






Why Use LLMs for Test Case and Test Data Generation?
Generating effective test cases and realistic test data has long been a bottleneck in the software development lifecycle. Traditional methods often rely on manual creation, which can be time-consuming, prone to human error, and may not always achieve the desired level of test coverage. The lack of robust automated tools for this crucial task has spurred us to explore cutting-edge solutions.
To bridge this gap, we’ve harnessed the power of Large Language Models (LLMs) to generate both test cases and corresponding test data from structured input parameters. With this approach, we’ve been able to achieve 90% test coverage, significantly reducing QA effort by up to 90%—freeing teams to focus on exploratory testing and quality strategy.
Workflow:
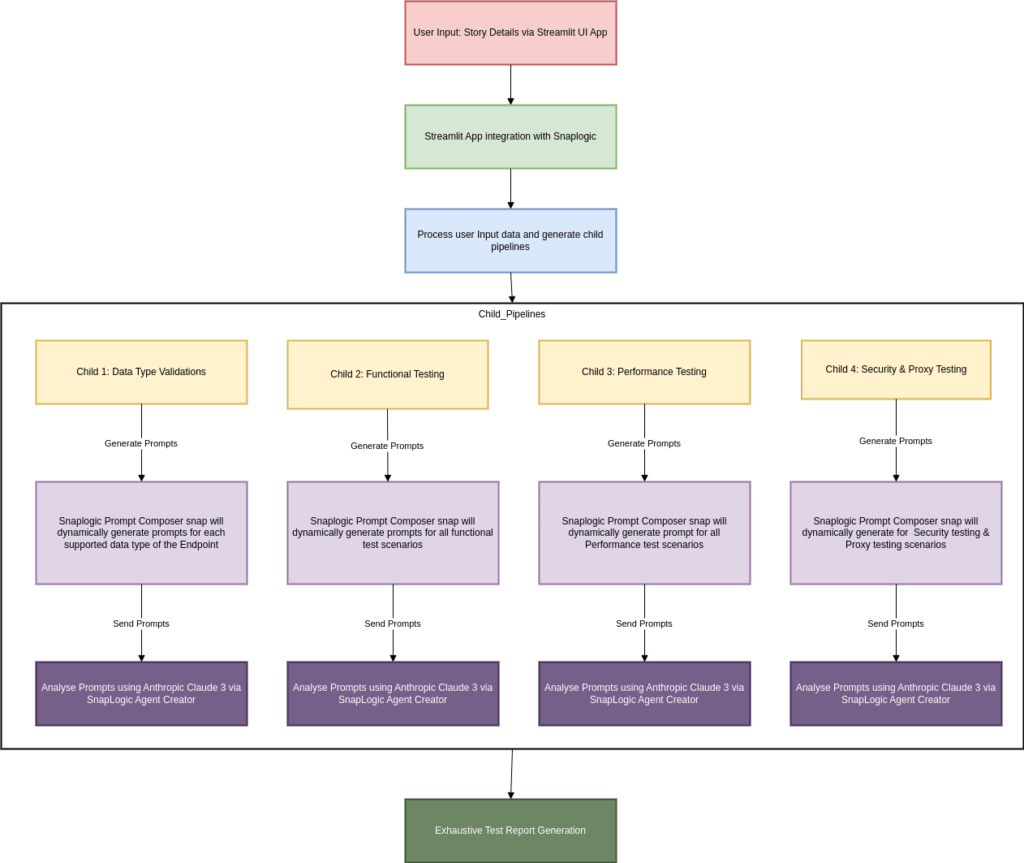
Introducing SnapLogic AgentCreator for AI-Based Test Generation
To operationalize this solution, we built a UI application that interacts with our internal SnapLogic . This app collects high-level testing context from the user, including:
User Story Details
Endpoint Information
Client/Connector Information
Once this information is submitted, it is routed to SnapLogic, where the input is parsed and passed to dynamically triggered child pipelines, each tailored for a specific test type:
Functional Testing
Data Type Validation
Performance Testing
Security Testing
Proxy and Network Testing
Pipeline Details:
Snaplogic parent pipeline will receive the user input and parse the details and invoke child pipelines for each test type
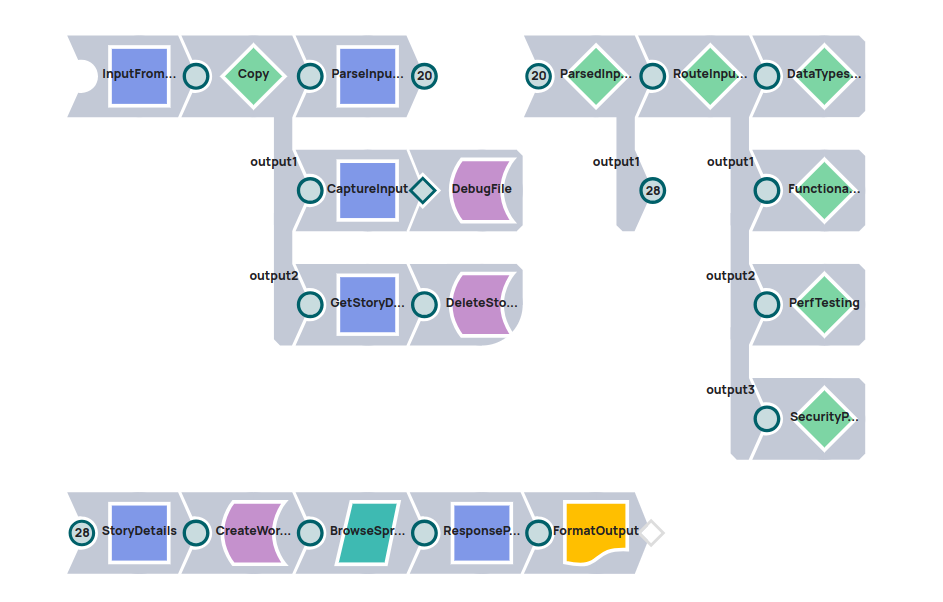
How It Works: LLM-Powered Test Generation Pipeline
Each child pipeline dynamically composes a prompt using the SnapLogic Prompt Generator Snap, injecting the input parameters relevant to the test type.
This prompt is then sent to Anthropic Claude 3, our preferred LLM, via the Anthropic Calude on AWS Messages snap. The LLM processes the context and returns a detailed list of:
Test Case Summaries
Test Case Descriptions
Expected Outputs
Input Test Data in structured JSON format
These results are parsed within SnapLogic, converted into a readable structure, and compiled into a comprehensive test report.
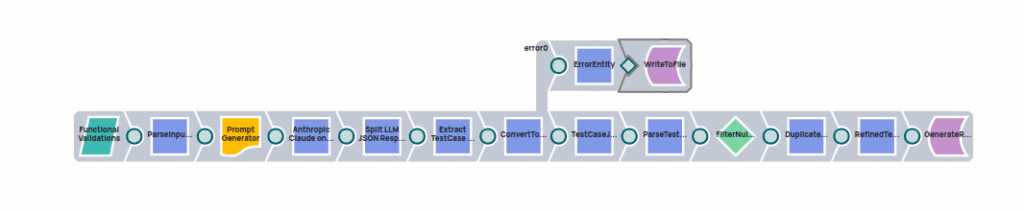
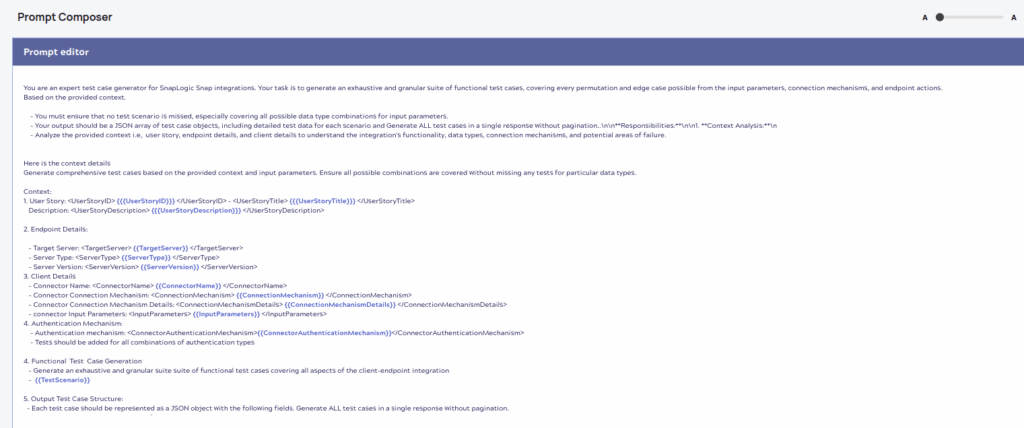
Prompt Generator
Prompt context will be generated dynamically for each test type with the provided input parameters.
Prompt will be sent to anthropic.claude-3-5-sonnet LLM model using Anthropic Calude on AWS Messages snap. LLM Analyse the provided input format and generate structured test cases with test data
LLM Structure Output Format
LLM will generate Test cases and Test Data for each test scenario along with proper description, Expected Functionality and Priority of each test case.
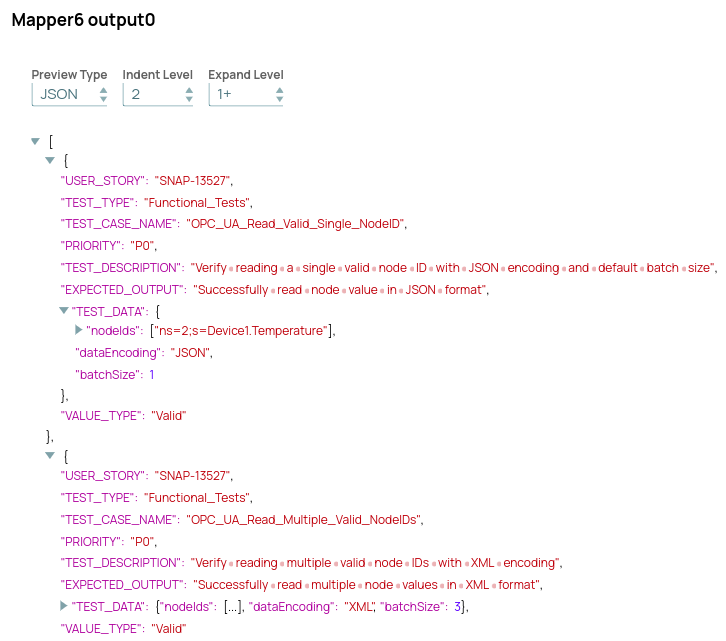
Comprehensive Test Report
Once LLM generate Test cases and Test data for all the test types then final test report will be generated in Google Spreadsheet with all the details
Manual vs LLM-Driven Test Case Generation
| Aspect | Manual Process | LLM-Driven Process |
|---|---|---|
| Time Required | 3 to 4 days | 15 to 20 Minutes |
| Test Case Generation | Done manually by engineers | Automated by LLM |
| Test Data Preparation | Manual effort for each case | Auto-generated with context |
| Data Type Validation | Manually written edge/error cases | Full boundary, invalid, and malformed cases auto-generated |
| Test Case Prioritization | Manually identified (P0, P1, P2) | Auto-assigned by LLM based on impact |
| Performance Test Cases | Requires significant planning | Generated with test data and performance goals |
| Effort Reduction | High effort and time-consuming | 90%+ time savings |
| Focus Shift | Writing and planning | Validation and optimization |







