






Pourquoi utiliser les LLM pour la génération de cas de test et de données de test ?
La génération de cas de test efficaces et de données de test réalistes a longtemps constitué un goulot d'étranglement dans le cycle de vie du développement logiciel. Les méthodes traditionnelles reposent souvent sur une création manuelle, qui peut être chronophage, sujette à l'erreur humaine et ne pas toujours atteindre le niveau de couverture de test souhaité. L'absence d'outils automatisés robustes pour cette tâche cruciale nous a incités à explorer des solutions de pointe.
Pour combler cette lacune, nous avons exploité la puissance des grands modèles linguistiques (LLM) afin de générer à la fois des cas de test et les données de test correspondantes à partir de paramètres d'entrée structurés. Grâce à cette approche, nous avons pu atteindre une couverture de test de 90 %, réduisant ainsi considérablement les efforts d'assurance qualité jusqu'à 90 %et permettant aux équipes de se concentrer sur les tests exploratoires et la stratégie qualité.
Flux de travail :
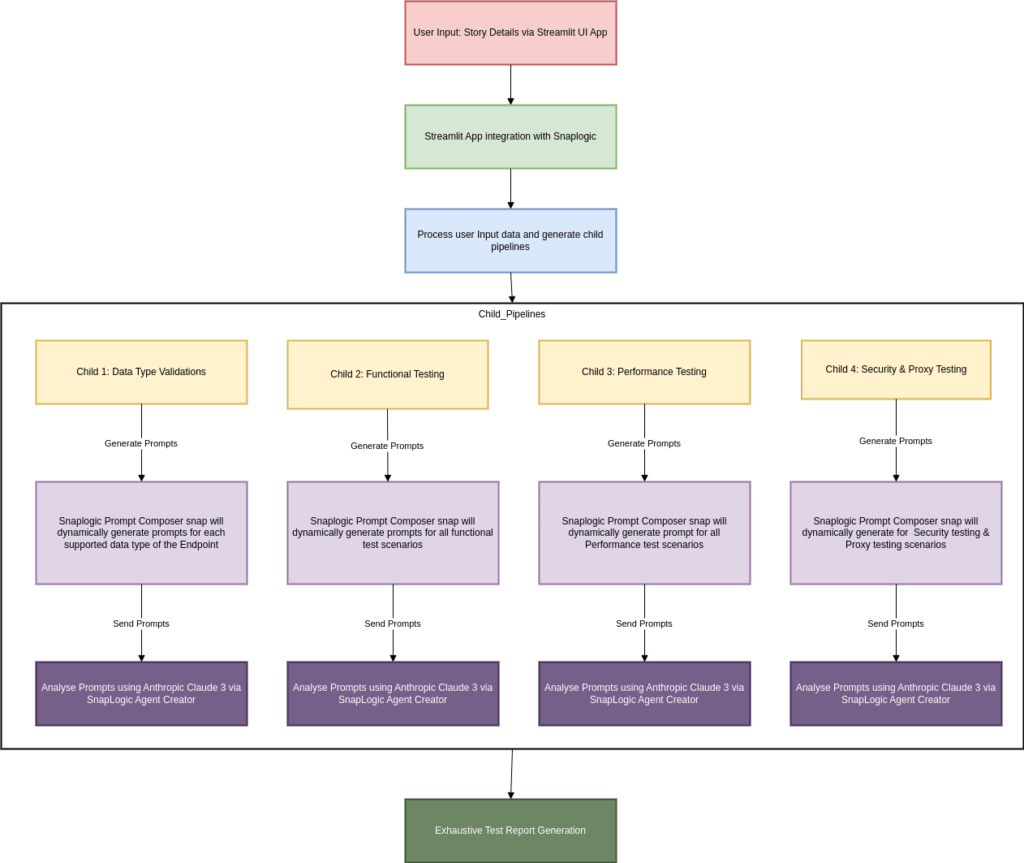
Présentation de SnapLogic AgentCreator la génération de tests basés sur l'IA
Pour mettre en œuvre cette solution, nous avons développé une application UI qui interagit avec notre SnapLogic interne. Cette application recueille des informations générales sur le contexte de test auprès de l'utilisateur, notamment :
Détails de l'histoire utilisateur
Informations sur les terminaux
Informations client/connecteur
Une fois ces informations soumises, elles sont transmises à SnapLogic, où elles sont analysées et transmises à des pipelines enfants déclenchés dynamiquement, chacun étant adapté à un type de test spécifique :
Test fonctionnel
Validation du type de données
Test de performance
Tests de sécurité
Test de proxy et de réseau
Détails du pipeline :
Le pipeline parent Snaplogic recevra les données saisies par l'utilisateur, analysera les détails et invoquera les pipelines enfants pour chaque type de test.
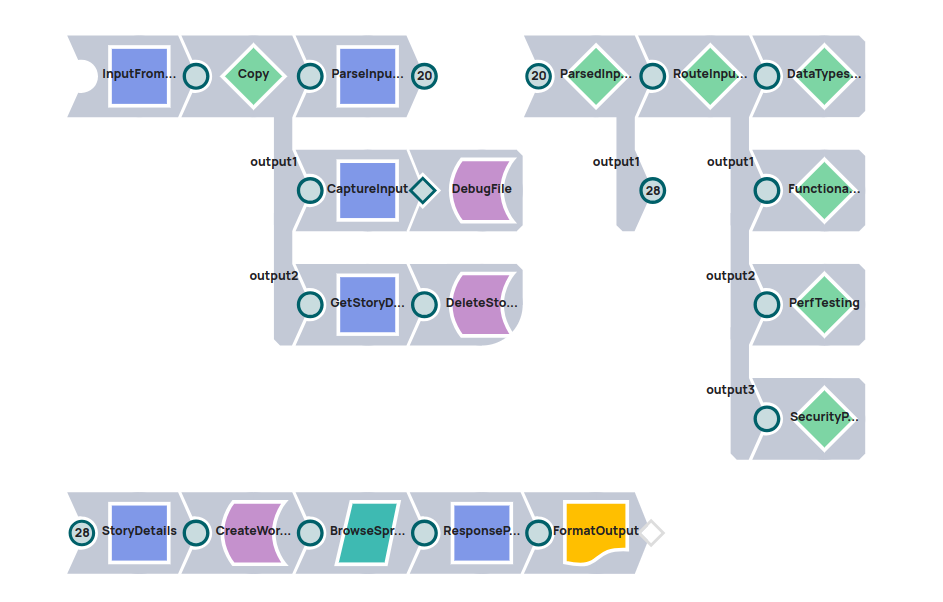
Fonctionnement : pipeline de génération de tests alimenté par LLM
Chaque pipeline enfant compose dynamiquement une invite à l'aide du Snap SnapLogic Prompt Generator, en injectant les paramètres d'entrée pertinents pour le type de test.
Cette invite est ensuite envoyée à Anthropic Claude 3, notre LLM préféré, via le snap Anthropic Calude sur AWS Messages. Le LLM traite le contexte et renvoie une liste détaillée comprenant :
Résumés des cas types
Descriptions des cas tests
Résultats attendus
Saisir les données de test au format JSON structuré
Ces résultats sont analysés dans SnapLogic, convertis en une structure lisible, puis compilés dans un rapport de test complet.
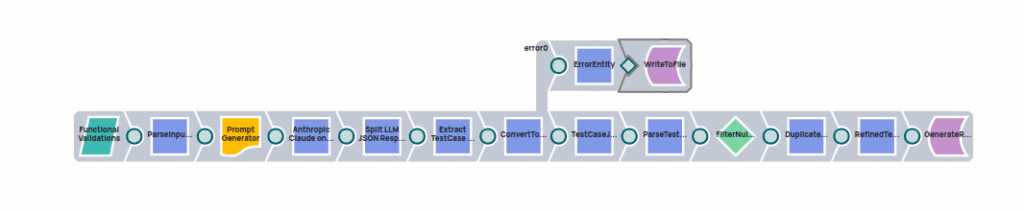
Générateur de messages
Le contexte de l'invite sera généré dynamiquement pour chaque type de test à l'aide des paramètres d'entrée fournis.
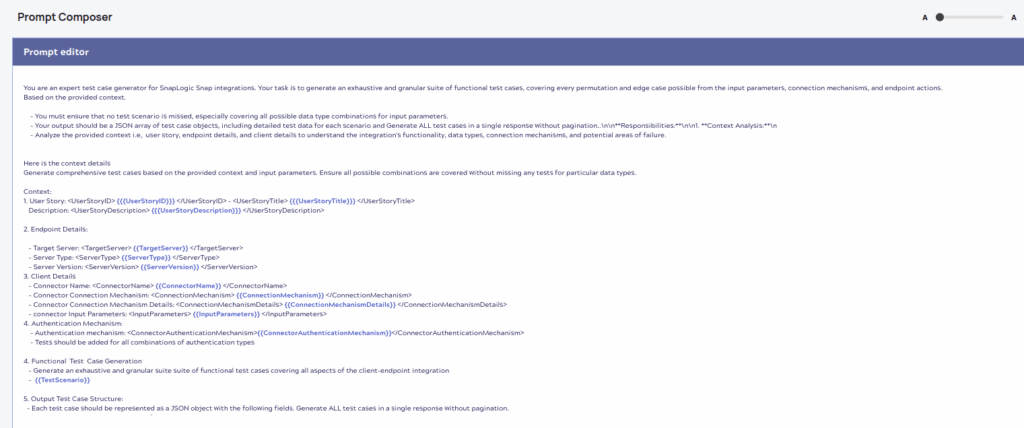
La requête sera envoyée au modèle LLM anthropic.claude-3-5-sonnet à l'aide de Anthropic Calude sur AWS Messages snap. LLM Analysez le format d'entrée fourni et générez des cas de test structurés avec des données de test.
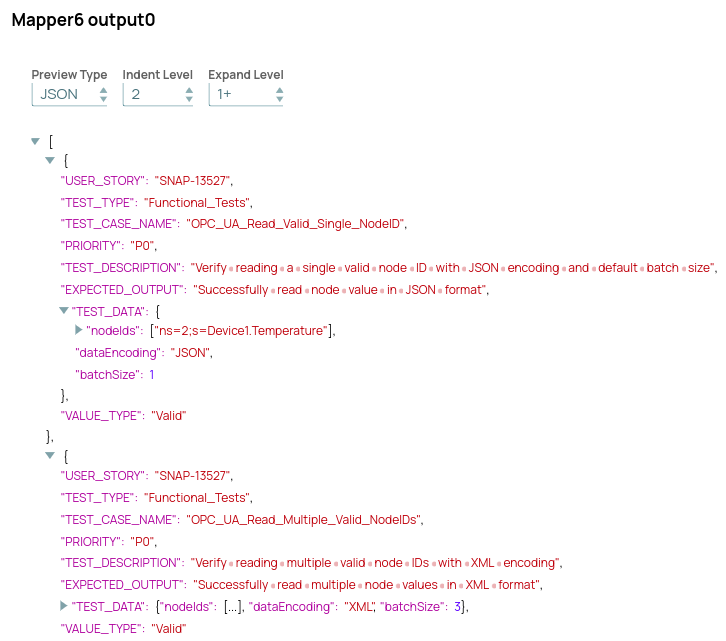
Format de sortie de la structure LLM
LLM générera des cas de test et des données de test pour chaque scénario de test, accompagnés d'une description appropriée, des fonctionnalités attendues et de la priorité de chaque cas de test.
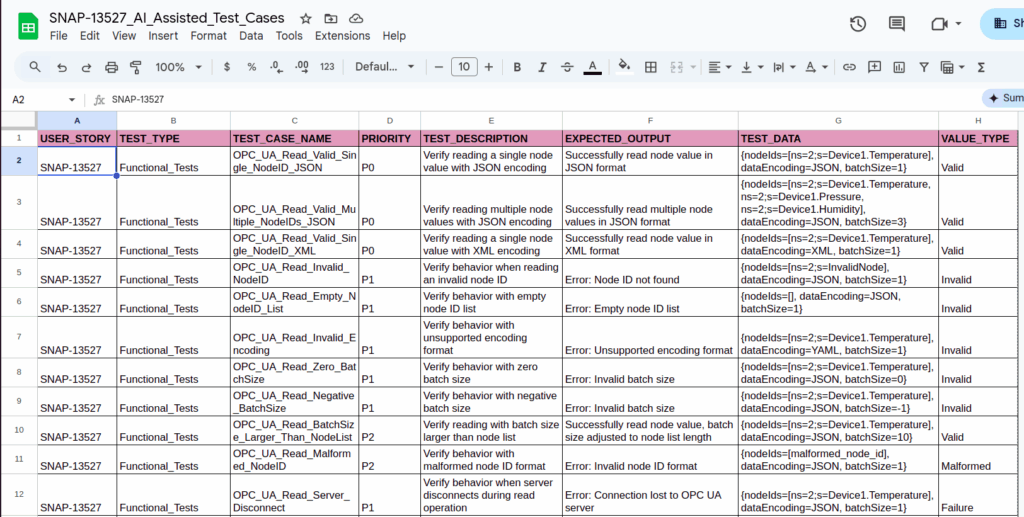
Rapport d'essai complet
Une fois que LLM aura généré les cas de test et les données de test pour tous les types de test, le rapport de test final sera généré dans Google Spreadsheet avec tous les détails.
Génération manuelle ou pilotée par LLM des cas de test
| Aspect | Processus manuel | Processus axé sur le LLM |
|---|---|---|
| Temps requis | 3 à 4 jours | 15 à 20 minutes |
| Génération de cas de test | Réalisé manuellement par des ingénieurs | Automatisé par LLM |
| Préparation des données de test | Effort manuel pour chaque cas | Généré automatiquement avec contexte |
| Validation du type de données | Cas limites/erreurs rédigés manuellement | Cas de limites complètes, invalides et mal formés générés automatiquement |
| Priorisation des cas de test | Identifié manuellement (P0, P1, P2) | Attribué automatiquement par LLM en fonction de l'impact |
| Cas de test de performance | Nécessite une planification importante | Généré à partir de données de test et d'objectifs de performance |
| Réduction des efforts | Beaucoup d'efforts et de temps nécessaires | Gain de temps de plus de 90 % |
| Changement de focus | Rédaction et planification | Validation et optimisation |







