






Qu'est-ce que la génération augmentée par la récupération (RAG) ?
La génération augmentée par la recherche (RAG) est le processus qui consiste à améliorer les données de référence utilisées par les modèles linguistiques (LLM) en les intégrant à des systèmes traditionnels de recherche d'informations. Cette approche hybride permet aux LLM d'accéder à des bases de connaissances externes, des bases de données et d'autres sources d'informations faisant autorité, et de les utiliser, améliorant ainsi la précision, la pertinence et l'actualité des réponses générées sans nécessiter de formation approfondie. Sans RAG, les LLM génèrent des réponses basées sur les informations sur lesquelles ils ont été formés. Avec le RAG, le processus de génération de réponses est enrichi par l'intégration d'informations externes dans la génération.
Comment fonctionne la génération augmentée par la récupération ?
La génération augmentée par la récupération fonctionne en réunissant plusieurs systèmes ou services afin de générer la requête vers le LLM. Cela signifie qu'une configuration sera nécessaire pour prendre en charge les différents systèmes et services afin de fournir les données appropriées pour un flux de travail RAG. Cela implique plusieurs étapes clés :
1. Création d'une source de données externe :
Les données externes désignent les informations qui ne font pas partie des données d'entraînement d'origine du LLM. Ces données peuvent provenir de diverses sources, telles que des API, des bases de données, des référentiels de documents et des pages Web. Les données sont prétraitées et converties en représentations numériques (embeddings) à l'aide de modèles d'embedding, puis stockées dans une base de données vectorielle consultable avec une référence aux données qui ont été utilisées pour générer l'embedding. Cela forme une bibliothèque de connaissances qui peut être utilisée pour enrichir une invite lors de l'appel du LLM pour générer une réponse à une entrée donnée.
2. Récupération des informations pertinentes :
Lorsqu'un utilisateur saisit une requête, celle-ci est intégrée dans une représentation vectorielle et comparée aux entrées de la base de données vectorielle. La base de données vectorielle récupère les documents ou les données les plus pertinents en fonction de leur similarité sémantique. Par exemple, une requête concernant les politiques de congé d'une entreprise permettrait de récupérer à la fois le document général sur la politique de congé et les politiques de congé spécifiques à chaque poste.
3. Augmentation de la promptitude LLM :
Les informations récupérées sont ensuite intégrées dans l'invite à envoyer au LLM à l'aide de techniques d'ingénierie des invites. Cette invite entièrement formée est envoyée au LLM, fournissant un contexte supplémentaire et des données pertinentes qui permettent au modèle de générer des réponses plus précises et plus adaptées au contexte.
4. Génération de la réponse :
Le LLM traite l'invite augmentée et génère une réponse cohérente, adaptée au contexte et enrichie d'informations précises et actualisées.
Le diagramme suivant illustre le flux de données lors de l'utilisation de RAG avec des LLM.

Pourquoi utiliser la génération augmentée par la récupération ?
RAG relève plusieurs défis inhérents à l'utilisation des LLM en exploitant des sources de données externes :
1. Précision et pertinence accrues :
En accédant à des informations actualisées et fiables, RAG garantit que les réponses générées sont précises, spécifiques et pertinentes par rapport à la requête de l'utilisateur. Cela est particulièrement important pour les applications nécessitant des informations précises et actuelles, telles que des détails spécifiques sur une entreprise, des dates et des articles de sortie, les nouvelles fonctionnalités disponibles pour un produit, les détails individuels d'un produit, etc.
2. Mise en œuvre rentable :
RAG permet aux organisations d'améliorer les performances des LLM sans avoir recours à un réglage minutieux ou à une formation personnalisée des modèles, qui sont coûteux et prennent beaucoup de temps. En intégrant des bibliothèques de connaissances externes, RAG offre un moyen plus efficace de mettre à jour et d'élargir la base de connaissances du modèle.
3. Amélioration de la confiance des utilisateurs :
Avec RAG, les réponses peuvent inclure des citations ou des références aux sources d'information originales, ce qui accroît la transparence et la confiance. Les utilisateurs peuvent vérifier la source de l'information, ce qui renforce la crédibilité et la confiance dans un système d'IA.
4. Contrôle accru pour les développeurs :
Les développeurs peuvent facilement mettre à jour et gérer les sources de connaissances externes utilisées par le LLM, ce qui permet une adaptation flexible aux exigences changeantes ou aux besoins spécifiques d'un domaine. Ce contrôle inclut la possibilité de restreindre la récupération d'informations sensibles et de garantir l'exactitude des réponses générées. Associé à un cadre d'évaluation (lien vers l'article sur le pipeline d'évaluation), cela peut aider à déployer plus rapidement de nouveaux contenus auprès des consommateurs en aval.
Snaplogic GenAI App Builder : créer facilement des RAG
Snaplogic GenAI App Builder permet aux utilisateurs professionnels de créer des solutions basées sur des modèles linguistiques à grande échelle (LLM) sans avoir besoin de compétences en codage. Cet outil offre le moyen le plus rapide de développer des applications d'entreprise génératives en tirant parti des services de leaders du secteur tels que OpenAI, Azure OpenAI, Amazon Bedrock, Anthropic Claude sur AWS et Google Gemini. Les utilisateurs peuvent créer sans effort des applications LLM et les workflows cette plateforme robuste.
Avec Snaplogic GenAI App Builder, vous pouvez créer à la fois un pipeline d'indexation et un pipeline de génération augmentée par la recherche (RAG) avec un minimum d'efforts.
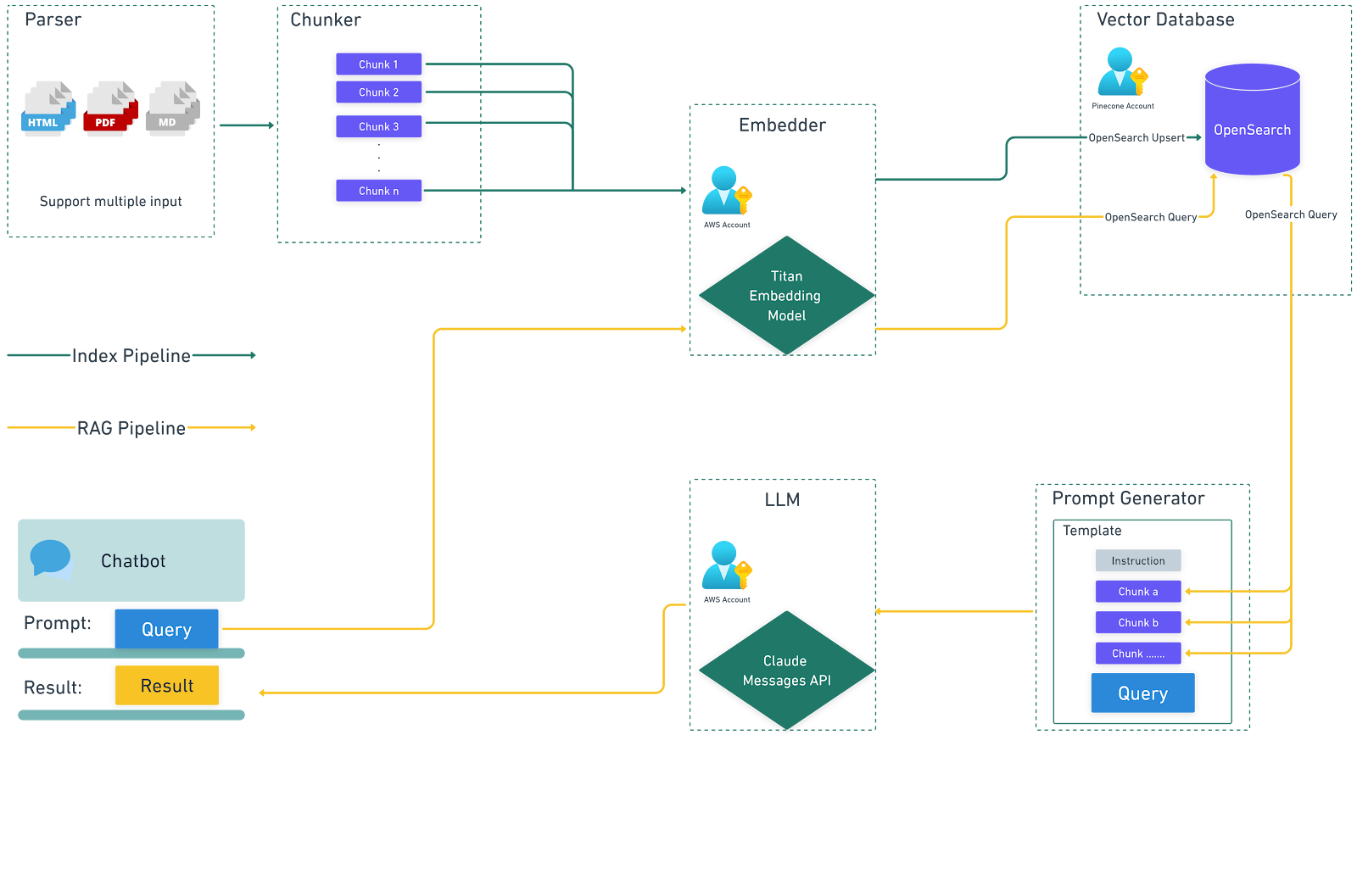
Pipeline d'indexation
Ce pipeline est conçu pour stocker le contenu d'un fichier PDF dans une bibliothèque de connaissances, rendant ainsi le contenu facilement accessible pour une utilisation future.

Après avoir exécuté ce pipeline, nous pourrons visualiser ces vecteurs dans OpenSearch.
Pipeline RAG
Ce pipeline permet la création d'un chatbot capable de répondre à des questions en se basant sur les informations stockées dans la bibliothèque de connaissances.

Pour mettre en œuvre ces pipelines, la solution utilise Amazon Bedrock Snap Pack et OpenSearch Snap Pack. Cependant, les utilisateurs ont la possibilité d'utiliser d'autres Snaps LLM et bases de données vectorielles pour obtenir des fonctionnalités similaires.






