






L'elaborazione multimodale nell'IA generativa rappresenta un salto trasformativo nel modo in cui i sistemi di IA estraggono e sintetizzano simultaneamente informazioni da più tipi di dati, come testo, immagini, audio e video. A differenza dei modelli tradizionali di IA a modalità singola, che si concentrano su un solo tipo di dati, i sistemi multimodali integrano ed elaborano flussi di dati diversi in parallelo, creando una comprensione olistica di scenari complessi. Questo approccio integrato è fondamentale per le applicazioni che richiedono non solo informazioni isolate da una singola modalità, ma una sintesi coerente tra diverse fonti di dati, che porta a risultati contestualmente più ricchi e accurati.
L'intelligenza artificiale generativa, con elaborazione multimodale, sta ridefinendo l'estrazione di testo, superando l'OCR tradizionale grazie all'interpretazione del testo nel suo contesto visivo e contestuale. A differenza dell'OCR, che converte solo le immagini in testo, l'intelligenza artificiale generativa analizza il contesto dell'immagine circostante, il layout e il significato, migliorando l'accuratezza e la profondità. Ad esempio, in documenti complessi, è in grado di distinguere tra titoli, testo del corpo e annotazioni, strutturando le informazioni in modo più intelligente. Inoltre, eccelle nei testi di bassa qualità o multilingue, rendendola preziosa nei settori che richiedono precisione e interpretazione sfumata.
Nell'analisi video, un'IA generativa dotata di elaborazione multimodale è in grado di interpretare simultaneamente gli elementi visivi di una scena, l'audio (come i dialoghi o i suoni di sottofondo) e qualsiasi testo associato (come i sottotitoli o i metadati). Ciò consente all'IA di produrre una descrizione o un riassunto della scena molto più sfumato di quello che si otterrebbe analizzando solo il video o l'audio. L'interazione tra queste modalità garantisce che la descrizione generata rifletta non solo il contenuto visivo e uditivo, ma anche il contesto e il significato più profondi derivanti dalla loro combinazione.
In attività come la didascalia delle immagini, i sistemi di IA multimodale vanno oltre il semplice riconoscimento degli oggetti in una foto. Sono in grado di interpretare la relazione semantica tra l'immagine e il testo che l'accompagna, migliorando la pertinenza e la specificità delle didascalie generate. Questa capacità è particolarmente utile in campi in cui il contesto fornito da una modalità influenza in modo significativo l'interpretazione di un'altra, come nel giornalismo, dove le immagini e i resoconti scritti devono essere significativamente allineati, o nell'istruzione, dove gli ausili visivi sono integrati con il testo didattico.
L'elaborazione multimodale consente all'IA di sintetizzare immagini mediche (come radiografie o risonanze magnetiche) con l'anamnesi del paziente, le note cliniche e persino le interazioni dal vivo tra medico e paziente in applicazioni altamente specializzate come la diagnostica medica. Questa analisi completa consente all'IA di fornire diagnosi e raccomandazioni terapeutiche più accurate, affrontando la complessa interazione tra sintomi, dati storici e diagnostica visiva. Allo stesso modo, nel servizio clienti, i sistemi di IA multimodale possono migliorare la qualità della comunicazione analizzando il contenuto testuale della richiesta di un cliente e il tono e il sentimento della sua voce, portando a risposte più empatiche ed efficaci.
Al di là dei singoli casi d'uso, l'elaborazione multimodale svolge un ruolo cruciale nel miglioramento delle capacità di apprendimento e generalizzazione dei modelli di IA. Grazie all'addestramento su una gamma più ampia di tipi di dati, i sistemi di IA sviluppano modelli più robusti e flessibili in grado di adattarsi a una più ampia varietà di compiti e scenari. Ciò è particolarmente importante negli ambienti reali, dove i dati sono spesso eterogenei e richiedono una comprensione cross-modale per essere interpretati appieno.
Con il continuo progresso delle tecnologie di elaborazione multimodale, si prospettano nuove possibilità in diversi settori. Nel campo dell'intrattenimento, l'IA multimodale potrebbe migliorare l'esperienza dei media interattivi integrando perfettamente voce, immagini ed elementi narrativi. Nel campo dell'istruzione, potrebbe rivoluzionare l'apprendimento personalizzato adattando la trasmissione dei contenuti ai diversi input sensoriali. Nel campo sanitario, la fusione dei dati multimodali potrebbe portare a scoperte rivoluzionarie nella medicina di precisione. In definitiva, la capacità di comprendere e generare contenuti multimodali ricchi di contesto posiziona l'IA generativa come una tecnologia fondamentale nella prossima ondata di innovazione guidata dall'IA.
Generatore di contenuti multimodali Snap
Il generatore di contenuti multimodali Snap codifica i file o i documenti in ingresso nel formato multimodale di Snap, preparandoli per una perfetta integrazione. L'output di questo Snap deve essere collegato al generatore di prompt Snap per completare e formattare il payload del messaggio per l'ulteriore elaborazione. Questa configurazione semplificata consente una gestione efficiente dei contenuti multimodali all'interno dell'ecosistema Snap.
Le proprietà Snap
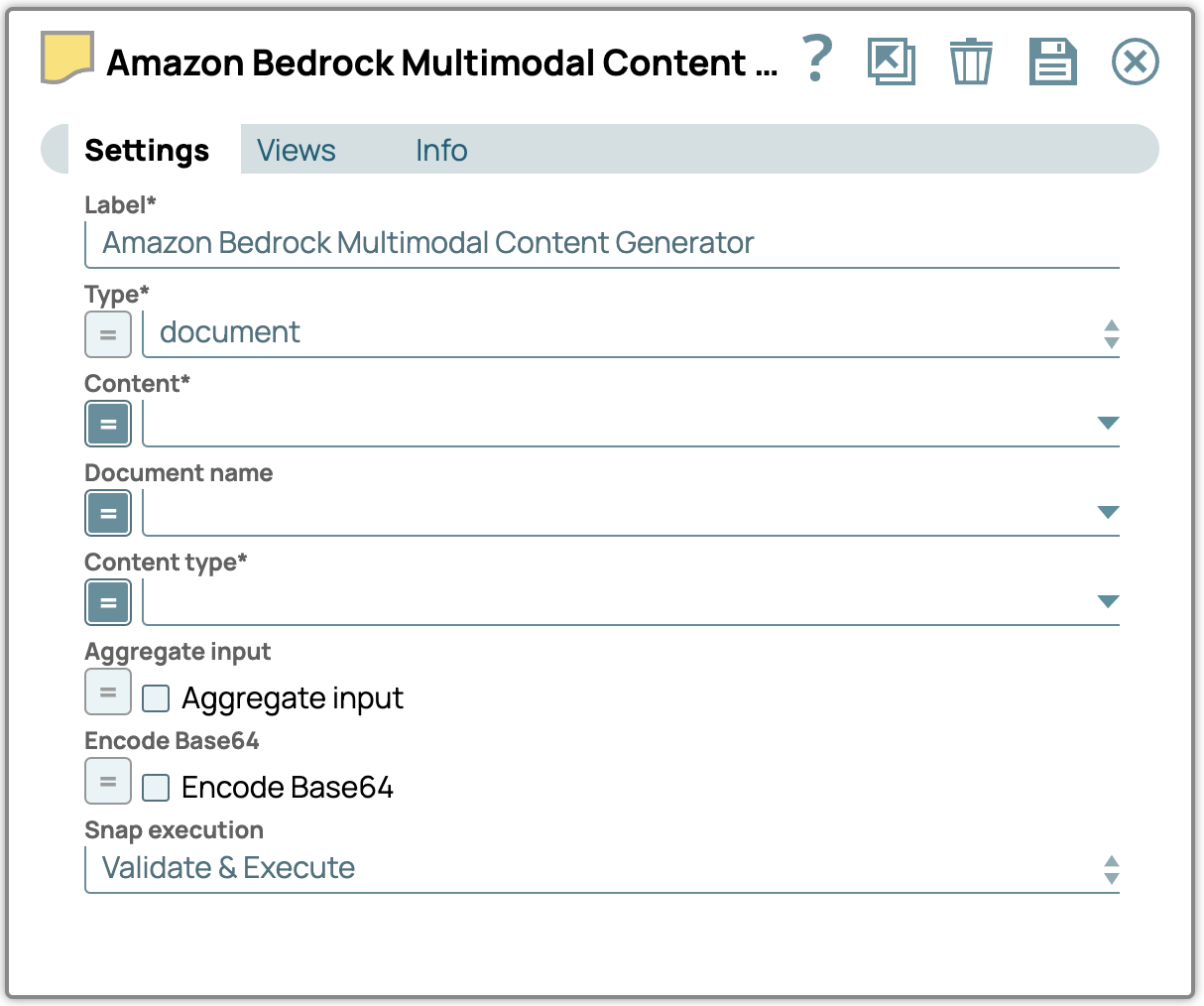
Tipo: selezionare il tipo di contenuto multimodale.
Tipo di contenuto – Definisci il tipo di contenuto specifico per i dati trasmessi all'LLM.
Contenuto – Specifica il percorso del contenuto multimodale da elaborare.
Nome del documento – Assegna un nome al documento a scopo di riferimento e identificazione.
Input aggregato – Abilita questa opzione per combinare tutti gli input in un unico contenuto.
Codifica Base64 – Abilita questa opzione per convertire il testo immesso in codifica Base64.
Nota:
- La proprietà Contenuto appare solo se la vista di input è di tipo documento. Il valore assegnato a Contenuto deve essere in formato Base64 per gli input di tipo documento, mentre Snap utilizzerà automaticamente il formato binario come contenuto per i tipi di input binari.
- Il nome del documento può essere impostato specificatamente per i tipi di documento multimodali.
- La proprietà Encode Base64 codifica il testo immesso in Base64 per impostazione predefinita. Se deselezionata, il contenuto verrà trasmesso senza codifica.
Progettazione di un flusso di lavoro multimodale rapido
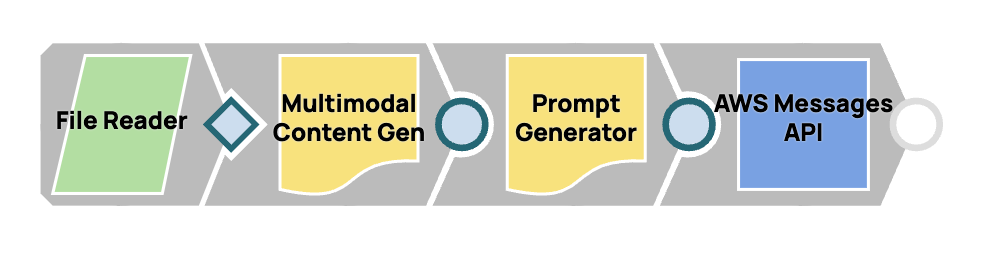
In questo processo, integreremo più Snap per creare un flusso di lavoro continuo per la generazione di contenuti multimodali e la consegna immediata. Collegando lo Snap Multimodal Content Generator allo Snap Prompt Generator, lo configuriamo per gestire contenuti multimodali. Il payload del messaggio finalizzato verrà quindi inviato a Claude da Anthropic Claude su AWS Messages.
Passaggi:
1. Aggiungi lo Snap File Reader:
- Trascinare e rilasciare il File Reader Snap sulla tela del designer.
- Configura lo Snap File Reader accedendo al pannello delle impostazioni, quindi seleziona un file contenente immagini (ad esempio un file PDF). Se non l'hai ancora fatto, scarica i file di immagini di esempio in fondo a questo post.
File immagine di esempio (Japan_flowers.jpg)

2. Aggiungi lo Snap Generatore di contenuti multimodali: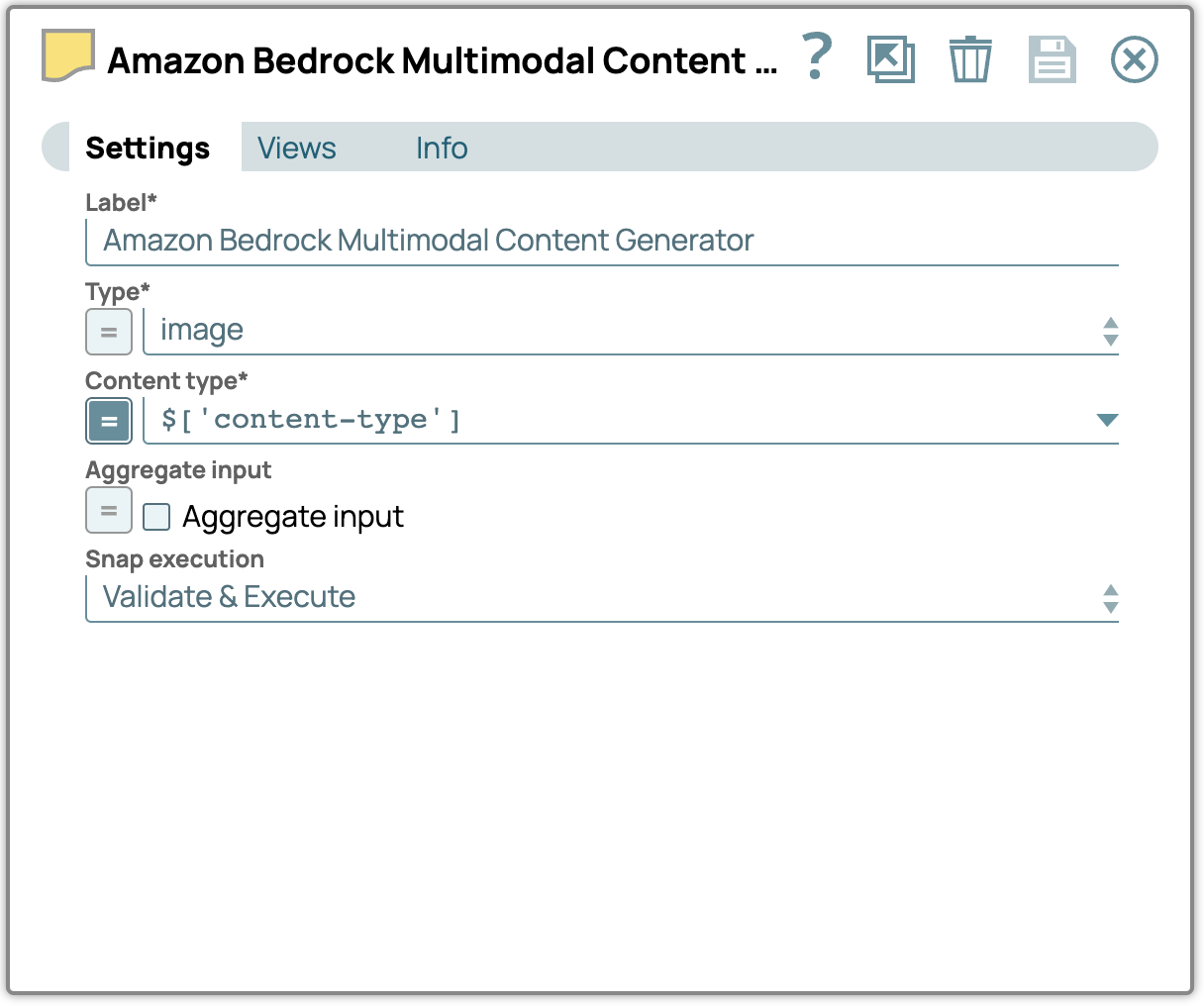
- Trascinare e rilasciare lo Snap Multimodal Content Generator sul designer e collegarlo allo Snap File Reader.
- Apri il pannello delle impostazioni, seleziona il tipo di file e specifica il tipo di contenuto appropriato.
- Ecco una descrizione dettagliata degli attributi di output del Generatore di contenuti multimodali:
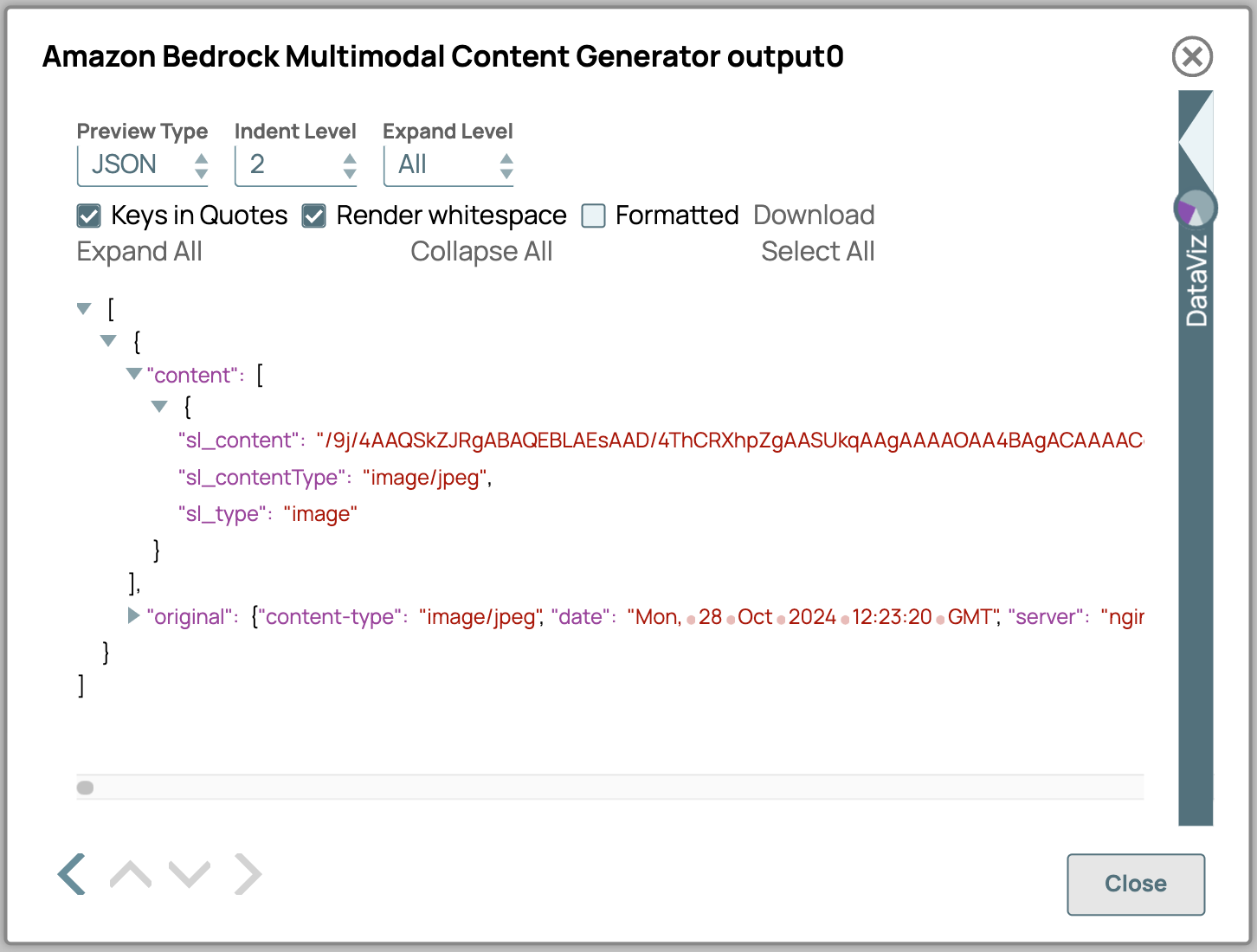
- sl_content: Contiene il contenuto effettivo codificato in formato Base64.
- sl_contentType: Indica il tipo di contenuto dei dati. Questo viene selezionato dalla configurazione oppure, se l'input è binario, estrae il contentType dall'intestazione binaria.
- sl_type: specifica il tipo di contenuto come definito nelle impostazioni Snap; in questo caso, verrà visualizzato "immagine".
3. Aggiungi lo Snap Prompt Generator:
- Aggiungi lo Snap Prompt Generator al designer e collegalo allo Snap Multimodal Content Generator.
- Nel pannello delle impostazioni, abilitare la casella di controllo Output prompt avanzato e configurare la proprietà Contenuto per utilizzare l'input proveniente dallo Snap Generatore di contenuti multimodali.
- Clicca su "Modifica prompt" e inserisci le tue istruzioni.

4. Aggiungere e configurare lo Snap LLM:
- Aggiungi Anthropic Claude su AWS Message API Snap come LLM.
- Collega questo Snap al Snap Generatore di prompt.
- Nelle impostazioni, seleziona un modello che supporti contenuti multimodali.
- Selezionare la casella di controllo Usa payload messaggio e inserire il payload del messaggio nel campo Payload messaggio.
5. Verifica il risultato: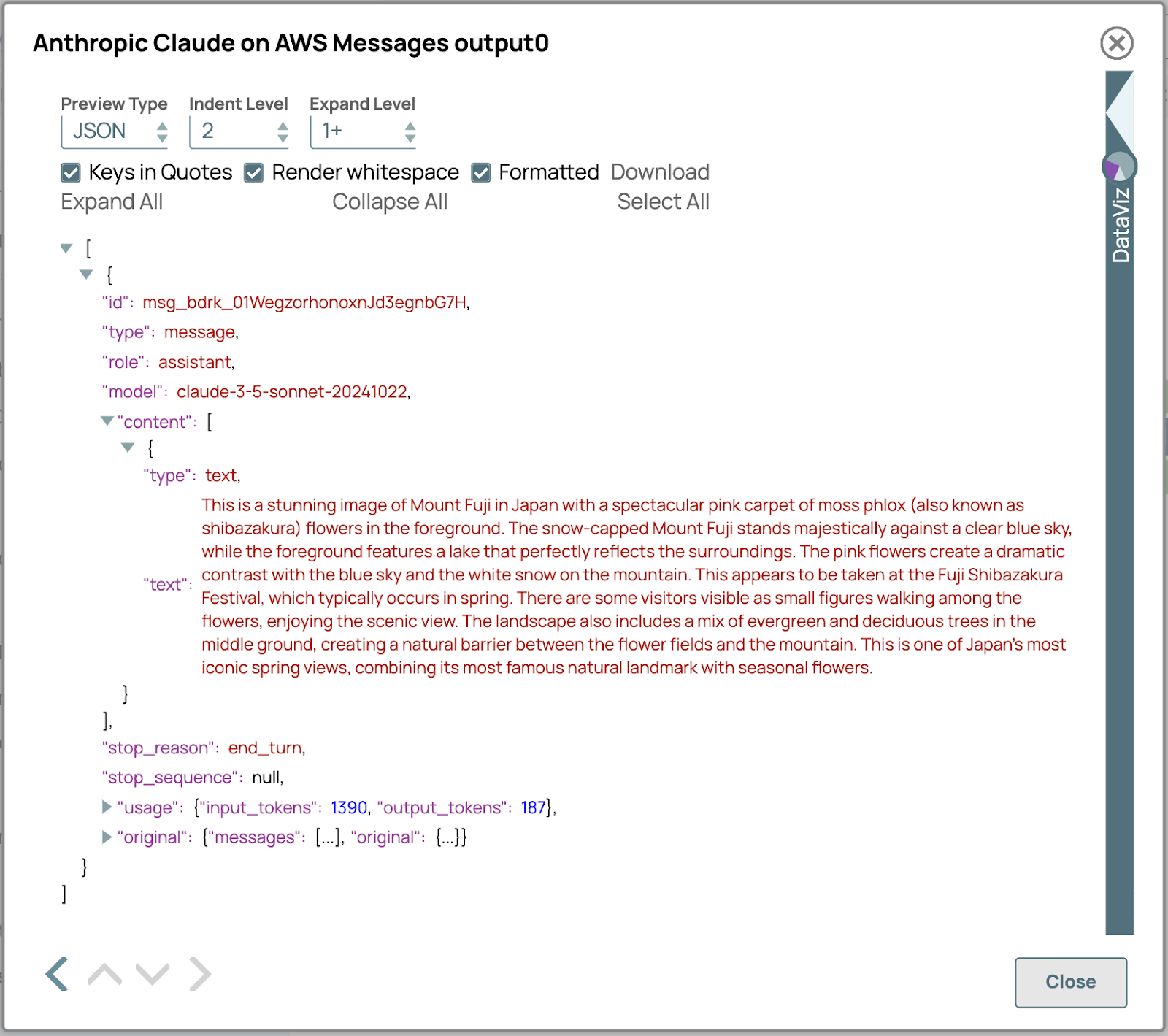
- Controlla l'output di LLM Snap per assicurarti che il contenuto multimodale sia stato elaborato correttamente.
- Verificare che la risposta generata sia conforme ai requisiti previsti in termini di contenuto e formato.
- Se sono necessarie modifiche, rivedere le impostazioni degli Snap precedenti per perfezionare la configurazione.
Modelli multimodali per l'estrazione avanzata dei dati
I modelli multimodali stanno ridefinendo l'estrazione dei dati andando oltre le tradizionali funzionalità OCR. A differenza dell'OCR, che converte principalmente le immagini in testo, questi modelli analizzano e interpretano direttamente i contenuti all'interno dei PDF e delle immagini, acquisendo informazioni contestuali complesse come il layout, la formattazione e le relazioni semantiche che l'OCR da solo non è in grado di ottenere. Comprendendo sia le strutture testuali che quelle visive, l'IA multimodale è in grado di gestire documenti complessi, inclusi tabelle, moduli e grafici incorporati, senza richiedere processi OCR separati. Questo approccio non solo migliora la precisione, ma ottimizza anche i flussi di lavoro riducendo la dipendenza dai tradizionali strumenti OCR.
Nell'odierno contesto ricco di dati, le informazioni sono spesso presentate in formati diversi, rendendo essenziale la capacità di analizzare e ricavare informazioni da fonti di dati diverse. Immaginate di gestire una raccolta di fatture salvate come PDF o foto da scanner e smartphone, dove è necessario un approccio semplificato per interpretarne il contenuto. I modelli linguistici multimodali di grandi dimensioni (LLM) eccellono in questi scenari, consentendo l'estrazione senza soluzione di continuità delle informazioni tra i diversi tipi di file. Questi modelli supportano attività quali l'identificazione automatica dei dettagli chiave, la generazione di riepiloghi completi e l'analisi delle tendenze all'interno delle fatture, sia che si tratti di documenti scansionati che di immagini. Ecco una guida passo passo per implementare questa funzionalità all'interno di SnapLogic.
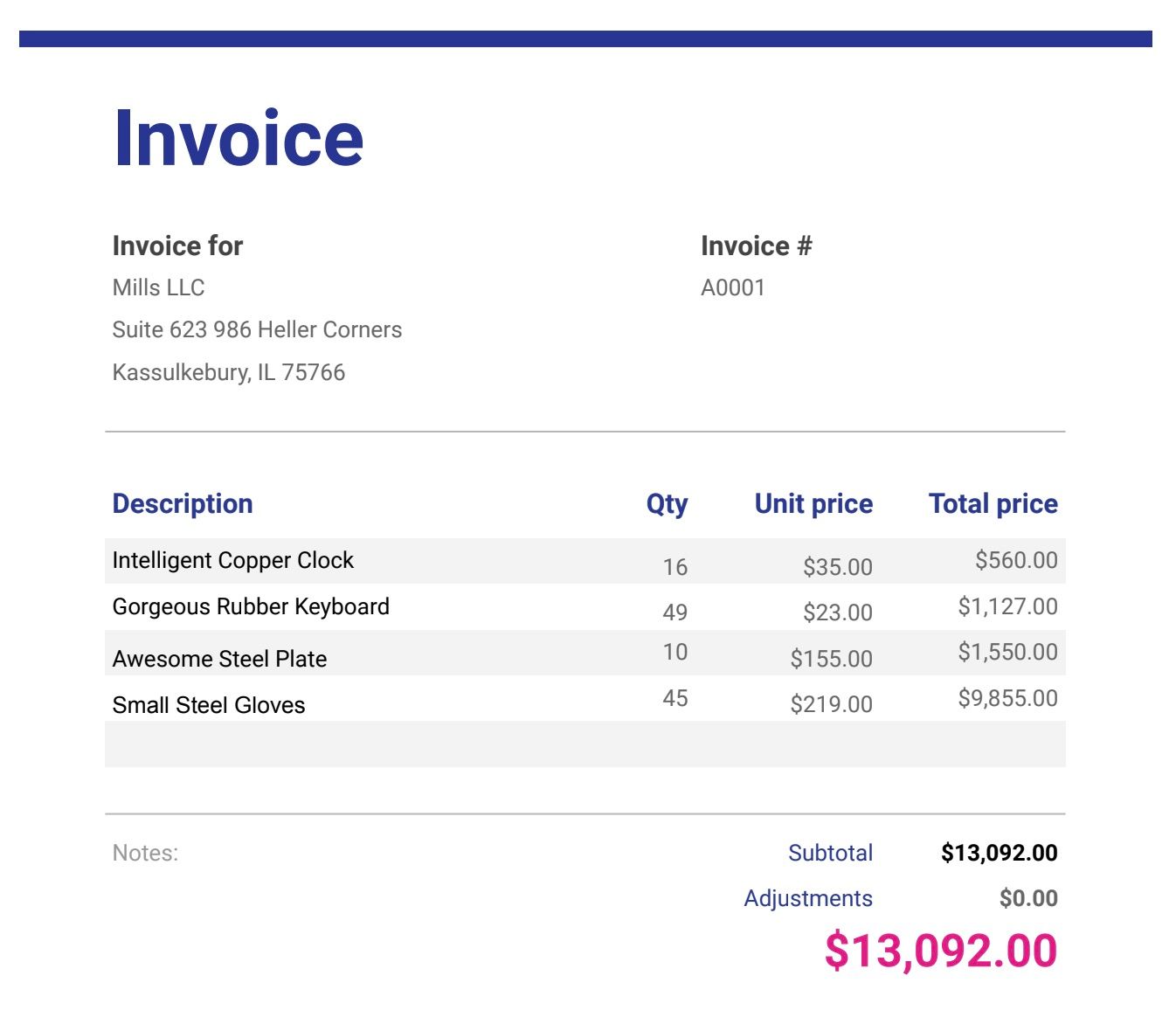
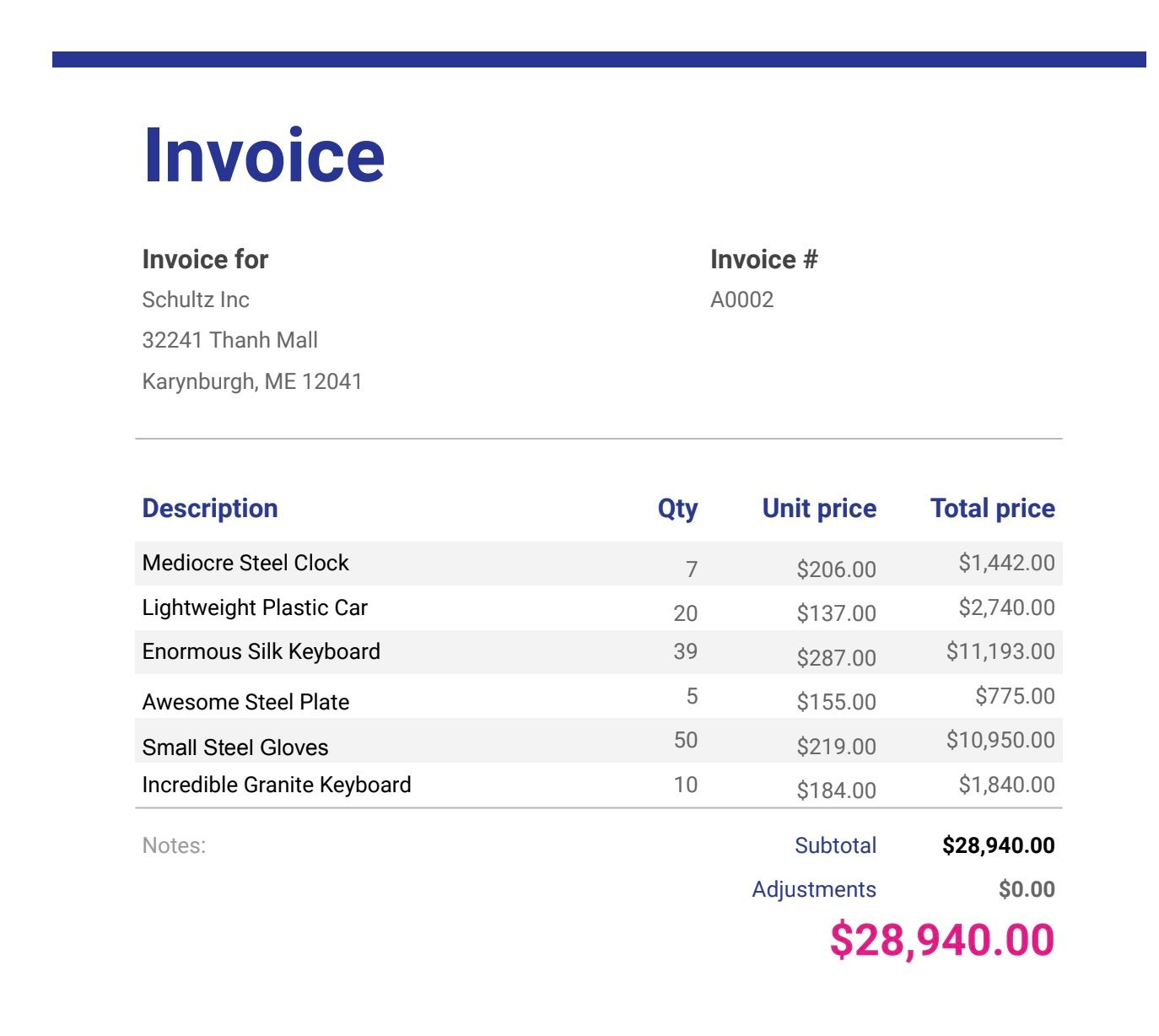
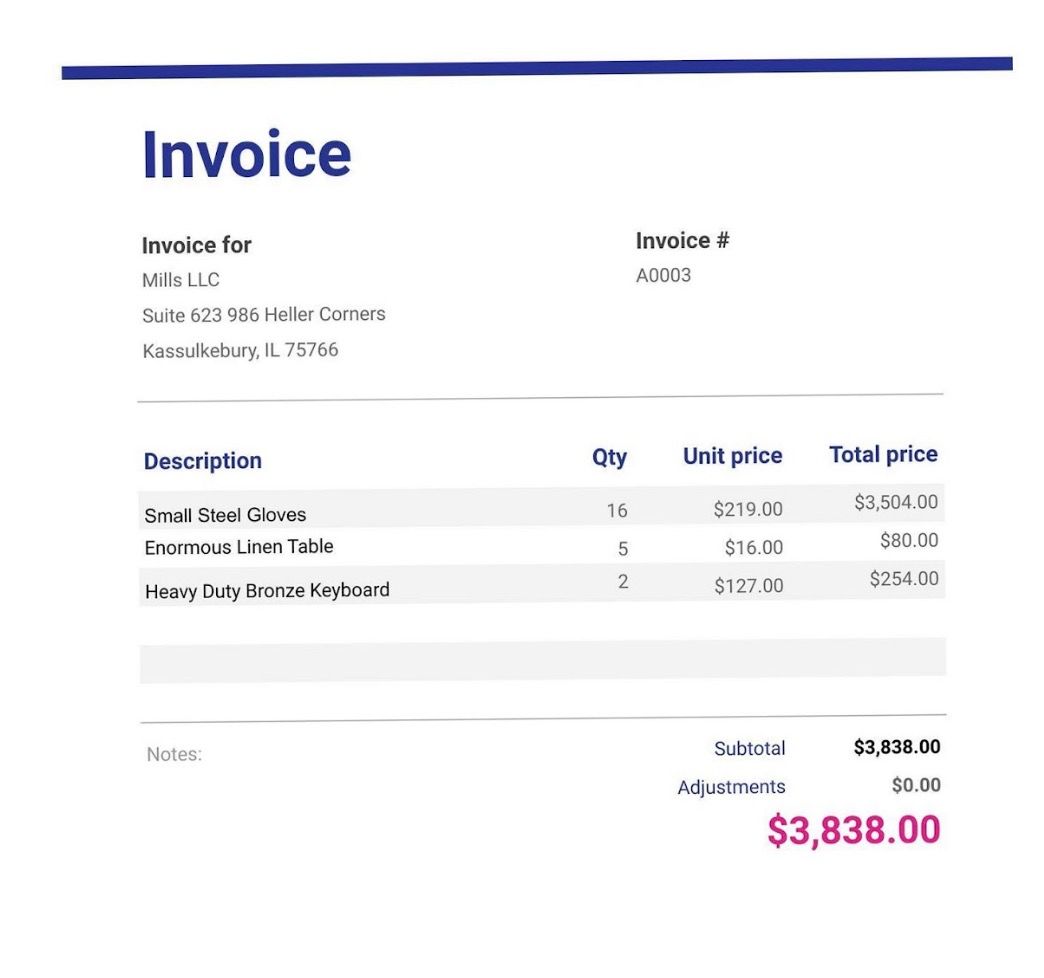
File di fatture di esempio ( scarica i file in fondo a questo post se non l'hai ancora fatto)
Carica i file delle fatture
- Apri Direttore pagina e vai al tuo progetto che verrà utilizzato per archiviare le pipeline e i file correlati
- Clicca sul + (più) e selezionare File
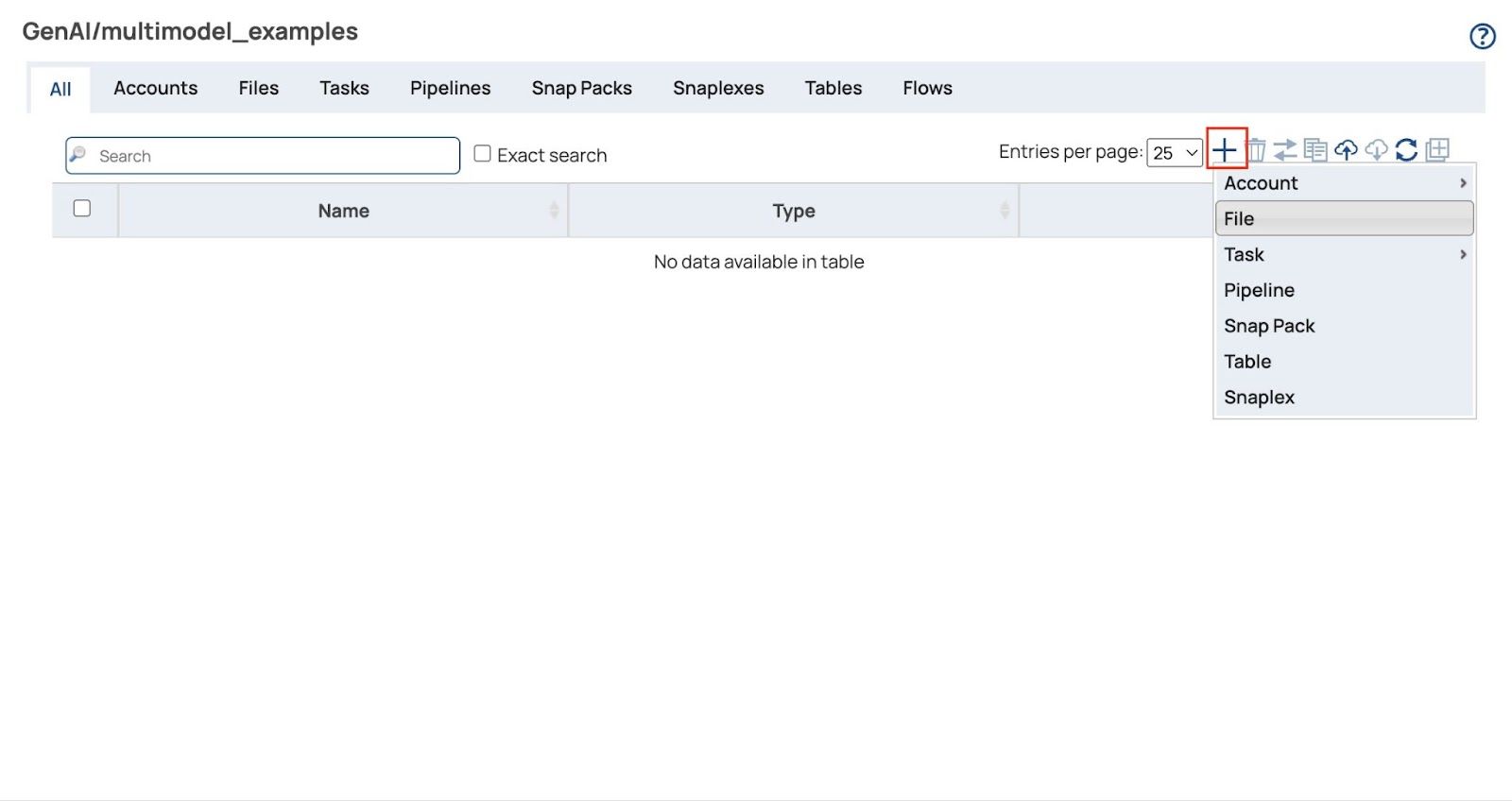
- Il Carica file Si aprirà una finestra di dialogo. Clicca su "Scegli file" per selezionare tutti i file delle fatture sia in formato PDF che immagine (scarica i file delle fatture di esempio in fondo a questo post se non l'hai già fatto).
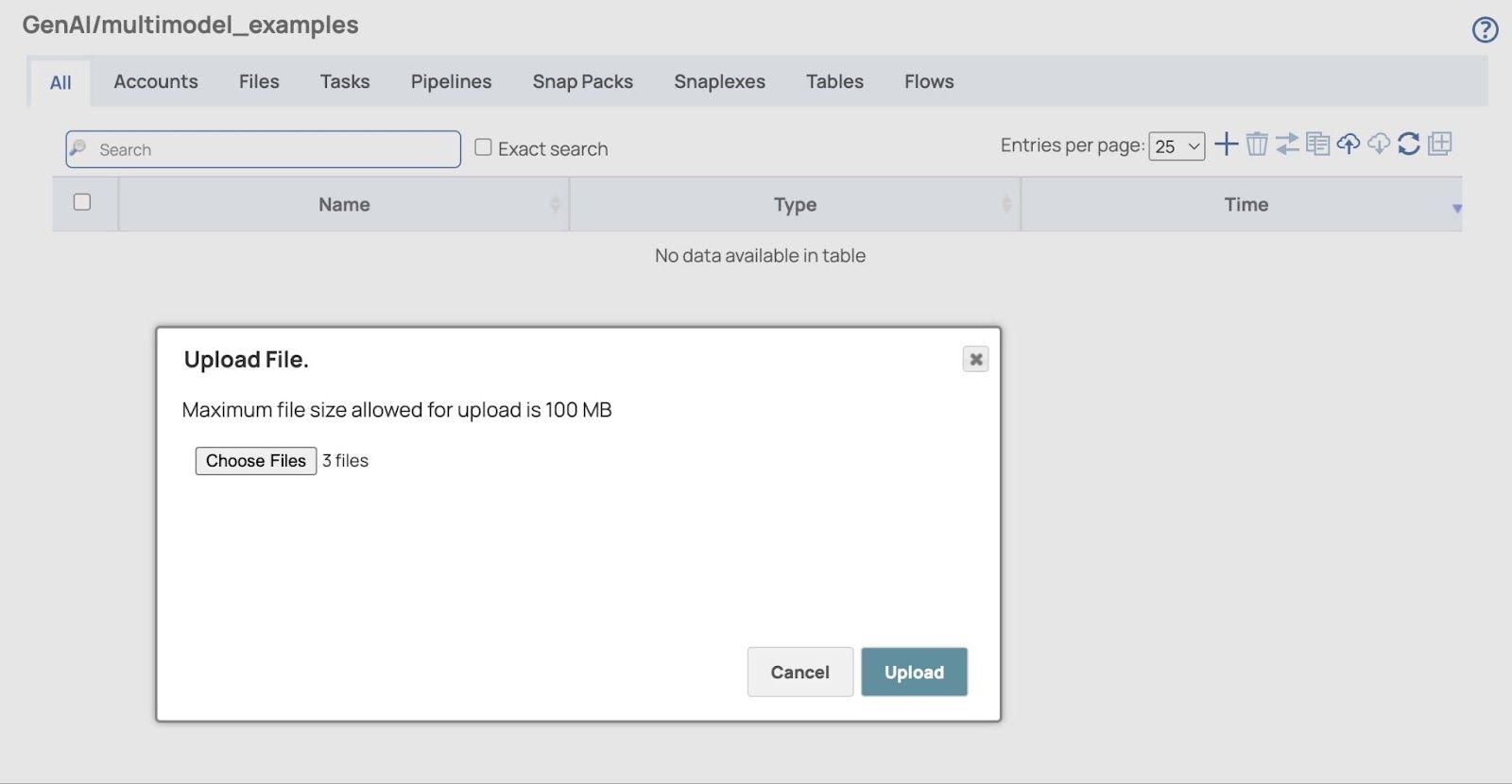
- Clicca Caricare e verranno visualizzati i file caricati.
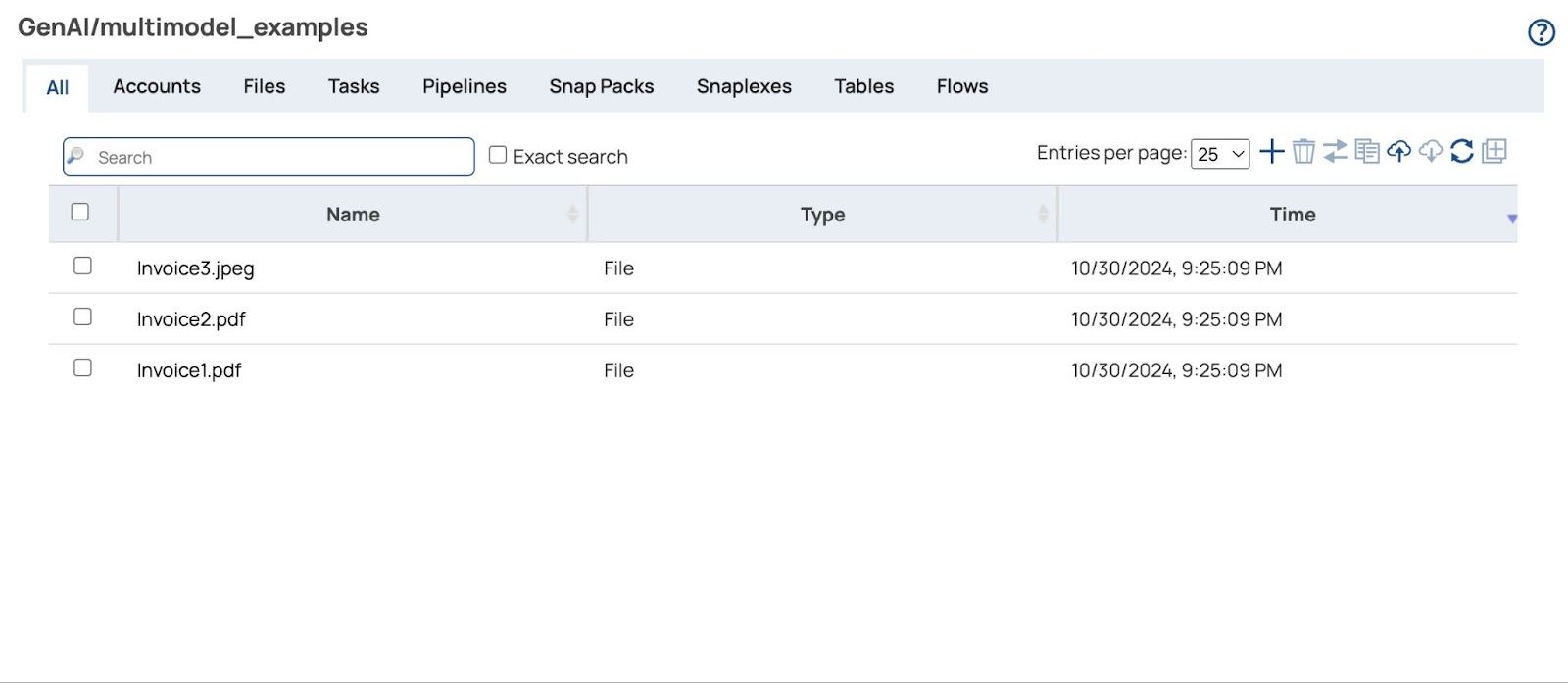
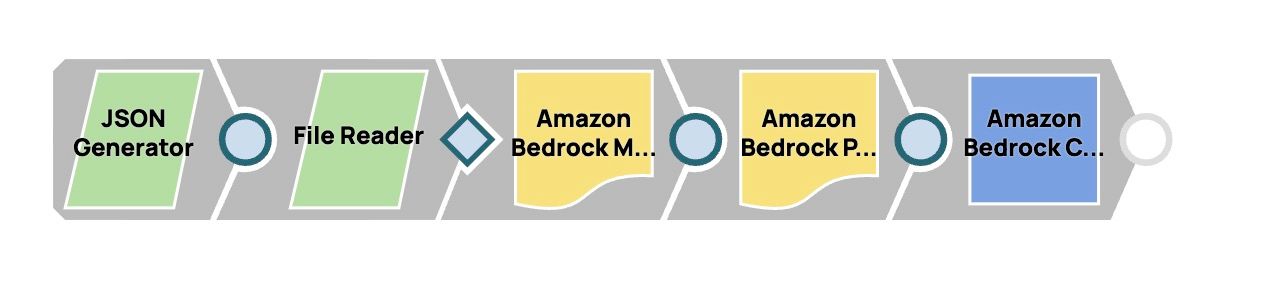
Costruzione della conduttura
- Aggiungi lo Snap JSON Generator:
- Trascina e rilascia il generatore JSON sulla tela del designer.
- Clicca su Snap per aprire le impostazioni, quindi clicca sul pulsante "Modifica JSON".
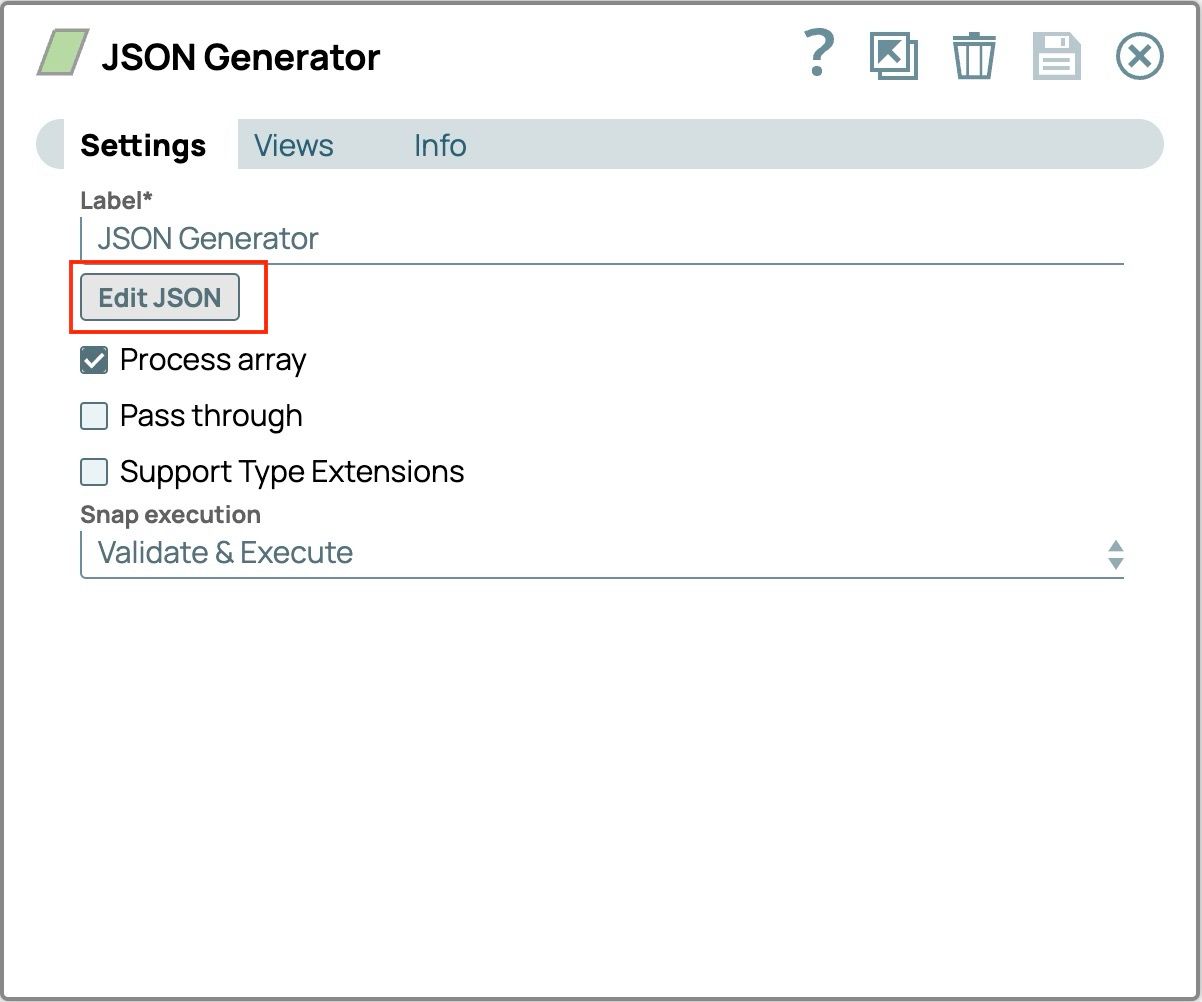
- Evidenzia tutto il testo dal modello ed eliminalo.
- Incolla tutti i nomi dei file delle fatture nel formato riportato di seguito. L'editor dovrebbe apparire come segue.
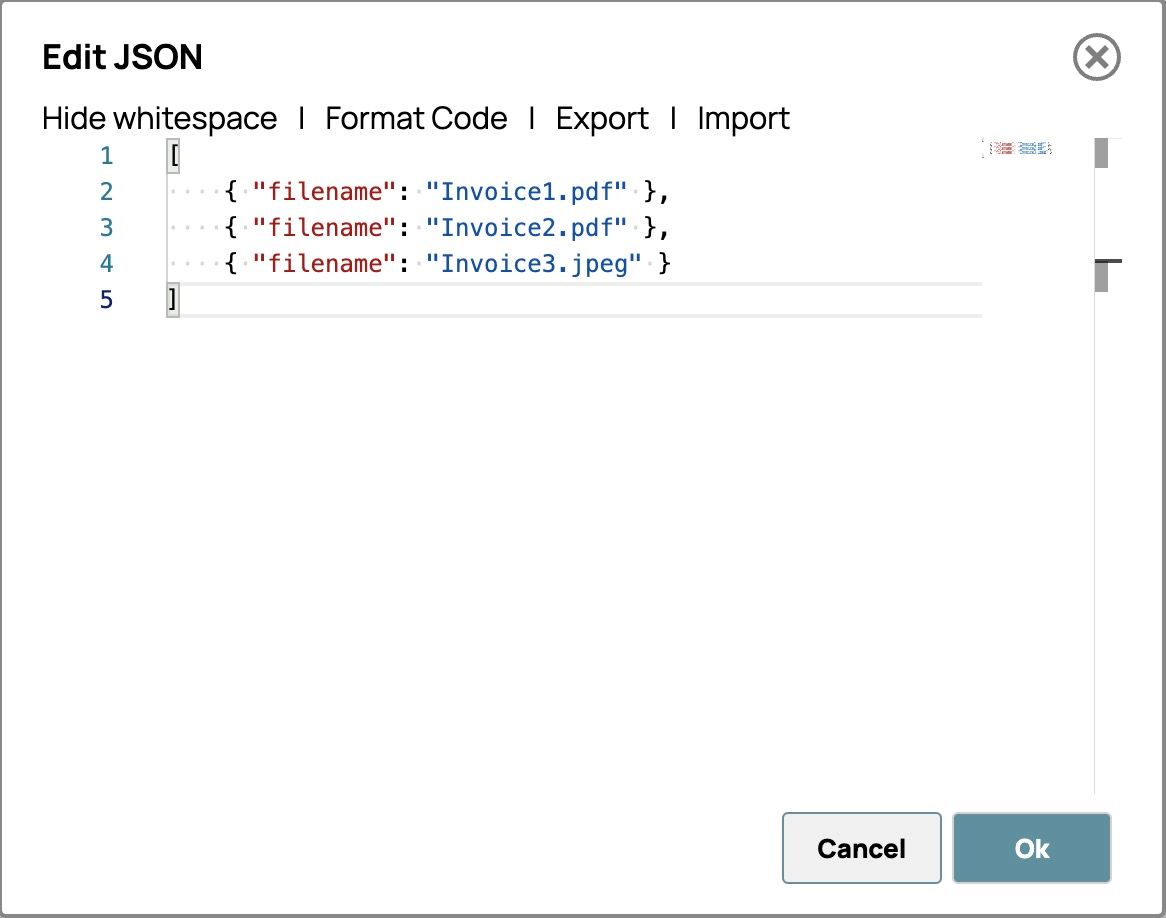
- Fai clic su "OK" nell'angolo in basso a destra per salvare il messaggio.
- Salva le impostazioni e chiudi Snap
- Aggiungi lo Snap File Reader:
- Trascinare e rilasciare il File Reader Snap sulla tela del designer.
- Clicca su Snap per aprire il pannello di configurazione.
- Collega lo Snap al Generatore JSON Scatta seguendo questi passaggi:
- Selezionare la scheda Visualizzazioni
- Clicca sul pulsante più (+) su Input pannello per aggiungere la vista di input (input0)
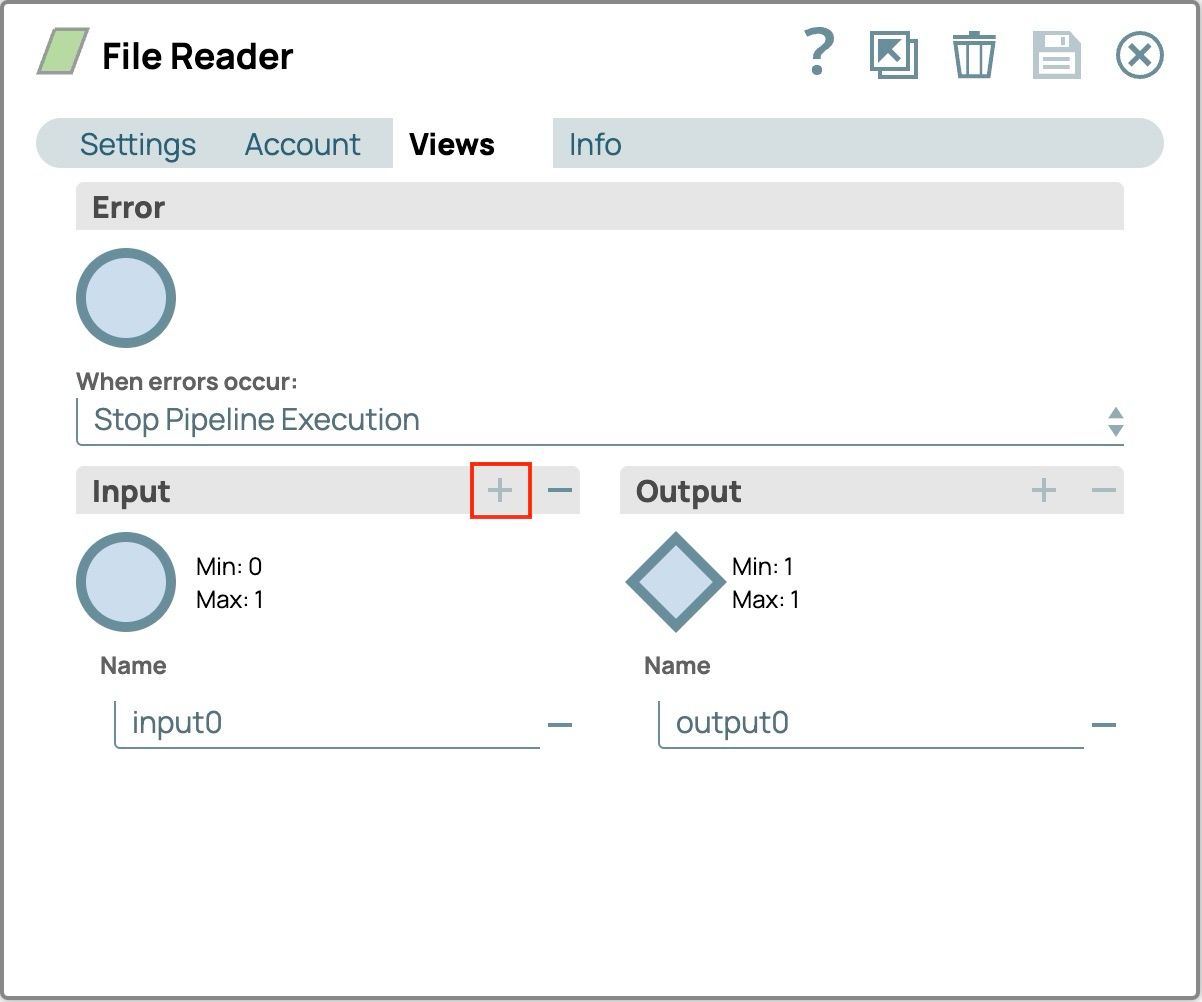
- Salva la configurazione
- Lo Snap sulla tela avrà la vista di input. Collegandolo allo Snap JSON Generator
- Nel pannello di configurazione, seleziona la scheda Impostazioni
- Imposta il File campo abilitando l'espressione facendo clic sul segno di uguale davanti al campo di immissione testo e impostandolo su $nomefile per leggere tutti i file che abbiamo specificato nel Generatore JSON Scatto
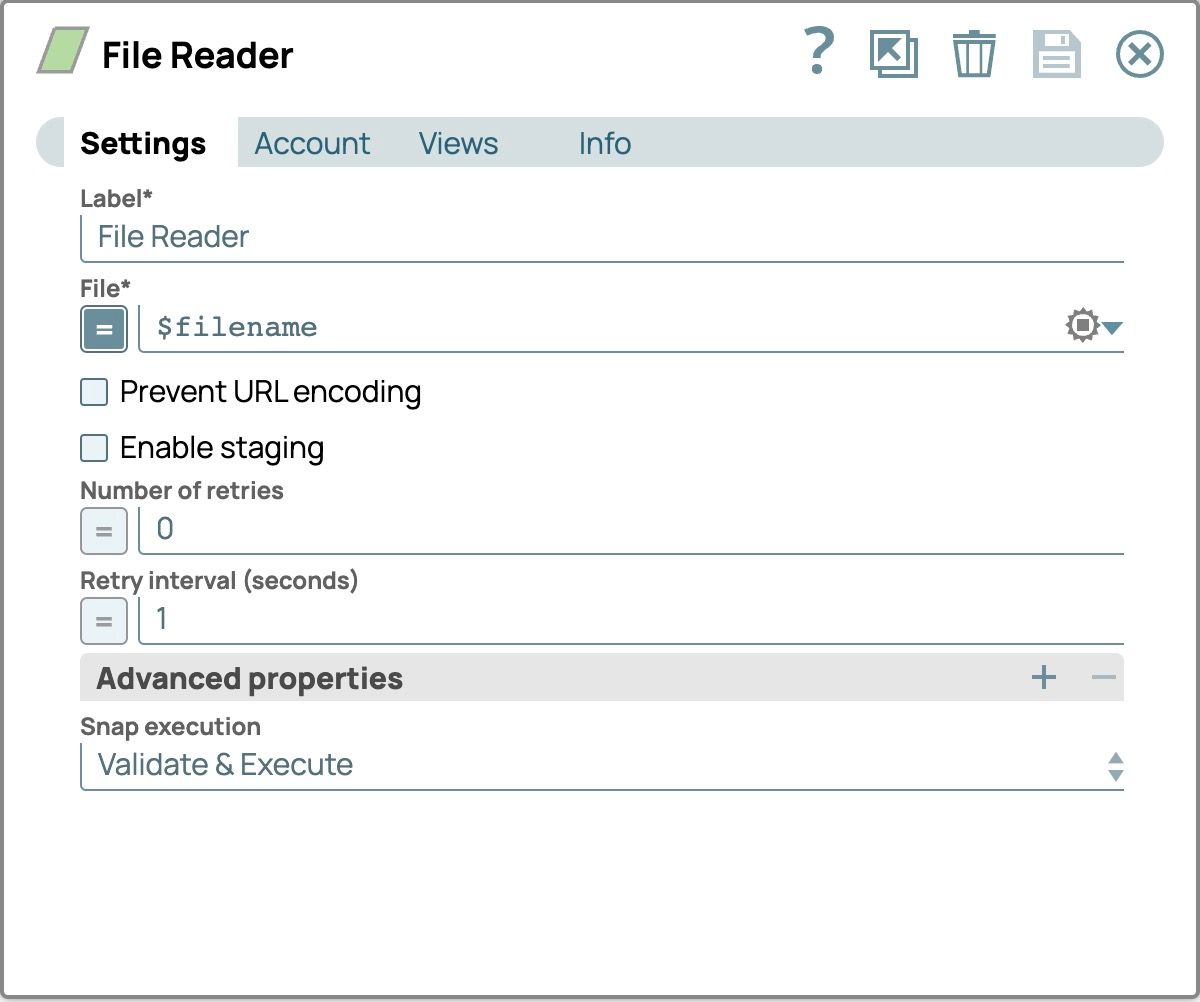
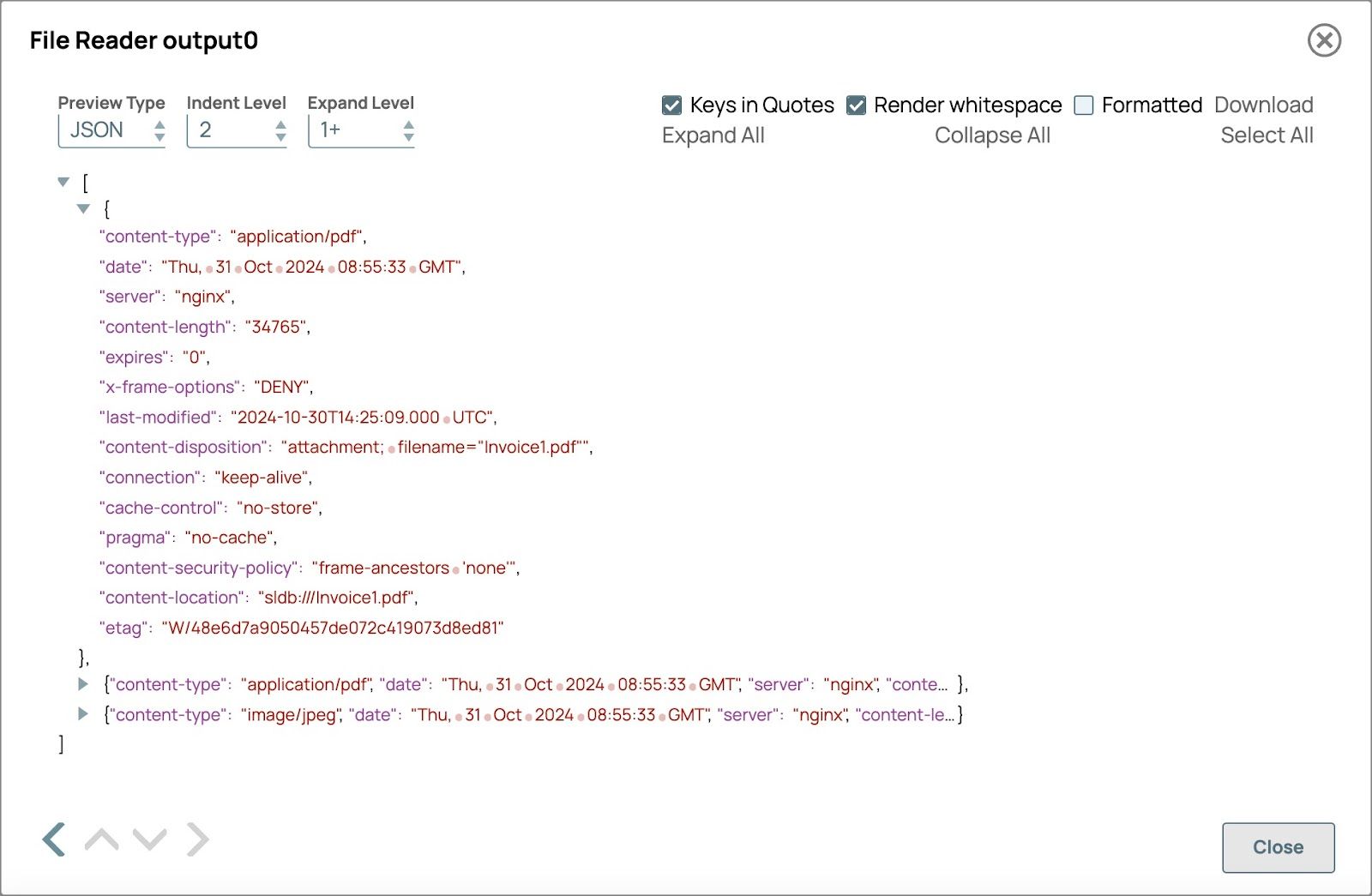
Convalida la pipeline per visualizzare l'output del File Reader.
Campi che saranno utilizzati nel generatore di contenuti multimodali Snap
- Il tipo di contenuto mostra il tipo di contenuto del file
- Posizione del contenuto mostra il percorso del file e verrà utilizzato nel nome del documento
- Aggiungi lo Snap Generatore di contenuti multimodali:
- Trascinare e rilasciare lo Snap Generatore di contenuti multimodali sulla tela del designer e collegarlo allo Snap Lettore di file.
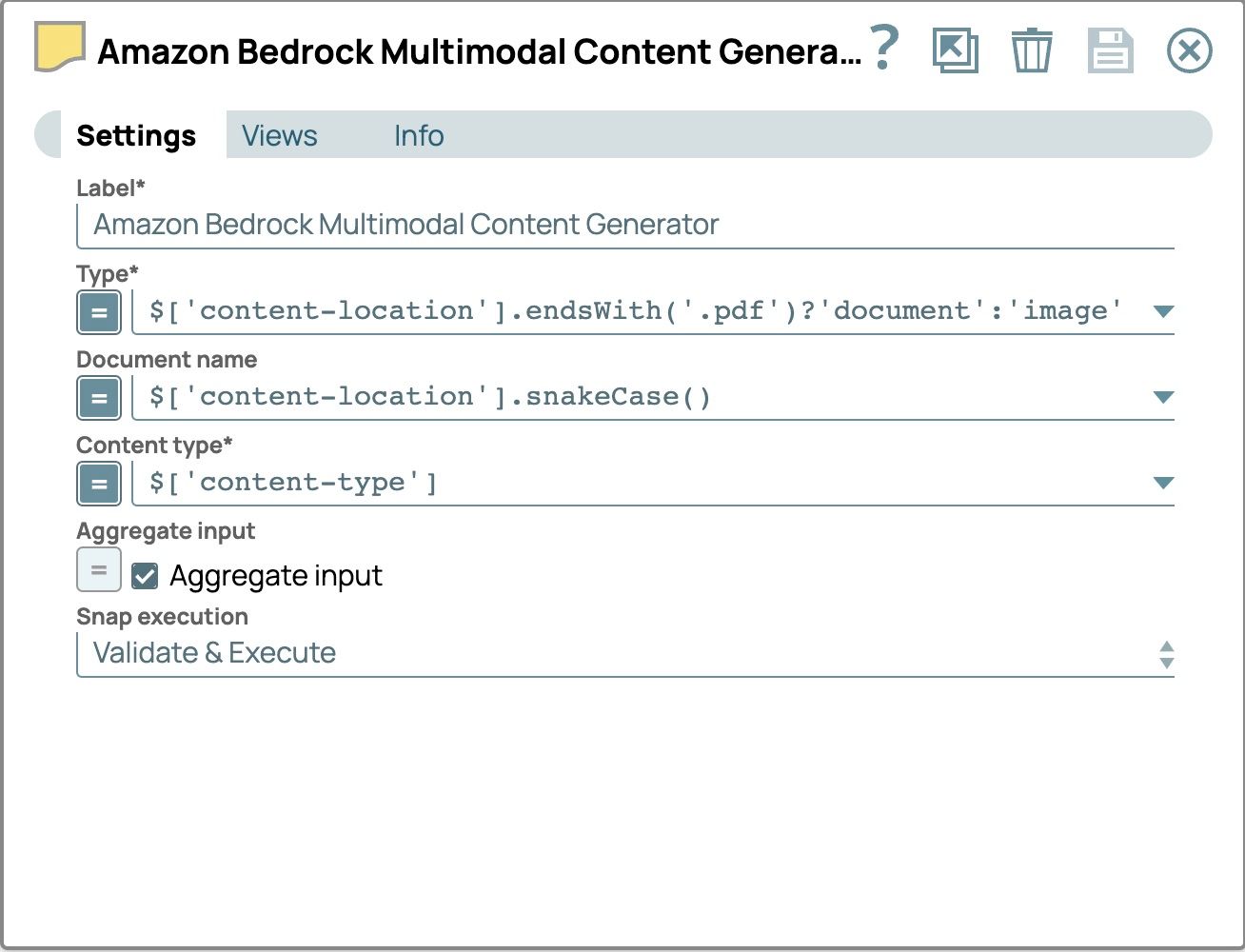
- Clicca su Snap per aprire il pannello delle impostazioni e configurare i seguenti campi:
- Tipo:
- abilitare l'espressione
- imposta il valore su$['content-location'].endsWith('.pdf') ? 'document' : 'image'
- Nome del documento
- abilitare l'espressione
- imposta il valore su
$[‘content-location’].snakeCase() - Utilizza la versione snake-case del percorso del file come nome del documento per identificare ogni file e renderlo compatibile con l'API Amazon Bedrock Converse. Nello snake case, le parole sono in minuscolo e separate da trattini bassi (_).
- Input aggregato
- selezionare la casella di controllo
- Utilizza questa opzione per unire tutti i file di input in un unico documento.
- Le impostazioni dovrebbero ora apparire come segue
- Tipo:
- Convalida la pipeline per vedere il Generatore di contenuti multimodali Scatta l'output.
L'anteprima dovrebbe apparire come nell'immagine sottostante. Lo sl_type sarà documento per il file pdf e immagine per il file immagine e il nome sarà il percorso semplificato del file.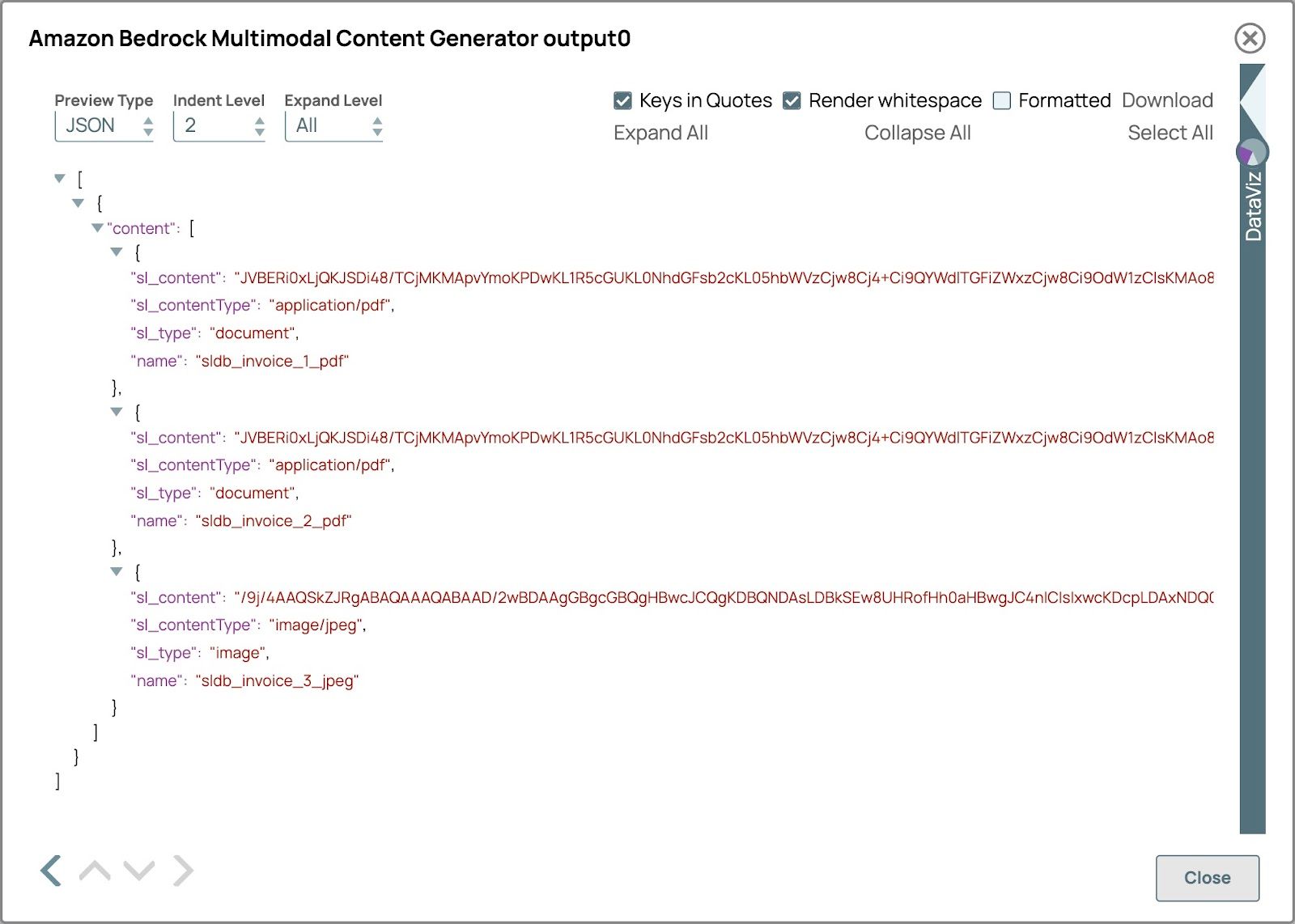
- Aggiungi lo Snap Prompt Generator:
- Trascinare e rilasciare lo Snap Prompt Generator sulla tela del designer e collegarlo allo Snap Multimodal Content Generator.
- Clicca su Snap per aprire il pannello delle impostazioni e configurare i seguenti campi:
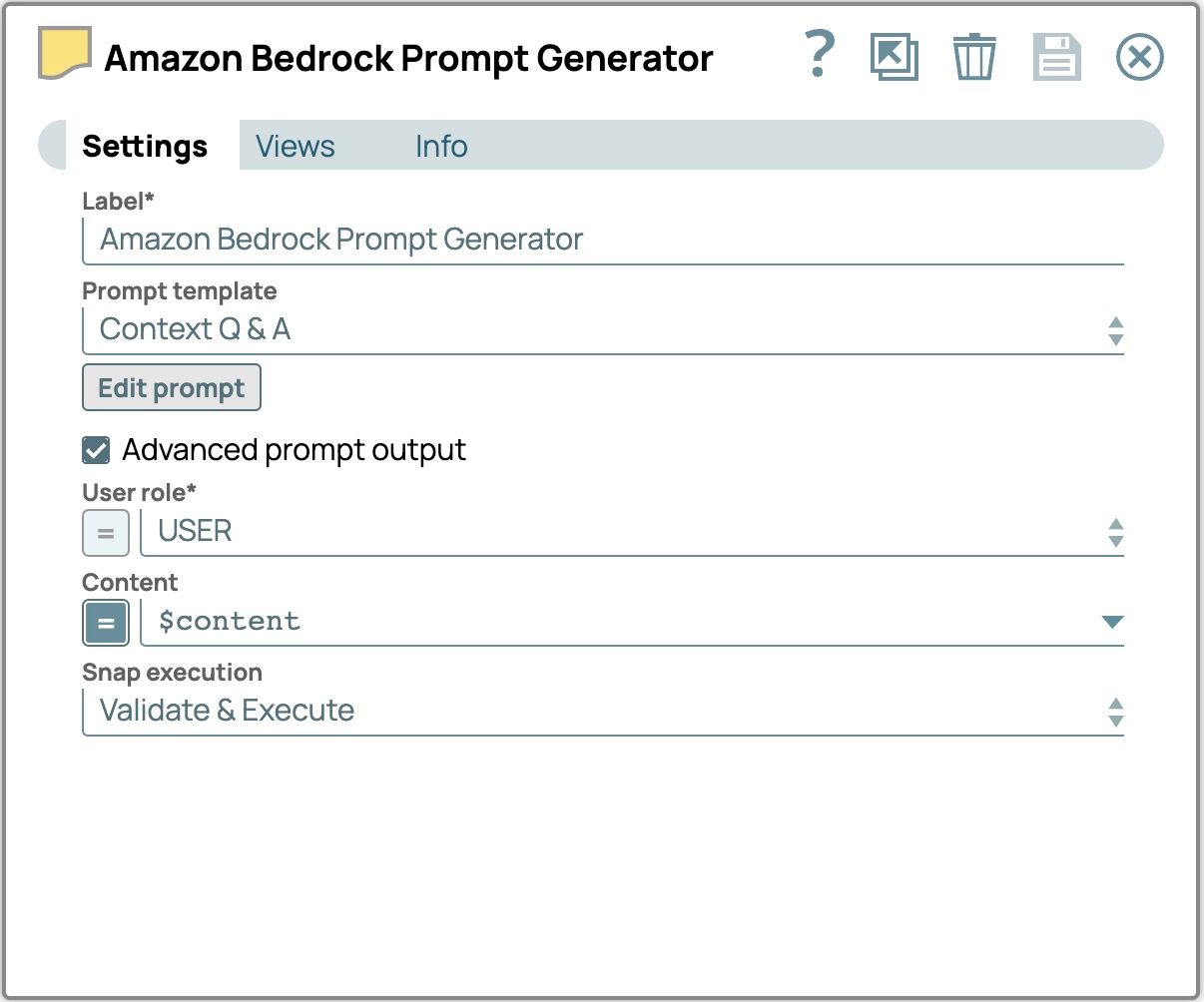
- Selezionare la casella di controllo Output prompt avanzato.
- Imposta il contenuto su $content per utilizzare il contenuto inserito dal generatore di contenuti multimodali Snap.
- Clicca su "Modifica prompt" e inserisci le tue istruzioni. Ad esempio,
Sulla base della quantità totale indicata in tutte le fatture,
quale prodotto presenta le quantità di acquisto più elevate e più basse,
e in quali fatture sono riportati questi dettagli?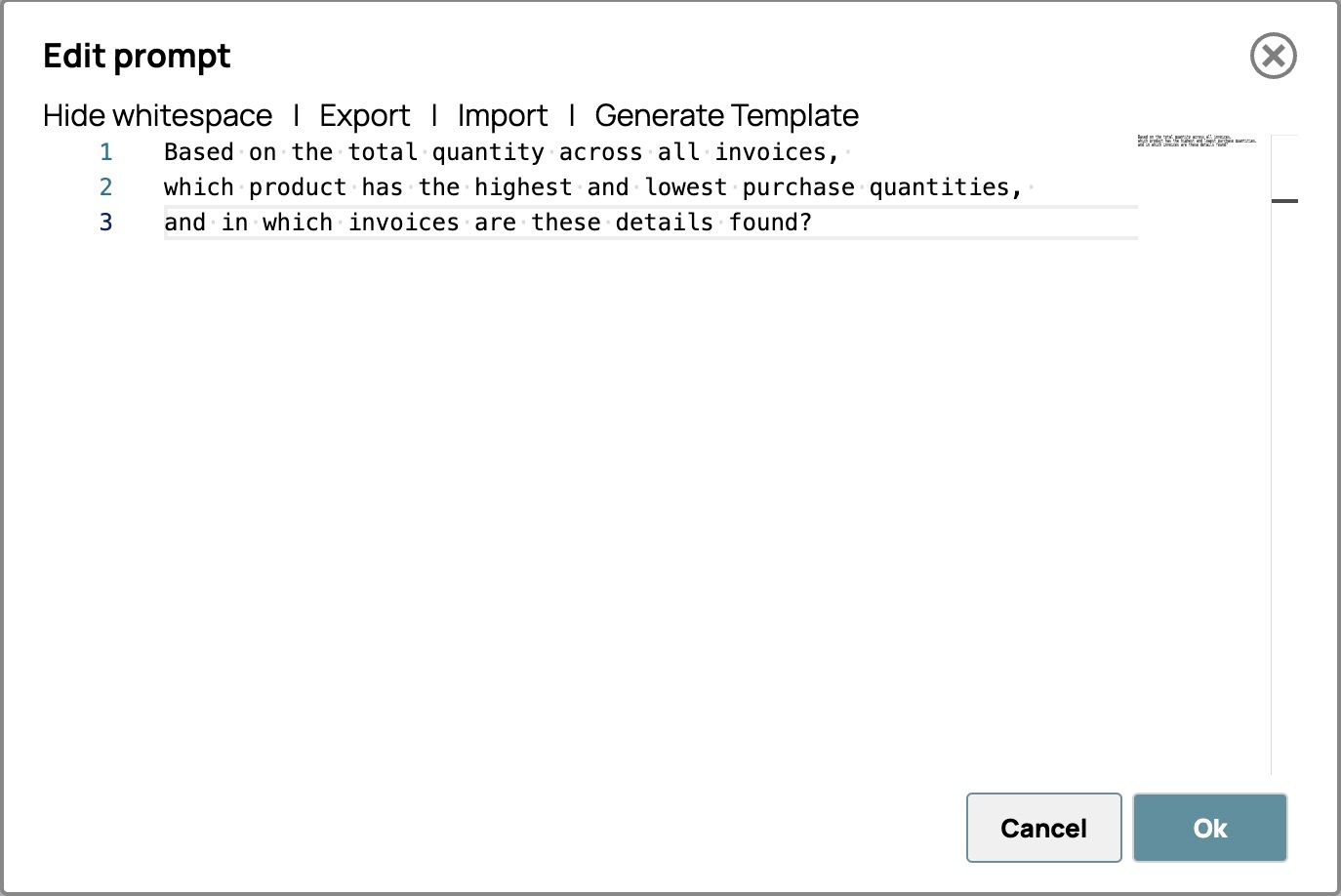
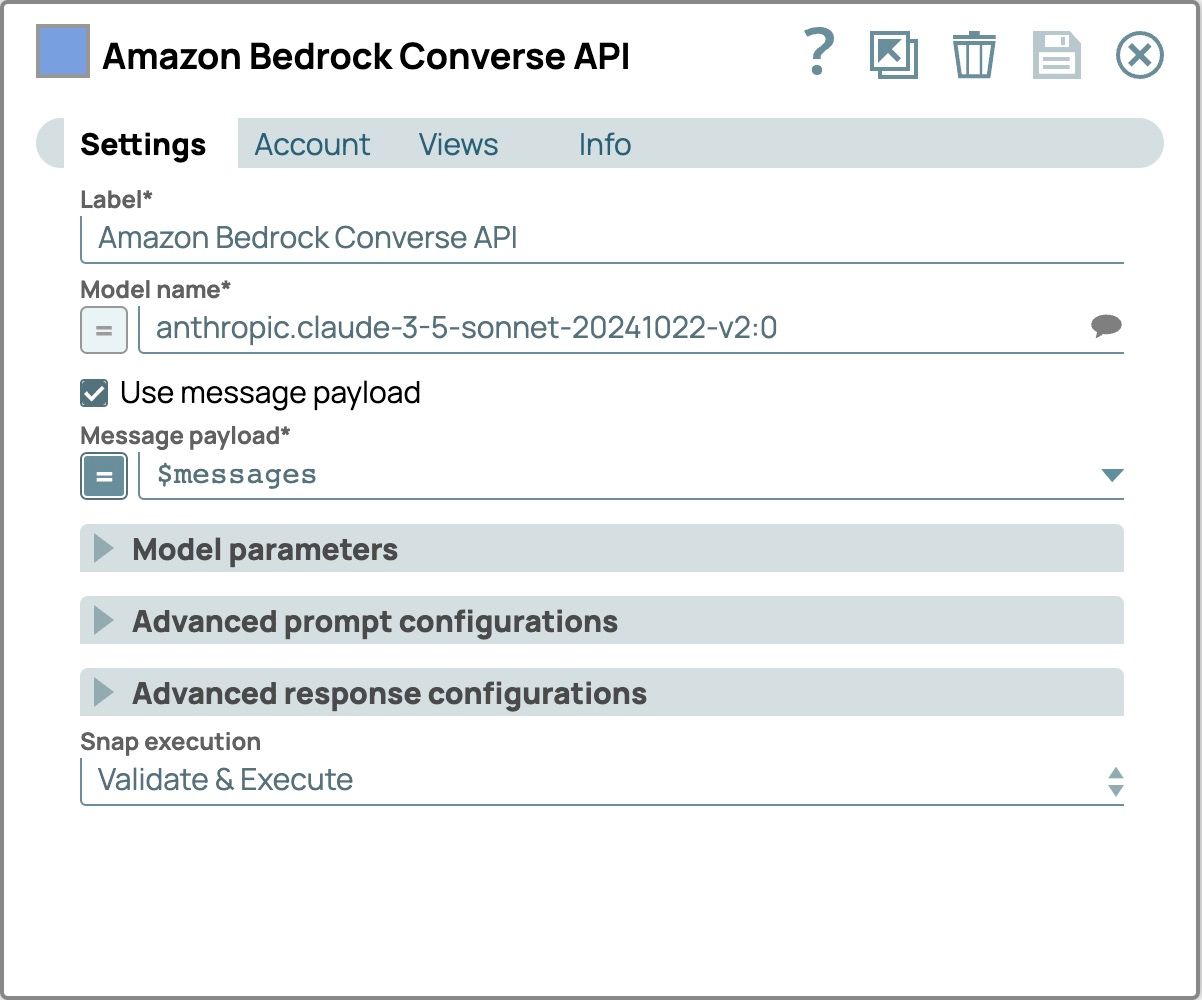
- Aggiungi e configura lo Snap LLM:
- Aggiungi Amazon Bedrock Converse API Snap come LLM
- Collega questo Snap al Snap Generatore di prompt
- Clicca su Snap per aprire il pannello di configurazione
- Seleziona la scheda Account e seleziona il tuo account
- Seleziona il Impostazioni scheda
- Seleziona un modello che supporti contenuti multimodali.
- Selezionare la casella di controllo Usa payload messaggio
- Imposta il Carico utile del messaggio a $messaggi utilizzare il messaggio dal Generatore di prompt Scatto
- Verifica il risultato:
Convalida la pipeline e apri l'anteprima del API Amazon Bedrock Converse Clicca. Il risultato dovrebbe essere simile al seguente: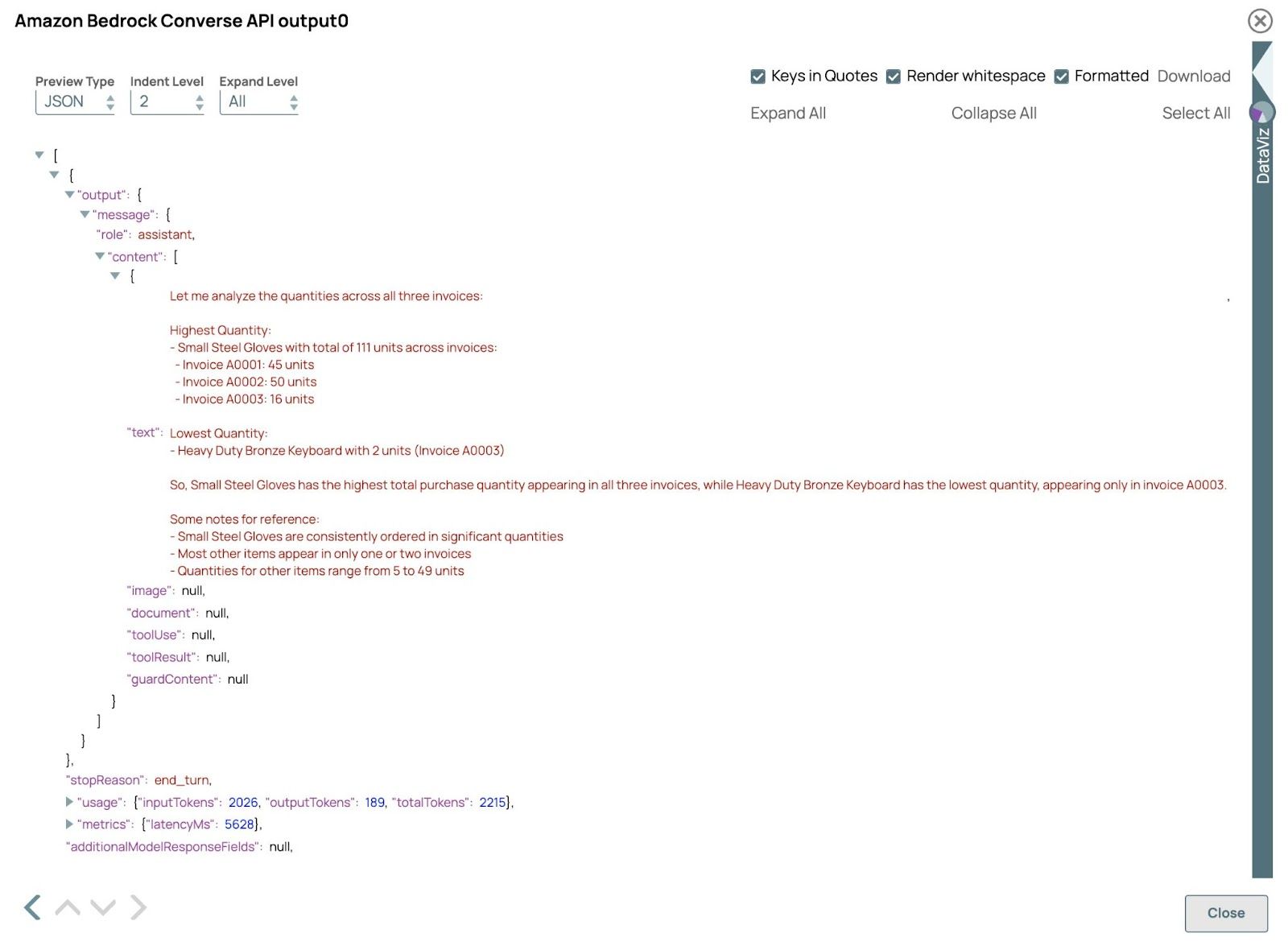
In questo esempio, l'LLM elabora con successo fatture sia in formato PDF che immagine, dimostrando la sua capacità di gestire input diversi in un unico flusso di lavoro. Estraendo e analizzando i dati in questi formati, l'LLM fornisce risposte e approfondimenti accurati, dimostrando l'efficienza e la flessibilità dell'elaborazione multimodale. È possibile regolare le query nel Generatore di prompt Clicca per esplorare diversi risultati.





