






La question était la suivante : « SnapLogic peut-il transférer 30 téraoctets de données d'Oracle vers Redshift et combien de temps cela prendrait-il ? » Cette question provenait d'un client actuel qui souhaitait obtenir des chiffres sur les performances. Pour répondre à cette demande, nous avons dû mettre en place une édition Enterprise d'Oracle RDS à utiliser comme source ; nous disposons d'une instance avant-vente de Redshift que nous avons utilisée comme cible.
Mon collègue Matt Sagervenait de terminer une demande similaire pour l'un de ses comptes. Malheureusement, la cible de son client était différente. Nous nous sommes réunis pour une réunion Zoom afin de procéder à la configuration et, en quelques heures, nous avions terminé. La plupart du temps a été consacré à la configuration de la nouvelle instance RDS et à la vérification du bon fonctionnement de toutes les autorisations du compte. Nous avons intégré Redshift Snap et effectué un test en quelques minutes. Et comme chaque exécution prenait moins de 7 minutes, nous avons pu l'optimiser rapidement.
SnapLogic dispose d'une instance de démonstration de l'édition standard d'Oracle RDS, mais pour ce test, nous avons souhaité utiliser l'édition Enterprise. La configuration par défaut est plus importante et nous avions besoin d'une capacité supplémentaire pour les tests.
Nous l'avons chargé avec 5,8 Go de données à l'aide d'un pipeline simple.
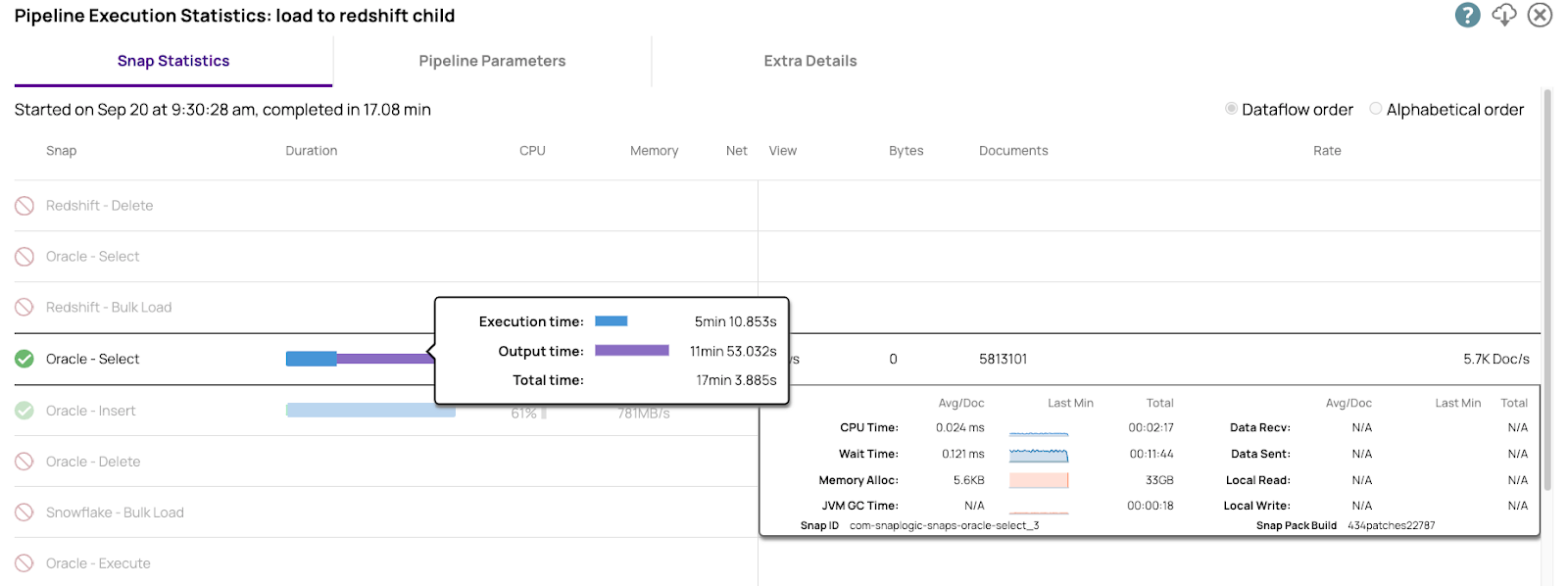
Une seule instance du pipeline a permis de transférer 5,8 Go de données depuis Oracle SE RDS vers Oracle EE RDS avec un débit soutenu de 5 700 lignes par seconde.
Voici les chiffres de performance issus d'Oracle Select. Nous disposons d'informations détaillées sur chaque indicateur opérationnel pertinent. Ces informations sont nécessaires pour optimiser les performances.
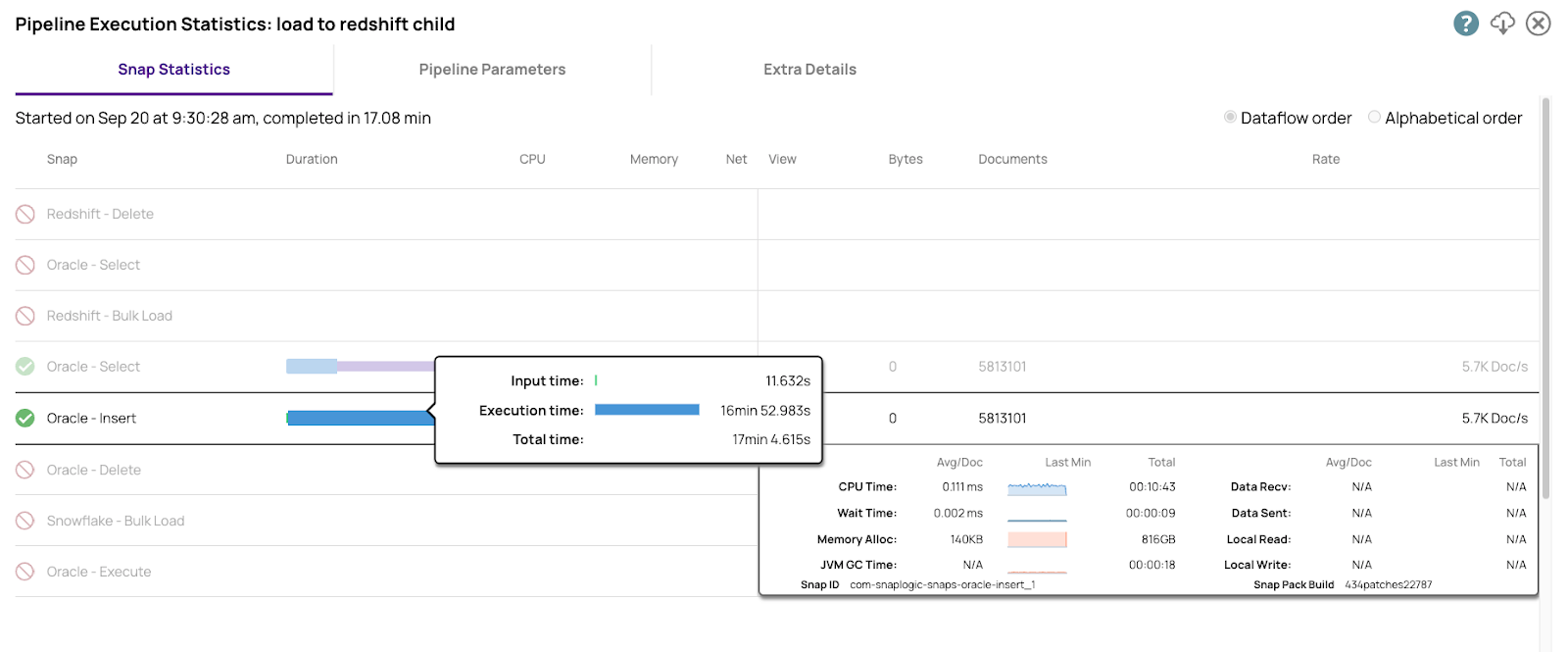
Voici les chiffres pour l'insertion dans l'édition Entreprise
Les deux instances Oracle, les compartiments S3 et Redshift se trouvaient tous dans la même région AWS afin de réduire autant que possible la latence réseau. Bien que ces chiffres soient intéressants, le véritable test s'est déroulé entre Oracle et Redshift.
Le Cloudplex que nous avons utilisé est un plex à six nœuds composé de nœuds 4vCPU et 16 Go de RAM.
Une fois les données importées dans Oracle, nous avons utilisé les pipelines de Matt et avons pu charger les données dans Redshift en parallèle à l'aide d'un pool de 32 pipelines enfants. La première exécution a pris un peu plus de sept minutes. Nous avons ajusté les tailles de récupération et de lot, et après trois autres exécutions, le temps final était de 5 813 101 lignes de données en 3,01 secondes.
Voici les résultats finaux du tableau de bord.
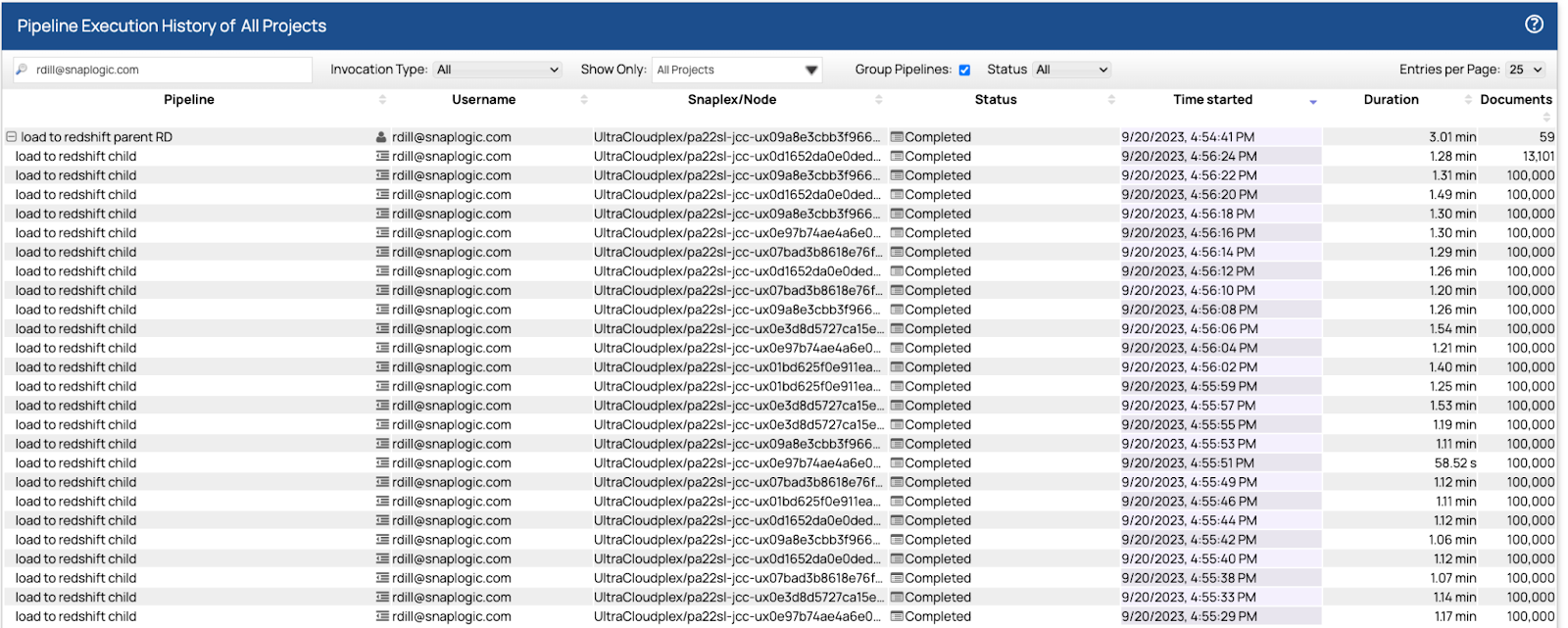
Chacun des pipelines enfants a lu et écrit 100 000 lignes dans un intervalle de temps compris entre 1,07 et 1,31 seconde. Le plan de contrôle a équilibré la charge des 32 pipelines enfants sur les six nœuds à l'aide d'un algorithme round robin, le moins utilisé. Les nœuds acceptaient et exécutaient autant de pipelines que possible. Lorsqu'ils atteignaient leur capacité maximale, les nouveaux pipelines étaient mis en attente et ne démarraient que lorsque le nœud avait la capacité de les exécuter. Du début à la fin, il a fallu 3,01 secondes pour exécuter le pipeline parent et les 59 instances enfants.
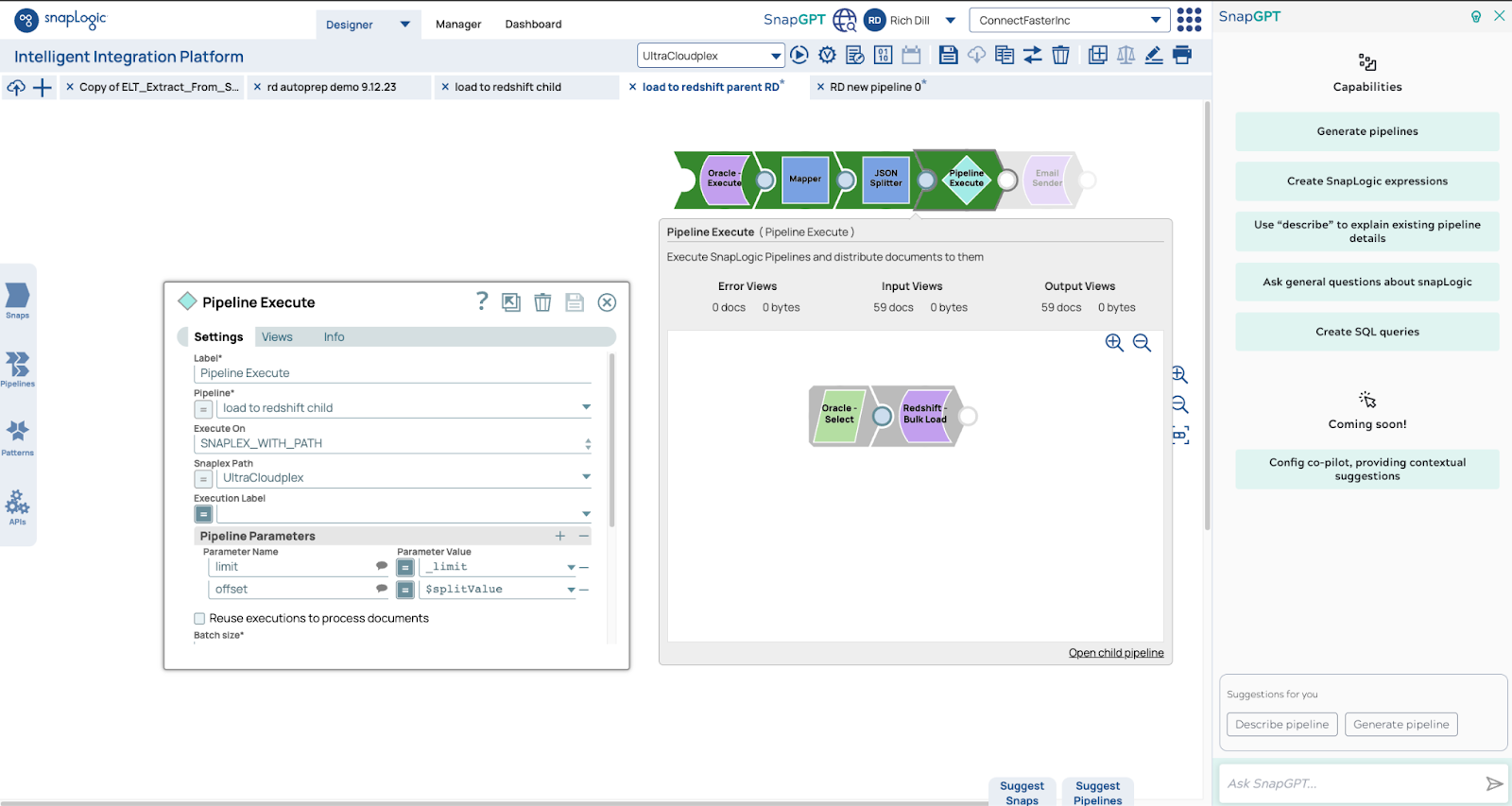
Voici les pipelines. Le pipeline parent utilise la fonction count pour obtenir le nombre de lignes. Nous utilisons ce nombre pour déterminer le nombre de pipelines enfants. Dans ce cas, 5,9 millions de lignes seront lues par 59 pipelines, chaque pipeline lisant et écrivant 100 000 lignes.
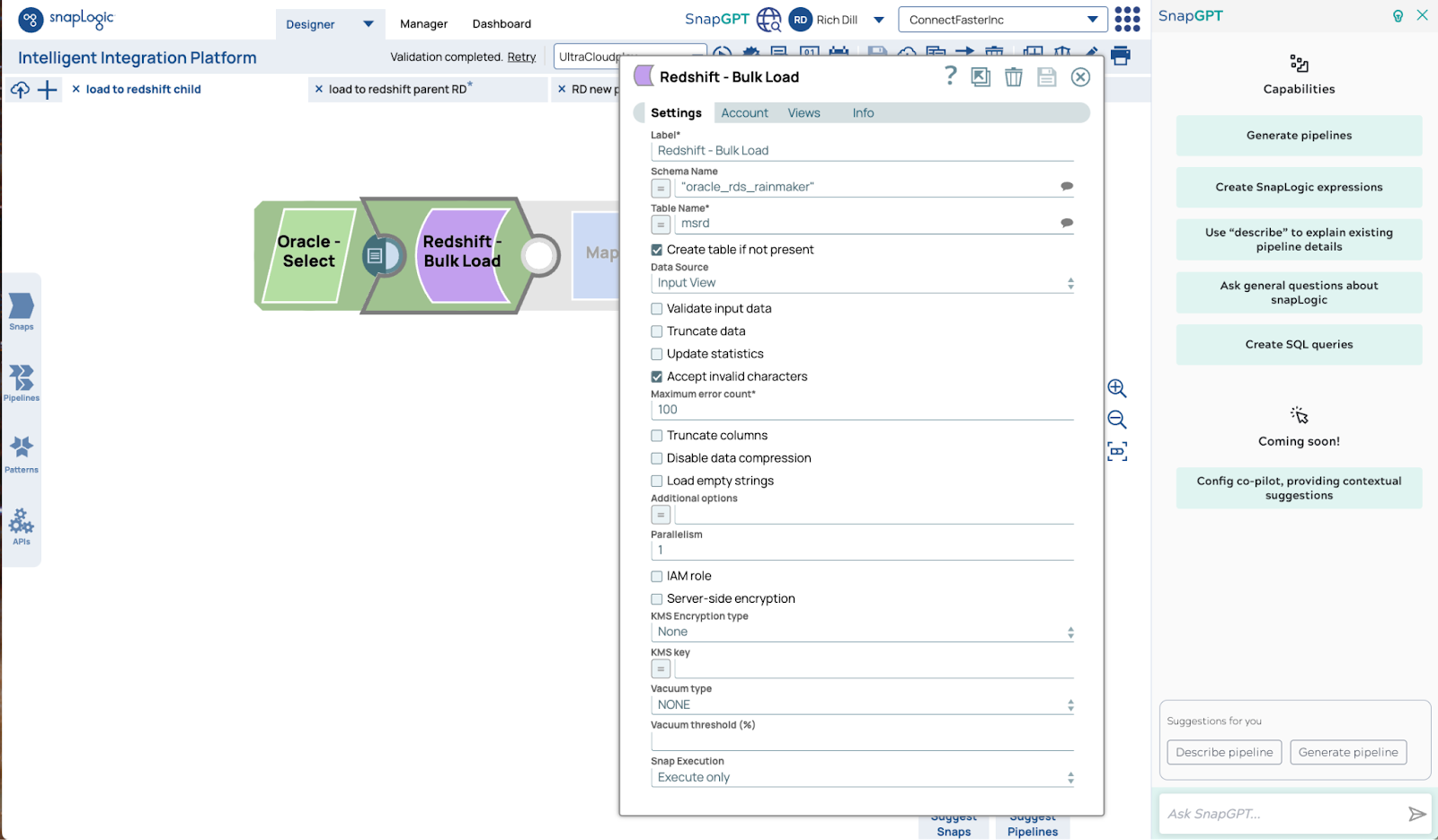
Voici la configuration Redshift Bulk Load Snap. Les paramètres standard sont suffisants pour fonctionner à grande échelle.
Nous avons utilisé un modèle courant pour répondre à une question d'un client en quelques heures. Nous avons pris un pipeline existant de Matt, en avons fait une copie, avons remplacé l'ancien chargement de base de données par le Redshift Bulk Load Snap et avons lancé des tests en quelques minutes.
Le test a été réalisé à l'aide de gigaoctets de données et de six grands nœuds pour modéliser le transfert de téraoctets. Il est facile de passer au niveau supérieur en augmentant simplement le nombre et la taille des nœuds. La limite supérieure de la capacité de ce modèle repose sur trois limites : les vitesses de lecture et d'écriture de la source et de la cible, ainsi que la bande passante du réseau. Nous avons des clients qui transfèrent chaque jour des téraoctets et des pétaoctets à l'aide de modèles comme celui-ci. Il est facile et rapide de transférer des données à grande échelle sans avoir à écrire de requêtes SQL ou de code complexes. Sélectionnez les Snaps de lecture et d'écriture dont vous avez besoin, attribuez-leur les paramètres appropriés et ajustez-les autant que nécessaire. En quelques minutes, votre tâche est terminée.






