






Publié à l‘origine sur medium.com.
Ce billet vise à donner un aperçu de la façon dont une plateforme d‘intégration en tant que service (iPaaS ) peut être utilisée dans une entreprise pour éliminer les silos de données. Il s‘adresse à un public d‘intégrateurs et d‘architectes de données. Les plateformes d‘intégration offrent deux types de fonctionnalités :
- Intégration des données: Traitement des données par lots. Le site d‘intégration plateforme permet de traiter des données provenant de différents systèmes de stockage et formats de fichiers et de développer visuellement des fonctionnalités de transformation des données.
- Intégration des applications: Synchronisation des données entre les applications. L‘intégration plateforme fournit des connecteurs permettant de lire et d‘écrire des données à partir de divers points d‘extrémité d‘application. Ces connecteurs, combinés aux transformations prises en charge dans le cadre de l‘intégration des données, permettent de déplacer les données de n‘importe quelle source vers n‘importe quelle cible, tout en effectuant les transformations nécessaires.
Structure typique d‘une entreprise
Une entreprise typique utilise plusieurs applications, certaines fonctionnant en tant qu‘applications SaaS et d‘autres dans les centres de données du client. Cette configuration de réseau montre la tâche peu enviable à laquelle est confronté un intégrateur de données qui doit combiner des données provenant de sources multiples.
L‘entreprise présentée utilise deux centres de données, l‘un à l‘est des États-Unis et l‘autre à l‘ouest, chacun hébergeant quelques applications (comme SAP/Oracle) et quelques bases de données. Il existe un compte IaaS (AWS/Azure/GCP) qui héberge des applications personnalisées et un entrepôt de données. Plusieurs applications SaaS sont utilisées (comme Workday/NetSuite, etc.).
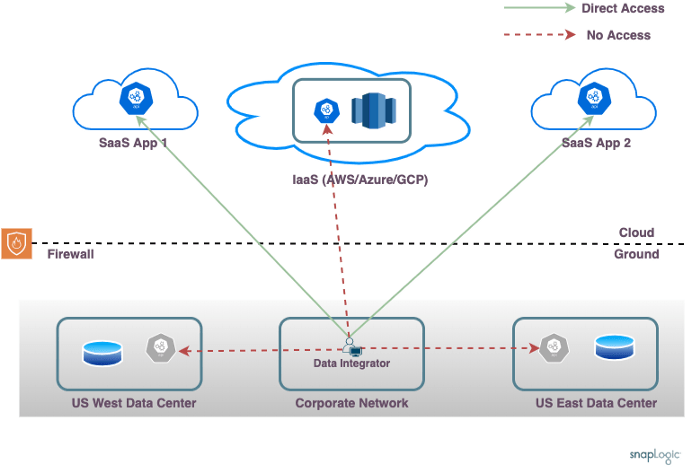
Voici quelques-unes des complexités à prendre en compte :
- Réseau d‘entreprise: L‘intégrateur de données construit les pipelines pour orchestrer le traitement des données. Le réseau de l‘entreprise à partir duquel la conception du pipeline a lieu (ou le réseau domestique, le cas échéant) peut ne pas avoir d‘accès réseau direct au centre de données et aux comptes IaaS de cloud .
- Localité des données: Le développement du pipeline et le traitement réel des données se font sur des machines différentes. L‘intégrateur de données se trouve sur le réseau de l‘entreprise, mais le traitement réel des données doit généralement avoir lieu sur l‘un des nœuds du centre de données ou sur le compte IaaS. Cela est nécessaire en raison des exigences de connectivité des points d‘extrémité et pour s‘assurer que le traitement des données tient compte de la localité des données et se fait plus près des sources de données.
- Pare-feu sur site: Les nœuds sur site se trouvent derrière un pare-feu. Bien qu‘il soit possible d‘ouvrir une règle de pare-feu pour autoriser les connexions entrantes à partir de l‘internet ouvert, cela n‘est généralement pas recommandé et est interdit par les équipes d‘exploitation du réseau de l‘entreprise.
- Réseaux isolés: Les nœuds du compte IaaS ne sont généralement pas accessibles depuis le centre de données sur site et vice-versa. Il est possible de mettre en place Direct Connect ou une configuration réseau équivalente pour permettre un accès direct entre les nœuds sur site et les nœuds IaaS, mais une architecture de réseau d‘entreprise qui n‘exige pas d‘accès direct entre les centres de données serait plus flexible et plus fiable à long terme. En outre, les différents centres de données sur site peuvent ne pas être en mesure de communiquer directement entre eux. Les VPN peuvent permettre l‘accès à certains points d‘extrémité, mais ils ne permettent généralement pas l‘accès à tous les points d‘extrémité simultanément. Cela est particulièrement vrai lorsque l‘on considère les centres de données répartis dans le monde entier et les cas où il peut y avoir des points d‘extrémité dans plusieurs régions IaaS ou même plusieurs fournisseurs IaaS.
Les scénarios de haut niveau en termes de configuration du réseau seraient les suivants :
- SaaS uniquement: Les petites entreprises peuvent n‘utiliser que des applications SaaS, sans applications IaaS. Cette situation est inhabituelle dans les grandes entreprises. Le transfert de données de Salesforce vers un entrepôt de données Snowflake entre dans cette catégorie.
- Cloud Seulement: Les entreprises plus récentes peuvent n‘utiliser que des applications SaaS avec quelques comptes IaaS pour des applications personnalisées, sans centres de données sur site. La combinaison de données provenant d‘une base de données RDS (accessible uniquement à partir du compte AWS du client) avec des données NetSuite et la génération d‘un rapport entreraient dans cette catégorie.
- Cloud et Ground: La plupart des entreprises ont une combinaison d‘applications SaaS, d‘applications sur IaaS Cloud et d‘applications Ground sur site. Les grandes entreprises peuvent avoir plusieurs centres de données, répartis géographiquement pour le basculement et pour servir les employés et les utilisateurs dans le monde entier. La lecture de données à partir d‘une instance SAP sur site, leur fusion avec des données provenant d‘un entrepôt Redshift et l‘écriture des résultats dans une base de données Oracle située dans un autre centre de données entrent dans cette catégorie.
En termes d‘exigences d‘intégration, le premier scénario, SaaS Only, serait le plus facile à satisfaire. Le traitement des données pour cette catégorie peut s‘effectuer n‘importe où, car les points finaux (application SaaS) sont accessibles de n‘importe où.
Le scénario Cloud Only dépend des types d‘applications exécutées sur le compte IaaS. Si un entrepôt de données est exécuté sur le compte cloud et que l‘entrepôt est ouvert à l‘internet public (sécurisé à l‘aide de mécanismes d‘authentification plutôt qu‘au niveau du réseau), le traitement des données peut être exécuté n‘importe où. Pour les applications personnalisées exécutées sur le site cloud qui ne sont pas accessibles via l‘internet public, le traitement des données doit être exécuté sur le réseau IaaS ou sur des nœuds qui peuvent atteindre le réseau IaaS.
Le scénario Cloud et Ground est le plus complexe en termes d‘exigences d‘intégration. Si un cas d‘utilisation exige que des données soient combinées entre une base de données fonctionnant aux États-Unis Ouest et une application fonctionnant aux États-Unis Est ou sur le site cloud, l‘intégration se heurte au fait qu‘aucun nœud n‘aura d‘accès direct à tous les points d‘extrémité requis.
iPaaS vs solutions d‘intégration traditionnelles
Les solutions d‘intégration traditionnelles impliquent l‘installation d‘outils d‘intégration sur site qui permettent le développement de pipelines de traitement des données. Cette solution s‘accompagne de tous les défis habituels associés aux applications sur site, tels que des frais généraux élevés pour la maintenance et les mises à jour. Outre les avantages habituels du modèle SaaS, iPaaS présente certains avantages par rapport aux outils d‘intégration sur site
- Mises à jour régulières: Pour une intégration plateforme, même si aucune nouvelle fonctionnalité ne doit être fournie, s‘assurer que les connecteurs vers les différents points finaux sont mis à jour et que de nouveaux connecteurs sont disponibles nécessite que l‘intégration plateforme soit régulièrement mise à jour, ce qui est plus facile avec le modèle iPaaS.
- Facilité d‘utilisation: les outils d‘intégration traditionnels nécessitent généralement un client lourd et peuvent ne pas être facilement accessibles à tous les utilisateurs au sein de l‘entreprise. Le modèle iPaaS, avec des outils basés sur un navigateur, signifie que la fonctionnalité est disponible pour tous les utilisateurs finaux et qu‘elle est conviviale.
- Modèle distribué: l‘approche iPaaS permet un modèle distribué, contrairement au modèle centralisé utilisé par les outils d‘intégration traditionnels. Cela permet de gérer facilement des scénarios d‘intégration distribuée tels que le modèle Cloud et Ground décrit ci-dessus.
Les différents produits iPaaS adoptent des approches différentes pour résoudre les problèmes décrits ci-dessus. Ce schéma montre l‘approche de haut niveau adoptée par SnapLogic.
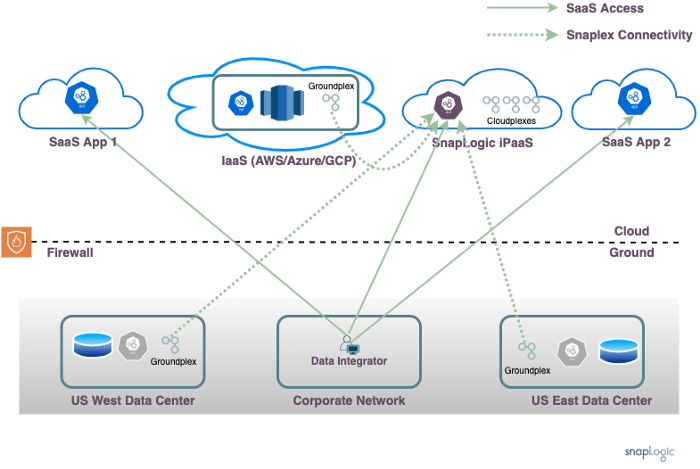
L‘approche SnapLogic utilise un service iPaaS, fonctionnant sur le site public cloud, comme n‘importe quel service SaaS. Toutes les interactions entre l‘utilisateur et l‘intégrateur de données se font par l‘intermédiaire de ce service. Le traitement réel des données s‘effectue sur des agents de traitement des données dédiés, appelés Snaplex.
Pour le scénario SaaS Only, tout le traitement des données peut se faire dans SnapLogic cloud. Pour les scénarios de traitement des données nécessitant un accès aux données sur l‘IaaS du client ou sur site, les processus des agents Snaplex peuvent être installés sur site selon les besoins.
Cette approche permet de résoudre les problèmes complexes évoqués précédemment :
- Réseau d‘entreprise: L‘intégrateur de données travaille à partir du réseau de l‘entreprise, en interagissant uniquement avec SnapLogic cloud . Le processus de développement des pipelines permet d‘orchestrer facilement les pipelines de données fonctionnant sur n‘importe quel centre de données ou compte IaaS du client.
- Localité des données: Le traitement des données s‘effectue sur le Snaplex le plus proche de la source de données, ce qui permet un traitement tenant compte de la localité des données.
- Pare-feu sur site: Les Snaplex peuvent fonctionner derrière le pare-feu du client, en effectuant des requêtes sortantes vers le SnapLogic Cloud. Il n‘est pas nécessaire d‘ouvrir des règles de pare-feu entrantes.
- Réseaux isolés: L‘orchestration de pipelines, où les données sont lues à partir d‘une source dans un centre de données et combinées avec des données provenant d‘un autre site, est facilitée par le modèle distribué.
Les agents Snaplex installés sur place sont des services sans état, qui se mettent automatiquement à jour selon les besoins en communiquant avec SnapLogic cloud. Comme il s‘agit d‘un service sans état, l‘installation est simple, aucune base de données locale n‘est nécessaire, tout l‘état est conservé dans SnapLogic cloud. Les agents utilisent des connexions sortantes vers le SnapLogic cloud, ce qui élimine la nécessité d‘ouvrir des règles de pare-feu pour autoriser l‘accès.
L‘approche SnapLogic permet d‘avoir une intégration unique plateforme à l‘échelle de l‘entreprise. Cela permet aux utilisateurs finaux de créer facilement des pipelines de données et d‘orchestrer le flux de données entre les points d‘extrémité sur site et cloud , brisant ainsi les silos de données au sein de l‘entreprise.







