






Questo documento esplora l'integrazione delle funzionalità Vertex AI Retrieval Augmented Generation (RAG) CloudGoogle Cloudcon SnapLogic. Approfondiremo il funzionamento di Vertex AI RAG, i suoi vantaggi rispetto ai database vettoriali tradizionali e le applicazioni pratiche all'interno della piattaforma SnapLogic. La guida tratterà la configurazione e l'utilizzo di Vertex AI RAG, l'automazione dei feed di conoscenza e l'integrazione con gli snap Generate di SnapLogic per migliorare le prestazioni LLM.
Motore RAG di Vertex AI
Il motore RAG di Vertex AI semplifica il processo di generazione potenziata dal recupero (RAG) attraverso due fasi principali:
- Gestione delle conoscenze: il motore RAG di Vertex AI crea e mantiene una base di conoscenze creando un corpus che funge da indice per l'archiviazione dei file sorgente.
- Query di recupero: dopo aver ricevuto una richiesta, il motore RAG di Vertex AI effettua una ricerca efficiente in questa base di conoscenze per identificare e recuperare le informazioni più pertinenti alla richiesta.
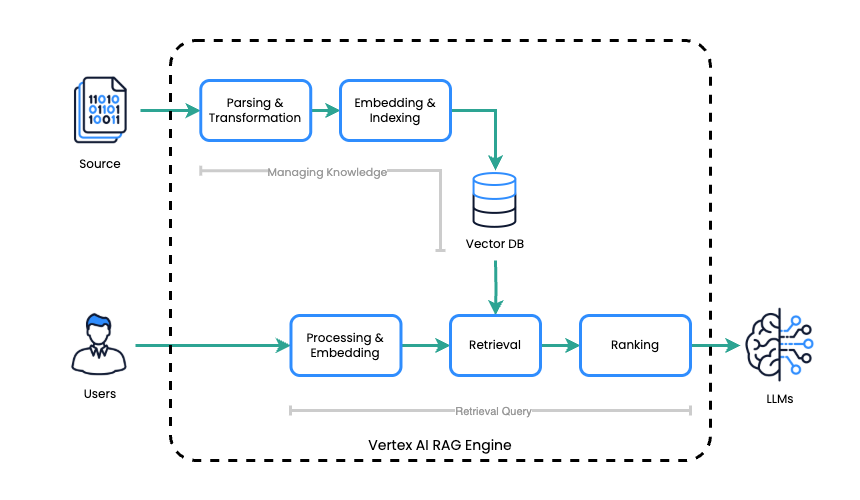
Il motore Vertex AI RAG integra Vertex AI CloudGoogle Cloudcon l'architettura RAG per produrre risposte LLM accurate e contestualmente rilevanti. Copre attività relative alla gestione della conoscenza creando un corpus come indice per i file di origine. Per l'elaborazione, recupera in modo efficiente le informazioni rilevanti da questa base di conoscenza quando riceve un prompt, quindi sfrutta l'LLM per generare una risposta basata sul contesto recuperato.
Differenza tra database vettoriale
Sebbene sia i database vettoriali tradizionali che il motore RAG di Vertex AI siano progettati per migliorare le risposte LLM fornendo conoscenze esterne, essi differiscono in modo significativo nell'approccio e nelle capacità.
Database vettoriali
I database vettoriali si concentrano principalmente sull'archiviazione e l'interrogazione di incorporamenti vettoriali. Per utilizzarli con un LLM per RAG, in genere è necessario:
- Gestione manuale della generazione dell'incorporamento: sei responsabile della generazione degli incorporamenti vettoriali per i tuoi dati di origine utilizzando un modello di incorporamento.
- Logica di recupero degli handle: è necessario implementare la logica per interrogare il database vettoriale, recuperare gli embedding pertinenti e quindi mapparli nuovamente al testo sorgente originale.
- Integrazione con LLM: il testo recuperato deve quindi essere esplicitamente trasmesso all'LLM come parte del prompt.
- Nessuna integrazione LLM integrata: sono indipendenti dall'LLM e richiedono l'integrazione manuale per i flussi di lavoro RAG.
Motore RAG di Vertex AI
Il motore RAG di Vertex AI offre una soluzione più integrata e semplificata, eliminando gran parte della complessità. Le differenze principali includono:
- Gestione integrata delle conoscenze: gestisce l'intero ciclo di vita della tua base di conoscenze, dall'acquisizione dei file sorgente grezzi all'indicizzazione e alla gestione del corpus. Non è necessario generare manualmente gli embedding o gestire l'archiviazione dei vettori.
- Recupero automatico: il motore esegue automaticamente il recupero delle informazioni rilevanti dal proprio corpus in base alla richiesta dell'utente.
- Integrazione LLM senza soluzione di continuità: è progettato per funzionare direttamente con gli LLM di Vertex AI, gestendo la contestualizzazione del prompt con le informazioni recuperate prima di trasmetterlo all'LLM.
- Soluzione end-to-end: fornisce una soluzione più completa per RAG, semplificando lo sviluppo e l'implementazione di applicazioni basate su RAG.
In sostanza, un database vettoriale tradizionale è un componente che richiede una notevole orchestrazione per implementare il RAG. Al contrario, Vertex AI RAG Engine è un servizio gestito più completo che semplifica l'intero flusso di lavoro RAG fornendo gestione integrata delle conoscenze, recupero e integrazione LLM.
Questo vantaggio fondamentale consente una significativa semplificazione della pipeline di elaborazione RAG, spesso complessa. Snellendo questo processo, possiamo ottenere una maggiore efficienza, ridurre i potenziali punti di errore e, in ultima analisi, fornire risultati più accurati e pertinenti quando si utilizzano modelli linguistici di grandi dimensioni (LLM) per attività che richiedono conoscenze esterne. Questa semplificazione non solo migliora le prestazioni, ma aumenta anche la gestibilità e la scalabilità complessive dei sistemi basati su RAG, rendendoli più accessibili ed efficaci per una gamma più ampia di applicazioni.
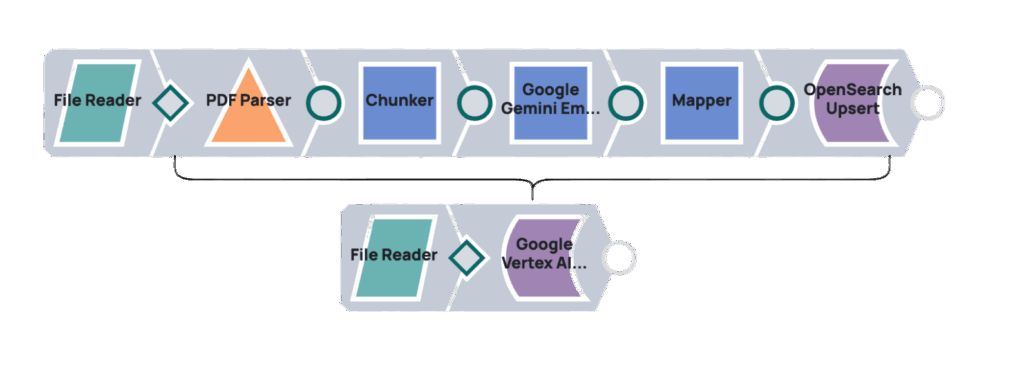
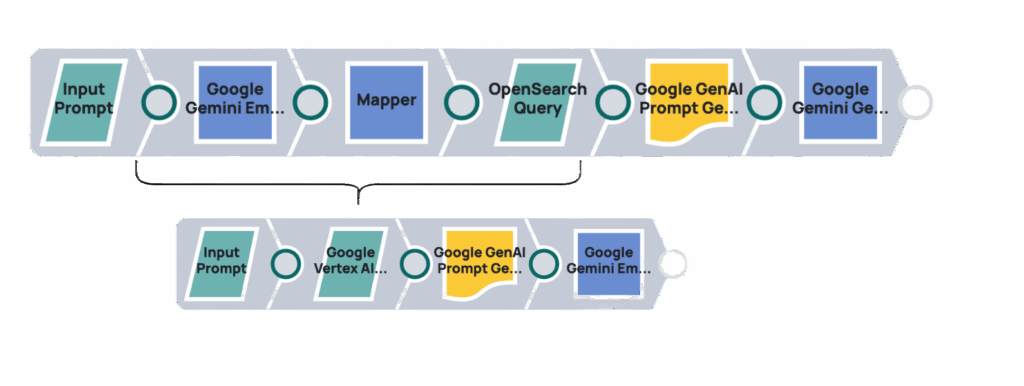
L'utilizzo del motore RAG di Vertex AI con l'IA generativa (anziché direttamente tramite l'API Gemini) offre diversi vantaggi. Migliora il recupero delle informazioni relative alle query attraverso strumenti integrati, semplificando l'accesso ai dati per i modelli di IA generativa. Questa integrazione nativa all'interno di Vertex AI ottimizza il flusso di informazioni, riduce la complessità e porta a un sistema più robusto per la generazione potenziata dal recupero.
Motore RAG Vertex AI in SnapLogic
SnapLogic ora include una serie di Snap per l'utilizzo del motore RAG di Vertex AI.
Gestione del corpus
I seguenti Snap sono disponibili per la gestione dei corpora RAG:
- Google Vertex AI RAG Crea corpus
- Corpus dell'elenco RAG di Google Vertex AI
- Google Vertex AI RAG Ottieni corpus
- Google Vertex AI RAG Elimina corpus




Gestione dei file in Corpus
I seguenti Snap consentono la gestione dei file all'interno di un corpus RAG:
- Google Vertex AI RAG Corpus Aggiungi file
- File elenco corpus RAG di Google Vertex AI
- Google Vertex AI RAG Corpus Ottieni file
- Google Vertex AI RAG Corpus Rimuovi file




Recupero
Per eseguire operazioni di recupero, utilizzare il seguente Snap:
- Google Vertex AI RAG Query di recupero

Prova a utilizzare Vertex AI RAG
Vediamo un esempio pratico di come sfruttare il motore RAG di Vertex AI all'interno di SnapLogic. Questa sezione ti guiderà nella configurazione di un corpus, nell'aggiunta di file, nell'esecuzione di query di recupero e nell'integrazione dei risultati nelle tue applicazioni LLM.
Preparazione
Prima dell'integrazione, sono necessari due passaggi fondamentali: in primo luogo, configurare un Cloud Google Cloud con API abilitate, fatturazione collegata e autorizzazioni necessarie.
Elenco delle API Google abilitate richieste
- https://console.cloud.google.com/apis/library/cloudresourcemanager.googleapis.com
- https://console.cloud.google.com/apis/library/aiplatform.googleapis.com
SnapLogic offre due metodi principali per connettersi alle Cloud di Google Cloud :
- Account di servizio (consigliato): SnapLogic può utilizzare un account di servizio esistente che disponga delle autorizzazioni necessarie.
- OAuth2: questo metodo richiede la configurazione di OAuth2.
Token di accesso: un token di accesso è una credenziale di sicurezza temporanea che consente di accedere Cloud di Google Cloud . Richiede l'aggiornamento manuale del token alla scadenza.
Creare il corpus
Per creare il corpus, utilizza Google Vertex AI RAG Create Corpus Snap.
- Posiziona Google Vertex AI RAG Create Corpus Snap.
- Crea un account di servizio Google GenAI
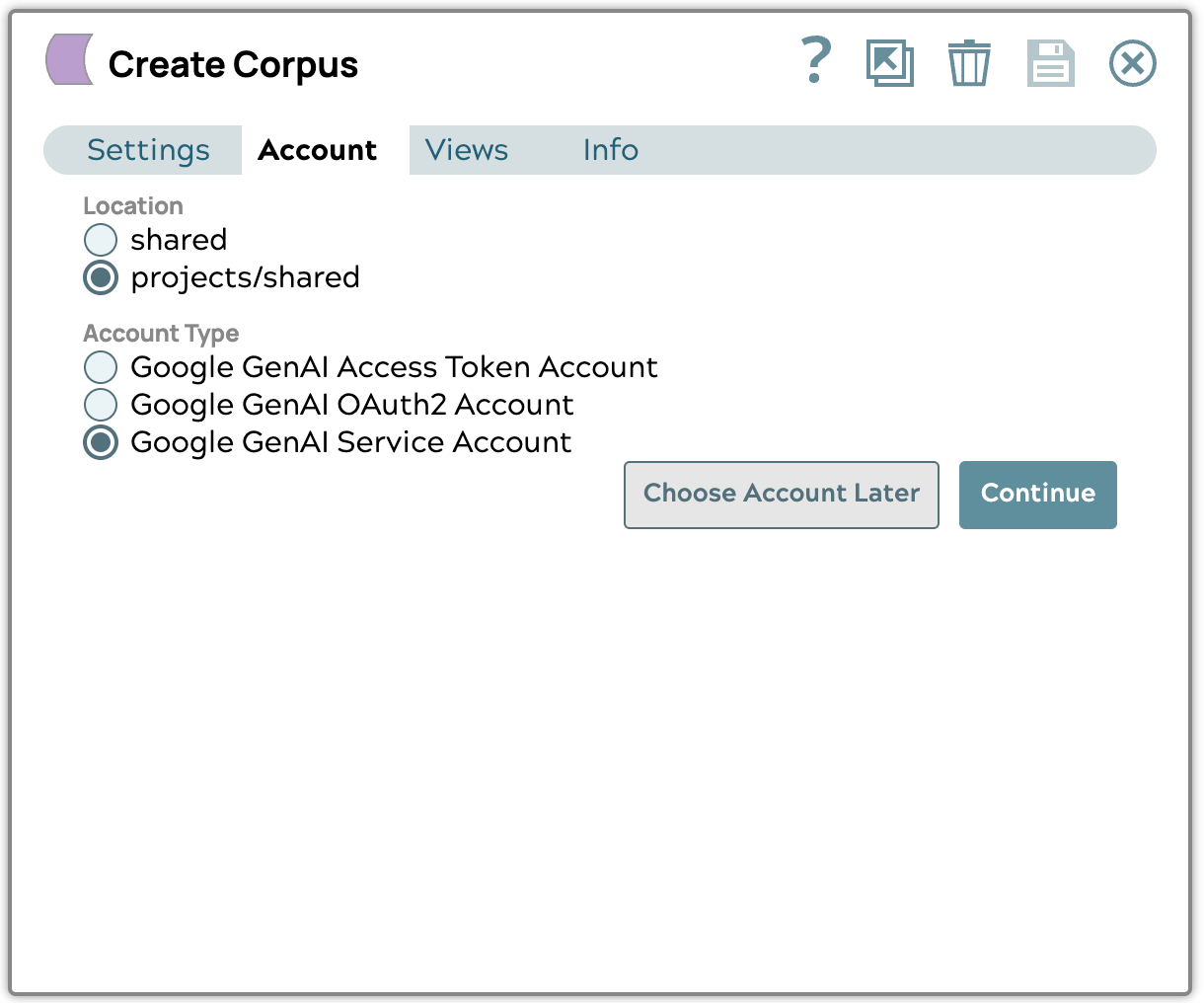
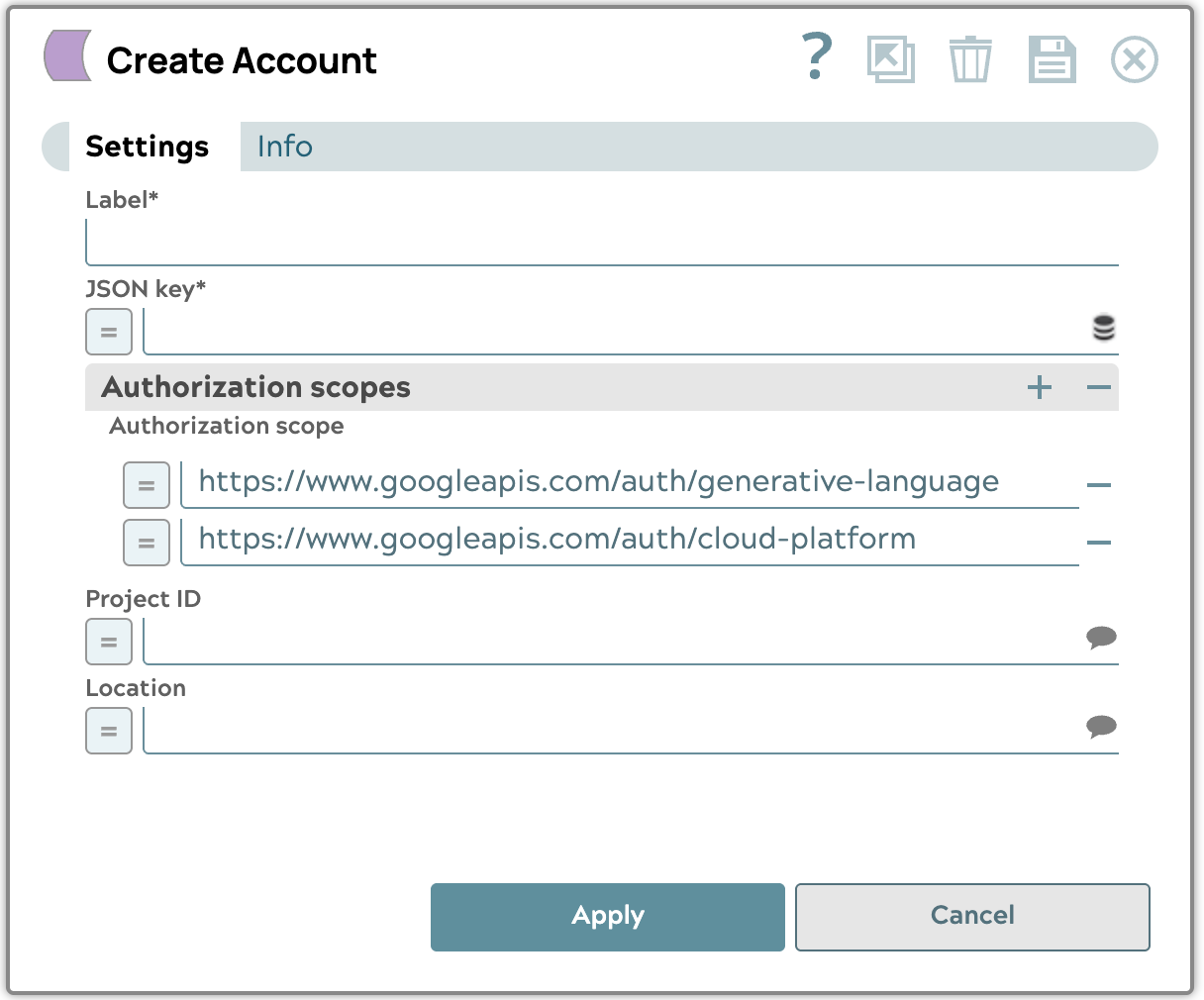
Carica il file della chiave JSON dell'account di servizio ottenuto da Google Cloud , quindi seleziona il progetto e la posizione delle risorse che desideri utilizzare. Ti consigliamo di utilizzare la posizione "us-central1".
- Modifica la configurazione impostando il nome visualizzato e l'esecuzione Snap su "Convalida ed esegui".
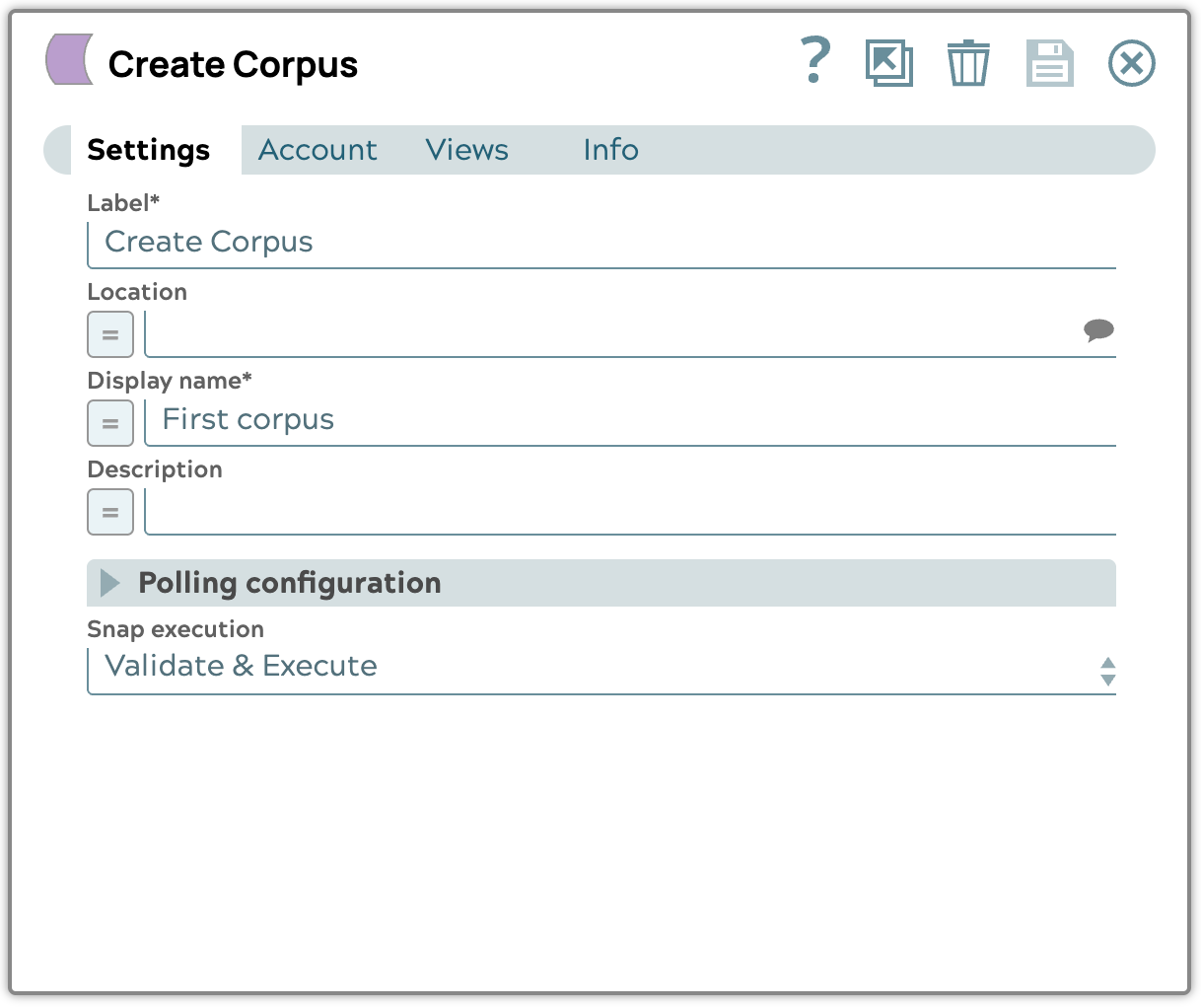
- Convalida la pipeline per ottenere il risultato del corpus nell'output.
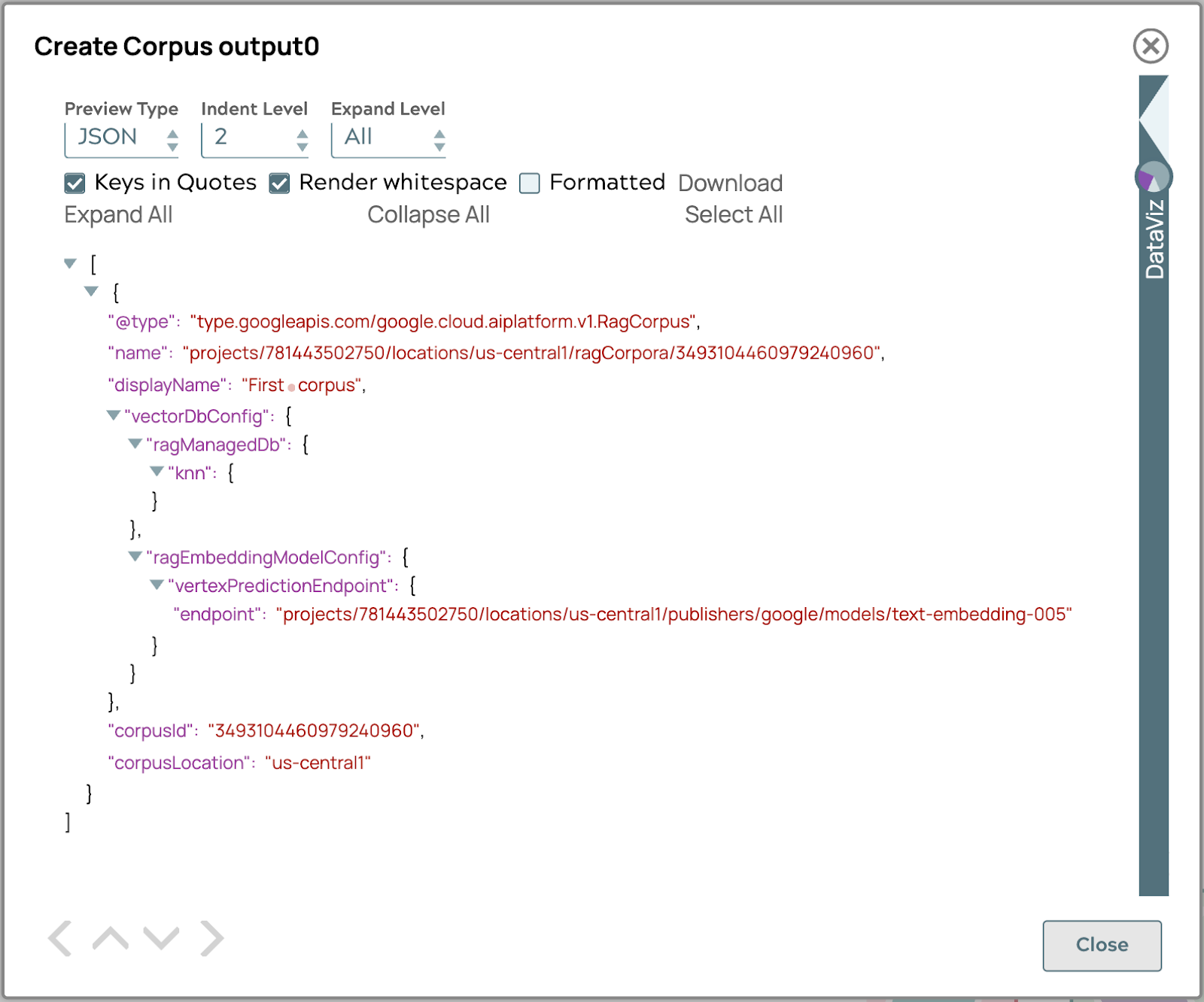
Se il risultato è simile all'immagine sopra, ora hai il corpus pronto per aggiungere il documento.
Carica il documento
Per caricare documenti per Google Vertex AI RAG, integra SnapLogic utilizzando una pipeline che collega gli Snap "Google Vertex AI RAG Corpus Add File" e "File Reader". Il "File Reader" accede al documento, trasmettendone il contenuto allo Snap "Google Vertex AI RAG Corpus Add File", che lo carica in un corpus Vertex AI RAG specificato.
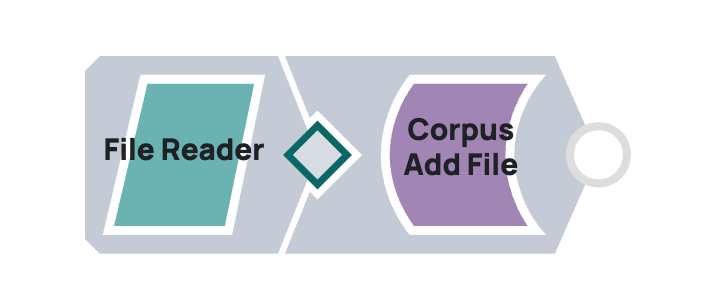
Esempio
- Scarica il documento di esempio. File di esempio: Nozioni di base su SnapLogic.pdf
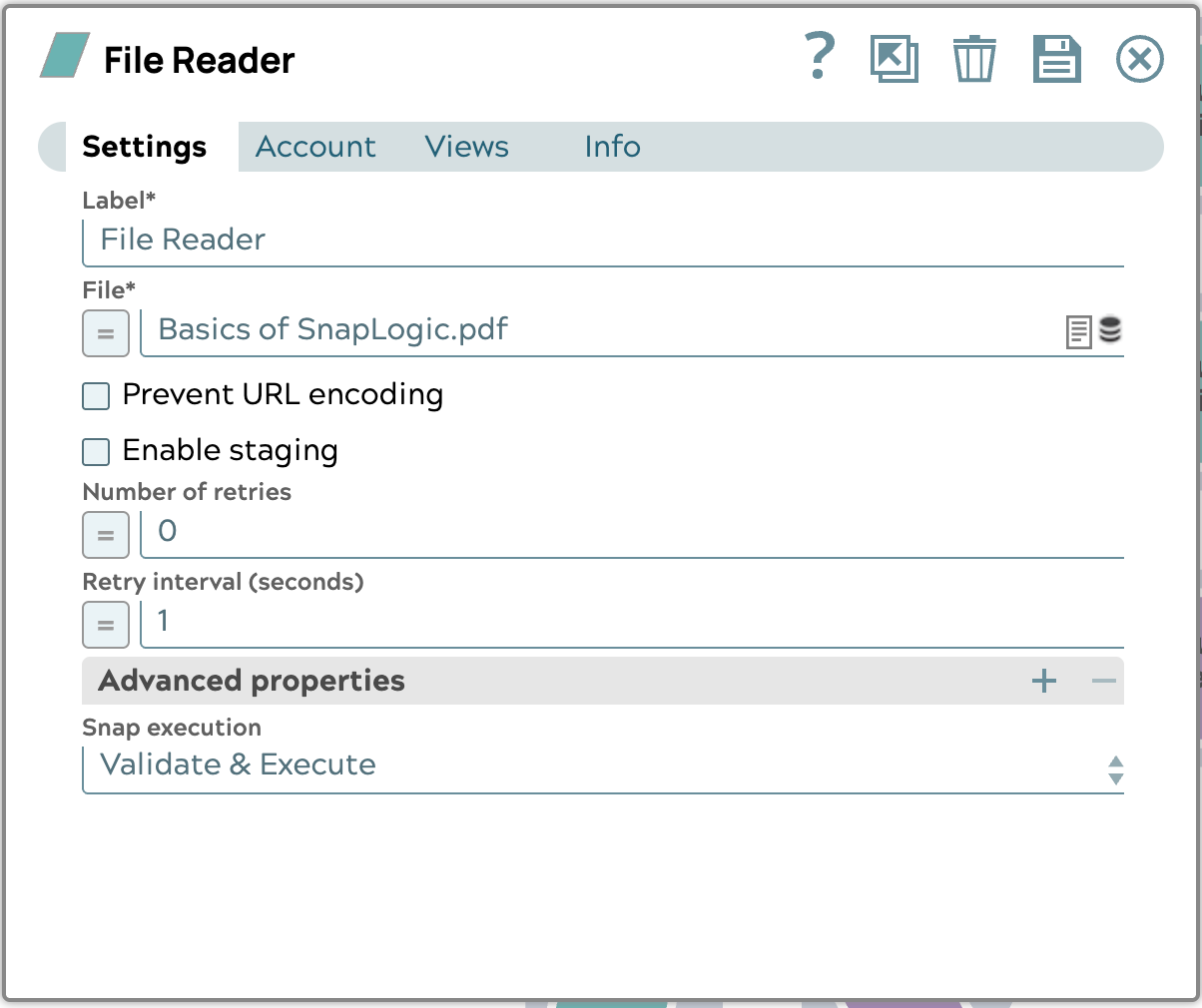
- Configurare lo Snap File Reader come segue:
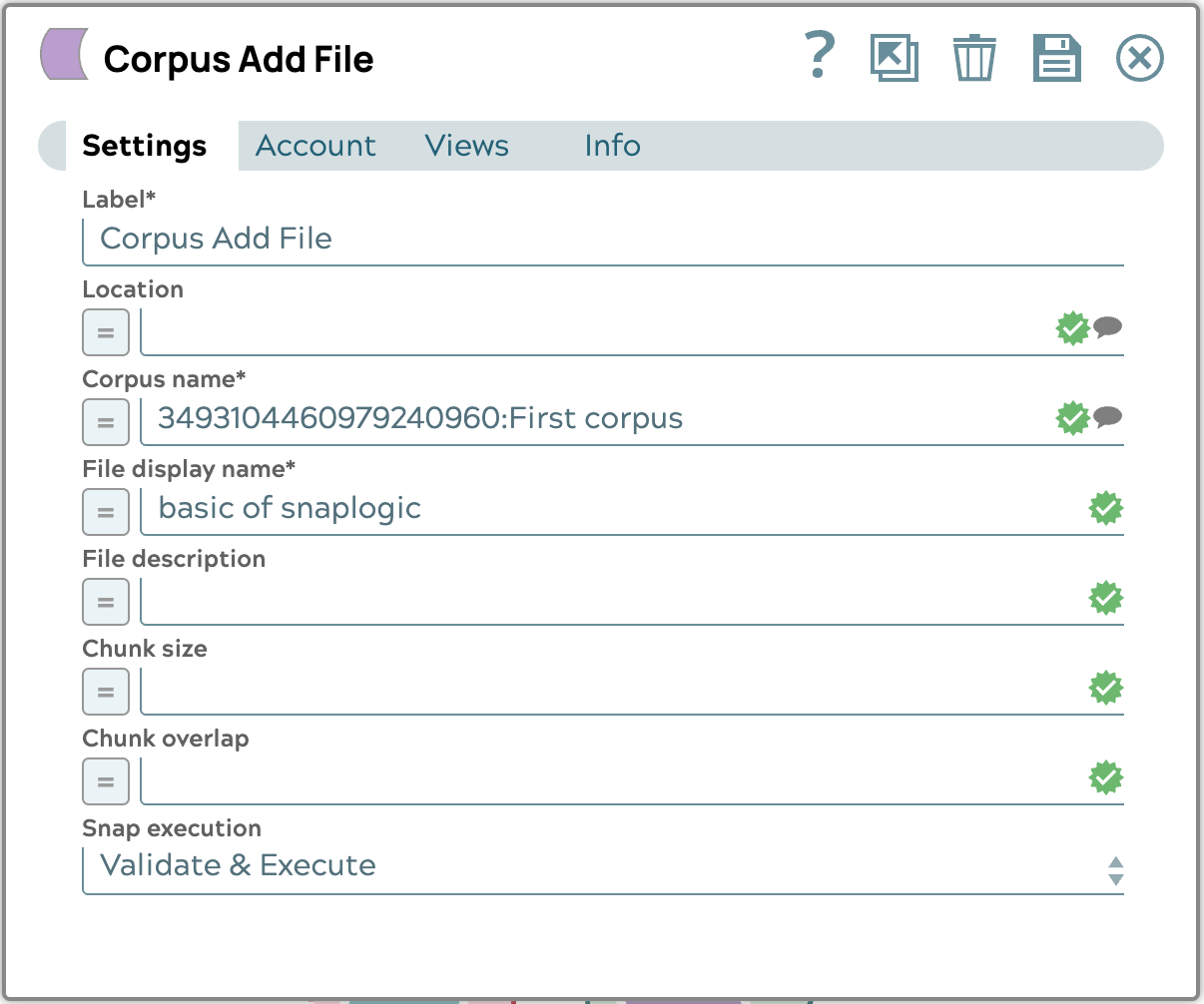
- Configurare Corpus Add File Snap come segue:
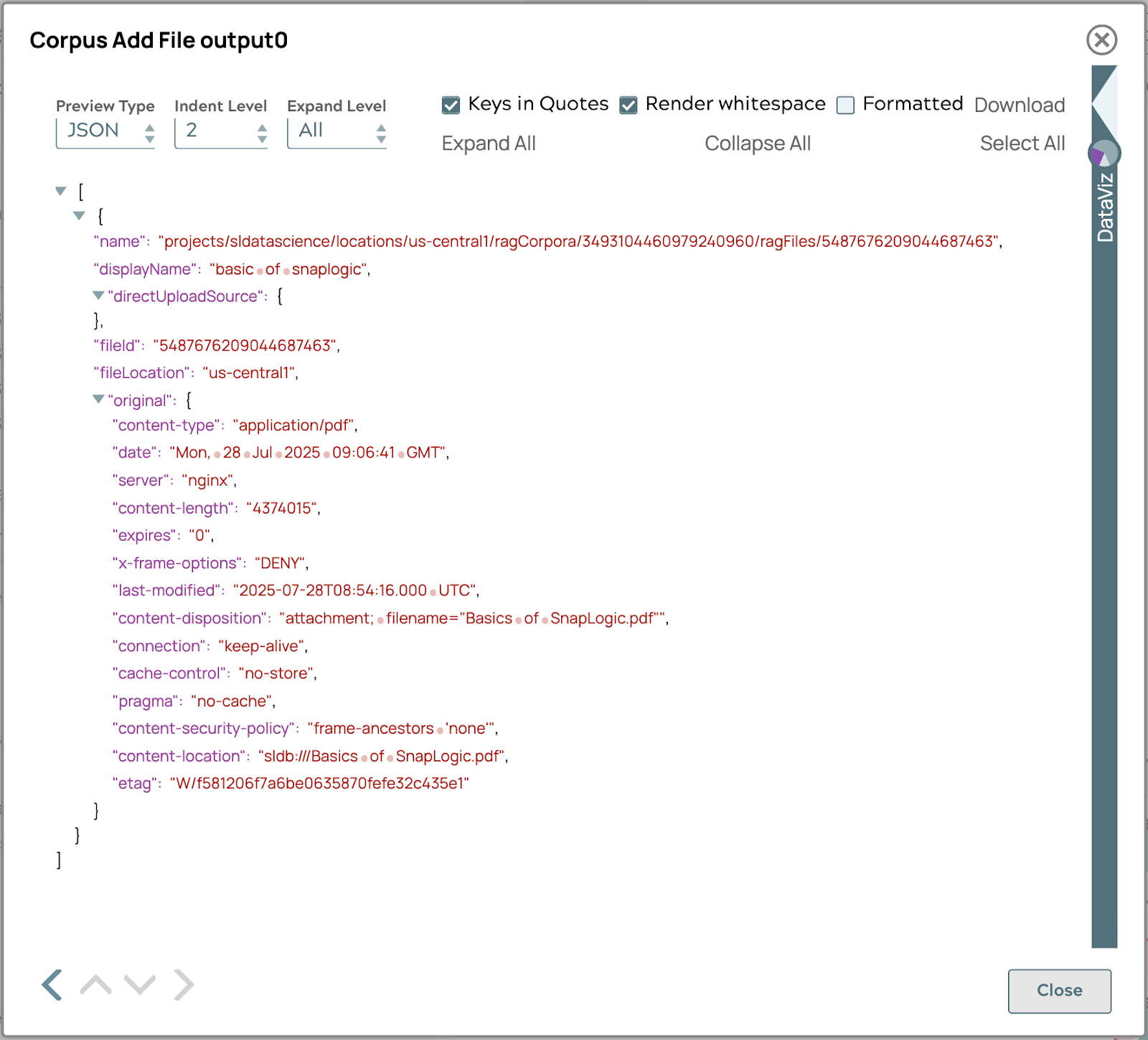
Questi passaggi aggiungeranno il file Basics of SnapLogic.pdf al corpus nella sezione precedente. Se la pipeline viene eseguita correttamente, l'output apparirà come segue.
Recupera query
Questa sezione illustra come utilizzare Google Vertex AI RAG Retrieval Query Snap per recuperare informazioni rilevanti dal corpus. Questo snap prende una query dell'utente e restituisce i documenti o gli snippet di testo più pertinenti.

Esempio
Dal corpus esistente, interrogheremo la domanda "Quali tipi di snap ha SnapLogic?" e configureremo lo snap di conseguenza.
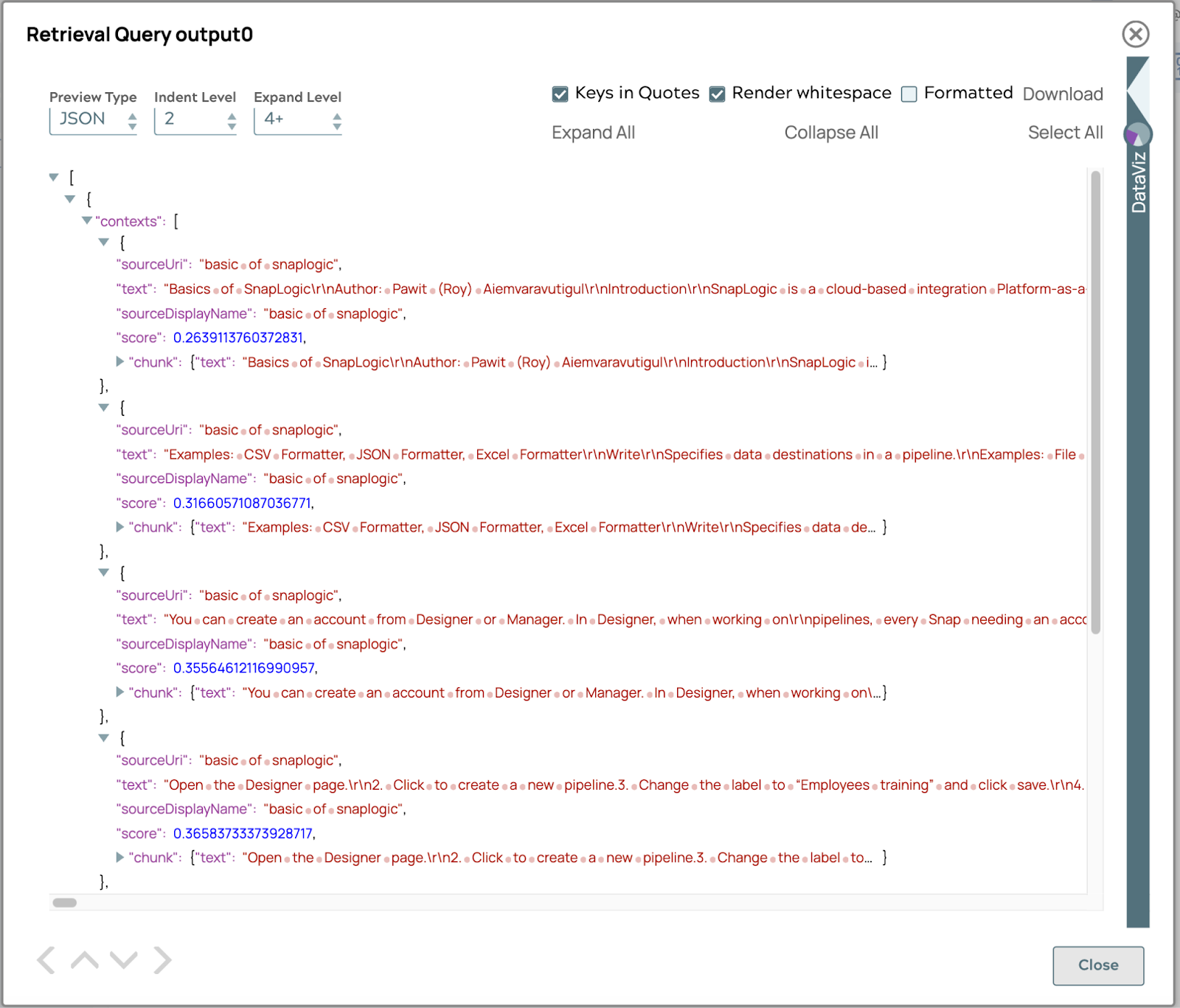
Il risultato visualizzerà un elenco di frammenti di testo correlati alla domanda, ordinati in base al valore del punteggio. Il valore del punteggio viene calcolato in base alla somiglianza o alla distanza tra la query e ciascun frammento di testo. La somiglianza o la distanza dipendono dal vectorDB scelto. Per impostazione predefinita, il punteggio è COSINE_DISTANCE.
Genera il risultato
Ora che abbiamo recuperato con successo le informazioni rilevanti dal nostro corpus, il passo successivo fondamentale è sfruttare il contesto recuperato per generare una risposta coerente e accurata utilizzando un LLM. Questa sezione mostrerà come integrare i risultati ottenuti da Google Vertex AI RAG Retrieval Query Snap con un modello di IA generativa, come Google Gemini Generate Snap, per produrre una risposta finale basata sulle informazioni potenziate.

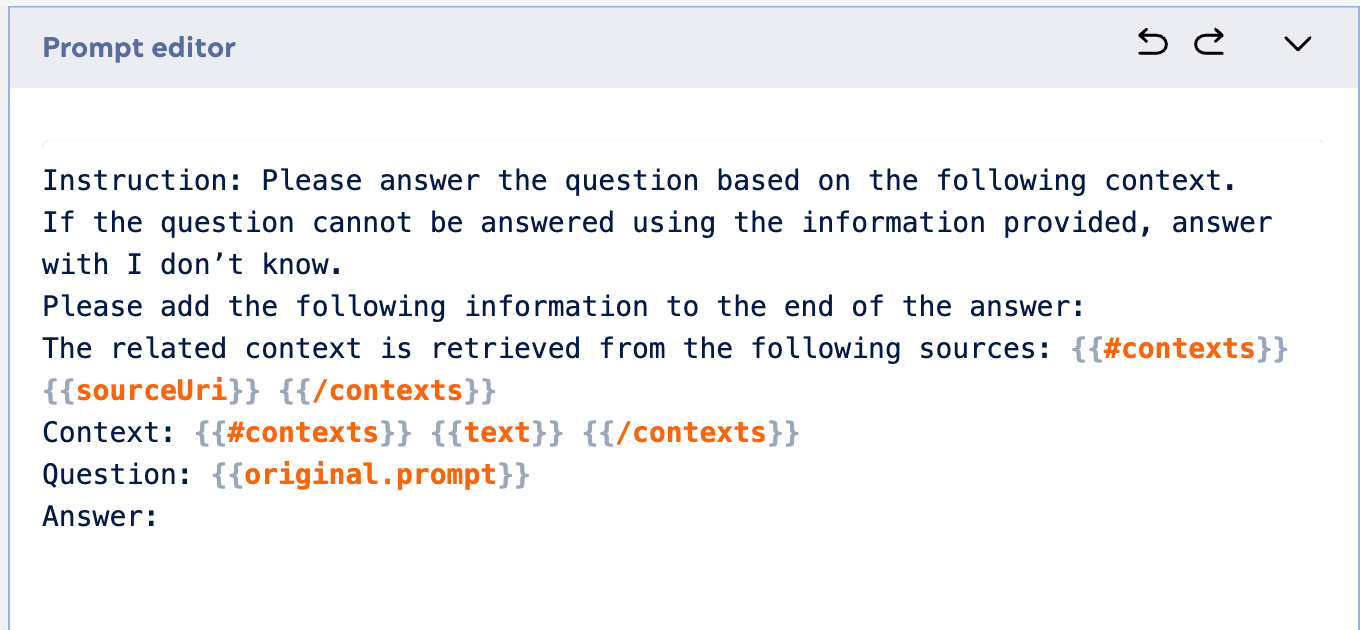
Ecco un esempio di prompt da utilizzare nel generatore di prompt:
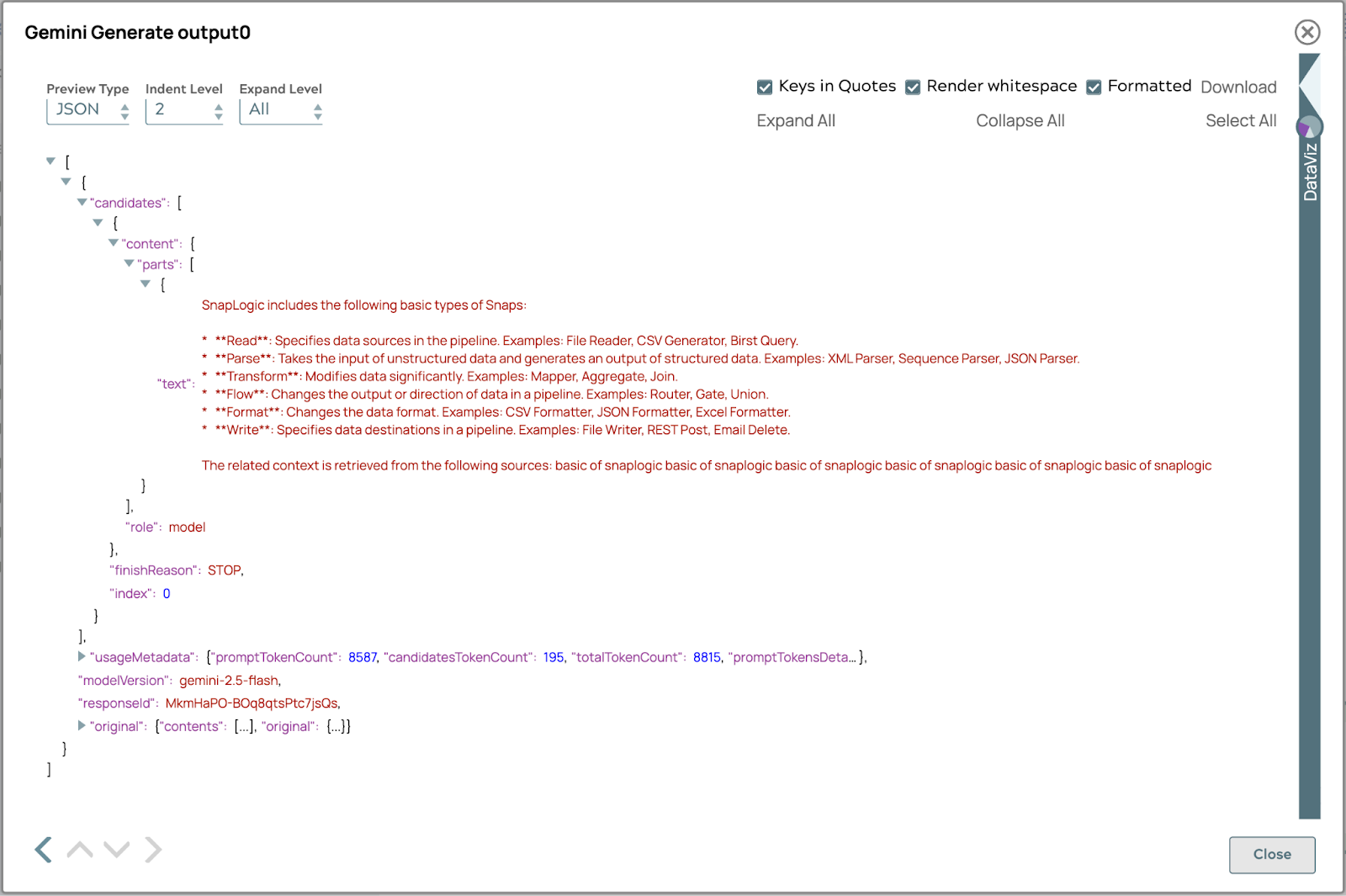
La risposta finale apparirà come segue:
Inoltre, l'integrazione tra Vertex AI RAG e SnapLogic offre il vantaggio significativo della compatibilità tra modelli. Ciò significa che i flussi di lavoro RAG consolidati e i processi di recupero dei dati possono essere adattati e utilizzati senza soluzione di continuità con diversi modelli linguistici di grandi dimensioni oltre a Vertex AI, come i modelli open source o altri LLM commerciali. Questa flessibilità consente alle organizzazioni di sfruttare il proprio investimento nell'infrastruttura RAG in un ecosistema diversificato di modelli di IA, garantendo una maggiore adattabilità, applicazioni a prova di futuro e la possibilità di scegliere l'LLM più adatto per compiti specifici senza dover ricostruire l'intera pipeline di recupero delle informazioni. Questo vantaggio cross-model garantisce che la soluzione RAG rimanga versatile e preziosa, indipendentemente dall'evoluzione del panorama LLM.
Richiesta di recupero automatico con lo strumento integrato Vertex AI
L'utilizzo dello strumento integrato in Vertex AI Gemini Generate Snap per il recupero automatico semplifica notevolmente la pipeline RAG. Invece di eseguire manualmente una query di recupero e quindi passare i risultati a una fase di generazione separata, questo approccio integrato consente al modello Gemini di consultare automaticamente il corpus RAG configurato in base al prompt di input. Ciò riduce il numero di passaggi e la complessità della pipeline, poiché i processi di recupero e generazione vengono gestiti in modo trasparente all'interno di un unico Snap. In questo modo si garantisce che l'LLM abbia sempre accesso alle informazioni contestuali più rilevanti dalla vostra base di conoscenza senza richiedere un'orchestrazione esplicita, consentendo una generazione di contenuti più efficiente e accurata.

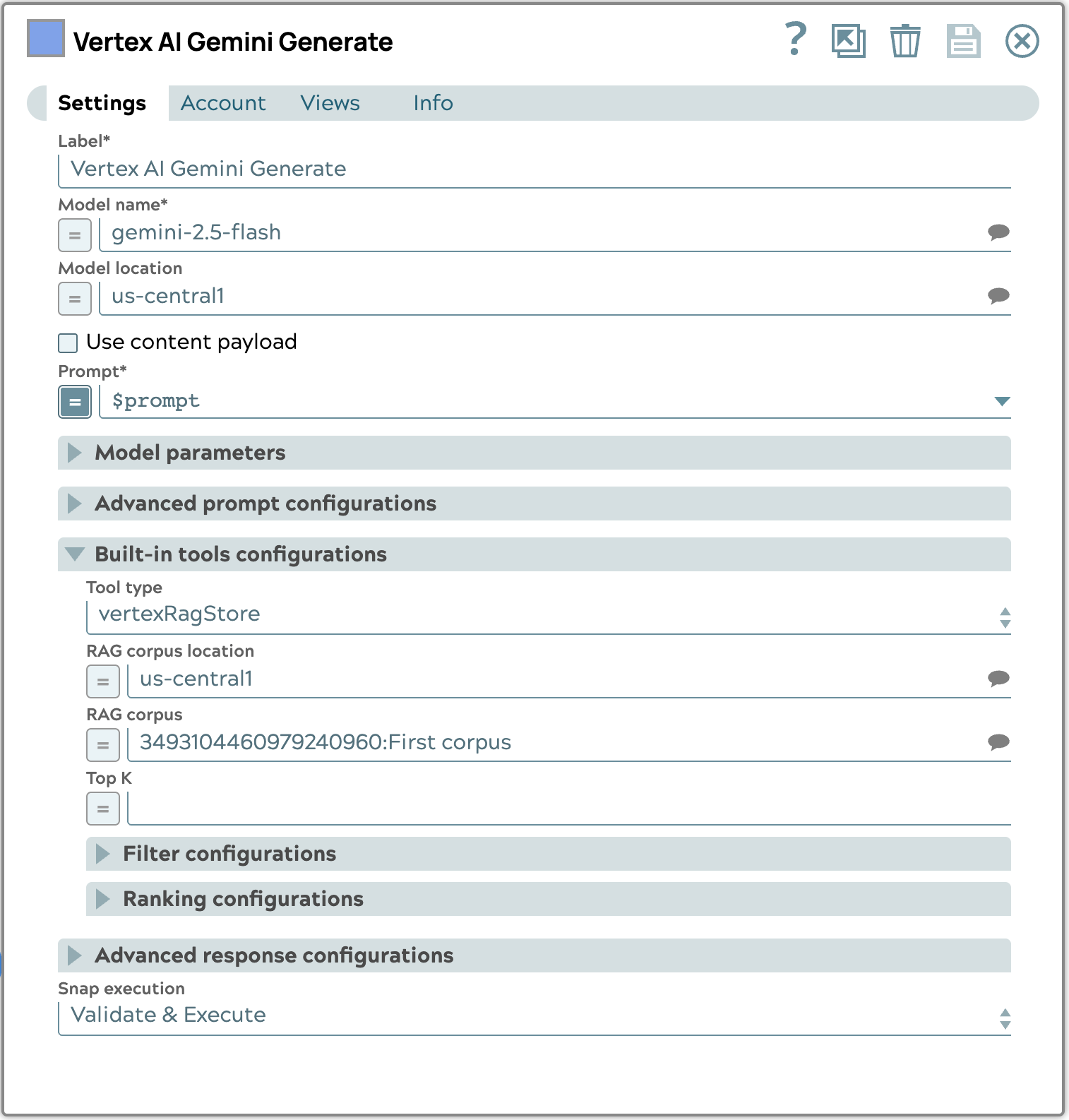
L'esempio di configurazione rapida riportato di seguito mostra come configurare la sezione Strumenti integrati. Nello specifico, selezioniamo il tipo vertexRagStore e designiamo il corpus di destinazione.
La risposta finale generata utilizzando il processo di recupero automatico verrà visualizzata di seguito.
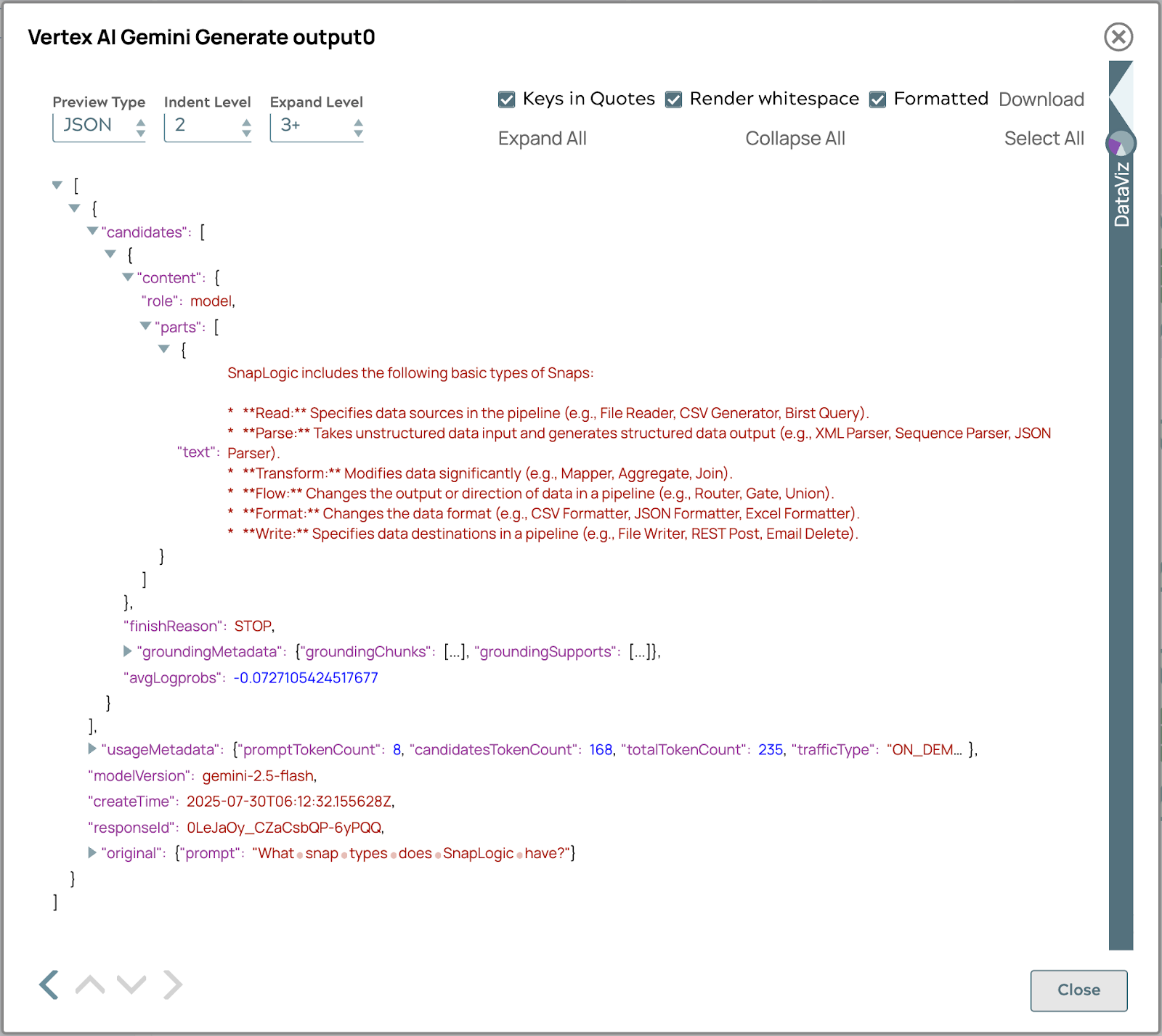
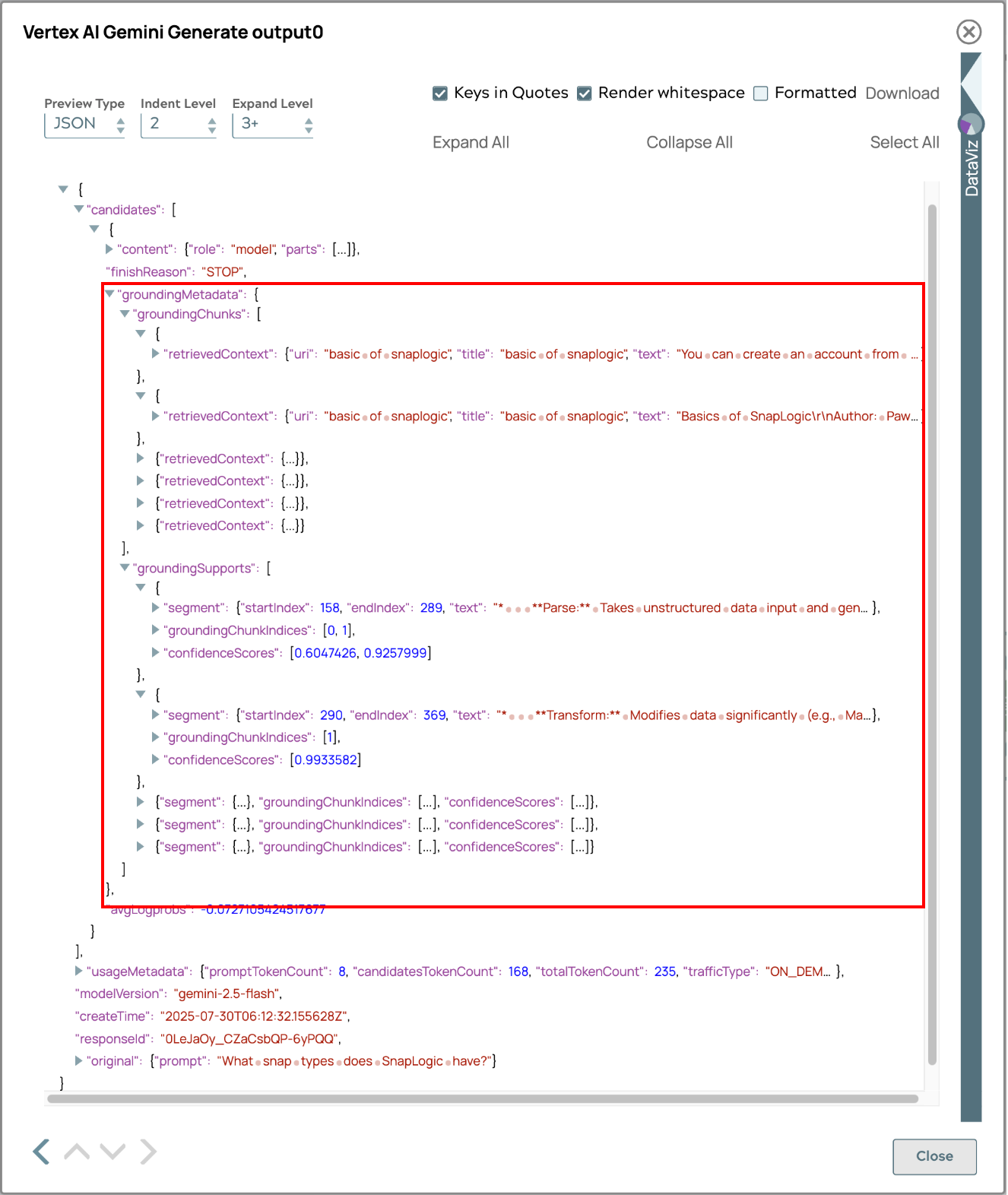
La risposta include metadati di base per il tracciamento delle fonti, consentendo agli utenti di risalire all'origine delle informazioni. Questa funzione migliora la trasparenza, la verifica dei fatti e rafforza la fiducia nell'accuratezza e nell'affidabilità dei contenuti. Gli utenti possono approfondire il materiale di riferimento, incrociare i fatti e acquisire una comprensione completa, aumentando l'utilità e l'affidabilità del sistema.
Sintesi
Questo documento illustra come integrare le funzionalità Vertex AI Retrieval Augmented Generation (RAG) CloudGoogle Cloudcon SnapLogic per migliorare i flussi di lavoro LLM. I punti chiave includono:
- Processo RAG semplificato: Vertex AI RAG semplifica la gestione e il recupero delle conoscenze, eliminando complessità quali la generazione manuale di embedding e la logica di recupero, tipicamente richieste dai database vettoriali tradizionali.
- Soluzione integrata: a differenza dei database vettoriali autonomi, Vertex AI RAG offre una soluzione end-to-end per RAG, gestendo tutto, dall'acquisizione dei file grezzi all'integrazione con gli LLM.
- Integrazione SnapLogic: SnapLogic fornisce Snap dedicati per la gestione dei corpora Vertex AI RAG (creazione, elenco, recupero, eliminazione), la gestione dei file all'interno dei corpora (aggiunta, elenco, recupero, rimozione) e l'esecuzione di query di recupero.
- Applicazione pratica: la guida ha fornito un esempio dettagliato di come impostare un corpus, caricare documenti, eseguire query di recupero utilizzando Google Vertex AI RAG Retrieval Query Snap e integrare i risultati con modelli di IA generativa come Google Gemini Generate Snap per ottenere risposte contestualmente accurate.
- Compatibilità tra modelli: un vantaggio significativo di questa integrazione è la possibilità di adattare i flussi di lavoro RAG consolidati e i processi di recupero dei dati con vari LLM oltre a Vertex AI, inclusi modelli open source e altri modelli commerciali, garantendo flessibilità e adeguatezza alle esigenze future.
- Recupero automatico con strumenti integrati: l'integrazione consente il recupero automatico tramite strumenti integrati in Vertex AI Gemini Generate Snap, semplificando la pipeline RAG grazie alla gestione del recupero e della generazione in un unico passaggio.
Sfruttando Vertex AI RAG con SnapLogic, le organizzazioni possono semplificare lo sviluppo e l'implementazione di applicazioni basate su RAG, ottenendo risposte LLM più accurate, contestualmente pertinenti ed efficienti.





