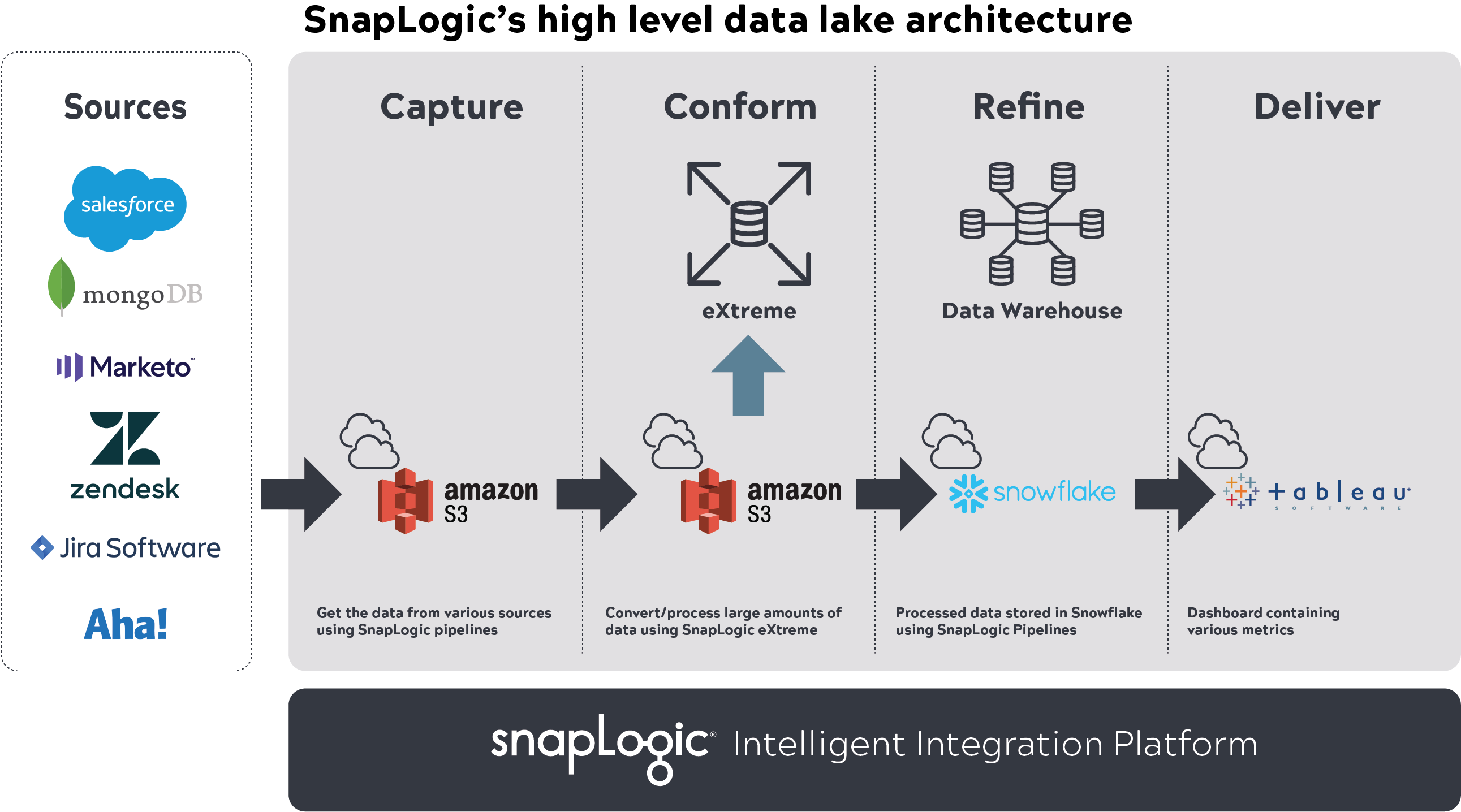
Once these applications were set up and defined, we started to capture KPIs and other data types requested by stakeholders. We worked with them and other team members to identify applications where the data resided, excluding specific sensitive data to meet security compliances. The analytics team then built SnapLogic pipelines to ingest data from these sources into the S3 data lake, processed it using SnapLogic eXtreme based on business logic, stored the resultant star schema set (facts, dimensions) in Snowflake, and delivered insights into Tableau. These pipelines were automated to include change data capture.
The DevOps team then created access profiles so the appropriate people had access to these datasets.
An ongoing effort is required where the business users need to own respective data and improve it, so it becomes easy to ingest and process in the data lake. Various gaps were also identified during the data lake building process (data quality, missed data set, etc.), and respective LOBs rectified it. Insights derived were shared with executives and various teams to get early feedback. We then iterated and made the data lake better based on the feedback obtained.
Results
I am proud to say that SnapLogic’s culture of innovation, openness to change, and transparent decision-making helped us realize the full potential of our data. The right KPIs were built and visualized with the help of an automated cloud data lake and a self-service solution. Through the data lake, we gained enterprise-wide connectivity and a single source of truth, connected missing pieces together, and obtained transparency on customer usage, patterns, and their issues. The data lake also allowed us to make meaningful actions from insights derived near real-time, leading to increased customer satisfaction, better forecasting, and increased revenue.
In part two of this blog series, I will share some best practices on data lake architecture and the process to build a data lake. In the meantime, read more about how to acquire insights from data lakes using the same technologies we used.





