Nel nostro ultimo articolo sul contesto degli agenti di dati, abbiamo spiegato perché il contesto rappresenta il problema fondamentale per gli agenti di IA aziendali. Al di sopra del modello, della potenza di calcolo e della pipeline si colloca un requisito ancora più fondamentale: il contesto. Un agente che non sa a quali sistemi è collegato, cosa contengono tali sistemi o come interrogarli correttamente genererà risposte che sembrano plausibili ma che non rispecchiano la realtà.
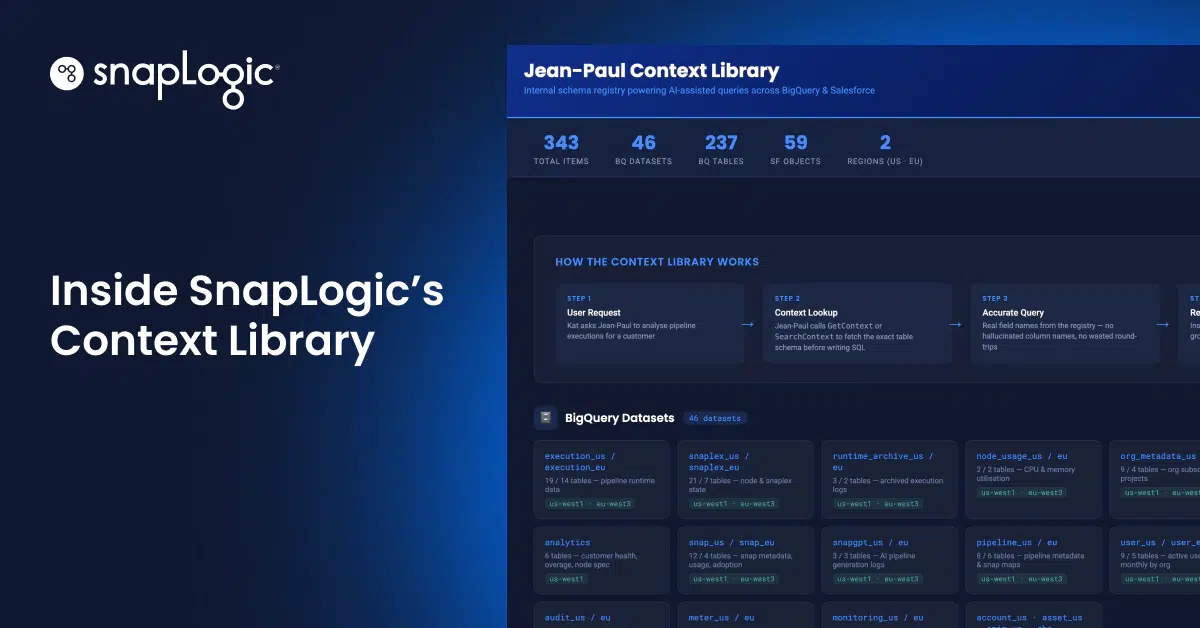
Questo articolo offre una panoramica della Context Library, una funzionalità fondamentale di Jean-Paul, l'Enterprise AI Agent di SnapLogic, che garantisce l'affidabilità degli agenti di intelligenza artificiale negli ambienti aziendali di produzione. Il testo illustra come viene individuato il contesto, come viene archiviato, come viene applicato e perché proprio l'applicazione del contesto fa la differenza tra un'implementazione affidabile e una semplice demo ben intenzionata.
Perché gli agenti di IA aziendali falliscono dal punto di vista del contesto
Quando un agente di intelligenza artificiale interroga Salesforce, deve conoscere alcuni dettagli specifici del proprio ambiente: a quale organizzazione si sta rivolgendo, quali oggetti sono presenti, quali campi contengono, quali nomi di campo l'API si aspetta effettivamente e quali oggetti sono attivi e quali invece sono relitti abbandonati di un progetto di integrazione risalente a tre anni fa.
Quelle informazioni devono pur provenire da qualche parte. Non si trovano nei pesi del modello, né nella configurazione dei connettori. In assenza di un contesto strutturato, gli agenti ricorrono all'inferenza. Ad esempio, essi:
- Interroga “Account.Name” quando il campo effettivo è “Account.Customer_Name__c”
- Scrivere una query SOQL su oggetti privi di record
- Tipi di campo interpretati erroneamente, nullabilità interpretata erroneamente e risultati restituiti che sembrano corretti finché non vengono verificati.
Il contesto non è un semplice optional. È ciò che distingue un agente in grado di effettuare ricerche accurate da uno che formula deduzioni errate.
La Context Library è la risposta di SnapLogic a questa esigenza. Si tratta di una base di conoscenze strutturata, consultabile e che si aggiorna automaticamente, che Jean-Paul consulta prima di agire. È inoltre programmata per effettuare questa consultazione prima di agire. Ecco come funziona.
Scoperta degli strumenti: il ruolo del contesto
La Libreria dei contesti è integrata nell'interfaccia di amministrazione di Jean-Paul e presenta due schede principali: "Ricerca strumenti " e "Contesti". È dalla scheda "Ricerca strumenti" che ha inizio il processo.
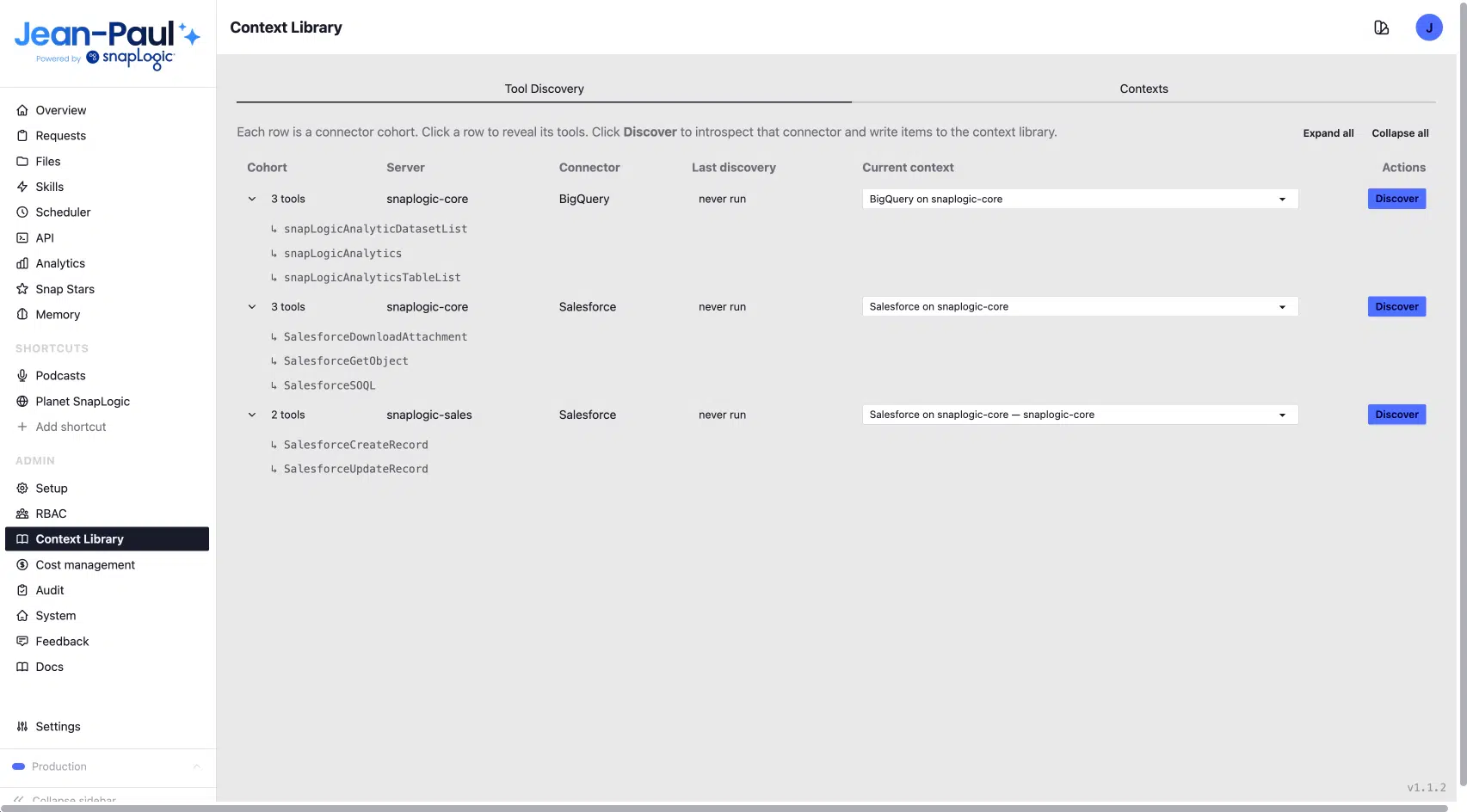
La scheda "Ricerca strumenti" elenca tutte le serie di connettori a disposizione di Jean-Paul, tra cui:
- BigQuery su SnapLogic Core
- Salesforce su SnapLogic Core
- Salesforce su SnapLogic Sales
Ogni voce mostra la data dell'ultimo rilevamento e presenta un unico pulsante "Scopri".
Cliccando su "Scopri" si esegue direttamente l'introspezione del connettore in tempo reale. Jean-Paul comunica con il sistema collegato, ne elenca i contenuti e registra i risultati nella libreria: schemi degli oggetti, descrizioni dei campi, tipi di dati, indicatori di nullabilità, numero di record, timestamp dell'ultima attività e una sintesi dello scopo di ciascun oggetto. L'agente vede ciò che è effettivamente presente: dati aggiornati, in tempo reale e accurati.
Una singola esecuzione della funzione di rilevamento di Salesforce genera 59 oggetti, ciascuno con metadati completi a livello di campo: nomi API, etichette, numero di campi e note strutturate che l'agente può leggere e analizzare al momento dell'esecuzione della query. Ogni funzione di rilevamento è progettata appositamente per il sistema che analizza.
La funzione di individuazione di Salesforce individua gli oggetti rilevanti per l'utilizzo da parte degli agenti, filtra quelli privi di record ed esclude quelli senza personalizzazioni o configurazioni significative. È così che si arriva a 59 oggetti selezionati e ricchi di informazioni, anziché a un elenco grezzo di diverse centinaia.
Lo stesso principio vale per le piattaforme di dati (BigQuery, Snowflake, Databricks, Oracle, PostgreSQL), che richiedono un'analisi a livello di catalogo poiché gli schemi non sono autodocumentanti a livello di campo. L'individuazione del contesto è necessaria per qualsiasi sistema di registrazione (Salesforce, ServiceNow, piattaforme HCM) o data warehouse che possa essere personalizzato o esteso. Jean-Paul include funzioni di individuazione per tutti questi sistemi.
Il cambiamento architettonico che conta: la documentazione come effetto collaterale dell'introspezione. Viene generata automaticamente dalla piattaforma e riflette sempre lo stato attuale del sistema.
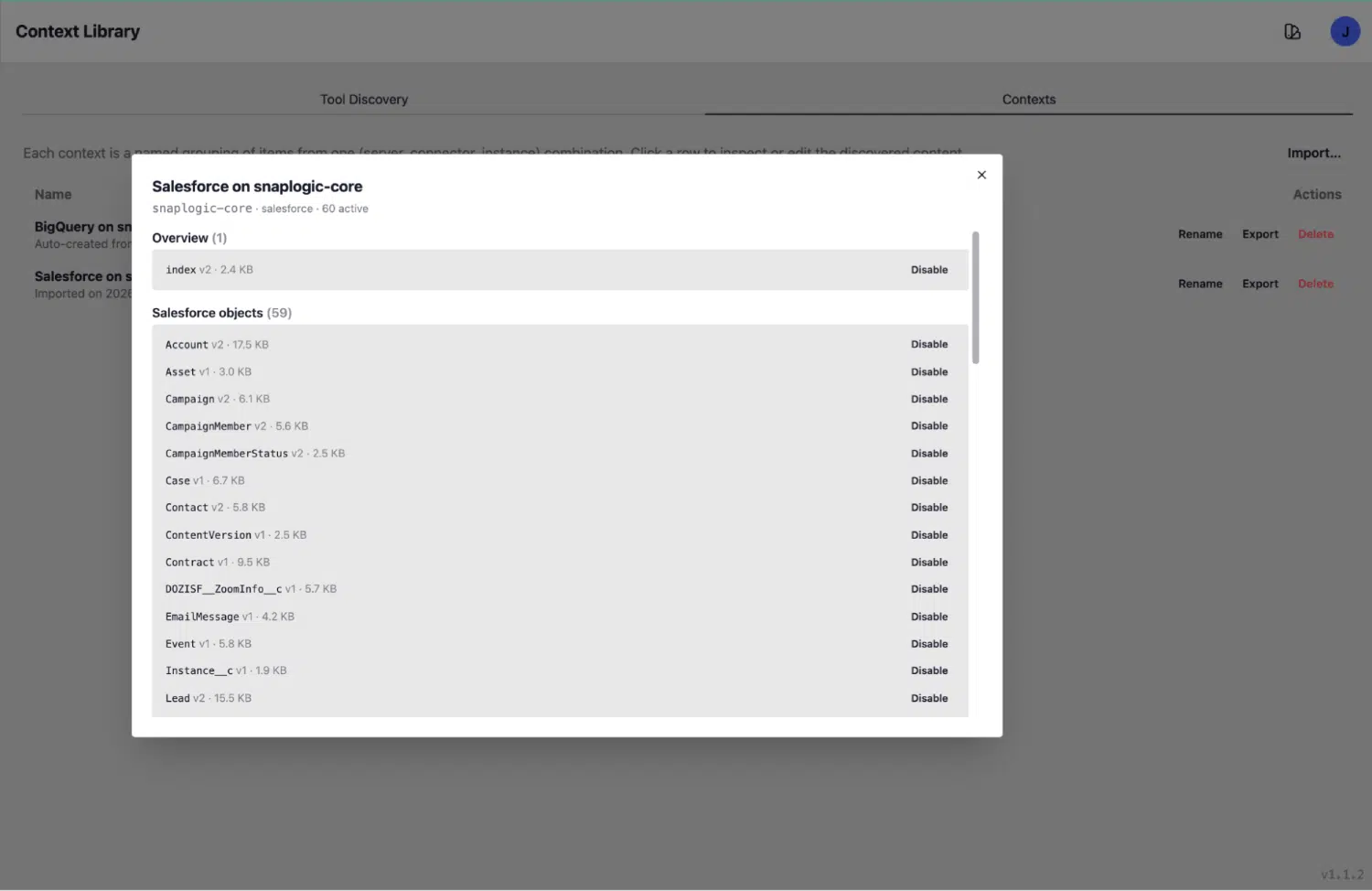
La scheda "Contesti": una base di conoscenze ricca e strutturata
Una volta individuato, ogni oggetto diventa una voce dettagliata nella scheda "Contesti". Questo è ciò che l'agente legge al momento dell'inferenza: un documento di conoscenza strutturato contenente tutto il necessario per effettuare una ricerca accurata.
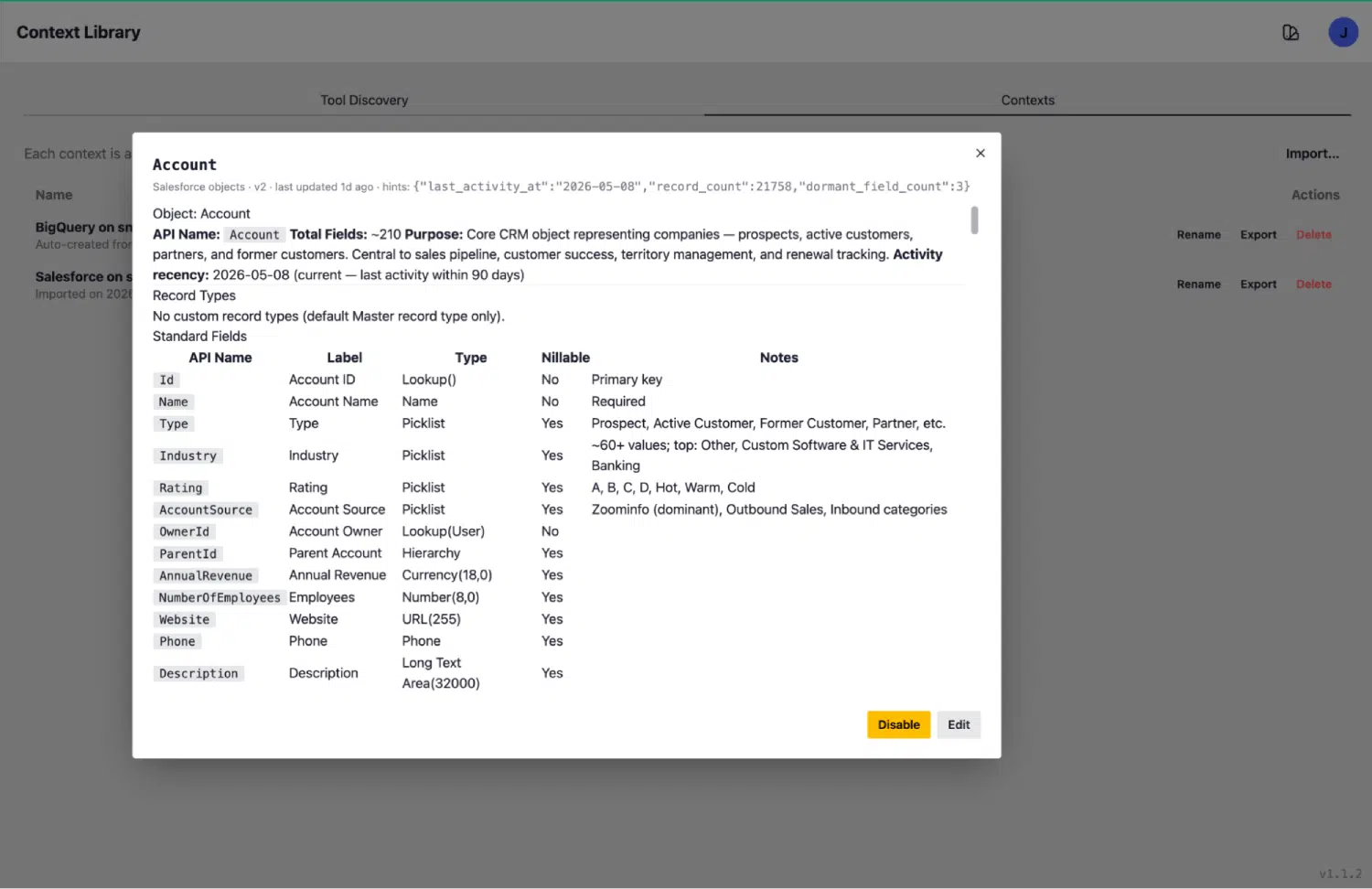
Prendiamo come esempio concreto l'oggetto Account. La sua voce di contesto include:
- Nome e tipo dell'API: Account, sf_object
- Sintesi dello scopo: «Oggetto CRM fondamentale che rappresenta aziende, potenziali clienti, clienti attivi, ex clienti, partner, ecc.»
- Numero di record: 21.168
- Attività recente: ultima attività il 22/05/2026, entro gli ultimi 90 giorni (questo oggetto è attivo e in uso)
- Totale campi: 210 campi, elencati con etichette, nomi API, tipi di dati, indicatori di nullabilità e note di facile comprensione
- Segnali di inattività: indicati ove applicabile, in modo che l'agente sappia quali oggetti sono attivi e quali sono di fatto abbandonati
Il contesto di BigQuery funziona allo stesso modo. L'introspezione del connettore BigQuery genera voci di contesto a livello di dataset e di tabella: definizioni dello schema, descrizioni delle colonne, chiavi di partizione, numero di righe e indicatori di attualità dei dati. Un agente che chiede «Cosa contiene la tabella pipeline_events?» riceve dalla libreria una risposta strutturata, basata sulle informazioni attuali relative allo schema.
La precisione a livello di campo determina se una query va a buon fine o restituisce silenziosamente risultati errati. In un ambiente di produzione, questa differenza è fondamentale.
Politiche relative agli strumenti: rendere obbligatorio l'uso del contesto
Disporre di un contesto accurato è un requisito fondamentale. Assicurarsi che l'agente lo legga prima di ogni chiamata allo strumento è un altro. La scheda "Tool Policies" di Jean-Paul costituisce il livello di applicazione che collega questi due aspetti.
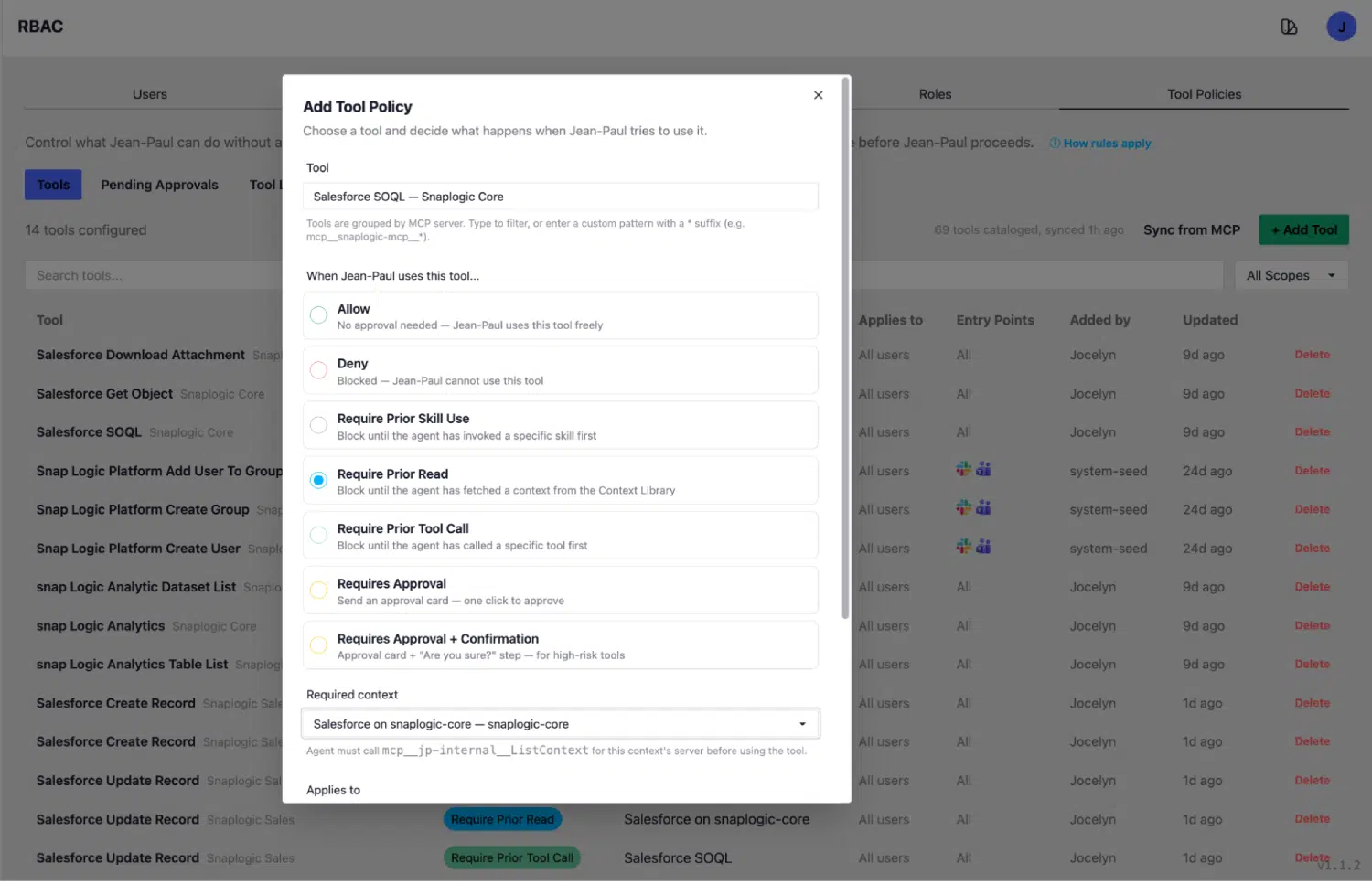
Ogni strumento registrato nella piattaforma SnapLogic è associato a una politica. I tipi di politica più importanti richiedono:
- Approvazione: è necessaria la conferma da parte di un utente prima che lo strumento esegua l'operazione. Utilizzata per operazioni di scrittura, azioni irreversibili e qualsiasi operazione che comporti conseguenze concrete.
- Lettura preliminare: l'agente deve recuperare una voce di contesto dalla Libreria dei contesti prima che questo strumento possa essere eseguito. L'esecuzione è subordinata a tale lettura. Questa è la politica che impone l'esecuzione di query basate sullo schema.
- Chiamata a uno strumento precedente: l'agente deve richiamare uno strumento prerequisito specificato prima che questo strumento possa essere eseguito. L'esecuzione è subordinata a tale chiamata precedente.
L'esempio classico: SalesforceSOQL prevede una politica denominata "Require Prior Read" che impone di eseguire prima una chiamata GetContext(sf_object). L'agente non può eseguire una query SOQL senza aver prima letto il contesto dell'oggetto pertinente dalla libreria. La politica funge da filtro.
Lo stesso principio vale per le query BigQuery, le ricerche relative alle politiche delle risorse umane, la consultazione dei verbali delle riunioni e qualsiasi strumento che richieda una conoscenza approfondita dello schema per funzionare correttamente. Attualmente sono configurate e applicate sedici politiche in tutti gli ambiti dei connettori.
Una volta implementate le politiche relative agli strumenti, l'agente chiama ogni volta GetContext e poi SalesforceSOQL, sempre in quest'ordine. Derive dello schema, oggetti obsoleti, complessità delle organizzazioni multiple: tutto diventa gestibile quando l'agente è strutturalmente tenuto a consultare le conoscenze aggiornate prima di agire. Basta creare il giusto livello di applicazione e le indicazioni si risolvono da sole.
Mantenere aggiornata la libreria dei contesti
Gli schemi aziendali sono in continua evoluzione. I campi vengono rinominati. Alcuni oggetti vengono dismessi. Vengono aggiunte nuove tabelle. Il numero di record varia. Una libreria di contesti deve riflettere lo stato attuale di ogni sistema collegato ed essere aggiornata automaticamente man mano che tali sistemi cambiano.
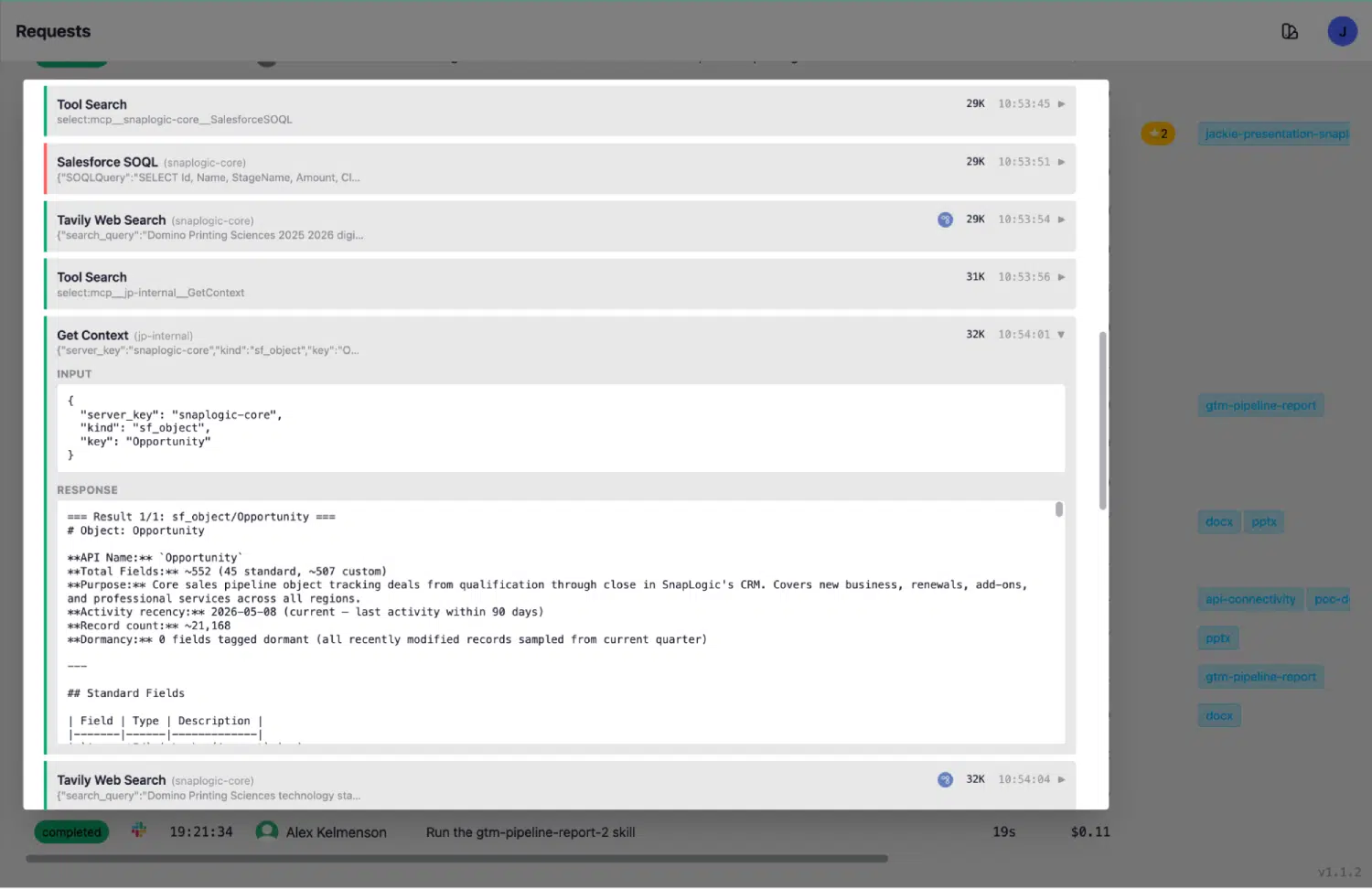
La Context Library risolve questo problema tramite la re-introspezione in tempo reale. Ogni voce del contesto è accompagnata da un timestamp che indica l’ora dell’ultima rilevazione. Il pulsante «Discover» riavvia su richiesta l’introspezione completa sul connettore in tempo reale. La rilezione programmata mantiene la libreria aggiornata senza alcun intervento manuale.
Il registro delle richieste costituisce la traccia di controllo di ogni azione compiuta dagli agenti. Quando un agente esegue una query in Salesforce, il registro mostra l'intera sequenza: ToolSearch per individuare la chiave di contesto corretta, GetContext che restituisce una risposta in tempo reale comprendente il numero di record odierno e la data dell'ultima attività, quindi SalesforceSOQL che esegue l'operazione sulla base di informazioni accurate e aggiornate relative allo schema.
Il contesto che l'agente legge riflette lo stato attuale del sistema. È proprio questo che rende le implementazioni aziendali in produzione sulla piattaforma SnapLogic fondamentalmente diverse: le informazioni dell'agente sui sistemi collegati rimangono aggiornate automaticamente, senza che sia necessario un intervento umano per aggiornare la documentazione ogni volta che un amministratore di Salesforce aggiunge un campo.
Come si traduce tutto ciò nelle implementazioni reali
Gli ambienti di dati aziendali possono essere piuttosto disordinati. I sistemi cambiano, i connettori si moltiplicano e le organizzazioni crescono a un ritmo che supera quello della documentazione. La Context Library è stata progettata per gestire questa complessità senza richiedere un intervento umano ogni volta che si verifica un cambiamento. Ecco come funziona nei principali scenari che i team IT e di gestione dei dati devono affrontare:
- Deriva dello schema: quando l'amministratore di Salesforce rinomina o riorganizza i campi, la successiva esecuzione della scoperta aggiorna automaticamente la libreria. L'agente interroga la nuova configurazione, non un'istantanea obsoleta.
- Proliferazione dei connettori: quando Salesforce è presente in più ambiti di connettori (vendite, core, partner), a ciascuno viene assegnato un proprio contesto di individuazione. L'agente sa esattamente dove si trova ogni oggetto, senza dover fare supposizioni.
- Ambienti multi-organizzazione: le voci di contesto separate per ciascuna organizzazione includono il conteggio dei record e i segnali di attività, in modo che l'agente possa distinguere i sistemi di produzione attivi da quelli legacy inattivi.
- Tracciabilità: ogni contesto letto viene registrato, fornendo ai team addetti alla conformità una visione chiara delle informazioni che hanno determinato ogni azione degli agenti.
Il filo conduttore che accomuna tutti questi aspetti è un semplice principio architettonico: gli agenti di intelligenza artificiale operano al livello delle informazioni che ricevono. Se si strutturano correttamente tali informazioni e le si mantengono aggiornate, il modello avrà tutto ciò che serve per essere davvero utile.
La Context Library è ora disponibile su Jean-Paul ed è già operativa sulla piattaforma SnapLogic, integrandosi con Salesforce, BigQuery, Zendesk, i verbali delle riunioni, le politiche delle risorse umane e un numero sempre crescente di sistemi collegati.
Richiedi l'accesso anticipato a Jean-Paul
Jean-Paul, l'Enterprise AI Agent di SnapLogic, è ora disponibile per alcuni clienti selezionati nell'ambito dell'accesso anticipato. Se la tua azienda è pronta a passare dalla versione demo a un'implementazione operativa, ci farebbe piacere parlarti.