





Résumez cela avec l'IA
Dans mon premier article sur les pipelines SnapLogic Ultra, j‘ai commencé à passer en revue les aspects à prendre en compte lors de la conception de ces pipelines à faible latence. Une fois que vous avez déterminé le bon nombre de vues, vous devez déterminer le type de vues. Les vues non connectées d‘un Ultra Pipeline agissent comme les gardiens de la tâche, recevant et renvoyant les documents des applications externes.
- Binaire – Les vues binaires permettent de diffuser des données binaires.
Cas d'utilisation : le pipeline Ultra peut servir à mettre en place une solution de capture d'images permettant de diffuser des données d'images binaires vers une application de gestion de contenu. Le Snap « Binary to Document » peut être utilisé comme Snap de départ du pipeline, le contenu binaire étant alors disponible dans le champ $content.
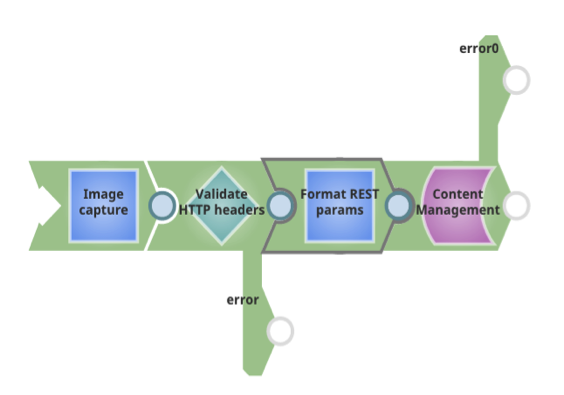
Cas d‘utilisation 2 : Réception d‘un flux binaire compressé, décompression et téléchargement vers un point final.
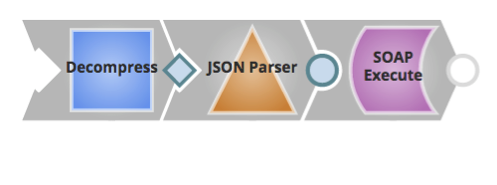
- Document – Les vues « Document » doivent être utilisées lorsque les en-têtes HTTP de la requête ou de la réponse doivent être analysés ou modifiés.
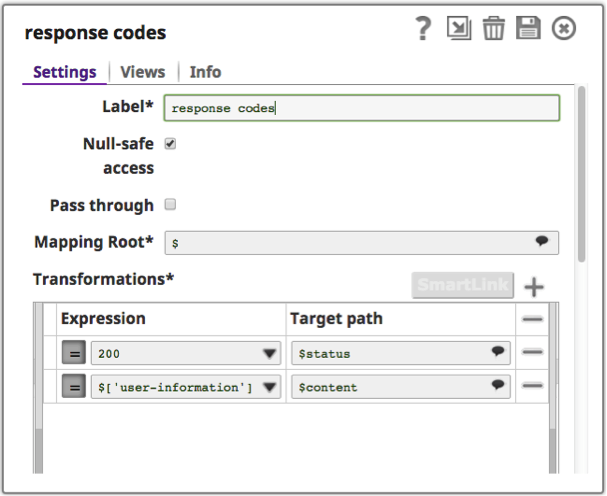
Cas d'utilisation : dans le pipeline illustré ci-dessous, les vues d'entrée et de sortie de document sont utilisées pour lire et définir les en-têtes HTTP. Un Snap de routage peut être utilisé pour déterminer la méthode et le type de contenu de la requête HTTP, ce qui permet au pipeline de traiter correctement le contenu XML ou JSON. Le pipeline renvoie un code d'état HTTP personnalisé défini dans le Snap « codes de réponse ».
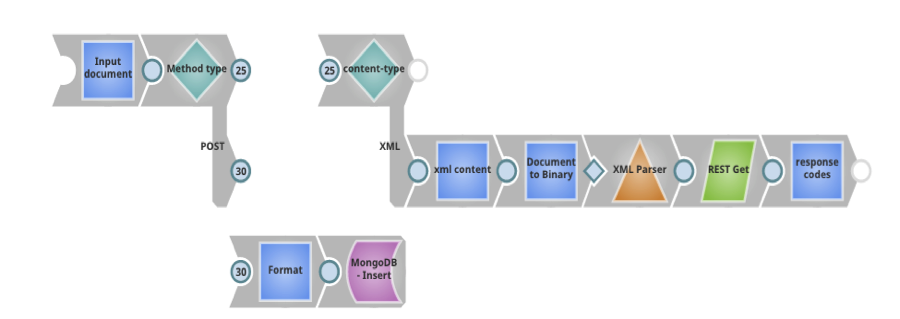
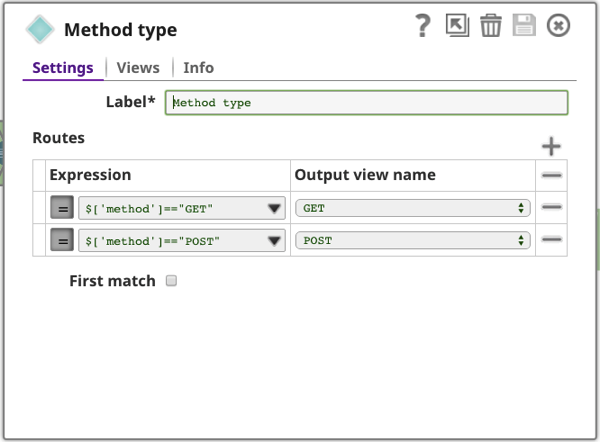
Les configurations utilisées dans cette filière sont les suivantes
Dans mon prochain article, je passerai en revue la gestion des erreurs et des exceptions d‘Ultra Pipeline.



