






La domanda era: "SnapLogic è in grado di trasferire 30 terabyte di dati da Oracle a Redshift e quanto tempo ci vorrebbe?" Questa domanda è stata posta da un cliente attuale che ha richiesto alcuni dati sulle prestazioni. Per soddisfare questa richiesta, abbiamo dovuto avviare una versione Enterprise Edition di Oracle RDS da utilizzare come fonte; abbiamo utilizzato un'istanza pre-vendita di Redshift come destinazione.
Il mio collega Matt Sageraveva appena completato una richiesta simile per uno dei suoi account. Purtroppo l'obiettivo del suo cliente era diverso. Ci siamo riuniti per una riunione su Zoom per effettuare la configurazione e in un paio d'ore abbiamo completato il lavoro. La maggior parte del tempo è stata dedicata alla configurazione della nuova istanza RDS e alla verifica del corretto funzionamento di tutte le autorizzazioni dell'account. Abbiamo inserito Redshift Snap e in pochi minuti abbiamo eseguito un test. E poiché ogni esecuzione richiedeva meno di 7 minuti, siamo stati in grado di ottimizzarla rapidamente.
SnapLogic dispone di un'istanza demo della versione standard di Oracle RDS, ma per questo test abbiamo voluto utilizzare la versione Enterprise Edition. La configurazione predefinita è più ampia e volevamo una capacità aggiuntiva per i test.
L'abbiamo caricato con 5,8 gigabyte di dati utilizzando una semplice pipeline.
Una singola istanza della pipeline è stata in grado di trasferire 5,8 GB di dati da Oracle SE RDS a Oracle EE RDS con un throughput sostenuto di 5,7k righe al secondo.
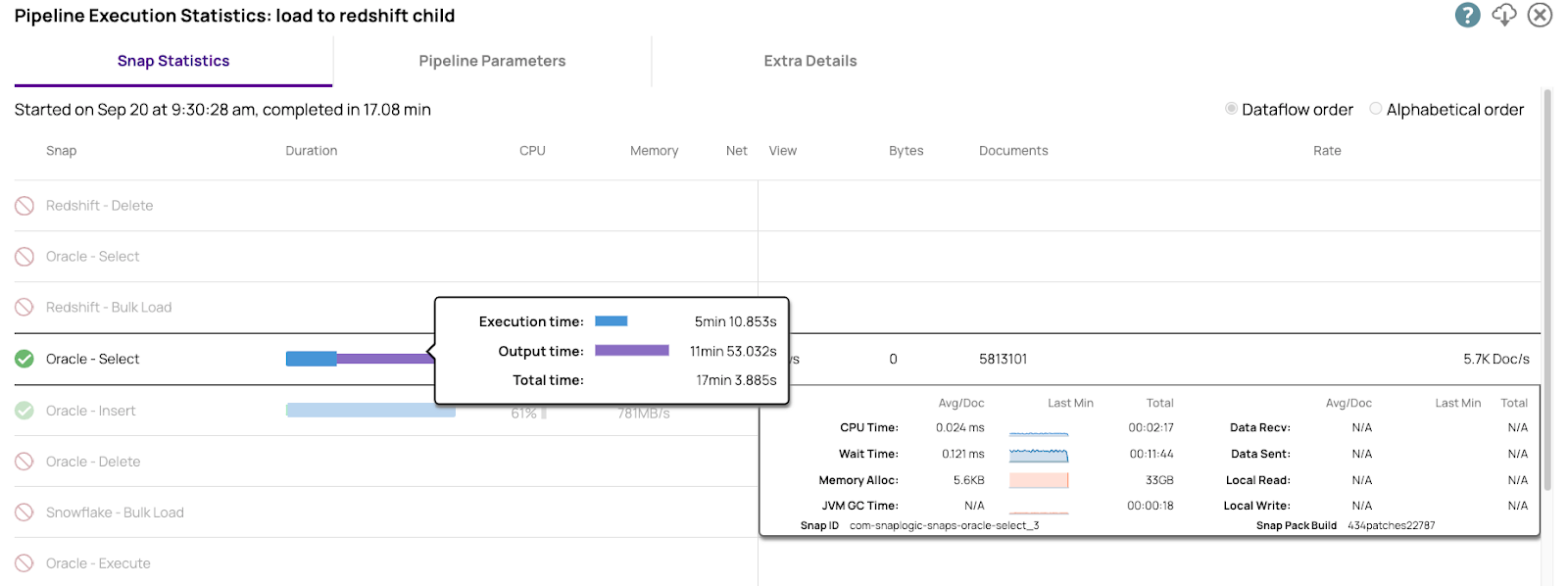
Ecco i dati relativi alle prestazioni di Oracle Select. Disponiamo di informazioni dettagliate su ogni parametro operativo rilevante. Queste informazioni sono necessarie per l'ottimizzazione delle prestazioni.
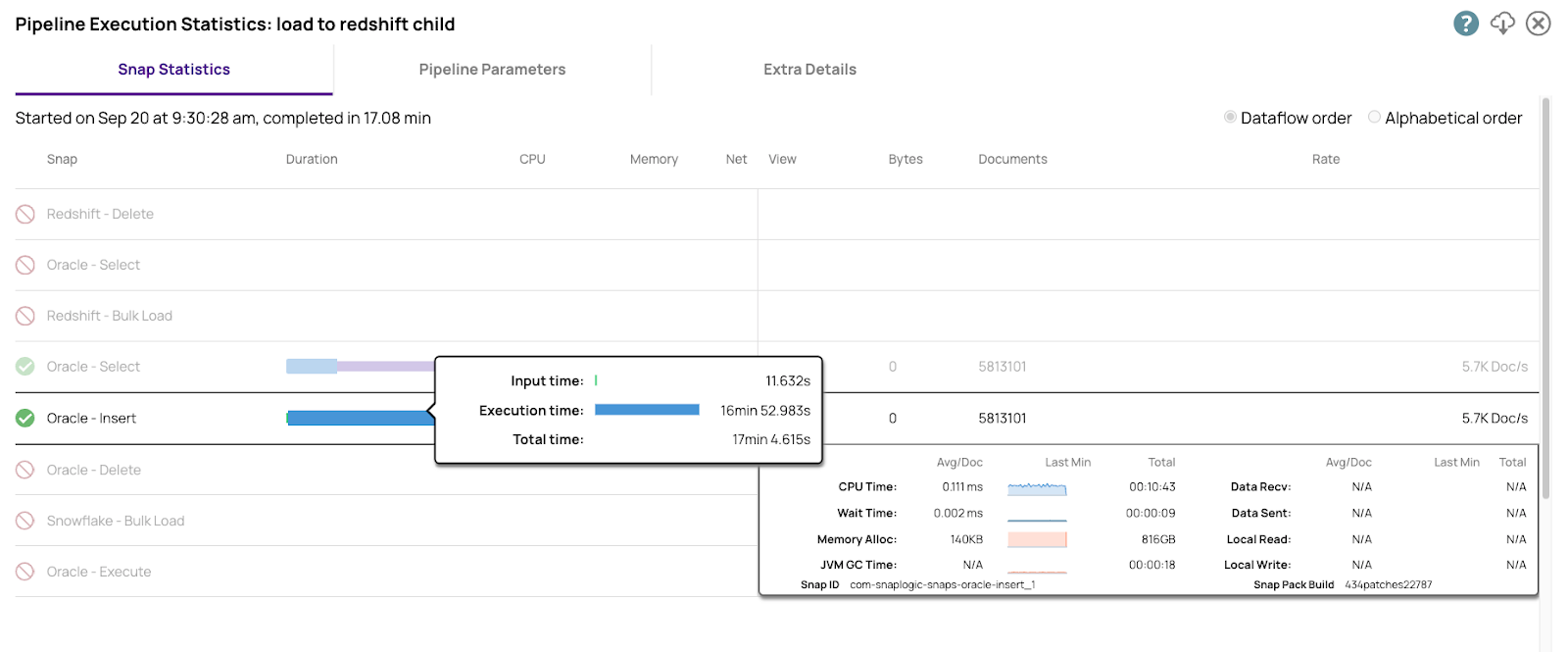
Ecco i numeri per l'inserimento nell'Enterprise Edition
Entrambe le istanze di Oracle, i bucket S3 e Redshift si trovavano nella stessa regione AWS per ridurre il più possibile la latenza di rete. Sebbene questi numeri siano interessanti, il vero test è stato quello tra Oracle e Redshift.
Il Cloudplex che abbiamo utilizzato è un plex a sei nodi composto da 4 CPU virtuali e nodi con 16 GB di RAM.
Una volta ottenuti i dati in Oracle, abbiamo utilizzato le pipeline di Matt e siamo riusciti a caricare i dati in Redshift in parallelo utilizzando un pool di 32 pipeline secondarie. La prima esecuzione ha richiesto poco più di sette minuti. Abbiamo modificato le dimensioni di recupero e batch e, dopo altre tre esecuzioni, il tempo finale è stato di 5.813.101 righe di dati in 3,01 secondi.
Ecco i risultati finali dal dashboard.
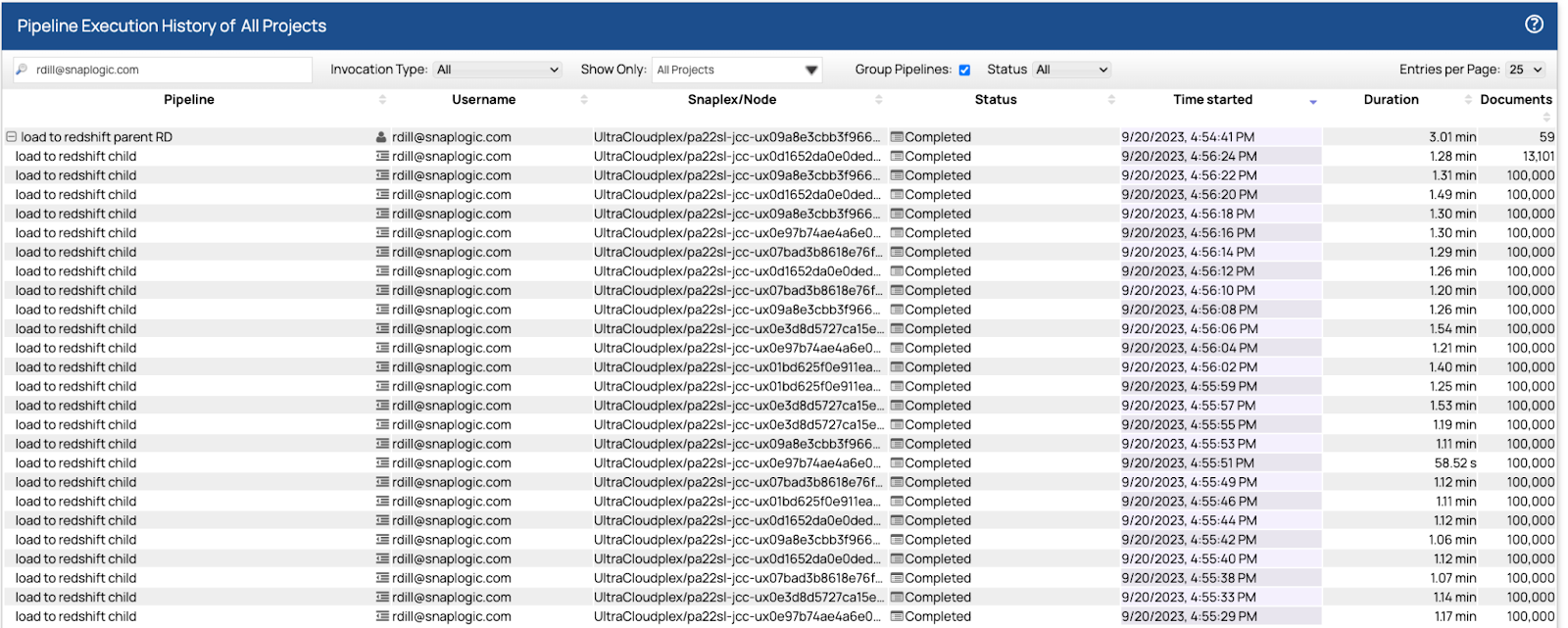
Ciascuna delle pipeline figlie ha letto e scritto 100.000 righe in un intervallo di tempo compreso tra 1,07 e 1,31 secondi. Il piano di controllo ha bilanciato il carico delle 32 pipeline figlie sui sei nodi utilizzando un algoritmo round robin, least used. I nodi accettavano ed eseguivano il maggior numero possibile di operazioni. Quando raggiungevano la capacità massima, le nuove pipeline venivano messe in attesa e avviate solo quando il nodo aveva la capacità di eseguirle. Dall'inizio alla fine, l'esecuzione della pipeline principale e delle 59 istanze secondarie ha richiesto 3,01 secondi.
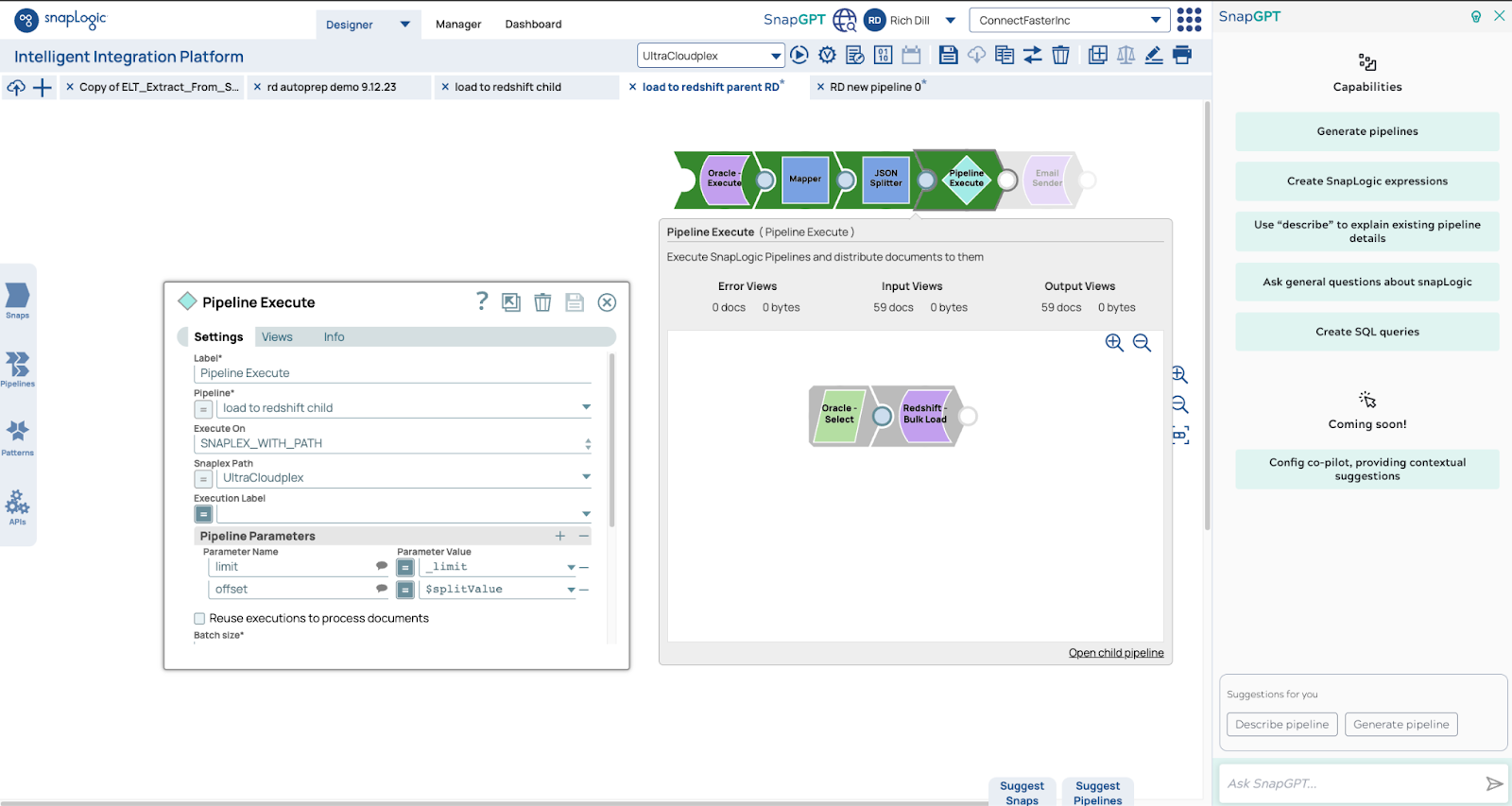
Ecco le pipeline. La pipeline principale utilizza la funzione count per ottenere il numero di righe. Utilizziamo tale numero per determinare il numero di pipeline secondarie, in questo caso 5,9 milioni di righe saranno lette da 59 pipeline, ciascuna delle quali leggerà e scriverà 100.000 righe.
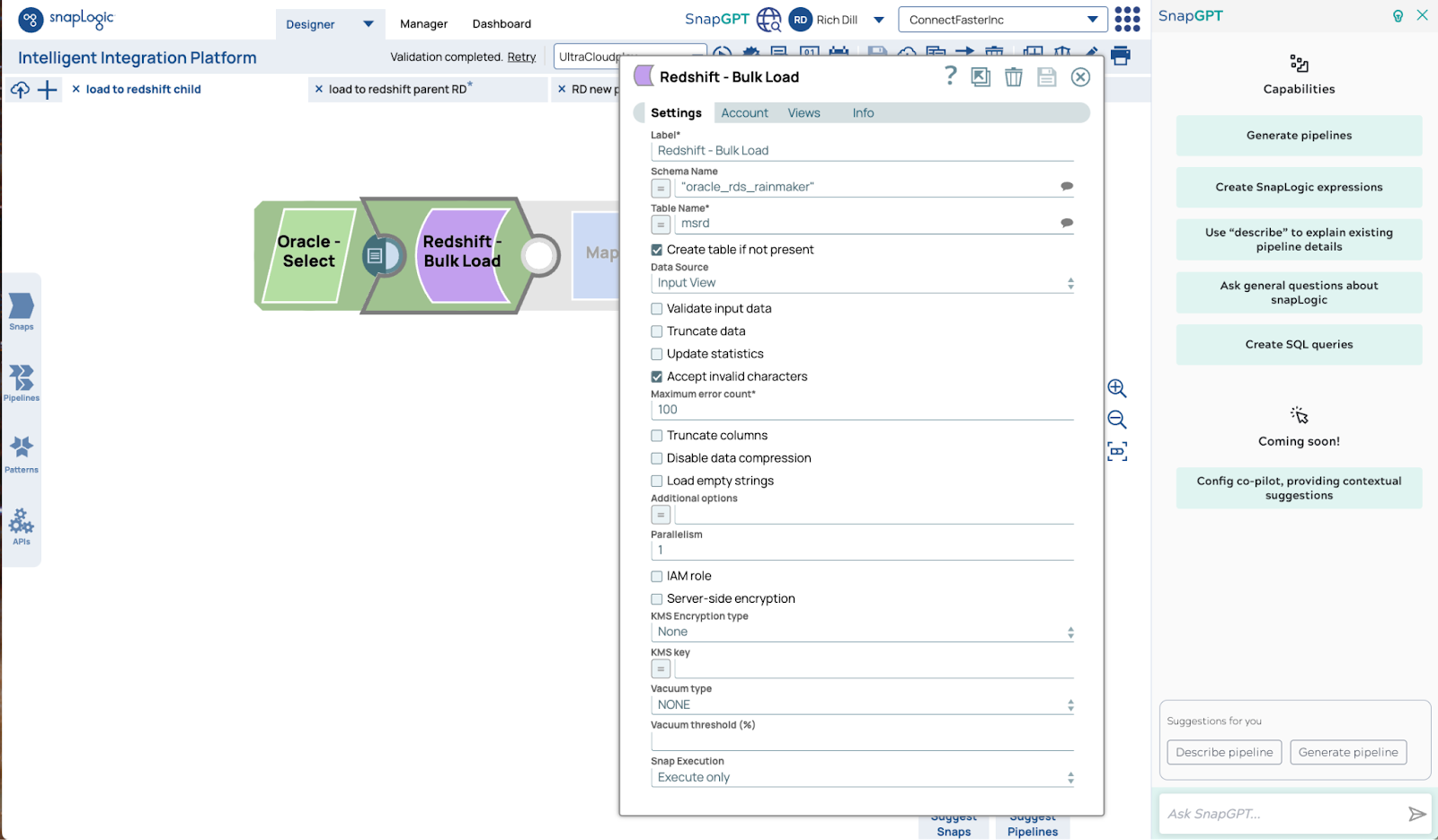
Ecco la configurazione di Redshift Bulk Load Snap: le impostazioni standard sono tutto ciò che serve per ottenere prestazioni su larga scala.
Abbiamo utilizzato un modello comune per rispondere alla domanda di un cliente in un paio d'ore. Abbiamo preso una pipeline esistente di Matt, ne abbiamo fatto una copia e abbiamo sostituito il vecchio caricamento del database con Redshift Bulk Load Snap, eseguendo i test in pochi minuti.
Il test è stato eseguito utilizzando gigabyte di dati e sei nodi di grandi dimensioni per modellare terabyte in movimento. Per passare al livello successivo è sufficiente aumentare il numero e le dimensioni dei nodi. Il limite massimo della capacità di questo modello si basa su tre limiti: la velocità di lettura e scrittura dell'origine e della destinazione e la larghezza di banda della rete. Abbiamo clienti che trasferiscono terabyte e petabyte ogni giorno utilizzando modelli come questo. È un'operazione semplice e veloce trasferire dati su larga scala senza scrivere complesse istruzioni SQL o codice. Selezionate gli Snap di lettura e scrittura necessari, assegnate loro i parametri corretti e ottimizzateli secondo le vostre esigenze: in pochi minuti il vostro compito sarà completato.






