






Ce document explore l'intégration des fonctionnalités Vertex AI Retrieval Augmented Generation (RAG) CloudGoogle Cloudavec SnapLogic. Nous examinerons en détail le fonctionnement de Vertex AI RAG, ses avantages par rapport aux bases de données vectorielles traditionnelles et ses applications pratiques au sein de plateforme SnapLogic. Ce guide traitera de la configuration et de l'utilisation de Vertex AI RAG, de l'automatisation des flux de connaissances et de l'intégration avec les snaps Generate de SnapLogic pour améliorer les performances LLM.
Moteur RAG Vertex AI
Le moteur Vertex AI RAG rationalise le processus de génération augmentée par la récupération (RAG) en deux étapes principales :
- Gestion des connaissances: le moteur RAG de Vertex AI établit et maintient une base de connaissances en créant un corpus qui sert d'index pour stocker les fichiers source.
- Requête de recherche: dès réception d'une demande, le moteur RAG de Vertex AI effectue une recherche efficace dans cette base de connaissances afin d'identifier et de récupérer les informations les plus pertinentes pour la requête.
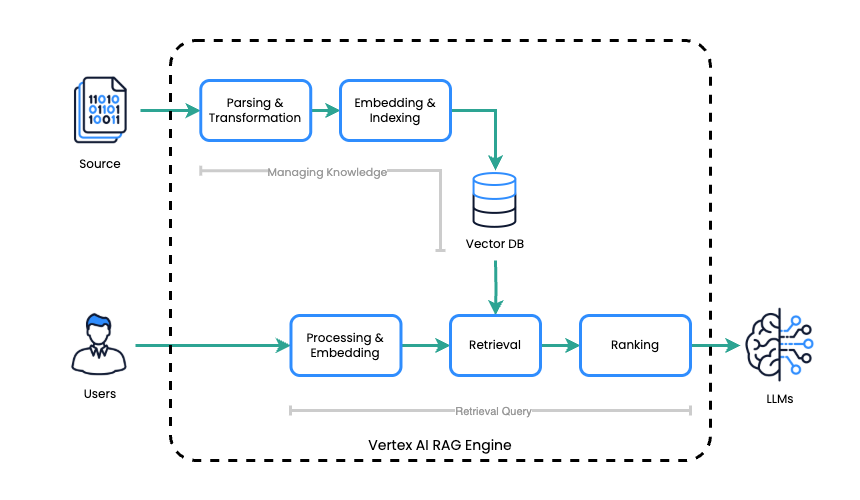
Le moteur Vertex AI RAG intègre Vertex AI CloudGoogle Cloudà l'architecture RAG afin de produire des réponses LLM précises et pertinentes dans leur contexte. Il couvre les tâches liées à la gestion des connaissances en créant un corpus qui sert d'index pour les fichiers source. Pour le traitement, il récupère efficacement les informations pertinentes dans cette base de connaissances lorsqu'une invite est reçue, puis exploite le LLM pour générer une réponse basée sur le contexte récupéré.
Différence entre une base de données vectorielle
Bien que les bases de données vectorielles traditionnelles et le moteur RAG de Vertex AI soient tous deux conçus pour améliorer les réponses des modèles LLM en fournissant des connaissances externes, leur approche et leurs capacités diffèrent considérablement.
Bases de données vectorielles
Les bases de données vectorielles se concentrent principalement sur le stockage et l'interrogation d'intégrations vectorielles. Pour les utiliser avec un LLM pour RAG, vous devez généralement :
- Gérer manuellement la génération d'intégration: vous êtes responsable de la génération d'intégrations vectorielles pour vos données source à l'aide d'un modèle d'intégration.
- Logique de récupération des identifiants: vous devez implémenter la logique permettant d'interroger la base de données vectorielle, de récupérer les intégrations pertinentes, puis de les remapper vers le texte source d'origine.
- Intégration avec le LLM: le texte récupéré doit ensuite être explicitement transmis au LLM dans le cadre de l'invite.
- Pas d'intégration LLM intégrée: ils sont indépendants du LLM et nécessitent une intégration manuelle pour les workflows RAG.
Moteur RAG Vertex AI
Le moteur RAG de Vertex AI offre une solution plus intégrée et rationalisée, qui élimine une grande partie de la complexité. Les principales différences sont les suivantes :
- Gestion intégrée des connaissances: elle gère l'ensemble du cycle de vie de votre base de connaissances, depuis l'ingestion des fichiers sources bruts jusqu'à l'indexation et la gestion du corpus. Vous n'avez pas besoin de générer manuellement des intégrations ni de gérer le stockage vectoriel.
- Récupération automatisée: le moteur effectue automatiquement la récupération des informations pertinentes à partir de son corpus en fonction de la requête de l'utilisateur.
- Intégration transparente des LLM: il est conçu pour fonctionner directement avec les LLM de Vertex AI, en gérant la contextualisation de l'invite avec les informations récupérées avant de la transmettre au LLM.
- Solution de bout en bout: elle offre une solution plus complète pour le RAG, simplifiant le développement et le déploiement d'applications basées sur le RAG.
En substance, une base de données vectorielle traditionnelle est un composant qui nécessite une orchestration importante pour mettre en œuvre le RAG. En revanche, le moteur RAG de Vertex AI est un service géré plus complet qui simplifie l'ensemble du workflow RAG en fournissant une gestion intégrée des connaissances, une récupération et une intégration LLM.
Cet avantage fondamental permet une simplification significative du pipeline de traitement RAG, souvent complexe. En rationalisant ce processus, nous pouvons gagner en efficacité, réduire les points de défaillance potentiels et, au final, fournir des résultats plus précis et pertinents lorsque nous exploitons des modèles linguistiques à grande échelle (LLM) pour des tâches qui nécessitent des connaissances externes. Cette simplification améliore non seulement les performances, mais aussi la gestion et l'évolutivité globales des systèmes basés sur RAG, les rendant plus accessibles et plus efficaces pour un plus large éventail d'applications.
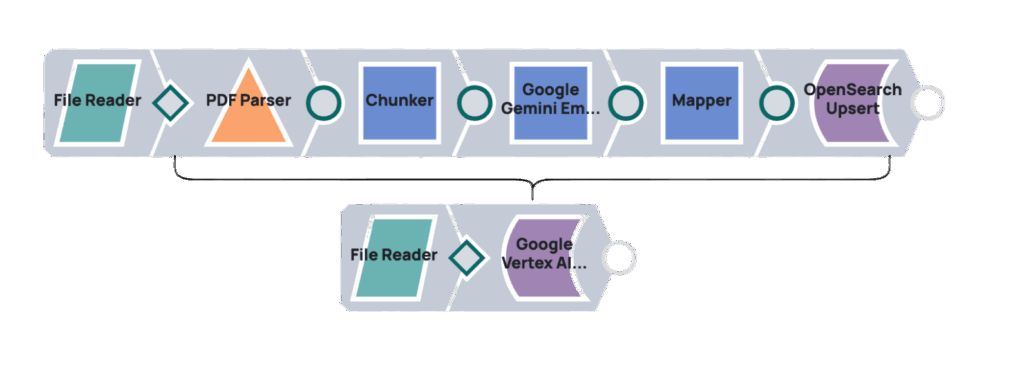
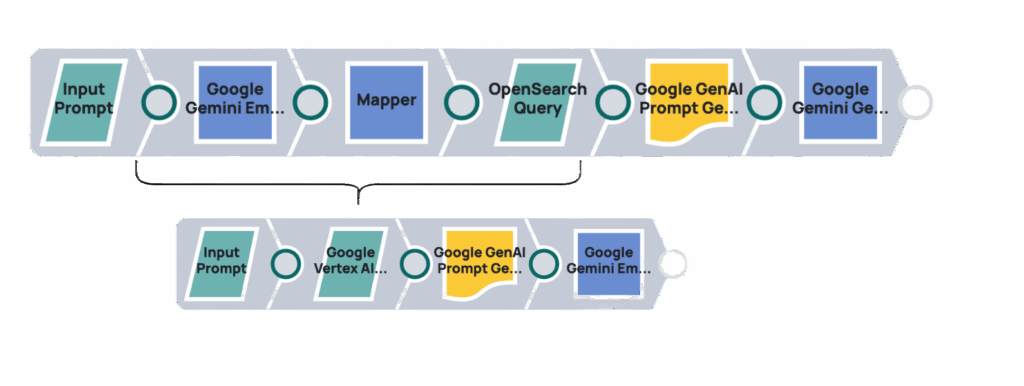
L'utilisation du moteur RAG de Vertex AI avec l'IA générative (au lieu de passer directement par l'API Gemini) offre plusieurs avantages. Elle améliore la recherche d'informations liées aux requêtes grâce à des outils intégrés, ce qui simplifie l'accès aux données pour les modèles d'IA générative. Cette intégration native dans Vertex AI optimise le flux d'informations, réduit la complexité et permet d'obtenir un système plus robuste pour la génération augmentée par la recherche.
Moteur Vertex AI RAG dans SnapLogic
SnapLogic inclut désormais un ensemble de Snaps permettant d'utiliser le moteur RAG de Vertex AI.
Gestion du corpus
Les Snaps suivants sont disponibles pour gérer les corpus RAG :
- Google Vertex AI RAG Créer un corpus
- Corpus de liste RAG de Google Vertex AI
- Google Vertex AI RAG Obtenir le corpus
- Google Vertex AI RAG Supprimer le corpus




Gestion des fichiers dans Corpus
Les Snaps suivants permettent la gestion des fichiers au sein d'un corpus RAG :
- Google Vertex AI RAG Corpus Ajouter un fichier
- Fichier de liste de corpus Google Vertex AI RAG
- Google Vertex AI RAG Corpus Obtenir le fichier
- Google Vertex AI RAG Corpus Supprimer le fichier




Récupération
Pour effectuer des opérations de récupération, utilisez le Snap suivant :
- Requête de recherche Google Vertex AI RAG

Essayez d'utiliser Vertex AI RAG
Voyons un exemple pratique illustrant comment exploiter le moteur RAG Vertex AI dans SnapLogic. Cette section vous guidera dans la configuration d'un corpus, l'ajout de fichiers, l'exécution de requêtes de recherche et l'intégration des résultats dans vos applications LLM.
Étape de préparation
Avant l'intégration, deux étapes clés sont nécessaires : tout d'abord, configurez un Cloud Google Cloud avec les API activées, la facturation liée et les autorisations nécessaires.
Liste des API Google activées requises
- https://console.cloud.google.com/apis/library/cloudresourcemanager.googleapis.com
- https://console.cloud.google.com/apis/library/aiplatform.googleapis.com
SnapLogic propose deux méthodes principales pour se connecter aux Cloud Google Cloud :
- Compte de service (recommandé): SnapLogic peut utiliser un compte de service existant qui dispose des autorisations nécessaires.
- OAuth2: cette méthode nécessite la configuration d'OAuth2.
Jeton d'accès : un jeton d'accès est un identifiant de sécurité temporaire permettant d'accéder Cloud Google Cloud . Il doit être actualisé manuellement lorsqu'il expire.
Créer le corpus
Pour créer le corpus, utilisez le snap Google Vertex AI RAG Create Corpus.
- Placez le snap Google Vertex AI RAG Create Corpus.
- Créer un compte de service Google GenAI
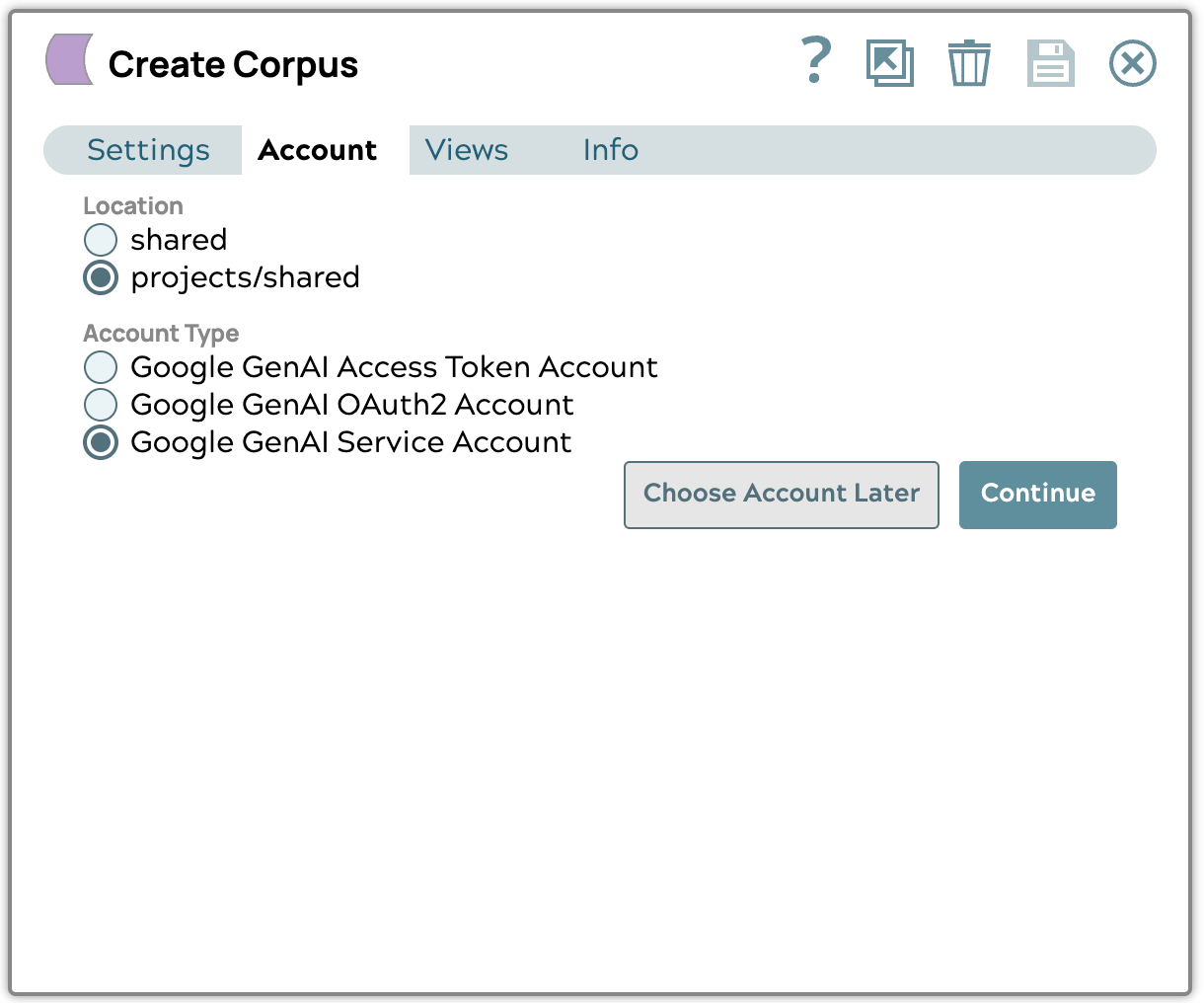
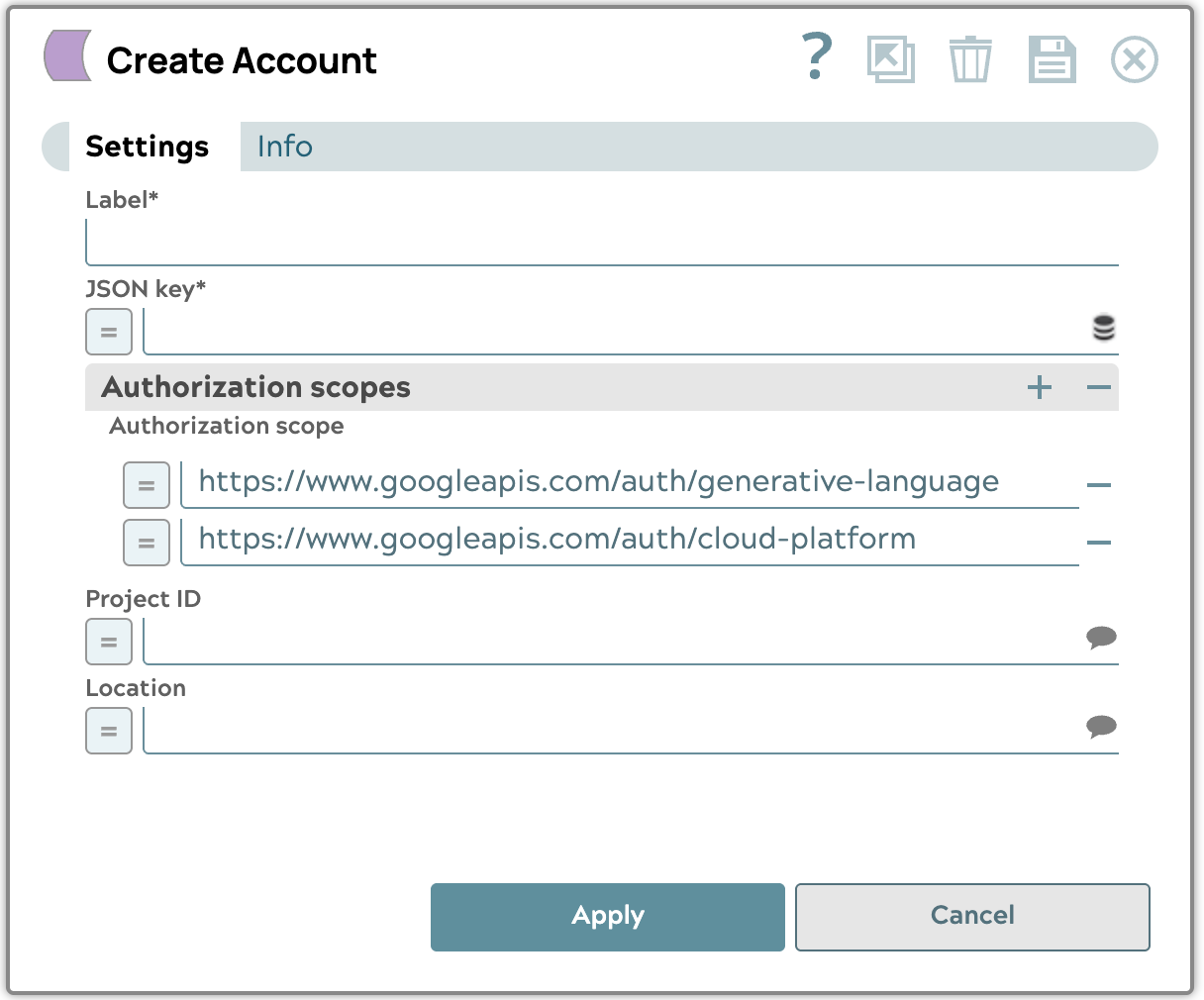
Téléchargez le fichier de clé JSON du compte de service que vous avez obtenu auprès de Google Cloud , puis sélectionnez le projet et l'emplacement des ressources que vous souhaitez utiliser. Nous vous recommandons d'utiliser l'emplacement « us-central1 ».
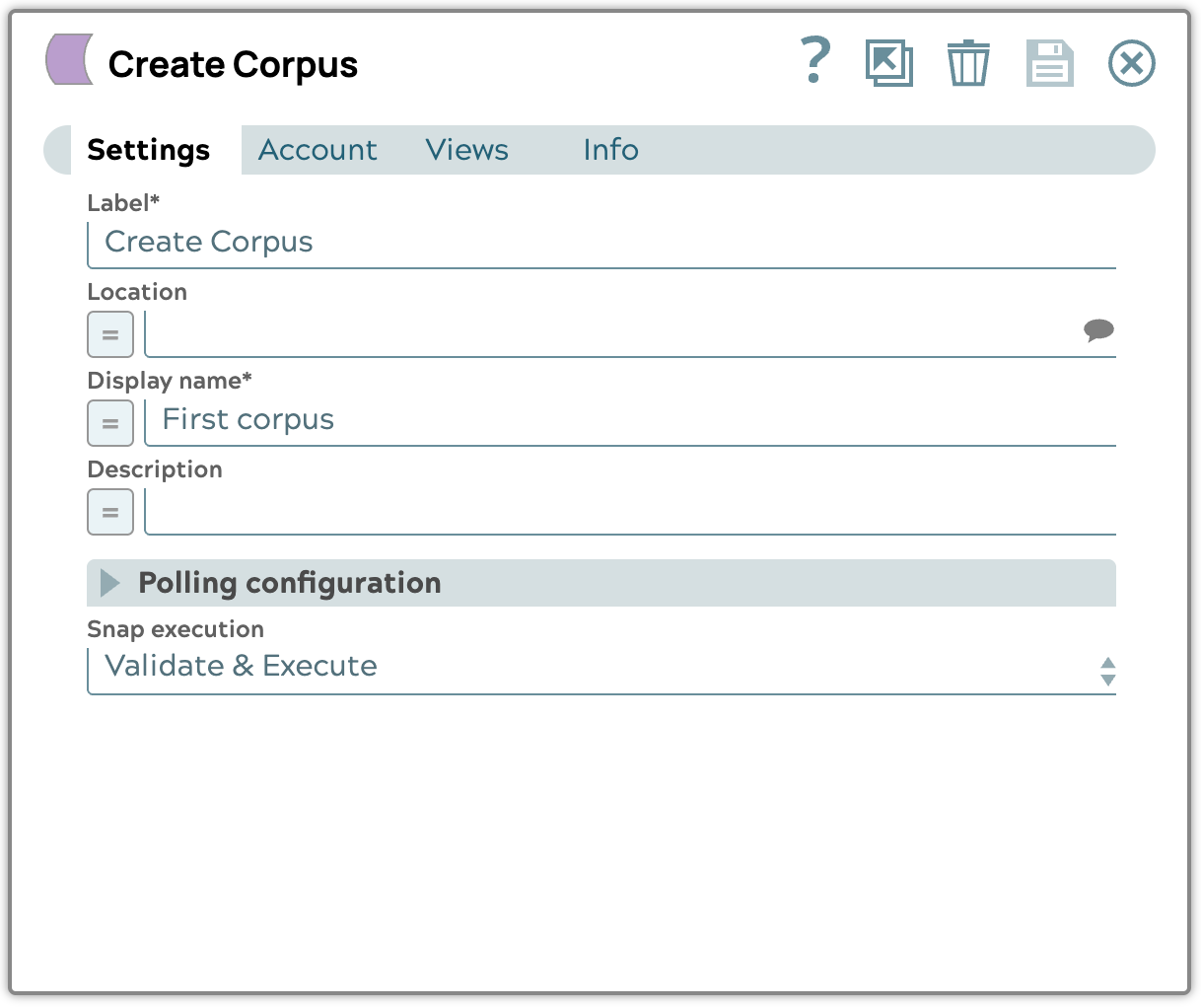
- Modifiez la configuration en définissant le nom d'affichage et l'exécution Snap sur « Valider et exécuter ».
- Valider le pipeline pour obtenir le résultat du corpus dans la sortie.
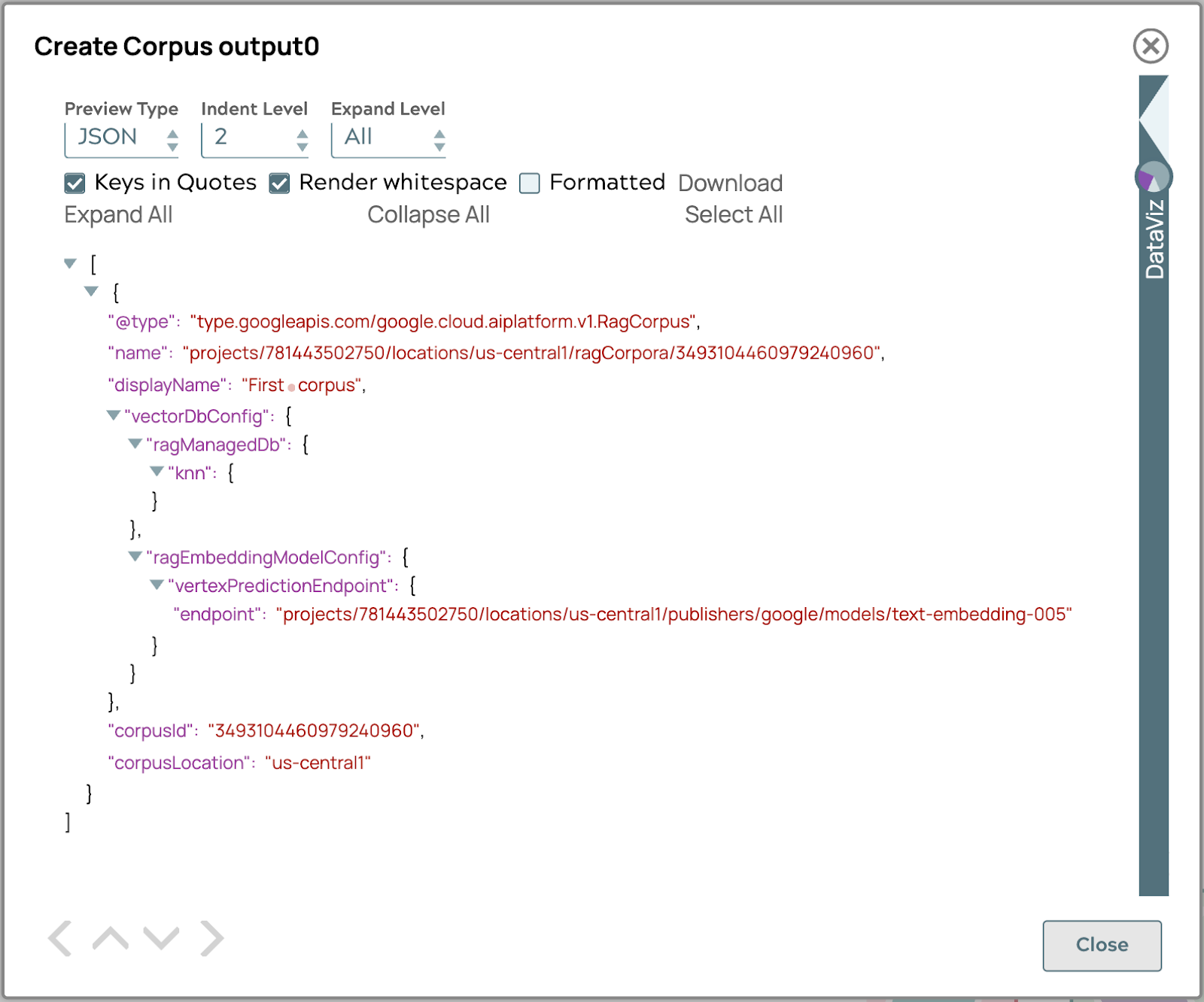
Si le résultat est similaire à l'image ci-dessus, votre corpus est prêt à accueillir le document.
Télécharger le document
Pour télécharger des documents vers Google Vertex AI RAG, intégrez SnapLogic à l'aide d'un pipeline reliant les Snaps « Google Vertex AI RAG Corpus Add File » et « File Reader ». Le « File Reader » accède au document et transmet son contenu au Snap « Google Vertex AI RAG Corpus Add File », qui le télécharge vers un corpus Vertex AI RAG spécifié.
Exemple
- Téléchargez le document d'exemple. Fichier d'exemple : Basics of SnapLogic.pdf
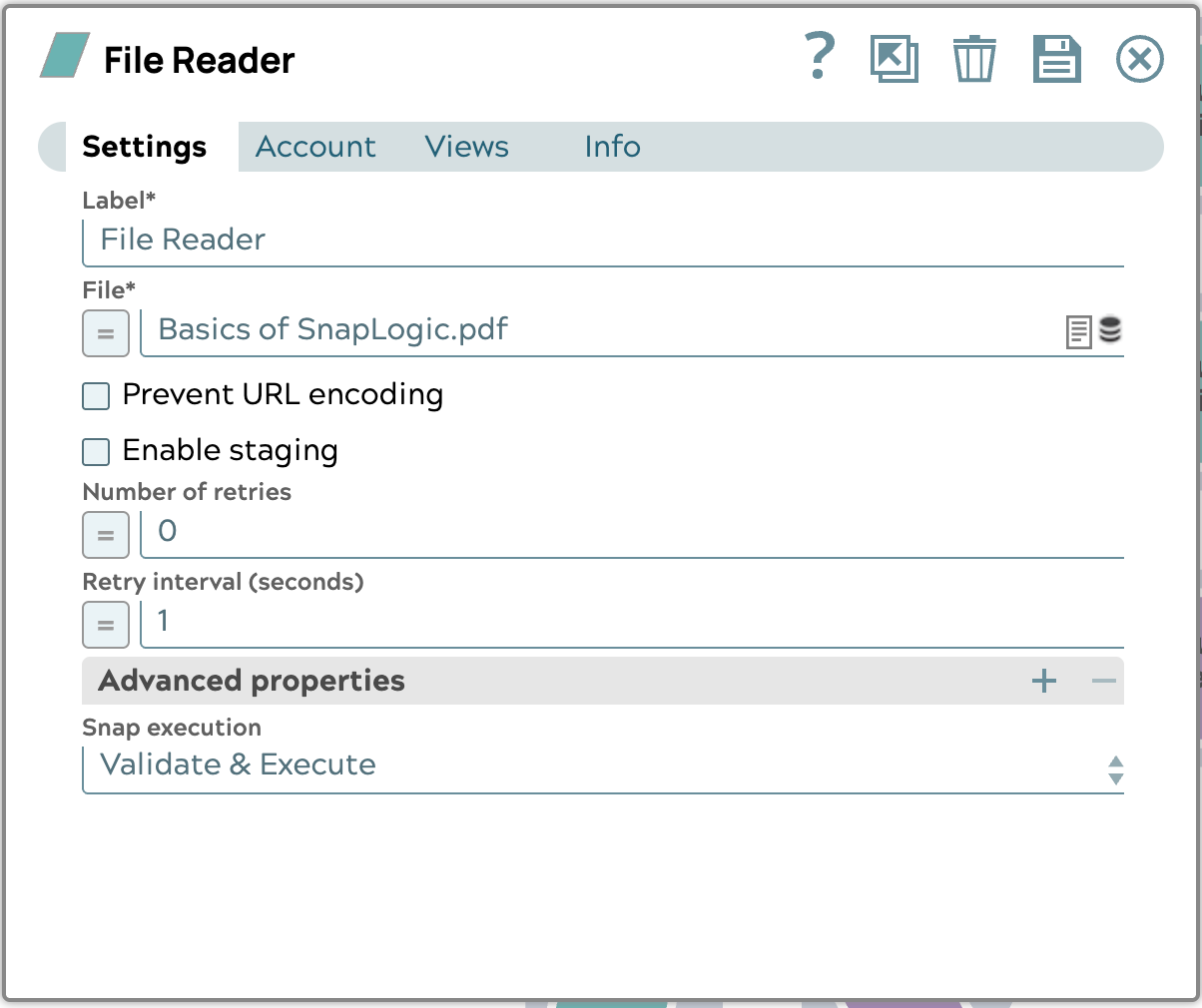
- Configurez le Snap File Reader comme suit :
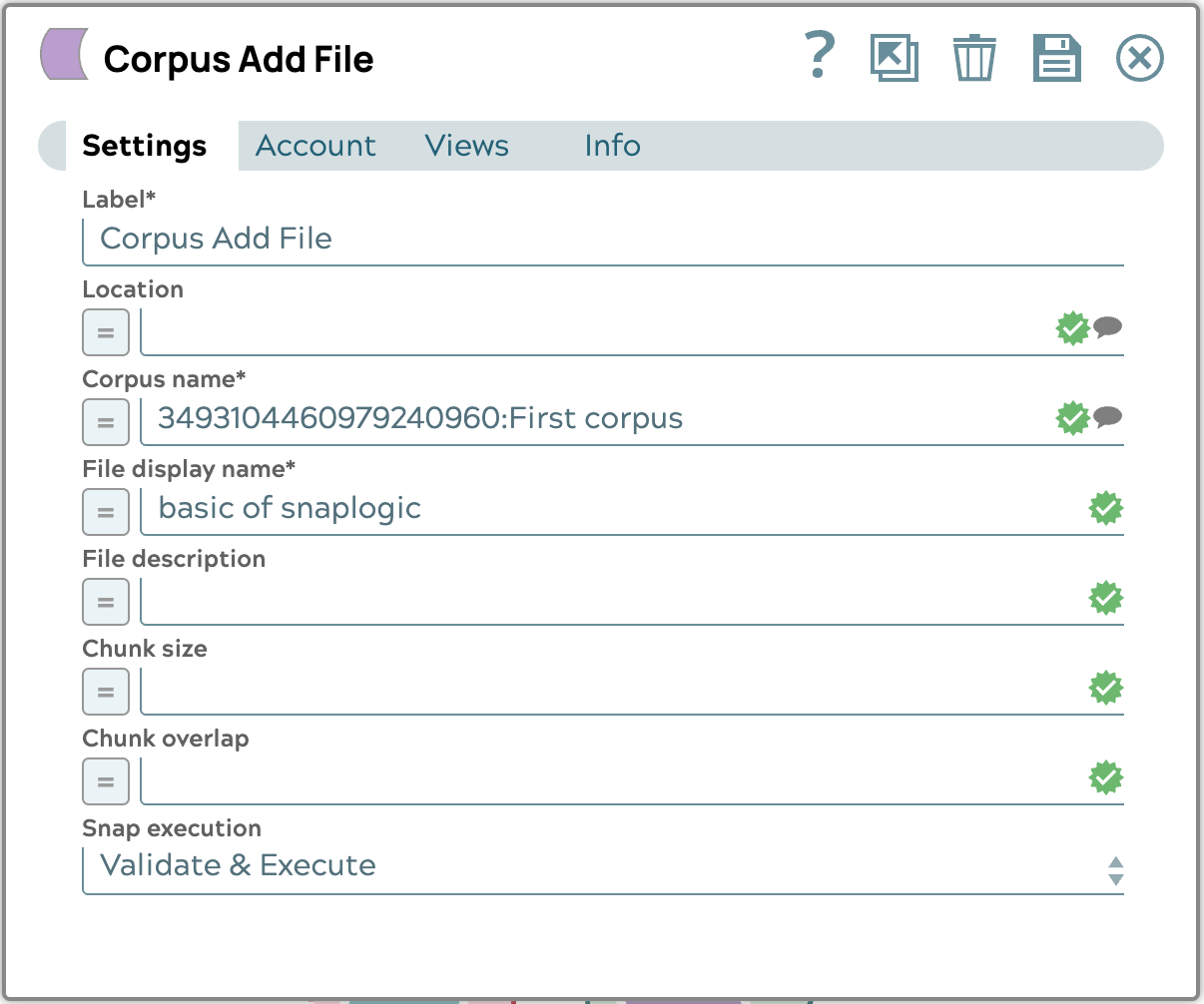
- Configurez le module Corpus Add File Snap comme suit :
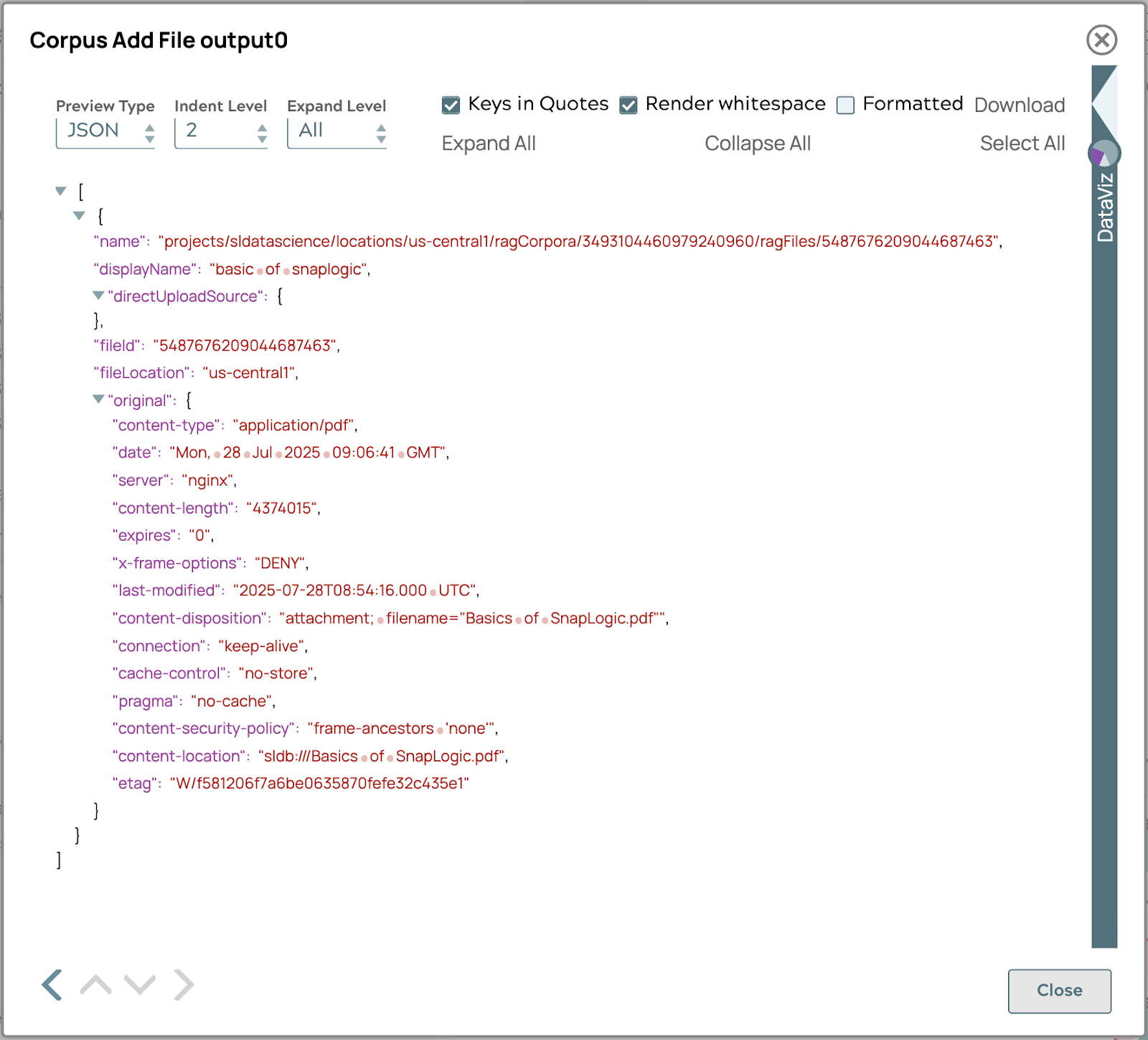
Ces étapes ajouteront le fichier Basics of SnapLogic.pdf au corpus de la section précédente. Si vous exécutez le pipeline avec succès, le résultat sera le suivant.
Récupérer la requête
Cette section montre comment utiliser le snap Google Vertex AI RAG Retrieval Query pour extraire des informations pertinentes du corpus. Ce snap prend en charge la requête d'un utilisateur et renvoie les documents ou extraits de texte les plus pertinents.

Exemple
À partir du corpus existant, nous poserons la question « Quels types de snap SnapLogic propose-t-il ? » et configurerons le snap en conséquence.
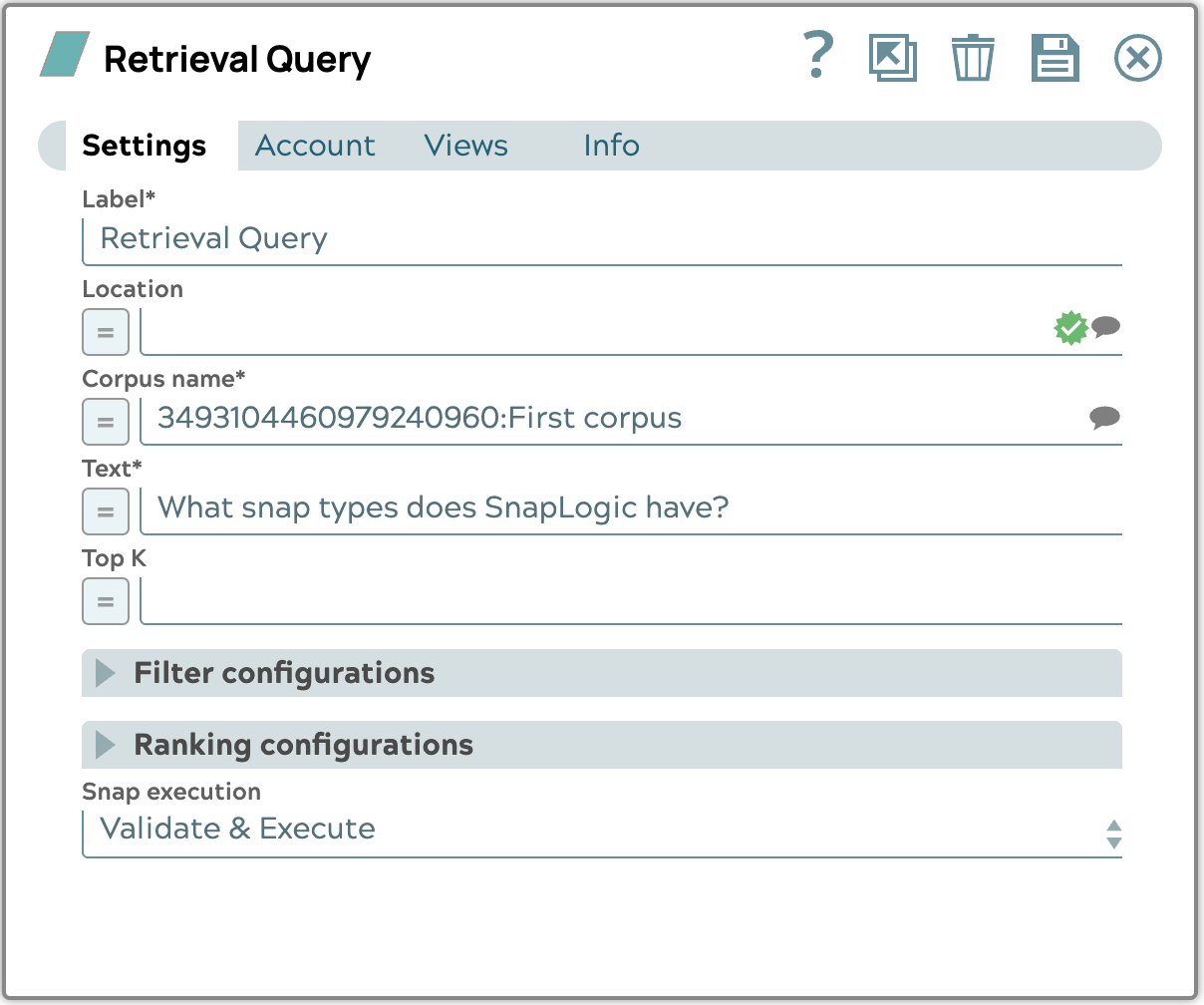
Le résultat affichera une liste de fragments de texte liés à la question, classés par valeur de score. La valeur du score est calculée à partir de la similarité ou de la distance entre la requête et chaque fragment de texte. La similarité ou la distance dépend de la base de données vectorielle que vous choisissez. Par défaut, le score est la COSINE_DISTANCE.
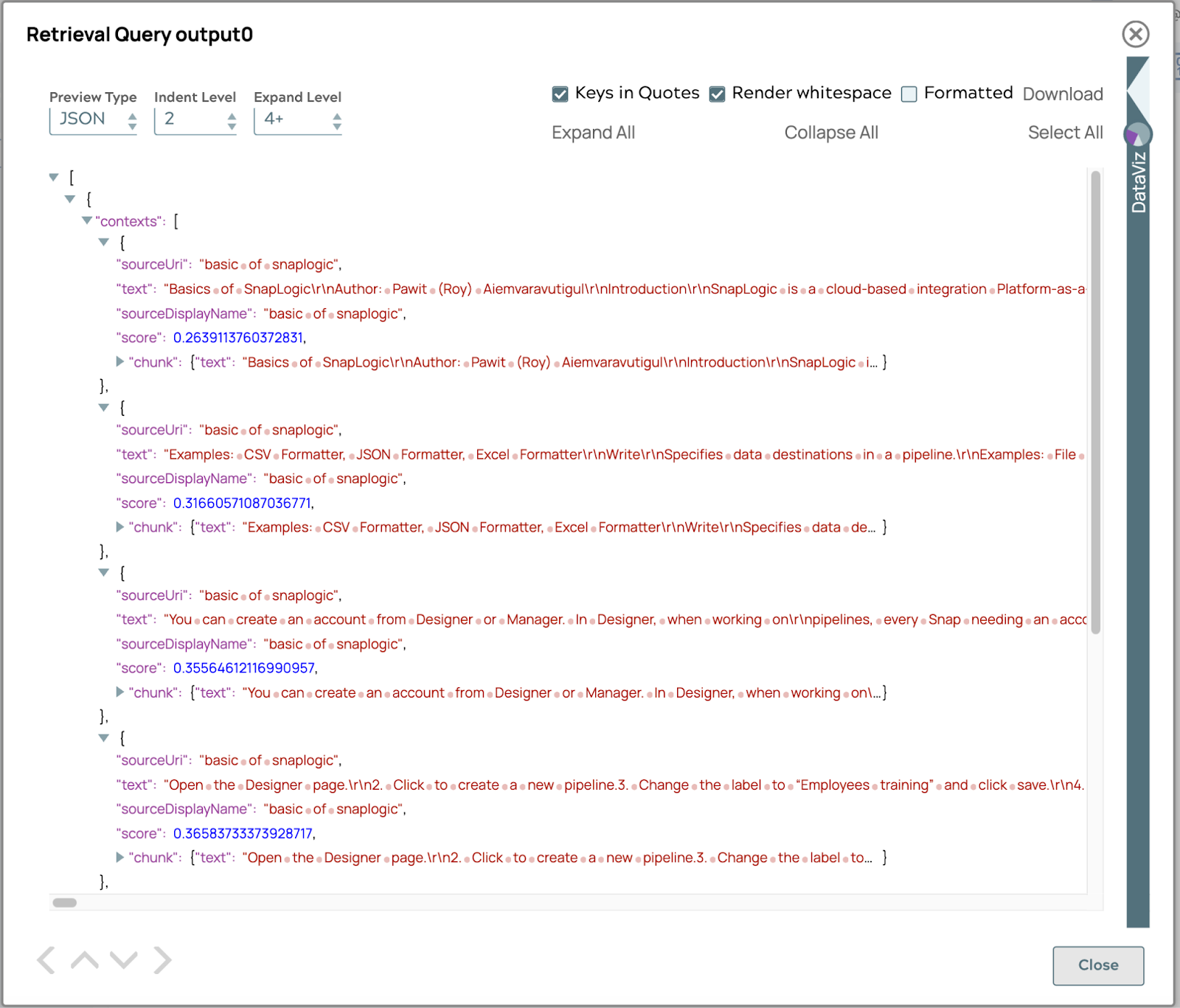
Générer le résultat
Maintenant que nous avons réussi à extraire les informations pertinentes de notre corpus, l'étape cruciale suivante consiste à exploiter ce contexte extrait pour générer une réponse cohérente et précise à l'aide d'un LLM. Cette section montre comment intégrer les résultats du Google Vertex AI RAG Retrieval Query Snap à un modèle d'IA générative, tel que le Google Gemini Generate Snap, afin de produire une réponse finale basée sur les informations enrichies.

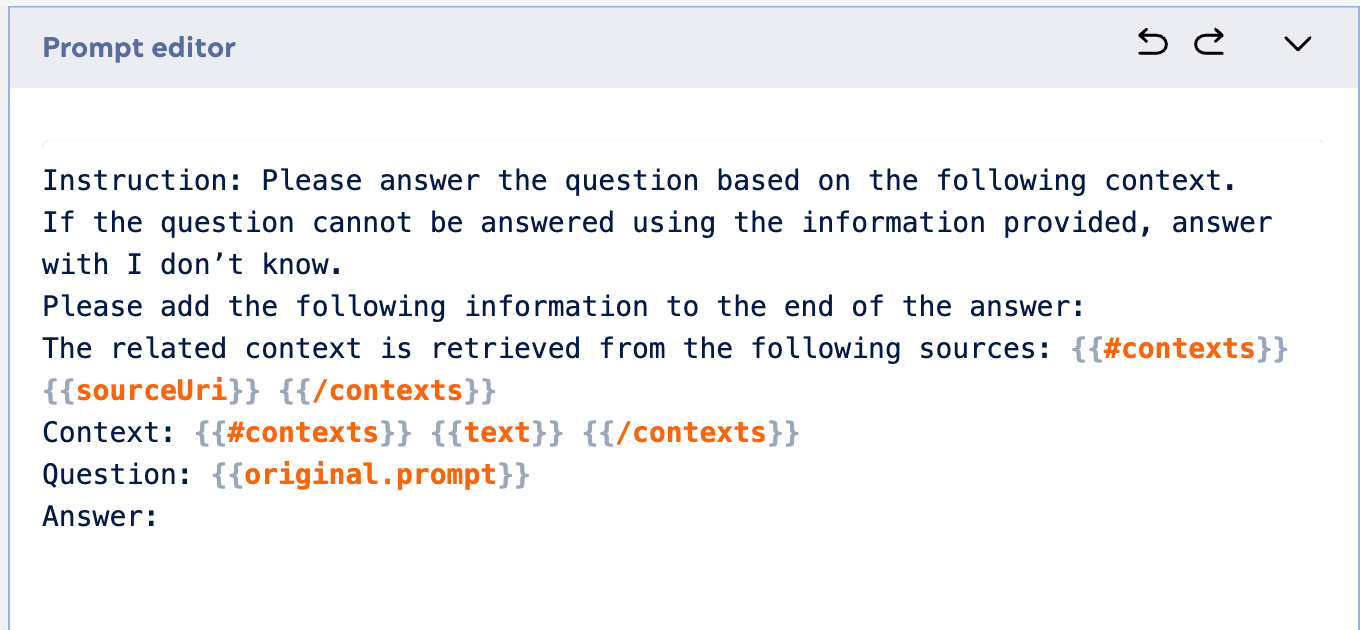
Voici un exemple de prompt à utiliser dans le générateur de prompts :
La réponse finale apparaîtra comme suit :
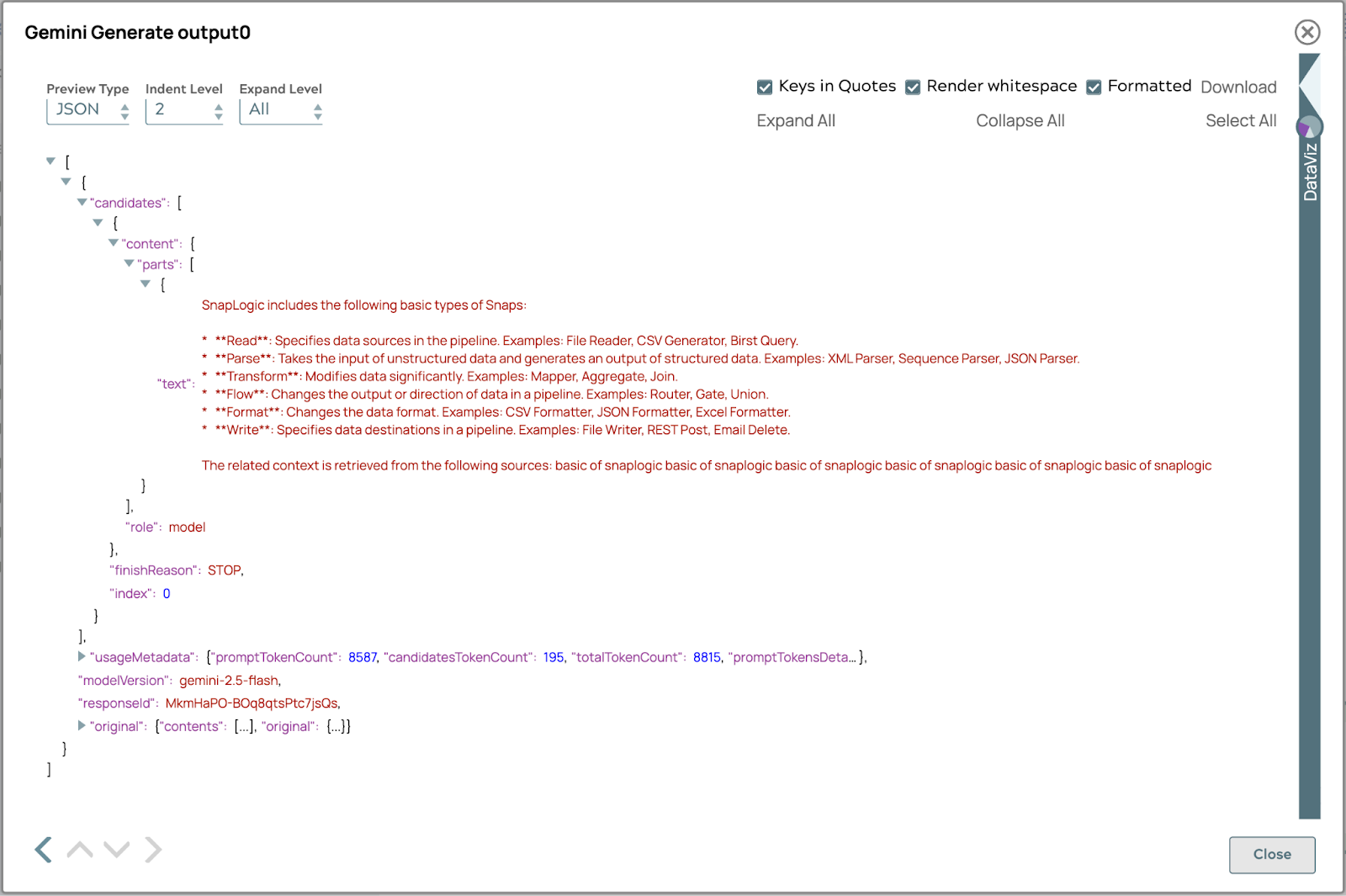
De plus, l'intégration entre Vertex AI RAG et SnapLogic offre l'avantage considérable d'une compatibilité entre les modèles. Cela signifie que les workflows RAG les workflows processus de récupération de données établis peuvent être adaptés et utilisés de manière transparente avec différents modèles linguistiques de grande taille au-delà de Vertex AI, tels que les modèles open source ou d'autres LLM commerciaux. Cette flexibilité permet aux organisations de tirer parti de leur investissement dans l'infrastructure RAG à travers un écosystème diversifié de modèles d'IA, ce qui leur offre une plus grande adaptabilité, des applications à l'épreuve du temps et la possibilité de choisir le LLM le mieux adapté à des tâches spécifiques sans avoir à reconstruire l'ensemble du pipeline de récupération d'informations. Cet avantage intermodèle garantit que la solution RAG reste polyvalente et précieuse, quelle que soit l'évolution du paysage des LLM.
Récupération automatique des requêtes avec l'outil intégré Vertex AI
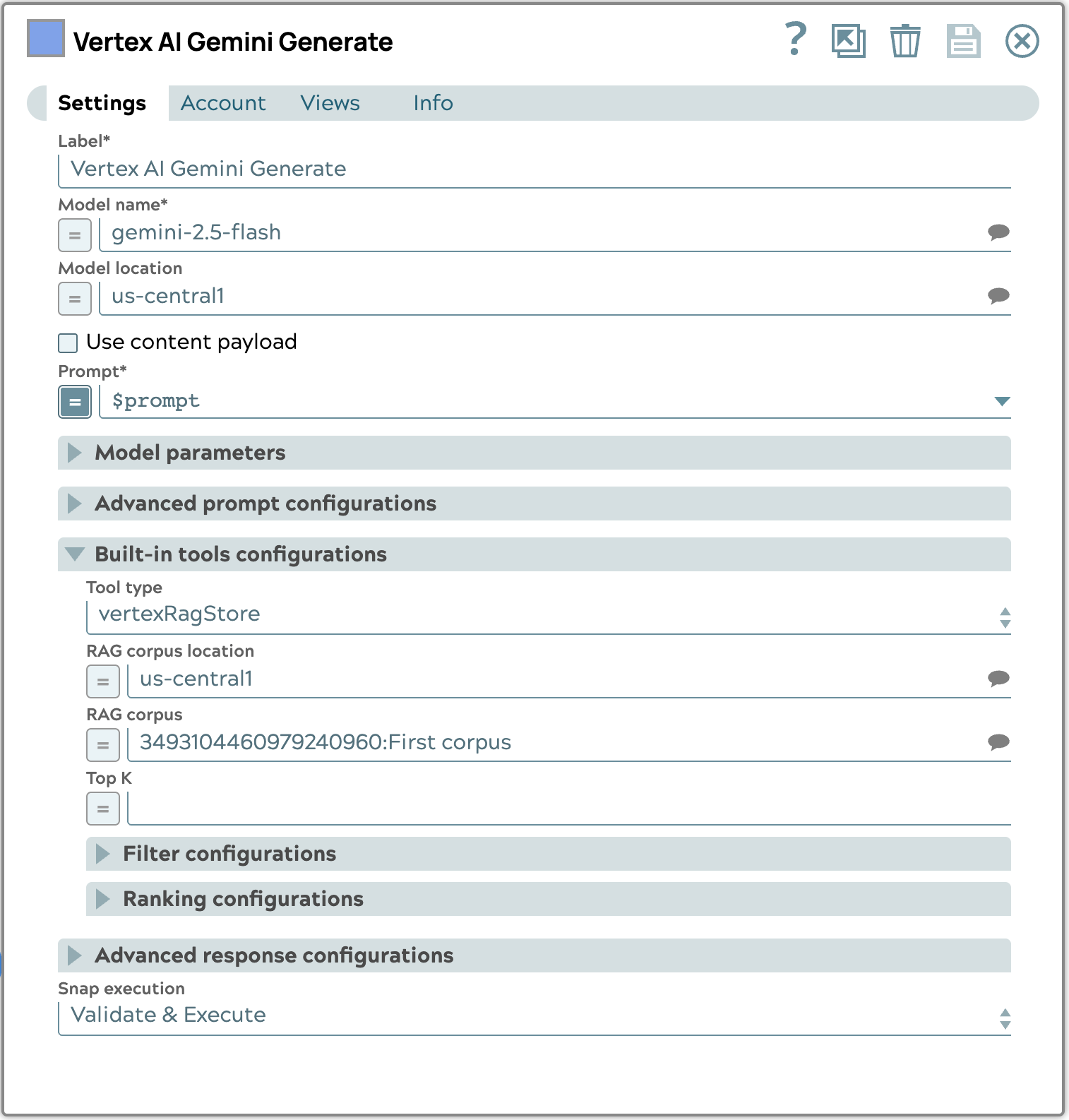
L'utilisation de l'outil intégré dans Vertex AI Gemini Generate Snap pour la récupération automatique simplifie considérablement le pipeline RAG. Au lieu d'effectuer manuellement une requête de récupération puis de transmettre les résultats à une étape de génération distincte, cette approche intégrée permet au modèle Gemini de consulter automatiquement le corpus RAG configuré en fonction de l'invite de saisie. Cela réduit le nombre d'étapes et la complexité du pipeline, car les processus de récupération et de génération sont gérés de manière transparente dans un seul Snap. Cela garantit que le LLM a toujours accès aux informations contextuelles les plus pertinentes de votre base de connaissances sans nécessiter d'orchestration explicite, ce qui permet une génération de contenu plus efficace et plus précise.

L'exemple de configuration ci-dessous montre comment configurer la section Outils intégrés. Plus précisément, nous sélectionnons le type vertexRagStore et désignons le corpus cible.
La réponse finale générée à l'aide du processus de récupération automatique s'affichera ci-dessous.
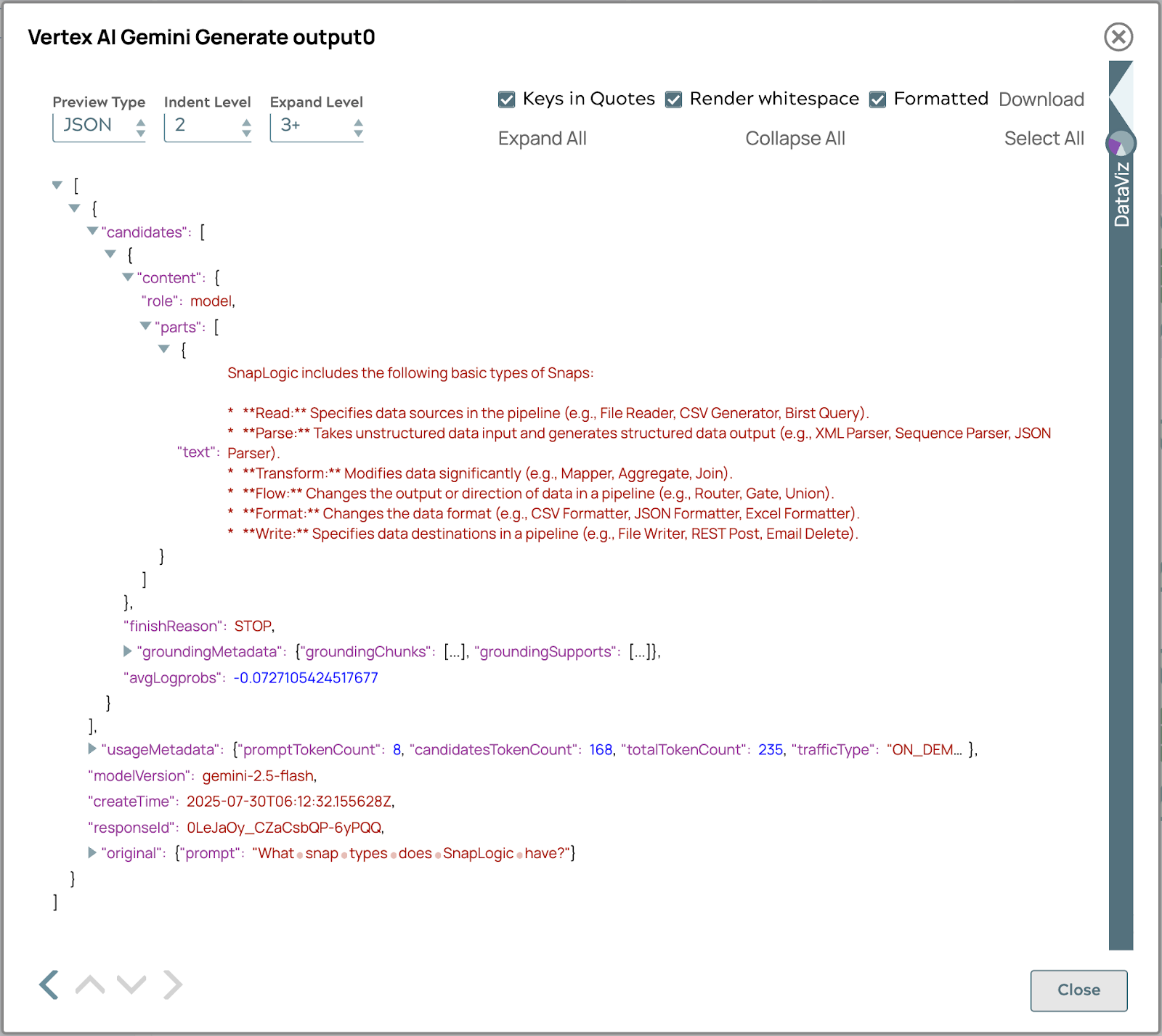
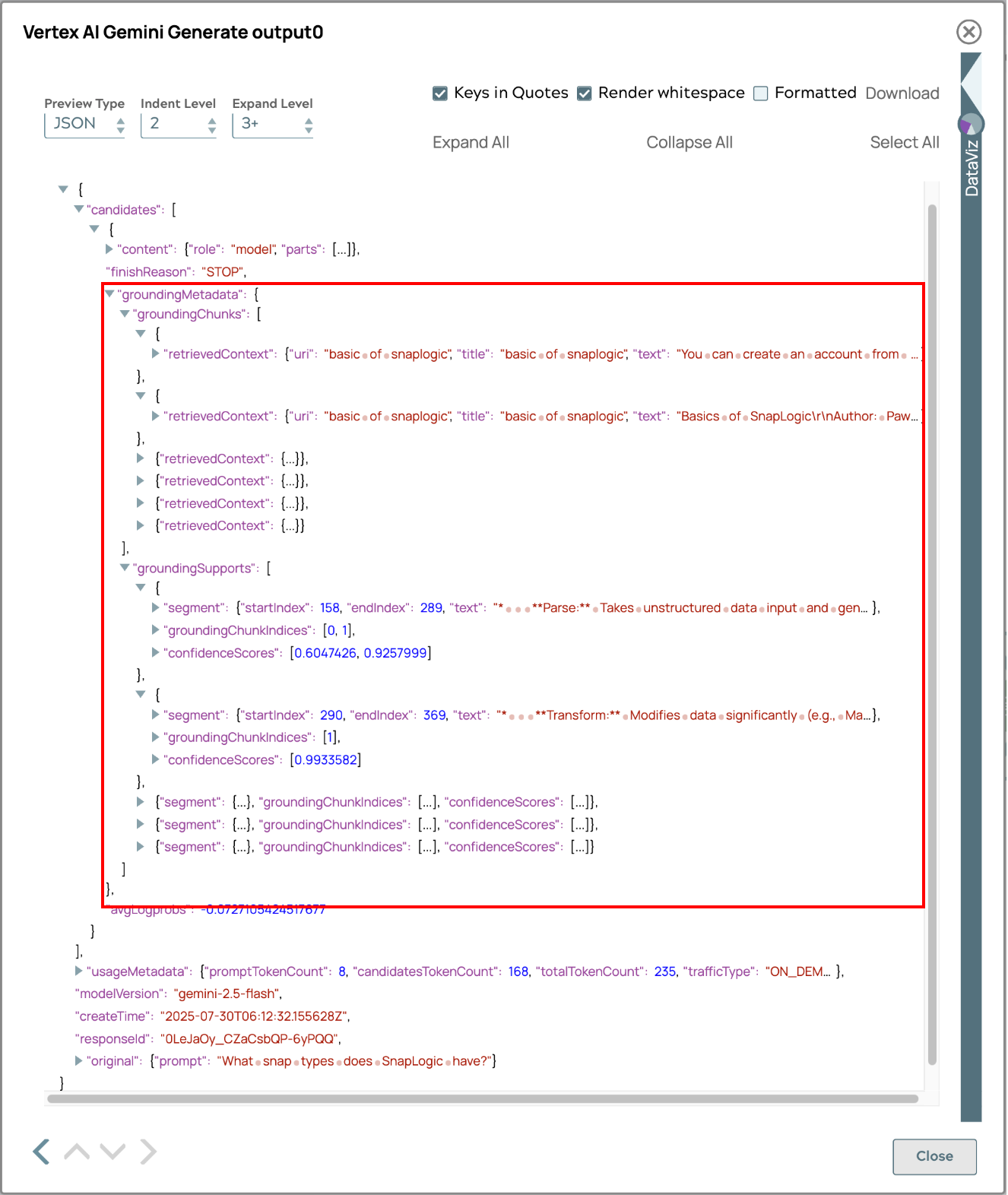
La réponse comprend des métadonnées de base pour le suivi des sources, permettant aux utilisateurs de retracer l'origine des informations. Cette fonctionnalité améliore la transparence, la vérification des faits et renforce la confiance dans l'exactitude et la fiabilité du contenu. Les utilisateurs peuvent approfondir leurs recherches sur les sources, recouper les faits et acquérir une compréhension complète, ce qui renforce l'utilité et la fiabilité du système.
Résumé
Ce document explique comment intégrer les fonctionnalités Vertex AI Retrieval Augmented Generation (RAG) CloudGoogle Cloudà SnapLogic afin d'améliorer les workflows LLM. Les points clés à retenir sont les suivants :
- Processus RAG rationalisé: Vertex AI RAG simplifie la gestion et la récupération des connaissances, en éliminant les complexités telles que la génération manuelle d'intégration et la logique de récupération, qui sont généralement requises avec les bases de données vectorielles traditionnelles.
- Solution intégrée: contrairement aux bases de données vectorielles autonomes, Vertex AI RAG offre une solution complète pour le RAG, prenant en charge toutes les étapes, de l'ingestion des fichiers bruts à l'intégration avec les LLM.
- Intégration SnapLogic: SnapLogic fournit des Snaps dédiés à la gestion des corpus Vertex AI RAG (création, listage, récupération, suppression), à la gestion des fichiers au sein des corpus (ajout, listage, récupération, suppression) et à l'exécution de requêtes de recherche.
- Application pratique: le guide fournit un exemple étape par étape de la configuration d'un corpus, du téléchargement de documents, de l'exécution de requêtes de recherche à l'aide du Google Vertex AI RAG Retrieval Query Snap et de l'intégration des résultats à des modèles d'IA générative tels que le Google Gemini Generate Snap pour obtenir des réponses contextuellement précises.
- Compatibilité entre modèles: l'un des avantages significatifs de cette intégration réside dans la possibilité d'adapter les workflows RAG les workflows processus de récupération de données établis à divers modèles d'apprentissage automatique (LLM) au-delà de Vertex AI, y compris des modèles open source et d'autres modèles commerciaux, garantissant ainsi flexibilité et pérennité.
- Récupération automatisée à l'aide d'outils intégrés: l'intégration permet une récupération automatisée via les outils intégrés dans Vertex AI Gemini Generate Snap, simplifiant ainsi le pipeline RAG en gérant la récupération et la génération de manière transparente en une seule étape.
En exploitant Vertex AI RAG avec SnapLogic, les entreprises peuvent simplifier le développement et le déploiement d'applications basées sur la technologie RAG, ce qui permet d'obtenir des réponses LLM plus précises, plus pertinentes contextuellement et plus efficaces.





