






I dati sono una risorsa importante per ogni organizzazione e consentono ai leader di prendere decisioni aziendali pienamente informate. Tuttavia, sono anche diventati un ostacolo importante per chi analizza lo stato di salute della propria organizzazione e cerca opportunità per migliorare il business. Nella prima parte della mia serie in due parti, illustrerò come SnapLogic ha superato queste barriere per diventare data-driven con il data lake cloud e l'analisi self-service.
Barriere di dati
L'estrazione di informazioni dai dati può essere facilmente compromessa a causa di molteplici fattori, tra cui:
- Non esiste un'unica fonte di verità: i dati sono frammentati, sepolti in varie fonti e in diversi dipartimenti.
- Nessuna standardizzazione: I dati esistono in molte forme, come quelle strutturate, semi-strutturate e non strutturate.
- Dati non puliti: I dati devono essere attendibili e quindi richiedono un lavoro supplementare, come la rimozione delle duplicazioni dei dati, la ricerca dei valori mancanti, ecc. per renderli di qualità superiore
- Manca il versioning dei dati: I dati possono crescere in modo esponenziale ed è difficile tenerne traccia.
Le organizzazioni hanno anche affrontato diverse sfide con processi interni rigidi, l'adozione di tecnologie legacy di lunga durata, l'assenza di collaborazione trasversale tra i reparti per la condivisione dei dati, il tutto con un approccio manuale e soggetto a errori.
I fattori di cui sopra, combinati con la mancanza di iniziative di trasformazione digitale (adozione dicloud , cambiamento culturale, processi agili, ecc. Nell'economia odierna, i dati errati possono avere un impatto sull'esperienza del cliente, sulla crescita dei ricavi a livello di top line e di bottom line, aumentare il turn-over dei clienti e impedire potenziali opportunità.
Avviare il cambiamento con i dati prima di tutto in SnapLogic
In SnapLogic avevamo problemi simili: prendevamo decisioni basate sulle intuizioni dei dati sposati da sistemi disparati e da set di dati siloed. I tentativi di ottenere informazioni non erano ottimali e richiedevano molte ore per mettere insieme manualmente i dati orientati ai lotti. Colleghi di reparti diversi, compreso il sottoscritto, eseguivano report periodici e una tantum che richiedevano dati specifici non sempre facilmente disponibili. In alcuni casi, non avevamo una visione olistica di come i clienti utilizzavano i nostri prodotti, né comprendevamo il sentiment dei clienti per innovare il nostro portafoglio.
Dopo aver creato un numero infinito di report che però generavano poche informazioni, ci siamo resi conto che avevamo bisogno di un framework comune e unificato per superare le nostre barriere di accesso ai dati, in modo da poter ricavare informazioni utili e prendere decisioni basate sui dati.
SnapLogic investe in un lago di dati
Sulla base delle mie precedenti osservazioni sulle limitazioni dei nostri dati, SnapLogic ha cercato di diventare più orientata ai dati investendo in un'iniziativa di analisi del data lake cloud . Ho guidato questa iniziativa e ho coinvolto gli stakeholder per capire i loro requisiti aziendali e poi ho creato un framework di dati che li soddisfacesse. Dopo settimane di messa a punto dei requisiti aziendali e di formulazione della nostra strategia sui dati, abbiamo costruito una soluzione di data lake cloud da diversi terabyte per fornire un'unica fonte di verità. L'obiettivo era quello di fornire ai principali utenti interni "analisi self-service" per scoprire nuove opportunità, identificare lacune, ecc. Abbiamo basato il nostro framework di dati sulle esigenze di SnapLogic e su ciò che volevamo ottenere. Anche se le nostre esigenze sono uniche, tutte le aziende hanno bisogno di una serie di principi per un quadro comune di dati per essere guidate dai dati.
Di seguito riportiamo una serie di fasi che SnapLogic ha seguito per definire la nostra strategia di data lake e ottenere il consenso degli stakeholder. Queste fasi sono applicabili a qualsiasi azienda che intraprenda un'iniziativa di data lake.
1. Identificare la sfida
Per prima cosa è necessario rendersi conto e accettare il fatto che c'è un ostacolo nell'ottenere i dati giusti, il che significa che le operazioni quotidiane sono inefficaci e l'incapacità di prendere decisioni chiave. Una volta identificati i problemi dei dati, il team di leadership deve riunirsi per definire le iniziative chiave sui dati che guidano gli obiettivi aziendali dell'organizzazione. Questi tipi di iniziative possono essere spinti da catalizzatori o cambiamenti organizzativi, tra cui cambiamenti culturali e di leadership, cambiamenti operativi, miglioramento della collaborazione tra team e processi agili. Abbiamo anche apportato alcune modifiche operative di base, ma necessarie, per quanto riguarda il modo in cui i dati possono essere resi disponibili tra i diversi team, tra cui ingegneria, vendite, finanza e marketing.
2. Creare una visione per il data lake
Sono state effettuate analisi e ricerche più approfondite per comprendere le nostre sfide aziendali. Creare una visione della strategia dei dati di SnapLogic è stato fondamentale per aiutarci a concentrarci su una serie di importanti obiettivi aziendali:
- Fornite visibilità a livello aziendale
- Influenzare la roadmap del prodotto, i prezzi e gli investimenti
- Prendere decisioni informate basate su dati e non su opinioni.
- Ampliare o scoprire le opportunità di vendita, aumentando così i ricavi.
- Ridurre la rinuncia dei clienti con un atteggiamento proattivo
- Comprendere il percorso del cliente e identificare le potenziali lacune
- Migliorare il posizionamento del prodotto
Sono stati quindi definiti degli obiettivi per comunicare perché la creazione di un data lake è importante e come può portare benefici ai vari dipartimenti. In SnapLogic abbiamo definito chiaramente quali dati dovevamo comprendere e visualizzare, compresi i punti di dati per tracciare il percorso del cliente, per misurare il consumo o l'utilizzo degli utenti, per conoscere le diverse personas di utenti, per correlare l'utilizzo rispetto a settori, aree geografiche e dimensioni, ecc. Mappando questi tipi di informazioni con le varie linee di business (LOB) dell'organizzazione, siamo stati in grado di trarre vantaggio dai dati che in precedenza erano sempre stati disponibili ma non raggiungibili.
3. Ottenere l'approvazione dell'esecutivo
Ottenere un feedback sulla nostra visione da parte dei nostri campioni e stakeholder ci ha aiutato fin dall'inizio. Ascoltare i feedback spesso comporta diverse iterazioni, ma ne vale la pena per mettere a punto la visione e la strategia dei dati. Comprendendo gli obiettivi aziendali degli stakeholder, ho creato una visione condivisa e ho spiegato come la nostra strategia potesse aiutarli a realizzare vari vantaggi aziendali, tra cui l'analisi predittiva.
Una volta pronti i risultati, ho presentato i seguenti argomenti al team di leadership:
- Visione e strategia
- Limiti attuali dei dati e loro impatto sul processo decisionale
- Driver aziendali
- Obiettivi
- Vantaggi per le linee di business
- La proposta di architettura e il piano
- Costi e budget
4. Collaborare con i team per ottenere i giusti KPI.
Il piano di esecuzione è fondamentale una volta approvata l'iniziativa di analisi del data lake. Lavorando con i manager di diversi reparti, sono riuscito a scoprire le metriche essenziali di cui avevano bisogno per questo progetto. Non solo ho capito i punti dolenti e gli obiettivi di questi manager, ma ho anche scoperto molti indicatori chiave di prestazione (KPI) che non avevamo identificato nel nostro piano di esecuzione iniziale. Credo che lavorare a stretto contatto con ciascun team abbia contribuito al nostro successo, per cui li ho seguiti costantemente per conoscere i nostri progressi, in modo che sapessero che eravamo responsabili.
Una preparazione approfondita è stata la chiave del nostro successo. Ho creato un elenco di domande per i nostri interlocutori, affinché rispondessero con le informazioni giuste. Di seguito sono riportate alcune domande che ho posto loro:
- Cosa volete sapere dei vostri clienti? Con quale frequenza?
- Cosa vorreste sapere su singoli utenti, gruppi specifici e sull'intera base di clienti?
- Come misurate il successo del vostro team? Quali sono le metriche chiave che monitorate per il successo?
- Che tipo di anomalie vorresti vedere?

Abbiamo anche osservato modelli e domande comuni, tra cui:
- Cosa bisogna fare per far crescere il nostro business?
- Quale percentuale di prospect si è convertita in clienti? Perché altri non si sono convertiti?
- Come possiamo garantire la fidelizzazione?
- Quanti casi di assistenza vengono aperti e risolti per cliente?
- Qual è il costo medio di acquisizione dei clienti (CAC)?
La comprensione dei KPI relativi a queste importanti domande, la stesura di un elenco e la definizione delle priorità hanno fatto parte dei passi successivi. In SnapLogic, alcuni dei KPI consistevano nel capire i modelli di utilizzo dei clienti, l'adozione, se una tendenza è in aumento o in diminuzione e fornire avvisi proattivi ai team giusti.
5. Assumere il giusto set di competenze
Quando si costruisce e si evolve un data lake, è importante capire quali sono le competenze necessarie.
In SnapLogic abbiamo creato un team di analisi separato che io dirigo e gestisco. Ho valutato attentamente i candidati per assicurarmi che le loro competenze fossero complementari alla nostra visione e ai nostri requisiti. Il nostro team di analisi è composto da un architetto esperto che in passato ha costruito molti data lake aziendali, da una manciata di sviluppatori che costruiscono pipeline di integrazione e flussi di lavoro nella SnapLogic Intelligent Integration Platform (IIP), da un QA che convalida i dati e da un esperto di Tableau che crea i report.
6. Iterare per perfezionare il nostro lago di dati
Affinché il data lake abbia successo, potrebbe dover passare attraverso più iterazioni prima di essere reso disponibile a tutti i dipendenti. Il nostro obiettivo aziendale era quello di avere un'architettura di base che potesse essere scalabile, flessibile, sicura e collegabile, in modo da poter sostituire facilmente gli strumenti in futuro. Per creare il data lake abbiamo utilizzato diversi database e applicazioni.
Ad esempio, abbiamo utilizzato Snaplogic IIP per acquisire e conformare dati multi-terabyte in AWS S3, SnapLogic eXtreme per l'elaborazione di set di dati di grandi dimensioni, Snowflake per archiviare i dati elaborati con SnapLogic e Tableau per visualizzare i report.
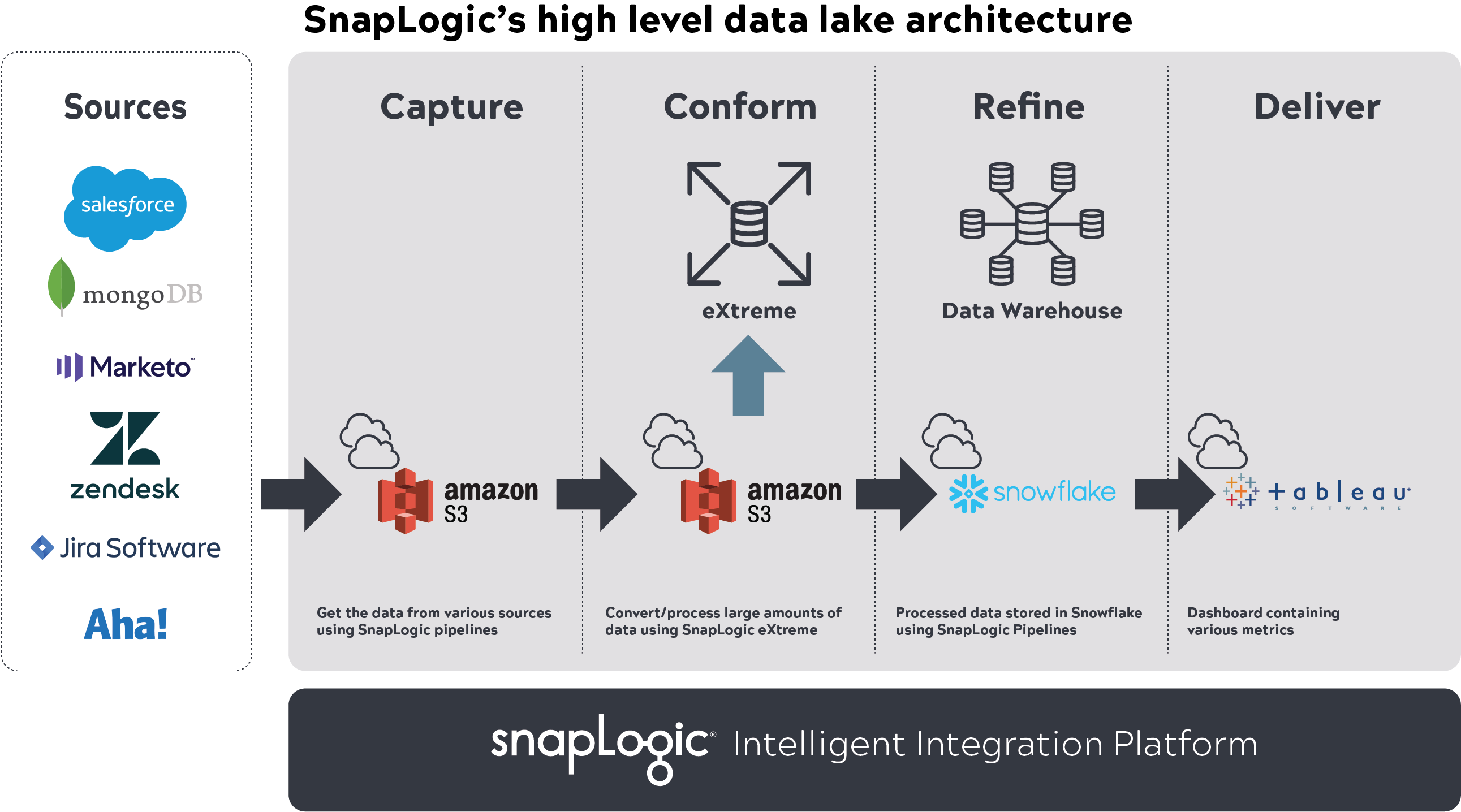
Una volta impostate e definite queste applicazioni, abbiamo iniziato ad acquisire i KPI e altri tipi di dati richiesti dagli stakeholder. Abbiamo collaborato con loro e con altri membri del team per identificare le applicazioni in cui risiedevano i dati, escludendo dati sensibili specifici per soddisfare le norme di sicurezza. Il team di analisi ha poi costruito pipeline SnapLogic per ingerire i dati da queste fonti nel data lake S3, li ha elaborati con SnapLogic eXtreme in base alla logica aziendale, ha memorizzato il set di star schema (fatti, dimensioni) risultante in Snowflake e ha fornito approfondimenti in Tableau. Queste pipeline sono state automatizzate per includere la cattura dei dati di modifica.
Il team DevOps ha quindi creato dei profili di accesso in modo che le persone appropriate potessero accedere a questi set di dati.
È necessario uno sforzo continuo in cui gli utenti aziendali devono possedere i rispettivi dati e migliorarli, in modo che diventino facili da ingerire ed elaborare nel data lake. Durante il processo di creazione del data lake sono state identificate varie lacune (qualità dei dati, set di dati mancanti, ecc.) e i rispettivi LOB le hanno corrette. Le informazioni ottenute sono state condivise con i dirigenti e i vari team per ottenere un primo feedback. Abbiamo poi iterato e migliorato il data lake sulla base del feedback ottenuto.
Risultati
Sono orgoglioso di dire che la cultura di SnapLogic, fatta di innovazione, apertura al cambiamento e trasparenza decisionale, ci ha aiutato a realizzare il pieno potenziale dei nostri dati. I KPI giusti sono stati costruiti e visualizzati con l'aiuto di un data lake automatizzato cloud e di una soluzione self-service. Grazie al data lake, abbiamo ottenuto una connettività a livello aziendale e un'unica fonte di verità, abbiamo collegato i pezzi mancanti e ottenuto trasparenza sull'utilizzo dei clienti, sui loro modelli e sui loro problemi. Il data lake ci ha anche permesso di intraprendere azioni significative sulla base di informazioni ottenute in tempo reale, con conseguente aumento della soddisfazione dei clienti, miglioramento delle previsioni e incremento dei ricavi.
Nella seconda parte di questa serie di blog, condividerò alcune best practice sull'architettura dei data lake e sul processo di costruzione di un data lake. Nel frattempo, leggete di più su come acquisire insight dai data lake utilizzando le stesse tecnologie che abbiamo usato noi.





