






Le traitement multimodal dans l'IA générative représente une avancée révolutionnaire dans la manière dont les systèmes d'IA extraient et synthétisent simultanément des informations provenant de plusieurs types de données, telles que du texte, des images, de l'audio et de la vidéo. Contrairement aux modèles d'IA traditionnels à modalité unique, qui se concentrent sur un seul type de données, les systèmes multimodaux intègrent et traitent divers flux de données en parallèle, créant ainsi une compréhension holistique de scénarios complexes. Cette approche intégrée est essentielle pour les applications qui nécessitent non seulement des informations isolées provenant d'une seule modalité, mais aussi une synthèse cohérente entre différentes sources de données, ce qui permet d'obtenir des résultats plus riches et plus précis sur le plan contextuel.
L'IA générative, grâce au traitement multimodal, redéfinit l'extraction de texte, surpassant l'OCR traditionnel en interprétant le texte dans son environnement visuel et contextuel. Contrairement à l'OCR, qui se contente de convertir des images en texte, l'IA générative analyse le contexte, la mise en page et la signification de l'image environnante, améliorant ainsi la précision et la profondeur. Par exemple, dans des documents complexes, elle peut faire la différence entre les titres, le corps du texte et les annotations, structurant ainsi les informations de manière plus intelligente. De plus, elle excelle dans les textes de mauvaise qualité ou multilingues, ce qui la rend précieuse dans les secteurs qui exigent une interprétation précise et nuancée.
Dans l'analyse vidéo, une IA générative équipée d'un traitement multimodal peut interpréter simultanément les éléments visuels d'une scène, l'audio (comme les dialogues ou les sons d'arrière-plan) et tout texte associé (comme les sous-titres ou les métadonnées). Cela permet à l'IA de produire une description ou un résumé de la scène beaucoup plus nuancé que ce qui pourrait être obtenu en analysant uniquement la vidéo ou l'audio. L'interaction entre ces modalités garantit que la description générée reflète non seulement le contenu visuel et auditif, mais aussi le contexte et la signification plus profonds qui découlent de leur combinaison.
Dans des tâches telles que la légende d'images, les systèmes d'IA multimodaux vont au-delà de la simple reconnaissance d'objets dans une photo. Ils peuvent interpréter la relation sémantique entre l'image et le texte qui l'accompagne, améliorant ainsi la pertinence et la spécificité des légendes générées. Cette capacité est particulièrement utile dans les domaines où le contexte fourni par une modalité influence considérablement l'interprétation d'une autre, comme dans le journalisme, où les images et les rapports écrits doivent s'aligner de manière significative, ou dans l'éducation, où les supports visuels sont intégrés au texte pédagogique.
Le traitement multimodal permet à l'IA de synthétiser des images médicales (telles que des radiographies ou des IRM) avec les antécédents du patient, les notes cliniques et même les interactions en direct entre le médecin et le patient dans des applications hautement spécialisées telles que les diagnostics médicaux. Cette analyse complète permet à l'IA de fournir des diagnostics et des recommandations de traitement plus précis, en tenant compte de l'interaction complexe entre les symptômes, les données historiques et les diagnostics visuels. De même, dans le domaine du service à la clientèle, les systèmes d'IA multimodaux peuvent améliorer la qualité de la communication en analysant le contenu textuel de la demande d'un client ainsi que le ton et le sentiment de sa voix, ce qui permet d'obtenir des réponses plus empathiques et plus efficaces.
Au-delà des cas d'utilisation individuels, le traitement multimodal joue un rôle crucial dans l'amélioration des capacités d'apprentissage et de généralisation des modèles d'IA. En s'entraînant sur un éventail plus large de types de données, les systèmes d'IA développent des modèles plus robustes et plus flexibles, capables de s'adapter à une plus grande variété de tâches et de scénarios. Cela est particulièrement important dans les environnements réels, où les données sont souvent hétérogènes et nécessitent une compréhension intermodale pour être pleinement interprétées.
À mesure que les technologies de traitement multimodal continuent de progresser, elles promettent de débloquer de nouvelles capacités dans divers secteurs. Dans le domaine du divertissement, l'IA multimodale pourrait améliorer les expériences médiatiques interactives en intégrant de manière transparente la voix, les éléments visuels et narratifs. Dans le domaine de l'éducation, elle pourrait révolutionner l'apprentissage personnalisé en adaptant la diffusion de contenu à différentes entrées sensorielles. Dans le domaine de la santé, la fusion des données multimodales pourrait conduire à des percées dans la médecine de précision. En fin de compte, la capacité à comprendre et à générer du contenu multimodal riche en contexte positionne l'IA générative comme une technologie fondamentale dans la prochaine vague d'innovations basées sur l'IA.
Générateur de contenu multimodal Snap
Le générateur de contenu multimodal Snap encode les fichiers ou documents entrants au format de contenu multimodal Snap, les préparant ainsi pour une intégration transparente. La sortie de ce Snap doit être connectée au générateur de messages Snap afin de compléter et formater le message pour un traitement ultérieur. Cette configuration simplifiée permet une gestion efficace du contenu multimodal au sein de l'écosystème Snap.
Les propriétés Snap
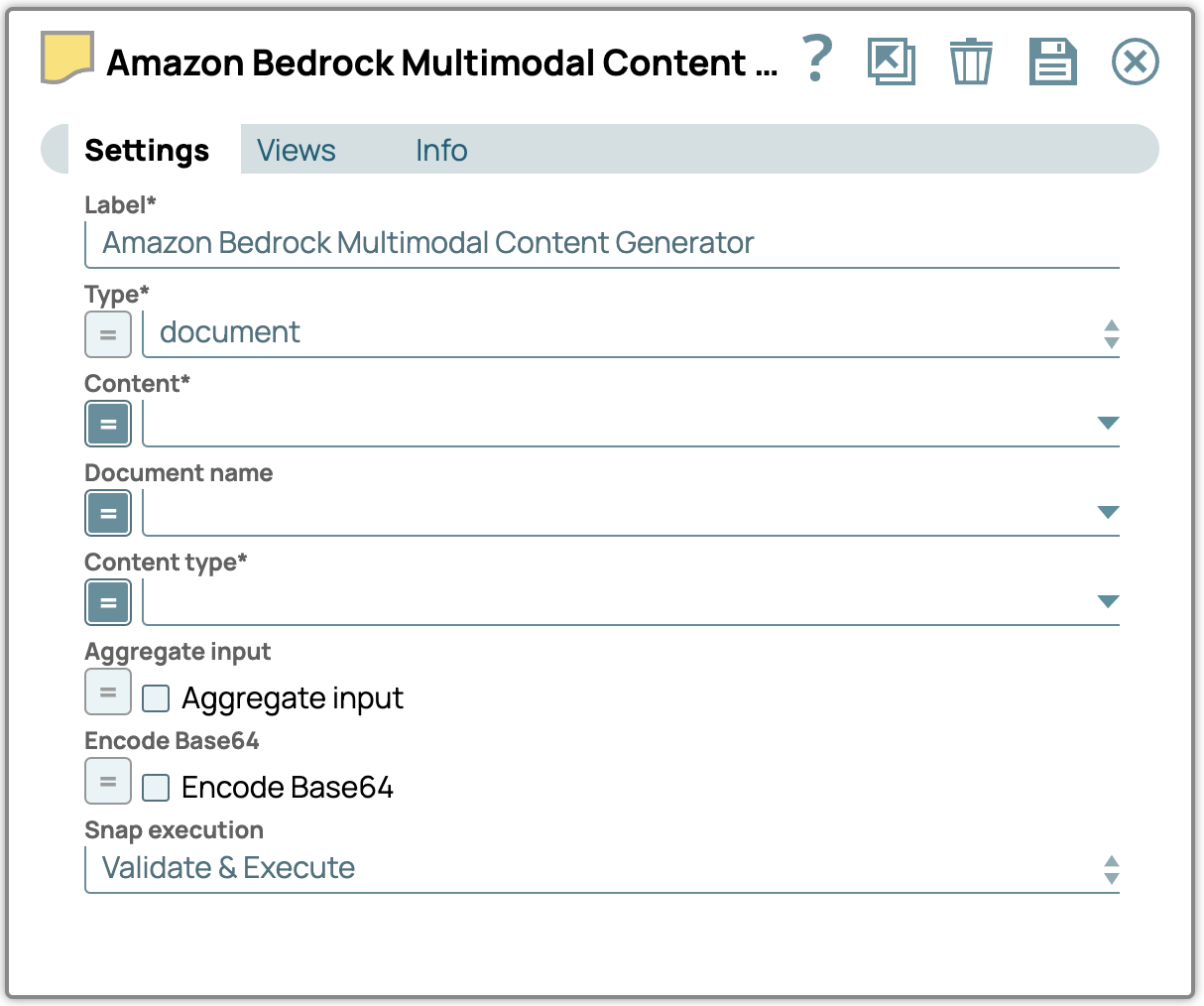
Type – Sélectionnez le type de contenu multimodal.
Type de contenu – Définissez le type de contenu spécifique pour les données transmises au LLM.
Contenu – Spécifiez le chemin d'accès au contenu multimodal à traiter.
Nom du document – Nommez le document à des fins de référence et d'identification.
Entrée agrégée – Activez cette option pour combiner toutes les entrées en un seul contenu.
Encodage Base64 – Activez cette option pour convertir le texte saisi en encodage Base64.
Remarque :
- La propriété Contenu n'apparaît que si la vue d'entrée est de type document. La valeur attribuée à Contenu doit être au format Base64 pour les entrées de type document, tandis que Snap utilisera automatiquement le format binaire comme contenu pour les types d'entrée binaires.
- Le nom du document peut être défini spécifiquement pour les types de documents multimodaux.
- La propriété Encode Base64 encode par défaut le texte saisi en Base64. Si elle n'est pas cochée, le contenu sera transmis sans encodage.
Conception d'un flux de travail multimodal rapide
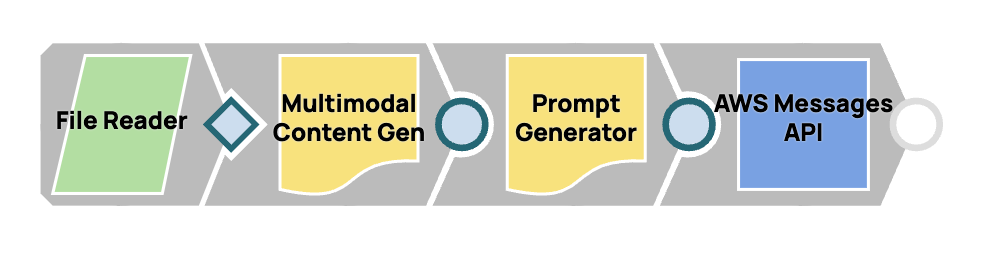
Dans ce processus, nous intégrerons plusieurs Snaps afin de créer un flux de travail fluide pour la génération de contenu multimodal et la livraison rapide. En connectant le Snap Multimodal Content Generator au Snap Prompt Generator, nous le configurons pour gérer le contenu multimodal. Le message finalisé sera ensuite envoyé à Claude par Anthropic Claude sur AWS Messages.
Étapes :
1. Ajoutez le Snap File Reader :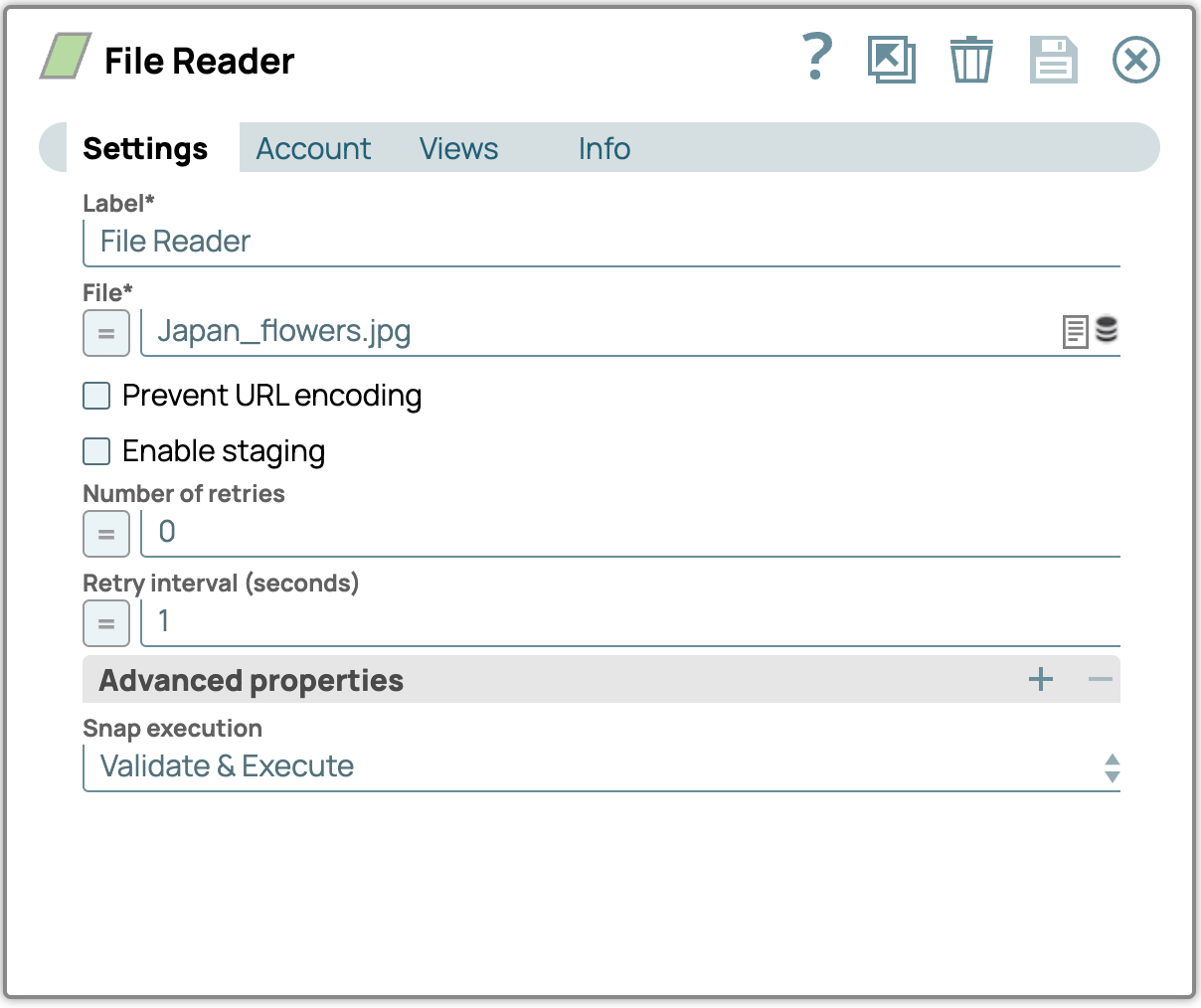
- Glissez-déposez le composant File Reader Snap sur le canevas du concepteur.
- Configurez le Snap File Reader en accédant à son panneau de paramètres, puis sélectionnez un fichier contenant des images (par exemple, un fichier PDF). Téléchargez les fichiers image d'exemple au bas de cet article si vous ne l'avez pas déjà fait.
Exemple de fichier image (Japan_flowers.jpg)

2. Ajoutez le Snap Générateur de contenu multimodal :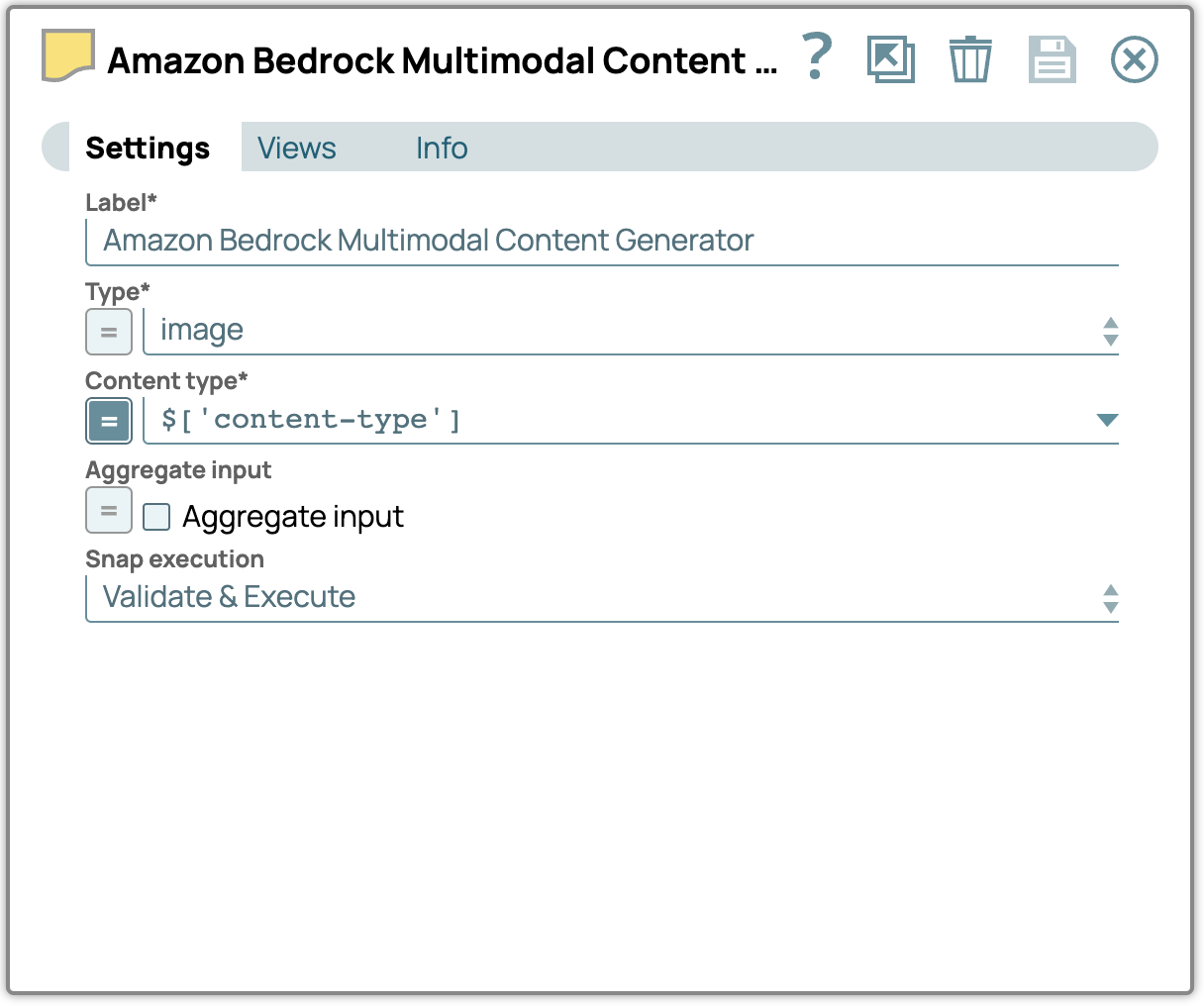
- Glissez-déposez le composant Multimodal Content Generator Snap dans le concepteur et connectez-le au composant File Reader Snap.
- Ouvrez son panneau de configuration, sélectionnez le type de fichier et spécifiez le type de contenu approprié.
- Voici une description détaillée des attributs de sortie du générateur de contenu multimodal :
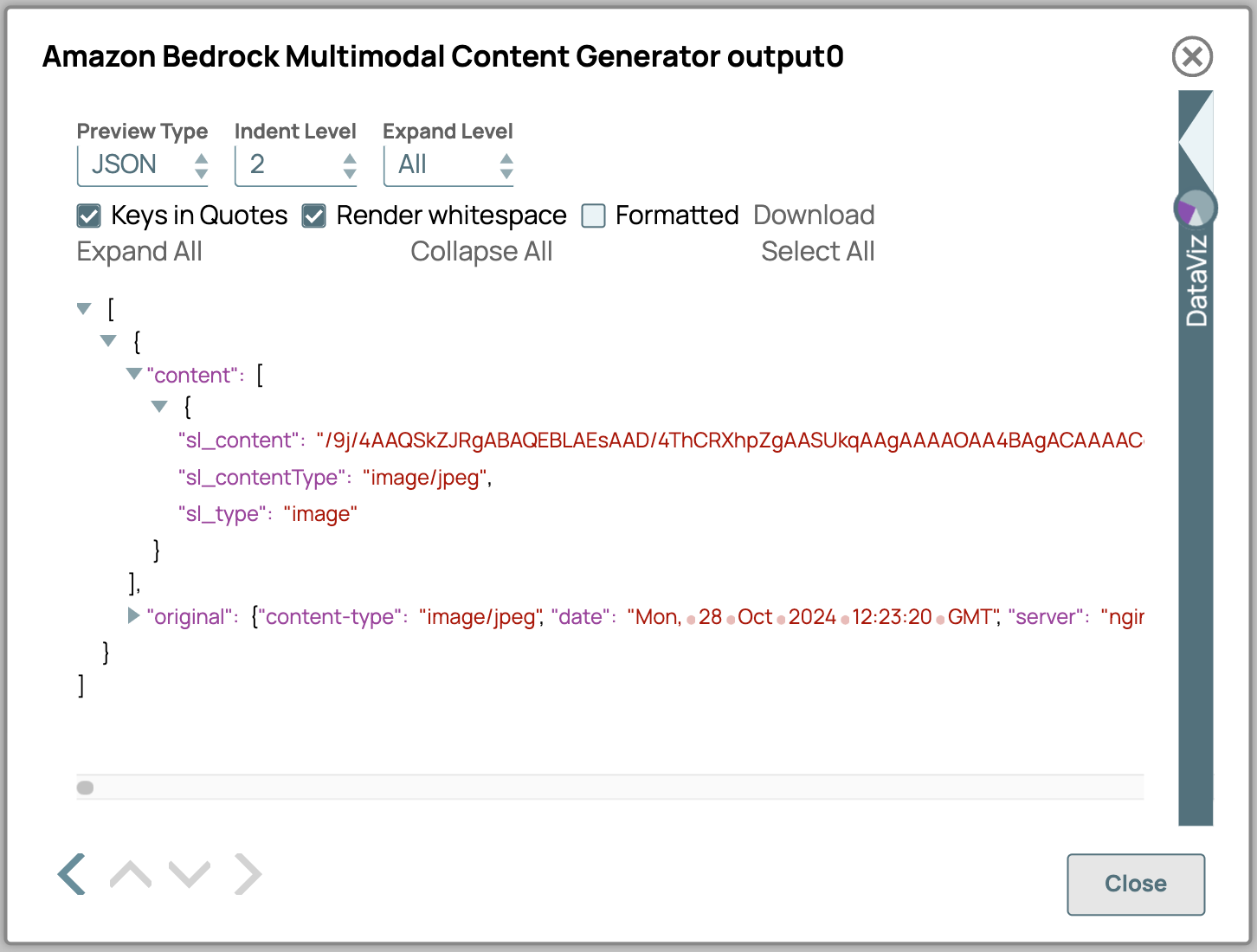
- sl_content: contient le contenu réel encodé au format Base64.
- sl_contentType: indique le type de contenu des données. Il est soit sélectionné dans la configuration, soit, si l'entrée est binaire, extrait de l'en-tête binaire.
- sl_type: Spécifie le type de contenu tel que défini dans les paramètres Snap ; dans ce cas, il affichera « image ».
3. Ajoutez le Snap Générateur de messages :
- Ajoutez le Snap Générateur de messages au concepteur et associez-le au Snap Générateur de contenu multimodal.
- Dans le panneau des paramètres, cochez la case « Advanced Prompt Output » (Sortie avancée de l'invite) et configurez la propriété « Content » (Contenu) pour utiliser les données d'entrée provenant du Snap « Multimodal Content Generator » (Générateur de contenu multimodal).
- Cliquez sur « Modifier l'invite » et saisissez vos instructions.

4. Ajouter et configurer le Snap LLM :
- Ajoutez Anthropic Claude sur AWS Message API Snap en tant que LLM.
- Connectez ce Snap au Snap Générateur de messages.
- Dans les paramètres, sélectionnez un modèle qui prend en charge le contenu multimodal.
- Cochez la case Utiliser la charge utile du message et saisissez la charge utile du message dans le champ Charge utile du message.
5. Vérifiez le résultat :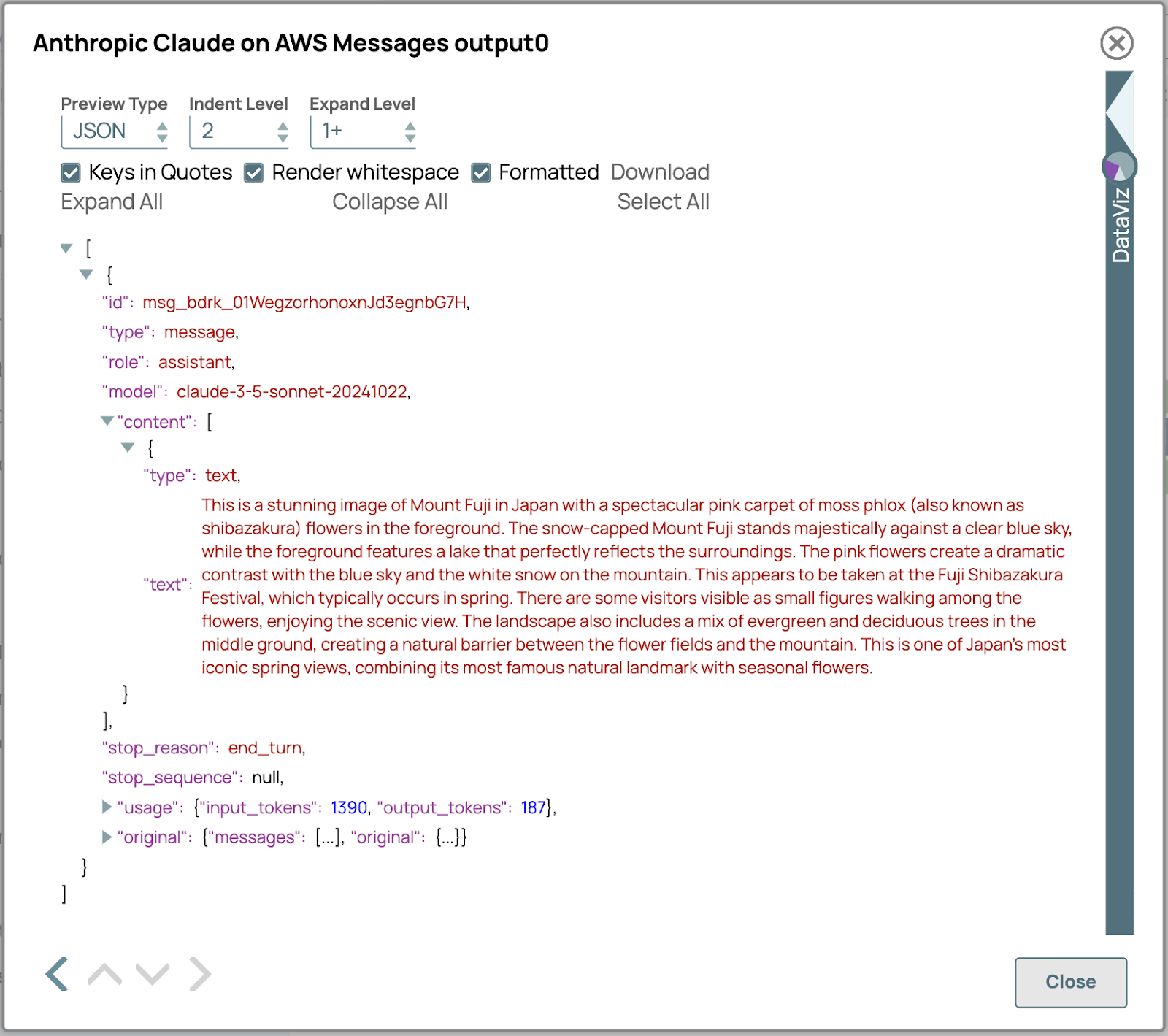
- Vérifiez le résultat généré par LLM Snap afin de vous assurer que le contenu multimodal a été traité correctement.
- Vérifiez que la réponse générée correspond au contenu et aux exigences de format attendus.
- Si des ajustements sont nécessaires, revoyez les paramètres des Snaps précédents afin d'affiner la configuration.
Modèles multimodaux pour l'extraction avancée de données
Les modèles multimodaux redéfinissent l'extraction de données en allant au-delà des capacités traditionnelles de l'OCR. Contrairement à l'OCR, qui convertit principalement des images en texte, ces modèles analysent et interprètent directement le contenu des fichiers PDF et des images, capturant des informations contextuelles complexes telles que la mise en page, le formatage et les relations sémantiques, ce que l'OCR seul ne peut pas faire. En comprenant à la fois les structures textuelles et visuelles, l'IA multimodale peut gérer des documents complexes, notamment des tableaux, des formulaires et des graphiques intégrés, sans nécessiter de processus OCR distincts. Cette approche améliore non seulement la précision, mais optimise également les workflows réduisant la dépendance aux outils OCR traditionnels.
Dans l'environnement actuel riche en données, les informations sont souvent présentées sous des formats variés, ce qui rend essentielle la capacité à analyser et à tirer des enseignements de sources de données diverses. Imaginez que vous gériez une collection de factures enregistrées au format PDF ou sous forme de photos provenant de scanners et de smartphones, où une approche rationalisée est nécessaire pour interpréter leur contenu. Les modèles linguistiques multimodaux à grande échelle (LLM) excellent dans ces scénarios, permettant une extraction transparente des informations dans tous les types de fichiers. Ces modèles prennent en charge des tâches telles que l'identification automatique des détails clés, la génération de résumés complets et l'analyse des tendances dans les factures, qu'elles proviennent de documents numérisés ou d'images. Voici un guide étape par étape pour mettre en œuvre cette fonctionnalité dans SnapLogic.
Exemples de fichiers de facturation ( téléchargez les fichiers au bas de cet article si vous ne l'avez pas déjà fait)
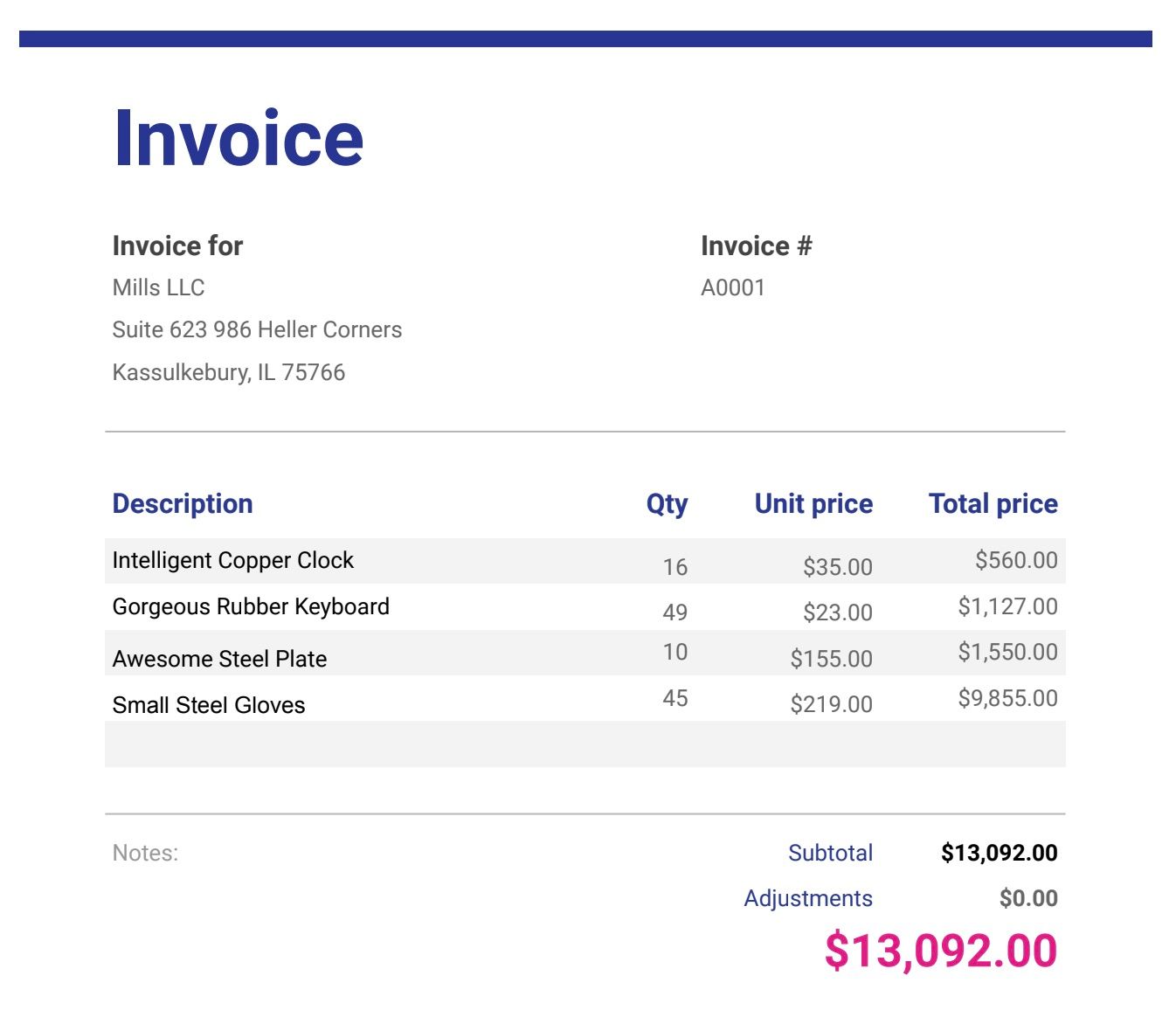
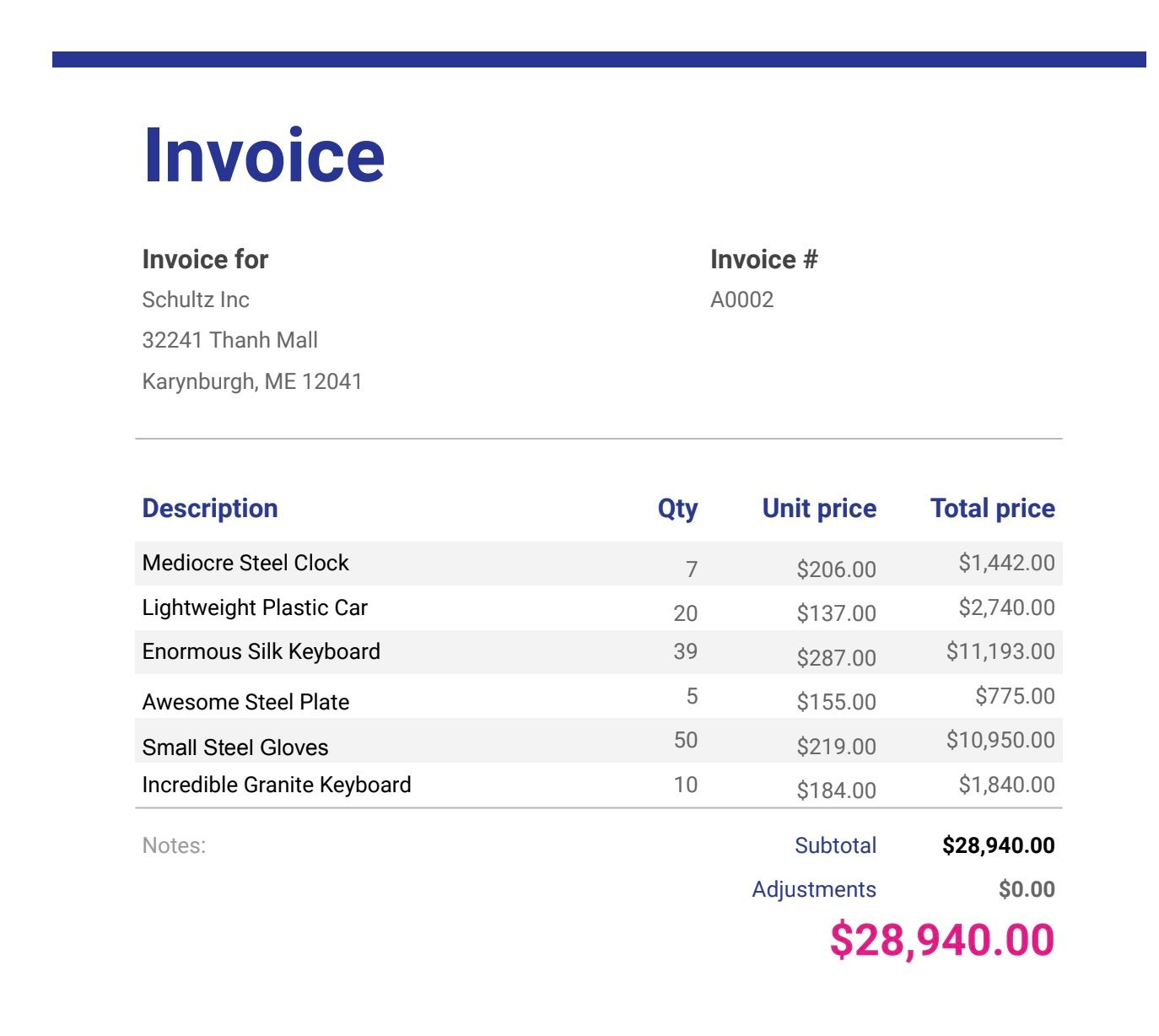
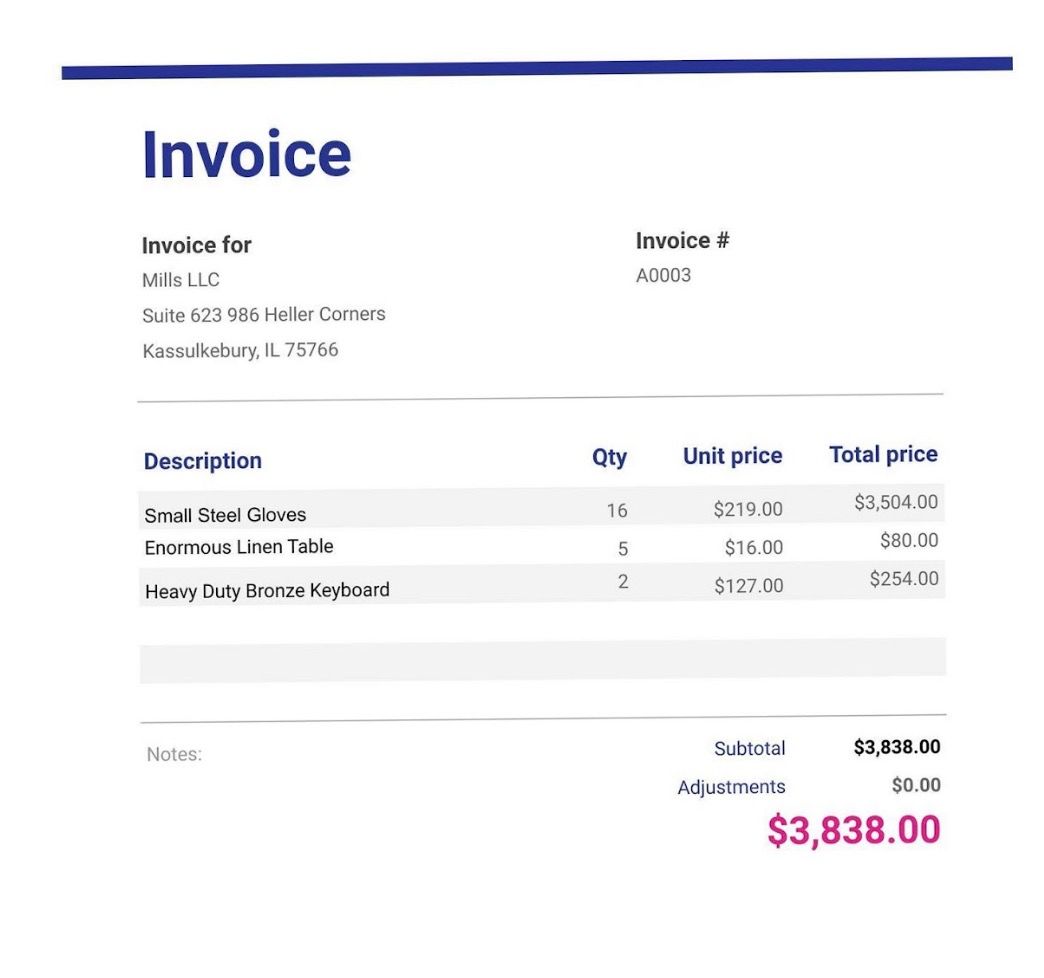
Télécharger les fichiers de facturation
- Ouvrir Gestionnaire page et accédez à votre projet qui sera utilisé pour stocker les pipelines et les fichiers associés.
- Cliquez sur le + signe (plus) et sélectionner Fichier
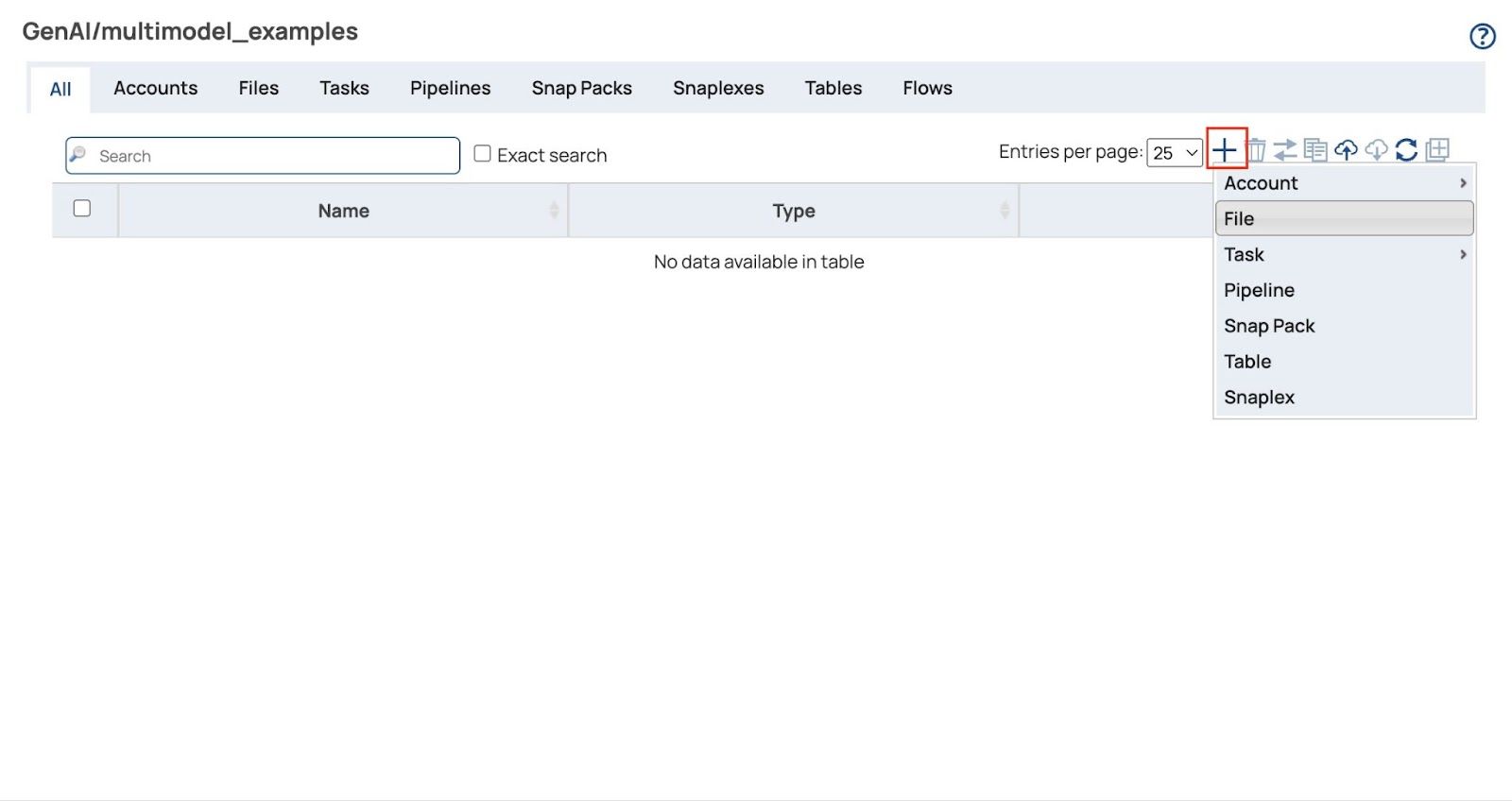
- Les Télécharger le fichier Une boîte de dialogue apparaît. Cliquez sur « Choisir les fichiers » pour sélectionner tous les fichiers de factures au format PDF et image (téléchargez les exemples de fichiers de factures au bas de cet article si vous ne l'avez pas déjà fait).
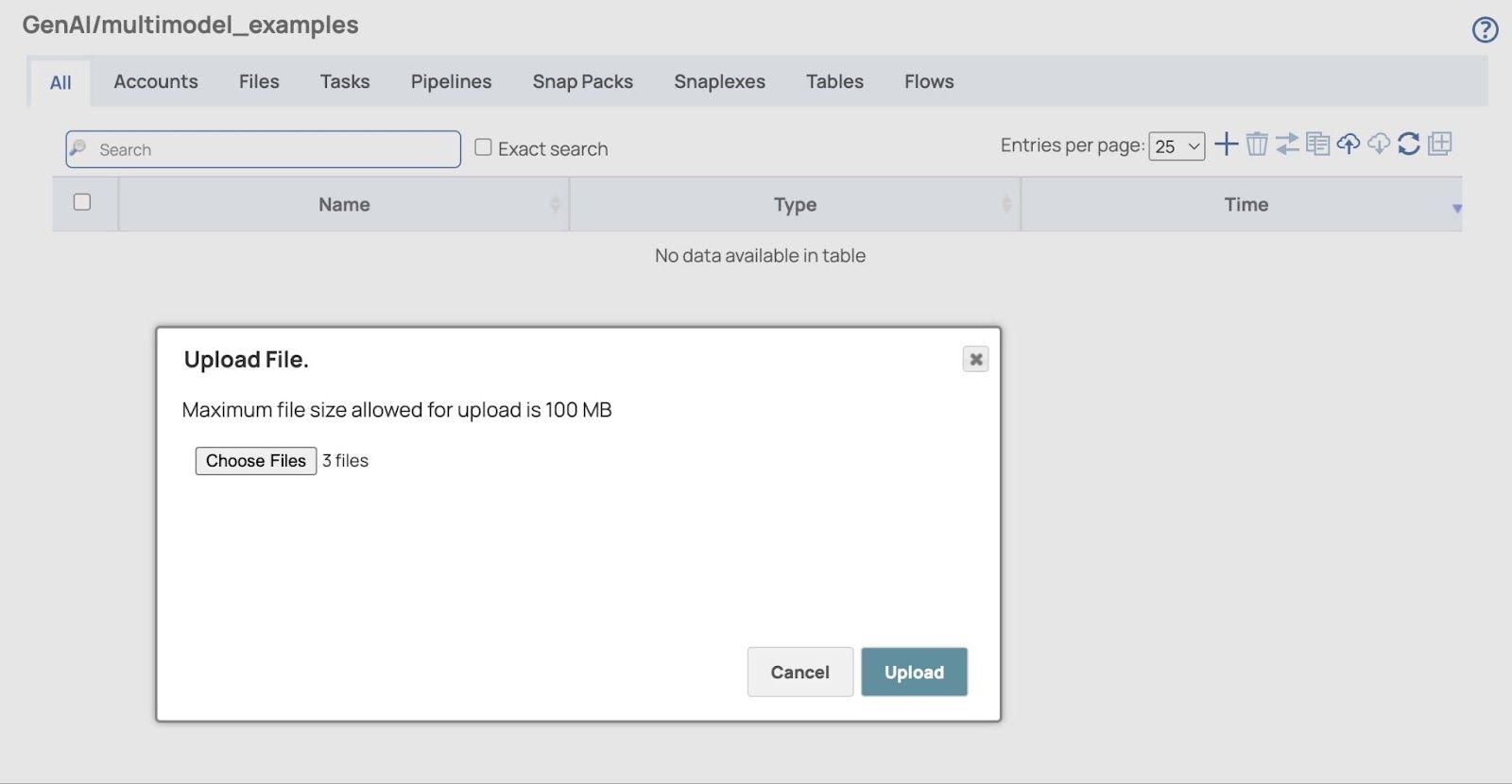
- Cliquez Télécharger bouton et les fichiers téléchargés s'afficheront.
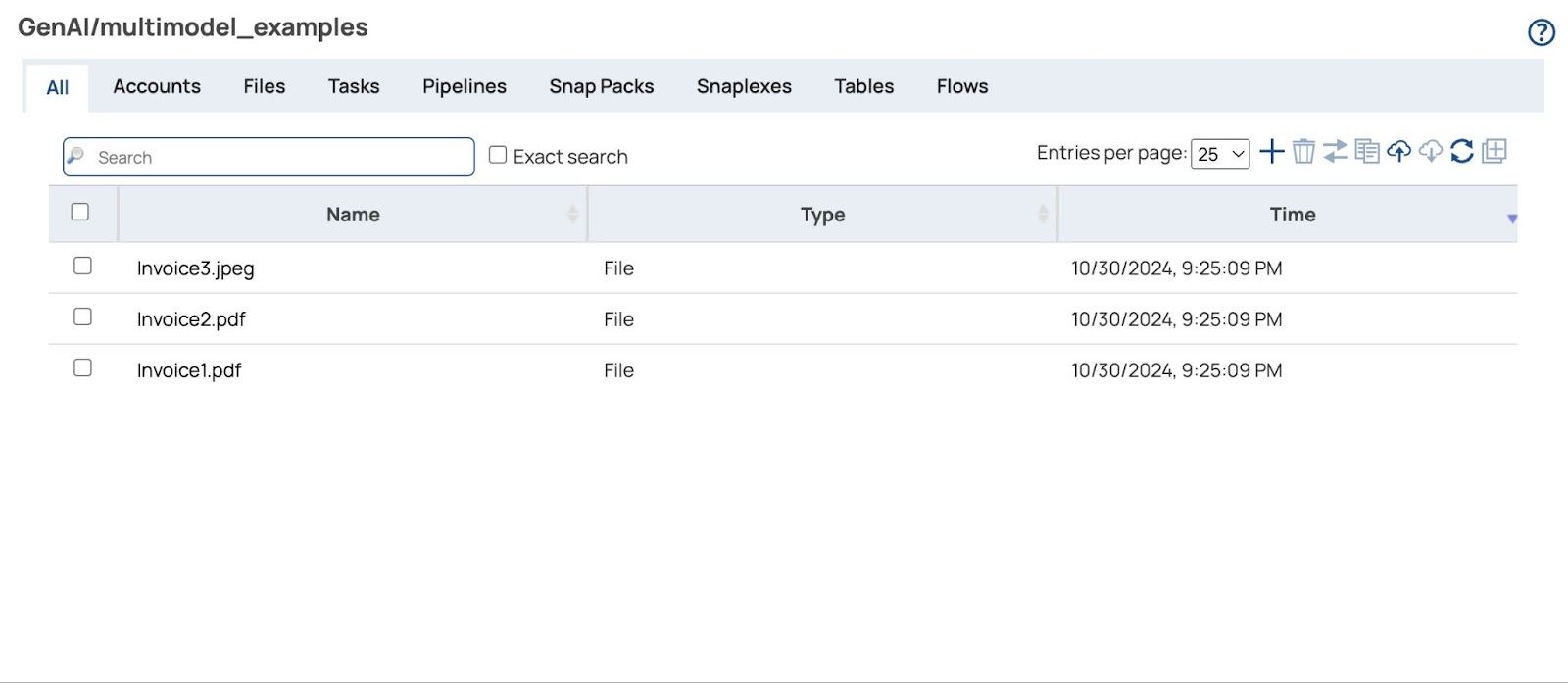
Construire le pipeline
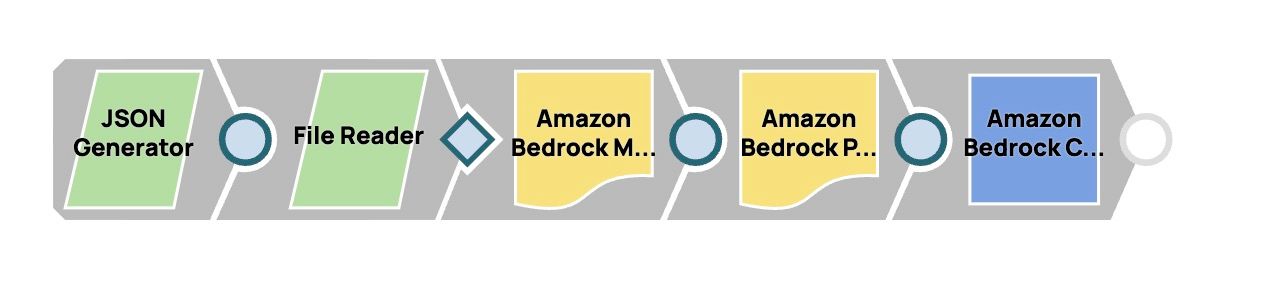
- Ajoutez le Snap JSON Generator :
- Glissez-déposez le générateur JSON sur le canevas du concepteur.
- Cliquez sur Snap pour ouvrir les paramètres, puis cliquez sur le bouton « Modifier JSON ».
- Sélectionnez tout le texte du modèle et supprimez-le.
- Collez tous les noms de fichiers de factures dans le format ci-dessous. L'éditeur devrait ressembler à ceci.
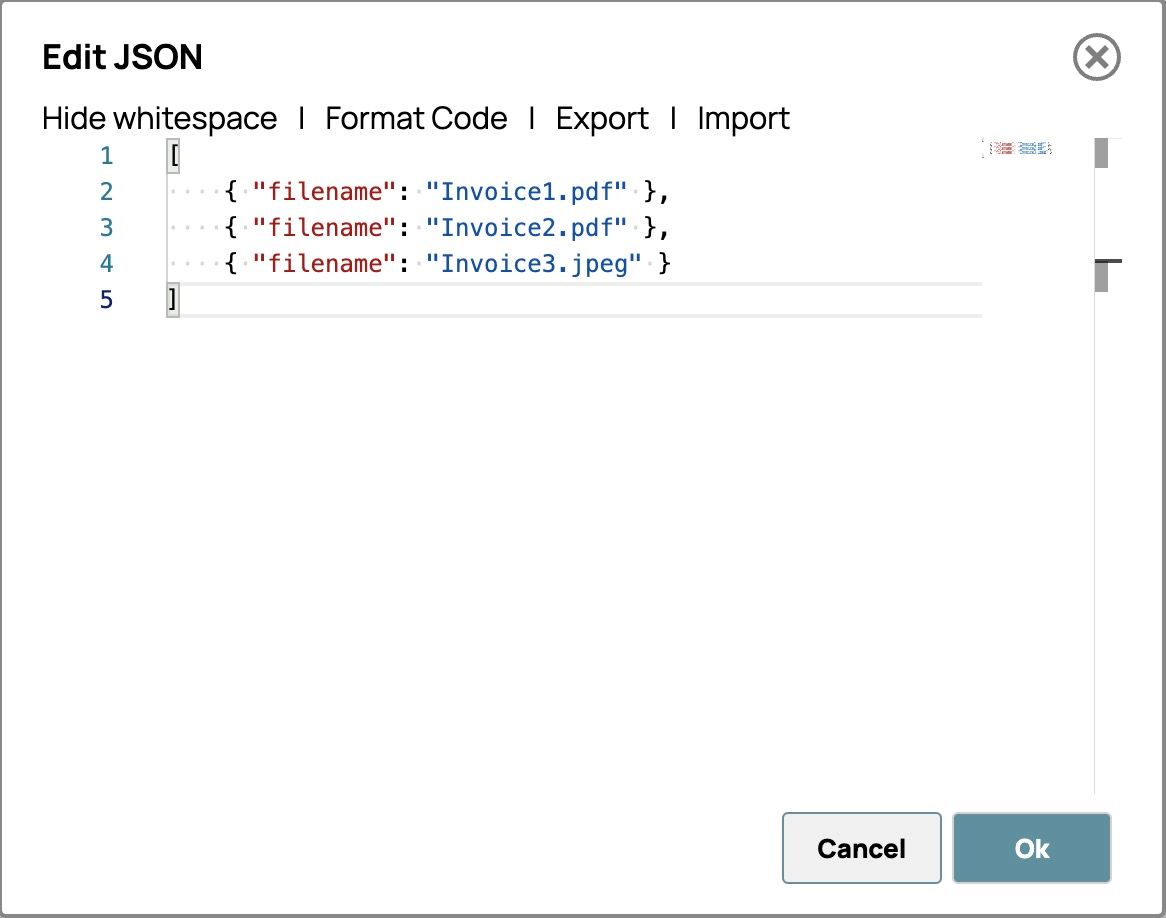
- Cliquez sur « OK » dans le coin inférieur droit pour enregistrer l'invite.
- Enregistrez les paramètres et fermez Snap.
- Ajouter le Snap Lecteur de fichiers :
- Glissez-déposez le composant File Reader Snap sur le canevas du concepteur.
- Cliquez sur le bouton « Snap » pour ouvrir le panneau de configuration.
- Connectez le Snap au Générateur JSON Appuyez sur ces étapes :
- Sélectionnez l'onglet Vues
- Cliquez sur le bouton plus (+) sur le Entrée volet pour ajouter la vue d'entrée (input0)
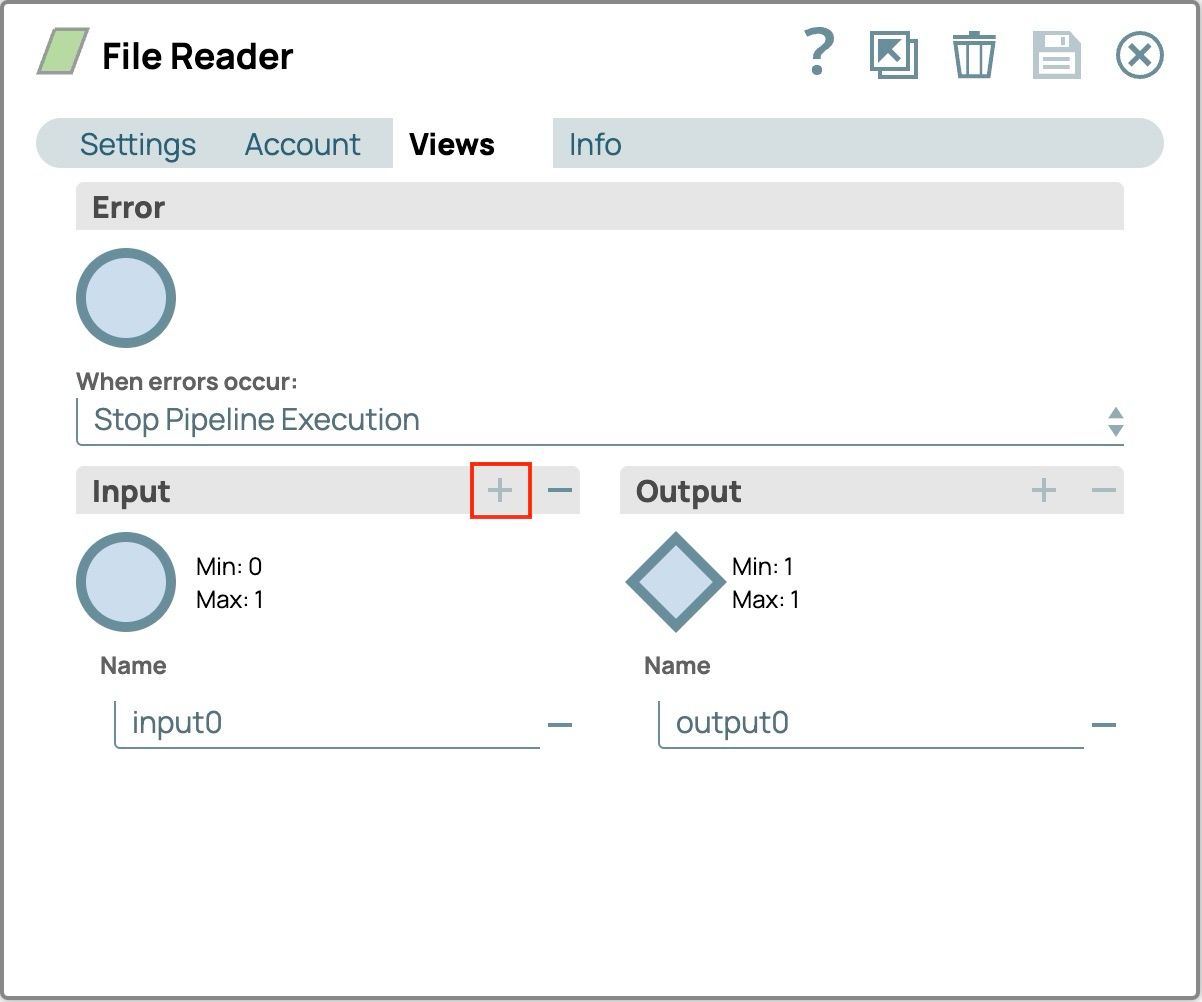
- Enregistrer la configuration
- Le Snap sur la toile affichera la vue d'entrée. Connectez-le au Snap Générateur JSON .
- Dans le panneau de configuration, sélectionnez l'onglet Paramètres.
- Définissez le Fichier champ en activant l'expression en cliquant sur le signe égal devant la saisie de texte et en le définissant sur $nom_fichier pour lire tous les fichiers que nous avons spécifiés dans le Générateur JSON Snap
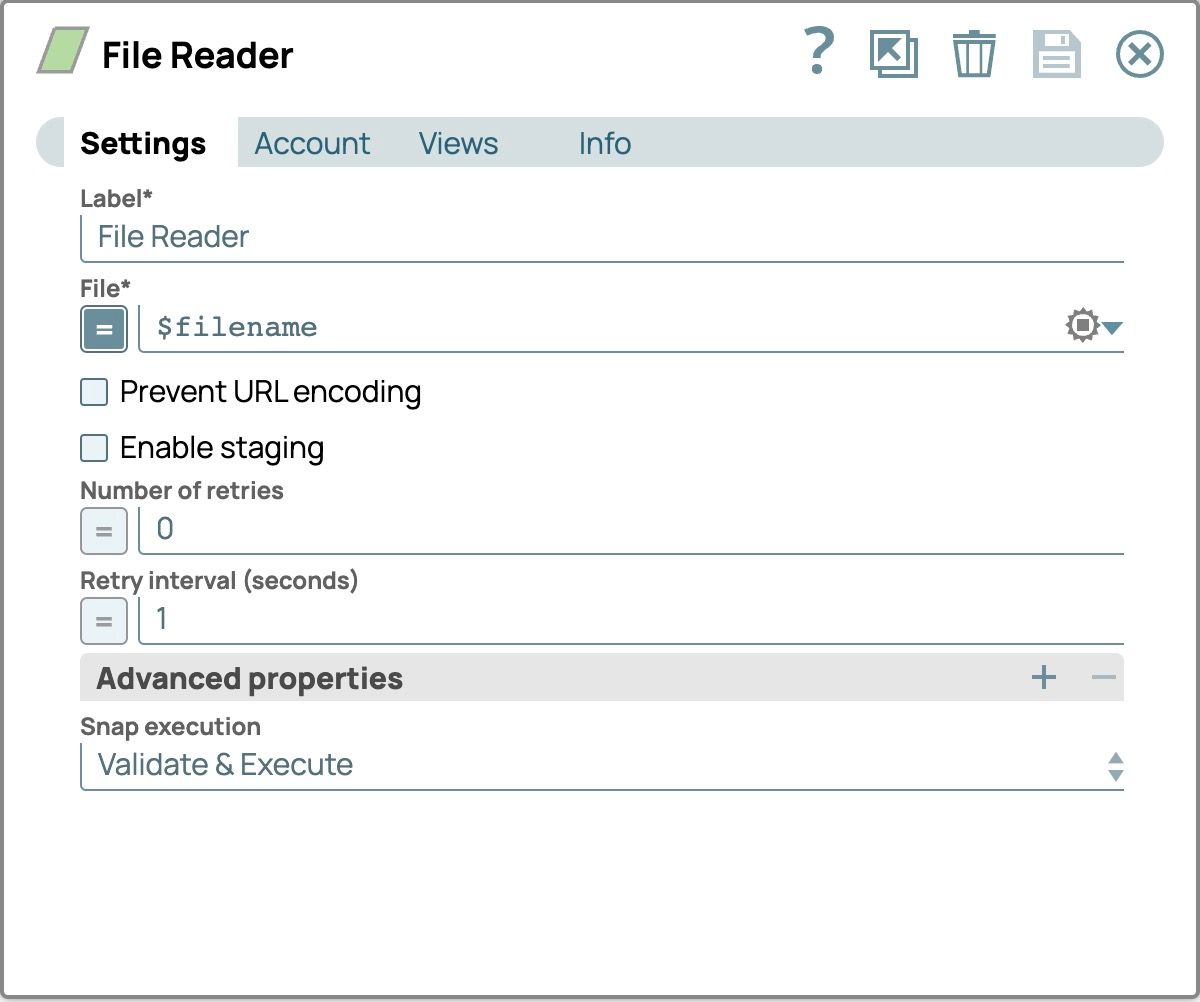
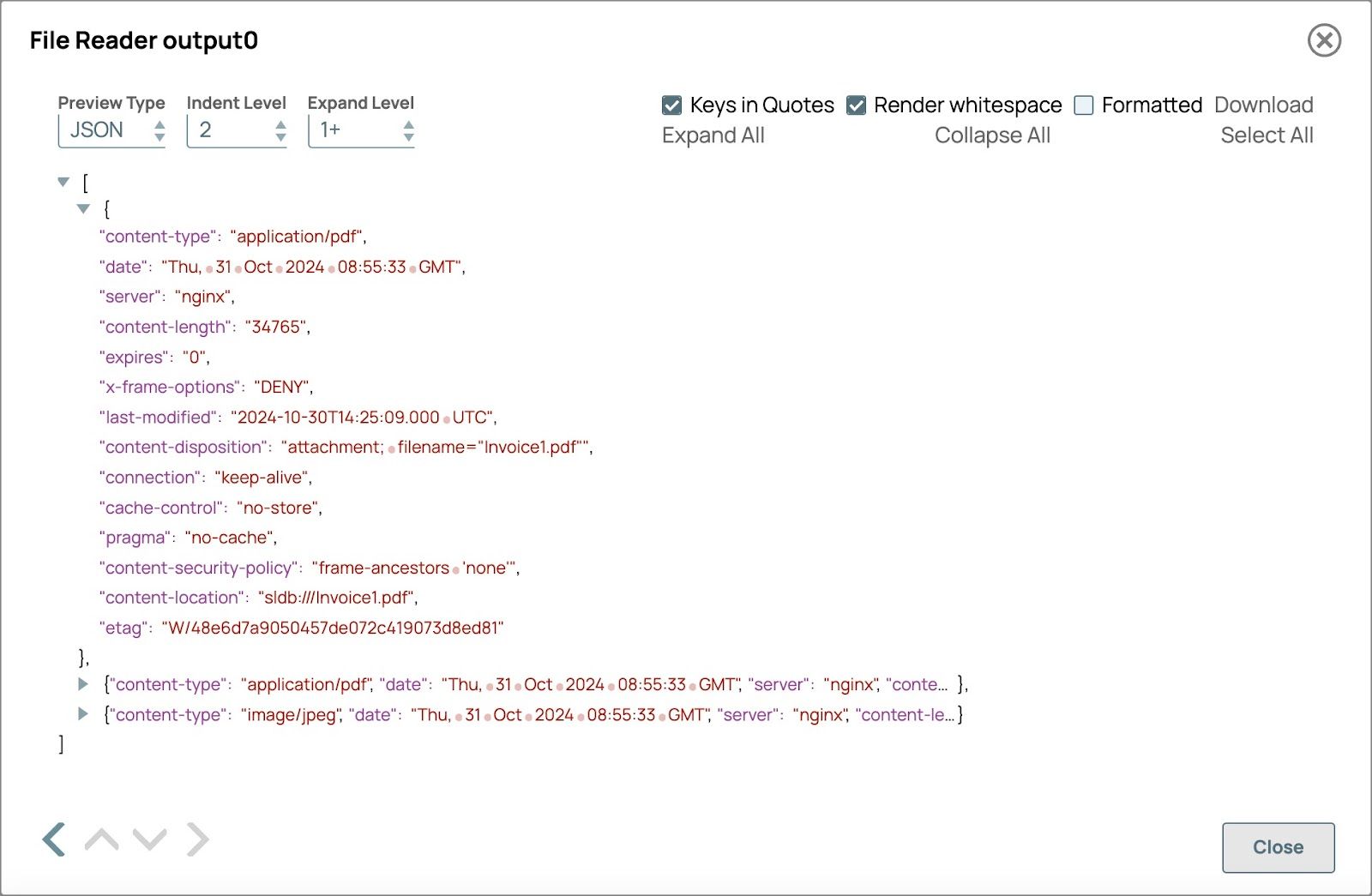
Validez le pipeline pour voir la sortie du lecteur de fichiers.
Champs qui seront utilisés dans le générateur de contenu multimodal Snap
- Le type de contenu indique le type de contenu du fichier.
- Emplacement du contenu affiche le chemin d'accès au fichier et celui-ci sera utilisé dans le nom du document
- Ajouter le générateur de contenu multimodal Snap :
- Glissez-déposez le composant Multimodal Content Generator Snap sur le canevas du concepteur et connectez-le au composant File Reader Snap.
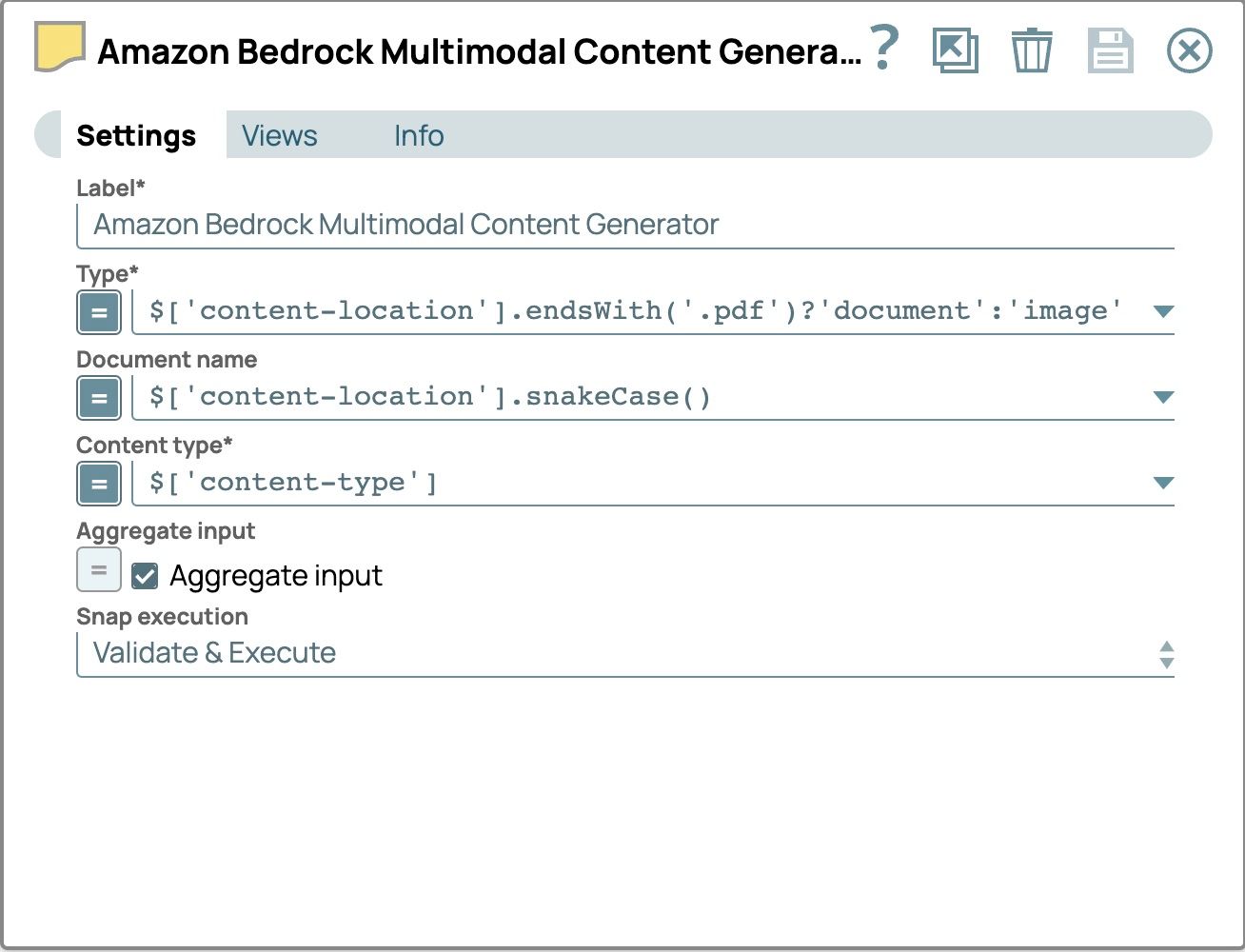
- Cliquez sur le bouton Snap pour ouvrir le panneau des paramètres et configurer les champs suivants :
- Type :
- activer l'expression
- définir la valeur sur$[‘emplacement-du-contenu’].endsWith(‘.pdf’) ? ‘document’ : ‘image’
- Nom du document
- activer l'expression
- définir la valeur sur
$[‘content-location’].snakeCase() - Utilisez la version en snake case du chemin d'accès au fichier comme nom de document afin d'identifier chaque fichier et de le rendre compatible avec l'API Amazon Bedrock Converse. En snake case, les mots sont en minuscules et séparés par des traits de soulignement (_).
- Entrée agrégée
- Cochez la case.
- Utilisez cette option pour combiner tous les fichiers d'entrée en un seul document.
- Les paramètres devraient maintenant ressembler à ce qui suit
- Type :
- Valider le pipeline pour voir le Générateur de contenu multimodal Sortie instantanée.
L'aperçu devrait ressembler à l'image ci-dessous. Le sl_type sera document pour le fichier pdf et image pour le fichier image et le nom sera le chemin d'accès simplifié au fichier.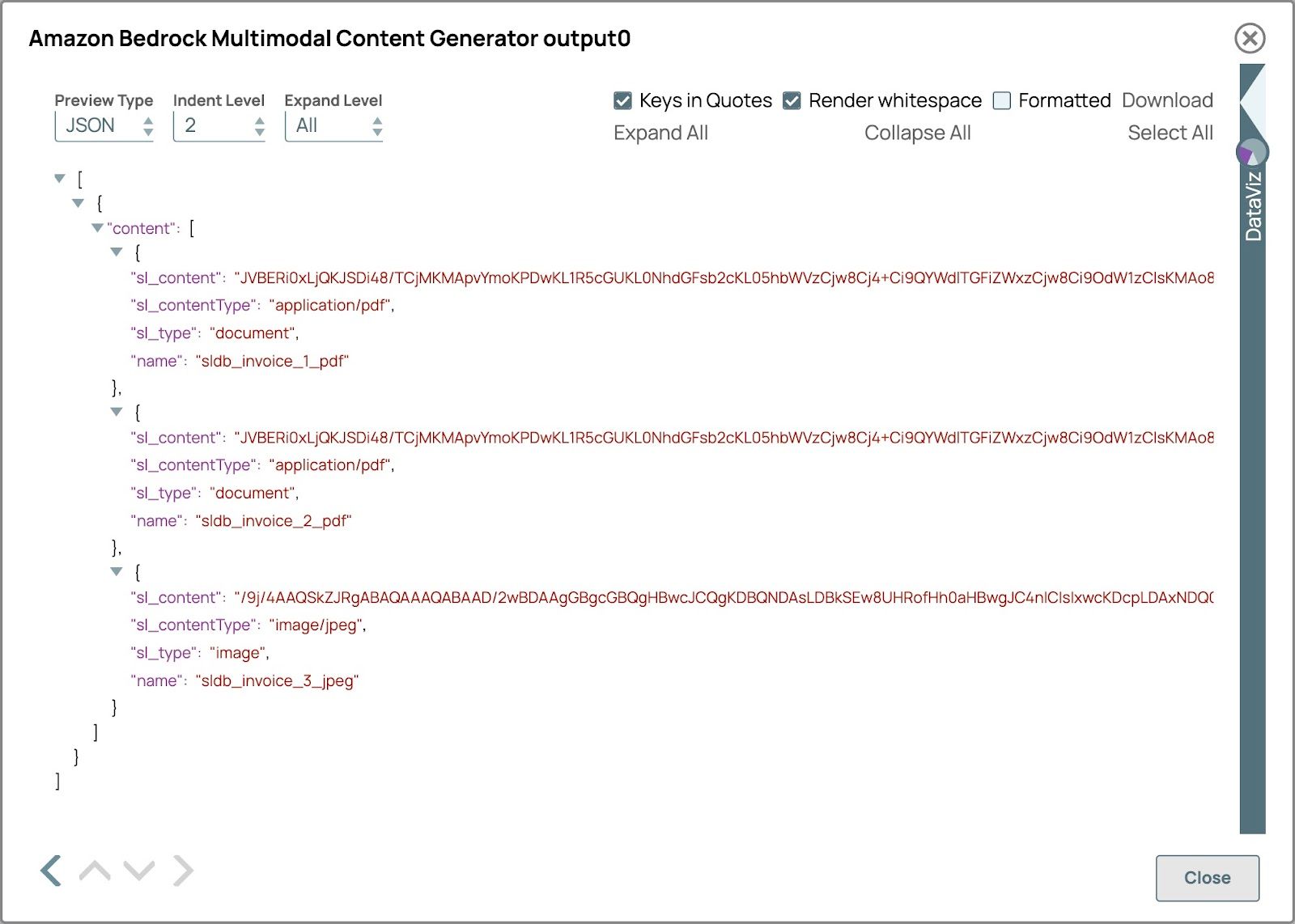
- Ajoutez le Snap Générateur de messages :
- Faites glisser et déposez le composant Prompt Generator Snap sur le canevas du concepteur et connectez-le au composant Multimodal Content Generator Snap.
- Cliquez sur le bouton Snap pour ouvrir le panneau des paramètres et configurer les champs suivants :
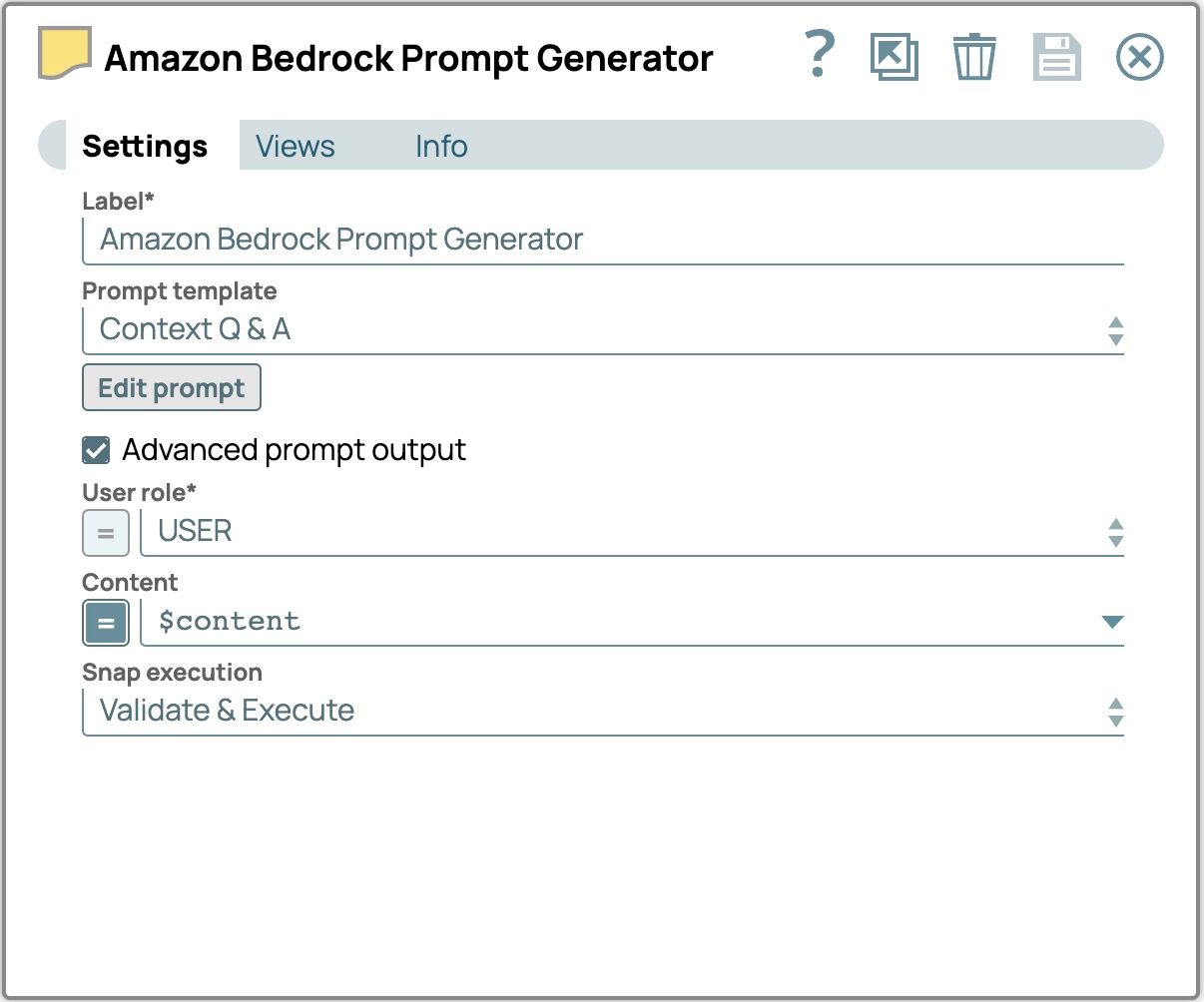
- Cochez la case « Advanced Prompt Output » (Sortie avancée des invites).
- Définissez le contenu sur $content pour utiliser le contenu saisi à partir du générateur de contenu multimodal Snap.
- Cliquez sur « Modifier l'invite » et saisissez vos instructions. Par exemple,
Sur la base du montant total de toutes les factures,
quel produit présente les quantités d'achat les plus élevées et les plus faibles,
et dans quelles factures ces informations se trouvent-elles ?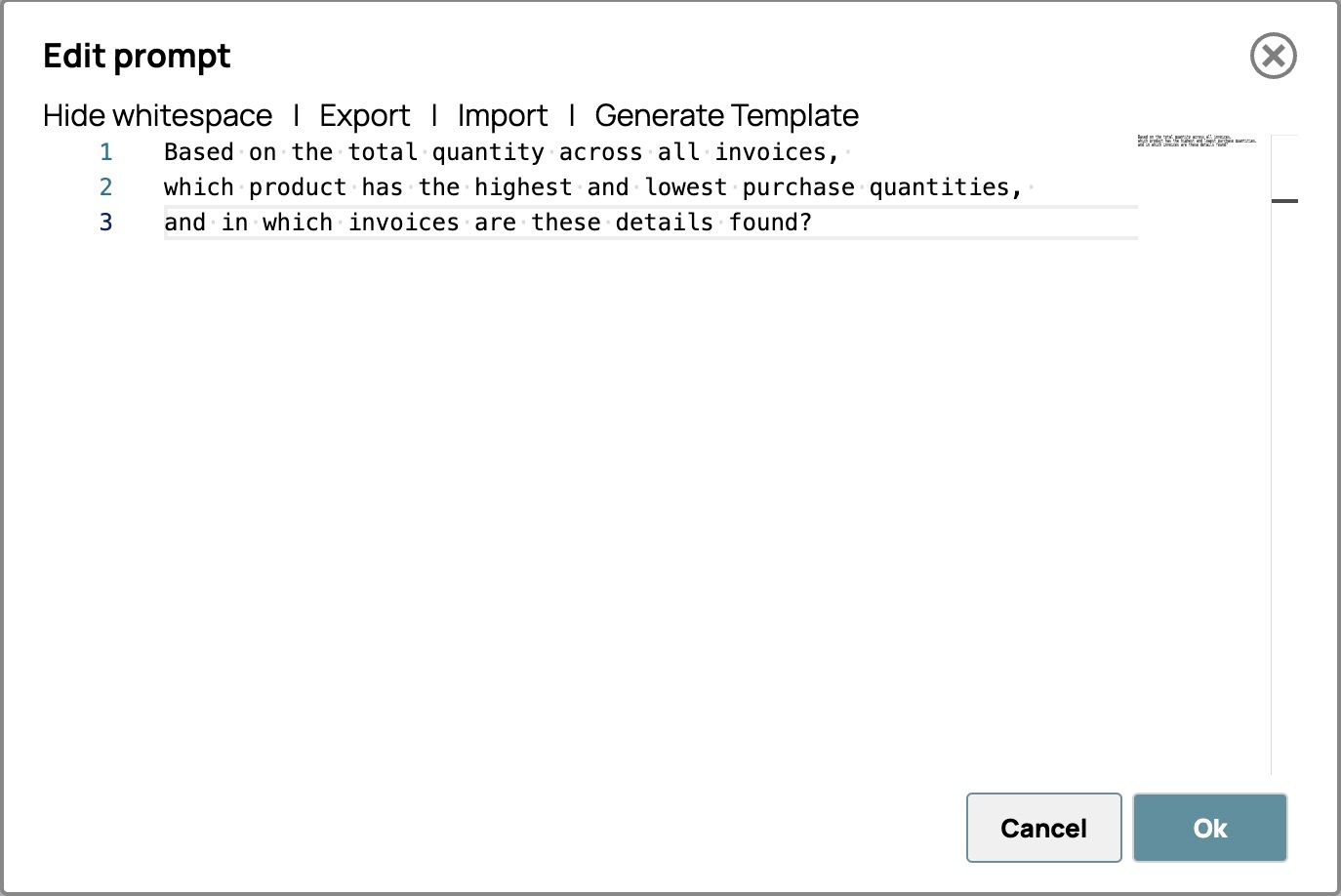
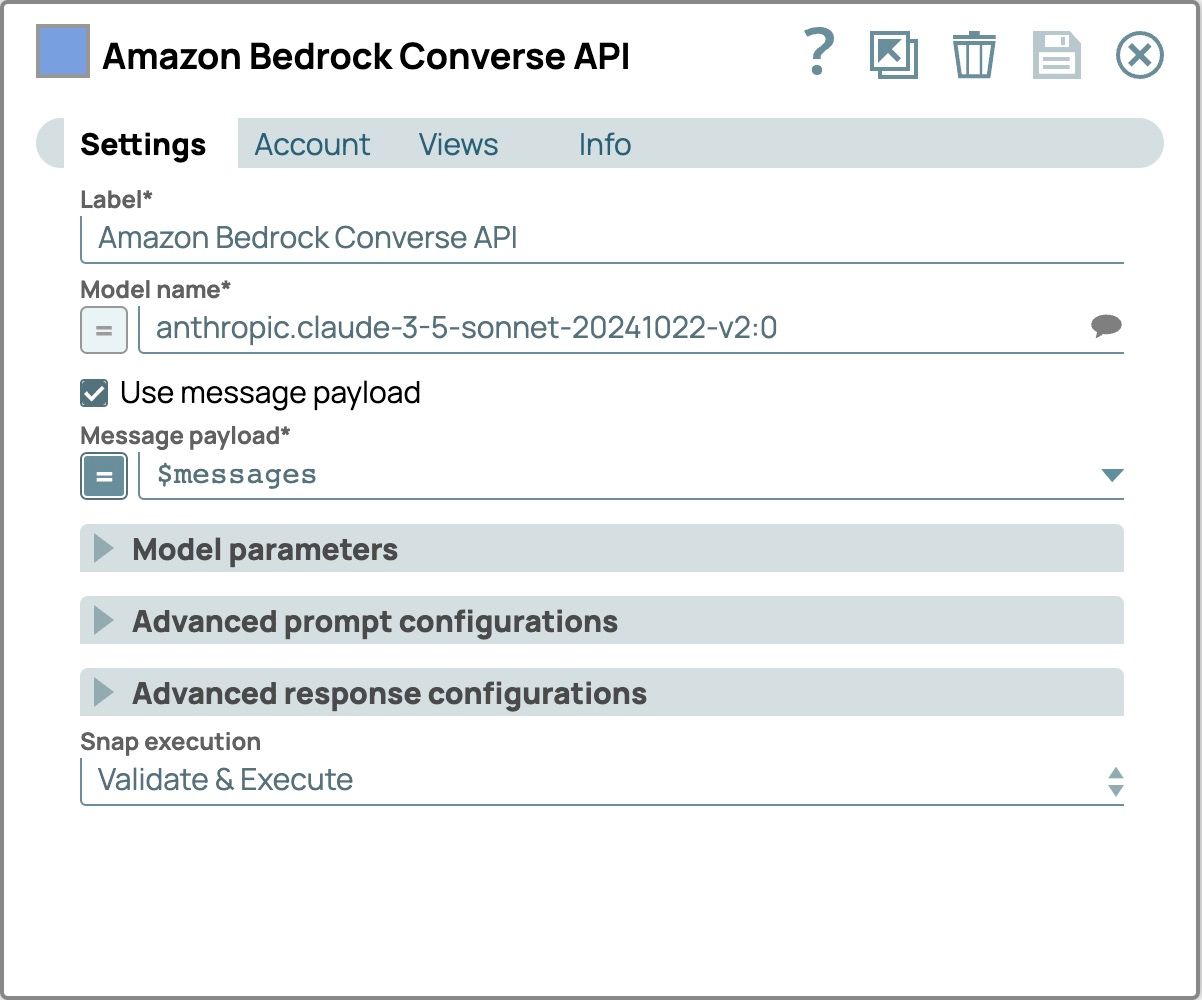
- Ajouter et configurer le Snap LLM :
- Ajoutez l'API Amazon Bedrock Converse Snap en tant que LLM.
- Connectez ce Snap au Snap Générateur de messages
- Cliquez sur le bouton « Snap » pour ouvrir le panneau de configuration.
- Sélectionnez l'onglet Compte, puis sélectionnez votre compte.
- Sélectionnez le Paramètres onglet
- Sélectionnez un modèle qui prend en charge le contenu multimodal.
- Cochez la case « Utiliser la charge utile du message ».
- Définissez le Charge utile du message à $messages utiliser le message provenant du Générateur de messages Snap
- Vérifiez le résultat :
Valider le pipeline et ouvrir l'aperçu du API Amazon Bedrock Converse Clic. Le résultat devrait ressembler à ceci :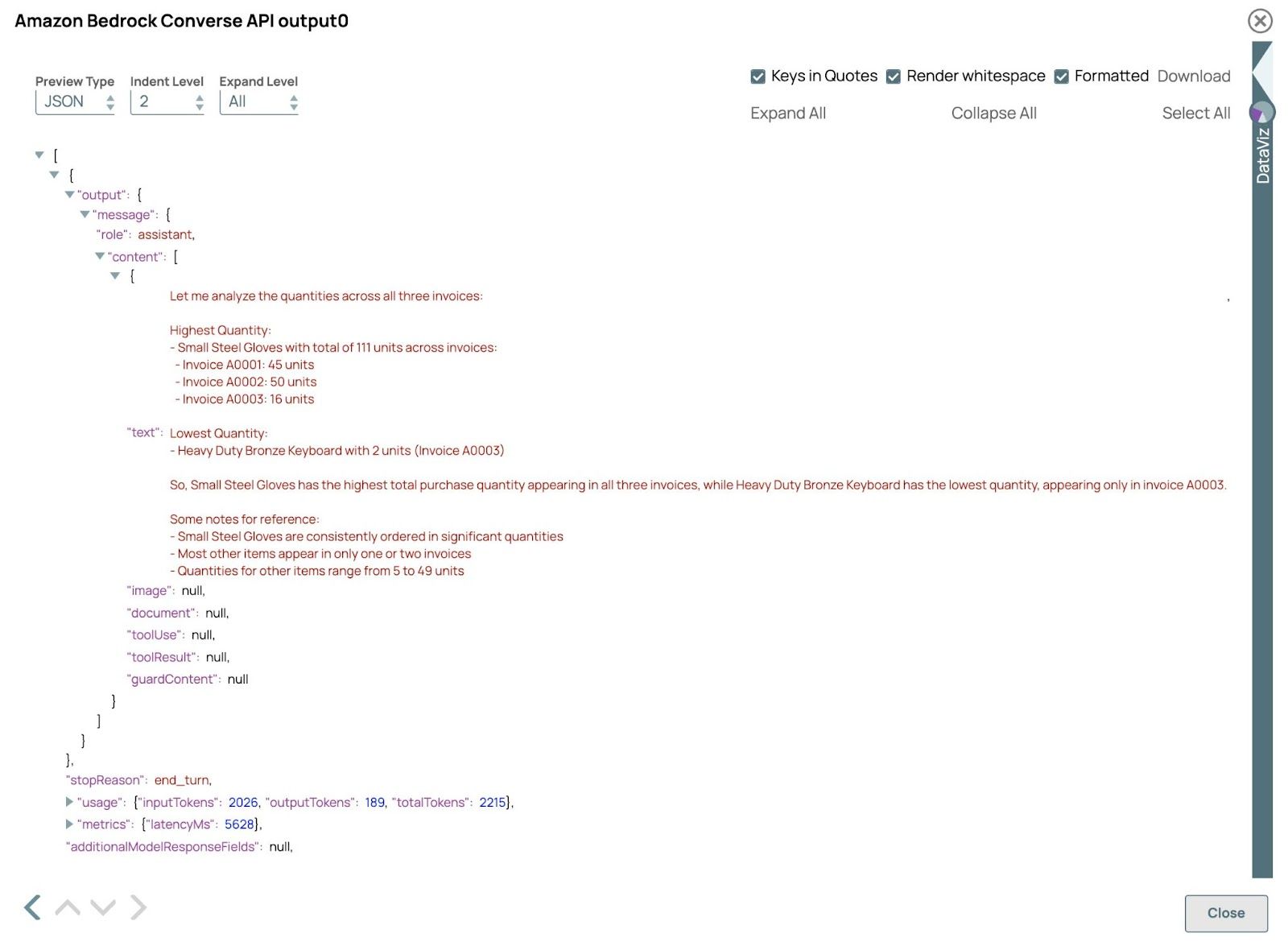
Dans cet exemple, le LLM traite avec succès les factures au format PDF et au format image, démontrant ainsi sa capacité à gérer divers types de données dans un seul flux de travail. En extrayant et en analysant les données de ces différents formats, le LLM fournit des réponses et des informations précises, démontrant ainsi l'efficacité et la flexibilité du traitement multimodal. Vous pouvez ajuster les requêtes dans le Générateur de messages Cliquez pour explorer différents résultats.





