






Poiché le esigenze di integrazione diventano sempre più sensibili alla latenza, in particolare nelle pipeline che sfruttano gli Snap dei modelli linguistici di grandi dimensioni (LLM), ridurre al minimo i ritardi di esecuzione è diventato fondamentale per mantenere le prestazioni su larga scala. In risposta a ciò, SnapLogic ha rilasciato una versione migliorata dello Snap PipelineLoop, progettata per affrontare due principali colli di bottiglia delle prestazioni: il sovraccarico di avvio e la latenza di output dei documenti.
Questo articolo fornisce una panoramica dettagliata dei miglioramenti, spiega il loro impatto sulle pipeline di chiamata degli strumenti nel mondo reale e offre una guida pratica su come configurare e applicare queste funzionalità per ottenere miglioramenti immediati delle prestazioni.
Cosa c'è di nuovo nel PipelineLoop potenziato?
1. Tempo di output dei documenti ottimizzato
PipelineLoop Snap è stato migliorato con un intervallo di polling più breve ed efficiente, che consente di rilevare più rapidamente le pipeline figlie completate e di inviare i documenti di output con un ritardo minore. Sebbene il meccanismo rimanga basato sul polling anziché essere completamente guidato dagli eventi, la riduzione dei tempi di attesa riduce significativamente la latenza di output, in particolare nei carichi di lavoro con molte iterazioni.
2. Pipeline pre-generata
Nel comportamento tradizionale di PipelineLoop, viene inizializzata una nuova pipeline figlia per ogni documento in entrata. Sebbene ciò funzioni bene per attività leggere, diventa inefficiente per i carichi di lavoro che richiedono l'utilizzo di strumenti, dove il tempo di inizializzazione può essere significativo. Per ovviare a questo problema, la versione migliorata di PipelineLoop introduce la possibilità di mantenere un pool di pipeline figlie pre-generate che vengono inizializzate in anticipo e riutilizzate durante le iterazioni.
Il numero di pipeline attive è controllato dalla proprietà Pre-spawned pipelines. Man mano che ogni pipeline figlia viene completata, ne viene inizializzata automaticamente una nuova in background per mantenere pieno il pool, a meno che il numero totale di iterazioni non sia inferiore alla dimensione del pool configurata. Al termine del ciclo, tutte le pipeline inattive vengono chiuse in modo corretto.
Questa funzione è particolarmente utile in scenari in cui le pipeline secondarie sono di grandi dimensioni o richiedono passaggi di configurazione che richiedono molto tempo, come l'apertura di più connessioni di account o il caricamento di Snap complessi. Impostando le pipeline pre-generate su un valore superiore a uno, PipelineLoop può eliminare il ritardo di avvio a freddo per la maggior parte dei documenti, migliorando la produttività in condizioni di traffico elevato. I passaggi seguenti forniscono un modo per configurare il pipeloop con una pipeline pre-generata.
Guida alla pipeline pre-generata
Questa procedura guidata mostra come funziona nella pratica la funzione Pre-spawned Pipelines, utilizzando una semplice configurazione di pipeline padre-figlio.
1. Configurazione della pipeline principale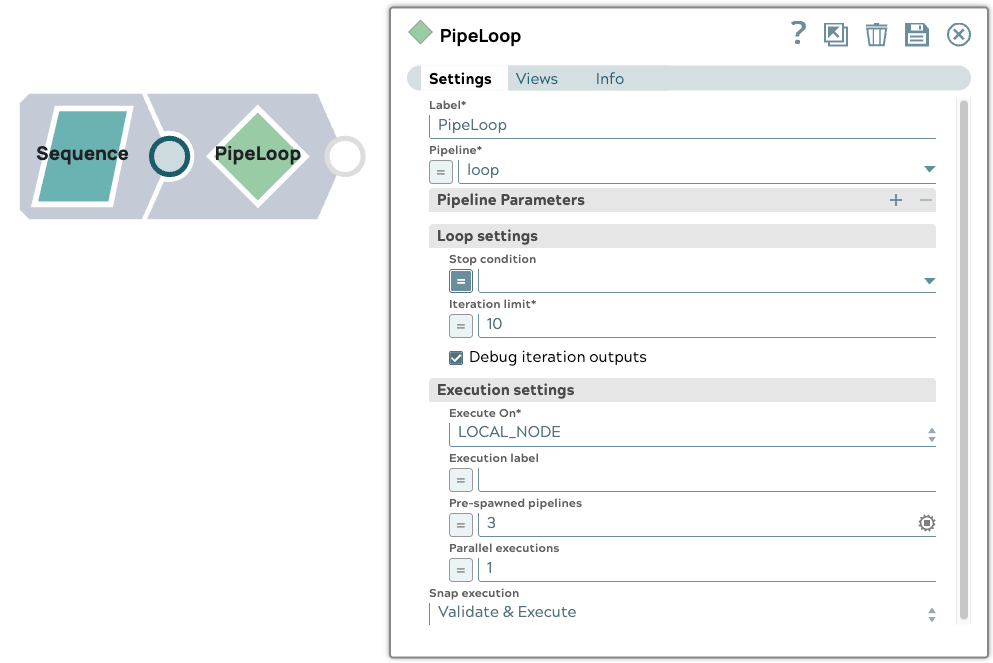
La pipeline principale include uno Snap Sequence configurato per emettere un documento di input. Utilizza uno Snap PipelineLoop con le seguenti impostazioni:
- Limite di iterazioni: 10
- Pipeline pre-generate: 3
2. Configurazione della pipeline secondaria
La pipeline secondaria contiene uno Script Snap che introduce un ritardo di 2 secondi prima di incrementare il valore in entrata di 1. Questo simula un'attività di elaborazione minima con un tempo di esecuzione evidente, ideale per osservare l'impatto del pre-spawning.
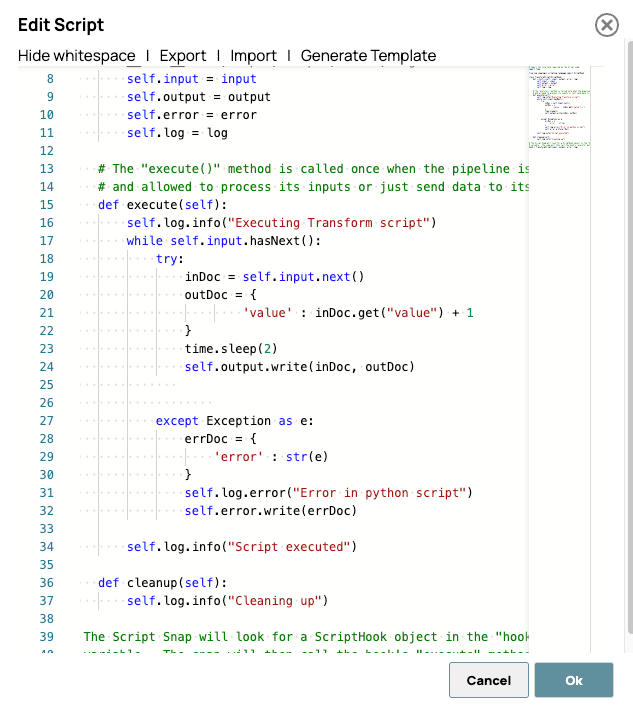
Ecco lo script. Questo script elabora ogni documento in ingresso aggiungendo uno al campo "valore" dopo un ritardo simulato di 2 secondi. Lo scopo del ritardo non è quello di simulare la latenza di elaborazione reale, ma piuttosto di rendere chiaramente osservabile l'attività della pipeline pre-generata nella dashboard SnapLogic o nei log di runtime.
3. Esecuzione della pipeline
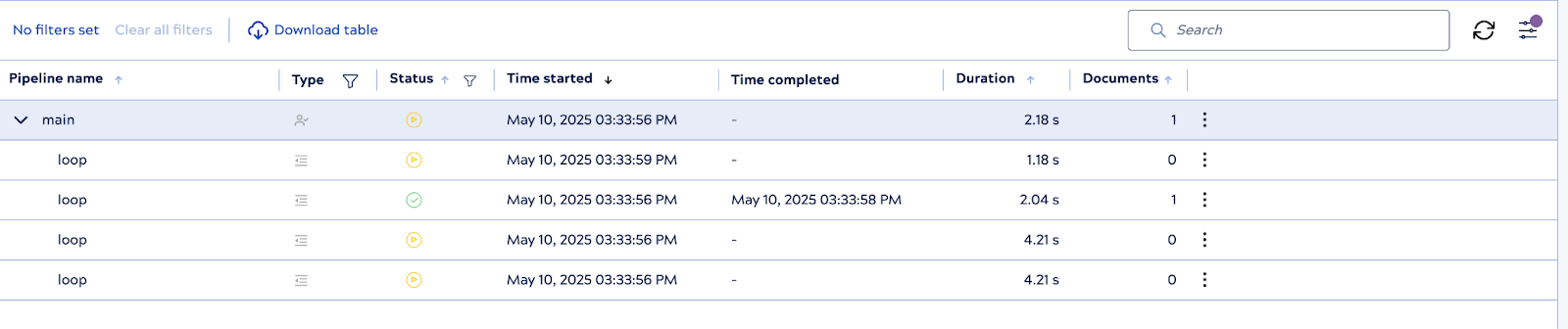
Quando viene eseguita la pipeline principale, il sistema inizializza immediatamente tre istanze di pipeline secondarie in anticipo: si tratta dei worker pre-generati. Man mano che ciascuno di essi termina l'elaborazione di un documento, PipelineLoop riutilizza o reintegra i worker secondo necessità, mantenendo il pool fino al limite configurato.
4. Conteggio delle esecuzioni controllate
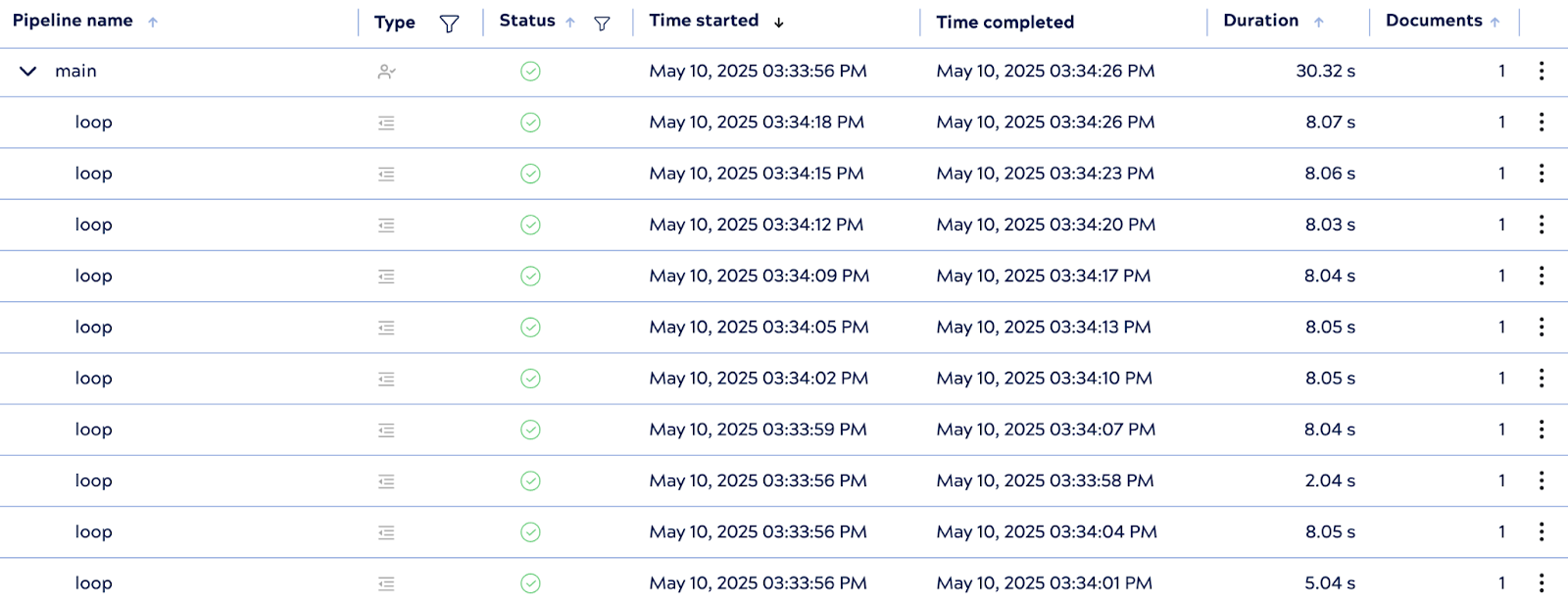
Nonostante disponga di worker pre-generati, PipelineLoop rispetta il limite di iterazioni pari a 10, garantendo che non si verifichino più di 10 esecuzioni figlie in totale. Una volta completate tutte e 10 le iterazioni, il ciclo chiude in modo corretto tutte le pipeline figlie inattive.
Questa configurazione evidenzia il vantaggio delle pipeline pre-inizializzate nella riduzione della latenza di esecuzione, in particolare per gli scenari in cui il tempo di avvio delle pipeline secondarie contribuisce in modo significativo alle prestazioni complessive.
3. Supporto dell'esecuzione parallela
Il PipelineLoop Snap potenziato introduce l'esecuzione parallela, consentendo l'elaborazione simultanea di più documenti di input su istanze pipeline figlie separate. Questa funzionalità è particolarmente utile quando si gestiscono carichi di lavoro ad alta produttività, dove l'elaborazione dei documenti uno alla volta creerebbe inutili colli di bottiglia.
Configurando la proprietà Esecuzioni parallele, gli utenti possono definire quanti documenti di input devono essere gestiti contemporaneamente. Ad esempio, impostando il valore su 3, il ciclo può avviare e gestire fino a tre esecuzioni contemporaneamente, migliorando significativamente la produttività complessiva della pipeline.
È importante sottolineare che questo parallelismo viene implementato senza compromettere la coerenza dei risultati. PipelineLoop mantiene l'allineamento dell'ordine di output, garantendo che i risultati vengano forniti nell'esatta sequenza in cui sono stati ricevuti i documenti di input, indipendentemente dall'ordine in cui le pipeline secondarie completano le loro attività. Ciò rende la funzione sicura da utilizzare anche nei flussi a valle che si basano su dati ordinati.
L'esecuzione parallela è progettata per massimizzare l'utilizzo delle risorse e ridurre al minimo i ritardi di elaborazione, fornendo una soluzione scalabile per scenari di integrazione ad alta intensità di dati e sensibili alla latenza.
Procedura dettagliata sull'esecuzione parallela
Questaprocedura dettagliata illustra come la funzionalità di esecuzione parallela nel PipelineLoop Snap migliorato ottimizzi le prestazioni preservando l'ordine di input. Per dimostrare il comportamento viene utilizzata una configurazione di pipeline padre-figlio di base.
1. Configurazione della pipeline principale
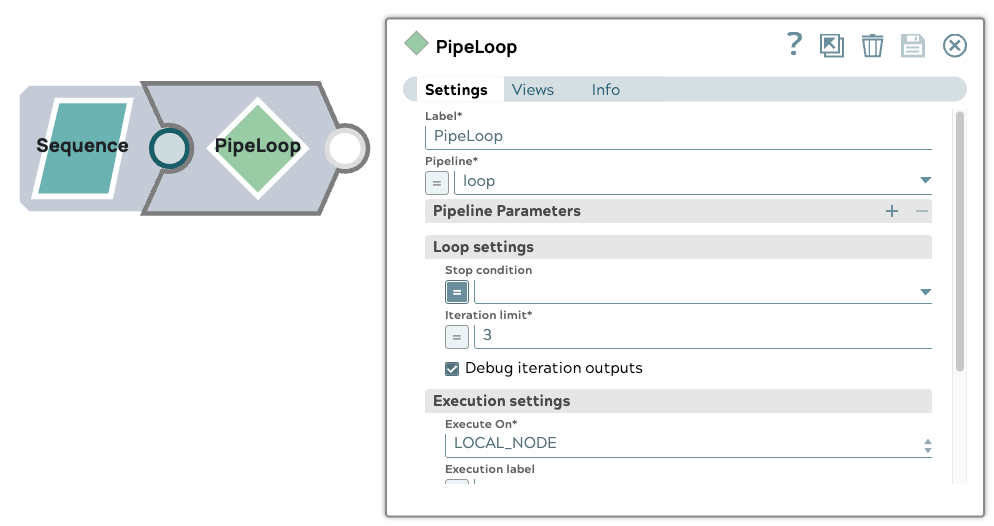
La pipeline principale inizia con uno Snap Sequence che genera tre documenti di input. Uno Snap PipelineLoop è configurato con i seguenti parametri:
- Limite di iterazioni: 3
- Esecuzioni parallele: 3
Questa configurazione consente a PipelineLoop di elaborare contemporaneamente tutti e tre i documenti di input.
2. Configurazione della pipeline secondaria
Il child pipeline è costituito da uno Script Snap che introduce un ritardo di 2 secondi prima di aggiungere il carattere "A" al campo "value" di ciascun documento.
Di seguito è riportato lo script utilizzato nello Script Snap:
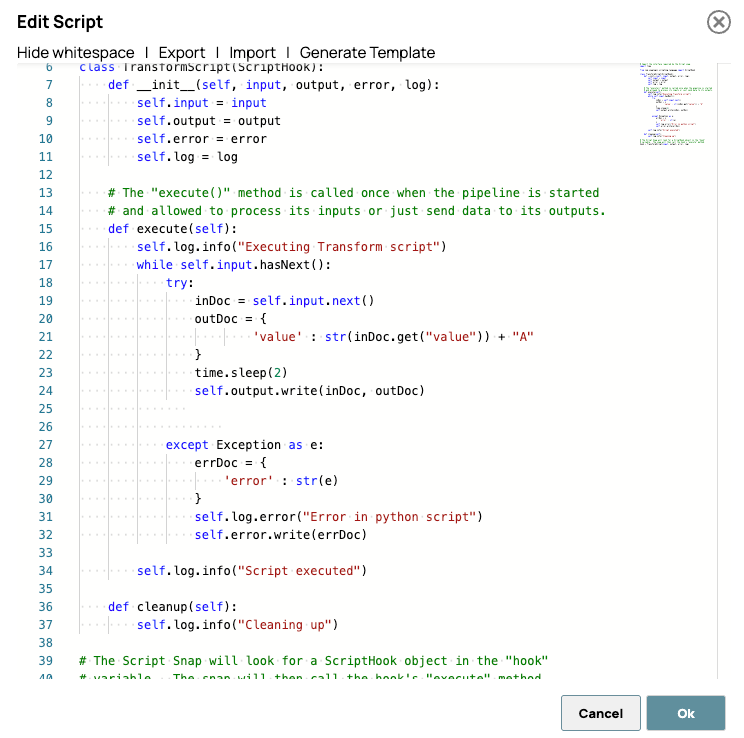
Il ritardo viene aggiunto intenzionalmente per visualizzare l'effetto dell'elaborazione parallela, rendendo più evidenti i miglioramenti delle prestazioni durante il monitoraggio o il test.
3. Comportamento di esecuzione
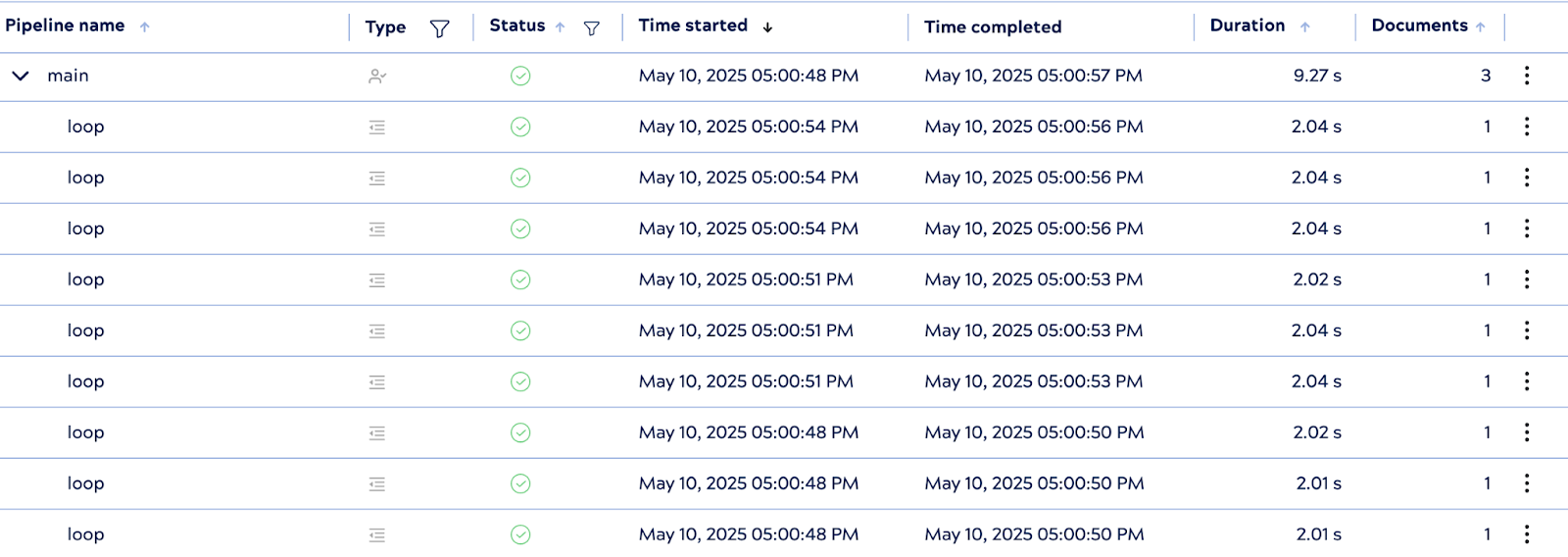
All'esecuzione, PipelineLoop avvia tre istanze di pipeline figlie in parallelo, una per ogni documento di input. Sebbene ogni pipeline figlia includa un ritardo di elaborazione di 2 secondi, l'esecuzione complessiva è stata completata in circa 9 secondi, un tempo comunque significativamente più veloce rispetto al tempo di esecuzione seriale ottimale di 18 secondi.
Sebbene il tempo di esecuzione teorico in condizioni di parallelismo ideali sia di circa 6 secondi, fattori reali quali il tempo di inizializzazione di Snap e la latenza dell'API possono introdurre un leggero sovraccarico. Ciononostante, il risultato dimostra un'efficace concorrenza ed evidenzia i vantaggi in termini di prestazioni dell'esecuzione parallela in scenari di integrazione pratici.
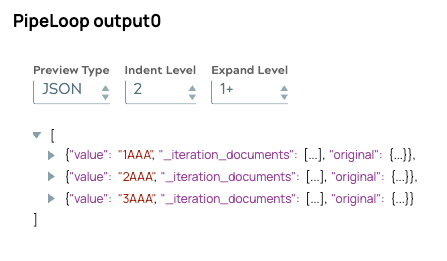
Cosa ancora più importante, anche con l'elaborazione simultanea, l'ordine di output rimane coerente con la sequenza di input originale. Ciò conferma che il meccanismo di accodamento interno di PipelineLoop allinea correttamente i risultati, garantendo un'elaborazione a valle affidabile.






