






Le mois de mai a été un mois marquant pour l'innovation produit chez SnapLogic. Dans la foulée de notre événement AgentFest, au cours duquel nous avons dévoilé AgentCreator 3.0 et APIM 3.0, nous avons continué à repousser les limites de ce qui est possible avec notre plateforme
Au-delà de ces annonces, la version de ce mois-ci apporte une nouvelle vague d'améliorations destinées à.. :
- Augmenter la productivité
- Renforcer les performances et la sécurité
- Améliorer l'observabilité
- Accroître la connectivité et la valeur
Examinons de plus près les nouveautés et la façon dont ces mises à jour peuvent aider votre équipe à avancer plus rapidement, sans compromettre les résultats ou la sécurité.
Productivité accrue grâce aux améliorations de SnapGPT
Les nouvelles améliorations apportées à SnapGPT rendent le développement de pipelines plus rapide, plus intelligent et plus intuitif. Avec la nouvelle fonctionnalité Pipeline Refinement (beta), les utilisateurs peuvent désormais demander à SnapGPT de modifier les pipelines existants. Vous pouvez rapidement attribuer des étiquettes descriptives et significatives aux Snaps, en insérant un Snap Router basé sur une logique spécifique. Mieux encore, SnapGPT comprend maintenant le contexte du canevas de pipeline, de sorte que vous pouvez faire des changements itératifs en utilisant un langage naturel sans avoir à répéter chaque détail.
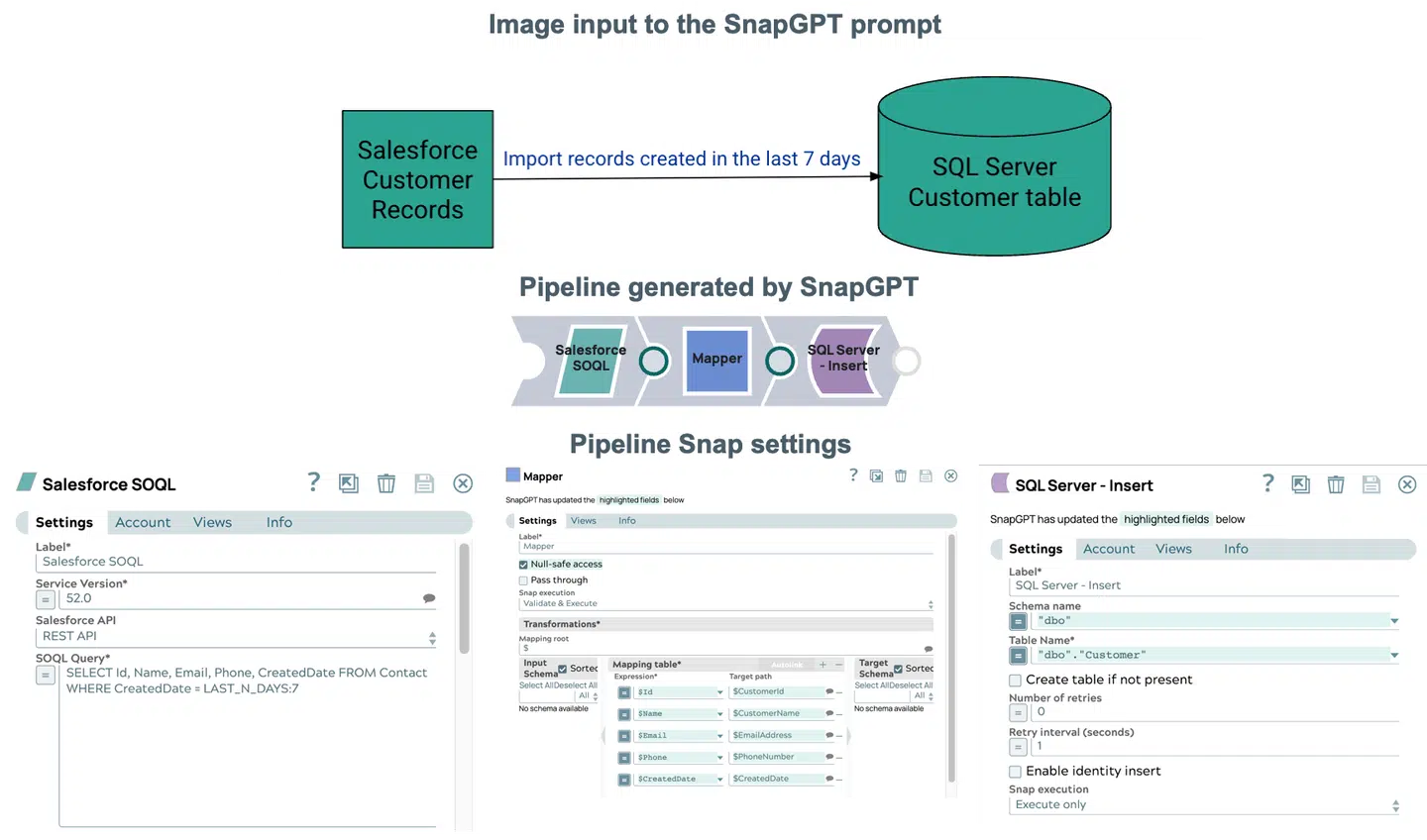
Une autre capacité intéressante : la création de pipeline à partir d'images. Il suffit de télécharger un diagramme de flux de données au format .jpg, .jpeg ou .png pour que SnapGPT génère un pipeline fonctionnel à partir de vos données visuelles. Que vous esquissiez des idées sur un tableau blanc ou que vous collaboriez avec des équipes à l'aide d'organigrammes, il n'a jamais été aussi facile de transformer des concepts en intégrations.
Surveillance simplifiée et dépannage plus rapide grâce à Monitor
SnapLogic Monitor est désormais l'application par défaut sur la plateforme SnapLogic pour visualiser les statistiques d'exécution et d'infrastructure et résoudre les problèmes. Vous aurez toujours accès au tableau de bord classique à partir du menu gaufre jusqu'en août 2025.
Les dernières améliorations apportées à Monitor facilitent plus que jamais l'identification et le dépannage des exécutions de tâches et de pipelines avec précision. Désormais, dans le catalogue des actifs, les onglets Tâches et Pipelines affichent des mesures opérationnelles clés, agrégées sur les 30 derniers jours :
- Total des courses
- Les succès et les échecs comptent
- Taux d'échec
- Durée moyenne d'exécution
- Nombre moyen de documents traités
Les utilisateurs peuvent rapidement filtrer par seuils métriques et effectuer des recherches dans ces nouveaux champs pour identifier les actifs peu performants ou défaillants. Ces améliorations simplifient la surveillance à grande échelle et aident les équipes à prendre des mesures proactives pour maintenir une santé optimale de l'intégration.
Un chemin plus rapide vers les workflows grâce à notre catalogue de modèles amélioré
Nous avons considérablement amélioré l'expérience utilisateur de notre catalogue de modèles. Le catalogue de modèles remanié vous donne toutes les informations à portée de main afin que vous puissiez identifier les modèles que vous souhaitez adopter rapidement. Avec cette version, vous verrez :
- Tags standardisés pour une meilleure organisation et un meilleur filtrage
- Un accès simplifié pour moins de clics pour ouvrir et appliquer un modèle
- Des informations en un coup d'œil, comme l'auteur du modèle et la date de sa dernière mise à jour.
- Découverte simplifiée grâce à des catégories d'accès rapide (comme AgentCreator qui vous aident à trouver ce dont vous avez besoin.

Amélioration de la connectivité grâce aux nouveaux Snap et Snap Packs
Favorisez les communications asynchrones avec le Google Pub/Sub Snap Pack
Avec le nouveau Snap Pack Pub/Sub de Google Cloud , les clients peuvent désormais construire facilement des architectures découplées et pilotées par les événements. Ce Snap Pack facilite la messagerie asynchrone entre les systèmes distribués, ce qui permet aux applications de publier, de consommer et d'accuser réception des messages sans couplage étroit. Il est idéal pour les pipelines de traitement de données en temps réel, la communication entre microservices et l'intégration des services Google Cloud dans lesles workflows cloud hybrides. Que vous construisiez des systèmes backend évolutifs ou des pipelines de streaming, ce Snap Pack apporte une livraison de messages fiable et de la flexibilité à votre architecture.
Modernisez vos opérations avec le Snap Pack OPC-UA
Le Snap Pack OPC UA permet une intégration transparente avec les systèmes industriels, ce qui en fait un atout majeur pour les clients des secteurs de la fabrication, de l'énergie et d'autres secteurs industriels. Grâce à un accès sécurisé et en temps réel aux données des capteurs, à la télémétrie des équipements et aux états des machines, les utilisateurs peuvent créer des pipelines d'automatisation qui relient les environnements IT et OT. Ce Snap Pack fournit des Snaps de lecture, de navigation, d'écriture et d'abonnement et prend en charge des cas d'utilisation tels que la maintenance prédictive, les jumeaux numériques et l'analyse industrielle, aidant les clients à moderniser leurs opérations tout en maintenant une gouvernance et une sécurité des données solides.
Gérer des données produit de haute qualité avec Syndigo Snap Pack
La gestion et la distribution de données produits de haute qualité sont facilitées par le nouveau Snap Pack de Syndigo. Conçu pour les détaillants et les fabricants, ce Snap Pack simplifie l'intégration avec les systèmes PIM et MDM de Syndigo, permettant une ingestion et une transformation transparentes du contenu produit. Il prend en charge les les workflows tels que l'intégration des données produit des fournisseurs, leur transformation pour les systèmes en aval et la synchronisation des données de base entre les différents canaux. Pour les entreprises qui cherchent à rationaliser les opérations des rayons numériques et à assurer la cohérence du contenu, ce Snap Pack apporte une valeur immédiate.
Meilleure interopérabilité avec le support d'Iceberg dans Amazon Athena Snap Pack
Apache Iceberg s'impose comme la norme par défaut pour les formats de tableaux ouverts. Les tables Iceberg peuvent être hébergées dans n'importe quel lac de données, comme S3, Azure Data Lake Storage et Google Cloud, et sont également prises en charge par Snowflake et Databricks, ce qui permet une interopérabilité totale. En outre, les tables Iceberg dans votre lac de données vous permettent d'exploiter n'importe quel moteur de traitement des données, comme Athena, Snowflake ou Trino, sans qu'il soit nécessaire de déplacer les données. L'ajout de la prise en charge des tables Iceberg dans le Snap Pack d'Amazon Athena permet aux clients de construire des architectures de lac de données plus dynamiques et plus rentables.
Nous avons également ajouté un nouveau Snap Bulk Upsert à l'Amazon Athena Snap Pack. Grâce à cela, les utilisateurs peuvent désormais fusionner et gérer efficacement de grands ensembles de données dans les tables Iceberg, ce qui permet des cas d'utilisation analytiques avancés tels que les dimensions à évolution lente (SCD), la journalisation d'audit et le suivi de la conformité. Cette amélioration renforce la cohérence des données, l'évolutivité et les performances des pipelines d'analyse, en particulier pour les clients qui utilisent des formats de table ouverts et des lacs de données distribués.
Pour en savoir plus sur ces mises à jour, consultez les notes de version du mois de mai. Si vous souhaitez voir des démonstrations en direct de certaines de ces fonctionnalités, rejoignez-nous pour notre Webinar les produits le 12 juin, à 9 heures, heure de Paris. Nous espérons vous y voir !






