





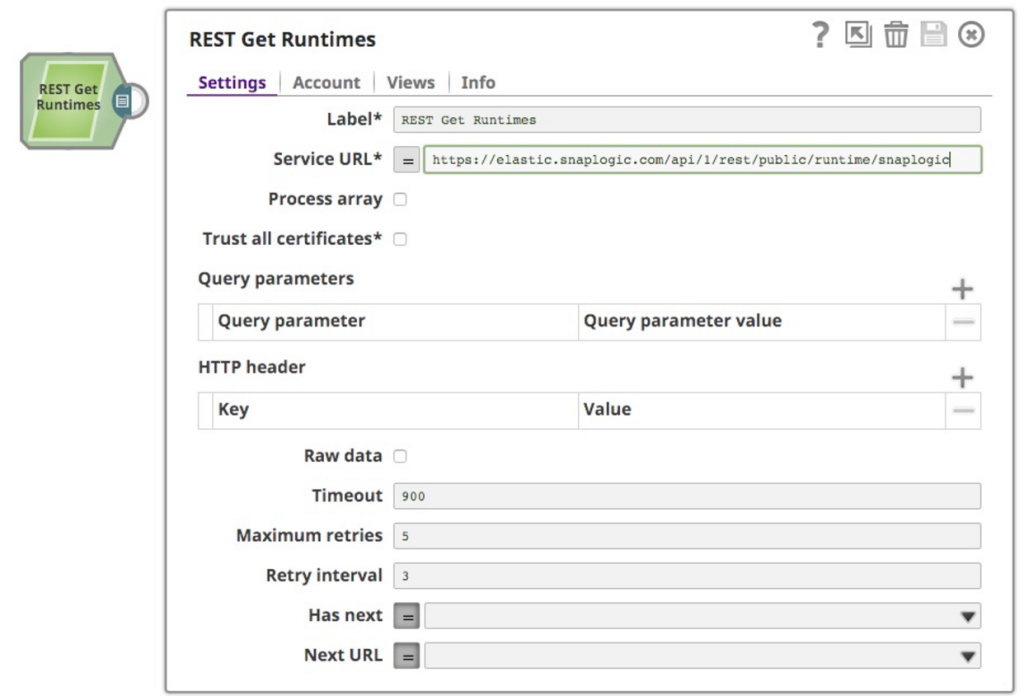
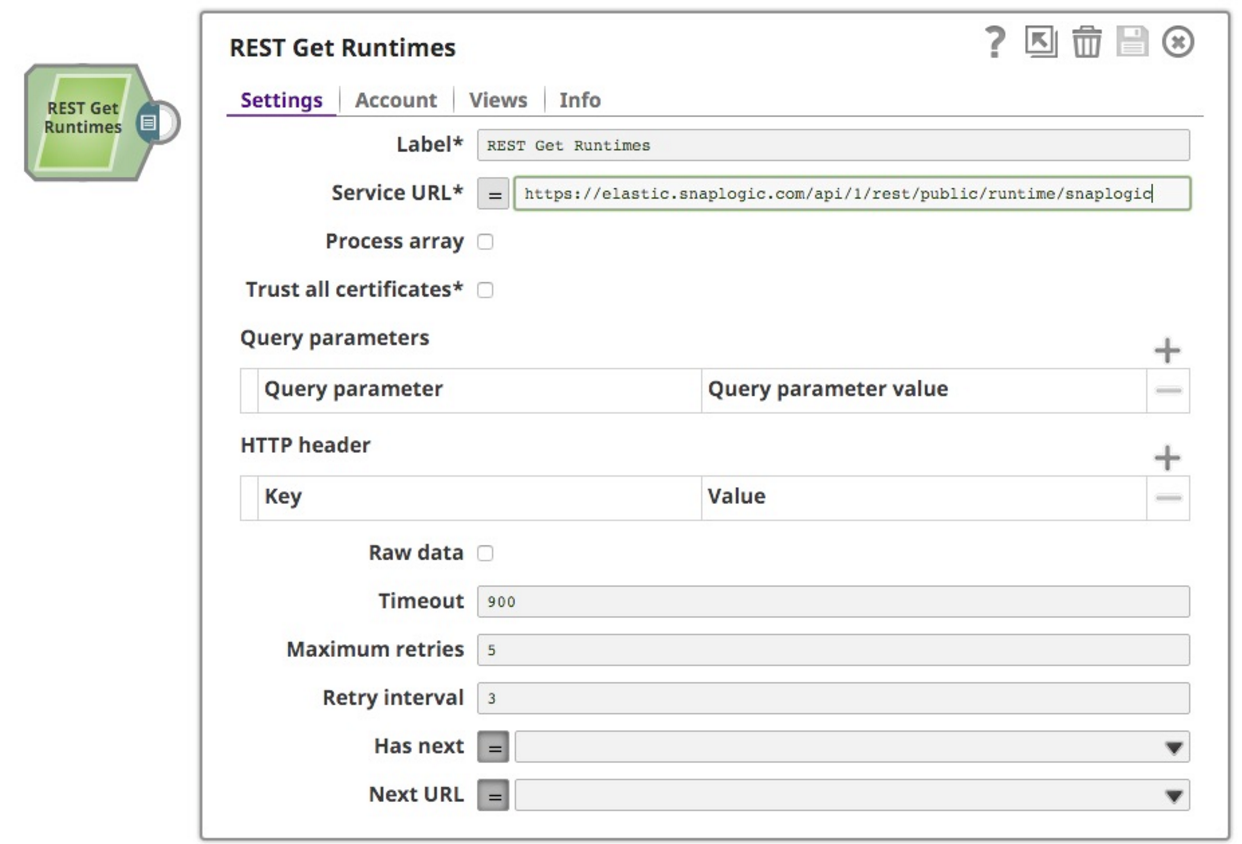
As a part of a wider analytics project I’m working on, analyzing runtime information from the SnapLogic platform, I chose to use the functionality exposed to all customers, the Public API for Pipeline Monitoring API and the REST API. These two things are combined in this post. I started by reading the documentation (of course), which shows the format of the request and response. So I created a new pipeline and dropped a REST GET Snap on the canvas:
I wanted to get the runtime data out of the snaplogic org on the SnapLogic platform so in the URL I specified snaplogic as the org. The other thing to remember is that the API will require authentication, so I created an basic auth account with my credentials. This works well, and retrieves me the info I wanted, as follows:
[
{
"headers": {
"x-frame-options": "DENY",
"connection": "keep-alive",
"x-sl-userid": "[email protected]",
"access-control-max-age": "17600",
"content-type": "application/json",
"date": "Sun, 31 Jan 2016 01: 29: 59 GMT",
"access-control-allow-credentials": "true",
"access-control-allow-methods": "GET, POST, OPTIONS, PUT, DELETE",
"x-sl-statuscode": "200",
"content-length": "5175",
"content-security-policy": "frame-ancestors 'none'",
"access-control-allow-origin": "*",
"server": "nginx/1.6.2",
"access-control-allow-headers": "authorization, x-date, content-type, if-none-match"
},
"statusLine": {
"reasonPhrase": "OK",
"statusCode": 200,
"protoVersion": "HTTP/1.1"
},
"entity": {
"response_map": {
"entries": [
{
"pipe_id": "1b10f684-24c0-4002-abd3-09b2e87e975f",
"ccid": "56ab61ed63766e7406c491ba",
"runtime_path_id": "snaplogic/rt/cloud/dev",
"subpipes": { },
"state_timestamp": "2016-01-31T01: 29: 43.758000+00: 00",
"parent_ruuid": null,
"create_time": "2016-01-31T01: 29: 43.484000+00: 00",
"id": "0aa7943d-d6c3-408c-9490-1d2b6b281227",
"runtime_label": "cloud-dev",
"cc_label": "prodxl-jcc1",
"documents": 9,
"user_id": "[email protected]",
"label": "REPORT - NGM FSM Ultra Task Failure Audit",
"state": "Completed",
"invoker": "scheduled"
},
...another 9 of these...
],
"total": 154,
"limit": 10,
"offset": 0
},
"http_status_code": 200
}
}
]Note that small section at the end, with the total, limit and offset, indicating that I had only retrieved the first 10 runtimes available. Retrieving more runtimes calls for the “pagination” feature that was added to the REST GET Snap last year (the documentation details examples on how to use the pagination with Eloqua, Marketo and HubSpot). The two fields in the infobox for the Snap are “Has Next”, a boolean which indicates if there is further iteration to be done, and “Next URL”, both of which are expressions, so the condition can be dynamic.
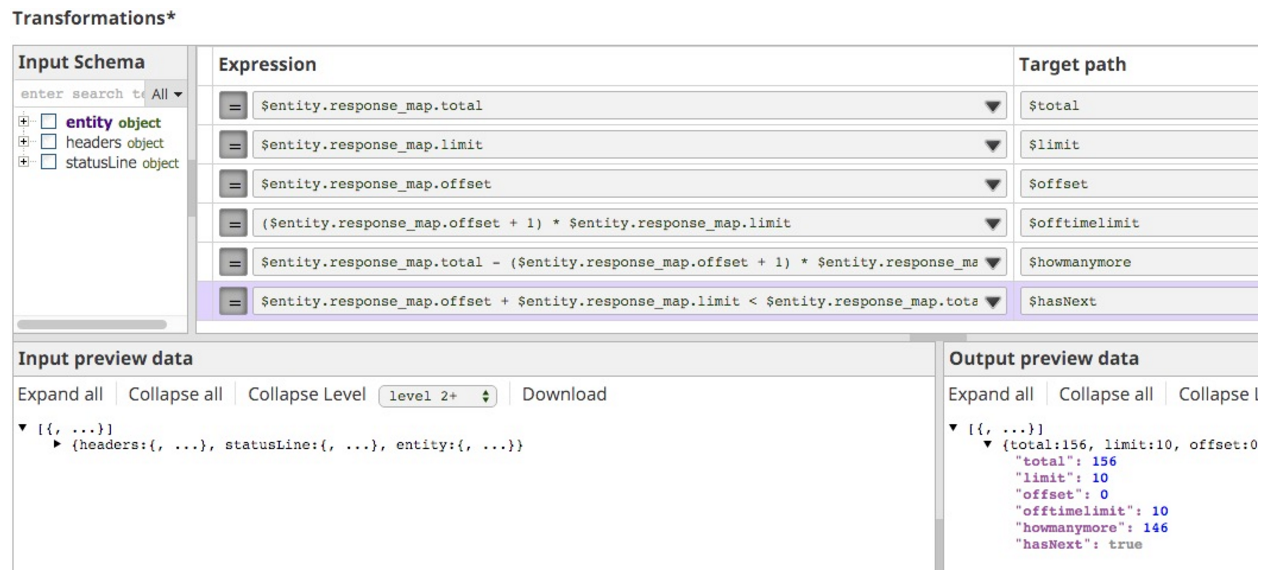
In the case of my SnapLogic runtime API, I had to figure out from those three fields (total, limit, offset) how to indicate if, and what the next URL was going to be. So, in order to work out my logic, I actually put a Mapper Snap next in the pipeline so I could iterate until I had the right expressions.
To give you an idea of the way I went about working it out, here is the state of my Mapper:
The important one in here is the expression I used to indicate if there is more to fetch, hasNext:
$entity.response_map.offset + $entity.response_map.limit < $entity.response_map.total
This I can now apply to the REST GET Snap, but first I should work out how to create the Next URL. The Next URL will be the same as the Service URL, but simply appending “?offset=n”, where n is the number I have already fetched, minus one, as we always start counting in true CS style, with 0! So my URL ends up being the expression:
‘https://elastic.snaplogic.com/api/1/rest/public/runtime/snaplogic?offset=’ + ($entity.response_map.offset+$entity.response_map.limit)
You do have to ensure that you set both fields toggled to expression mode.
This we can test to ensure the full data set is retrieved. When I save this time, the preview on the REST GET is as follows:
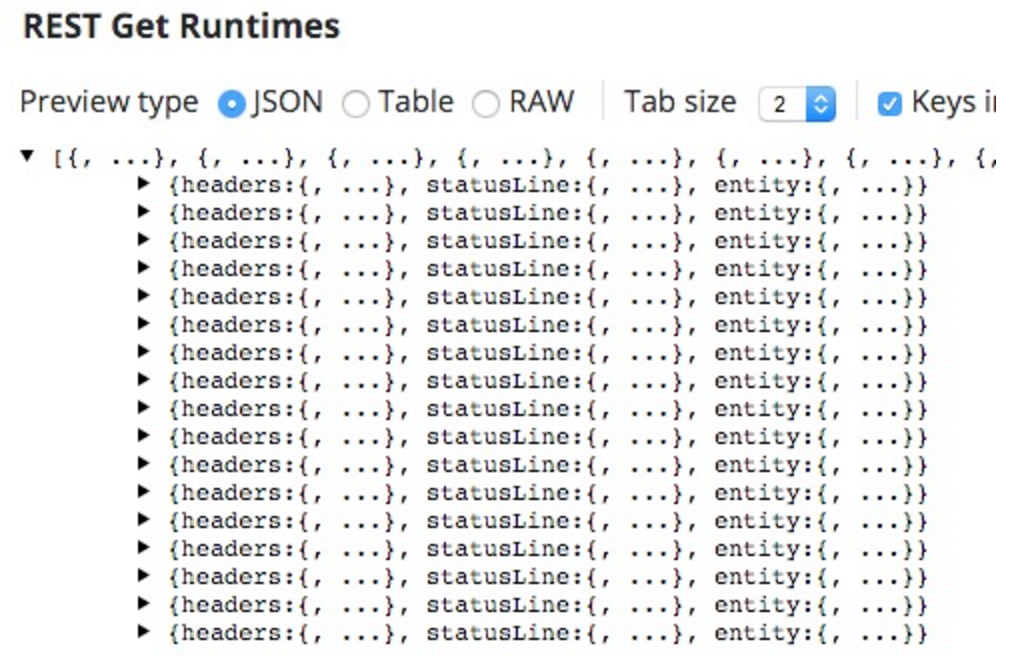
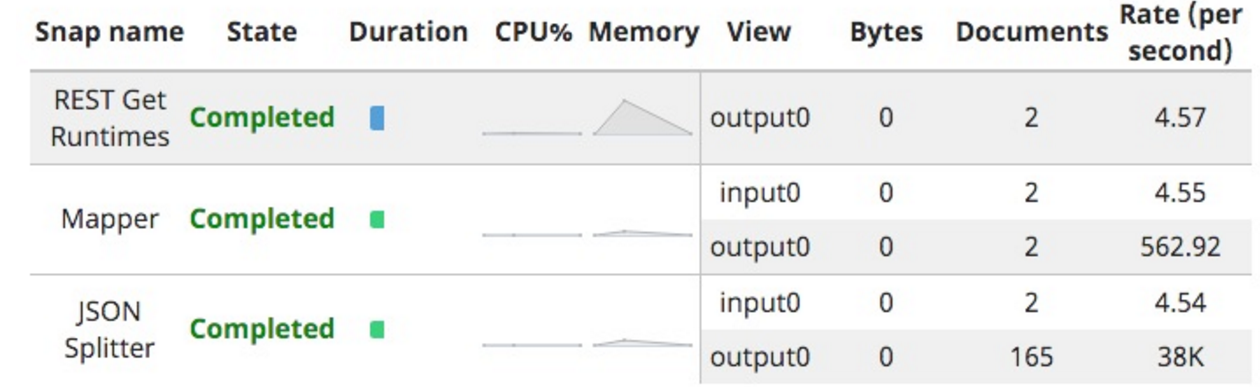
The time I ran this, the count of runtimes was as follows:

Hence the seventeen iterations.

Therein lies another issue; it comes out as seventeen documents, one for each iteration set, but with up to 10 (the default limit size) runtimes per iteration.
This causes me to put a JSON Splitter Snap to expand it out:
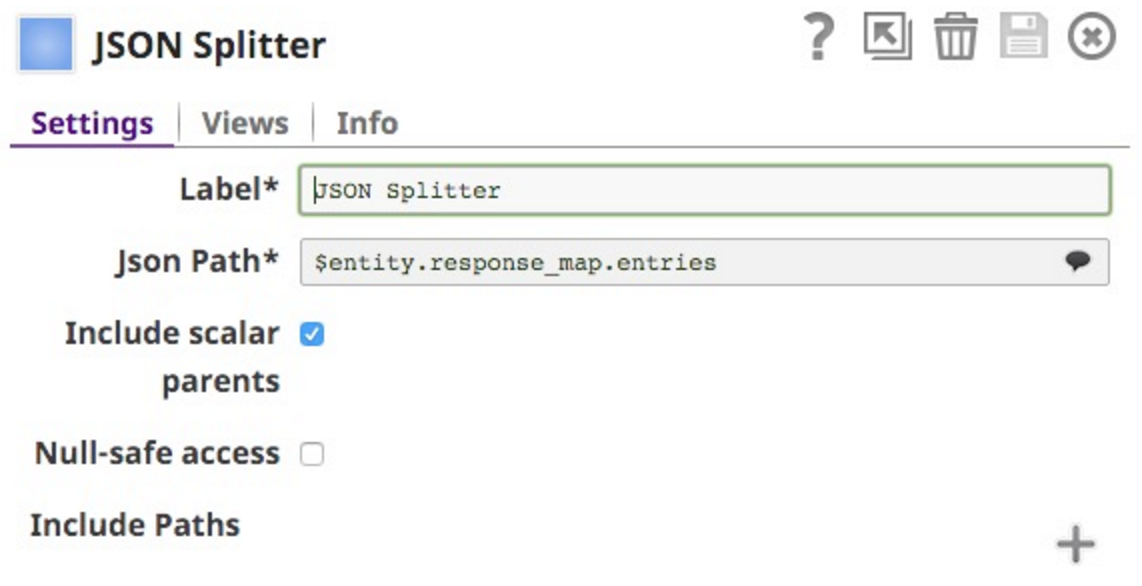
Note that I selected the $entity.response_mpa.entries as the JSONPath to split on. This is selectable from that drop-down (note that I cut off the bottom of the list, it does go on for all the keys in the document:
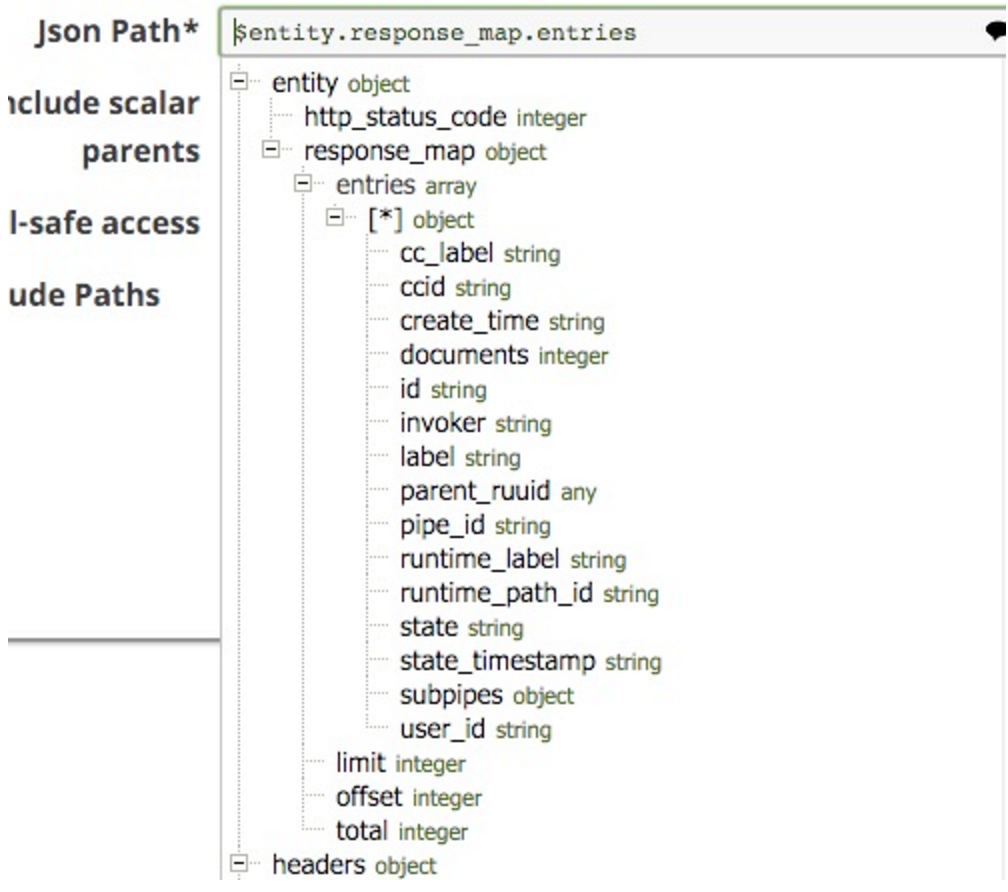
I also included the Scalar Parent, so that each document includes the direct parents:
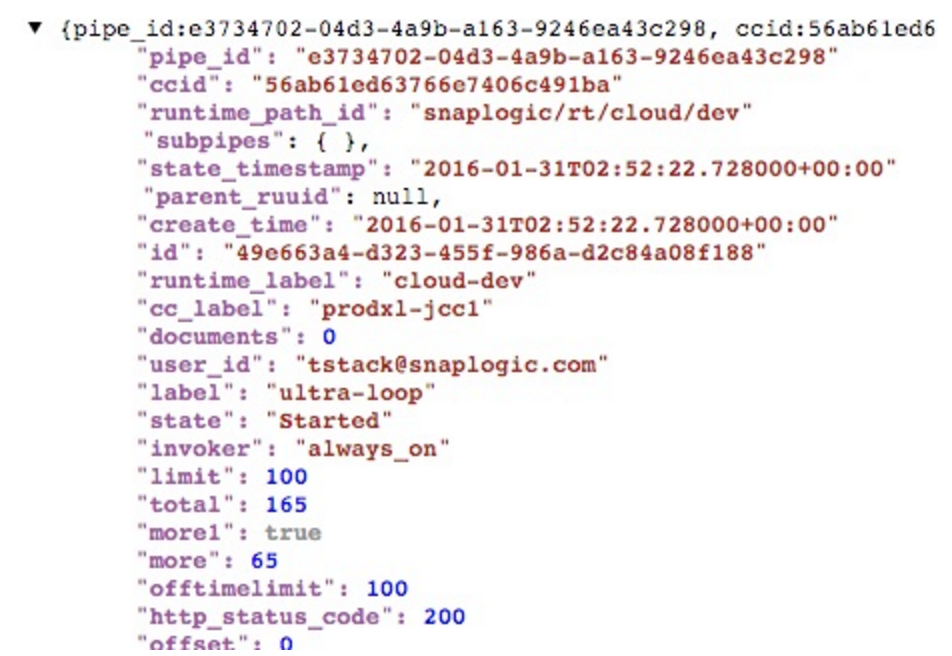
Now when I run, I will get the full number of pipeline runtimes each as separate documents:
Note: You may note that the number of runtimes in the request varies over this article, this is due to a different set of data being available over the time it took me to write it. You could be specific with the options on the API to be specific on the period of the request.
Next Steps:
- Check out similar posts from my colleague Robin Howlett
- Check out Greg Benson’s posts about the SnapLogic Elastic Integration Platform architecture
- Check out our videos to see SnapLogic in action or request a custom demo






{kind=link}