





Dans une enquête de McKinsey, 70 % des entreprises interrogées ont déclaré que leur société avait introduit l‘automatisation dans au moins une unité opérationnelle. Ce chiffre est en hausse par rapport à 66 % en 2020 et 57 % en 2018. L‘automatisation informatique continue de croître, grâce aux logiciels agnostiques et aux plateformes d‘intégration de données à code bas qui peuvent fonctionner dans tous les secteurs d‘activité.
L‘automatisation informatique consiste à remplacer les tâches manuelles et répétitives effectuées par le personnel technique et non technique par des systèmes logiciels. L‘automatisation libère des ressources, vous permet d‘évoluer rapidement, améliore l‘efficacité et permet à votre équipe de se concentrer sur des tâches plus stratégiques et créatives.
Les domaines d‘intérêt général de l‘automatisation informatique comprennent le service à la clientèle, les ressources humaines, l‘automatisation de la paie et la sécurité des données, mais ce n‘est pas tout. La migration des données, le processus ETL d‘une organisation et la gouvernance des données en général peuvent également être automatisés pour traiter de grandes quantités de données et améliorer la qualité et la cohérence des données. Voici comment :
Automatisation de la migration des données
La migration automatisée des données rend le processus plus rapide et plus fluide, garantissant que vos processus et applications critiques continuent de fonctionner comme d‘habitude pendant le processus de migration. Vous bénéficiez également d‘un meilleur contrôle de la qualité des données et réduisez les risques d‘erreur humaine. Selon IDC, 28,9 % des personnes interrogées dans le monde entier ont déclaré qu‘elles investiraient dans le développement et la migration d‘applications en 2021, ce qui en fait l‘un des cinq principaux domaines d‘automatisation informatique.
En automatisant la migration des données, vous rendez le processus évolutif et permettez la migration de grandes quantités de données sans qu‘il soit nécessaire d‘interrompre le service. Par exemple, vous pouvez migrer des centaines de milliers de fichiers XML dont les schémas changent constamment en créant un système qui détecte les changements structurels dans les fichiers et les mappe dans une nouvelle base de données. La migration manuelle de fichiers en constante évolution peut s‘avérer extrêmement difficile, voire impossible.
La migration peut déplacer les données des serveurs sur site vers le site cloud, du site cloud vers les serveurs sur site, et de plusieurs bases de données vers un entrepôt de données unique afin d‘éliminer les silos.
La migration d‘applications, comme le passage de Quip à Google Docs ou d‘Auth0 à Okta, est également une sorte de migration de données. Les données que vous avez créées avec votre application actuelle ou les données utilisées par votre application actuelle doivent encore être transférées vers la nouvelle application.
Lors d‘un processus de migration de données, vous devez
- Familiarisez-vous avec le système actuel et le système cible.
- Décidez si vous allez effectuer la migration en une seule fois ou par étapes.
- Développer la ou les applications nécessaires à la migration.
- Tester la ou les applications.
- Procéder à la migration après avoir effectué des tests approfondis.
C‘est l‘étape 3 qui différencie une migration de données automatisée d‘une migration manuelle. Par exemple, si vous passez de Mailchimp à HubSpot, vous devrez :
- Téléchargez votre base de données d‘emails sous forme de fichier CSV depuis Mailchimp
- Télécharger le fichier dans HubSpot et faire correspondre chaque colonne du fichier à son équivalent.
- Allez dans HubSpot et configurez toutes les campagnes automatisées que vous aviez dans Mailchimp.
- Assurez-vous que tous les déclencheurs d‘emails qui fonctionnent dans Mailchimp fonctionnent également dans HubSpot.
Pour mettre en place des campagnes automatisées de cette manière, vous devrez télécharger des dizaines de modèles d‘e-mails à partir de Mailchimp et les convertir dans un format acceptable pour HubSpot. Ou alors, vous devrez concevoir de nouveaux modèles à partir de zéro.
Cela représente beaucoup de travail manuel. C‘est pourquoi la migration manuelle des données n‘est plus très courante. Automatiser la même migration signifie créer un programme qui le fait pour vous, en lisant tous les modèles de Mailchimp et en créant les mêmes dans HubSpot. Pour cela, le programme/application que vous utilisez doit pouvoir communiquer à la fois avec Mailchimp et HubSpot.
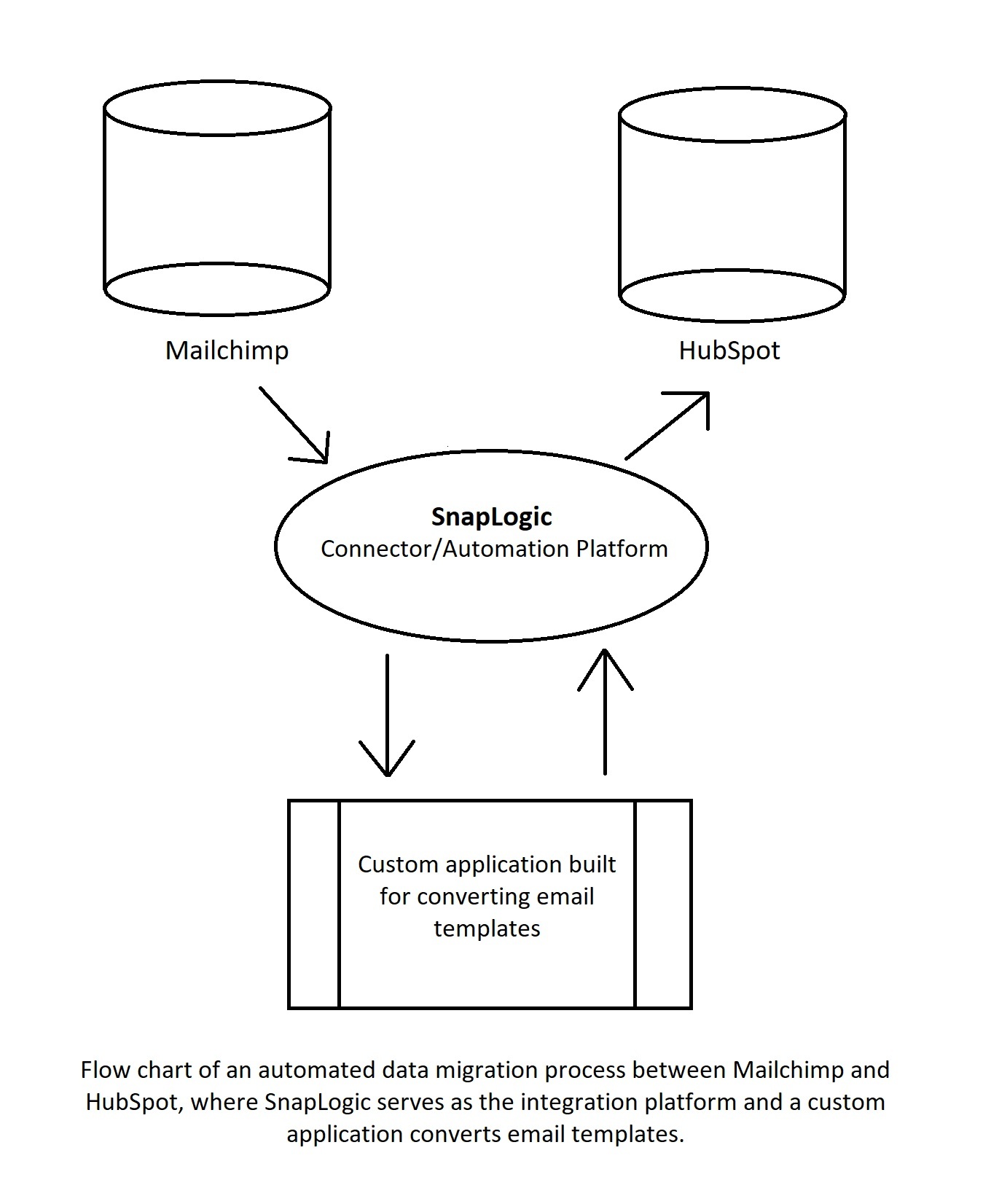
Dans le diagramme ci-dessus, un connecteur/automation plateforme prend les données de Mailchimp et les envoie à une application personnalisée qui les convertit en un formulaire acceptable pour HubSpot. Ensuite, le site plateforme envoie les données à HubSpot. Des automatisations plus complexes impliqueront davantage d‘applications et de processus, mais l‘utilisation d‘une automatisation à code bas plateforme aidera à réguler le workflow et permettra à différentes applications de communiquer entre elles.
Automatisation de l‘ETL vers l‘ELT
L‘automatisation du processus ETL permet d‘économiser des ressources précieuses en réduisant la quantité de code à écrire pour extraire, transformer et charger les données.
Les données existent dans différentes structures et schémas à travers les nombreuses applications et bases de données de votre organisation. Pour véritablement exploiter la valeur de ces données, elles doivent être extraites, transformées et chargées (ETL) dans un référentiel central, tel qu‘un entrepôt de données, où elles peuvent être analysées pour en tirer des informations utiles à l‘entreprise.
La configuration d‘un processus ETL implique beaucoup de codage manuel. Chaque nouvelle source de données nécessite des instructions spéciales pour la connexion et l‘extraction des données. Une fois les données extraites, un codage supplémentaire est nécessaire pour transformer correctement les données dans un format acceptable pour l‘entrepôt de données cible. Enfin, les données peuvent être chargées dans l‘entrepôt pour être analysées. Chaque nouveau pipeline de transfert de données dans l‘entrepôt de données nécessite un effort manuel supplémentaire.
Une meilleure approche consiste à utiliser un logiciel d‘intégration spécialisé à faible code ( plateforme ) pour faire la même chose. En automatisant le processus ETL et en tirant parti de l‘évolutivité d‘un entrepôt de données cloud , vous pouvez effectivement transformer l‘approche ETL traditionnellement manuelle en une approche ELT moderne. Dans cette approche, l‘extraction et le chargement des données sont simplifiés grâce à des pipelines de données standardisés, tandis que la transformation des données est automatisée dans l‘entrepôt de données cloud .
Le passage de l‘ETL à l‘ELT accélère considérablement le processus de chargement, ce qui vous permet d‘obtenir beaucoup plus rapidement des données de meilleure qualité pour l‘analyse commerciale.
Gouvernance des données et automatisation de la conformité
L‘automatisation de la gouvernance des données permet aux utilisateurs professionnels d‘avoir une vue d‘ensemble des données de l‘organisation - leur emplacement, leur objectif, leur structure et leur utilisation dans les différents processus de l‘entreprise. L‘automatisation de la gouvernance des données garantit également que vos données sont sécurisées et qu‘elles ne sont pas utilisées à mauvais escient.
Un programme de gouvernance des données aborde les questions suivantes
- Les définitions de chaque point de données
- Le rôle et les responsabilités de chaque utilisateur en matière de données
- L‘emplacement physique et en ligne des sources et du stockage des données
- Le flux et la lignée des données
- Les règles permettant de créer, manipuler, stocker, extraire, modifier et supprimer des données.
L‘automatisation de la gouvernance des données consiste à cartographier le parcours complet des données au sein de l‘entreprise et à contrôler l‘ensemble des pipelines et des actifs de données.
Dans une organisation, il y a plusieurs pipelines de données en jeu. Par exemple, un prospect s‘inscrit à une démonstration de produit sur votre site web, est assigné à un représentant commercial, participe à la démonstration et finit par devenir un client. À chaque étape de ce processus, les données ont été traitées dans une application différente avant d‘arriver dans votre entrepôt de données.
- Le prospect a saisi ses coordonnées dans un formulaire et s‘est inscrit à une démonstration.
- Les données sont passées du formulaire à l‘application de marketing ou de vente et ont été attribuées à un représentant commercial.
- L‘utilisateur a suivi la démonstration et a acheté le produit.
- Le point de données qui enregistre le statut de l‘utilisateur est passé de "prospect" à "client" et les données ont été transférées dans l‘entrepôt de données.
- Si l‘utilisateur n‘avait pas acheté le produit après la démonstration, ses informations auraient été renvoyées à l‘outil de marketing pour d‘autres campagnes.
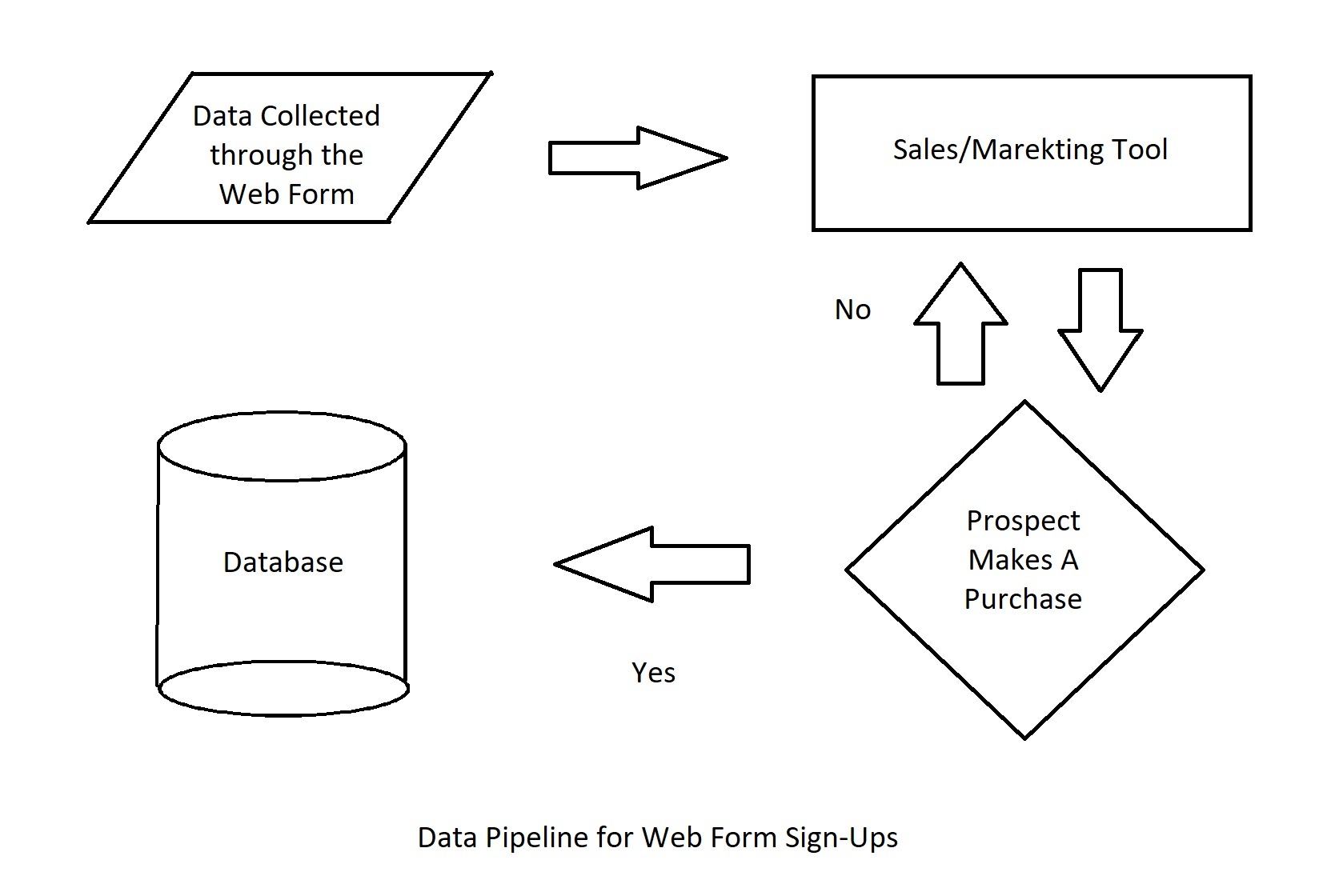
L‘automatisation de ce processus signifie qu‘il n‘y a pas d‘intervention humaine à aucun stade. Le formulaire web doit être connecté à l‘outil de vente/marketing, soit par intégration directe, soit à l‘aide de connecteurs de données. Le statut doit changer de lui-même une fois que le prospect a acheté le produit, et les données doivent être transférées vers la base de données principale une fois que le statut du prospect est devenu celui d‘un client.
L‘automatisation complète de la gouvernance des données peut être réalisée une fois que les workflows a été mis en place pour garantir la qualité des données et que tous les processus (comme dans l‘exemple ci-dessus) ne nécessitent que peu ou pas d‘intervention manuelle.
Automatisation des pipelines de ML
L‘automatisation permet de faire évoluer l‘apprentissage automatique. L‘automatisation du pipeline d‘apprentissage automatique permet d‘accélérer le cycle d‘itération et d‘améliorer le contrôle et le test des performances.
Dans un pipeline d‘apprentissage automatique, l‘extraction des données, la validation, la préparation/l‘étiquetage, l‘entraînement du modèle de ML, ainsi que l‘évaluation et la validation du modèle sont tous automatisés. L‘automatisation du pipeline d‘apprentissage automatique fait désormais partie intégrante de la formation d‘un algorithme d‘apprentissage automatique, car l‘alternative manuelle n‘est ni extensible ni réalisable.
En général, le seul processus d‘étiquetage des données nécessite plusieurs personnes travaillant pendant des semaines (voire des mois, selon l‘ampleur du projet), pour étiqueter les données destinées aux algorithmes d‘apprentissage automatique. Dans un pipeline d‘apprentissage automatique, chaque composant du pipeline est codifié.
- Extraction de données - automatisée par le traitement intelligent des documents, où des outils intelligents parcourent les documents et extraient les données pertinentes pour le projet.
- Validation des données - automatisée au moyen de scripts écrits dans des langages de programmation ou d‘ outils spécialisés pour la validation des données.
- Préparation des données/étiquetage - partiellement automatisé grâce à l‘ apprentissage actif ou entièrement automatisé grâce à l‘ étiquetage programmé.
- Formation du modèle ML - automatisée avec l‘aide d‘ AutoML Snap de SnapLogic.
- Évaluation et validation du modèle de ML - automatisées à l‘aide d‘un code personnalisé qui alimente en données de test plusieurs modèles de ML.
Lorsque chaque étape du pipeline est automatisée, il suffit de disposer de connecteurs de données pour permettre le flux de données d‘un processus à l‘autre, et l‘automatisation est complète.
Automatisation de l‘informatique avec SnapLogic
Nous vivons à l‘ère de l‘hyper-automatisation. L‘une des principales exigences en matière d‘automatisation de la gouvernance des données, du processus ETL ou de tout autre processus de migration des données est de pouvoir créer les workflows pour déplacer les données entre les différentes applications. La création d‘applications personnalisées pour réaliser l‘automatisation nécessite beaucoup de codage et de développement. SnapLogic offre une option de code bas pour aider vos applications à communiquer entre elles. Explorez l‘intégration de données de SnapLogic plateforme pour voir comment elle peut contribuer à l‘automatisation de l‘informatique dans votre entreprise.
Vous cherchez plus d‘informations sur l‘intégration des données et l‘automatisation ? SnapLogic a créé pour vous le Guide ultime de l‘intégration des données.







