






Originally published on medium.com.
This post aims to provide an overview of how an Integration Platform As a Service (iPaaS) can be used in an Enterprise to eliminate data silos. This is intended for an audience of data integrators and data architects. Integration platforms provide two main sets of functionality:
- Data Integration: Batch processing of data. The integration platform provides support for processing data from various storage systems and file formats and supports visual development of data transformation functionality.
- Application Integration: Syncing of data between applications. The integration platform provides connectors to read and write data from various application endpoints. This combined with the transformations supported as part of data integration allows data to be moved from any source to any target, while performing transformations as required.
Typical Enterprise Layout
A typical Enterprise runs multiple applications, some running as SaaS applications and others running in the customer’s own data centers. This network layout shows the unenviable task facing a data integrator having to combine data from multiple sources.
The Enterprise shown uses two data centers, one in US East and another in US West, each hosting some applications (like SAP/Oracle) and some databases. There is an IaaS account (AWS/Azure/GCP) which hosts custom applications and a data warehouse. There are multiple SaaS applications in use (like Workday/NetSuite etc).
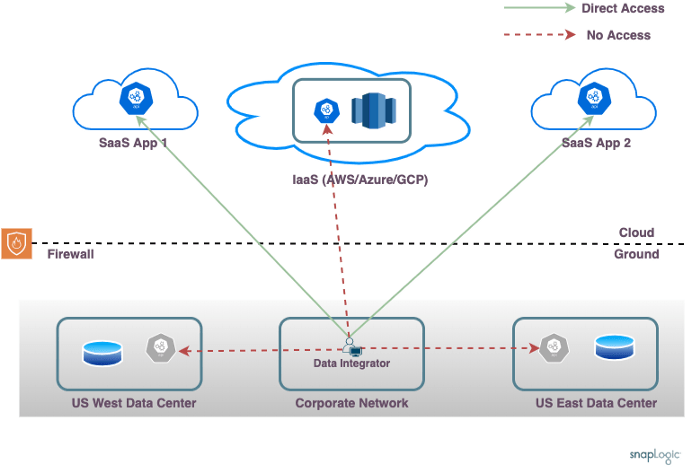
Some of the complexities to consider include:
- Corporate network: The data integrator builds the pipelines to orchestrate the data processing. The corporate network where the pipeline design happens from (or home network as the case might be) might not have direct network access to the data center and cloud IaaS accounts.
- Data Locality: The pipeline development and actual data processing happen on different machines. The data integrator is on the corporate network but the actual data processing usually needs to happen on one of the data centres nodes or on the IaaS account. This would be required because of endpoint connectivity requirements and to ensure that data processing is data locality aware and happens closer to the data sources.
- On-premises Firewall: The on-premises nodes are behind a firewall. While it is possible to open a firewall rule to allow inbound connections from the open internet, this is not usually recommended and is disallowed by Enterprise network operations teams.
- Isolated Networks: Nodes in the IaaS account are not usually reachable from the on-premises data centre and vice-versa. It is possible to setup up Direct Connect or equivalent networking setup to allow direct access between on-premise nodes and IaaS nodes, but an Enterprise network architecture which does not require direct access between data centers as a requirement would be more flexible and reliable in the longer term. Also, the various on-premises data centers might not be able to talk to each other directly. VPN’s might allow access to some of the endpoints but they usually will not allow access to all the endpoints simultaneously. This is especially true when considering data centers distributed across the globe and cases where there might be endpoints in multiple IaaS regions or even multiple IaaS providers.
The high-level scenarios in terms of network layout would be:
- SaaS Only: Smaller companies might be running purely using SaaS applications, with no IaaS applications. This would be unusual for larger enterprises. Moving data from Salesforce to a Snowflake data warehouse would be in this category.
- Cloud Only: Newer companies might be using only SaaS applications with some IaaS accounts for custom applications, with no on-premises data centers. Combining data from an RDS database (accessible from within the customer’s AWS account only) with NetSuite data and generating a report would be in this category.
- Cloud and Ground: Most enterprises have a combination of SaaS applications, applications on IaaS Cloud and on-premises Ground applications. Larger enterprises might have multiple data centers, geographically distributed for failover and for serving employees and users across the world. Reading data from an on-premises SAP instance and joining it with data from Redshift warehouse and writing the results to an Oracle database in another data center would be in this category.
In terms of integration requirements, the first scenario, SaaS Only would be the easiest to satisfy. Data processing for this category can run anywhere, because the endpoints (SaaS application) are reachable from anywhere.
The Cloud Only scenario depends on the kinds of applications being run on the IaaS account. If a data warehouse is run in the cloud account, and the warehouse is open to the public internet (secured using authentication mechanisms rather than at the network level), then the data processing can run anywhere. For custom applications running in the cloud which are not reachable over the public internet. the data processing has to run on the IaaS network or on nodes which can reach the IaaS network.
The Cloud and Ground scenario has the most complexities in terms of integration requirements. If a use case requires data to be combined between a database running in US West with an application running in US East or in the cloud, the integration has the challenge that no node will have direct access to all the required endpoints.
iPaaS vs Traditional Integration Solutions
Traditional integration solutions involve installing on-premises integration tools which allow the development of data processing pipelines. This comes with all the usual challenges associated with on-premises applications, like high overhead for maintenance and upgrades. Beyond the usual advantages of the SaaS model, iPaaS has some advantages over the on-premise integration tools
- Regular Updates: For an integration platform, even if no new functionality needs to be delivered, ensuring that connectors to the various endpoints are kept updated and new connectors are available requires that the integration platform gets regular updates, which is easier with the iPaaS model.
- Ease Of Use: The traditional integration tools usually require a fat client and might not be easily available to all users within the Enterprise. The iPaaS model, with browser-based tools means that the functionality is available to all end-users and is user-friendly.
- Distributed Model: iPaaS approach enables a distributed model, as against the centralized model used by traditional integration tools. This allows for easy handling of distributed integration scenarios like the Cloud and Ground model described above.
Various iPaaS products take different approaches to solve the challenges outlined above. This layout shows the high-level approach adopted by SnapLogic.
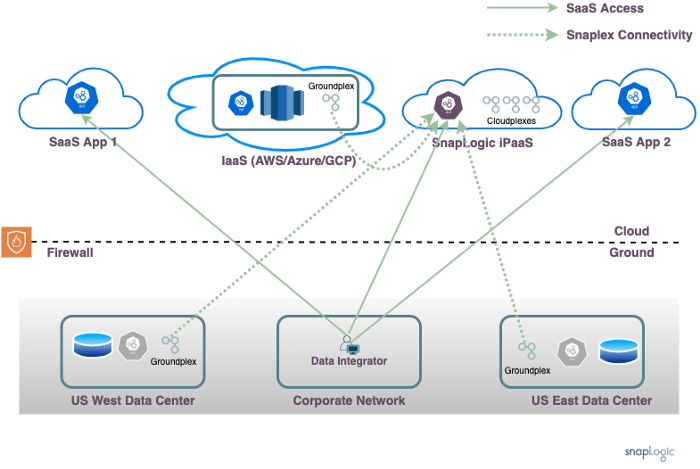
The SnapLogic approach utilizes an iPaaS service, running in the public cloud, like any regular SaaS service. All data integrator user interactions happen against this service. Actual data processing happens on dedicated data processing agents called Snaplexes.
For the SaaS Only scenario, all data processing can happen within the SnapLogic cloud. For the data processing scenarios requiring access to data on the customer IaaS or on-premises, Snaplex agents processes can be installed on-premises as required.
This approach addresses the complexities discussed earlier:
- Corporate network: The data integrator works from the corporate network, interacting with the SnapLogic cloud only. The pipeline development process allows for easy orchestration of data pipelines running on any of the customer data centers or IaaS accounts.
- Data Locality: The data processing happens on the Snaplex closest to the data source, allowing for data locality aware processing.
- On-premises Firewall: The Snaplexes can run behind the customer firewall, making outbound requests to the SnapLogic Cloud. There is no need to open inbound firewall rules.
- Isolated Networks: Orchestrating pipelines, where data is read from a source in one data center and combined with data from another location is made easy through the distributed model.
The Snaplex agents installed on-premises are stateless services, which automatically upgrade themselves as required by communicating with the SnapLogic cloud. Being stateless, the installation is simple, with no local database required, all state is maintained in the SnapLogic cloud. The agents use outbound connections to the SnapLogic cloud, removing the need to open firewall rules to allow access.
The SnapLogic approach enables having a single integration platform Enterprise-wide. This allows end-users to easily build data pipelines and orchestrate data flow across on-premises and cloud endpoints, breaking data silos within the Enterprise.







