Dans notre dernier article consacré au contexte des agents de données, nous avons expliqué pourquoi le contexte constitue le problème fondamental pour les agents d'IA d'entreprise. Au-delà du modèle, de la puissance de calcul et du pipeline, il existe une exigence plus fondamentale encore : le contexte. Un agent qui ignore à quels systèmes il est connecté, ce que ces systèmes contiennent ou comment les interroger correctement produira des réponses qui semblent plausibles mais qui ne reflètent pas la réalité.
Cet article propose une présentation de la bibliothèque Context, une fonctionnalité essentielle de Jean-Paul, l'agent d'IA d'entreprise de SnapLogic, qui garantit la fiabilité des agents d'IA dans les environnements d'entreprise en production. Il explique comment le contexte est identifié, comment il est stocké, comment il est appliqué, et pourquoi cette application fait toute la différence entre un déploiement fiable et une simple démonstration bien intentionnée.
Pourquoi les agents IA d'entreprise peinent à prendre en compte le contexte
Lorsqu'un agent IA interroge Salesforce, il doit connaître certaines informations spécifiques à votre environnement : à quelle organisation il s'adresse, quels objets existent, quels champs ils contiennent, quels noms de champs l'API attend réellement, et quels objets sont encore actifs par rapport à ceux qui ne sont plus qu'une relique d'un projet d'intégration datant d'il y a trois ans.
Ces informations doivent bien provenir de quelque part. Elles ne se trouvent ni dans les poids du modèle, ni dans la configuration des connecteurs. En l'absence de contexte structuré, les agents se rabattent sur l'inférence. Par exemple, ils :
- Interroger « Account.Name » alors que le champ réel est « Account.Customer_Name__c »
- Écrire une requête SOQL sur des objets ne contenant aucun enregistrement
- Des types de champs mal interprétés, une gestion erronée des valeurs nulles et des résultats qui semblent corrects jusqu’à ce que quelqu’un les valide.
Le contexte n'est pas un simple atout. C'est ce qui distingue un agent capable d'effectuer des requêtes précises de celui qui tire des conclusions erronées.
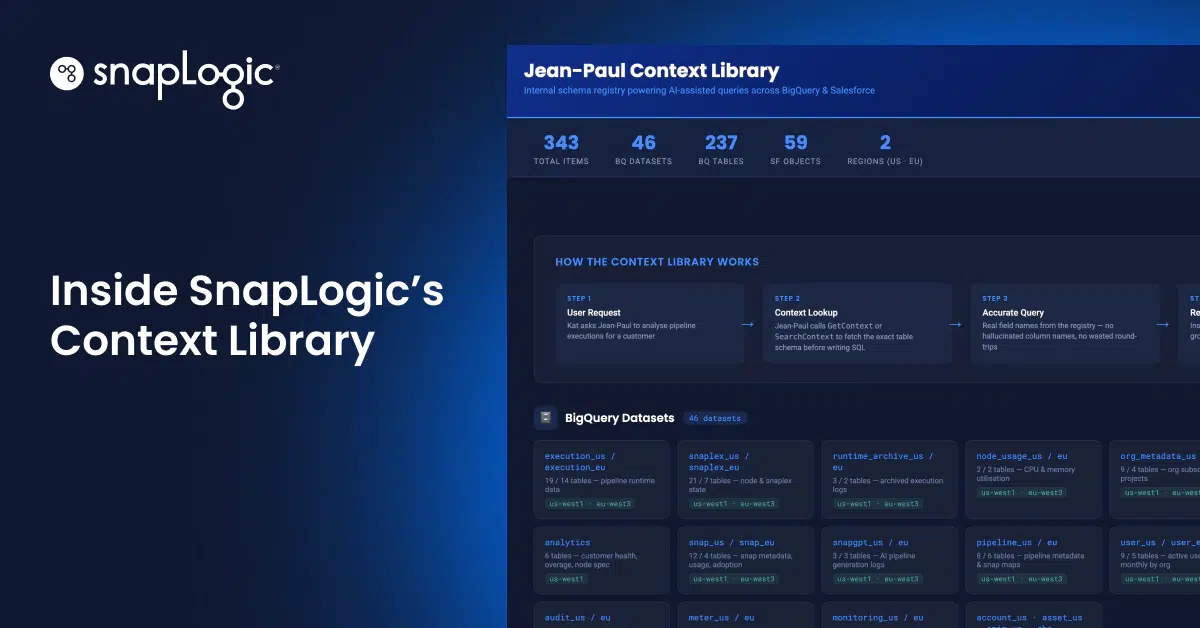
La bibliothèque Context est la réponse apportée par SnapLogic à ce problème. Il s'agit d'une base de connaissances structurée, consultable et mise à jour automatiquement, que Jean-Paul consulte avant d'agir. Il est d'ailleurs obligé de la consulter avant d'agir. Voici comment cela fonctionne.
Découverte d'outils : comment le contexte entre en jeu
La bibliothèque Context est intégrée à l'interface d'administration de Jean-Paul et comporte deux onglets principaux : « Recherche d'outils » et « Contextes ». C'est dans l'onglet « Recherche d'outils » que le processus commence.
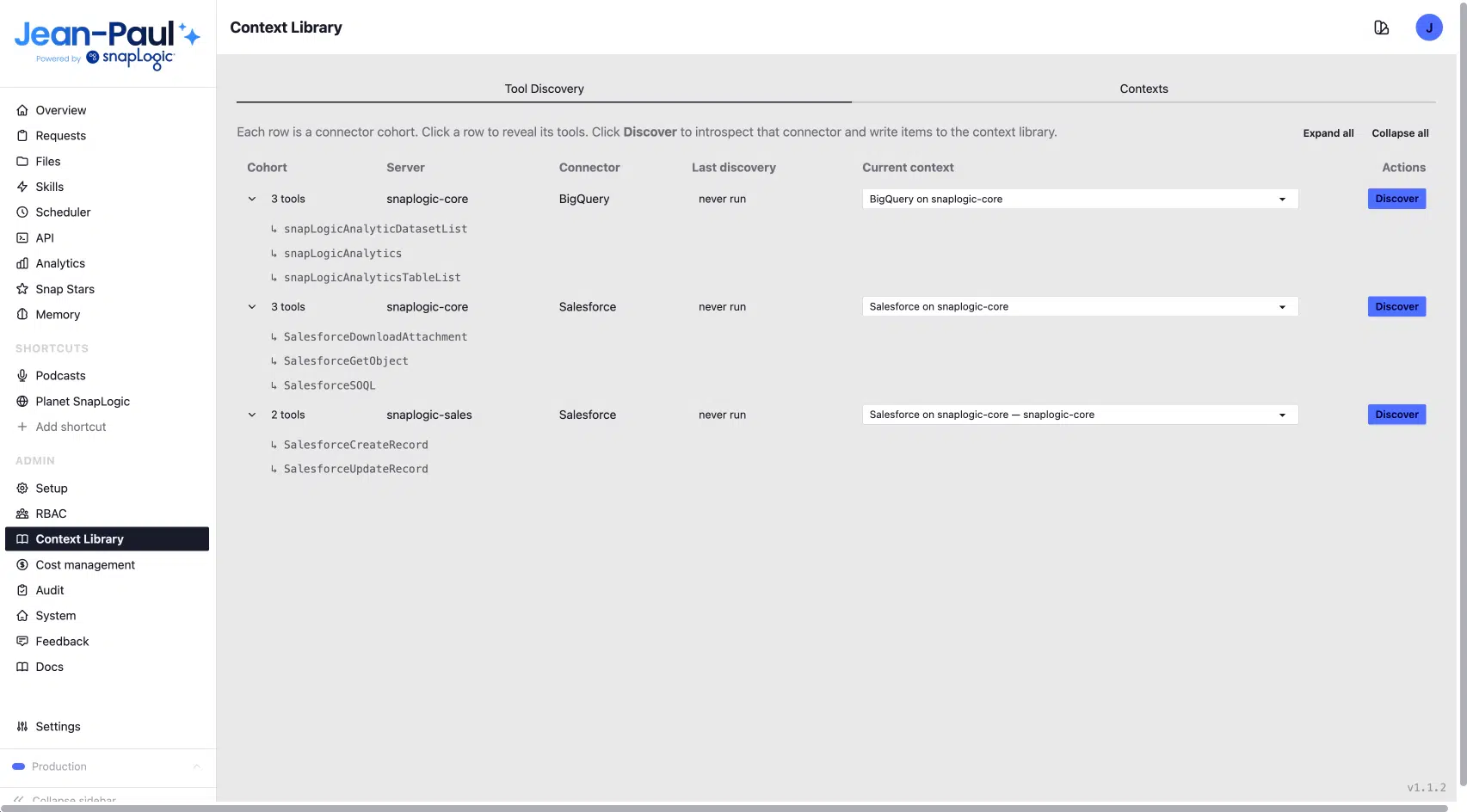
L'onglet « Découverte d'outils » répertorie toutes les cohortes de connecteurs mises à la disposition de Jean-Paul, notamment :
- BigQuery sur SnapLogic Core
- Salesforce sur SnapLogic Core
- Salesforce sur SnapLogic Sales
Chaque entrée affiche la date de sa dernière découverte et comporte un seul bouton « Découvrir ».
En cliquant sur « Découvrir », le connecteur en temps réel est directement analysé. Jean-Paul communique avec le système connecté, recense les éléments présents et enregistre les résultats dans la bibliothèque : schémas d'objets, descriptions de champs, types de données, indicateurs de nullité, nombre d'enregistrements, horodatages de la dernière activité et un résumé synthétique de la fonction de chaque objet. L'agent voit ce qui est réellement présent : des données actuelles, en temps réel et précises.
Une seule exécution de la fonction de découverte de Salesforce génère 59 objets, chacun contenant des métadonnées complètes au niveau des champs : noms d'API, libellés, nombre de champs et notes structurées que l'agent peut lire et analyser au moment de la requête. Chaque fonction de découverte est spécialement conçue pour le système qu'elle analyse.
L'analyse Salesforce identifie les objets pertinents pour une utilisation par les agents, filtre ceux qui ne contiennent aucun enregistrement et exclut ceux qui ne présentent aucune personnalisation ni configuration significative. C'est ainsi qu'elle aboutit à une sélection de 59 objets riches en informations, plutôt qu'à une liste brute de plusieurs centaines d'éléments.
Le même principe s'applique aux plateformes de données (BigQuery, Snowflake, Databricks, Oracle, PostgreSQL), qui nécessitent une introspection au niveau du catalogue, car les schémas ne sont pas auto-documentés au niveau des champs. La découverte du contexte est indispensable pour tout système de référence (Salesforce, ServiceNow, plateformes HCM) ou entrepôt de données pouvant être personnalisé ou étendu. Jean-Paul intègre des fonctions de découverte pour chacun d'entre eux.
Le changement architectural qui compte : la documentation comme effet secondaire de l'introspection. Elle est générée automatiquement par la plateforme reflète toujours l'état actuel du système.
L'onglet « Contexte » : des connaissances riches et structurées
Une fois détecté, chaque objet devient une entrée de contexte détaillée dans l'onglet « Contexts ». C'est ce que l'agent lit au moment de l'inférence : un document de connaissances structuré contenant tout ce qui est nécessaire pour effectuer une requête avec précision.
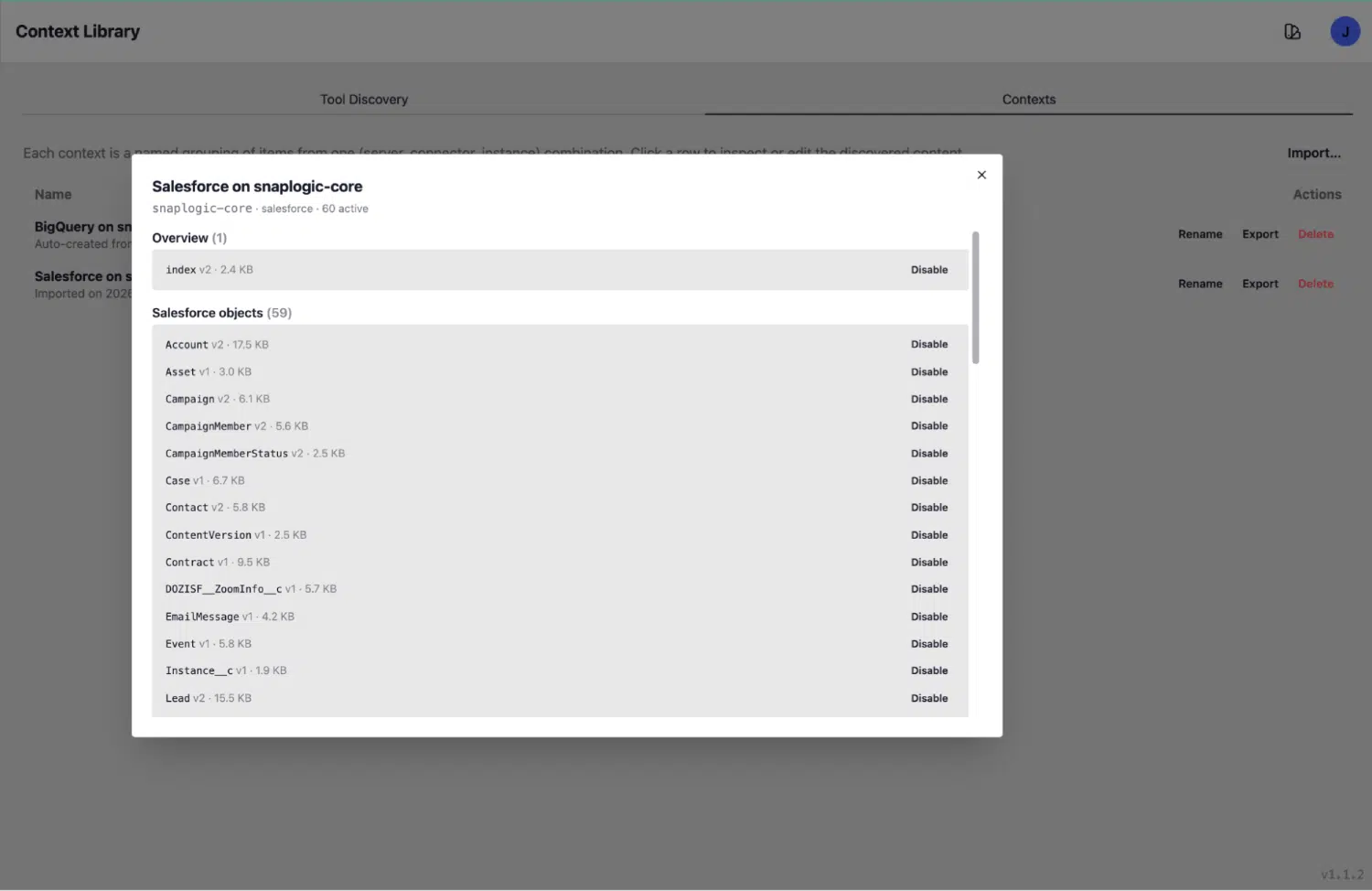
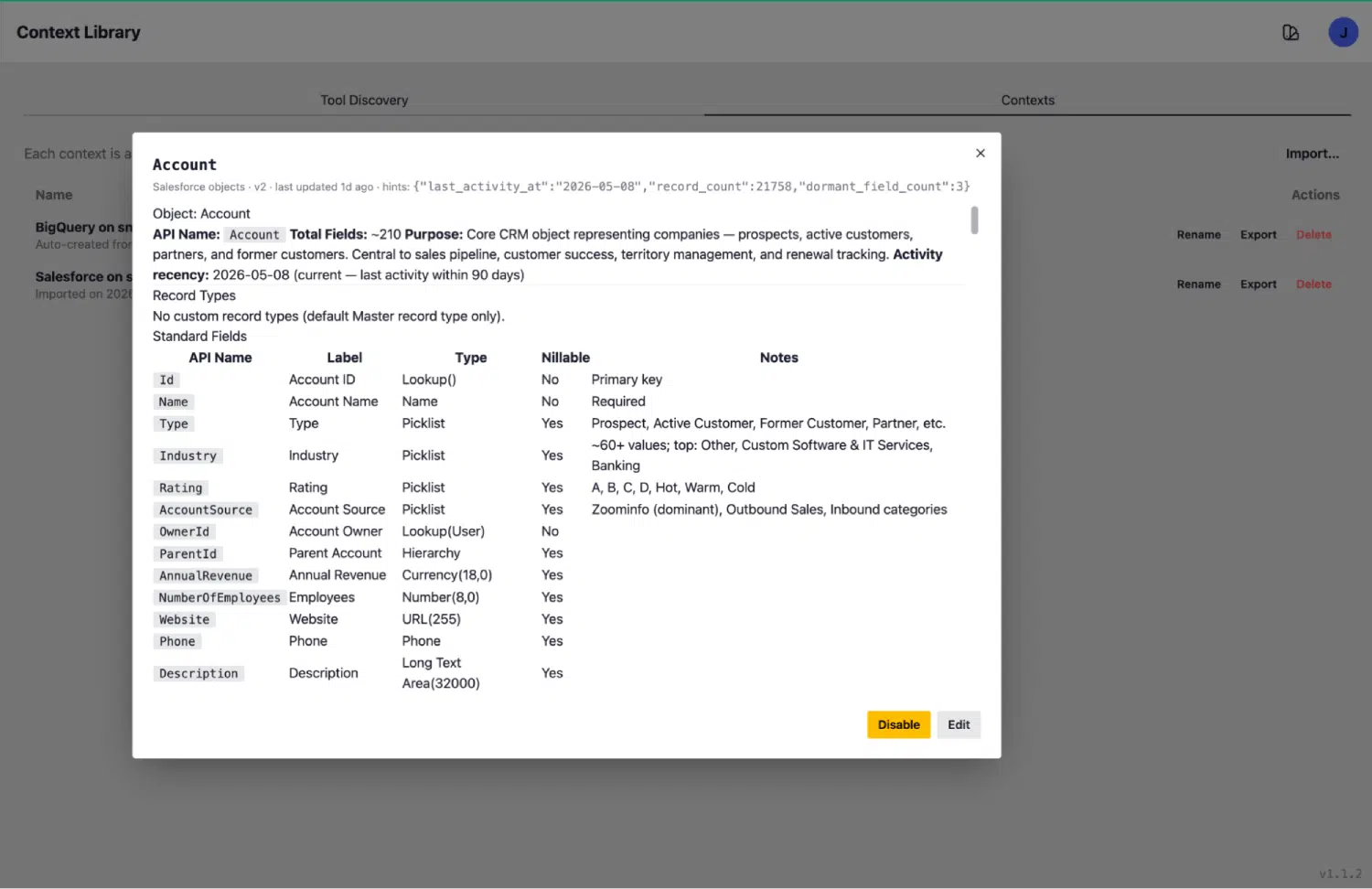
Prenons l'objet Account comme exemple concret. Son entrée de contexte comprend :
- Nom et type de l'API : Account, sf_object
- Résumé de l'objectif : « Objet CRM central représentant les entreprises, les prospects, les clients actifs, les anciens clients, les partenaires, etc. »
- Nombre d'enregistrements : 21 168
- Activité récente : dernière activité le 22 mai 2026, il y a moins de 90 jours (cet objet est actif et utilisé)
- Nombre total de champs : 210 champs, répertoriés avec leurs libellés, leurs noms d'API, leurs types de données, leurs indicateurs de valeur nulle et leurs notes lisibles par l'utilisateur
- Signaux de dormance : mis en évidence le cas échéant, afin que l'agent sache quels objets sont actifs et lesquels sont effectivement abandonnés
Le contexte BigQuery fonctionne de la même manière. L'introspection du connecteur BigQuery génère des entrées de contexte au niveau des ensembles de données et des tables : définitions de schéma, descriptions de colonnes, clés de partition, nombre de lignes et indicateurs de fraîcheur des données. Un agent qui demande « Que contient la table pipeline_events ? » obtient de la bibliothèque une réponse structurée, fondée sur les connaissances actuelles du schéma.
La précision au niveau des champs détermine si une requête aboutit ou renvoie silencieusement des résultats erronés. Dans un environnement de production, cette distinction est cruciale.
Politiques relatives aux outils : rendre obligatoire l'utilisation du contexte
Disposer d'un contexte précis est une exigence. S'assurer que l'agent le consulte avant chaque appel d'outil en est une autre. L'onglet « Politiques d'outils » de Jean-Paul constitue la couche d'application qui relie ces deux éléments.
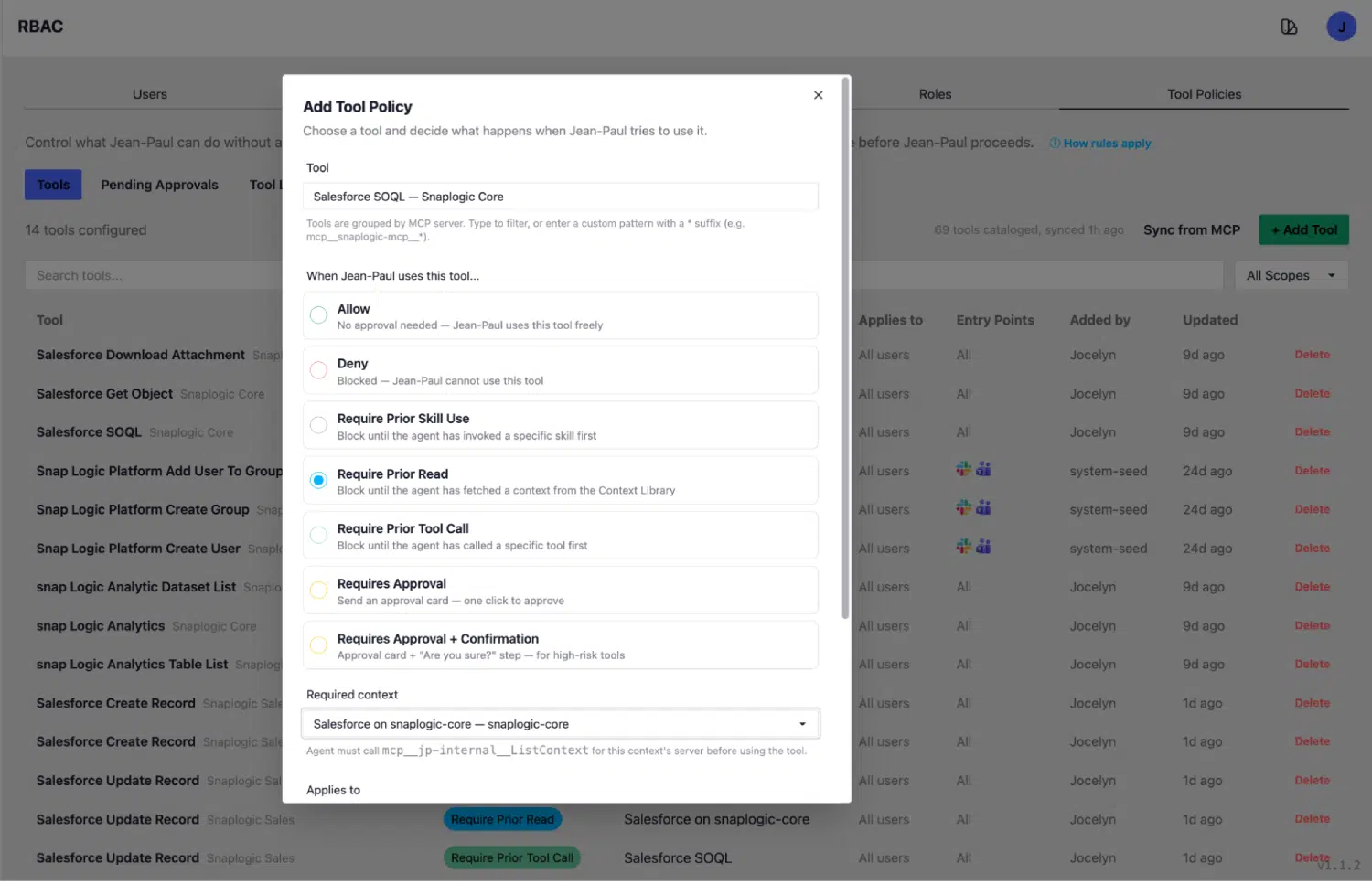
Chaque outil enregistré sur la plateforme SnapLogic plateforme une politique. Les principaux types de politiques requièrent :
- Validation : une intervention humaine est requise avant l'exécution de l'outil. Utilisée pour les opérations d'écriture, les actions irréversibles et toute action ayant des conséquences concrètes.
- Lecture préalable : l'agent doit récupérer une entrée de contexte dans la bibliothèque de contextes avant que cet outil puisse s'exécuter. L'exécution dépend de cette lecture. C'est cette politique qui garantit le respect du principe « schéma d'abord » lors des requêtes.
- Appel préalable d'un outil : l'agent doit appeler un outil préalable spécifié avant que cet outil puisse s'exécuter. L'exécution dépend de cet appel préalable.
L'exemple type : SalesforceSOQL dispose d'une politique « Require Prior Read » qui impose d'effectuer d'abord un appel GetContext(sf_object). L'agent ne peut pas exécuter de requête SOQL sans avoir préalablement lu le contexte de l'objet concerné dans la bibliothèque. Cette politique agit comme un filtre.
Ce principe s'applique également aux requêtes BigQuery, aux recherches de politiques RH, à la consultation des comptes-rendus de réunion et à tout outil dont le bon fonctionnement nécessite une connaissance précise du schéma. Seize politiques sont actuellement configurées et appliquées à l'ensemble des périmètres des connecteurs.
Une fois les règles d'outil mises en place, l'agent appelle systématiquement GetContext, puis SalesforceSOQL, dans cet ordre. Évolution des schémas, objets obsolètes, complexité liée à la gestion de plusieurs organisations : tout cela devient gérable lorsque l'agent est structurellement tenu de consulter les connaissances actuelles avant d'agir. Mettez en place la bonne couche d'application, et les invites se gèrent d'elles-mêmes.
Maintenir la bibliothèque de contextes à jour
Les schémas d'entreprise évoluent en permanence. Des champs sont renommés. Des objets sont obsolètes. De nouvelles tables sont ajoutées. Le nombre d'enregistrements varie. Une bibliothèque de contextes doit refléter l'état actuel de chaque système connecté et être mise à jour automatiquement à mesure que ces systèmes changent.
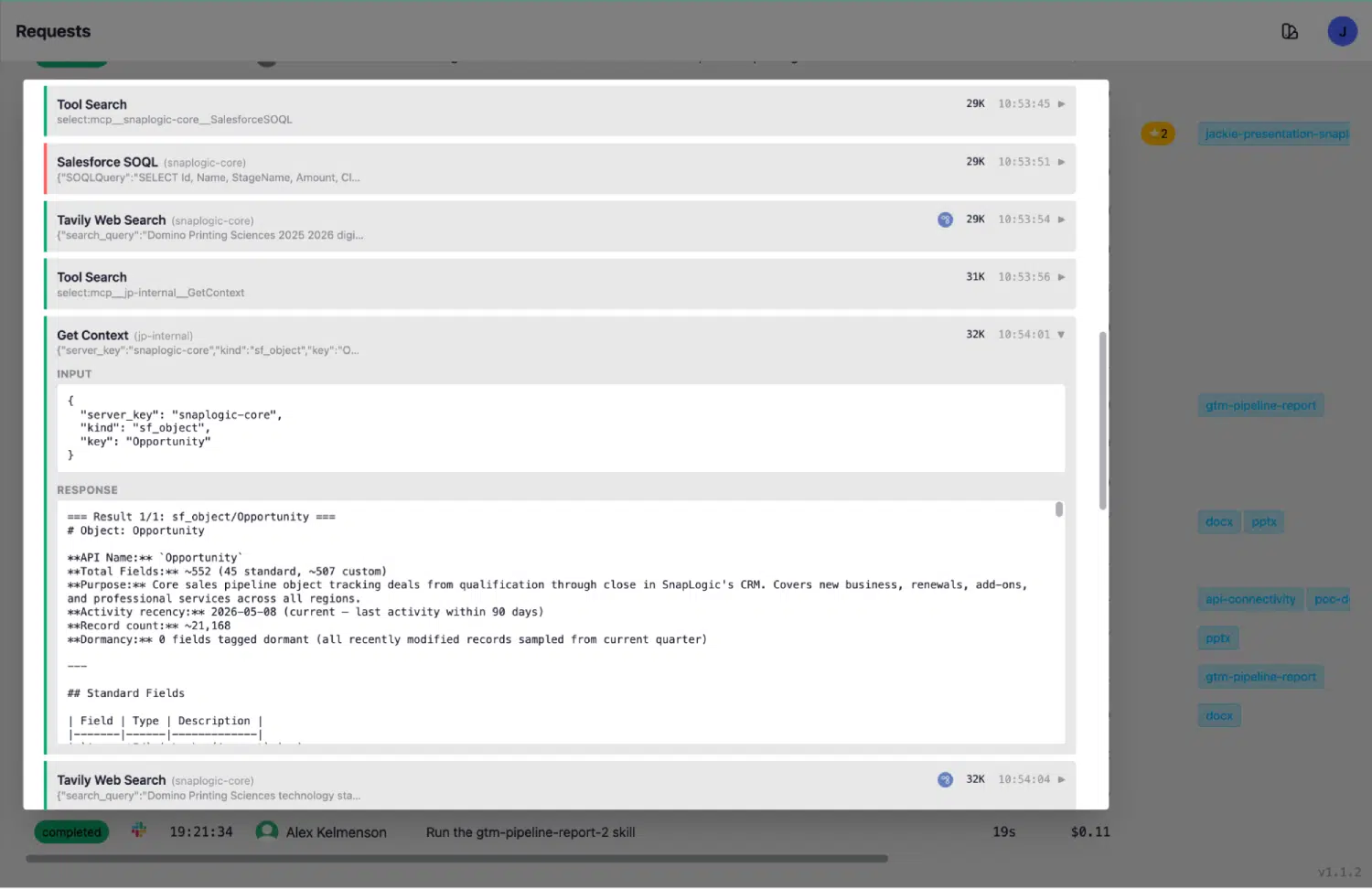
La bibliothèque de contextes résout ce problème grâce à une ré-introspection en temps réel. Chaque entrée de contexte comporte un horodatage indiquant la « dernière découverte ». Le bouton « Découvrir » relance, à la demande, l'introspection complète sur le connecteur en temps réel. La redécouverte planifiée permet de maintenir la bibliothèque à jour sans intervention humaine.
Le journal des requêtes constitue la piste d'audit de toutes les actions effectuées par les agents. Lorsqu'un agent exécute une requête Salesforce, le journal affiche la séquence complète : ToolSearch pour trouver la clé de contexte appropriée, GetContext renvoyant une réponse en temps réel qui inclut le nombre d'enregistrements du jour et la date de la dernière activité, puis SalesforceSOQL s'exécutant sur la base d'informations précises et à jour concernant le schéma.
Le contexte lu par l'agent reflète l'état actuel du système. C'est ce qui rend les déploiements en production sur plateforme SnapLogic plateforme différents : les informations dont dispose l'agent sur les systèmes connectés restent à jour automatiquement, sans qu'il soit nécessaire qu'un utilisateur mette à jour la documentation chaque fois qu'un administrateur Salesforce ajoute un champ.
À quoi cela ressemble-t-il dans la pratique ?
Les environnements de données d'entreprise peuvent être complexes. Les systèmes évoluent, les connecteurs se multiplient et les organisations se développent à un rythme qui dépasse celui de la mise à jour de la documentation. La bibliothèque Context est conçue pour gérer cette complexité sans nécessiter d'intervention humaine à chaque changement. Voici comment elle s'applique aux scénarios les plus courants auxquels sont confrontées les équipes chargées des données et de l'informatique :
- Évolution du schéma : lorsque votre administrateur Salesforce renomme ou restructure des champs, la prochaine opération de découverte met automatiquement à jour la bibliothèque. L'agent interroge la configuration actuelle, et non un instantané obsolète.
- Multiplication des connecteurs : lorsque Salesforce est déployé dans plusieurs périmètres de connecteurs (ventes, système central, partenaires), chacun dispose de son propre contexte de découverte. L'agent sait exactement où se trouve chaque objet, sans avoir à deviner.
- Environnements multi-organisations : les entrées de contexte distinctes pour chaque organisation comprennent le nombre d'enregistrements et des indicateurs d'activité, ce qui permet à l'agent de distinguer les systèmes de production actifs de ceux hérités qui sont inactifs.
- Traçabilité : chaque lecture de contexte est consignée, ce qui permet aux équipes chargées de la conformité de savoir précisément quelles informations ont guidé chaque action des agents.
Le fil conducteur qui relie tous ces éléments est un principe architectural simple : les agents IA fonctionnent en fonction de la qualité des informations qui leur sont fournies. Structurez correctement ces informations, veillez à ce qu’elles soient à jour, et le modèle disposera de tout ce dont il a besoin pour être véritablement utile.
La bibliothèque Context est désormais disponible dans Jean-Paul ; elle est déployée en production sur plateforme SnapLogic et couvre Salesforce, BigQuery, Zendesk, les comptes-rendus de réunion, les politiques RH, ainsi qu'une liste croissante de systèmes connectés.
Demandez un accès anticipé à Jean-Paul
Jean-Paul, l'agent IA d'entreprise de SnapLogic, est désormais accessible à certains clients dans le cadre d'un accès anticipé. Si votre entreprise est prête à passer de la phase de démonstration à un déploiement en production, nous serions ravis de vous rencontrer.