





In a McKinsey survey, 70% of corporate respondents said that their companies had introduced automation in at least one business unit. That number was up from 66% in 2020 and 57% in 2018. IT automation continues to grow, thanks to process-agnostic software and low-code data integration platforms that can work across industries.
IT automation is the process of replacing manual and repetitive tasks performed by both technical and non-tech staff with software systems. Automation frees up resources, enables you to scale quickly, improves efficiency, and allows your team to focus on more strategic and creative tasks.
The general areas of focus for IT automation include customer service, HR, payroll automation, and data security, but that’s not all. Data migration, the ETL process in an organization, and data governance in general can also be automated to handle large quantities of data and improve data quality and consistency. Here’s how:
Data Migration Automation
Automated data migration makes the process faster and smoother, ensuring that your critical processes and applications keep functioning as usual during the migration process. You also gain greater control over data quality and reduce the chances for human error. According to IDC, 28.9% of respondents from all over the world said they would invest in application development and migration in 2021 — making it one of the top five areas of focus in IT automation.
By automating data migration, you make the process scalable and allow for the migration of large amounts of data without any need for service interruption. For example, you can migrate hundreds of thousands of XML files with constantly changing schemas by creating a system that detects structural changes in the files and maps them to a new database. To migrate constantly changing files manually can be extremely difficult, if not impossible.
The migration can move data from on-premises servers to the cloud, from the cloud to on-premises servers, and from multiple databases into a single data warehouse to eliminate silos.
Application migration, such as moving from Quip to Google Docs or Auth0 to Okta, is also a kind of data migration. The data you have created through your current app or the data used by your current app still has to be moved to the new app.
In a data migration process, you:
- Familiarize yourself with the current system and the target system.
- Decide whether you will do the whole migration in one go or in phases.
- Develop the application(s) needed for migration.
- Test the application(s).
- Go through with the migration after thorough testing.
It is step 3 that differentiates an automated data migration from a manual one. For example, when switching from Mailchimp to HubSpot, you will have to:
- Download your email database as a CSV file from Mailchimp
- Upload the file into HubSpot and map each column from the file to its counterpart
- Go into HubSpot and set up all automated campaigns that you had in Mailchimp
- Make sure all email triggers working in Mailchimp also work in HubSpot
To set up automated campaigns that way, you will have to download dozens of email templates from Mailchimp and convert them into an acceptable format for HubSpot. Or, you’ll have to design new templates from scratch.
That’s a lot of manual work. And that’s why manual data migration is not that common anymore. Automating the same migration means creating a program that does this for you, reading all templates from Mailchimp and then creating the same in HubSpot. For that to happen, the program/app you use should be able to talk to both Mailchimp and HubSpot.
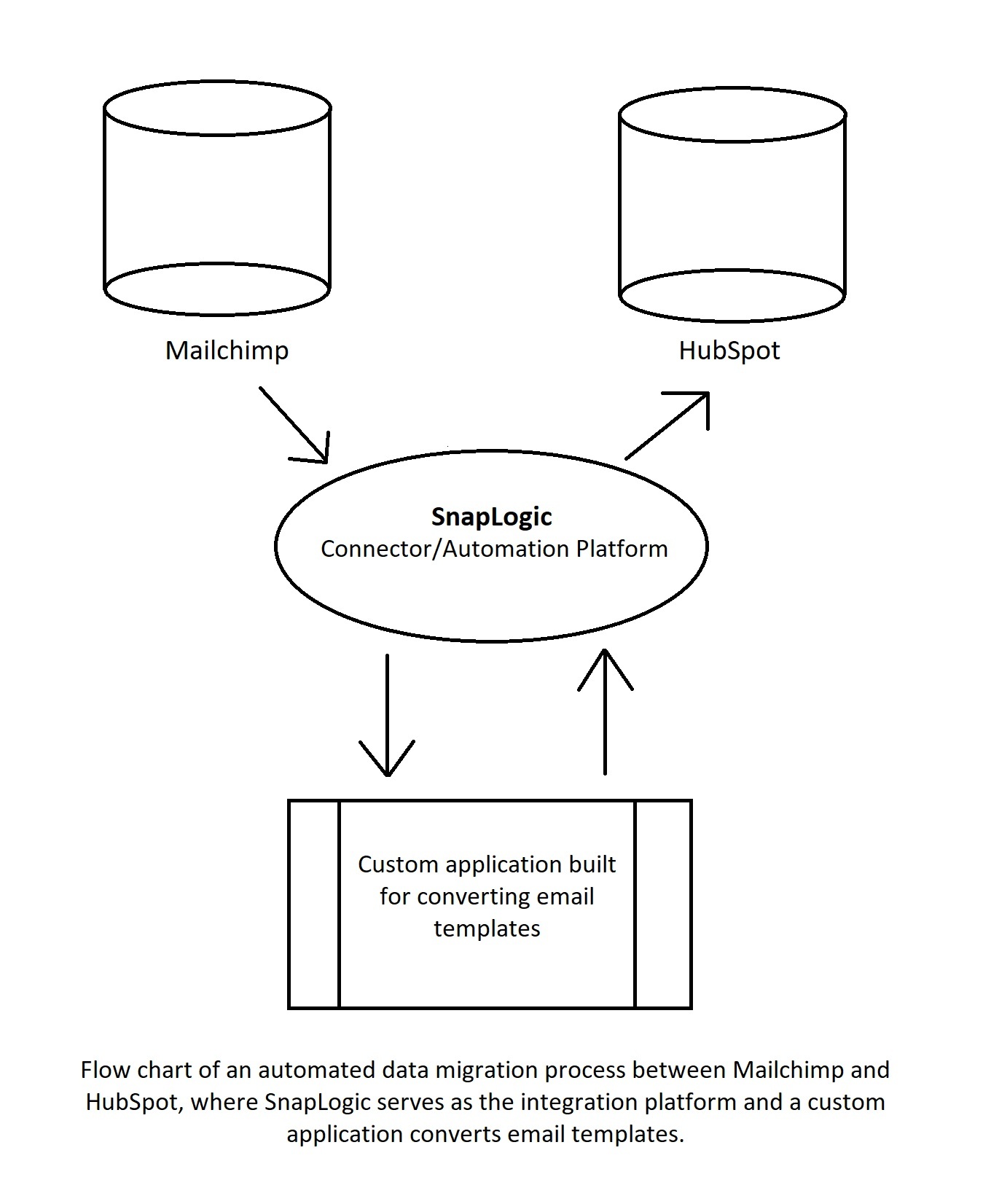
In the diagram above, a connector/automation platform takes data from Mailchimp and sends it to a custom application that converts it into an acceptable form for HubSpot. After that, the platform sends the data to HubSpot. More complex automations will have more applications and processes involved, but using a low-code automation platform will help regulate the workflow and allow different apps to talk to each other.
ETL to ELT Automation
Automating the ETL process saves valuable resources by minimizing the amount of code you have to write to extract, transform, and load data.
Data exists in various structures and schemas across the many different applications and databases within your organization. To truly unlock the value of this data, it must be extracted, transformed, and loaded (ETL) into a central repository, like a data warehouse, where it can be analyzed for business insights.
Configuring an ETL process involves a lot of manual coding. Each new data source requires special instructions to connect and extract the data. Once the data is extracted, additional coding is required to properly transform the data into a format that is acceptable for the target data warehouse. Finally, the data can be loaded into the warehouse for analysis. Each new pipeline for moving data into the data warehouse requires further manual effort.
A better approach is to use a low-code, specialized integration platform to do the same. By automating the ETL process and leveraging the scalability of a cloud data warehouse, you can effectively change the traditionally manual ETL approach into a modern ELT approach. In this approach, data extraction and loading is simplified through standardized data pipelines while the data transformation is automated within the cloud data warehouse.
Changing the process from ETL to ELT speeds up the loading process substantially, allowing you to get to higher-quality data for business analytics much faster.
Data Governance and Compliance Automation
Automation of data governance ensures that business users gain a complete overview of the data in the organization — its location, purpose, structure, and use in different business processes. Automating data governance also ensures that your data is secured and is not being misused.
A data governance program addresses:
- The definitions of each data point
- Each user’s role and responsibilities when it comes to data
- The physical and online locations of data sources and storage
- The flow and lineage of data
- The rules to create, manipulate, store, retrieve, change, and delete data.
Automating data governance means mapping the complete path of data as it travels through your organization and gaining full control of all data pipelines and assets.
There are multiple data pipelines in play at an organization. For example, a prospect signs up for a product demo on your website, gets assigned to a sales rep, takes the demo, and ends up becoming a customer. At every stage of this process, data was processed in a different app before making it to your data warehouse.
- The prospect entered their contact information in a form and signed up a demo
- The data traveled from the form to the marketing or sales application and got assigned to a sales rep
- The user took the demo and purchased the product
- The data point that captures user status changed from ‘prospect’ to ‘customer’ and the data moved to the data warehouse.
- If the user had not purchased the product after the demo, their information would have gone back to the marketing tool for more campaigns.
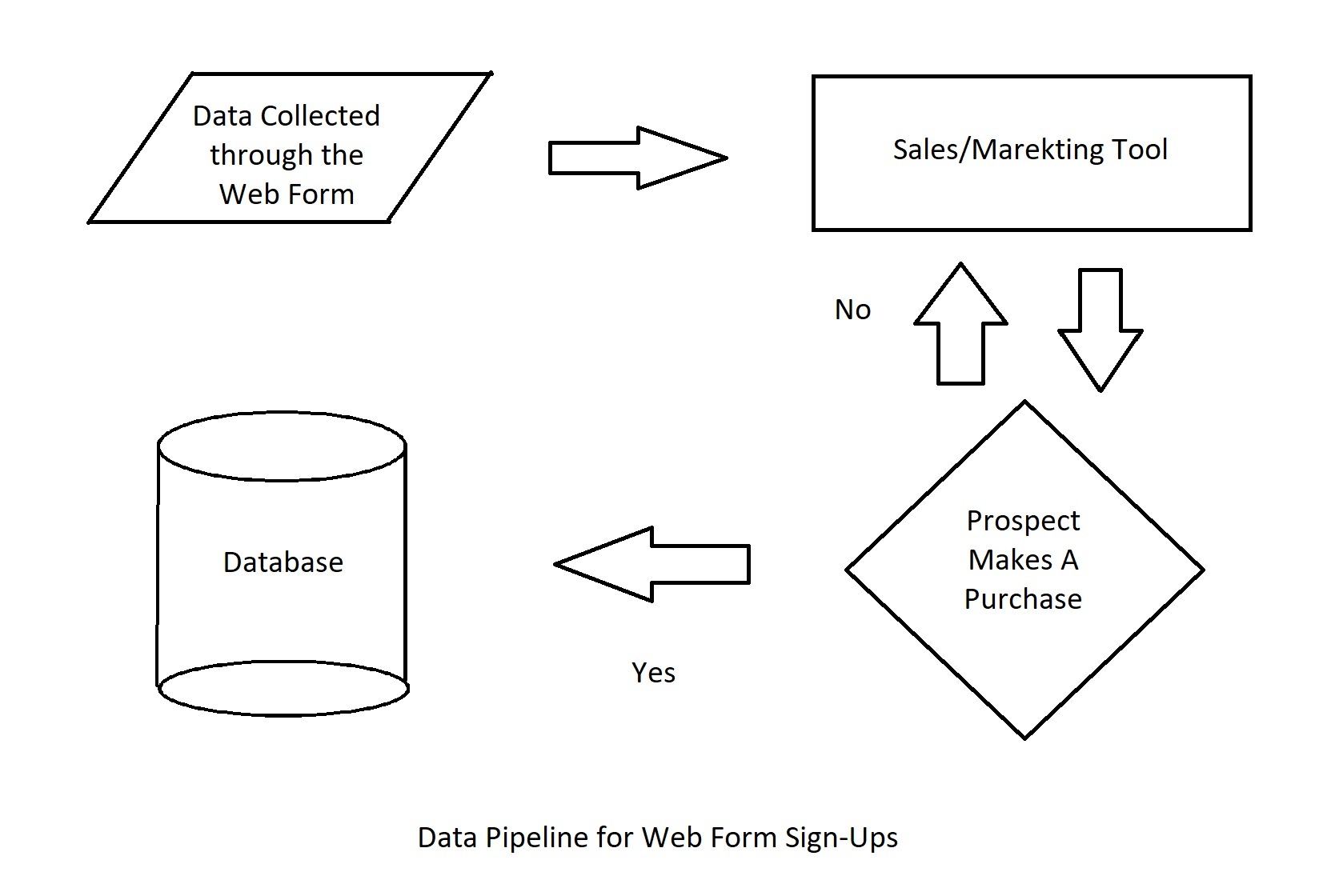
Automating this process means no human intervention at any stage. The web form should be connected to the sales/marketing tool either through direct integration or with the help of data connectors. The status should change on its own after the prospect purchases the product, and the data should travel to the main database once the prospect’s status changes to that of a customer.
Complete automation of data governance can be achieved once workflows have been placed to ensure data quality as well as all processes (such as the example above) require little to no manual interference.
ML Pipeline Automation
Automation allows machine learning to scale. Automating the machine learning pipeline results in a faster iteration cycle and better performance monitoring and testing.
In an automated machine learning pipeline, data extraction, validation, preparation/labeling, training of the ML model, and evaluation and validation of the model are all automated. Automating the ML pipeline is now a standard part of training a machine learning algorithm because the manual alternative is neither scalable nor feasible.
In general, just the data labeling process alone requires multiple people working for weeks (or even months, depending on the scale of the project), labeling data for machine learning algorithms. In an automated machine learning pipeline, each component of the pipeline is codified.
- Data extraction – automated through intelligent document processing, where intelligent tools go through documents and extract data relevant to the project.
- Data validation – automated through scripts written in programming languages or specialized tools for data validation.
- Data preparation/labeling – partially automated through active learning or completely automated through programmatic labeling.
- Training the ML model – automated with the help of SnapLogic’s AutoML Snap.
- Evaluation and validation of the ML model – automated with the help of custom code that feeds test data to multiple ML models.
When each individual step of the pipeline is automated, you just need data connectors to enable the flow of data from one process to another, and complete automation is achieved.
Achieve IT Automation with SnapLogic
We live in the era of hyper-automation. One of the biggest requirements for the automation of data governance, the ETL process, or any kind of data migration process is to be able to create workflows that move the data between different apps. Creating custom applications to achieve automation requires a lot of coding and development. SnapLogic offers a low-code option to help your applications talk to each other. Explore SnapLogic’s data integration platform to see how it can help with IT automation in your organization.
Looking for more information on data integration and automation? SnapLogic has created The Ultimate Guide to Data Integration just for you.







