






Alors que les exigences en matière d'intégration deviennent de plus en plus sensibles à la latence, en particulier dans les pipelines utilisant des Snaps de modèles linguistiques à grande échelle (LLM), il est devenu essentiel de réduire au minimum les délais d'exécution pour maintenir les performances à grande échelle. En réponse à cela, SnapLogic a lancé une version améliorée du Snap PipelineLoop, conçue pour résoudre deux goulots d'étranglement clés en matière de performances : les frais généraux de démarrage et la latence de sortie des documents.
Cet article fournit un aperçu détaillé des améliorations, explique leur impact sur les pipelines d'appel d'outils dans le monde réel et offre des conseils pratiques sur la manière de configurer et d'appliquer ces fonctionnalités afin d'obtenir des améliorations immédiates en termes de performances.
Quelles sont les nouveautés dans la version améliorée de PipelineLoop ?
1. Optimisation du temps de sortie des documents
Le PipelineLoop Snap a été amélioré grâce à un intervalle d'interrogation plus court et plus efficace, ce qui lui permet de détecter plus rapidement les pipelines enfants terminés et de transmettre les documents de sortie avec moins de retard. Bien que le mécanisme reste basé sur l'interrogation plutôt que entièrement piloté par les événements, la réduction du temps d'attente diminue considérablement la latence de sortie, en particulier dans les charges de travail comportant de nombreuses itérations.
2. Pipeline pré-généré
Dans le comportement traditionnel de PipelineLoop, un nouveau pipeline enfant est initialisé pour chaque document entrant. Si cela fonctionne bien pour les tâches légères, cela devient inefficace pour les charges de travail impliquant l'appel d'outils, où le temps d'initialisation peut être important. Pour remédier à cela, la version améliorée de PipelineLoop offre la possibilité de maintenir un pool de pipelines enfants pré-générés qui sont initialisés à l'avance et réutilisés au fil des itérations.
Le nombre de pipelines chauds est contrôlé par la propriété Pre-spawned pipelines. À mesure que chaque pipeline enfant s'achève, un nouveau pipeline est automatiquement initialisé en arrière-plan afin de maintenir le pool plein, sauf si le nombre total d'itérations est inférieur à la taille configurée du pool. À la fin de la boucle, tous les pipelines inactifs sont arrêtés de manière ordonnée.
Cette fonctionnalité est particulièrement utile dans les cas où les pipelines enfants sont volumineux ou impliquent des étapes de configuration fastidieuses, telles que l'ouverture de plusieurs connexions de compte ou le chargement de Snaps complexes. En définissant les pipelines pré-générés sur une valeur supérieure à un, PipelineLoop peut éliminer le délai de démarrage à froid pour la plupart des documents, améliorant ainsi le débit dans des conditions de trafic élevé. Les étapes suivantes expliquent comment configurer pipeloop avec un pipeline pré-généré.
Présentation du pipeline pré-généré
Ce guide pratique montre comment fonctionne la fonctionnalité Pipelines pré-générés dans la pratique, à l'aide d'une configuration simple de pipeline parent-enfant.
1. Configuration du pipeline parent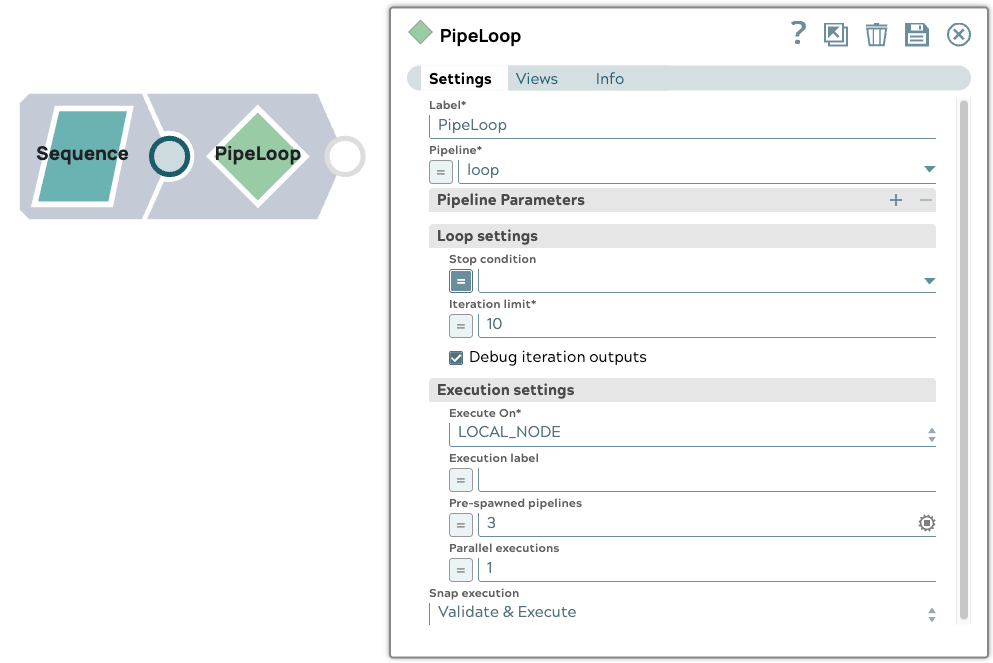
Le pipeline parent comprend un Snap Sequence configuré pour émettre un document d'entrée. Il utilise un Snap PipelineLoop avec les paramètres suivants :
- Limite d'itération : 10
- Pipelines pré-générés : 3
2. Configuration du pipeline enfant
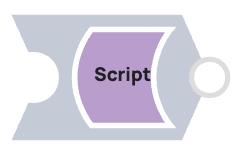
Le pipeline enfant contient un Script Snap qui introduit un délai de 2 secondes avant d'incrémenter la valeur entrante de 1. Cela simule une tâche de traitement minimale avec un temps d'exécution notable, idéal pour observer l'impact du pré-spawning.
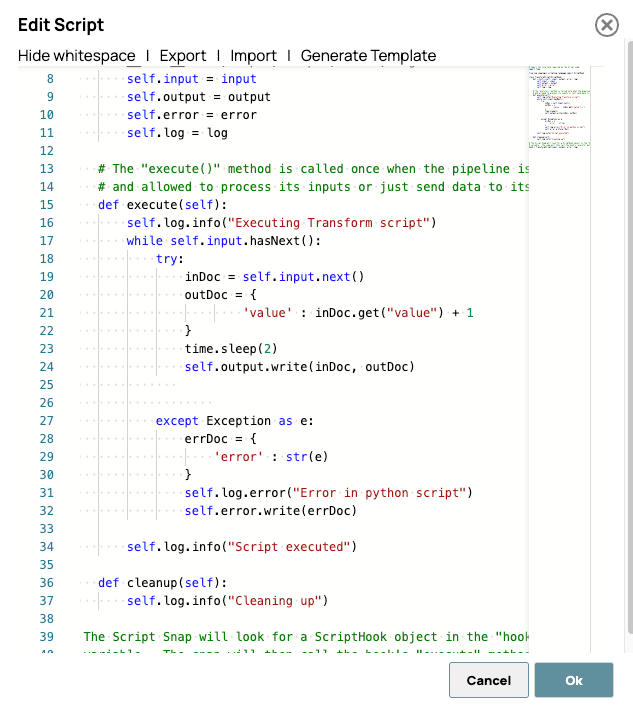
Voici le script. Ce script traite chaque document d'entrée en ajoutant un élément au champ « valeur » après un délai simulé de 2 secondes. Le but de ce délai n'est pas de simuler une latence de traitement réelle, mais plutôt de rendre l'activité du pipeline pré-généré clairement observable dans le tableau de bord SnapLogic ou les journaux d'exécution.
3. Exécution du pipeline
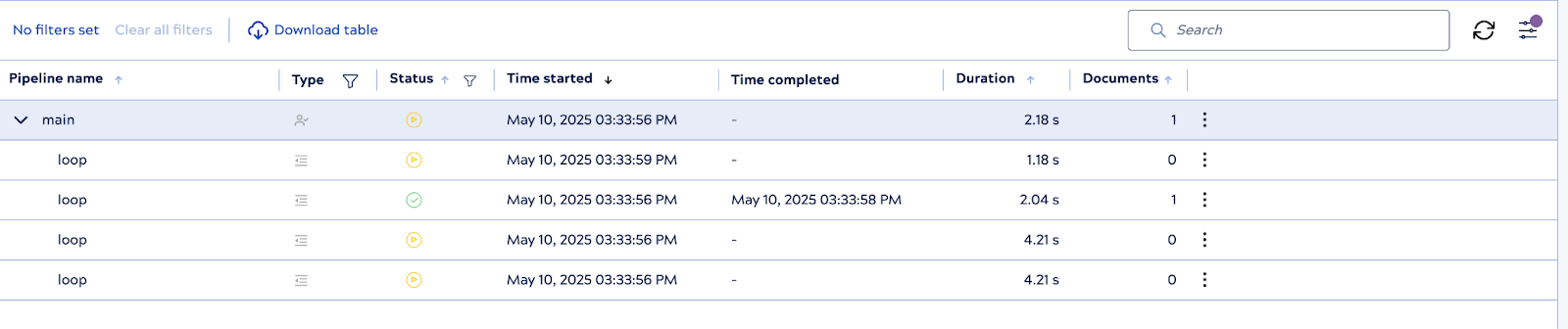
Lorsque le pipeline parent est exécuté, le système initialise immédiatement trois instances de pipeline enfant à l'avance : il s'agit des workers pré-générés. À mesure que chacun d'entre eux termine le traitement d'un document, PipelineLoop réutilise ou réapprovisionne les workers selon les besoins, en maintenant le pool jusqu'à la limite configurée.
4. Nombre d'exécutions contrôlées
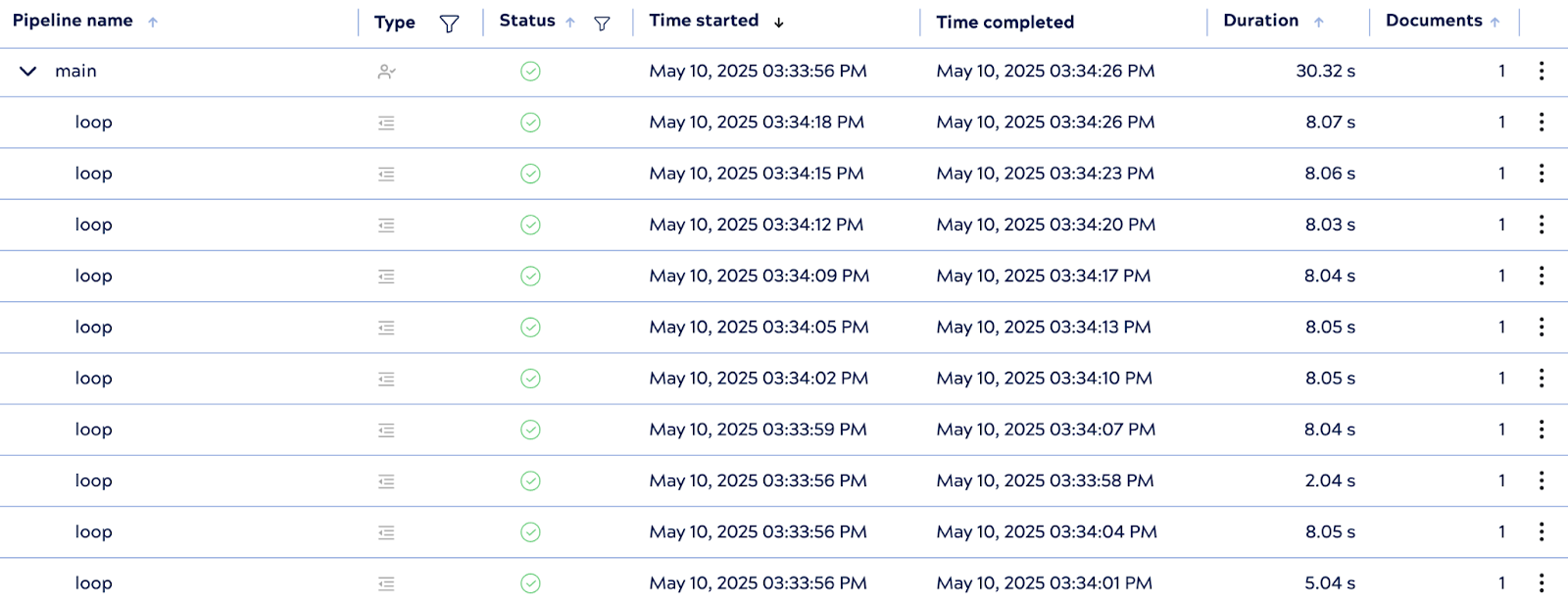
Malgré la présence de travailleurs pré-générés, PipelineLoop respecte la limite d'itération de 10, garantissant ainsi qu'il n'y ait pas plus de 10 exécutions enfants au total. Une fois les 10 itérations terminées, la boucle arrête progressivement tous les pipelines enfants inactifs.
Cette configuration met en évidence l'avantage des pipelines pré-initialisés pour réduire la latence d'exécution, en particulier dans les scénarios où le temps de démarrage des pipelines enfants contribue de manière significative aux performances globales.
3. Prise en charge de l'exécution parallèle
La fonctionnalité PipelineLoop Snap améliorée introduit l'exécution parallèle, permettant ainsi le traitement simultané de plusieurs documents d'entrée dans différentes instances de pipeline enfants. Cette fonctionnalité est particulièrement utile pour les charges de travail à haut débit, où le traitement des documents un par un créerait des goulots d'étranglement inutiles.
En configurant la propriété Exécutions parallèles, les utilisateurs peuvent définir le nombre de documents d'entrée à traiter simultanément. Par exemple, en définissant la valeur sur 3, la boucle peut lancer et gérer jusqu'à trois exécutions simultanées, ce qui améliore considérablement le débit global du pipeline.
Il est important de noter que ce parallélisme est mis en œuvre sans compromettre la cohérence des résultats. PipelineLoop maintient l'alignement de l'ordre de sortie, garantissant que les résultats sont fournis dans l'ordre exact dans lequel les documents d'entrée ont été reçus, quel que soit l'ordre dans lequel les pipelines enfants accomplissent leurs tâches. Cela rend cette fonctionnalité sûre à utiliser, même dans les flux en aval qui reposent sur des données ordonnées.
L'exécution parallèle est conçue pour optimiser l'utilisation des ressources et réduire les délais de traitement, offrant ainsi une solution évolutive pour les scénarios d'intégration gourmands en données et sensibles à la latence.
Présentation de l'exécution parallèle
Cetteprésentation illustre comment la fonctionnalité d'exécutionparallèle du PipelineLoop Snap amélioré améliore les performances tout en conservant l'ordre des entrées. Une configuration de pipeline parent-enfant de base est utilisée pour démontrer le comportement.
1. Configuration du pipeline parent
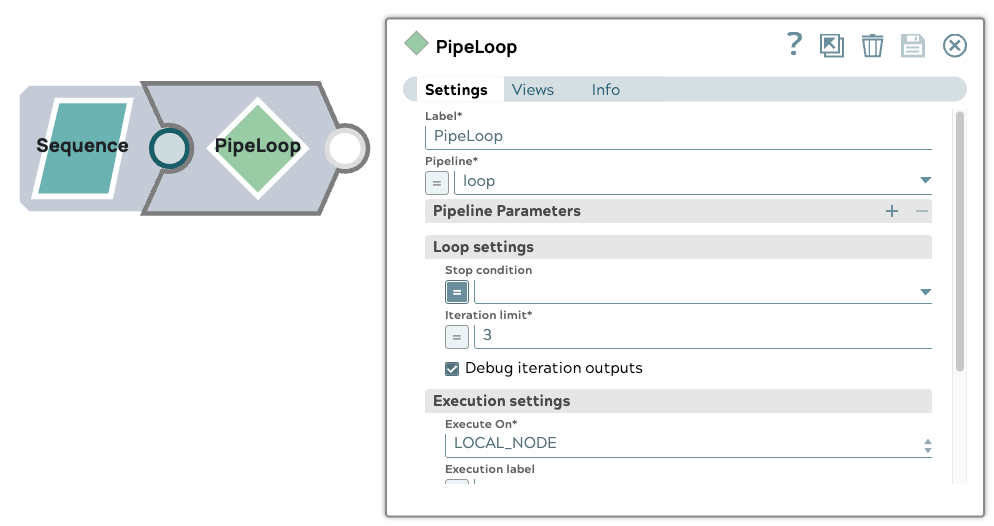
Le pipeline parent commence par un Snap Sequence qui génère trois documents d'entrée. Un Snap PipelineLoop est configuré avec les paramètres suivants :
- Limite d'itération : 3
- Exécutions parallèles : 3
Cette configuration permet à PipelineLoop de traiter simultanément les trois documents d'entrée.
2. Configuration du pipeline enfant
Le pipeline enfant se compose d'un Script Snap qui introduit un délai de 2 secondes avant d'ajouter le caractère « A » au champ « value » de chaque document.
Voici le script utilisé dans le Script Snap :
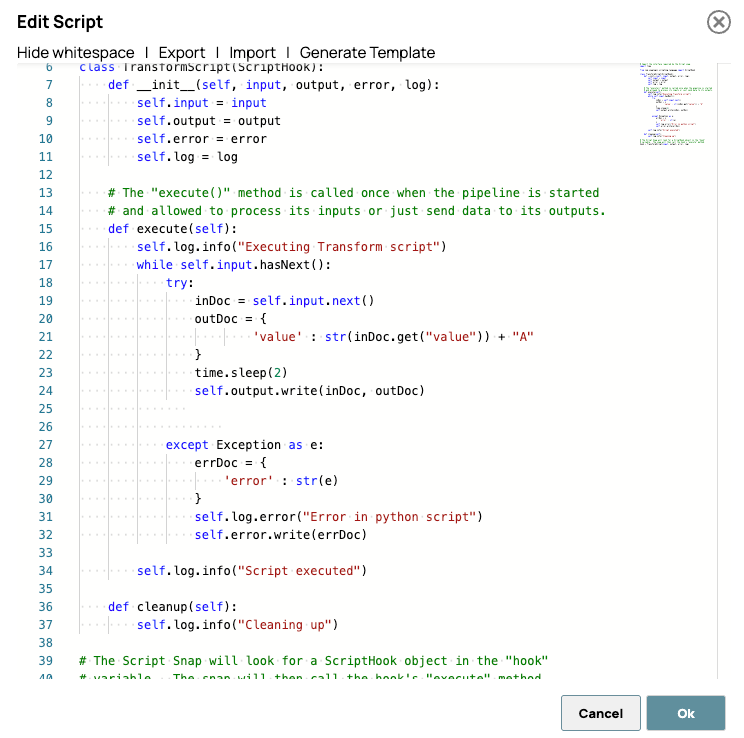
Le délai est ajouté intentionnellement afin de visualiser l'effet du traitement parallèle, rendant les gains de performance plus perceptibles pendant la surveillance ou les tests.
3. Comportement d'exécution
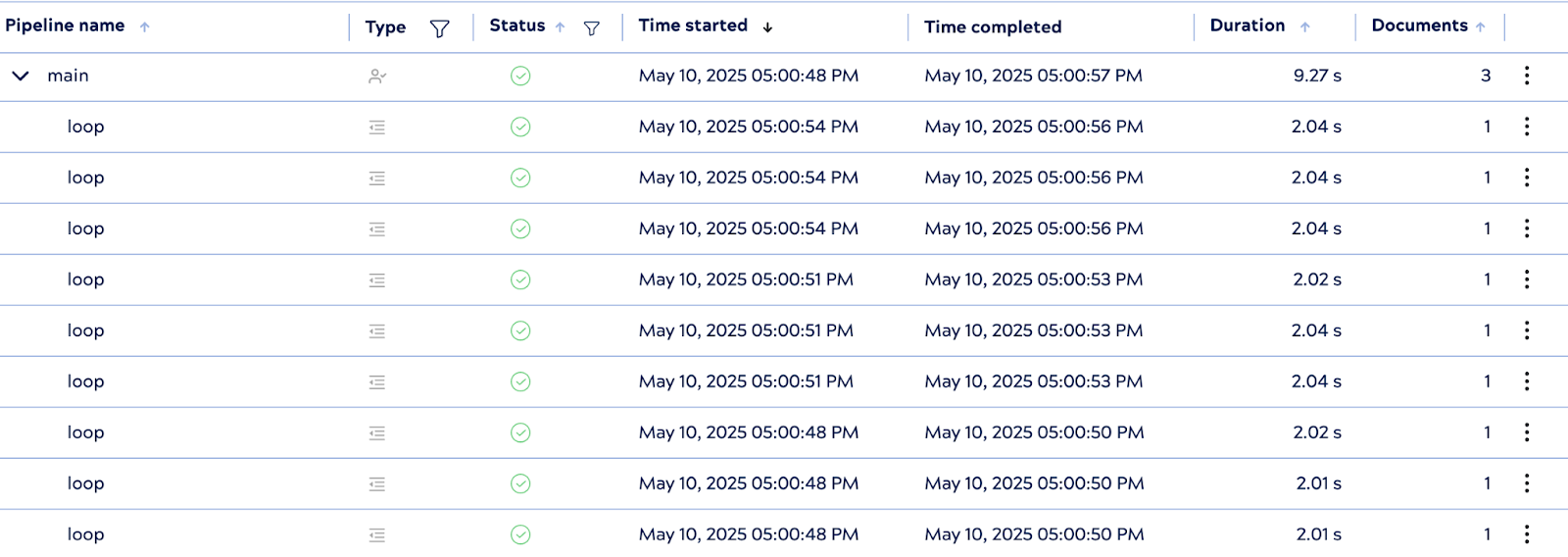
Lors de son exécution, PipelineLoop lance trois instances de pipeline enfants en parallèle, une pour chaque document d'entrée. Bien que chaque pipeline enfant comporte un délai de traitement de 2 secondes, l'exécution globale s'est achevée en environ 9 secondes, ce qui reste nettement plus rapide que le temps d'exécution série optimal de 18 secondes.
Alors que le temps d'exécution théorique dans des conditions parallèles idéales serait d'environ 6 secondes, des facteurs réels tels que le temps d'initialisation de Snap et la latence de l'API peuvent entraîner une légère surcharge. Malgré cela, le résultat démontre une concurrence efficace et met en évidence les avantages en termes de performances de l'exécution parallèle dans des scénarios d'intégration pratiques.
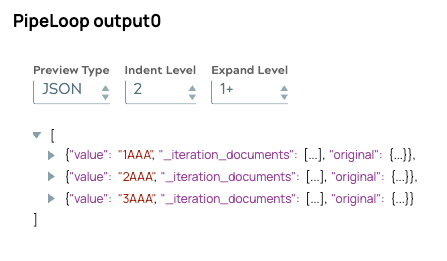
Plus important encore, même avec un traitement simultané, l'ordre de sortie reste cohérent avec la séquence d'entrée d'origine. Cela confirme que le mécanisme de mise en file d'attente interne de PipelineLoop aligne correctement les résultats, garantissant ainsi un traitement en aval fiable.






