






Dieses Dokument befasst sich mit der Integration der Vertex AI Retrieval Augmented Generation (RAG)-Funktionen von Google Cloud in SnapLogic. Wir werden uns eingehend mit der Funktionsweise von Vertex AI RAG, seinen Vorteilen gegenüber herkömmlichen Vektordatenbanken und praktischen Anwendungen innerhalb der SnapLogic-Plattform befassen. Der Leitfaden behandelt die Einrichtung und Nutzung von Vertex AI RAG, die Automatisierung von Wissensfeeds und die Integration mit SnapLogic Generate Snaps für eine verbesserte LLM-Leistung.
Vertex AI RAG-Engine
Die Vertex AI RAG Engine optimiert den Prozess der Retrieval-Augmented Generation (RAG) durch zwei grundlegende Schritte:
- Wissensmanagement: Die Vertex AI RAG Engine erstellt und pflegt eine Wissensdatenbank, indem sie einen Korpus erstellt, der als Index für die Speicherung von Quelldateien dient.
- Abfrage: Nach Erhalt einer Eingabeaufforderung durchsucht die Vertex AI RAG Engine diese Wissensdatenbank effizient, um die für die Anfrage relevantesten Informationen zu identifizieren und abzurufen.
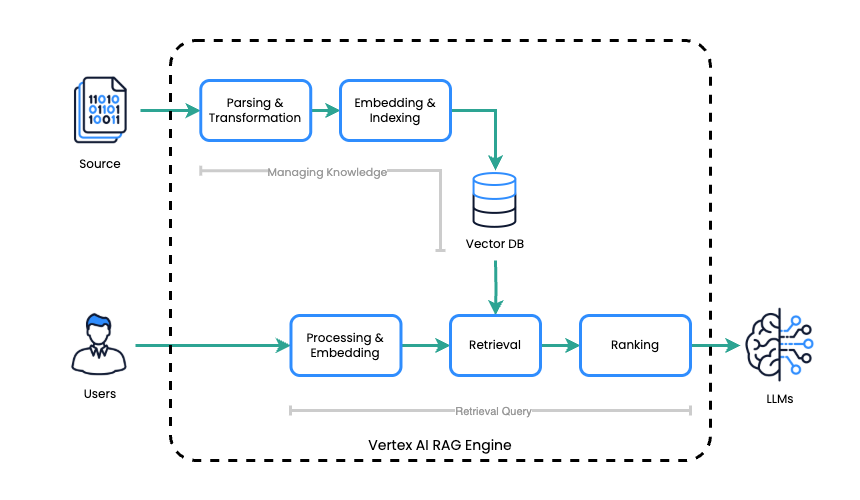
Die Vertex AI RAG Engine integriert Google Clouds Vertex AI mit der RAG-Architektur, um genaue und kontextbezogene LLM-Antworten zu generieren. Sie deckt Aufgaben im Zusammenhang mit der Wissensverwaltung ab, indem sie einen Korpus als Index für Quelldateien erstellt. Zur Verarbeitung ruft sie bei Erhalt einer Eingabeaufforderung effizient relevante Informationen aus dieser Wissensdatenbank ab und nutzt dann das LLM, um auf der Grundlage des abgerufenen Kontexts eine Antwort zu generieren.
Unterschied zwischen Vektordatenbank
Sowohl herkömmliche Vektordatenbanken als auch die Vertex AI RAG Engine wurden entwickelt, um die Antworten von LLM durch die Bereitstellung externen Wissens zu verbessern, unterscheiden sich jedoch erheblich in ihrem Ansatz und ihren Fähigkeiten.
Vektordatenbanken
Vektordatenbanken konzentrieren sich in erster Linie auf die Speicherung und Abfrage von Vektor-Einbettungen. Um sie mit einem LLM für RAG zu verwenden, müssen Sie in der Regel Folgendes tun:
- Manuelle Verwaltung der Einbettungsgenerierung: Sie sind dafür verantwortlich, Vektoreinbettungen für Ihre Quelldaten mithilfe eines Einbettungsmodells zu generieren.
- Logik zum Abrufen von Handles: Sie müssen die Logik zum Abfragen der Vektordatenbank, zum Abrufen relevanter Einbettungen und zum anschließenden Zurückverweisen auf den ursprünglichen Quelltext implementieren.
- Integration mit LLM: Der abgerufene Text muss dann explizit als Teil der Eingabeaufforderung an das LLM übergeben werden.
- Keine integrierte LLM-Integration: Sie sind unabhängig vom LLM und erfordern eine manuelle Integration für RAG-Workflows.
Vertex AI RAG-Engine
Die Vertex AI RAG Engine bietet eine stärker integrierte und optimierte Lösung, die einen Großteil der Komplexität abstrahiert. Zu den wichtigsten Unterschieden gehören:
- Integriertes Wissensmanagement: Es verwaltet den gesamten Lebenszyklus Ihrer Wissensdatenbank, von der Erfassung der Rohdateien bis zur Indizierung und Verwaltung des Korpus. Sie müssen keine Einbettungen manuell generieren oder den Vektorspeicher verwalten.
- Automatisierte Suche: Die Suchmaschine führt automatisch die Suche nach relevanten Informationen aus ihrem Korpus auf Grundlage der Eingabe des Benutzers durch.
- Nahtlose LLM-Integration: Das System ist so konzipiert, dass es direkt mit den LLMs von Vertex AI zusammenarbeitet und die Kontextualisierung der Eingabeaufforderung mit den abgerufenen Informationen übernimmt, bevor es diese an das LLM weiterleitet.
- End-to-End-Lösung: Sie bietet eine umfassendere Lösung für RAG und vereinfacht die Entwicklung und Bereitstellung von RAG-basierten Anwendungen.
Im Wesentlichen ist eine herkömmliche Vektordatenbank eine Komponente, deren Implementierung für RAG einen erheblichen Koordinationsaufwand erfordert. Im Gegensatz dazu ist die Vertex AI RAG Engine ein umfassenderer Managed Service, der den gesamten RAG-Workflow durch integriertes Wissensmanagement, Wissensabruf und LLM-Integration vereinfacht.
Dieser grundlegende Vorteil ermöglicht eine erhebliche Vereinfachung der oft komplexen RAG-Verarbeitungs-Pipeline. Durch die Rationalisierung dieses Prozesses können wir eine höhere Effizienz erzielen, potenzielle Fehlerquellen reduzieren und letztendlich genauere und relevantere Ergebnisse liefern, wenn wir große Sprachmodelle (LLMs) für Aufgaben einsetzen, die externes Wissen erfordern. Diese Vereinfachung verbessert nicht nur die Leistung, sondern auch die allgemeine Verwaltbarkeit und Skalierbarkeit von RAG-basierten Systemen, wodurch sie für ein breiteres Spektrum von Anwendungen zugänglicher und effektiver werden.
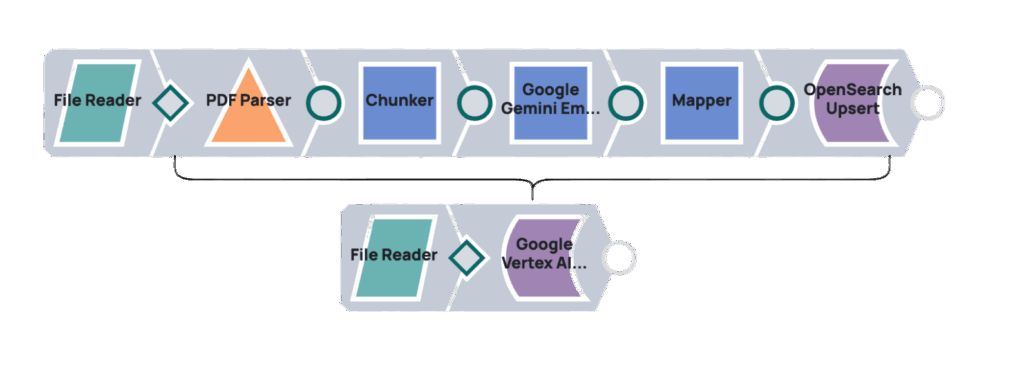
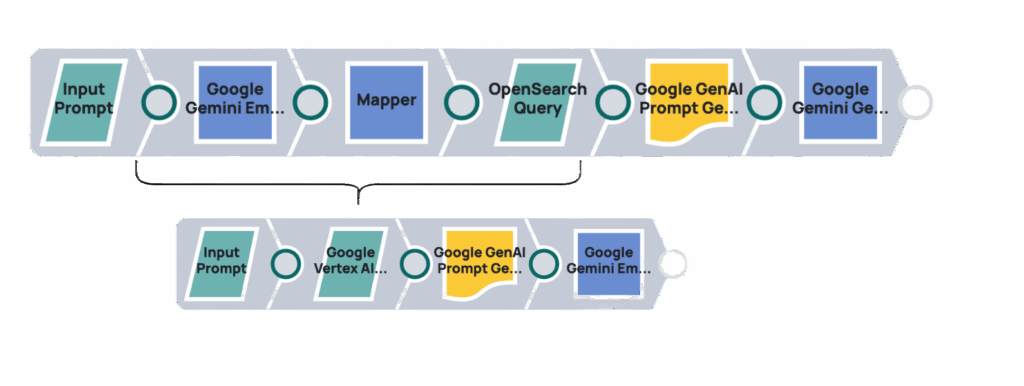
Die Verwendung der RAG-Engine von Vertex AI mit generativer KI (anstelle der direkten Nutzung über die Gemini-API) bietet Vorteile. Sie verbessert die abfragebasierte Informationsgewinnung durch integrierte Tools und optimiert den Datenzugriff für generative KI-Modelle. Diese native Integration in Vertex AI optimiert den Informationsfluss, reduziert die Komplexität und führt zu einem robusteren System für die abfragebasierte Generierung.
Vertex AI RAG Engine in SnapLogic
SnapLogic enthält jetzt eine Reihe von Snaps zur Nutzung der Vertex AI RAG Engine.
Korpusverwaltung
Die folgenden Snaps sind für die Verwaltung von RAG-Korpora verfügbar:
- Google Vertex AI RAG Korpus erstellen
- Google Vertex AI RAG-Listenkorpus
- Google Vertex AI RAG Korpus abrufen
- Google Vertex AI RAG Korpus löschen




Dateiverwaltung in Corpus
Die folgenden Snaps ermöglichen die Dateiverwaltung innerhalb eines RAG-Korpus:
- Google Vertex AI RAG-Korpus Datei hinzufügen
- Google Vertex AI RAG-Korpus-Listendatei
- Google Vertex AI RAG-Korpus Datei abrufen
- Google Vertex AI RAG-Korpus Datei entfernen




Wiederauffinden
Verwenden Sie für Suchvorgänge den folgenden Snap:
- Google Vertex AI RAG-Abfrage

Probieren Sie Vertex AI RAG aus.
Sehen wir uns ein praktisches Beispiel dafür an, wie Sie die Vertex AI RAG Engine in SnapLogic nutzen können. In diesem Abschnitt erfahren Sie, wie Sie einen Korpus einrichten, Dateien hinzufügen, Abfragen durchführen und die Ergebnisse in Ihre LLM-Anwendungen integrieren.
Vorbereitungsschritt
Vor der Integration sind zwei wichtige Schritte erforderlich: Richten Sie zunächst ein Google Cloud-Projekt mit aktivierten APIs, verknüpfter Abrechnung und den erforderlichen Berechtigungen ein.
Liste der erforderlichen aktivierten Google-APIs
- https://console.cloud.google.com/apis/library/cloudresourcemanager.googleapis.com
- https://console.cloud.google.com/apis/library/aiplatform.googleapis.com
SnapLogic bietet zwei primäre Methoden für die Verbindung mit Google Cloud-APIs:
- Dienstkonto (empfohlen): SnapLogic kann ein vorhandenes Dienstkonto verwenden, das über die erforderlichen Berechtigungen verfügt.
- OAuth2: Diese Methode erfordert die Konfiguration von OAuth2.
Zugriffstoken: Ein Zugriffstoken ist eine temporäre Sicherheitsanmeldeinformation für den Zugriff auf Google Cloud-APIs. Es muss manuell aktualisiert werden, wenn es abläuft.
Erstellen Sie den Korpus.
Um den Korpus zu erstellen, verwenden Sie den Google Vertex AI RAG Create Corpus Snap.
- Platzieren Sie den Google Vertex AI RAG Create Corpus Snap.
- Google GenAI-Dienstkonto erstellen
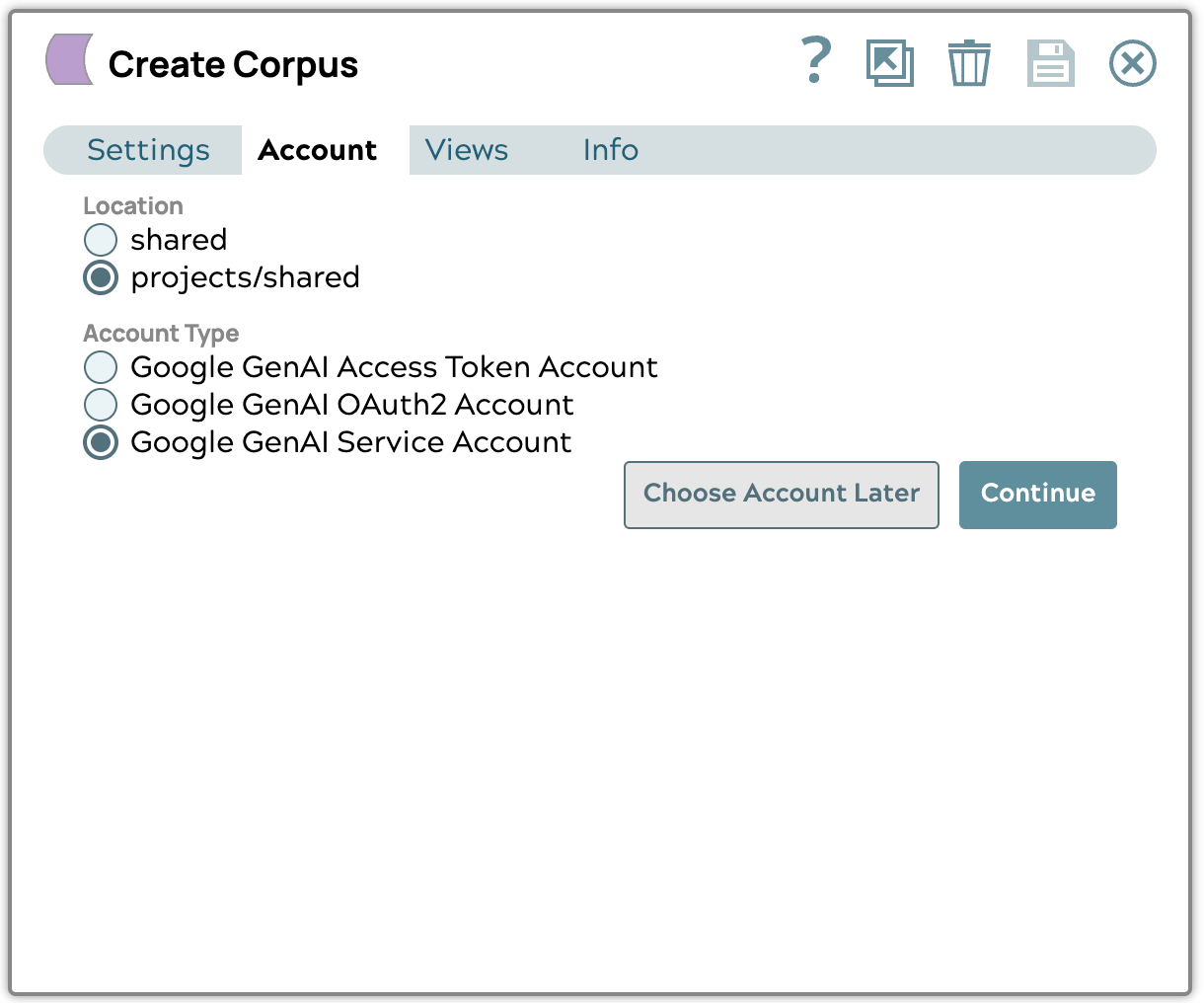
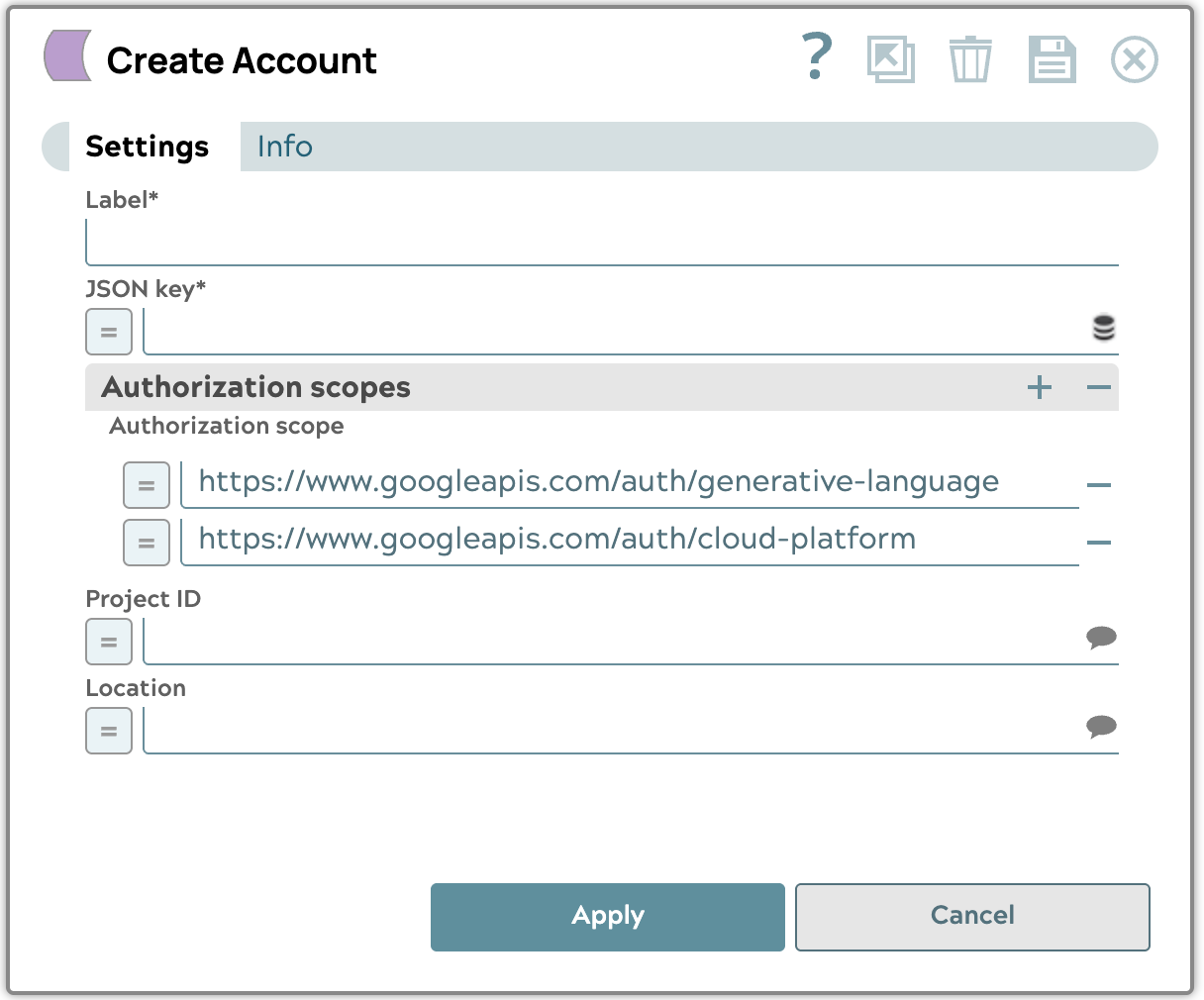
Laden Sie die JSON-Schlüsseldatei für das Dienstkonto hoch, die Sie von Google Cloud Platform erhalten haben, und wählen Sie dann das Projekt und den Speicherort der Ressource aus, die Sie verwenden möchten. Wir empfehlen die Verwendung des Speicherorts „us-central1“.
- Bearbeiten Sie die Konfiguration, indem Sie den Anzeigenamen und die Snap-Ausführung auf „Validieren und ausführen“ setzen.
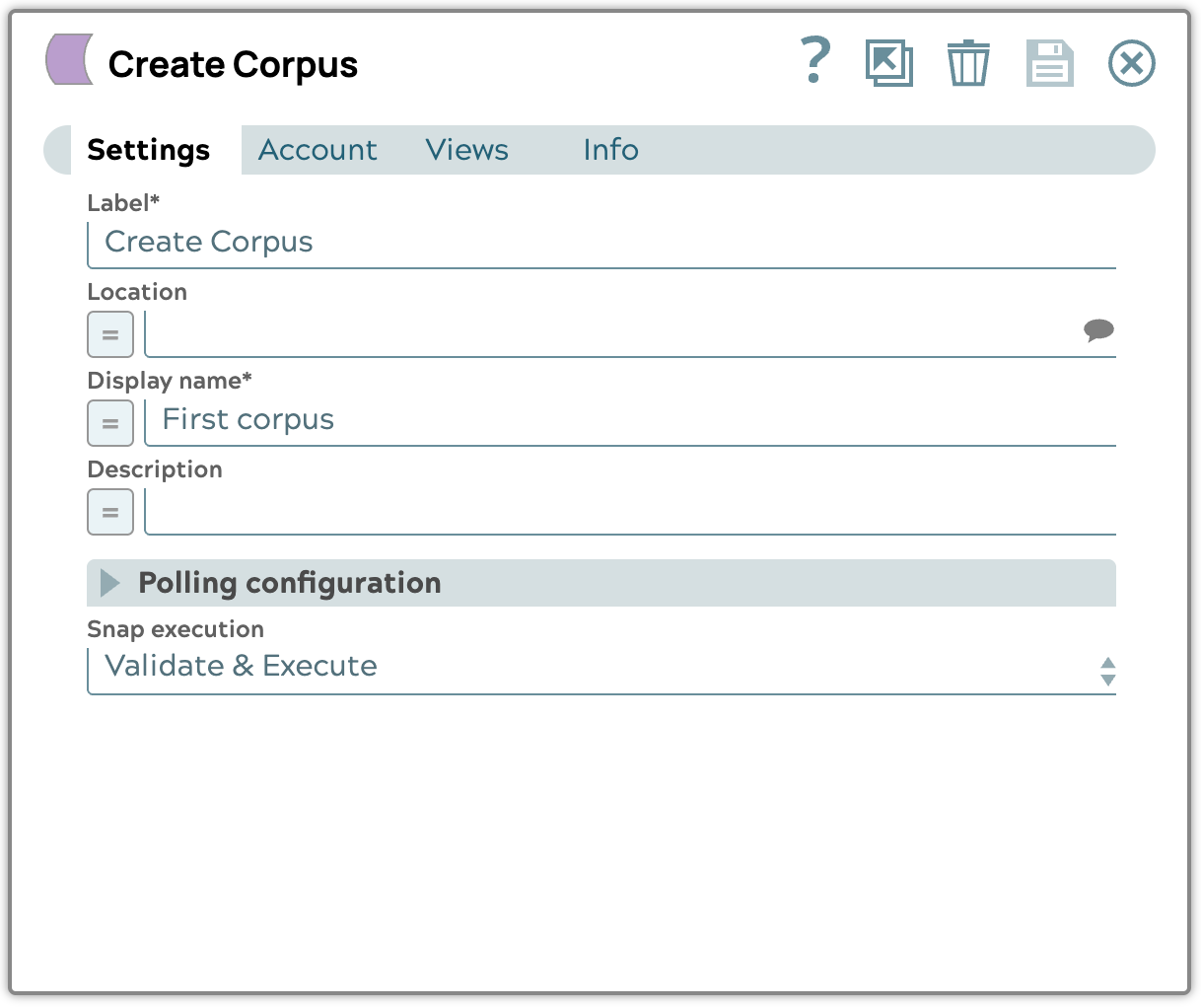
- Validieren Sie die Pipeline, um das Korpus-Ergebnis in der Ausgabe zu erhalten.
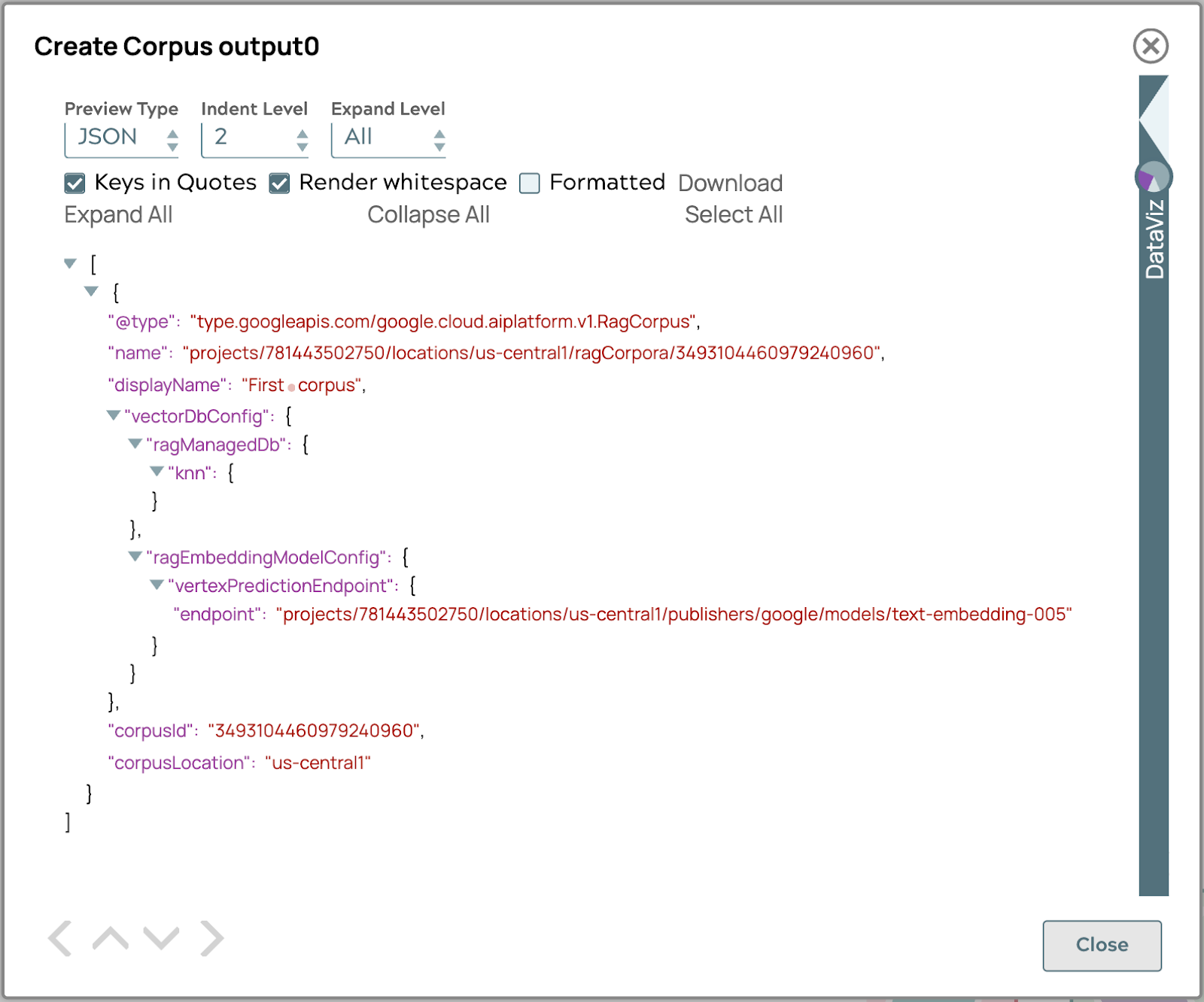
Wenn das Ergebnis dem obigen Bild ähnelt, ist der Korpus nun bereit, um das Dokument hinzuzufügen.
Laden Sie das Dokument hoch.
Um Dokumente für Google Vertex AI RAG hochzuladen, integrieren Sie SnapLogic mithilfe einer Pipeline, die die Snaps „Google Vertex AI RAG Corpus Add File“ und „File Reader“ miteinander verbindet. Der „File Reader“ greift auf das Dokument zu und übergibt dessen Inhalt an den Snap „Google Vertex AI RAG Corpus Add File“, der es in einen bestimmten Vertex AI RAG-Korpus hochlädt.
Beispiel
- Laden Sie das Beispieldokument herunter. Beispieldatei: Grundlagen von SnapLogic.pdf
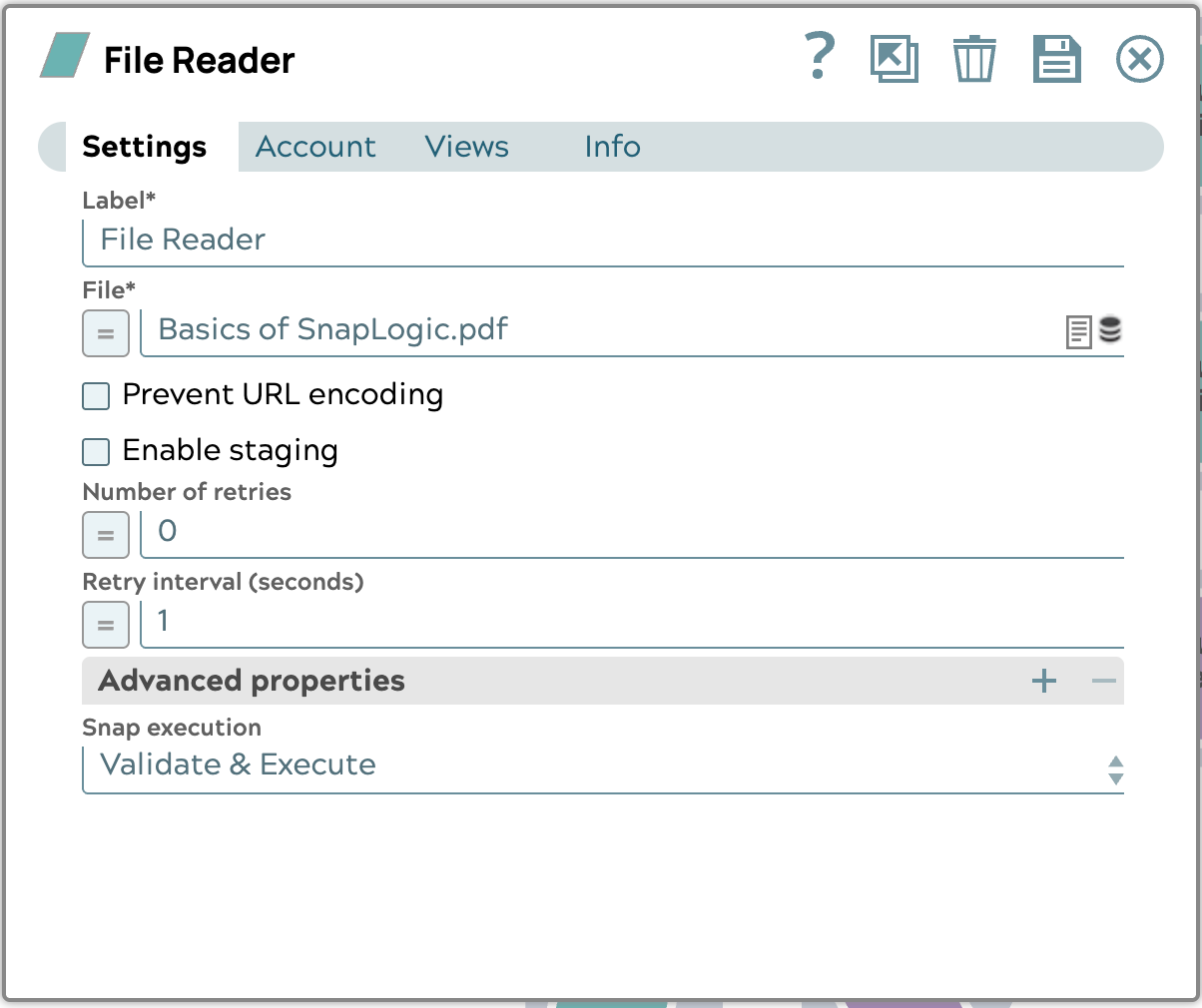
- Konfigurieren Sie den Dateileser-Snap wie folgt:
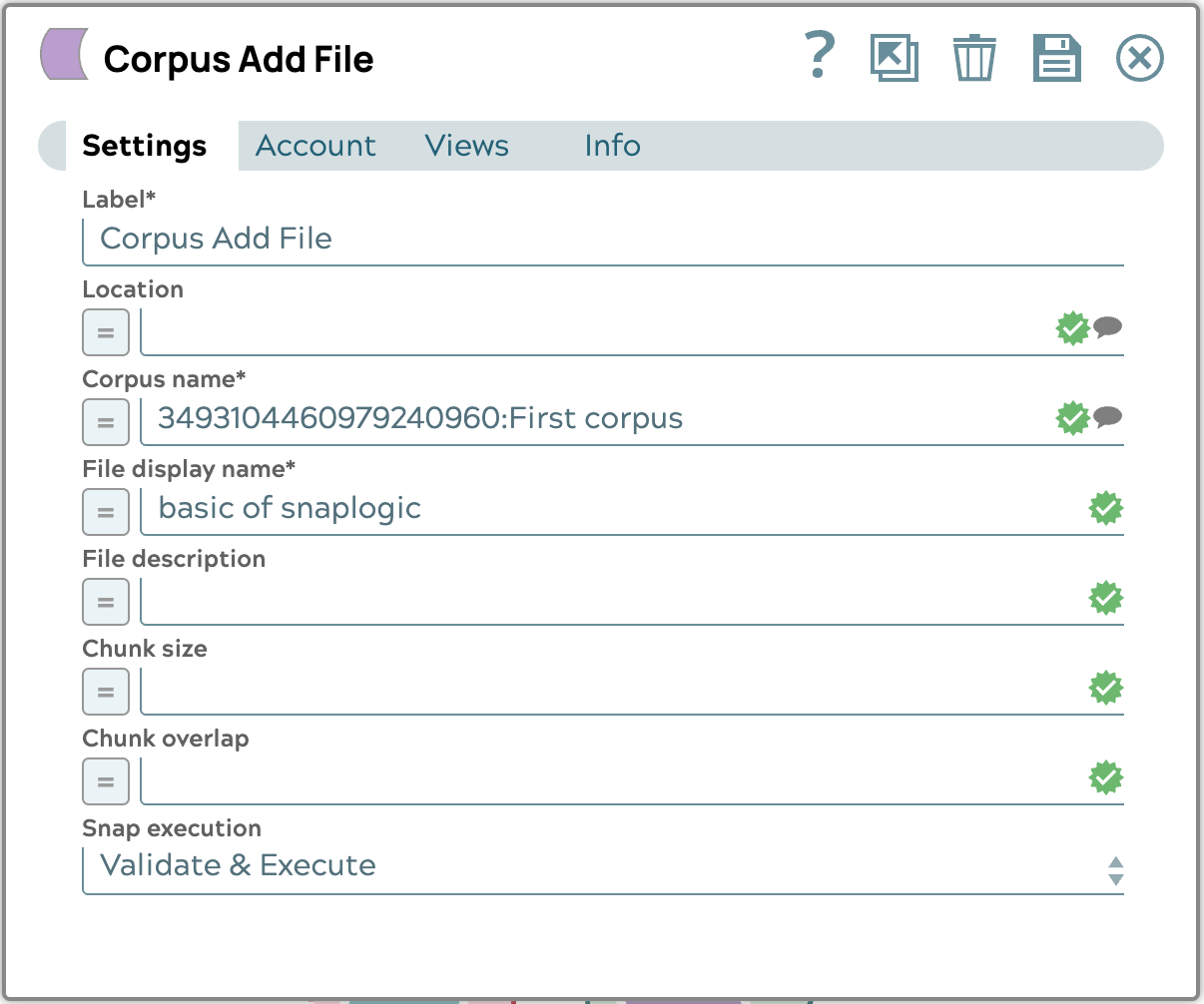
- Konfigurieren Sie den Corpus Add File Snap wie folgt:
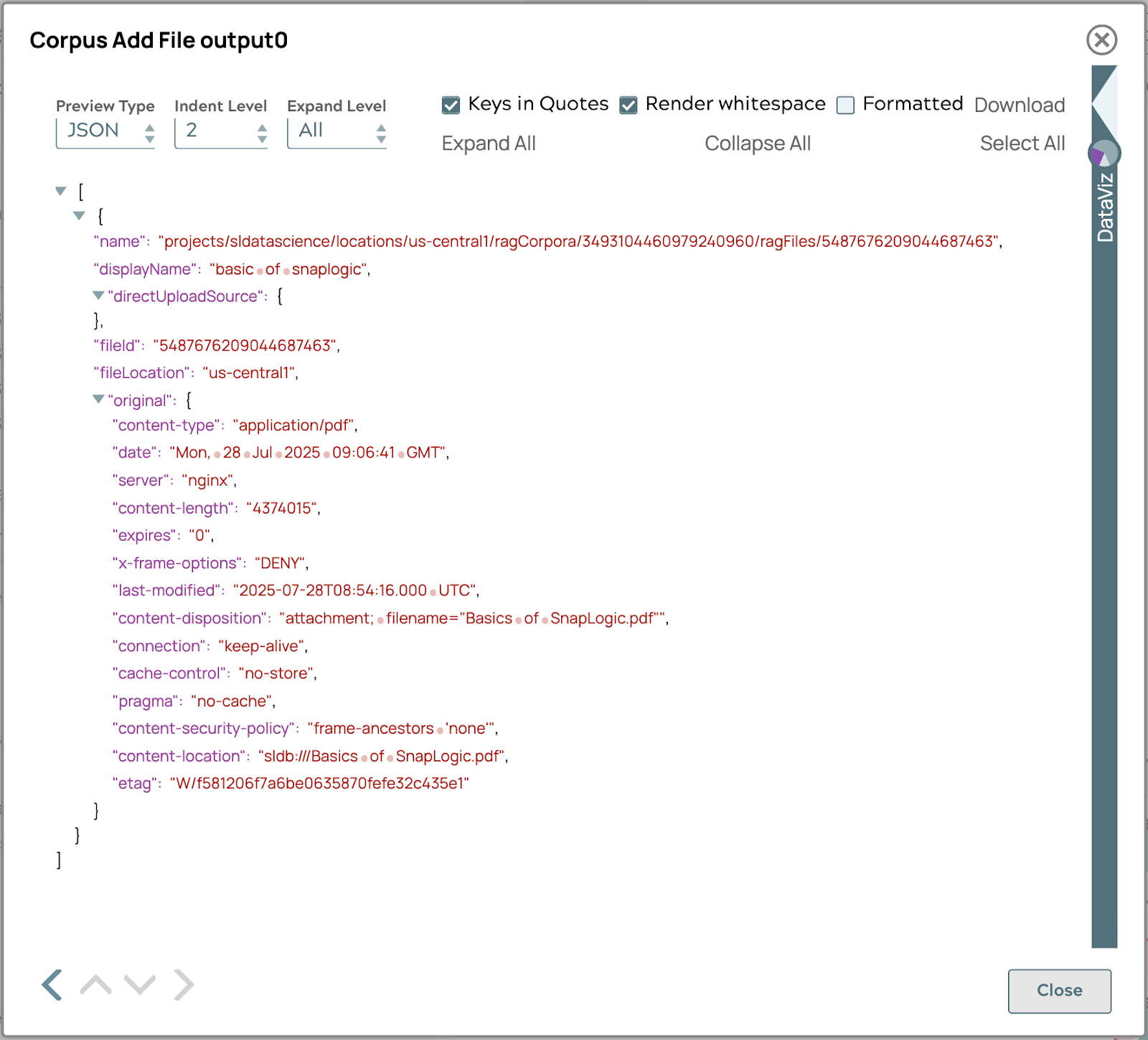
Mit diesen Schritten wird die Datei „Basics of SnapLogic.pdf“ zum Korpus im vorherigen Abschnitt hinzugefügt. Wenn Sie die Pipeline erfolgreich ausführen, wird die Ausgabe wie folgt angezeigt.
Abfrage abrufen
In diesem Abschnitt wird gezeigt, wie Sie mit dem Google Vertex AI RAG Retrieval Query Snap relevante Informationen aus dem Korpus abrufen können. Dieser Snap nimmt eine Benutzerabfrage entgegen und gibt die relevantesten Dokumente oder Textausschnitte zurück.

Beispiel
Aus dem vorhandenen Korpus werden wir die Frage „Welche Snap-Typen gibt es bei SnapLogic?“ abfragen und den Snap entsprechend konfigurieren.
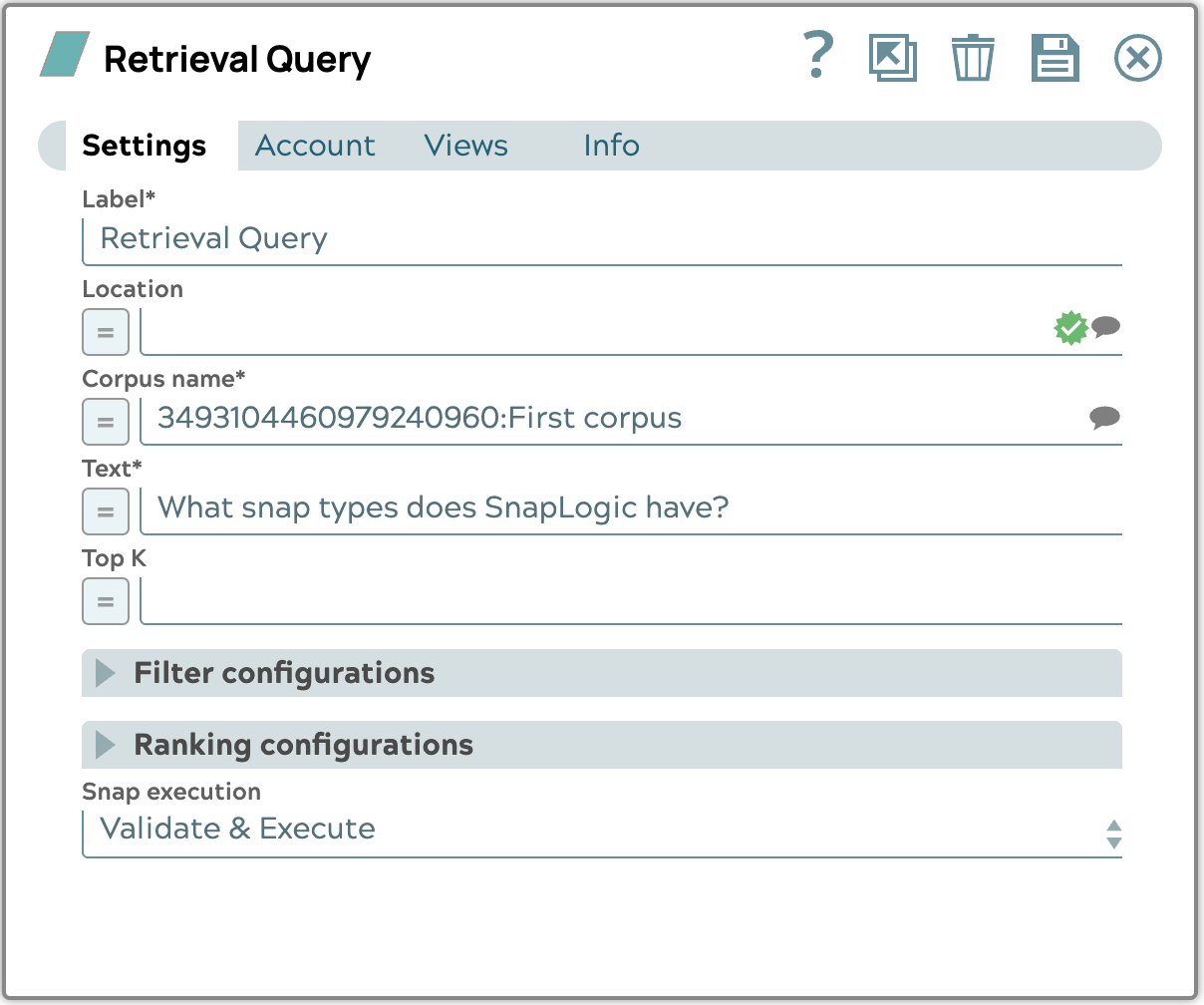
Das Ergebnis zeigt eine Liste von Textabschnitten an, die mit der Frage in Zusammenhang stehen, sortiert nach ihrem Punktwert. Der Punktwert wird anhand der Ähnlichkeit oder Distanz zwischen der Suchanfrage und jedem Textabschnitt berechnet. Die Ähnlichkeit oder Distanz hängt von der von Ihnen gewählten Vektor-Datenbank ab. Standardmäßig ist der Punktwert der COSINE_DISTANCE.
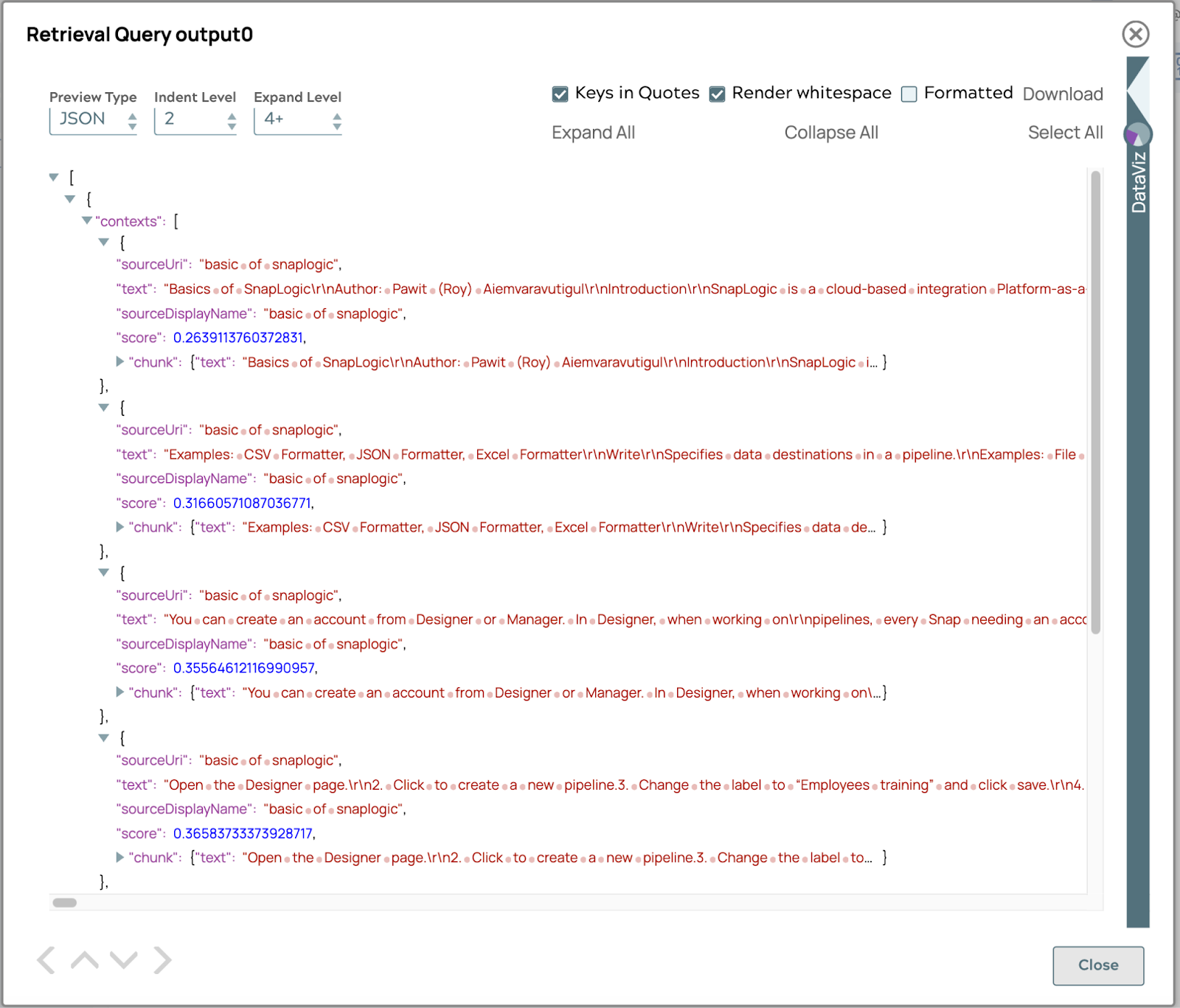
Ergebnis generieren
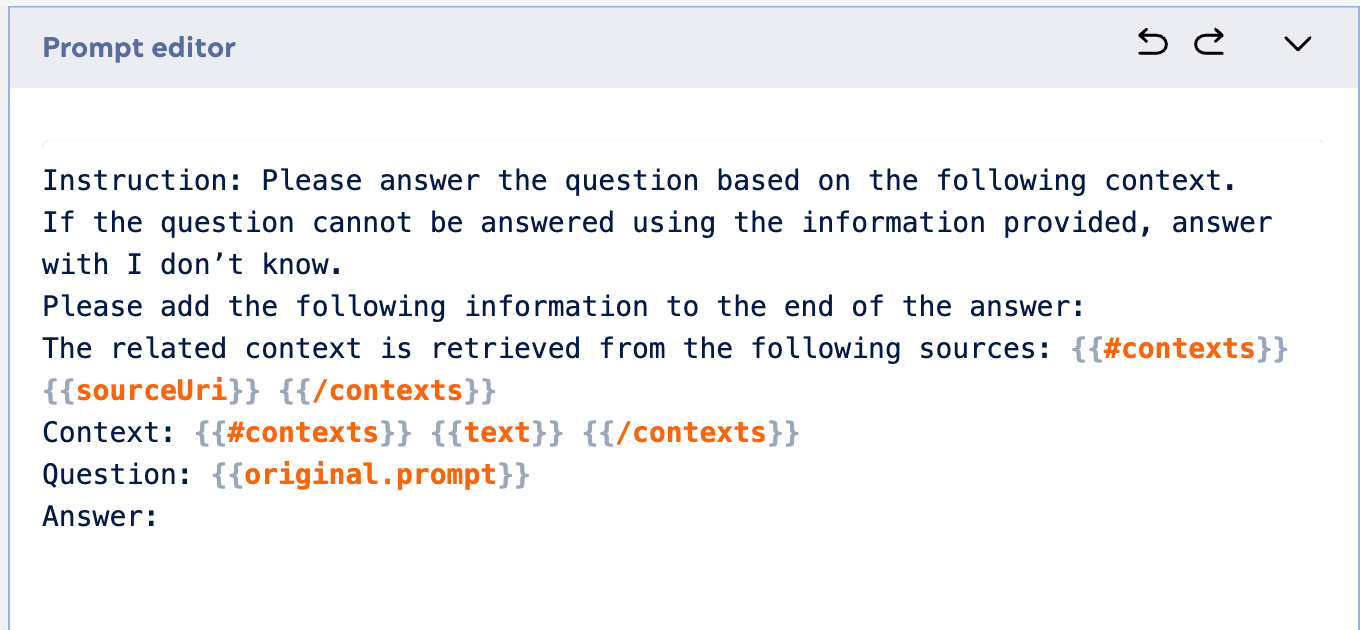
Nachdem wir nun erfolgreich relevante Informationen aus unserem Korpus abgerufen haben, besteht der nächste wichtige Schritt darin, diesen abgerufenen Kontext zu nutzen, um mithilfe eines LLM eine kohärente und genaue Antwort zu generieren. In diesem Abschnitt wird gezeigt, wie die Ergebnisse aus dem Google Vertex AI RAG Retrieval Query Snap mit einem generativen KI-Modell wie dem Google Gemini Generate Snap integriert werden können, um auf der Grundlage der erweiterten Informationen eine endgültige Antwort zu erstellen.

Hier ist ein Beispiel für eine Eingabeaufforderung, die Sie im Eingabeaufforderungsgenerator verwenden können:
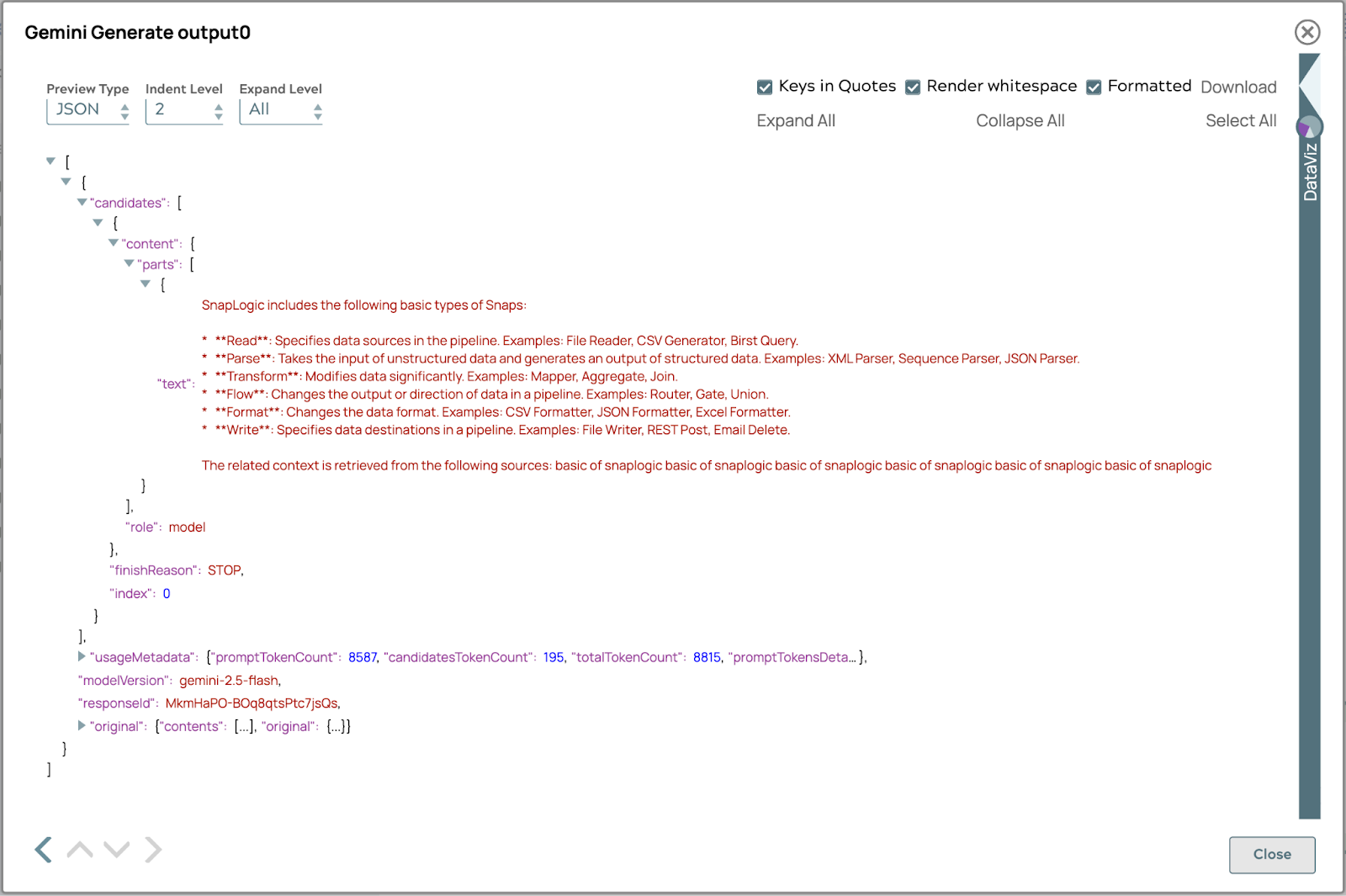
Die endgültige Antwort lautet wie folgt:
Darüber hinaus bietet die Integration zwischen Vertex AI RAG und SnapLogic den erheblichen Vorteil der modellübergreifenden Kompatibilität. Das bedeutet, dass die etablierten RAG-Workflows und Datenabrufprozesse nahtlos angepasst und mit verschiedenen großen Sprachmodellen außerhalb von Vertex AI genutzt werden können, beispielsweise mit Open-Source-Modellen oder anderen kommerziellen LLMs. Diese Flexibilität ermöglicht es Unternehmen, ihre Investitionen in die RAG-Infrastruktur in einem vielfältigen Ökosystem von KI-Modellen zu nutzen, was eine größere Anpassungsfähigkeit, Zukunftssicherheit der Anwendungen und die Möglichkeit bietet, das für bestimmte Aufgaben am besten geeignete LLM auszuwählen, ohne die gesamte Pipeline zur Informationsabfrage neu aufbauen zu müssen. Dieser modellübergreifende Vorteil stellt sicher, dass die RAG-Lösung unabhängig von sich weiterentwickelnden LLM-Landschaften vielseitig und wertvoll bleibt.
Automatische Abfrage mit dem integrierten Tool von Vertex AI
Die Verwendung des integrierten Tools im Vertex AI Gemini Generate Snap für die automatische Abfrage vereinfacht die RAG-Pipeline erheblich. Anstatt manuell eine Abfrage durchzuführen und die Ergebnisse dann an einen separaten Generierungsschritt weiterzuleiten, ermöglicht dieser integrierte Ansatz dem Gemini-Modell, den konfigurierten RAG-Korpus basierend auf der Eingabeaufforderung automatisch zu konsultieren. Dies reduziert die Anzahl der Schritte und die Komplexität der Pipeline, da die Abruf- und Generierungsprozesse nahtlos innerhalb eines einzigen Snaps abgewickelt werden. So wird sichergestellt, dass das LLM immer Zugriff auf die relevantesten Kontextinformationen aus Ihrer Wissensdatenbank hat, ohne dass eine explizite Orchestrierung erforderlich ist, was zu einer effizienteren und genaueren Generierung von Inhalten führt.

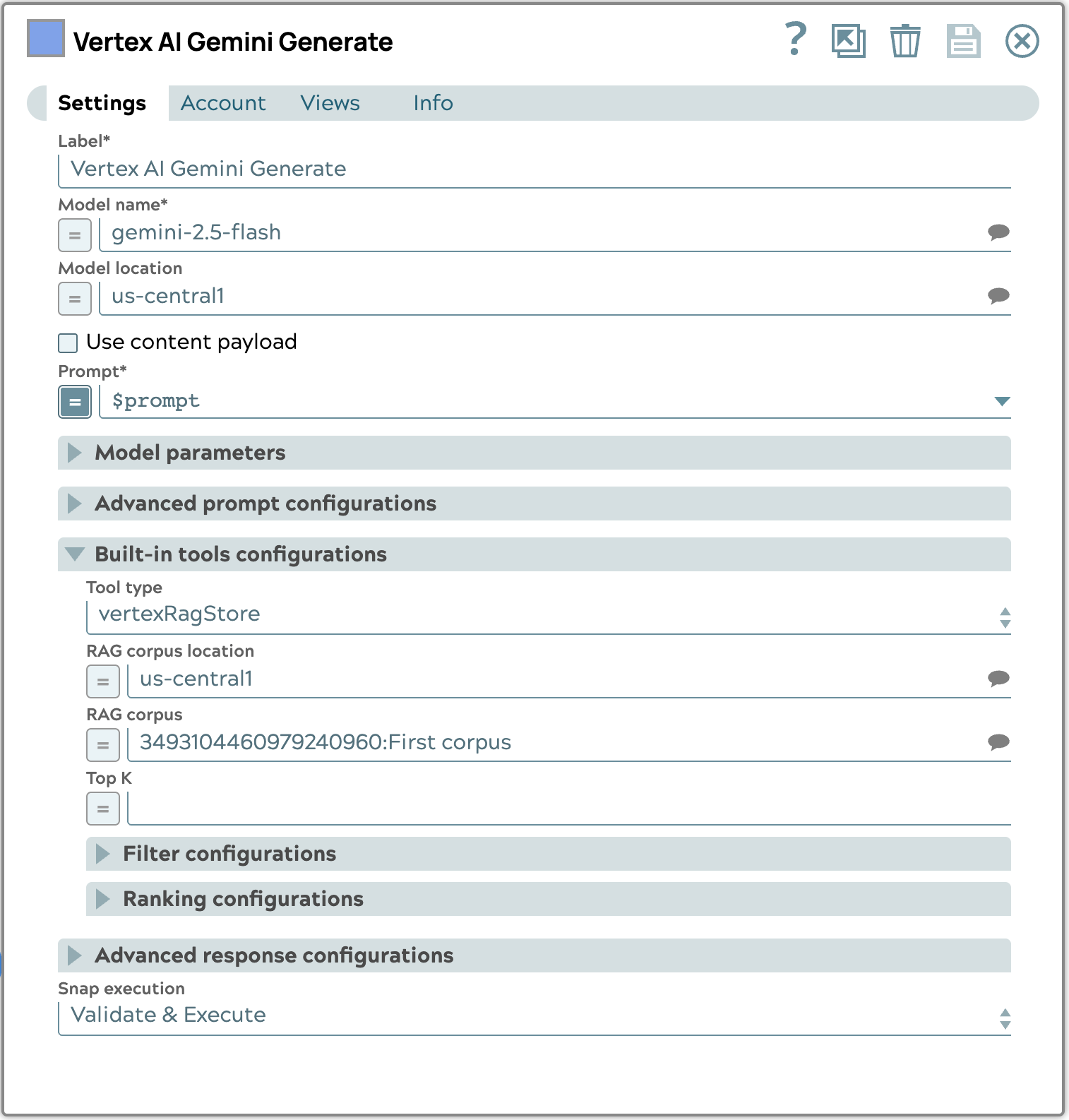
Das folgende Beispiel für eine Snap-Konfiguration zeigt, wie der Abschnitt „Built-in tools“ (Integrierte Tools) konfiguriert wird. Konkret wählen wir den Typ „vertexRagStore“ aus und legen den Zielkorpus fest.
Die endgültige Antwort, die mithilfe des automatischen Abrufprozesses generiert wurde, wird unten angezeigt.
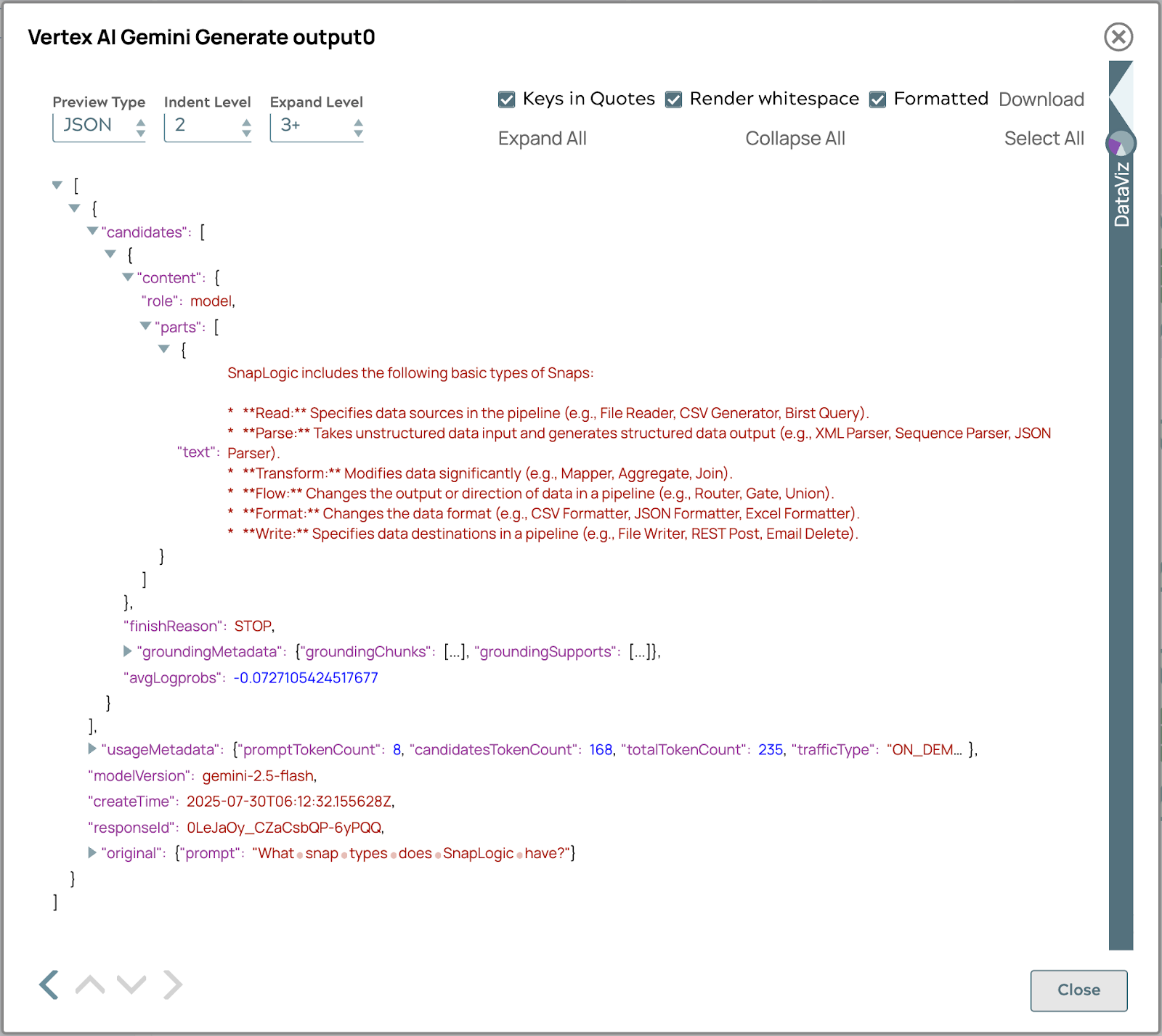
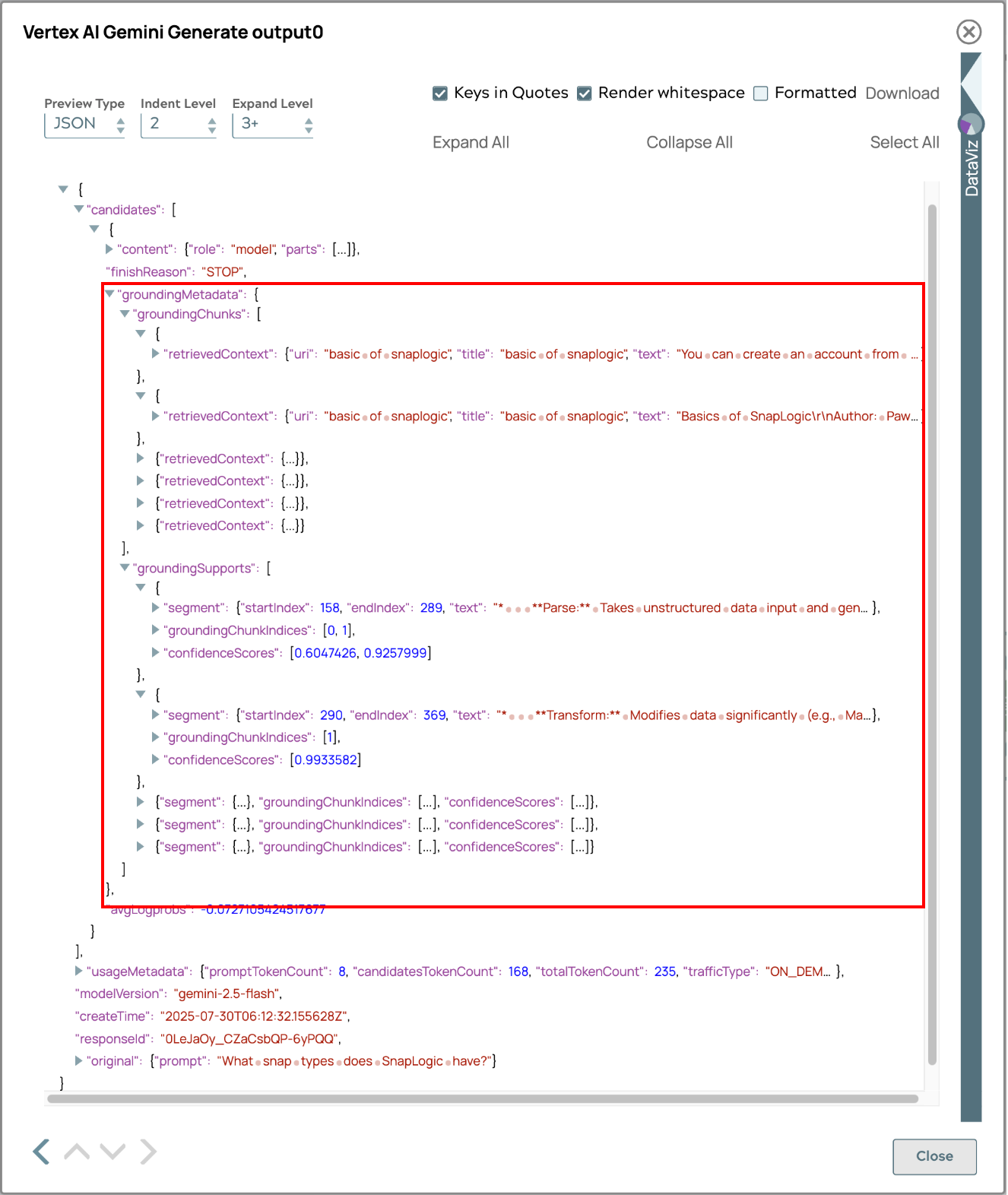
Die Antwort enthält Metadaten zur Quellenverfolgung, sodass Benutzer die Herkunft von Informationen zurückverfolgen können. Diese Funktion erhöht die Transparenz, ermöglicht die Überprüfung von Fakten und schafft Vertrauen in die Genauigkeit und Zuverlässigkeit der Inhalte. Benutzer können sich mit dem Quellmaterial befassen, Fakten miteinander vergleichen und ein umfassendes Verständnis erlangen, was die Nützlichkeit und Vertrauenswürdigkeit des Systems erhöht.
Zusammenfassung
Dieses Dokument zeigt, wie die Vertex AI Retrieval Augmented Generation (RAG)-Funktionen von Google Cloud in SnapLogic integriert werden können, um LLM-Workflows zu verbessern. Zu den wichtigsten Erkenntnissen gehören:
- Optimierter RAG-Prozess: Vertex AI RAG vereinfacht das Wissensmanagement und die Wissensabfrage, indem es komplexe Vorgänge wie die manuelle Generierung von Einbettungen und Abfragelogik abstrahiert, die bei herkömmlichen Vektordatenbanken in der Regel erforderlich sind.
- Integrierte Lösung: Im Gegensatz zu eigenständigen Vektordatenbanken bietet Vertex AI RAG eine End-to-End-Lösung für RAG, die alles von der Erfassung von Rohdateien bis zur Integration mit LLMs abdeckt.
- SnapLogic-Integration: SnapLogic bietet spezielle Snaps für die Verwaltung von Vertex AI RAG-Korpora (Erstellen, Auflisten, Abrufen, Löschen), die Verwaltung von Dateien innerhalb von Korpora (Hinzufügen, Auflisten, Abrufen, Entfernen) und die Durchführung von Abfragevorgängen.
- Praktische Anwendung: Der Leitfaden enthält eine Schritt-für-Schritt-Anleitung zum Einrichten eines Korpus, zum Hochladen von Dokumenten, zum Ausführen von Suchanfragen mit Google Vertex AI RAG Retrieval Query Snap und zum Integrieren der Ergebnisse in generative KI-Modelle wie Google Gemini Generate Snap, um kontextgenaue Antworten zu erhalten.
- Modellübergreifende Kompatibilität: Ein wesentlicher Vorteil dieser Integration ist die Möglichkeit, etablierte RAG-Workflows und Datenabrufprozesse mit verschiedenen LLMs über Vertex AI hinaus anzupassen, darunter Open-Source- und andere kommerzielle Modelle, wodurch Flexibilität und Zukunftssicherheit gewährleistet werden.
- Automatisierte Abfrage mit integrierten Tools: Die Integration ermöglicht eine automatisierte Abfrage über integrierte Tools im Vertex AI Gemini Generate Snap, wodurch die RAG-Pipeline vereinfacht wird, da Abfrage und Generierung nahtlos in einem einzigen Schritt abgewickelt werden.
Durch die Nutzung von Vertex AI RAG mit SnapLogic können Unternehmen die Entwicklung und Bereitstellung von RAG-basierten Anwendungen vereinfachen, was zu genaueren, kontextbezogenen und effizienteren LLM-Antworten führt.





