







Il n‘y a pas d‘IA sans données. La version de mai de SnapLogic plateforme accélère votre capacité à utiliser les données pour transformer votre organisation avec des applications GenAI. Avec cette version, vous pouvez :
- Connexion aux modèles de fondation de l‘Anthropic Claude, et à une autre base de données vectorielle : MongoDB Atlas Vector Search
- Gérer l‘ensemble des intégrations et des métadonnées à partir d‘un seul endroit grâce au tout nouveau catalogue d‘intégrations.
- Chargement et transformation aisés des données grâce aux nouvelles fonctions AutoSync et à la prise en charge des points d‘extrémité, à l‘aplatissement des fichiers Parquet, etc.
- Exploiter des données variées dans un plus grand nombre d‘endroits, comme la prise en charge des données géospatiales dans le serveur SQL.
- Automatiser les cycles de vie des API et de l‘infrastructure plateforme avec davantage d‘API publiques
Et bien d‘autres choses encore. Plongeons dans ces mises à jour !
Plus de LLMs supportés et support VectorDB dans GenAI Builder
La dernière version de GenAI Builder ajoute la prise en charge des modèles de fondation d‘Anthropic Claude dans le cadre du Amazon Bedrock LLM Snap Pack. Vous pouvez exploiter n‘importe quel modèle d‘Anthropic Claude et générer des réponses aux messages à partir de celui-ci. Cette capacité vous permet de construire des applications GenAI qui améliorent la productivité des employés, assistent les clients avec une meilleure expérience de service, améliorent l‘expérience des partenaires, et plus encore.
Regardez cette vidéo sur la façon dont vous pouvez construire les workflows pour alimenter vos applications GenAI avec Anthropic Claude.
Nous ajoutons également le support d‘une nouvelle base de données vectorielle, MongoDB Atlas Vector Search, pour vous aider à construire des applications GenAI. Si vous utilisez la base de données MongoDB Atlas Vector Search, vous pouvez la connecter à vos applications GenAI. Avec MongoDB Atlas Vector Search Snap, vous pouvez effectuer des requêtes vectorielles avancées telles que des recherches de similarité, des requêtes sur les plus proches voisins (ANN), des requêtes sur l‘étendue, etc. Vous pouvez maintenant construire des assistants IA de génération augmentée avec vos données d‘entreprise qui vivent sur MongoDB Atlas Vector Search.
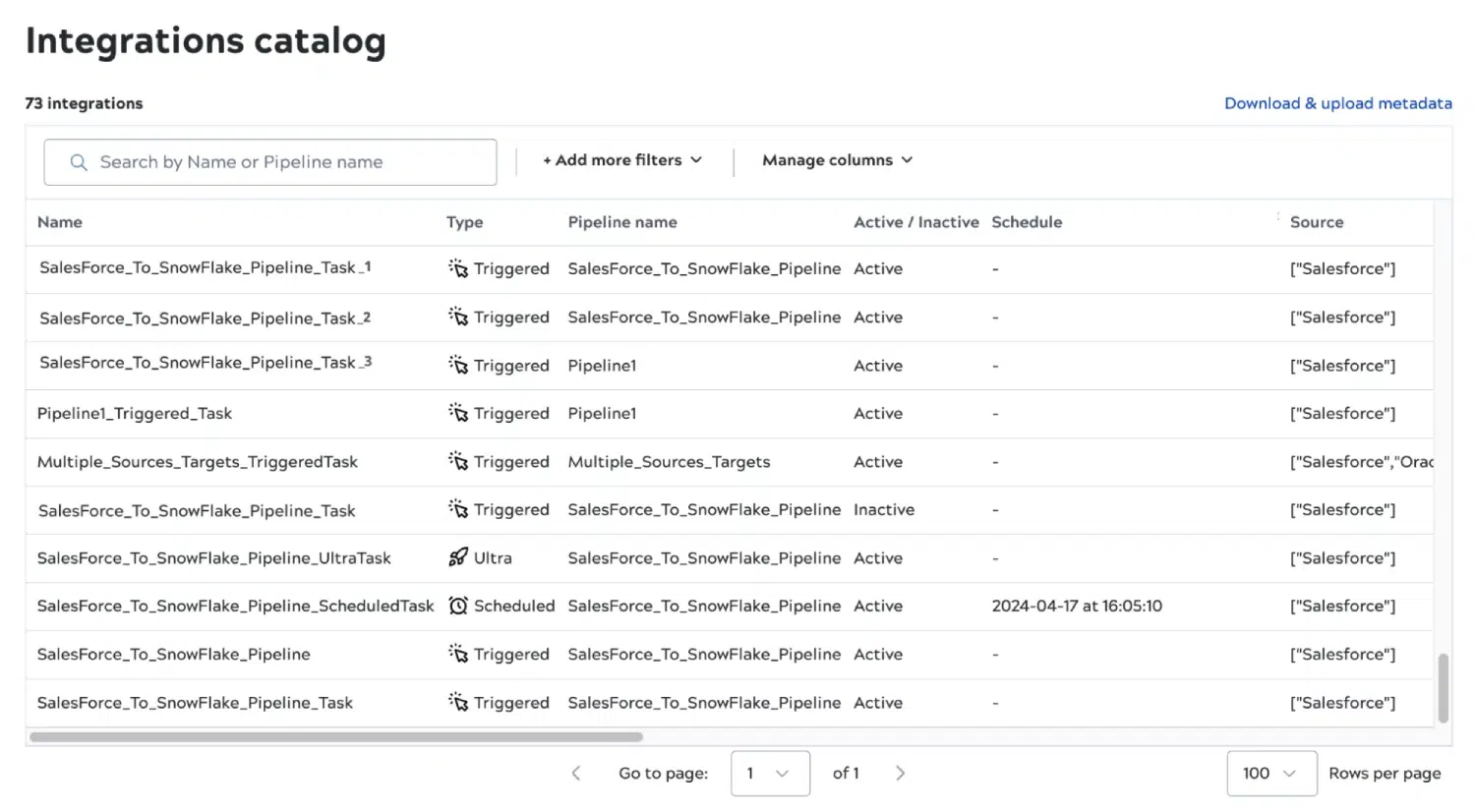
Tout nouveau catalogue d‘intégrations
Nous sommes très heureux d‘introduire un tout nouveau catalogue d‘intégrations avec cette version, pour vous donner une vue unifiée de toutes vos intégrations et des métadonnées associées. Le catalogue vous donne un répertoire de toutes les intégrations, permettant aux équipes de trouver, comprendre et gérer facilement les intégrations. Grâce au catalogue, vous pouvez comprendre votre paysage d‘intégration par domaine d‘activité et applications, identifier les pipelines en fonction des points d‘extrémité auxquels ils se connectent et réduire le coût des intégrations pour les applications nouvelles et existantes les workflows. Vous pouvez également suivre facilement ce que fait chaque pipeline afin d‘exploiter les intégrations existantes pour de nouvelles les workflows , réduisant ainsi le temps d‘intégration.
Le catalogue des intégrations expose des métadonnées qui ne sont disponibles nulle part ailleurs sur le site plateforme, telles que le propriétaire, l‘horaire et le nombre d‘instantanés. Une autre caractéristique importante est la possibilité d‘ajouter des métadonnées personnalisées. Grâce aux métadonnées personnalisées, les équipes informatiques centrales peuvent associer les intégrations aux processus métier afin de réduire le coût des opérations ou d‘améliorer le temps moyen de rétablissement (MTTR). En outre, elle peut utiliser les métadonnées personnalisées pour établir des rapports sur les applications connectées et les points de terminaison des données et comprendre les risques potentiels du système.
Les utilisateurs peuvent télécharger des métadonnées personnalisées pour les pipelines d‘intégration et exporter des métadonnées pour les intégrer à un catalogue de données tiers.
Découvrez le catalogue d‘intégrations dans cette vidéo de démonstration.
Amélioration des opérations et des transformations de données dans AutoSync
SnapLogic AutoSync a bénéficié d‘une forte augmentation de ses capacités au cours des derniers mois. En plus du connecteur HTTPClient Source qui vous permet d‘obtenir des données à partir de pratiquement n‘importe quel point d‘extrémité avec une API RESTFul, cette version ajoute de nouveaux points d‘extrémité cibles tels que Databricks, Amazon S3, Azure Data Lake Storage (ADLS) Gen2.
AutoSync offre désormais de nouvelles fonctionnalités qui vous permettent d‘arrêter un pipeline au milieu de son exécution. Mais comme l‘arrêt d‘un pipeline peut affecter l‘intégrité des données, nous recommandons de ne l‘utiliser qu‘en dernier recours et de procéder à un chargement complet dès que vous êtes prêt.
Le site plateforme vous permet désormais de mettre à niveau les points d‘extrémité d‘un pipeline AutoSync de manière transparente. Cela vous permettra d‘économiser des jours de travail pendant la durée de vie d‘un pipeline AutoSync, car vous n‘aurez plus à construire le même pipeline à partir de zéro.
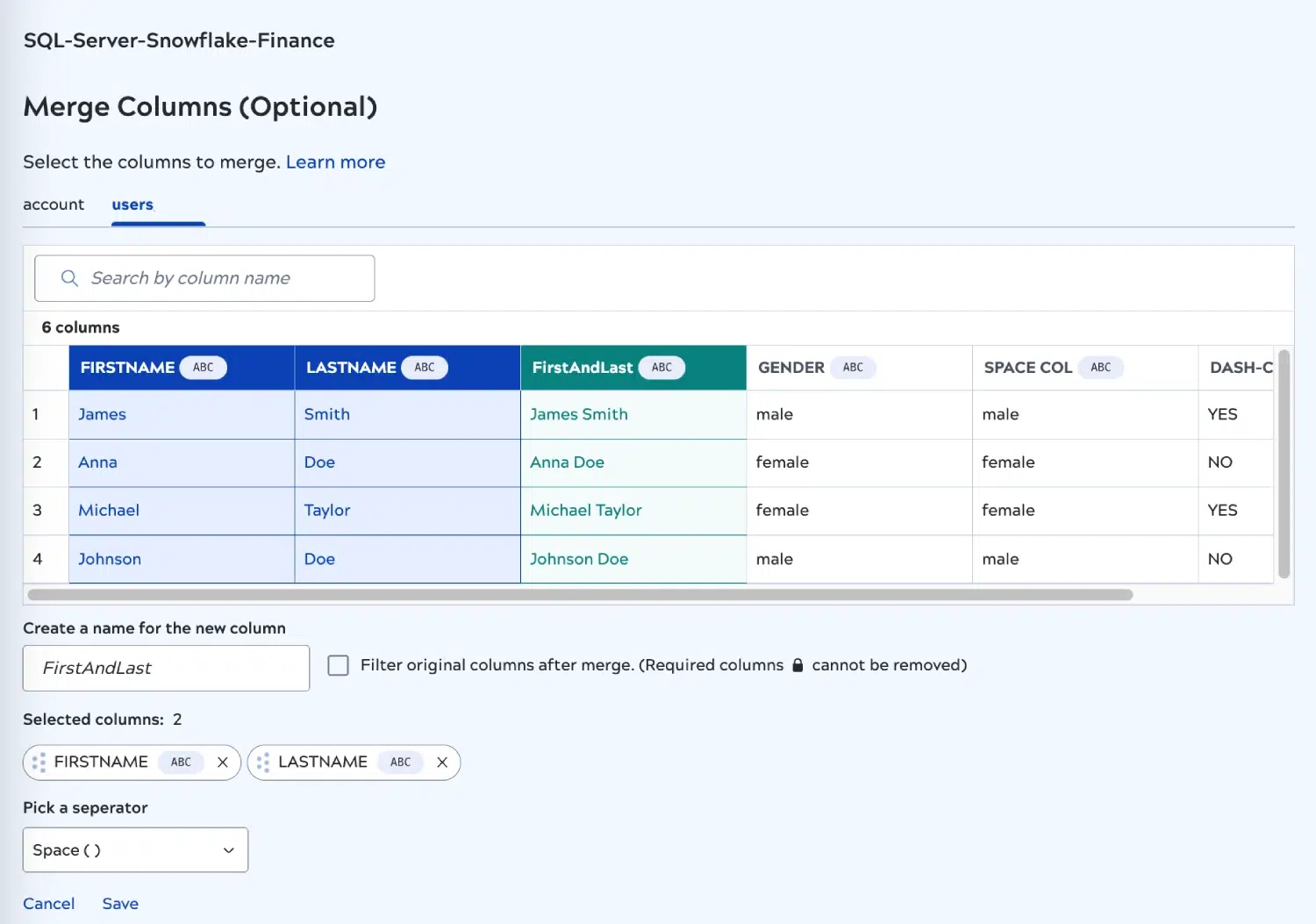
La version de mai introduit également de nouvelles fonctionnalités de transformation. Vous pouvez désormais concaténer plusieurs colonnes de type "String" à l‘aide de la nouvelle fonctionnalité Merge Column. Cela vous aidera à simplifier les structures de données dans la cible, ce qui se traduira par un stockage efficace et une réponse plus rapide aux requêtes.
Meilleure gestion des données parquet dans les ELT
Les clients qui souhaitent charger des fichiers parquet dans un entrepôt de données cloud tel que Snowflake via des charges de travail ELT peuvent désormais gérer facilement des ensembles de données imbriqués. La fonction ELT Load permet désormais d‘aplatir les données entrantes. Cette capacité vous permet d‘effectuer un prétraitement plus efficace, ce qui réduit le temps de traitement et les coûts dans l‘entrepôt de données cloud .
Mises à jour de Snap
La version de mai apporte de nombreuses améliorations à nos Snap Packs. Voici un résumé des principales mises à jour :
Snowflake Snap Pack: La version de mai ajoute la prise en charge des populaires tables Apache Iceberg aux snaps de chargement et d‘insertion de Snowflake Snap Pack. Les tables Iceberg répartissent les données sur plusieurs nœuds afin d‘accélérer le traitement des données et sont donc très populaires auprès de la communauté des utilisateurs. Cette fonctionnalité est en avant-première dans Snowflake mais nous savons que beaucoup d‘entre vous l‘ont déjà adoptée. Cette amélioration vous permet donc désormais d‘exploiter les pipelines SnapLogic pour créer et manipuler les tables Iceberg.
SQL Server Snap Pack : Les données géospatiales sont essentielles dans les secteurs de la vente au détail, de la chaîne d‘approvisionnement et de l‘assurance. À la demande de nos clients, nous avons donc ajouté la prise en charge des données géospatiales (géographie et géométrie) à Microsoft SQL Server Snap Pack. Ce support vous permet d‘insérer, de lire et de sélectionner les données géospatiales situées dans Microsoft SQL Server.
MongoDB Snap Pack : Nous ajoutons MongoDB Execute Snap au MongoDB Snap Pack afin que vous puissiez exécuter n‘importe quelle commande DDL (Data Definition Language) et DML (Data Manipulation Language) sur la base de données MongoDB.
NetSuite Snap Pack : Les mises à jour de mai du NetSuite Snap Pack ajoutent maintenant de nouveaux snaps pour déplacer des enregistrements en masse. L‘ajout de liste vous permet d‘ajouter de nouveaux enregistrements en vrac à NetSuite. Une liste d‘ajout asynchrone similaire ajoute ces enregistrements de manière asynchrone, c‘est-à-dire qu‘elle renvoie un ID de travail à l‘utilisateur. Le processus se termine en arrière-plan et vous pouvez vérifier l‘état de la tâche pour savoir si les enregistrements ont été ajoutés.
Automatisez votre cycle de vie API et votre infrastructure SnapLogic
Avec la version de mai, nous ajoutons plusieurs API publiques afin que vous puissiez automatiser le cycle de vie des API avec des outils CI/CD, tout comme vous gérez le cycle de vie de votre code ou de vos pipelines. Avec les nouvelles API publiques, vous pouvez créer une branche, créer une version d‘API, vérifier la branche, extraire les dernières modifications, étiqueter Git, vérifier le statut Repo, supprimer les modifications et supprimer une branche. Si vous développez des API pour vos clients internes ou externes, vous pouvez vous attendre à économiser des heures de travail manuel fastidieux chaque semaine grâce à ces API publiques.
Les nouvelles API publiques vous permettent également de procéder à un effacement progressif des API et de leurs versions. Les API seront alors placées dans une corbeille au lieu d‘être supprimées à jamais. Cela permettra aux gestionnaires d‘API de gagner du temps grâce à l‘échelle et de créer une meilleure expérience utilisateur grâce à la possibilité de revenir sur les suppressions si nécessaire.
De nouvelles API publiques permettent de créer, de mettre à jour et de supprimer un Groundplex afin de mettre en place une infrastructure à la volée pour des tests transitoires ou des initiatives de mise à l‘essai avant de promouvoir les changements vers la production. Une autre API publique vous permet de supprimer les modifications locales afin qu‘elles ne soient pas suivies par le dépôt GIT.
Amélioration de la sécurité des points d‘accès au proxy
Vous pouvez désormais ajouter une politique JWT à vos points d‘extrémité de proxy gérés dans API manager. L‘utilisateur peut configurer une politique de sortie JWT (JSON Web Token) pour ajouter une couche supplémentaire d‘authentification et de sécurité à ses API.
Une autre amélioration permet d‘ajouter plusieurs politiques de liaison de compte, telles que Outbound Basic Auth et Outbound OAuth, à un point de terminaison du proxy et les deux politiques seront appliquées dans l‘ordre. Auparavant, la première politique était ignorée. Cette modification permet à l‘utilisateur d‘avoir plusieurs politiques de liaison de compte dans un point de terminaison proxy/proxy. Cette modification s‘applique à toutes les politiques d‘authentification sortante.
Pour en savoir plus sur la version de mai, veuillez consulter les notes de version ou contacter l‘équipe chargée de la satisfaction de la clientèle.






