





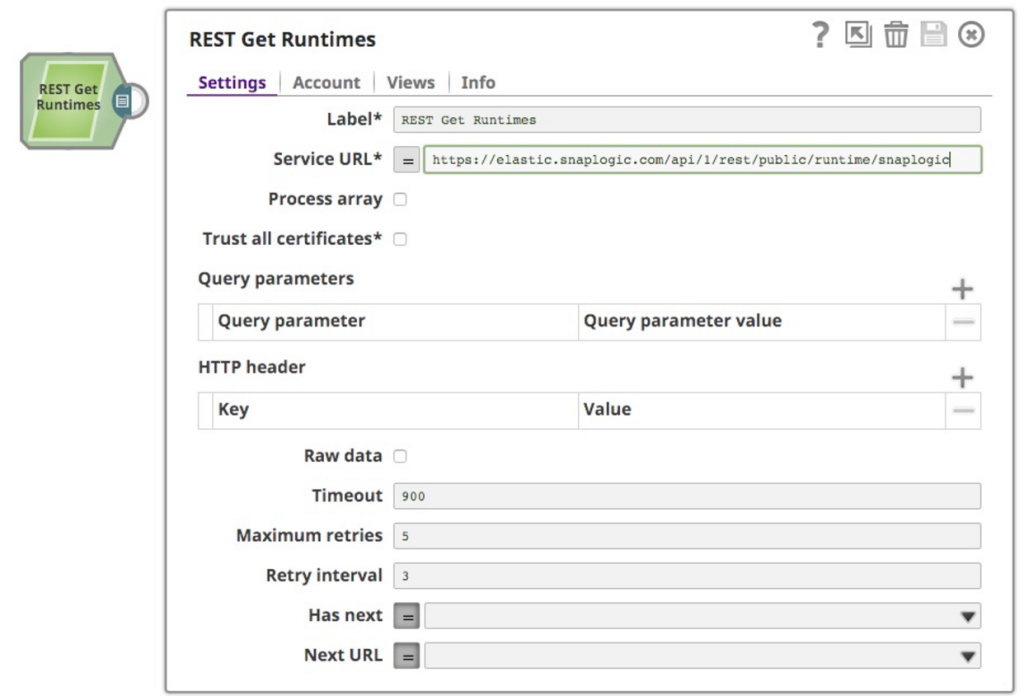
Nell'ambito di un progetto analitico più ampio a cui sto lavorando, che prevede l'analisi delle informazioni di runtime della piattaforma SnapLogic, ho scelto di utilizzare le funzionalità esposte a tutti i clienti, l'API pubblica per l'API di monitoraggio delle pipeline e l'API REST. Questi due elementi sono stati combinati in questo post. Ho iniziato leggendo la documentazione (ovviamente), che mostra il formato della richiesta e della risposta. Ho quindi creato una nuova pipeline e ho inserito un REST GET Snap nel canvas:
Volevo ottenere i dati di runtime dall'organizzazione snaplogic sulla piattaforma SnapLogic, quindi nell'URL ho specificato snaplogic come organizzazione. L'altra cosa da ricordare è che l'API richiede l'autenticazione, quindi ho creato un account basic auth con le mie credenziali. Questo funziona bene e mi restituisce le informazioni che volevo, come segue:
[
{
"headers": {
"x-frame-options": "DENY",
"connection": "keep-alive",
"x-sl-userid": "[email protected]",
"access-control-max-age": "17600",
"content-type": "application/json",
"date": "Sun, 31 Jan 2016 01: 29: 59 GMT",
"access-control-allow-credentials": "true",
"access-control-allow-methods": "GET, POST, OPTIONS, PUT, DELETE",
"x-sl-statuscode": "200",
"content-length": "5175",
"content-security-policy": "frame-ancestors 'none'",
"access-control-allow-origin": "*",
"server": "nginx/1.6.2",
"access-control-allow-headers": "authorization, x-date, content-type, if-none-match"
},
"statusLine": {
"reasonPhrase": "OK",
"statusCode": 200,
"protoVersion": "HTTP/1.1"
},
"entity": {
"response_map": {
"entries": [
{
"pipe_id": "1b10f684-24c0-4002-abd3-09b2e87e975f",
"ccid": "56ab61ed63766e7406c491ba",
"runtime_path_id": "snaplogic/rt/cloud/dev",
"subpipes": { },
"state_timestamp": "2016-01-31T01: 29: 43.758000+00: 00",
"parent_ruuid": null,
"create_time": "2016-01-31T01: 29: 43.484000+00: 00",
"id": "0aa7943d-d6c3-408c-9490-1d2b6b281227",
"runtime_label": "cloud-dev",
"cc_label": "prodxl-jcc1",
"documents": 9,
"user_id": "[email protected]",
"label": "REPORT - NGM FSM Ultra Task Failure Audit",
"state": "Completed",
"invoker": "scheduled"
},
...another 9 of these...
],
"total": 154,
"limit": 10,
"offset": 0
},
"http_status_code": 200
}
}
]Si noti la piccola sezione alla fine, con il totale, il limite e l'offset, che indica che ho recuperato solo i primi 10 runtime disponibili. Il recupero di più runtime richiede la funzione di "paginazione" che è stata aggiunta allo Snap REST GET l'anno scorso (la documentazione illustra in dettaglio gli esempi di utilizzo della paginazione con Eloqua, Marketo e HubSpot). I due campi dell'infobox per lo snap sono "Has Next", un booleano che indica se c'è un'ulteriore iterazione da fare, e "Next URL", entrambi espressioni, quindi la condizione può essere dinamica.
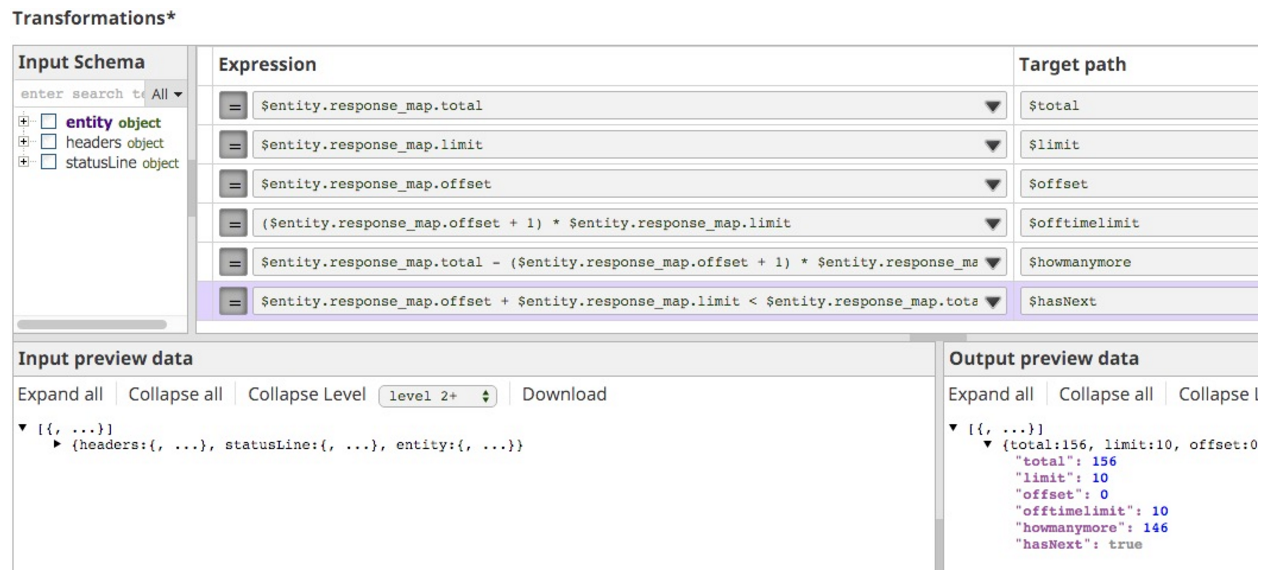
Nel caso della mia API runtime SnapLogic, dovevo capire da questi tre campi (total, limit, offset) come indicare se e quale sarebbe stato l'URL successivo. Quindi, per elaborare la mia logica, ho inserito un mapper Snap next nella pipeline, in modo da poter iterare fino a ottenere le espressioni giuste.
Per dare un'idea del modo in cui ho risolto il problema, ecco lo stato del mio mapper:
L'elemento importante qui è l'espressione che ho usato per indicare se c'è altro da recuperare, hasNext:
$entity.response_map.offset + $entity.response_map.limit < $entity.response_map.total
Ora posso applicarlo allo snap REST GET, ma prima devo capire come creare l'URL Next. L'URL Next sarà lo stesso dell'URL Service, ma aggiungendo semplicemente "?offset=n", dove n è il numero che ho già recuperato, meno uno, dato che iniziamo sempre il conteggio in vero stile CS, con 0! Quindi il mio URL sarà l'espressione
'https://elastic.snaplogic.com/api/1/rest/public/runtime/snaplogic?offset=' + ($entity.response_map.offset+$entity.response_map.limit)
È necessario assicurarsi che entrambi i campi siano impostati in modalità espressione.
Questo può essere testato per assicurarsi che venga recuperato l'intero set di dati. Quando salvo questa volta, l'anteprima della GET REST è la seguente:
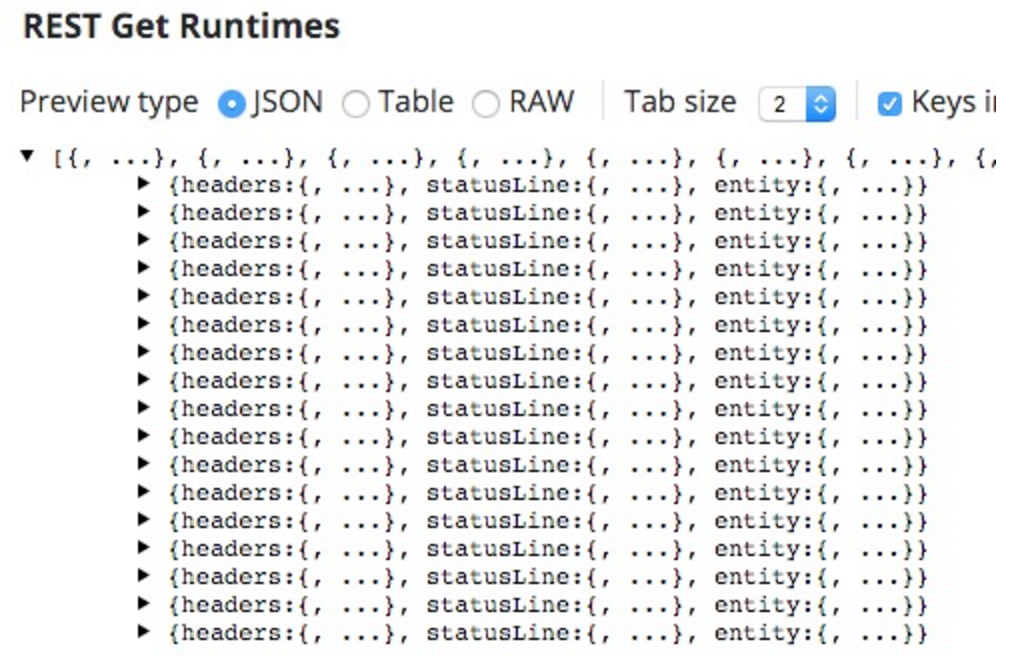
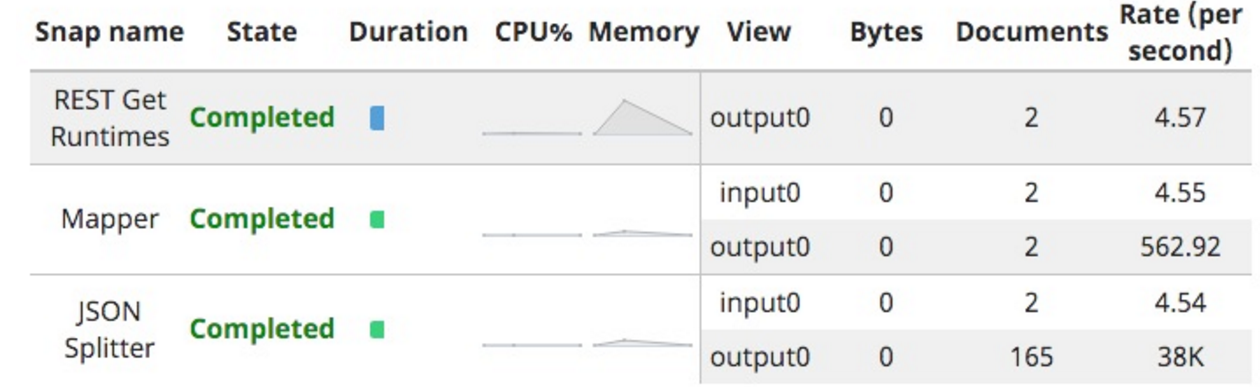
Quando l'ho eseguito, il conteggio dei tempi di esecuzione era il seguente:

Da qui le diciassette iterazioni.

Qui sta un altro problema: vengono fuori diciassette documenti, uno per ogni set di iterazioni, ma con un massimo di 10 (la dimensione limite predefinita) runtime per iterazione.
Questo mi spinge a inserire un JSON Splitter Snap per espanderlo:
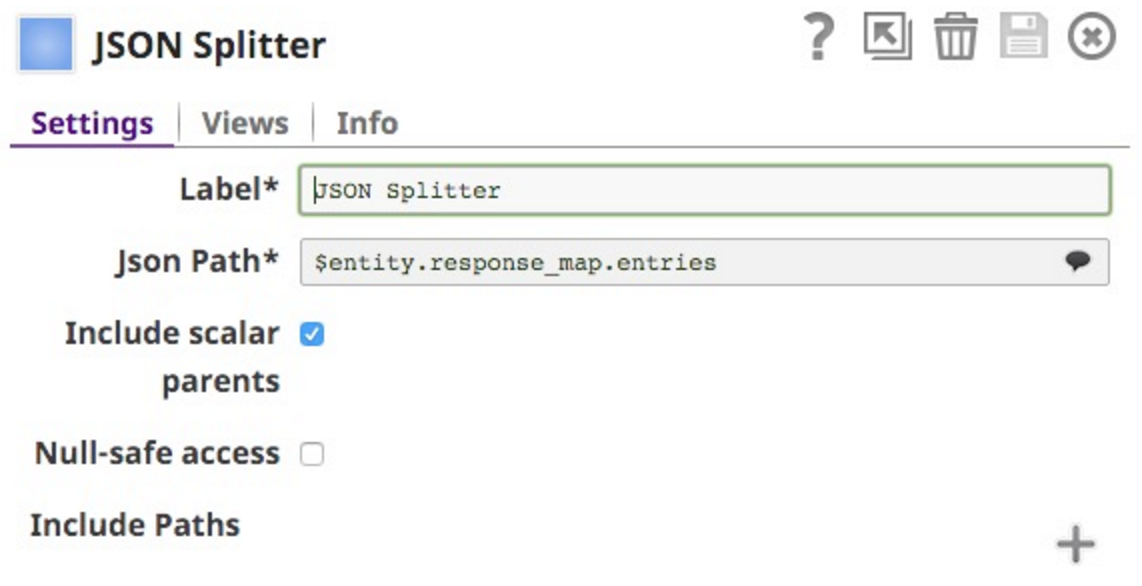
Si noti che ho selezionato $entity.response_mpa.entries come percorso JSON da dividere. Questo è selezionabile dal menu a tendina (si noti che ho tagliato la parte inferiore dell'elenco, ma continua per tutte le chiavi del documento:
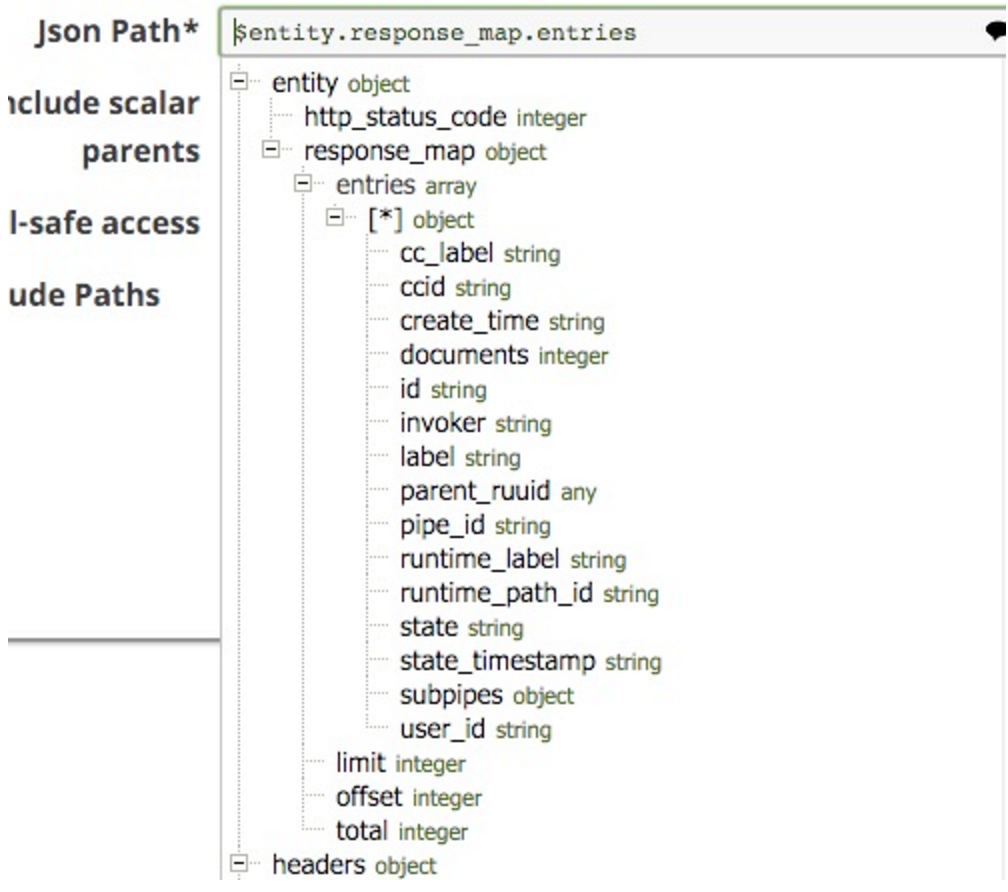
Ho incluso anche lo Scalar Parent, in modo che ogni documento includa i genitori diretti:
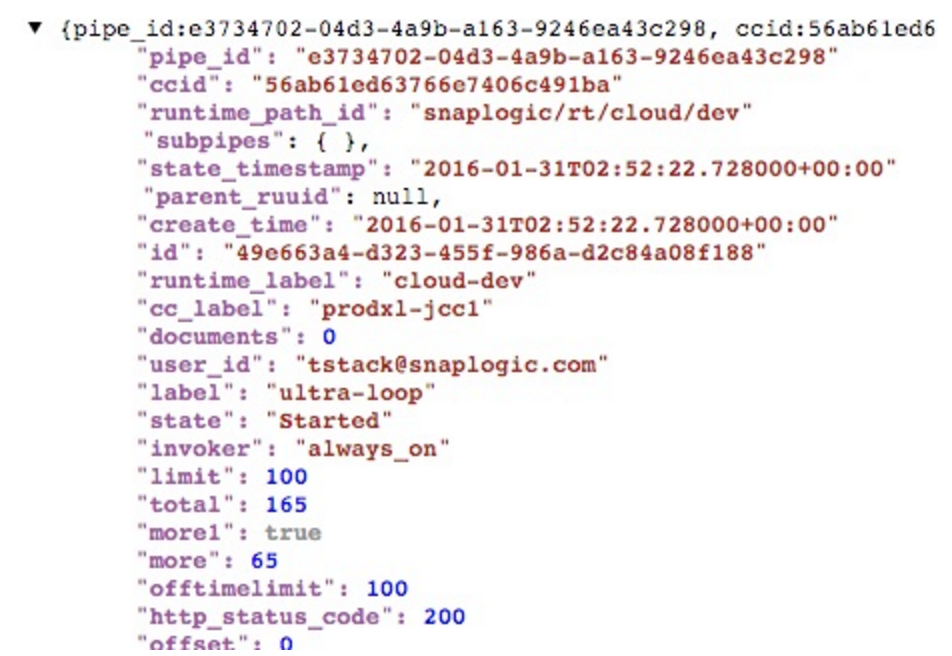
Ora, quando eseguo, otterrò il numero completo di runtime della pipeline, ciascuno come documento separato:
Nota: si può notare che il numero di tempi di esecuzione nella richiesta varia nel corso di questo articolo; ciò è dovuto alla disponibilità di una serie diversa di dati nel periodo di tempo che ho impiegato per scriverlo. È possibile utilizzare le opzioni dell'API per specificare il periodo della richiesta.
Prossimi passi:
- Date un'occhiata ai post simili del mio collega Robin Howlett
- Consultate i post di Greg Benson sull'architettura di SnapLogic Elastic Integration Platform.
- Guardate i nostri video per vedere SnapLogic in azione o richiedete una demo personalizzata.






{kind=link}