






Da Integrationsanforderungen zunehmend latenzempfindlich werden – insbesondere in Pipelines, die Snaps mit großen Sprachmodellen (LLM) nutzen –, ist die Minimierung von Ausführungsverzögerungen entscheidend geworden, um die Leistung in großem Maßstab aufrechtzuerhalten. Als Reaktion darauf hat SnapLogic eine verbesserte Version des PipelineLoop Snap veröffentlicht, die zwei wichtige Leistungsengpässe beseitigen soll: Start-Overhead und Latenz bei der Dokumentenausgabe.
Dieser Artikel bietet einen detaillierten Überblick über die Verbesserungen, erläutert deren Auswirkungen auf reale Tool-Aufruf-Pipelines und enthält praktische Anleitungen zur Konfiguration und Anwendung dieser Funktionen, um sofortige Leistungsverbesserungen zu erzielen.
Was ist neu in der erweiterten PipelineLoop?
1. Optimierte Dokumentenausgabezeit
Der PipelineLoop Snap wurde mit einem kürzeren und effizienteren Abfrageintervall verbessert, sodass er abgeschlossene untergeordnete Pipelines schneller erkennen und Ausgabedokumente mit geringerer Verzögerung übertragen kann. Der Mechanismus basiert zwar weiterhin auf Abfragen und ist nicht vollständig ereignisgesteuert, doch die reduzierte Wartezeit verringert die Ausgabelatenz erheblich – insbesondere bei Workloads mit vielen Iterationen.
2. Vorab erstellte Pipeline
Beim herkömmlichen PipelineLoop-Verhalten wird für jedes eingehende Dokument eine neue untergeordnete Pipeline initialisiert. Dies funktioniert zwar gut für einfache Aufgaben, ist jedoch ineffizient für Workloads, bei denen Tools aufgerufen werden und die Initialisierungszeit erheblich sein kann. Um dieses Problem zu beheben, bietet der erweiterte PipelineLoop die Möglichkeit, einen Pool von vorab erstellten untergeordneten Pipelines zu verwalten, die im Voraus initialisiert und über mehrere Iterationen hinweg wiederverwendet werden.
Die Anzahl der warmen Pipelines wird durch die Eigenschaft „Pre-spawned pipelines“ (Vorab erstellte Pipelines) gesteuert. Sobald eine untergeordnete Pipeline abgeschlossen ist, wird im Hintergrund automatisch eine neue initialisiert, um den Pool voll zu halten, es sei denn, die Gesamtzahl der Iterationen ist geringer als die konfigurierte Poolgröße. Nach Beendigung der Schleife werden alle inaktiven Pipelines ordnungsgemäß heruntergefahren.
Diese Funktion ist besonders nützlich in Szenarien, in denen untergeordnete Pipelines groß sind oder zeitaufwändige Einrichtungsschritte erfordern, wie z. B. das Öffnen mehrerer Kontoverbindungen oder das Laden komplexer Snaps. Durch Festlegen von „Pre-spawned pipelines“ auf einen Wert größer als eins kann PipelineLoop die Kaltstartverzögerung für die meisten Dokumente beseitigen und so den Durchsatz unter Bedingungen mit hohem Datenverkehr verbessern. Die folgenden Schritte beschreiben, wie Sie PipelineLoop mit vorab erstellten Pipelines konfigurieren können.
Durchlauf der vorab erstellten Pipeline
Diese Anleitung zeigt anhand einer einfachen Eltern-Kind-Pipeline-Konfiguration, wie die Funktion „Vorkonfigurierte Pipelines“ in der Praxis funktioniert.
1. Einrichtung der übergeordneten Pipeline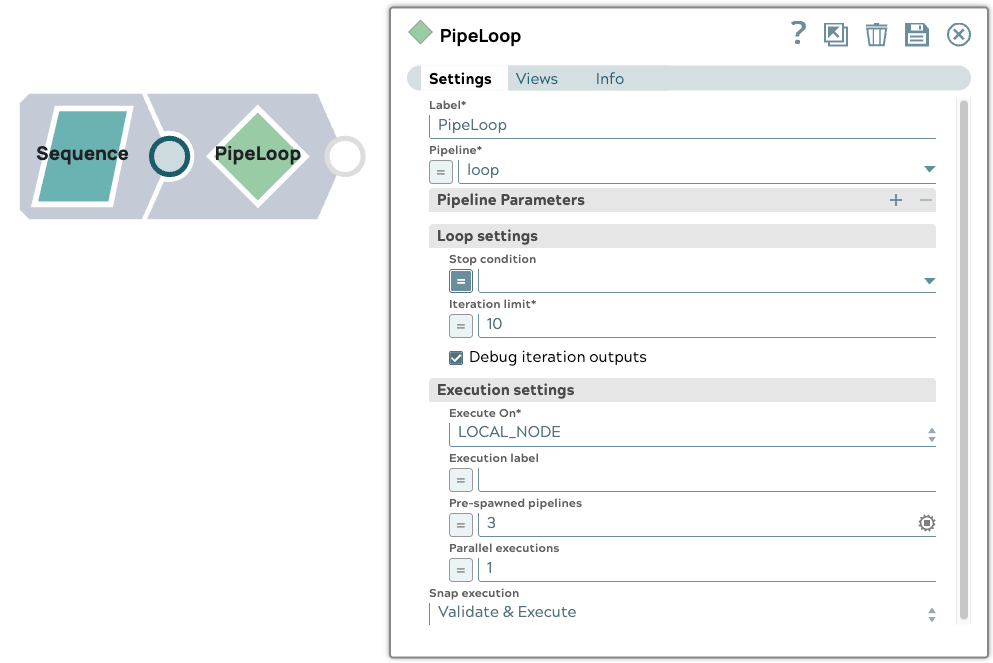
Die übergeordnete Pipeline enthält einen Sequence Snap, der so konfiguriert ist, dass er ein Eingabedokument ausgibt. Er verwendet einen PipelineLoop Snap mit den folgenden Einstellungen:
- Iterationsgrenze: 10
- Vorab erstellte Pipelines: 3
2. Einrichtung der Kinder-Pipeline
Die Child-Pipeline enthält einen Script Snap, der eine Verzögerung von 2 Sekunden einführt, bevor der eingehende Wert um 1 erhöht wird. Dies simuliert eine minimale Verarbeitungsaufgabe mit einer spürbaren Ausführungszeit, ideal, um die Auswirkungen des Pre-Spawning zu beobachten.
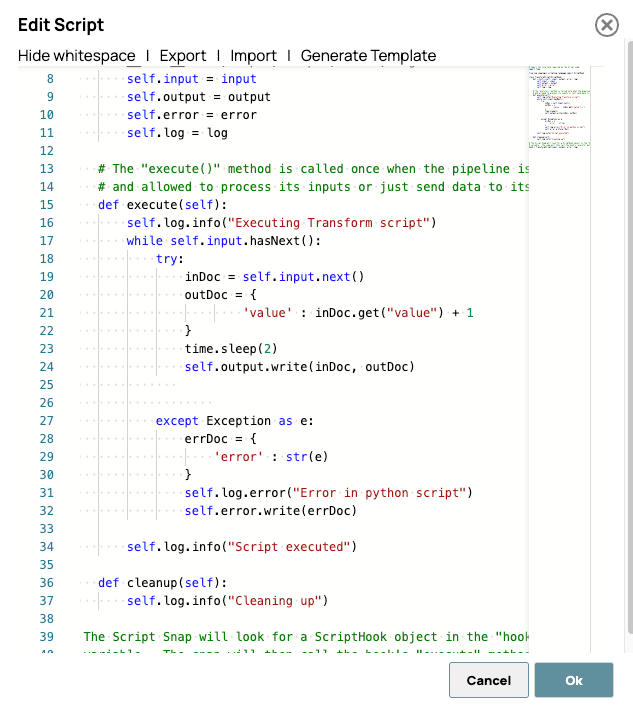
Hier ist das Skript. Dieses Skript verarbeitet jedes Eingabedokument, indem es nach einer simulierten Verzögerung von 2 Sekunden eine Eins zum Feld „Wert“ hinzufügt. Der Zweck der Verzögerung besteht nicht darin, eine tatsächliche Verarbeitungslatenz zu simulieren, sondern vielmehr darin, die vorab erstellte Pipeline-Aktivität im SnapLogic-Dashboard oder in den Laufzeitprotokollen deutlich sichtbar zu machen.
3. Pipeline-Ausführung
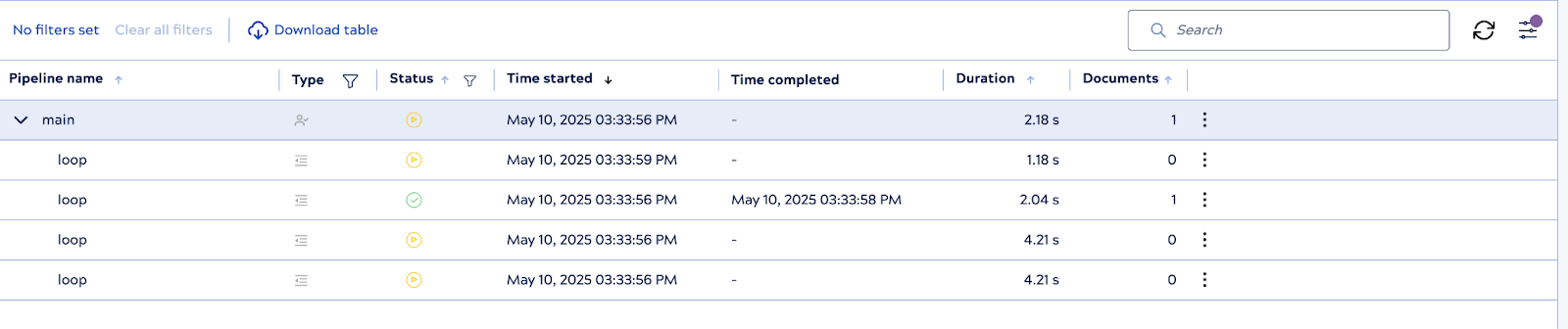
Wenn die übergeordnete Pipeline ausgeführt wird, initialisiert das System sofort drei untergeordnete Pipeline-Instanzen im Voraus – dies sind die vorab erzeugten Worker. Sobald jeder einzelne die Verarbeitung eines Dokuments abgeschlossen hat, verwendet PipelineLoop die Worker je nach Bedarf wieder oder füllt den Pool wieder auf, sodass die konfigurierte Obergrenze eingehalten wird.
4. Kontrollierte Ausführungsanzahl
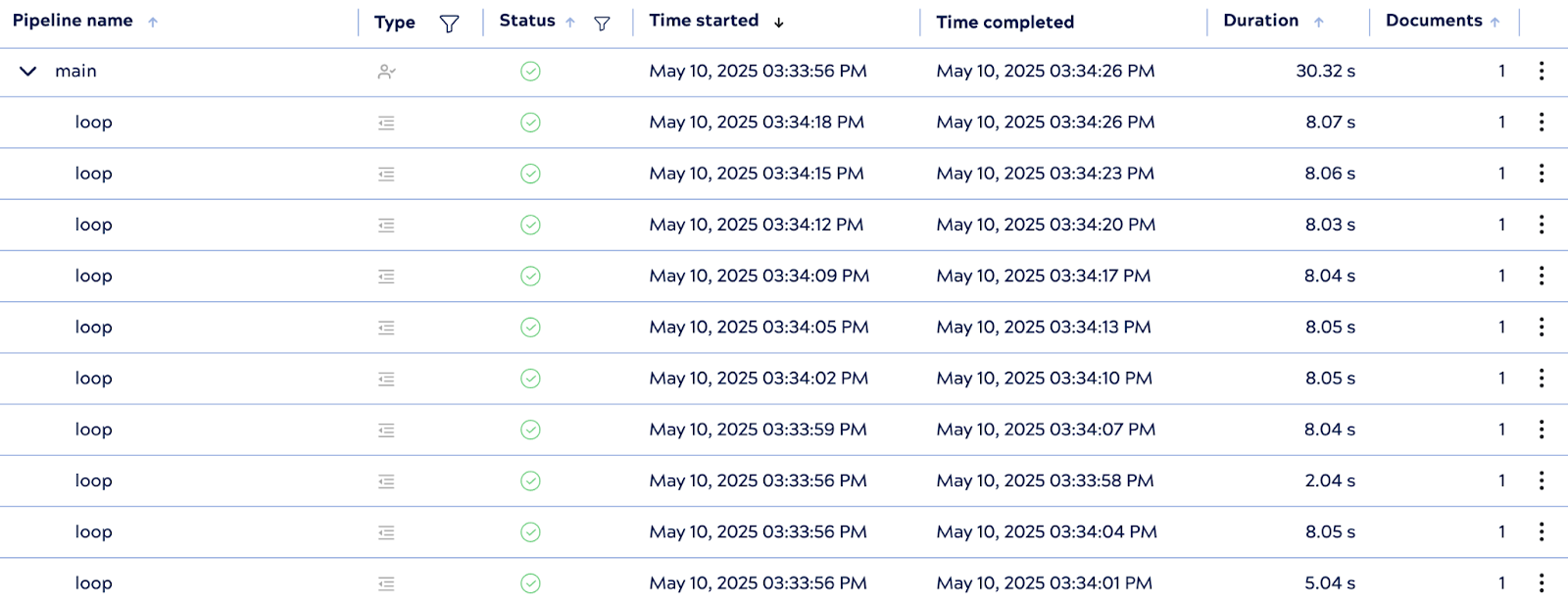
Obwohl vorab generierte Worker vorhanden sind, hält sich PipelineLoop an die Iterationsgrenze von 10 und stellt sicher, dass insgesamt nicht mehr als 10 untergeordnete Ausführungen stattfinden. Sobald alle 10 Iterationen abgeschlossen sind, beendet die Schleife alle inaktiven untergeordneten Pipelines ordnungsgemäß.
Diese Konfiguration verdeutlicht den Vorteil vorinitialisierter Pipelines bei der Reduzierung der Ausführungslatenz, insbesondere in Szenarien, in denen die Startzeit der untergeordneten Pipeline erheblich zur Gesamtleistung beiträgt.
3. Unterstützung paralleler Ausführung
Die verbesserte PipelineLoop-Snap-Funktion ermöglicht die parallele Ausführung, sodass mehrere Eingabedokumente gleichzeitig in separaten untergeordneten Pipeline-Instanzen verarbeitet werden können. Diese Funktion ist besonders vorteilhaft bei Workloads mit hohem Durchsatz, bei denen die Verarbeitung einzelner Dokumente unnötige Engpässe verursachen würde.
Durch Konfigurieren der Eigenschaft „Parallele Ausführungen“ können Benutzer festlegen, wie viele Eingabedokumente gleichzeitig verarbeitet werden sollen. Wenn Sie beispielsweise den Wert auf 3 setzen, kann die Schleife bis zu drei Schleifenausführungen gleichzeitig initiieren und verwalten, wodurch sich der Gesamtdurchsatz der Pipeline erheblich verbessert.
Wichtig ist, dass diese Parallelität ohne Beeinträchtigung der Ergebniskonsistenz implementiert wird. Die PipelineLoop behält die Ausgabereihenfolge bei und stellt sicher, dass die Ergebnisse in genau derselben Reihenfolge geliefert werden, in der die Eingabedokumente empfangen wurden – unabhängig davon, in welcher Reihenfolge die untergeordneten Pipelines ihre Aufgaben ausführen. Dadurch ist die Funktion auch in nachgelagerten Abläufen, die auf geordnete Daten angewiesen sind, sicher in der Anwendung.
Die parallele Ausführung wurde entwickelt, um die Ressourcennutzung zu maximieren und Verarbeitungsverzögerungen zu minimieren. Sie bietet eine skalierbare Lösung für datenintensive und latenzempfindliche Integrationsszenarien.
Parallelausführung – Schritt-für-Schritt-Anleitung „
“ Diese Schritt-für-Schritt-Anleitung veranschaulicht, wie die Parallelausführungsfunktion im erweiterten PipelineLoop Snap die Leistung verbessert und gleichzeitig die Eingabereihenfolge beibehält. Zur Veranschaulichung des Verhaltens wird eine grundlegende Eltern-Kind-Pipeline-Konfiguration verwendet.
1. Konfiguration der übergeordneten Pipeline
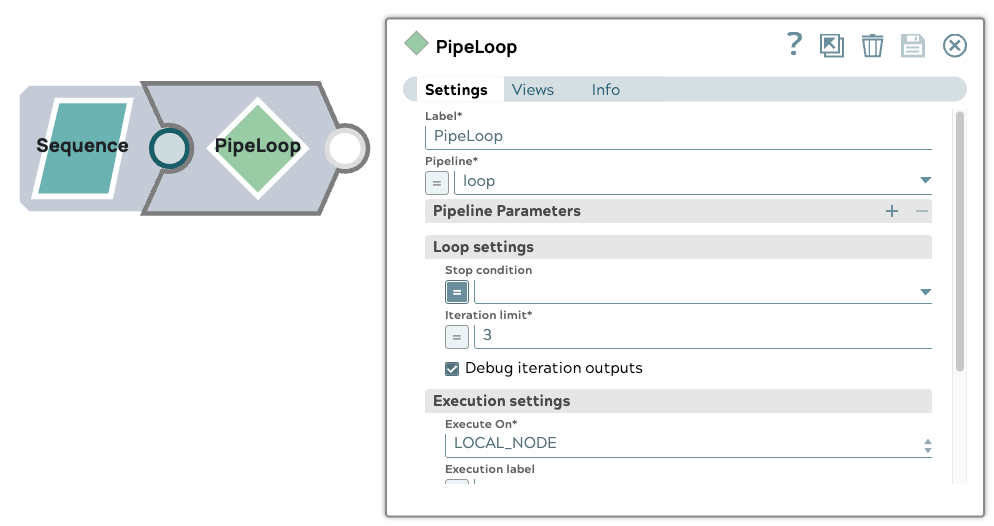
Die übergeordnete Pipeline beginnt mit einem Sequence Snap, der drei Eingabedokumente generiert. Ein PipelineLoop Snap ist mit den folgenden Parametern konfiguriert:
- Iterationsgrenze: 3
- Parallele Ausführungen: 3
Mit dieser Konfiguration kann PipelineLoop alle drei Eingabedokumente gleichzeitig verarbeiten.
2. Konfiguration der Child-Pipeline
Die Child-Pipeline besteht aus einem Script Snap, der eine Verzögerung von 2 Sekunden einführt, bevor das Zeichen „A“ an das Feld „value“ jedes Dokuments angehängt wird.
Nachfolgend finden Sie das im Script Snap verwendete Skript:
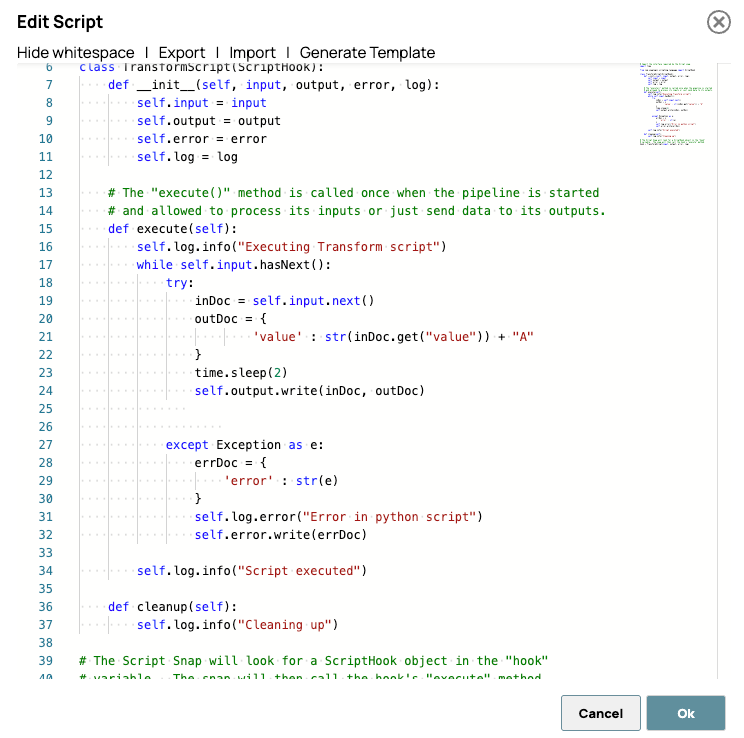
Die Verzögerung wird absichtlich hinzugefügt, um den Effekt der parallelen Verarbeitung zu visualisieren, wodurch die Leistungssteigerungen während der Überwachung oder beim Testen deutlicher sichtbar werden.
3. Ausführungsverhalten
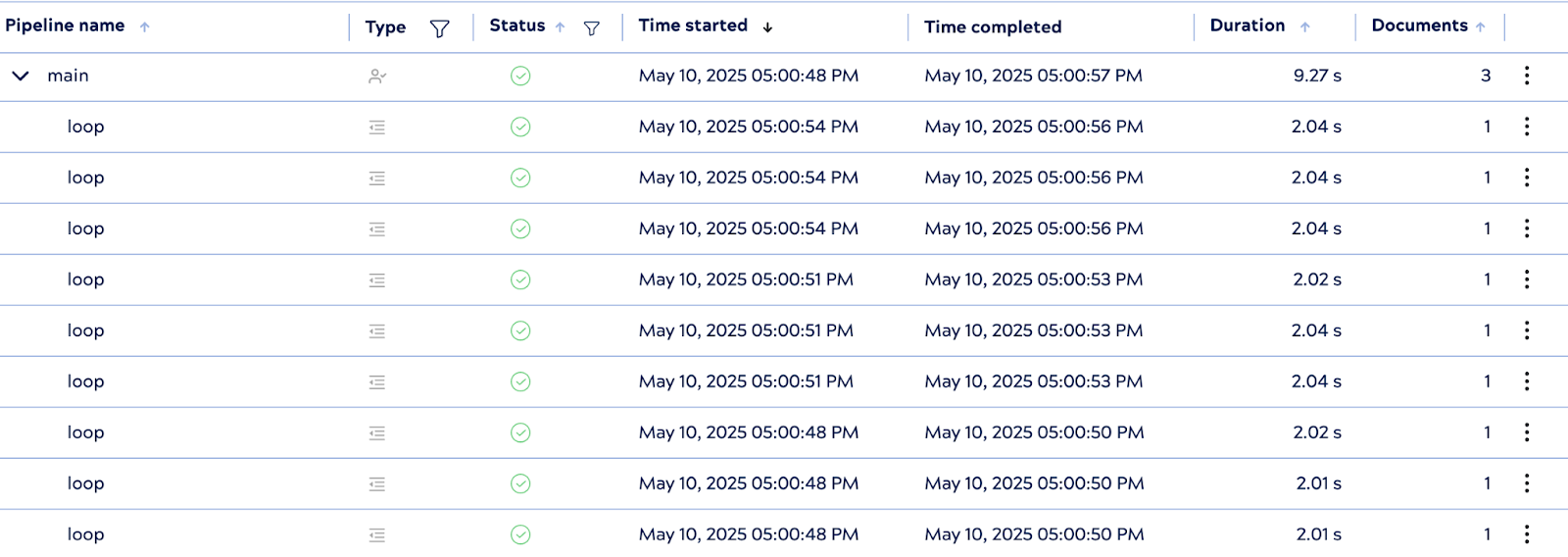
Bei der Ausführung initiiert die PipelineLoop drei untergeordnete Pipeline-Instanzen parallel – eine für jedes Eingabedokument. Obwohl jede untergeordnete Pipeline eine Verarbeitungsverzögerung von 2 Sekunden aufweist, wurde die gesamte Ausführung in etwa 9 Sekunden abgeschlossen, was immer noch deutlich schneller ist als die optimale serielle Ausführungszeit von 18 Sekunden.
Während die theoretische Laufzeit unter idealen parallelen Bedingungen etwa 6 Sekunden betragen würde, können reale Faktoren wie die Initialisierungszeit von Snap und die API-Latenz zu geringfügigen Overhead-Kosten führen. Dennoch zeigt das Ergebnis eine effektive Parallelität und unterstreicht die Leistungsvorteile der parallelen Ausführung in praktischen Integrationsszenarien.
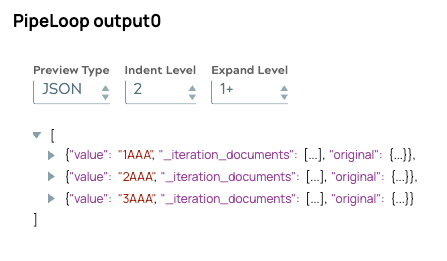
Am wichtigsten ist, dass selbst bei gleichzeitiger Verarbeitung die Ausgabereihenfolge mit der ursprünglichen Eingabereihenfolge übereinstimmt. Dies bestätigt, dass der interne Warteschlangenmechanismus von PipelineLoop die Ergebnisse korrekt ausrichtet und so eine zuverlässige nachgelagerte Verarbeitung gewährleistet.






