





In un sondaggio McKinsey, il 70% delle aziende intervistate ha dichiarato di aver introdotto l'automazione in almeno una business unit. Questo numero è aumentato rispetto al 66% del 2020 e al 57% del 2018. L'automazione dell'IT continua a crescere, grazie a un software che si adatta ai processi e a piattaforme di integrazione dei dati a basso codice che possono funzionare in tutti i settori.
L'automazione IT è il processo di sostituzione delle attività manuali e ripetitive svolte dal personale tecnico e non tecnico con sistemi software. L'automazione libera risorse, consente di scalare rapidamente, migliora l'efficienza e permette al team di concentrarsi su attività più strategiche e creative.
Le aree generali di interesse per l'automazione IT comprendono il servizio clienti, le risorse umane, l'automazione delle buste paga e la sicurezza dei dati, ma non solo. Anche la migrazione dei dati, il processo ETL di un'organizzazione e la governance dei dati in generale possono essere automatizzati per gestire grandi quantità di dati e migliorarne la qualità e la coerenza. Ecco come fare:
Automazione della migrazione dei dati
La migrazione automatizzata dei dati rende il processo più rapido e fluido, garantendo che i processi e le applicazioni critiche continuino a funzionare normalmente durante il processo di migrazione. Inoltre, si ottiene un maggiore controllo sulla qualità dei dati e si riducono le possibilità di errore umano. Secondo IDC, il 28,9% degli intervistati di tutto il mondo ha dichiarato che investirà nello sviluppo e nella migrazione delle applicazioni nel 2021, rendendola una delle prime cinque aree di interesse dell'automazione IT.
Automatizzando la migrazione dei dati, si rende il processo scalabile e si consente la migrazione di grandi quantità di dati senza alcuna interruzione del servizio. Ad esempio, è possibile migrare centinaia di migliaia di file XML con schemi in continua evoluzione creando un sistema che rileva le modifiche strutturali dei file e le mappa in un nuovo database. La migrazione manuale di file in continua evoluzione può essere estremamente difficile, se non impossibile.
La migrazione può spostare i dati dai server on-premises a cloud, da cloud ai server on-premises e da più database in un unico data warehouse per eliminare i silos.
La migrazione di applicazioni, come il passaggio da Quip a Google Docs o da Auth0 a Okta, è anche una sorta di migrazione di dati. I dati creati attraverso l'applicazione attuale o i dati utilizzati dall'applicazione attuale devono essere trasferiti alla nuova applicazione.
In un processo di migrazione dei dati:
- Familiarizzare con il sistema attuale e con quello di destinazione.
- Decidete se eseguire l'intera migrazione in un'unica soluzione o in fasi successive.
- Sviluppare le applicazioni necessarie per la migrazione.
- Testare le applicazioni.
- Procedere con la migrazione dopo averla testata a fondo.
È la fase 3 che differenzia una migrazione di dati automatizzata da una manuale. Ad esempio, quando si passa da Mailchimp a HubSpot, è necessario:
- Scaricate il vostro database di e-mail in un file CSV da Mailchimp.
- Caricare il file in HubSpot e mappare ogni colonna del file con la sua controparte.
- Entrate in HubSpot e impostate tutte le campagne automatizzate che avevate in Mailchimp.
- Assicuratevi che tutti i trigger delle email che funzionano in Mailchimp funzionino anche in HubSpot.
Per impostare campagne automatizzate in questo modo, dovrete scaricare decine di modelli di e-mail da Mailchimp e convertirli in un formato accettabile per HubSpot. Oppure dovrete progettare nuovi modelli da zero.
Si tratta di un sacco di lavoro manuale. Ecco perché la migrazione manuale dei dati non è più così comune. Automatizzare la stessa migrazione significa creare un programma che lo faccia per voi, leggendo tutti i modelli da Mailchimp e creando poi gli stessi in HubSpot. Affinché ciò avvenga, il programma/app che si utilizza deve essere in grado di parlare sia con Mailchimp che con HubSpot.
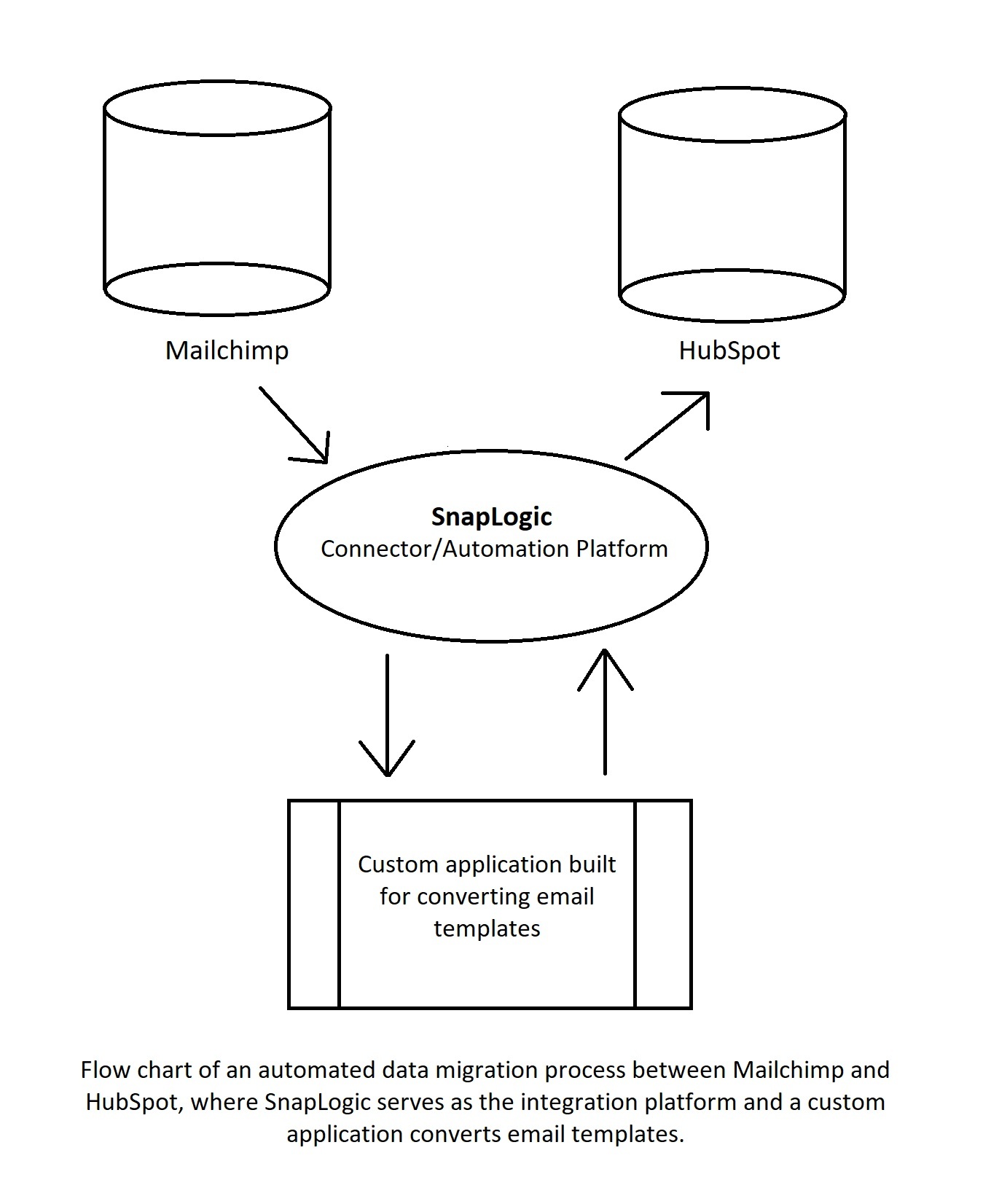
Nel diagramma qui sopra, un connettore/piattaforma di automazione prende i dati da Mailchimp e li invia a un'applicazione personalizzata che li converte in un modulo accettabile per HubSpot. Successivamente, la piattaforma invia i dati a HubSpot. Automazioni più complesse coinvolgeranno più applicazioni e processi, ma l'utilizzo di una piattaforma di automazione low-code aiuterà a regolare il flusso di lavoro e a consentire alle diverse applicazioni di dialogare tra loro.
Automazione da ETL a ELT
L'automazione del processo ETL consente di risparmiare risorse preziose riducendo al minimo la quantità di codice da scrivere per estrarre, trasformare e caricare i dati.
I dati esistono in varie strutture e schemi nelle diverse applicazioni e database dell'organizzazione. Per poterne sfruttare il valore, i dati devono essere estratti, trasformati e caricati (ETL) in un repository centrale, come un data warehouse, dove possono essere analizzati per ottenere informazioni di business.
La configurazione di un processo ETL comporta un'intensa attività di codifica manuale. Ogni nuova fonte di dati richiede istruzioni speciali per la connessione e l'estrazione dei dati. Una volta estratti i dati, è necessaria un'ulteriore codifica per trasformarli correttamente in un formato accettabile per il data warehouse di destinazione. Infine, i dati possono essere caricati nel magazzino per l'analisi. Ogni nuova pipeline per spostare i dati nel data warehouse richiede un ulteriore sforzo manuale.
Un approccio migliore consiste nell'utilizzare una piattaforma di integrazione specializzata e a basso codice per fare lo stesso. Automatizzando il processo ETL e sfruttando la scalabilità di un data warehouse cloud , è possibile modificare efficacemente l'approccio ETL tradizionalmente manuale in un moderno approccio ELT. In questo approccio, l'estrazione e il caricamento dei dati sono semplificati grazie a pipeline di dati standardizzate, mentre la trasformazione dei dati è automatizzata all'interno del data warehouse cloud .
Il passaggio dall'ETL all'ELT accelera notevolmente il processo di caricamento, consentendo di ottenere molto più rapidamente dati di qualità superiore per le analisi di business.
Automazione della governance dei dati e della conformità
L'automazione della governance dei dati garantisce che gli utenti aziendali abbiano una visione completa dei dati presenti nell'organizzazione: la loro posizione, lo scopo, la struttura e l'utilizzo nei diversi processi aziendali. L'automazione della governance dei dati garantisce inoltre che i dati siano protetti e non vengano utilizzati in modo improprio.
Un programma di governance dei dati si occupa di:
- Le definizioni di ciascun punto dati
- Ruolo e responsabilità di ciascun utente in materia di dati
- L'ubicazione fisica e online delle fonti e dell'archiviazione dei dati.
- Il flusso e il percorso dei dati
- Le regole per creare, manipolare, memorizzare, recuperare, modificare e cancellare i dati.
Automatizzare la governance dei dati significa mappare l'intero percorso dei dati che attraversano l'organizzazione e ottenere il pieno controllo di tutte le pipeline e gli asset di dati.
In un'azienda sono in gioco diverse pipeline di dati. Ad esempio, un cliente potenziale si iscrive per una demo del prodotto sul vostro sito web, viene assegnato a un rappresentante, partecipa alla demo e finisce per diventare un cliente. In ogni fase di questo processo, i dati sono stati elaborati in un'applicazione diversa prima di arrivare al data warehouse.
- Il potenziale cliente ha inserito i propri dati di contatto in un modulo e ha sottoscritto una demo.
- I dati sono passati dal modulo all'applicazione di marketing o di vendita e sono stati assegnati a un rappresentante di vendita.
- L'utente ha preso la demo e ha acquistato il prodotto
- Il punto di dati che cattura lo stato dell'utente è cambiato da "prospect" a "cliente" e i dati sono stati spostati nel data warehouse.
- Se l'utente non avesse acquistato il prodotto dopo la demo, le sue informazioni sarebbero tornate allo strumento di marketing per altre campagne.
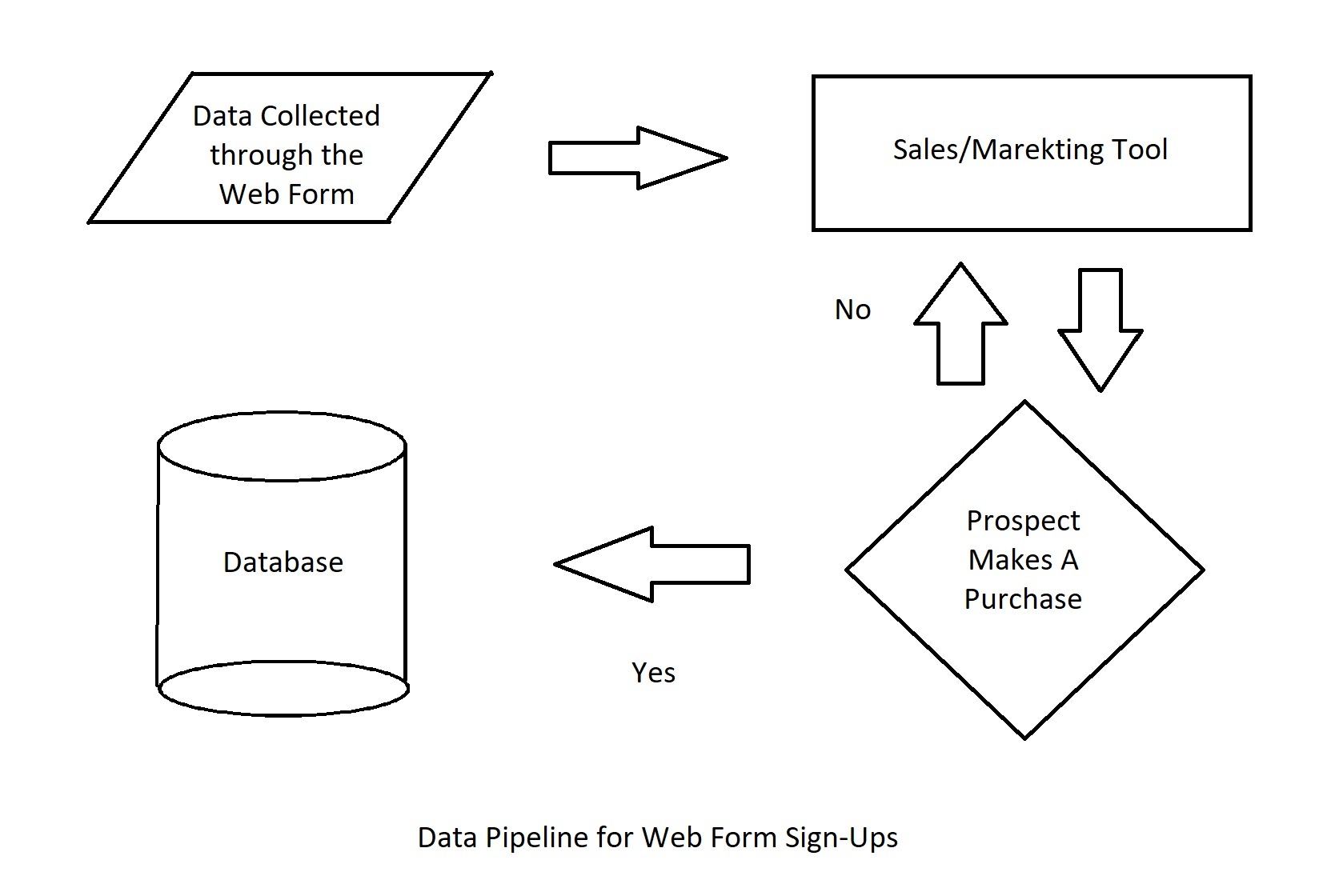
Automatizzare questo processo significa evitare l'intervento umano in qualsiasi fase. Il modulo web deve essere collegato allo strumento di vendita/marketing tramite integrazione diretta o con l'aiuto di connettori di dati. Lo stato deve cambiare da solo dopo che il potenziale cliente ha acquistato il prodotto e i dati devono essere trasferiti al database principale quando lo stato del potenziale diventa quello di cliente.
L'automazione completa della governance dei dati può essere raggiunta una volta che i flussi di lavoro sono stati posizionati per garantire la qualità dei dati e tutti i processi (come l'esempio precedente) richiedono un'interferenza manuale minima o nulla.
Automazione della pipeline ML
L'automazione consente all'apprendimento automatico di scalare. L'automazione della pipeline di apprendimento automatico si traduce in un ciclo di iterazione più rapido e in un migliore monitoraggio e test delle prestazioni.
In una pipeline di apprendimento automatico, l'estrazione dei dati, la convalida, la preparazione/etichettatura, l'addestramento del modello di ML, la valutazione e la convalida del modello sono tutti automatizzati. L'automazione della pipeline di ML è oggi una parte standard dell'addestramento di un algoritmo di apprendimento automatico, perché l'alternativa manuale non è né scalabile né fattibile.
In generale, il solo processo di etichettatura dei dati richiede più persone che lavorano per settimane (o addirittura mesi, a seconda della portata del progetto), etichettando i dati per gli algoritmi di apprendimento automatico. In una pipeline di apprendimento automatico, ogni componente della pipeline è codificato.
- Estrazione dei dati - automatizzata attraverso l'elaborazione intelligente dei documenti, dove strumenti intelligenti esaminano i documenti ed estraggono i dati rilevanti per il progetto.
- Convalida dei dati - automatizzata attraverso script scritti in linguaggi di programmazione o strumenti specializzati per la convalida dei dati.
- Preparazione dei dati/etichettatura - parzialmente automatizzata attraverso l' apprendimento attivo o completamente automatizzata attraverso l' etichettatura programmatica.
- Formazione del modello ML - automatizzata con l'aiuto di SnapLogic AutoML Snap.
- Valutazione e convalida del modello ML - automatizzata con l'aiuto di un codice personalizzato che alimenta i dati di test a più modelli ML.
Quando ogni singola fase della pipeline è automatizzata, sono sufficienti i connettori di dati per consentire il flusso di dati da un processo all'altro e si ottiene la completa automazione.
Ottenere l'automazione IT con SnapLogic
Viviamo nell'era dell'iper-automazione. Uno dei requisiti principali per l'automazione della governance dei dati, del processo ETL o di qualsiasi tipo di processo di migrazione dei dati è la possibilità di creare flussi di lavoro che spostino i dati tra le diverse applicazioni. La creazione di applicazioni personalizzate per ottenere l'automazione richiede un notevole sforzo di codifica e sviluppo. SnapLogic offre un' opzione low-code per aiutare le applicazioni a dialogare tra loro. Esplorate la piattaforma di integrazione dei dati di SnapLogic per vedere come può aiutare l'automazione IT nella vostra organizzazione.
Cercate maggiori informazioni sull'integrazione e l'automazione dei dati? SnapLogic ha creato per voi la Guida definitiva all'integrazione dei dati.







