






Pubblicato originariamente su medium.com.
Questo post intende fornire una panoramica su come una piattaforma di integrazione come servizio (iPaaS) possa essere utilizzata in un'azienda per eliminare i silos di dati. È destinato a un pubblico di integratori di dati e architetti di dati. Le piattaforme di integrazione forniscono due serie principali di funzionalità:
- Integrazione dei dati: Elaborazione in batch dei dati. La piattaforma di integrazione fornisce il supporto per l'elaborazione dei dati da vari sistemi di archiviazione e formati di file e supporta lo sviluppo visivo di funzionalità di trasformazione dei dati.
- Integrazione delle applicazioni: Sincronizzazione dei dati tra le applicazioni. La piattaforma di integrazione fornisce connettori per leggere e scrivere dati da vari endpoint di applicazioni. Questo, insieme alle trasformazioni supportate nell'ambito dell'integrazione dei dati, consente di spostare i dati da qualsiasi origine a qualsiasi destinazione, eseguendo le trasformazioni necessarie.
Layout aziendale tipico
Una tipica azienda esegue più applicazioni, alcune delle quali in modalità SaaS e altre nei data center del cliente. Questo layout di rete mostra il non facile compito di un integratore di dati che deve combinare dati provenienti da più fonti.
L'azienda mostrata utilizza due data center, uno negli Stati Uniti Est e uno negli Stati Uniti Ovest, ognuno dei quali ospita alcune applicazioni (come SAP/Oracle) e alcuni database. Esiste un account IaaS (AWS/Azure/GCP) che ospita applicazioni personalizzate e un data warehouse. Sono in uso diverse applicazioni SaaS (come Workday/NetSuite ecc.).
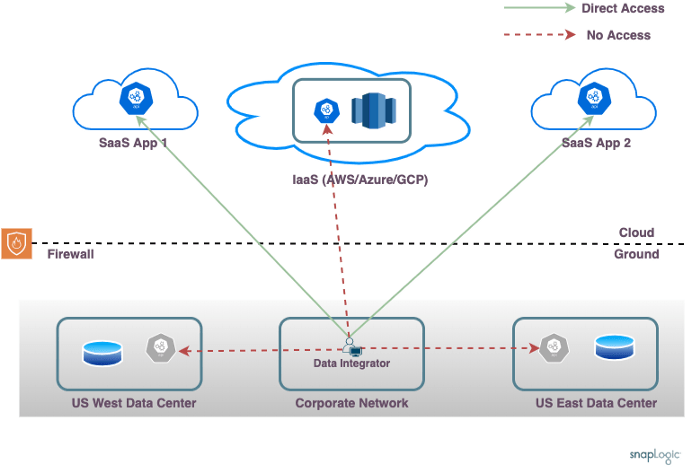
Alcune delle complessità da considerare sono:
- Rete aziendale: L'integratore di dati costruisce le pipeline per orchestrare l'elaborazione dei dati. La rete aziendale da cui avviene la progettazione delle pipeline (o la rete domestica, a seconda dei casi) potrebbe non avere accesso diretto al data center e agli account IaaS di cloud .
- Localizzazione dei dati: Lo sviluppo della pipeline e l'elaborazione effettiva dei dati avvengono su macchine diverse. L'integratore di dati si trova sulla rete aziendale, ma l'elaborazione effettiva dei dati di solito deve avvenire su uno dei nodi dei data center o sull'account IaaS. Ciò è necessario a causa dei requisiti di connettività degli endpoint e per garantire che l'elaborazione dei dati sia consapevole della località dei dati e avvenga più vicino alle fonti dei dati.
- Firewall on-premises: I nodi on-premises sono dietro un firewall. Sebbene sia possibile aprire una regola del firewall per consentire le connessioni in entrata da Internet, questa operazione non è generalmente consigliata e non è consentita dai team operativi delle reti aziendali.
- Reti isolate: I nodi dell'account IaaS non sono solitamente raggiungibili dal data center on-premise e viceversa. È possibile configurare Direct Connect o una configurazione di rete equivalente per consentire l'accesso diretto tra i nodi on-premise e i nodi IaaS, ma un'architettura di rete aziendale che non richieda l'accesso diretto tra i data center come requisito sarebbe più flessibile e affidabile a lungo termine. Inoltre, i vari data center on-premise potrebbero non essere in grado di parlare direttamente tra loro. Le VPN possono consentire l'accesso ad alcuni endpoint, ma di solito non consentono l'accesso a tutti gli endpoint contemporaneamente. Questo è particolarmente vero se si considerano i data center distribuiti in tutto il mondo e i casi in cui ci possono essere endpoint in più regioni IaaS o addirittura più fornitori IaaS.
Gli scenari di alto livello in termini di layout di rete sarebbero:
- Solo SaaS: Le aziende più piccole potrebbero utilizzare esclusivamente applicazioni SaaS, senza applicazioni IaaS. Questo sarebbe insolito per le grandi imprese. Lo spostamento dei dati da Salesforce a un data warehouse Snowflake rientra in questa categoria.
- Cloud Solo: Le aziende più recenti potrebbero utilizzare solo applicazioni SaaS con alcuni account IaaS per applicazioni personalizzate, senza data center in sede. La combinazione dei dati di un database RDS (accessibile solo dall'account AWS del cliente) con i dati di NetSuite e la generazione di un report rientrano in questa categoria.
- Cloud e Ground: La maggior parte delle aziende dispone di una combinazione di applicazioni SaaS, applicazioni su IaaS Cloud e applicazioni terrestri in sede. Le aziende più grandi potrebbero avere più data center, distribuiti geograficamente per il failover e per servire dipendenti e utenti in tutto il mondo. La lettura dei dati da un'istanza SAP on-premises e la loro unione con i dati del magazzino Redshift e la scrittura dei risultati su un database Oracle in un altro data center rientrano in questa categoria.
In termini di requisiti di integrazione, il primo scenario, SaaS Only, sarebbe il più facile da soddisfare. L'elaborazione dei dati per questa categoria può essere eseguita ovunque, perché gli endpoint (applicazione SaaS) sono raggiungibili da qualsiasi luogo.
Lo scenario Cloud Only dipende dal tipo di applicazioni eseguite sull'account IaaS. Se nell'account cloud viene eseguito un data warehouse e il warehouse è aperto alla rete Internet pubblica (protetto da meccanismi di autenticazione piuttosto che a livello di rete), l'elaborazione dei dati può essere eseguita ovunque. Per le applicazioni personalizzate eseguite in cloud che non sono raggiungibili attraverso la rete Internet pubblica, l'elaborazione dei dati deve essere eseguita sulla rete IaaS o su nodi che possono raggiungere la rete IaaS.
Lo scenario Cloud e Ground presenta le maggiori complessità in termini di requisiti di integrazione. Se un caso d'uso richiede la combinazione di dati tra un database in esecuzione negli Stati Uniti occidentali e un'applicazione in esecuzione negli Stati Uniti orientali o su cloud, l'integrazione presenta la sfida che nessun nodo avrà accesso diretto a tutti gli endpoint richiesti.
iPaaS vs. soluzioni di integrazione tradizionali
Le soluzioni di integrazione tradizionali prevedono l'installazione di strumenti di integrazione on-premise che consentono lo sviluppo di pipeline di elaborazione dei dati. Questo comporta tutte le consuete sfide associate alle applicazioni on-premise, come gli elevati costi di manutenzione e aggiornamento. Oltre ai consueti vantaggi del modello SaaS, iPaaS presenta alcuni vantaggi rispetto agli strumenti di integrazione on-premise
- Aggiornamenti regolari: Per una piattaforma di integrazione, anche se non è necessario fornire nuove funzionalità, per garantire l'aggiornamento dei connettori ai vari endpoint e la disponibilità di nuovi connettori è necessario che la piattaforma di integrazione venga aggiornata regolarmente, il che è più facile con il modello iPaaS.
- Facilità d'uso: gli strumenti di integrazione tradizionali richiedono di solito un client di tipo "fat" e potrebbero non essere facilmente disponibili per tutti gli utenti dell'azienda. Il modello iPaaS, con strumenti basati su browser, significa che la funzionalità è disponibile per tutti gli utenti finali ed è di facile utilizzo.
- Modello distribuito: l'approccio iPaaS consente un modello distribuito, rispetto al modello centralizzato utilizzato dagli strumenti di integrazione tradizionali. Ciò consente di gestire facilmente scenari di integrazione distribuita come il modello Cloud e Ground descritto in precedenza.
I vari prodotti iPaaS adottano approcci diversi per risolvere le sfide sopra descritte. Questo schema mostra l'approccio di alto livello adottato da SnapLogic.
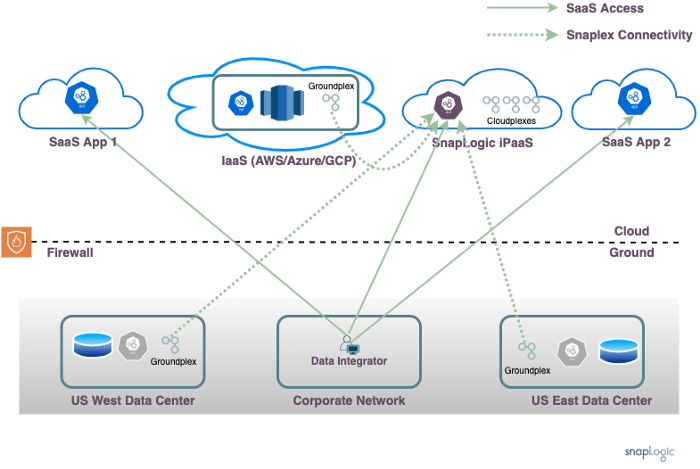
L'approccio di SnapLogic utilizza un servizio iPaaS, in esecuzione nel sito pubblico cloud, come qualsiasi altro servizio SaaS. Tutte le interazioni degli utenti dell'integratore di dati avvengono con questo servizio. L'elaborazione effettiva dei dati avviene su agenti di elaborazione dati dedicati, chiamati Snaplex.
Per lo scenario Solo SaaS, tutta l'elaborazione dei dati può avvenire all'interno di SnapLogic cloud. Per gli scenari di elaborazione dei dati che richiedono l'accesso ai dati sull'IaaS del cliente o in sede, i processi degli agenti Snaplex possono essere installati in sede, come richiesto.
Questo approccio affronta le complessità discusse in precedenza:
- Rete aziendale: L'integratore di dati lavora dalla rete aziendale e interagisce solo con SnapLogic cloud . Il processo di sviluppo delle pipeline consente una facile orchestrazione delle pipeline di dati in esecuzione su qualsiasi data center o account IaaS del cliente.
- Località dei dati: L'elaborazione dei dati avviene sullo Snaplex più vicino all'origine dei dati, consentendo un'elaborazione consapevole della località dei dati.
- Firewall on-premises: Gli Snaplex possono essere eseguiti dietro il firewall del cliente, facendo richieste in uscita a SnapLogic Cloud. Non è necessario aprire regole del firewall in entrata.
- Reti isolate: Il modello distribuito semplifica l'orchestrazione di pipeline in cui i dati vengono letti da una fonte in un data center e combinati con dati provenienti da un'altra sede.
Gli agenti Snaplex installati in sede sono servizi stateless, che si aggiornano automaticamente quando necessario comunicando con SnapLogic cloud. Essendo stateless, l'installazione è semplice e non richiede un database locale: tutto lo stato è mantenuto in SnapLogic cloud. Gli agenti utilizzano connessioni in uscita verso SnapLogic cloud, eliminando la necessità di aprire regole firewall per consentire l'accesso.
L'approccio di SnapLogic consente di disporre di un'unica piattaforma di integrazione a livello aziendale. Ciò consente agli utenti finali di creare facilmente pipeline di dati e di orchestrare il flusso di dati tra endpoint on-premises e cloud , rompendo i silos di dati all'interno dell'azienda.







