






Die Frage lautete: „Kann SnapLogic 30 Terabyte Daten von Oracle nach Redshift übertragen und wie lange würde das dauern?“ Diese Frage kam von einem bestehenden Kunden, der einige Leistungsdaten anforderte. Um diese Anfrage zu erfüllen, mussten wir eine Enterprise Edition von Oracle RDS als Quelle einrichten; als Ziel verwendeten wir eine Pre-Sales-Instanz von Redshift.
Mein Teamkollege Matt Sagerhatte gerade eine ähnliche Anfrage für eines seiner Konten bearbeitet. Leider war das Ziel für seinen Kunden ein anderes. Wir trafen uns zu einem Zoom-Meeting, um die Einrichtung vorzunehmen, und innerhalb weniger Stunden hatten wir dies erledigt. Die meiste Zeit verbrachten wir damit, die neue RDS-Instanz einzurichten und sicherzustellen, dass alle Kontoberechtigungen funktionierten. Wir fügten den Redshift Snap hinzu und führten innerhalb weniger Minuten einen Test durch. Da jeder Durchlauf weniger als 7 Minuten dauerte, konnten wir ihn schnell optimieren.
SnapLogic verfügt über eine Demo-Instanz der Standard Edition von Oracle RDS, aber für diesen Test wollten wir die Enterprise Edition verwenden. Die Standardkonfiguration ist umfangreicher, und wir wollten die zusätzliche Kapazität für die Tests nutzen.
Wir haben es mit einer einfachen Pipeline mit 5,8 Gigabyte Daten geladen.
Eine einzelne Instanz der Pipeline konnte 5,8 GB Daten von Oracle SE RDS zu Oracle EE RDS mit einem kontinuierlichen Durchsatz von 5,7 k Zeilen pro Sekunde übertragen.
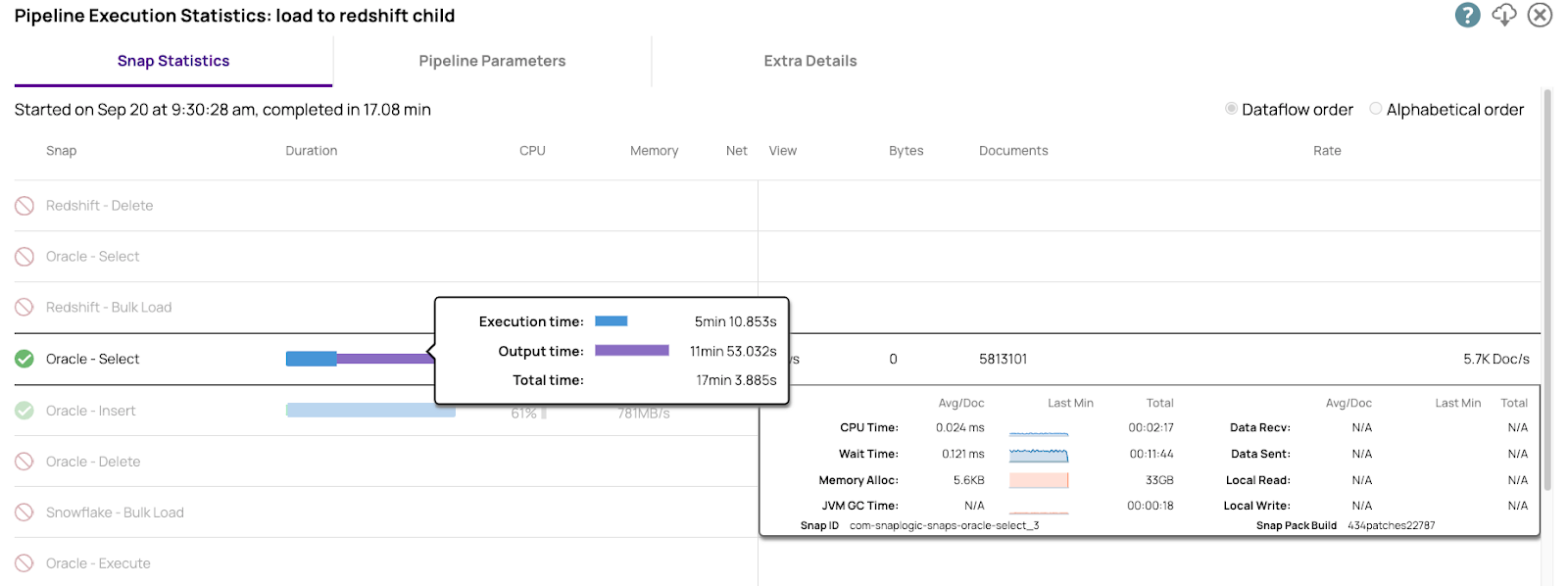
Hier sind die Leistungszahlen aus Oracle Select. Wir haben detaillierte Informationen zu allen relevanten Betriebskennzahlen. Diese Informationen werden für die Leistungsoptimierung benötigt.
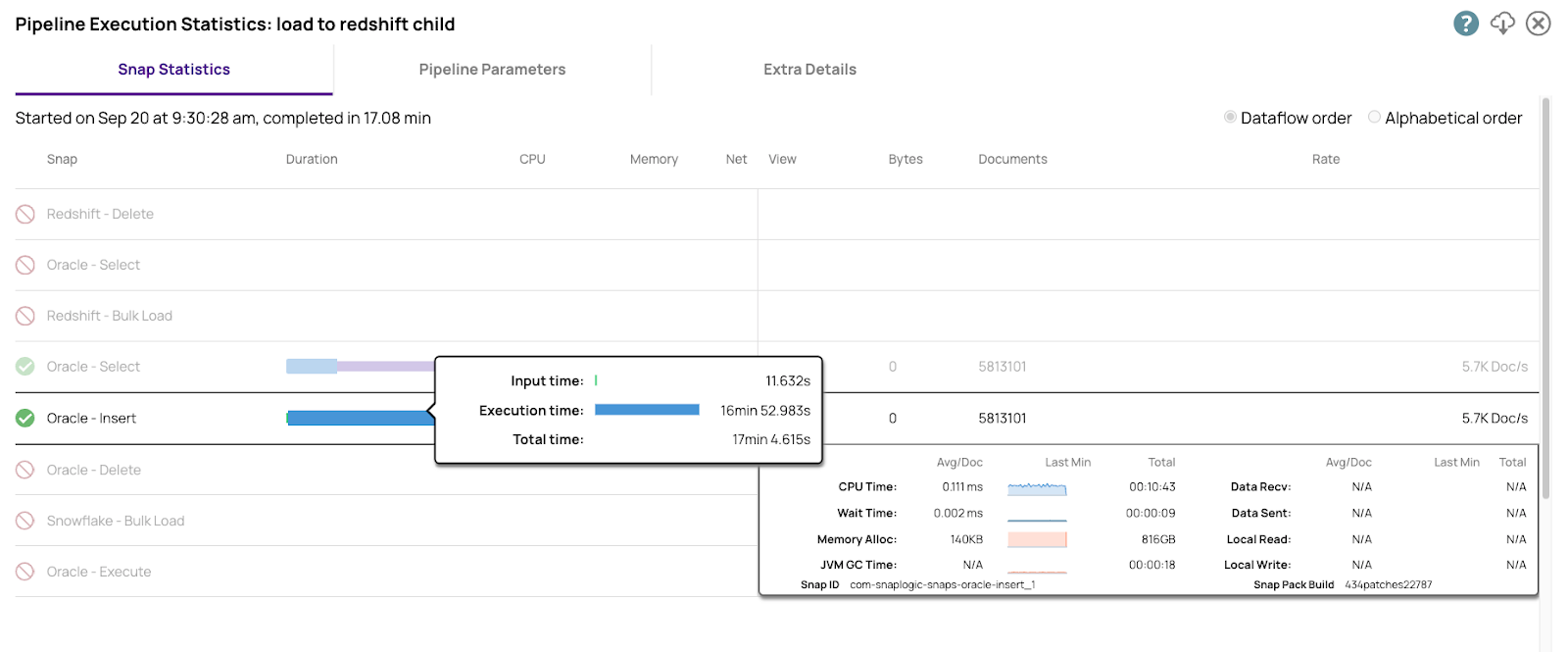
Hier sind die Zahlen für die Insert into Enterprise Edition
Beide Oracle-Instanzen, die S3-Buckets und Redshift befanden sich alle in derselben AWS-Region, um die Netzwerklatenz so weit wie möglich zu reduzieren. Diese Zahlen sind zwar interessant, aber der eigentliche Test fand zwischen Oracle und Redshift statt.
Der von uns verwendete Cloudplex ist ein Plex mit sechs Knoten, bestehend aus 4 vCPUs und 16 GB RAM-Knoten.
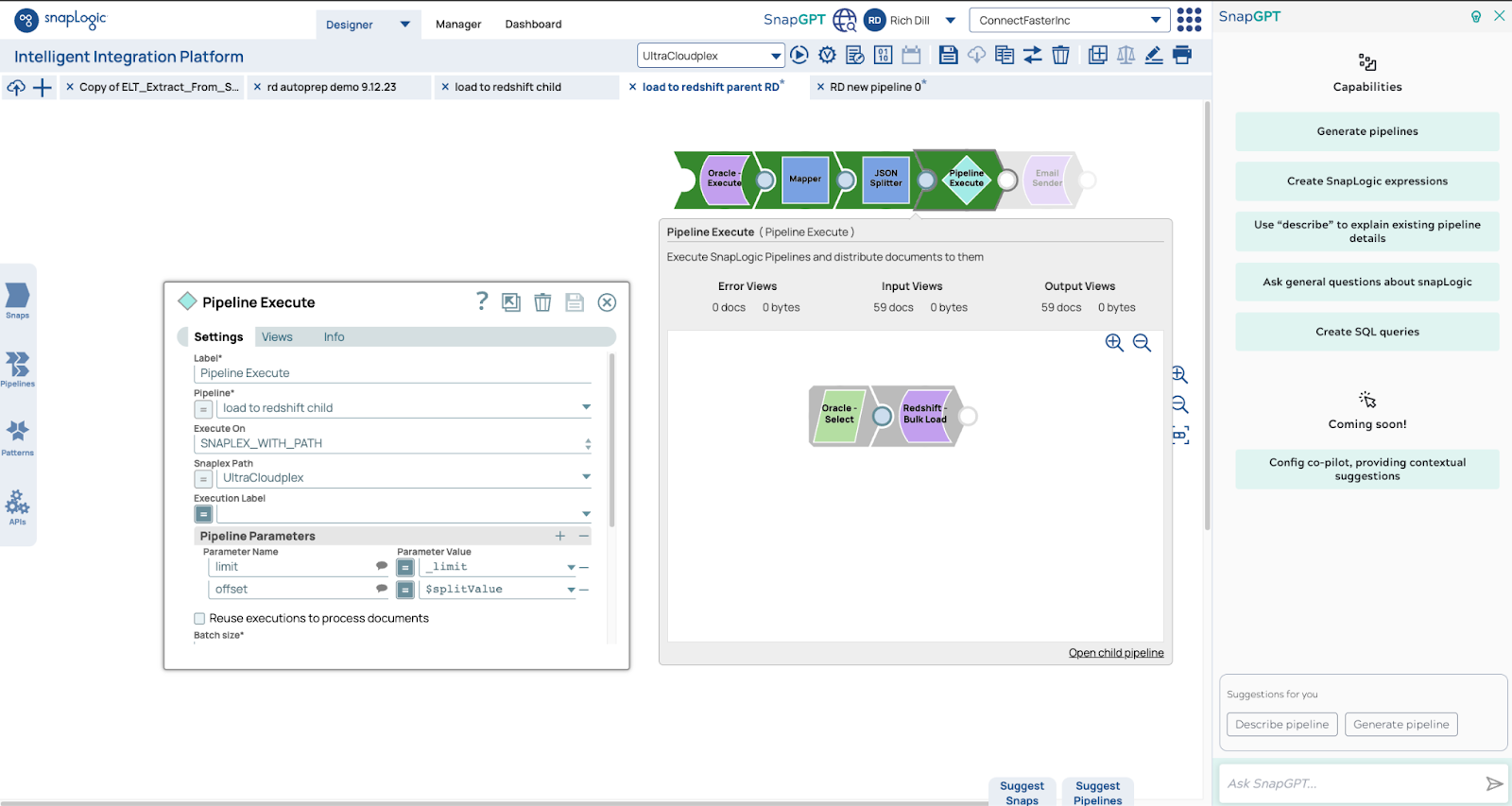
Nachdem wir die Daten in Oracle hatten, nahmen wir Matts Pipelines und konnten die Daten mithilfe eines Pools von 32 untergeordneten Pipelines parallel in Redshift laden. Der erste Durchlauf dauerte etwas mehr als sieben Minuten. Wir optimierten die Abruf- und Stapelgrößen, und nach drei weiteren Durchläufen betrug die Endzeit 5.813.101 Datenzeilen in 3,01 Sekunden.
Hier sind die endgültigen Ergebnisse aus dem Dashboard.
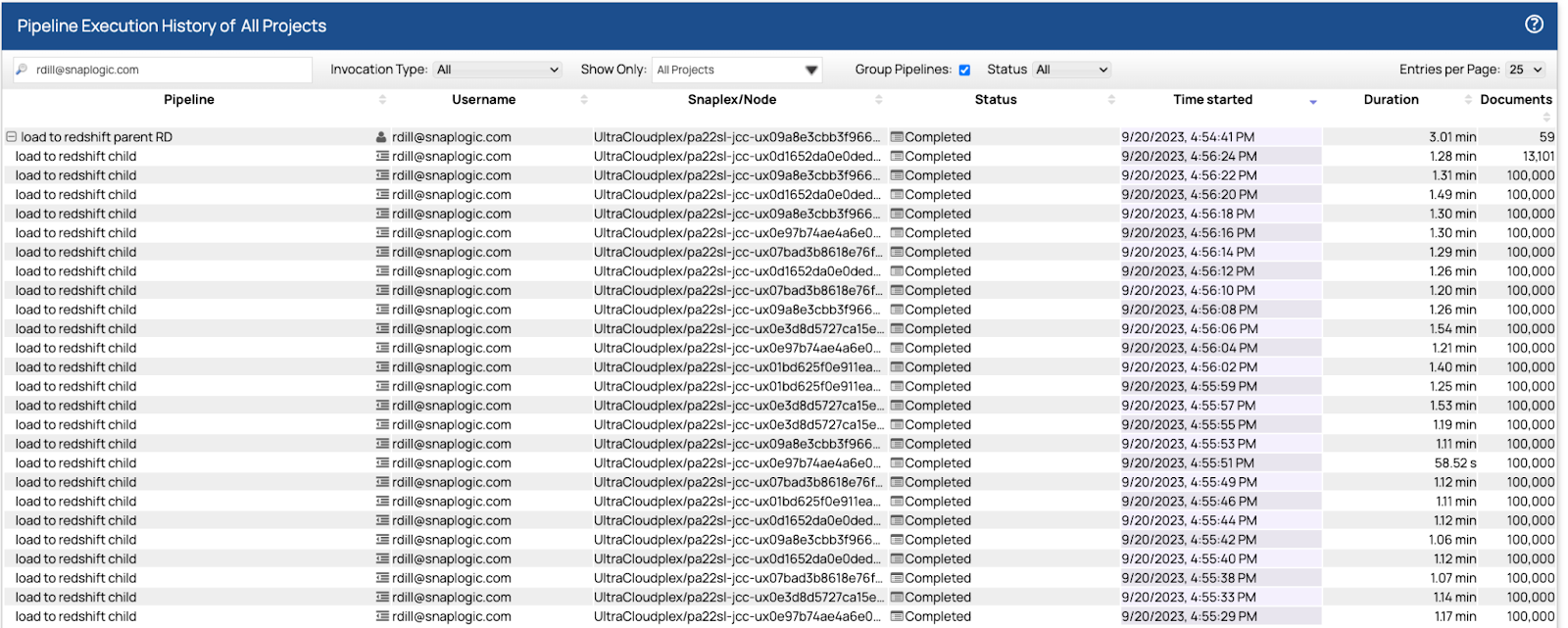
Jede der untergeordneten Pipelines las und schrieb 100.000 Zeilen in einem Zeitraum zwischen 1,07 Sekunden und 1,31 Sekunden. Die Steuerungsebene verteilte die Last der 32 untergeordneten Pipelines auf die sechs Knoten mithilfe eines Round-Robin-Algorithmus, der die am wenigsten genutzten Knoten bevorzugt. Die Knoten nahmen so viele Pipelines wie möglich an und führten sie aus. Wenn sie ihre Kapazitätsgrenze erreichten, wurden die neuen Pipelines bereitgestellt und erst gestartet, wenn der Knoten über die Kapazität verfügte, sie auszuführen. Von Anfang bis Ende dauerte es 3,01 Sekunden, um die übergeordnete Pipeline und die 59 untergeordneten Instanzen auszuführen.
Hier sind die Pipelines. Die übergeordnete Pipeline verwendet die Zählfunktion, um die Anzahl der Zeilen zu ermitteln. Anhand dieser Zahl bestimmen wir die Anzahl der untergeordneten Pipelines. In diesem Fall werden 5,9 Millionen Zeilen von 59 Pipelines gelesen, wobei jede Pipeline 100.000 Zeilen liest und schreibt.
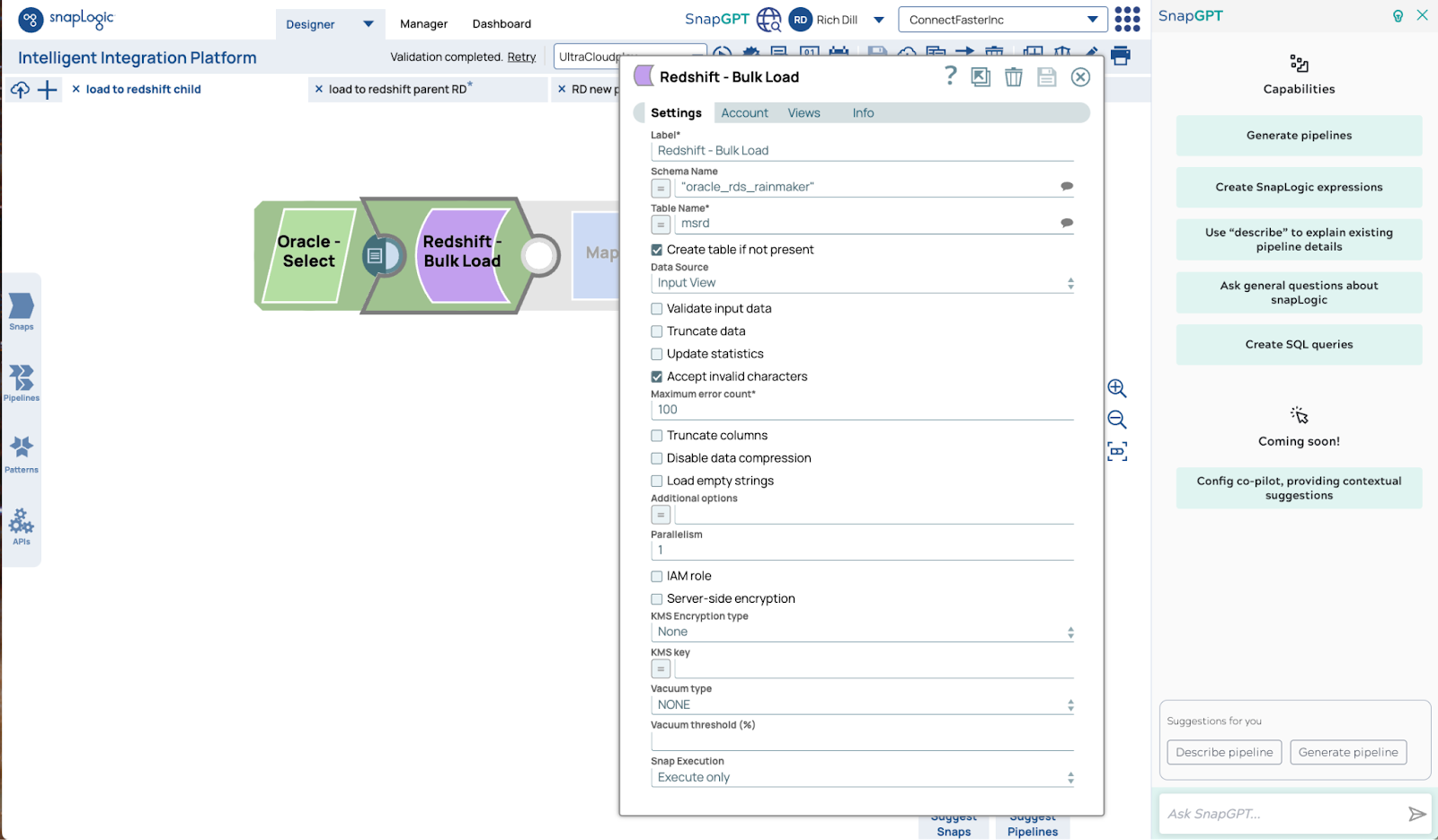
Hier ist die Konfiguration für Redshift Bulk Load Snap. Die Standardeinstellungen sind alles, was für eine skalierbare Ausführung erforderlich ist.
Wir haben ein gängiges Muster verwendet, um eine Kundenfrage innerhalb weniger Stunden zu beantworten. Wir haben eine vorhandene Pipeline von Matt genommen, eine Kopie davon erstellt, die alte Datenbankladung durch den Redshift Bulk Load Snap ersetzt und innerhalb weniger Minuten Tests durchgeführt.
Der Test wurde mit Gigabytes an Daten und sechs großen Knoten durchgeführt, um Terabytes zu modellieren. Eine Skalierung auf die nächste Stufe ist einfach durch eine Erhöhung der Anzahl und Größe der Knoten möglich. Die Obergrenze der Kapazität dieses Musters basiert auf drei Grenzen: den Lese- und Schreibgeschwindigkeiten der Quelle und des Ziels sowie der Netzwerkbandbreite. Wir haben Kunden, die täglich Terabytes und Petabytes mit solchen Mustern verschieben. Es ist eine schnelle und einfache Aufgabe, Daten in großem Umfang zu verschieben, ohne komplexe SQL-Anweisungen oder Code schreiben zu müssen. Wählen Sie die benötigten Lese- und Schreib-Snaps aus, geben Sie ihnen die richtigen Parameter und nehmen Sie die erforderlichen Anpassungen vor – und in wenigen Minuten ist Ihre Aufgabe erledigt.






