






Nous apprécions tous le Pipeline Execute Snap, qui simplifie considérablement un pipeline complexe en extrayant des sections dans un sous-pipeline. Cependant, il arrive parfois que nous souhaitions pouvoir exécuter un pipeline plusieurs fois pour effectuer certaines opérations, telles que l'interrogation d'un point de terminaison ou l'exécution d'appels LLM Tool. Dans cet article, nous allons présenter le Snap PipeLoop , qui ajoute l'itération au modèle de programmation SnapLogic. Avec PipeLoop, nous pouvons créer les workflows nouveaux les workflows étaient auparavant difficiles, voire impossibles à gérer.
Qu'est-ce que PipeLoop ?
PipeLoop est un nouveau Snap permettant l'exécution itérative sur un pipeline. Pour ceux qui sont familiers avec les itérations dans les langages de programmation, PipeLoop est essentiellement une boucle « do-while » pour les pipelines. L'utilisateur doit fournir une limite d'itération comme seuil maximal afin d'éviter l'épuisement des ressources ou une boucle infinie, ainsi qu'une condition d'arrêt facultative pour contrôler l'exécution.
Tout comme nous pouvons transmettre des documents d'entrée à PipeExec, nous pouvons également transmettre des documents d'entrée à PipeLoop. La différence entre les deux réside dans le fait que le document de sortie du pipeline exécuté avec PipeLoop sera utilisé comme prochaine entrée pour poursuivre l'exécution jusqu'à ce que la condition d'arrêt soit remplie ou que la limite soit atteinte. En raison de ce mécanisme unique, le pipeline exécuté par PipeLoop doit comporter une entrée non liée et une sortie non liée pour fonctionner correctement. Pour simplifier, PipeLoop peut être considéré comme un enchaînement d'une série de Snaps PipeExec avec le même pipeline, une longueur variable et une condition de sortie anticipée.
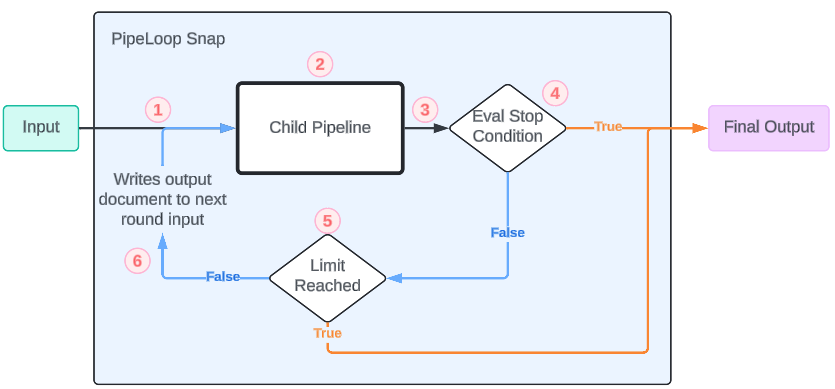
1.Les documentsentrantsdans PipeLoop sont transmis au pipeline enfant pour exécution. 2. Le pipeline enfant s'exécute. 3. La sortie enfant est collectée. 4. Évaluation de la condition d'arrêt en fonction de la sortie du document. Si elle est vraie, sortie et transmission du document de sortie à PipeLoop, sinon continuation. 5. Vérifier si la limite d'itération est atteinte. Si oui, quitter et transmettre le document de sortie à PipeLoop, sinon continuer. 6. Utiliser le document de sortie comme entrée pour le cycle suivant et continuer (1.).
Présentation de l'exécution de PipeLoop
Commençons par un exemple très simple. Nous allons créer un workflow PipeLoop qui incrémente un nombre de 1 à 3. Pour simplifier, nous appellerons le pipeline avec PipeLoop le « pipeline parent » et le pipeline exécuté par PipeLoop le « pipeline enfant ».
Configuration du pipeline parent
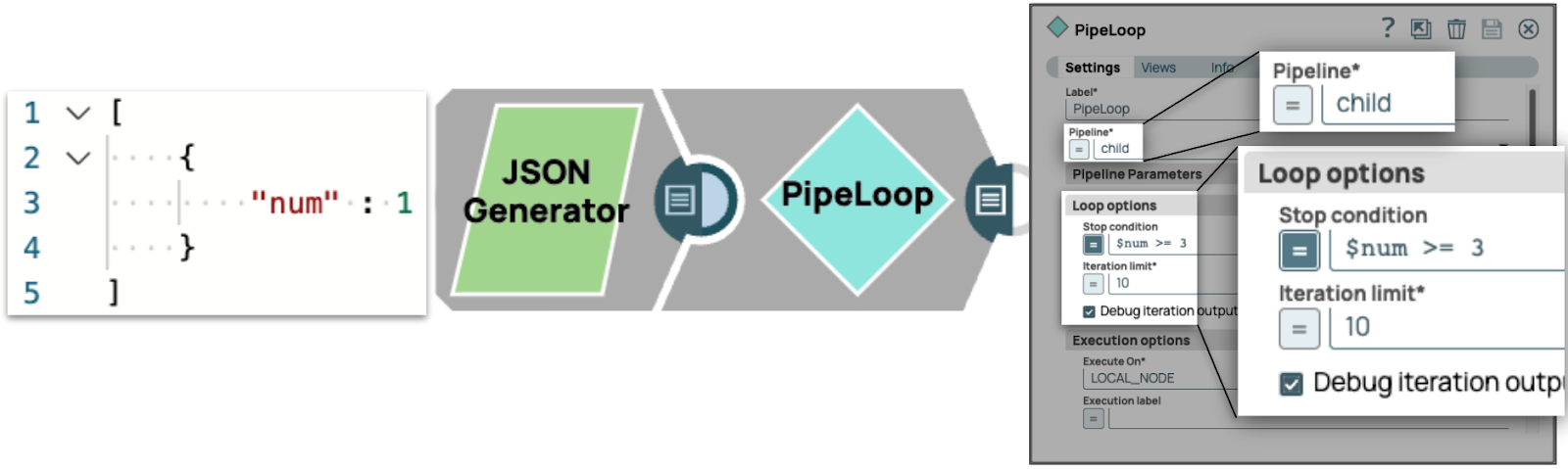
Le pipeline parent se compose d'un Snap JSON Generator avec un document en entrée et d'un Snap PipeLoop exécutant le pipeline «enfant »avec la condition d'arrêt « $num >= 3 ». Nous allons également activer « Debug Iteration output » (Déboguer la sortie d'itération) afin de voir la sortie de chaque cycle dans cette procédure pas à pas.
Configuration du pipeline enfant

Le pipeline enfant consiste en un seul snap mapper qui incrémente « $num » de 1, ce qui satisfait à l'exigence «un pipeline avec une entrée non liée et une sortie non liée » pour qu'un pipeline soit exécuté par PipeLoop.
Sortie
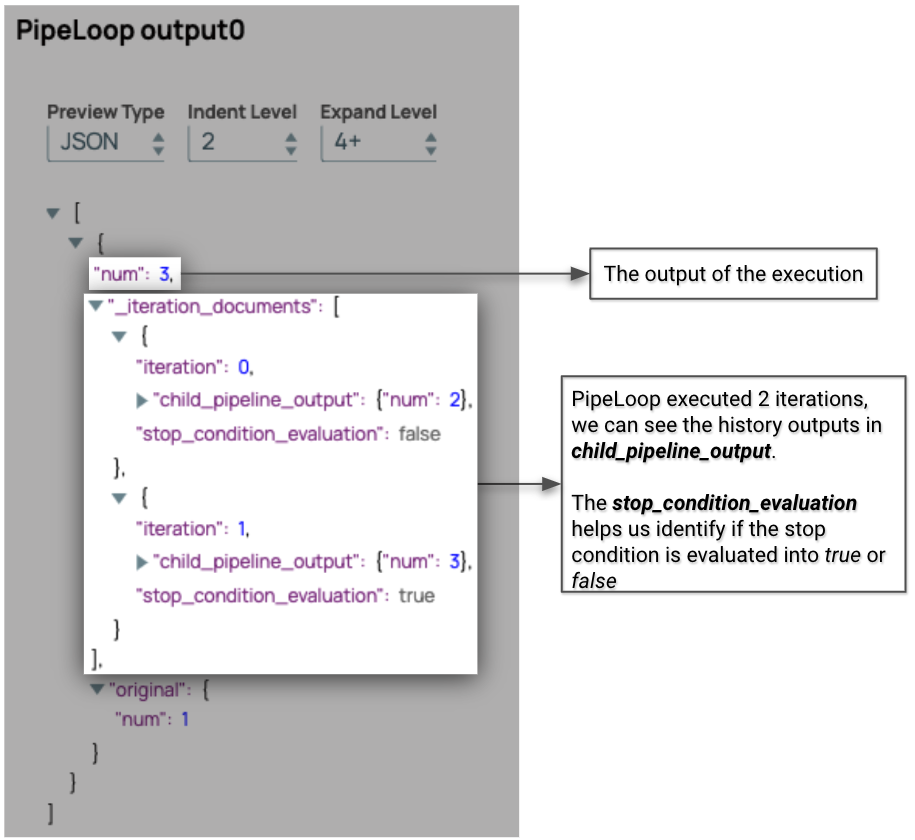
La sortie de PipeLoop comprend deux sections principales lorsque le mode Debug est activé : les champs de sortie et les _iteration_documents. Nous pouvons voir que la sortie finale est « num » : 3, ce qui signifie que PipeLoop a correctement exécuté la tâche.
Caractéristiques de PipeLoop
PipeLoop offre plusieurs fonctionnalités qui peuvent s'avérer utiles lors de la création de pipelines itératifs. Nous les classerons en fonction de leur emplacement.
Propriétés
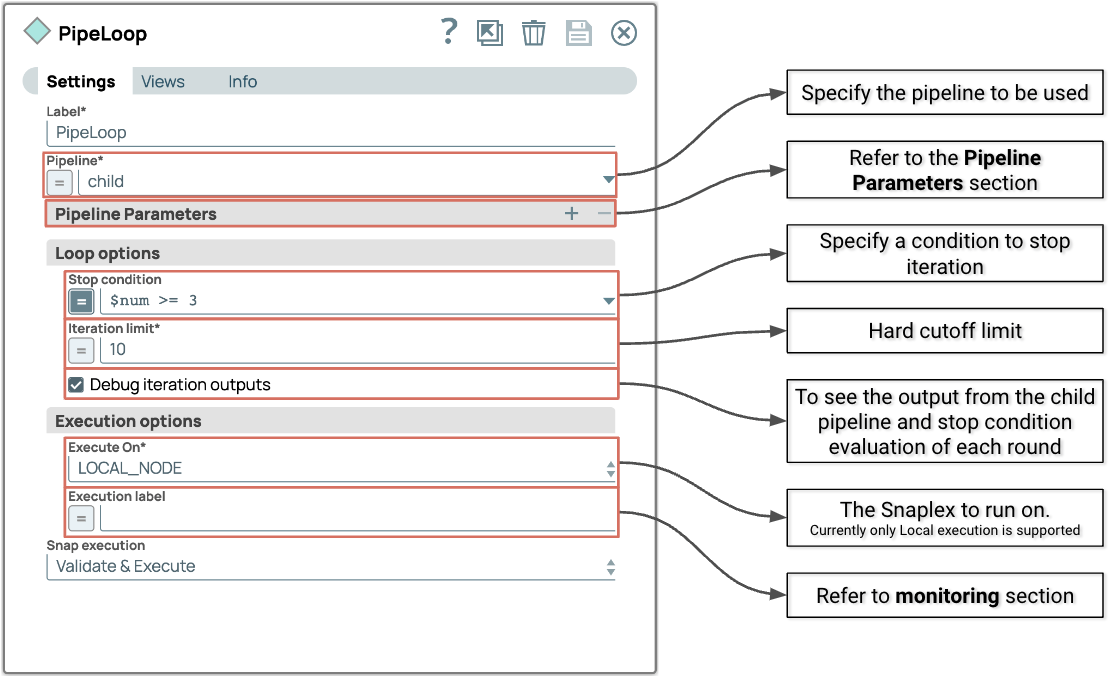
La propriété PipeLoop Snap comporte 4 sections principales.
- Conduite
- Paramètres du pipeline
- Options de boucle
- Options d'exécution
Conduite
Le pipeline à exécuter.
Paramètres du pipeline
Nous approfondirons ce sujet dans la section Paramètres du pipeline.
Options de boucle
Les options de boucle sont des paramètres de propriété liés aux itérations de cet ajustement.
Condition d'arrêt
Le champ Condition d'arrêt permet à l'utilisateur de définir une expression à évaluer après la première exécution. Si l'expression est évaluée comme vraie, l'itération sera arrêtée. La condition d'arrêt peut également être définie comme fausse si l'utilisateur souhaite utiliser cette boucle comme une boucle for traditionnelle.
Il arrive parfois que l'utilisateur saisisse une valeur non intentionnelle dans le champ Condition d'arrêt. Dans ce cas, PipeLoop génère un avertissement lorsque l'utilisateur fournit une chaîne non booléenne comme condition d'arrêt, tandis que la condition d'arrêt sera traitée comme fausse.
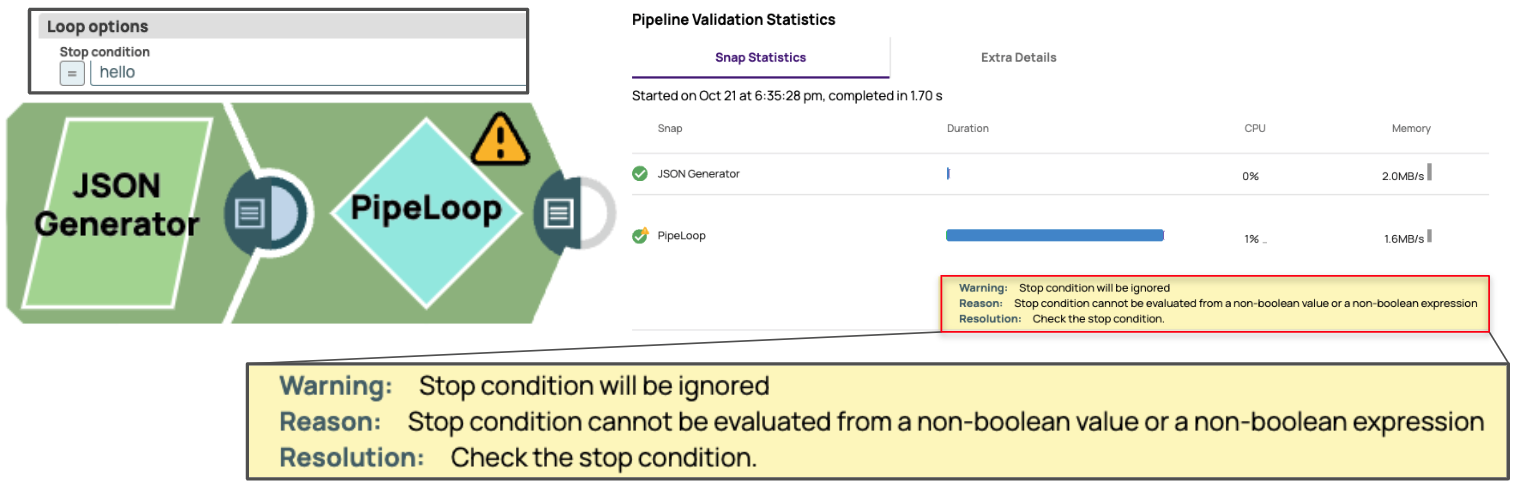
Limite d'itération
Le champ Limite d'itérations permet à l'utilisateur de limiter le nombre maximal d'itérations pouvant potentiellement se produire. Ce champ peut également être utilisé pour limiter le nombre total d'exécutions si la condition d'arrêt est définie sur faux.
Définir une valeur élevée pour la limite d'itération avec le mode débogage activé peut être dangereux. Les documents accumulés peuvent rapidement épuiser les ressources du processeur et de la mémoire vive. Pour éviter cela, PipeLoop génère un avertissement dans l'onglet Statistiques de validation du pipeline lorsque la limite d'itération est définie sur une valeur supérieure ou égale à 1 000 et que le mode débogage est activé.
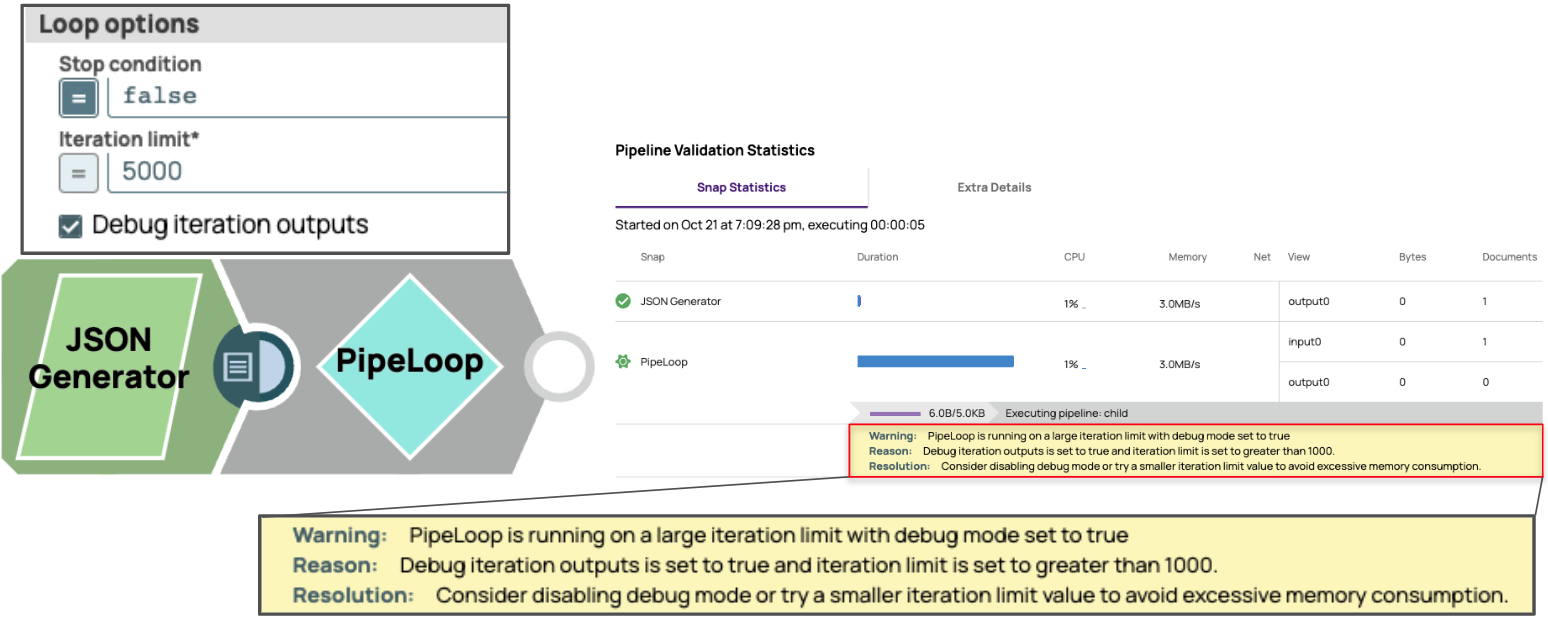
Sorties d'itération de débogage
Ce champ à bascule permet d'ajouter la sortie des pipelines enfants pour chaque itération et l'évaluation de la condition d'arrêt dans la sortie finale en tant que champ distinct.

Options d'exécution
Exécuter sur
Pour spécifier où l'exécution du pipeline doit avoir lieu. Actuellement, seules les exécutions locales (snaplex local, nœud local) sont prises en charge.
Étiquette d'exécution
Nous approfondirons ce sujet dans la section Surveillance.
Paramètres du pipeline
Les utilisateurs familiarisés avec les paramètres de pipeline dans PipeExec peuvent passer directement à la section suivante, car les instructions sont identiques.
Introduction aux paramètres de pipeline
Avant d'examiner la prise en charge des paramètres de pipeline dans PipeLoop Snap, prenons un peu de recul pour voir ce que sont les paramètres de pipeline et comment ils peuvent être exploités.
Les paramètres de pipeline sont des constantes de type chaîne qui peuvent être définies dans les paramètres Modifier la configuration du pipeline . Les utilisateurs peuvent utiliser ces paramètres comme constantes à n'importe quel endroit du pipeline. Une différence majeure entre les paramètres de pipeline et les variables de pipeline réside dans le fait que les paramètres de pipeline sont désignés par un préfixe underscore, tandis que les variables de pipeline sont désignées par un préfixe dollar.
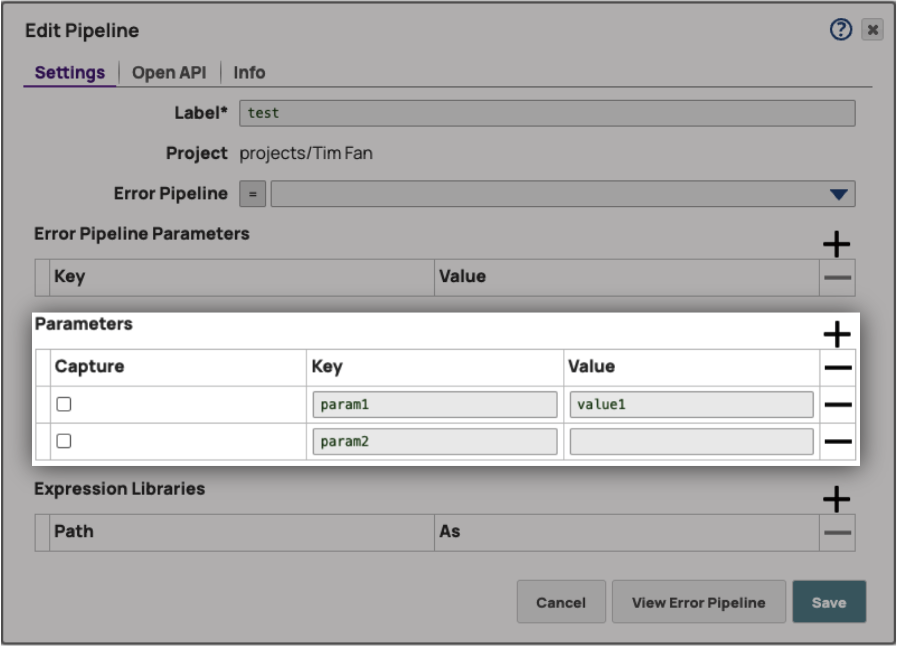
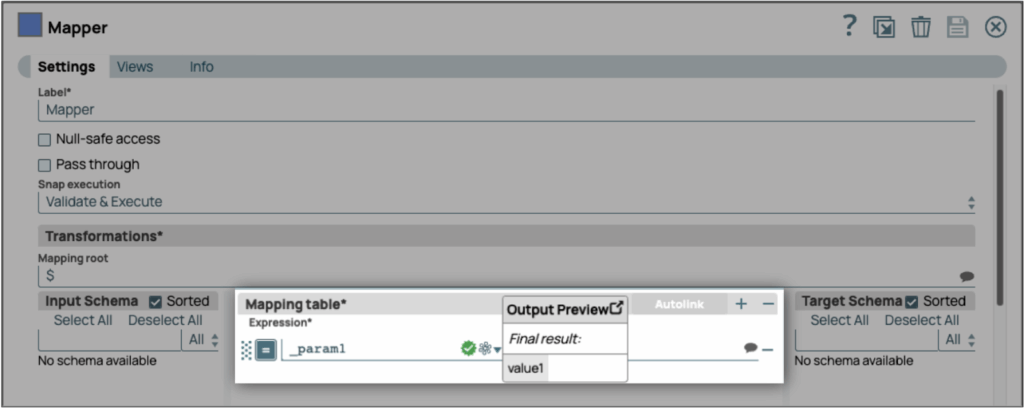
Exemple
Voyons comment fonctionnent les paramètres de pipeline avec PipeLoop. Notre objectif ici est d'imprimer « Hello PipeLoop ! » n fois, où n est la valeur de «num ».
Nous allons ajouter deux paramètres dans le pipeline enfant, param1 et param2. À titre d'exemple, nous attribuonsla valeur«value1 »à param1 et laissons param2 vide. Nous ajouterons ensuite un champ de message avec la valeur «Hello PipeLoop !» dans le générateur JSON afin de pouvoir attribuer la valeur String à param2. Nous pouvons désormais utiliser param2 comme constante dans le pipeline enfant. PipeLoop propose également des suggestions de noms de champs dans les champs Nom du paramètre pour faciliter l'utilisation.
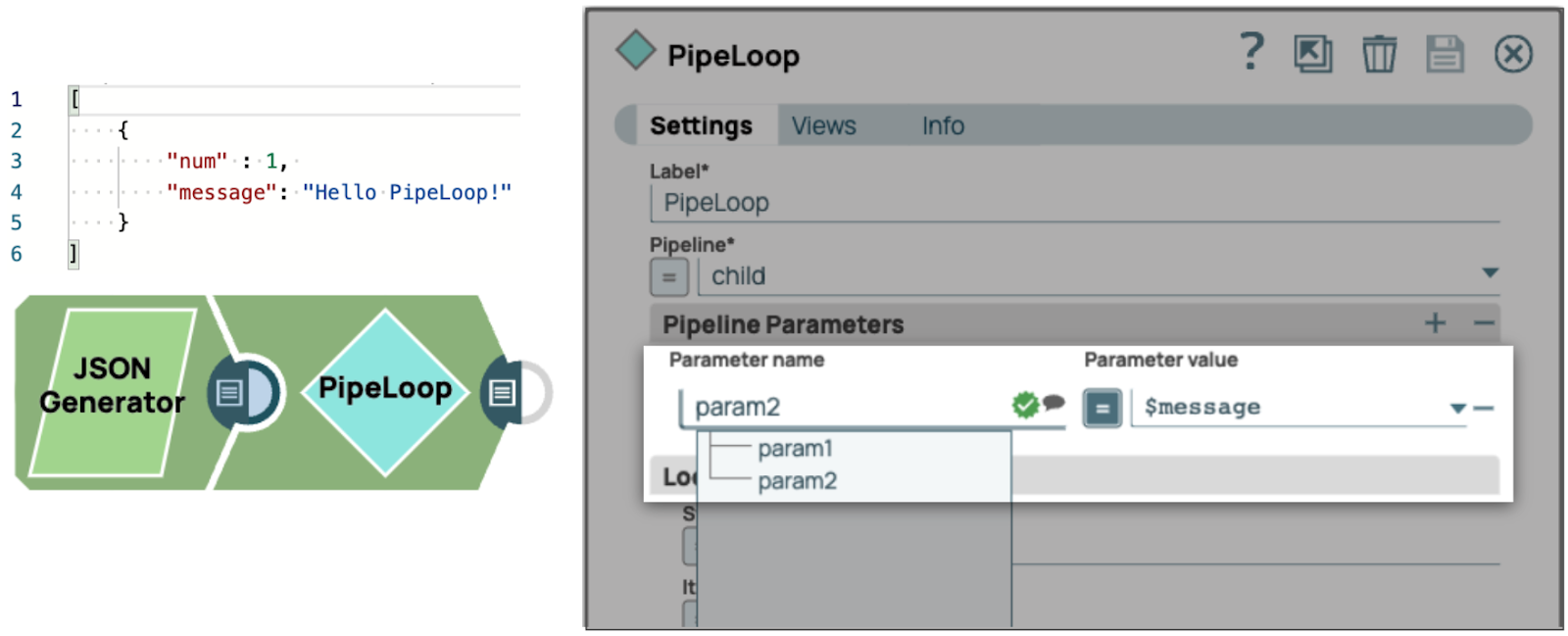
Pour notre pipeline enfant, nous allons ajouter une nouvelle ligne dans le tableau Mapping afin d'imprimer « Hello PipeLoop ! » à plusieurs reprises (suivi d'un caractère de nouvelle ligne). Il est important de noter que l'ordre du tableau Mapping n'affecte pas le résultat (le nombre de « Hello PipeLoop ! » imprimés dans ce cas), car les champs de sortie sont mis à jour une fois l'exécution de l'itération actuelle terminée.
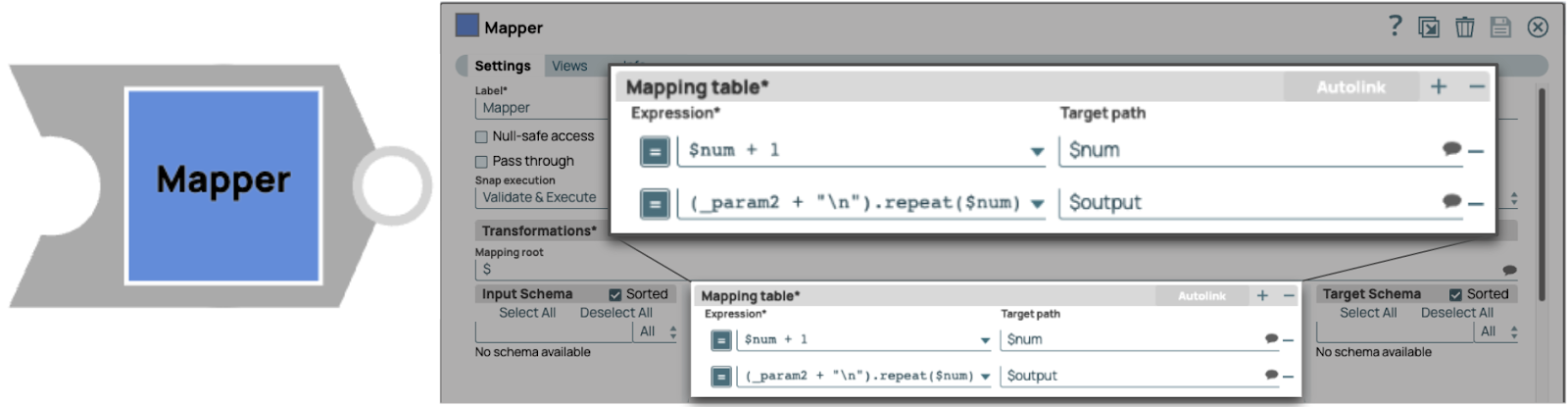
Voici le résultat final : on peut voir que « Hello PipeLoop ! » est imprimé deux fois. Mission accomplie.

Remarques
- Les paramètres de pipeline sont des constantes de chaîne qui peuvent être définies dans Modifier la configuration du pipeline.
- Les utilisateurs peuvent transmettre une chaîne de caractères aux paramètres de pipeline définis dans le pipeline enfant dans PipeLoop.
- Les paramètres de pipeline dans PipeLoop remplaceront les les valeurs précédentes des paramètres de pipeline définies dans le pipeline enfant si les paramètres partagent le même nom.
- Les paramètres du pipeline sont des constantes, ce qui signifie que les valeurs ne seront pas modifiées au cours des itérations, même si les utilisateurs le font.
Surveillance
Lorsqu'un snap dans un pipeline est exécuté, il n'y a aucune sortie tant que l'exécution n'est pas terminée. Par conséquent, en raison de la nature itérative de l'exécution du pipeline en tant que snap unique, il est légèrement difficile de savoir où en est l'exécution ou quelle exécution du pipeline correspond à quel document d'entrée. Pour remédier à cela, nous proposons deux fonctionnalités supplémentaires qui permettent d'améliorer la visibilité de l'exécution de PipeLoop.
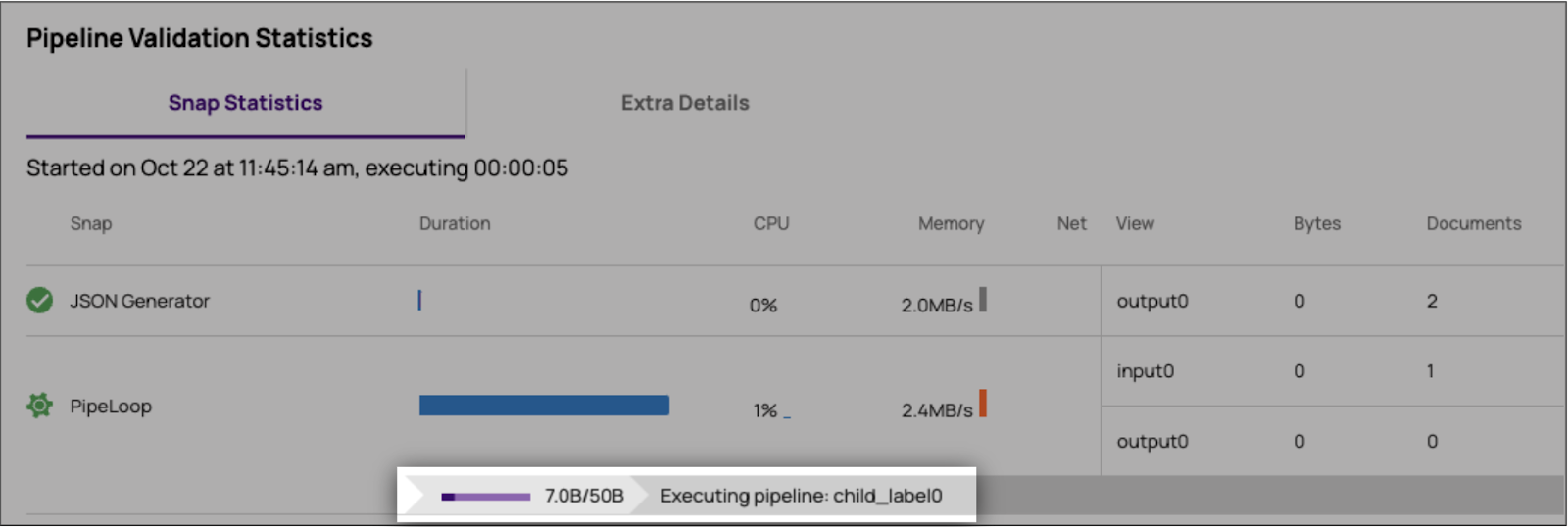
Barre de progression des statistiques du pipeline
Pendant l'exécution de PipeLoop, une barre de progression sera disponible dans l'onglet Pipeline Validation Statistics (Statistiques de validation du pipeline), afin que l'utilisateur puisse se faire une idée de l'itération à laquelle PipeLoop se trouve actuellement. Notez que la barre de progression peut ne pas refléter l'index d'itération réel si les exécutions du pipeline enfant sont courtes, en raison des intervalles d'interrogation.
Étiquette d'exécution
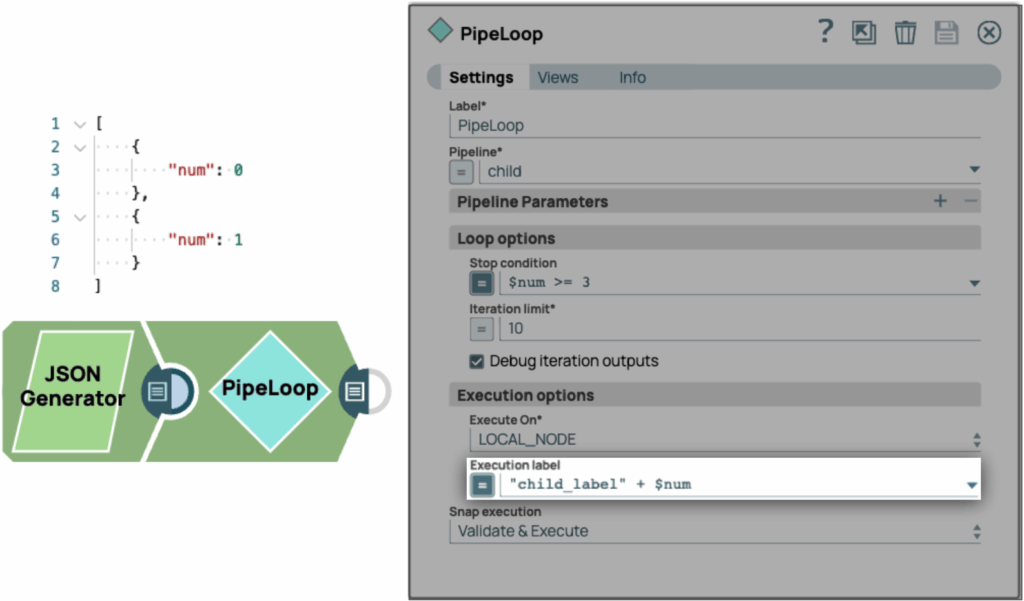
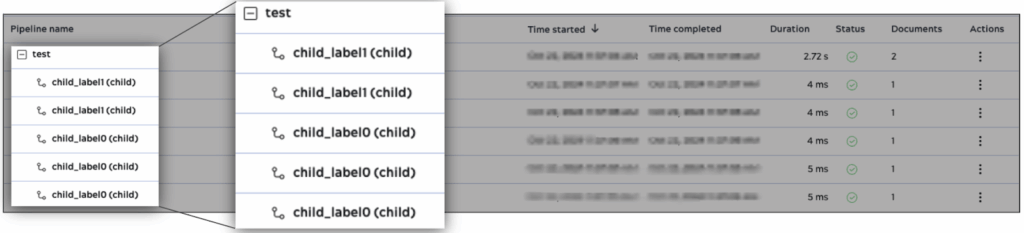
Lorsqu'un PipeLoop avec plusieurs documents d'entrée est exécuté, l'utilisateur ne peut pas savoir quelle exécution de pipeline est liée à quel document d'entrée dans SnapLogic Monitor. L'étiquette d'exécution est la solution à ce problème. L'utilisateur peut saisir une valeur dans le champ Étiquette d'exécution qui permet de différencier les documents d'entrée, de sorte que chaque document d'entrée ait sa propre étiquette dans Snaplogic Monitor pendant l'exécution.
Voici un exemple de deux documents d'entrée exécutés sur le pipeline enfant. Nous avons défini le label d'exécution avec l'expression « child_label » + $num, de sorte que l'exécution du premier document aura le label « child_label0 » et la deuxième exécution aura le label « child_label1 ».
Résumé
Dans cet article, nous avons présenté PipeLoop, un nouveau Snap pour les workflows d'exécution itératifs. Le pipeline exécuté par PipeLoop doit comporter une entrée non liée et une sortie non liée.
PipeLoop présente les caractéristiques suivantes :
- Prise en charge des paramètres de pipeline
- Condition d'arrêt pour quitter prématurément avec des avertissements
- Limite d'itération pour éviter les boucles infinies avec avertissements
- Mode débogage
- Étiquette d'exécution pour différencier les exécutions dans Monitor
- Barre de progression pour le suivi du statut
Bonne construction !





