






Dieser Leitfaden enthält eine Schritt-für-Schritt-Anleitung zur Verwendung von SnapLogic zum Extrahieren von Daten aus Formaten wie PDF, CSV, JSON und HTML. Unabhängig davon, ob Sie SnapLogic zum ersten Mal verwenden oder Ihre Datenextraktionsprozesse optimieren möchten, hilft Ihnen dieser Leitfaden beim Erstellen und Verwalten effektiver Pipelines.
Datenformate in SnapLogic
SnapLogic kann Daten aus einer Vielzahl von Quellen lesen und diese Daten in zwei Hauptformate konvertieren:
- Dokumentformat:
- Ein Dokument in SnapLogic ist ein JSON-ähnliches Format, das für die interne Datenverarbeitung verwendet wird. Dieses Format ermöglicht es Benutzern, mit Datenattributen auf ähnliche Weise wie bei JSON zu interagieren. Es unterstützt auch die internen Funktionen von SnapLogic, wie z. B. die Textverarbeitung, sodass Benutzer Ausdrücke für die Datenmanipulation und -transformation anwenden können. Diese Transformationen können durchgeführt werden, bevor die Daten an nachgelagerte Konnektoren gesendet werden, um sicherzustellen, dass die Daten für die nachfolgende Verarbeitung angemessen strukturiert und formatiert sind.
- Binärformat:
- Das Binärformat in SnapLogic wird zur Verarbeitung von Rohdatenströmen wie Bildern, PDFs oder anderen Dateitypen verwendet, die nicht den strukturierten Datenformaten entsprechen. Dieses Format ist besonders nützlich, wenn es sich um Nicht-Textdaten handelt oder wenn die Daten ohne Änderungen durch die Pipeline geleitet werden müssen. SnapLogic kann Binärdaten bei Bedarf in andere Formate konvertieren, sodass sie vor der Übertragung an nachgelagerte Komponenten verarbeitet, gespeichert oder transformiert werden können. Dies gewährleistet Flexibilität und Effizienz bei der Verarbeitung verschiedener Datentypen innerhalb der Pipeline.
Extrahieren von Daten aus Dateien in SnapLogic
SnapLogic bietet leistungsstarke Funktionen für die Extraktion von Daten aus verschiedenen Dateitypen und ist damit ein vielseitiges Tool für Datenintegrations-Workflows. Um diesen Prozess zu vereinfachen, stellt SnapLogic das SnapLogic File System (SLFS) zur Verfügung, eine integrierte Speicherlösung, mit der Benutzer Dateien direkt in der SnapLogic-Umgebung hochladen und verwalten können. Bei der Verwendung von SLFS für die Datenextraktion sind jedoch wichtige Überlegungen und Best Practices zu beachten.
Verwendung des SnapLogic-Dateisystems (SLFS)
Das SnapLogic-Dateisystem (SLFS) ermöglicht es Benutzern, Dateien zur Verarbeitung innerhalb ihrer Pipelines zu speichern und darauf zuzugreifen. Um Daten aus einer Datei mit SnapLogic zu extrahieren, müssen Benutzer die Datei zunächst in SLFS hochladen. Nach dem Hochladen kann die Datei von verschiedenen Snaps, die zum Lesen und Bearbeiten von Dateiinhalten entwickelt wurden, aufgerufen und verarbeitet werden.
SLFS hat jedoch eine Dateigrößenbeschränkung, sodass Benutzer Dateien mit einer maximalen Größe von 100 MB pro Datei hochladen können. Diese Beschränkung kann bei der Verarbeitung größerer Datensätze oder Dateien zu Problemen führen. Wenn die Datei diese Größenbeschränkung überschreitet, müssen Benutzer den Inhalt in mehrere kleinere Dateien aufteilen, bevor sie diese auf SLFS hochladen können. Dieser Ansatz mag zwar für kleinere oder segmentierte Daten funktionieren, wird jedoch im Allgemeinen nicht für die Verarbeitung großer Datenmengen empfohlen.
Bewährte Verfahren für den Umgang mit großen Dateien
Für die Verarbeitung von Dateien, die größer als 100 MB sind, empfiehlt es sich, externe Speichersysteme zu nutzen, anstatt sich auf SLFS zu verlassen. Externe Dateisysteme bieten mehr Flexibilität und Skalierbarkeit, sodass Sie deutlich größere Dateien verarbeiten können, ohne diese manuell segmentieren zu müssen. SnapLogic lässt sich nahtlos in verschiedene externe Speicherlösungen integrieren und ermöglicht so eine effiziente Datenextraktion und -verarbeitung.
- SFTP-Server: Benutzer können Secure File Transfer Protocol (SFTP)-Server zum Speichern und Abrufen großer Dateien verwenden. SnapLogic unterstützt die SFTP-Integration, sodass Sie Dateien direkt vom Server innerhalb Ihrer Pipelines sicher lesen und verarbeiten können.
- Objektspeicherdienste (z. B. Amazon S3): Cloud-basierte Objektspeicherdienste wie Amazon S3 bieten praktisch unbegrenzte Speicherkapazität und eignen sich daher ideal für die Verwaltung großer Datensätze. Dank der nativen Unterstützung von S3 durch SnapLogic können Benutzer in S3-Buckets gespeicherte Dateien lesen, schreiben und verwalten, wodurch eine reibungslose Datenverarbeitung ohne die Einschränkungen von SLFS gewährleistet ist.
Durch die Integration von SnapLogic in diese externen Speicherlösungen können Benutzer große Dateien effizient verwalten, Daten-Extraktions-Workflows optimieren und eine optimale Leistung über ihre gesamten Pipelines hinweg aufrechterhalten. Dieser Ansatz überwindet nicht nur die Einschränkungen von SLFS, sondern entspricht auch den Best Practices für eine skalierbare und zuverlässige Datenverarbeitung.
Lesen von Dateidaten und Verarbeiten in SnapLogic
In diesem Abschnitt befassen wir uns mit dem Lesen von Daten aus verschiedenen Dateiformaten mit SnapLogic. Dieser Leitfaden beschreibt die wichtigsten Schritte, Konfigurationsoptionen und bewährten Verfahren für eine effiziente und effektive Datenextraktion. Um Daten aus einer Datei mit SnapLogic zu lesen, können Sie die folgenden zwei wesentlichen Schritte ausführen:
1. Konfigurieren des Dateilesers Snap
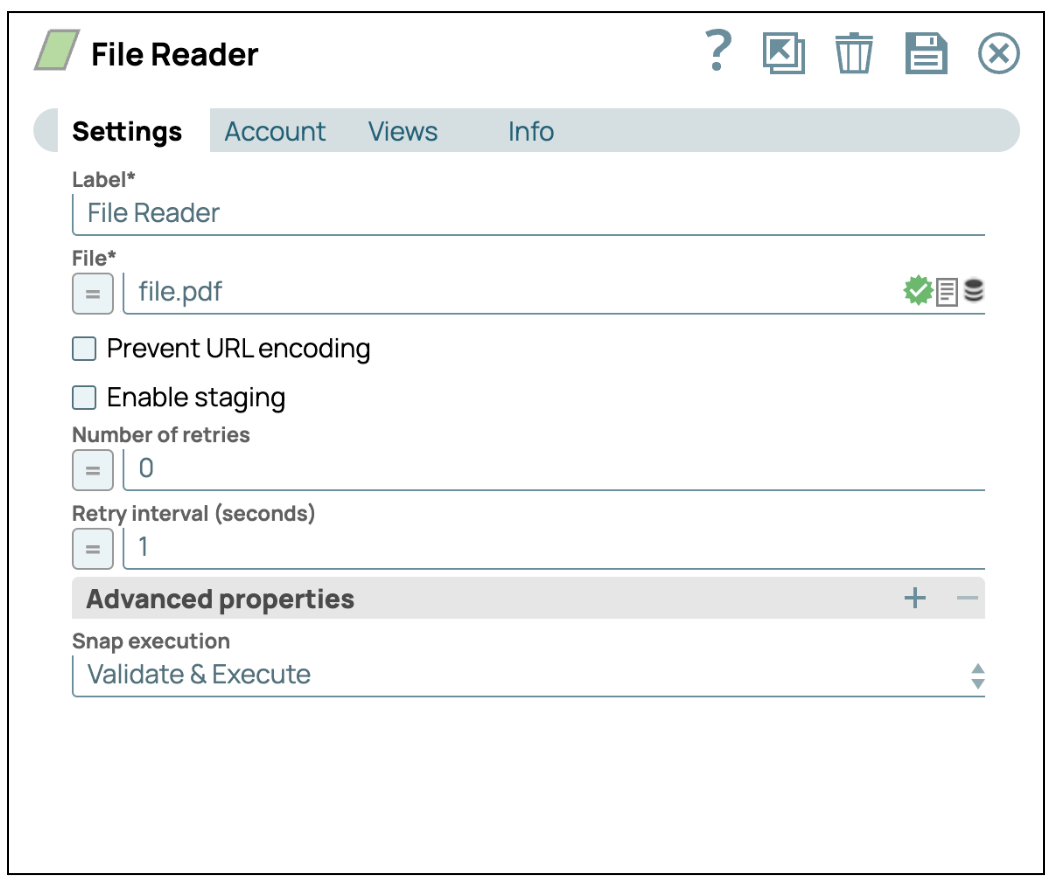
Die Konfiguration des File Reader Snap ist entscheidend für die Einrichtung einer SnapLogic-Pipeline, die präzise und effizient auf Daten aus verschiedenen Dateisystemen und Speicherlösungen zugreifen kann. Dieser Snap dient als Gateway für die Einbindung von Daten in Ihre Pipeline, und seine korrekte Konfiguration ist der Schlüssel für eine nahtlose Datenextraktion.
Wichtige Überlegungen:
- Identifizieren des Speicherorts der Datei:
SnapLogic unterstützt eine Vielzahl von Dateispeicherprotokollen und ermöglicht so den Zugriff auf lokal und in Remote-Umgebungen gespeicherte Dateien.- SLFS (SnapLogic File System): Ideal für kleinere Dateien, die vorübergehend in SnapLogic gespeichert werden.
- Amazon S3: Ein skalierbarer Cloud-Speicherdienst, der sich mit dem S3 File Reader Snap optimal verwalten lässt und so für optimierte Leistung und Benutzerfreundlichkeit sorgt.
- SFTP-Server: Für sichere Dateiübertragungen über ein Netzwerk unter Verwendung von SFTP.
- HTTP/HTTPS: Ermöglicht den direkten Zugriff auf Dateien, die auf Webservern gehostet werden.
- Azure Blob Storage: Optimiert für die Verarbeitung großer Mengen unstrukturierter Daten in der Cloud.
- Auswahl des geeigneten Protokolls:
Die Auswahl des richtigen Protokolls gewährleistet einen effizienten Dateizugriff basierend auf dem Speicherort. Jedes Protokoll erfordert spezifische Konfigurationen, um einen sicheren und genauen Datenabruf zu ermöglichen. Nachfolgend finden Sie die Richtlinien für die Konfiguration verschiedener Speicherprotokolle.- SLFS: Geben Sie den Dateipfad relativ zum SLFS-Stammverzeichnis an.
- Amazon S3: Es wird empfohlen, den S3 File Reader Snap für S3-spezifische Funktionen zu verwenden. Wenn Sie den File Reader Snap verwenden, stellen Sie sicher, dass der richtige Bucket-Name, der richtige Dateipfad und die richtigen AWS-Anmeldedaten angegeben sind.
- SFTP: Geben Sie die Serveradresse, den Dateipfad und die Authentifizierungsdaten (Benutzername, Passwort oder SSH-Schlüssel) ein.
- HTTP/HTTPS: Geben Sie die vollständige URL einschließlich aller erforderlichen Authentifizierungstoken ein.
- Azure Blob Storage: Geben Sie den Containernamen, den Blob-Pfad und die entsprechenden Anmeldedaten an.
- Konfiguration des Dateipfads:
Die korrekte Formatierung des Dateipfads ist für einen erfolgreichen Datenzugriff von entscheidender Bedeutung. Jedes Protokoll erfordert spezifische Pfadstrukturen.- SLFS: Verwenden Sie einen relativen Pfad (z. B. /myfiles/data.csv).
- S3: Formatieren Sie den Pfad für S3-Buckets (z. B. s3://mybucket/data/myfile.csv) und erwägen Sie zur Vereinfachung die Verwendung des S3 File Reader Snap.
- SFTP: Geben Sie den vollständigen Pfad relativ zum SFTP-Stammverzeichnis an (z. B. /home/user/data/myfile.csv).
- HTTP/HTTPS: Verwenden Sie die vollständige URL (z. B. https://www.example.com/files/myfile.csv).
- Azure Blob Storage: Geben Sie den Blob-Pfad innerhalb des Containers an.
- Authentifizierung und Anmeldedaten:
Der sichere Zugriff auf externe Speichersysteme erfordert eine robuste Authentifizierung. Je nach Speichertyp werden unterschiedliche Methoden verwendet, um den autorisierten Zugriff auf sensible Daten zu gewährleisten. Die richtige Konfiguration dieser Methoden ist für die Aufrechterhaltung der Datenintegrität und -sicherheit unerlässlich.
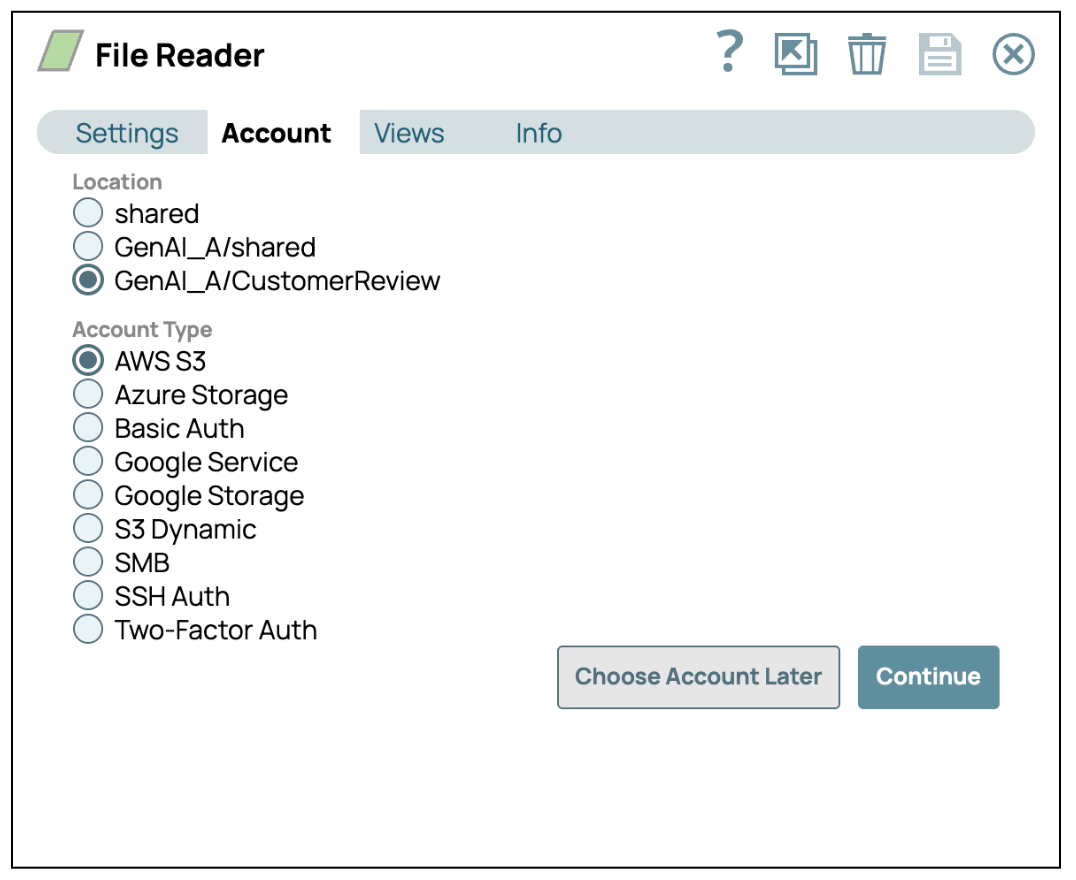
- S3: Verwenden Sie die AWS-Zugriffsschlüssel-ID und den geheimen Zugriffsschlüssel oder IAM-Rollen für AWS-Umgebungen. Der S3 File Reader Snap vereinfacht diesen Vorgang.
- SFTP: Konfigurieren Sie mit Benutzername/Passwort oder SSH-Schlüsseln und stellen Sie sicher, dass die richtige Schlüsseldatei angegeben ist.
- HTTP/HTTPS: Geben Sie bei Bedarf die Anmeldedaten für die Basisauthentifizierung oder Bearer-Token ein.
- Azure Blob Storage: Verwenden Sie je nach Ihren Sicherheitsanforderungen SAS-Token oder AAD-Anmeldeinformationen.
2. Auswahl des geeigneten Parser-Snaps
Sobald der File Reader Snap konfiguriert ist, besteht der nächste Schritt darin, den geeigneten Parser Snap für die Verarbeitung der Dateidaten auszuwählen:
- CSV-Dateien: Verwenden Sie den CSV-Parser-Snap, um CSV-Dateien (Comma Separated Values) zu lesen und zu analysieren. Dieser Snap verarbeitet verschiedene Trennzeichen und Kopfzeilen und ermöglicht so die direkte Zuordnung von CSV-Daten zu nachgelagerten Prozessen.
- JSON-Dateien: Der JSON Parser Snap eignet sich ideal zum Parsen sowohl flacher als auch verschachtelter JSON-Strukturen und konvertiert diese zur weiteren Verarbeitung in das Dokumentformat von SnapLogic.
- XML-Dateien: Der XML-Parser Snap verarbeitet XML-Daten effektiv und unterstützt das Parsen komplexer XML-Strukturen, einschließlich Attributen und verschachtelten Elementen.
- HTML-Dateien: Verwenden Sie den HTML-Parser Snap, um Daten aus HTML-Dokumenten zu extrahieren. Dabei werden XPath- oder CSS-Selektoren unterstützt, um bestimmte Elemente innerhalb des HTML-Codes genau zu lokalisieren.
- PDF-Dateien: Der PDF Parser Snap dient dazu, PDF-Dateien in ein strukturiertes Format wie JSON zu konvertieren, um eine weitere Bearbeitung innerhalb von SnapLogic zu ermöglichen.
Beispiel für das Lesen einer Datei in Snaplogic
CSV-Datei lesen
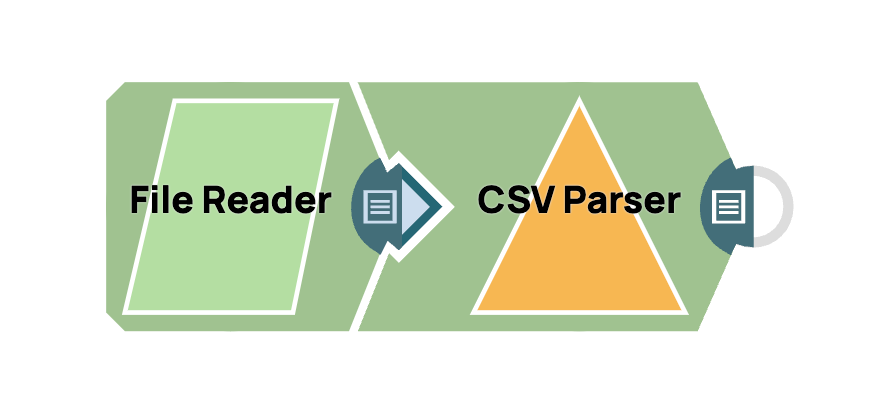
- Fügen Sie den Snap „Datei-Reader“ hinzu: Ziehen Sie den Snap „Datei-Reader“ per Drag & Drop in den Designer-Arbeitsbereich.
- Konfigurieren Sie den Dateileser-SnapKlicken Sie auf das Snap-Element „Dateileser“, um dessen Einstellungsfenster aufzurufen.
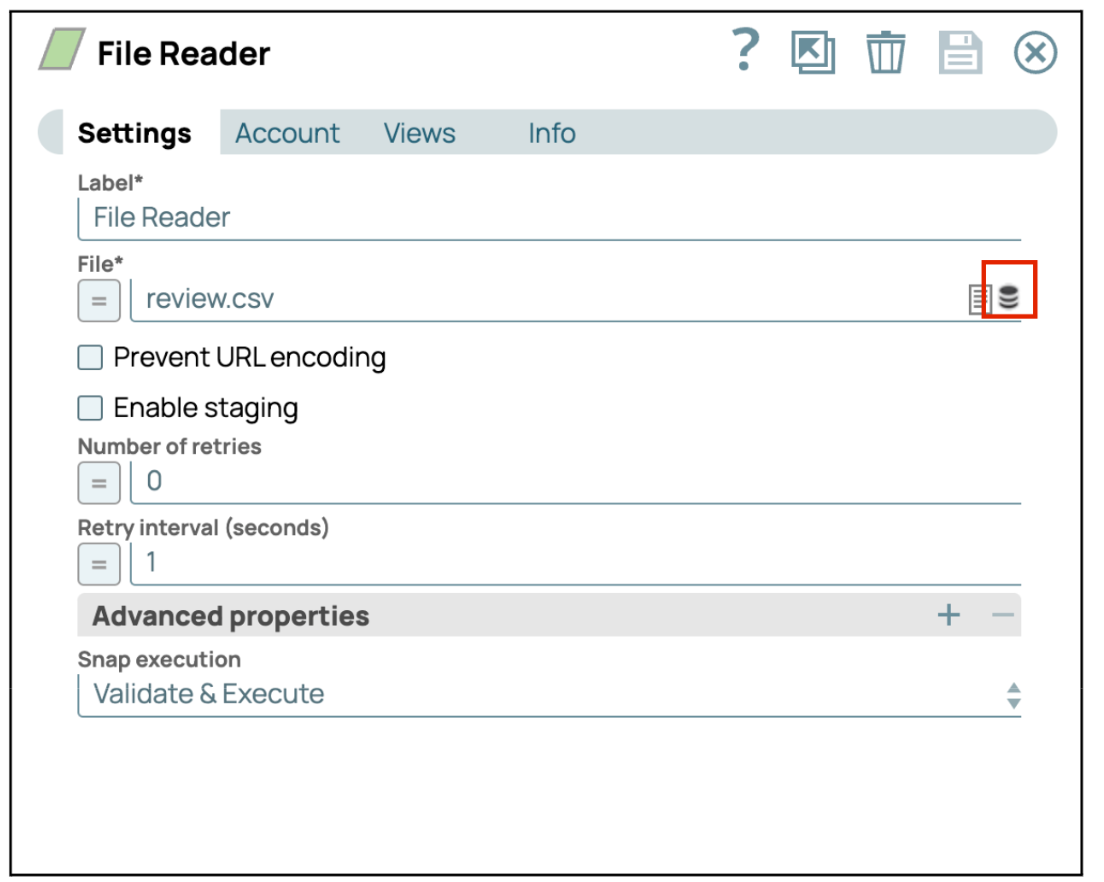
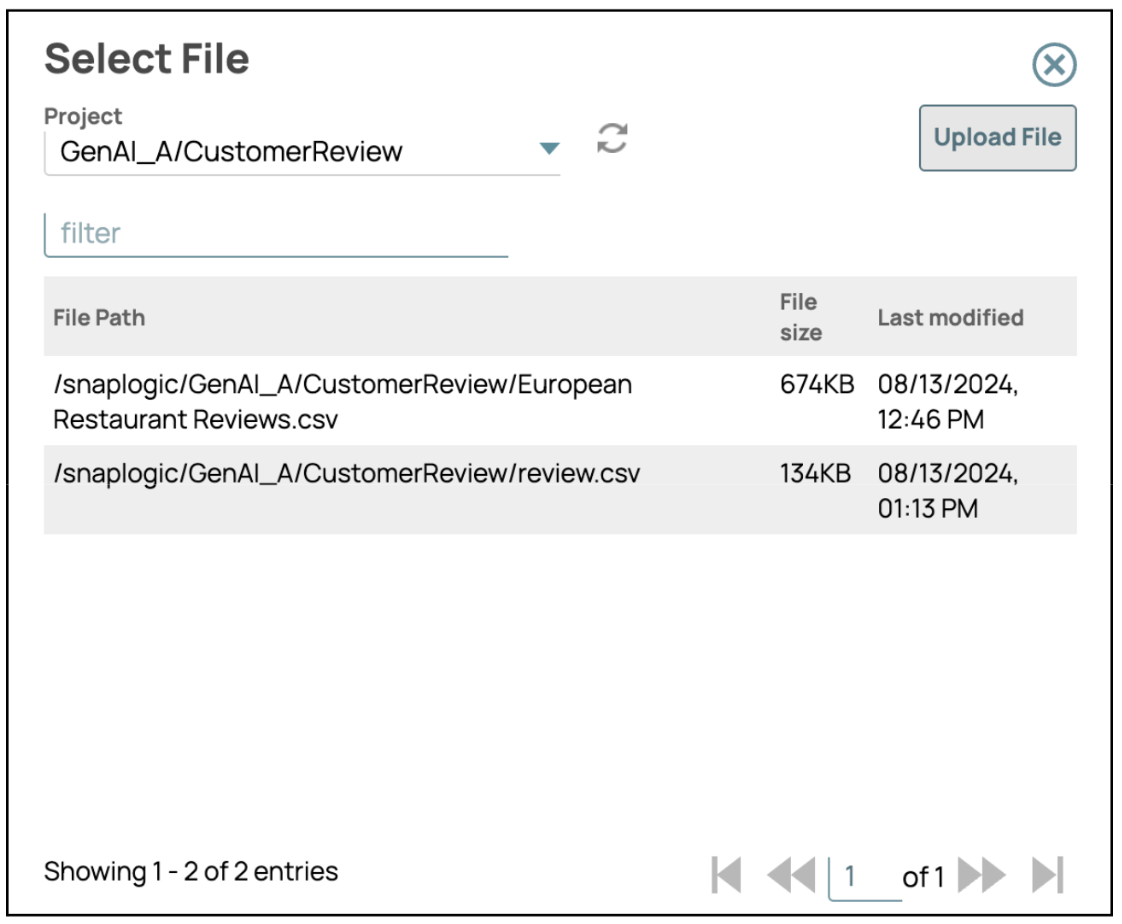
- Datei auswählen oder hochladenKlicken Sie in den Dateieinstellungen auf das Ordnersymbol, um entweder eine neue Datei hochzuladen oder eine vorhandene Datei aus dem Verzeichnis auszuwählen.
- Konfiguration speichern: Nachdem Sie die gewünschte Datei ausgewählt oder hochgeladen haben, klicken Sie auf „Speichern“ und schließen Sie anschließend das Einstellungsfenster.
- Fügen Sie den CSV-Parser-Snap hinzu: Ziehen Sie den „CSV-Parser”-Snap per Drag & Drop in den Arbeitsbereich und positionieren Sie ihn hinter dem Dateileser. Die Standardeinstellungen für den CSV-Parser sind in der Regel für die meisten Anwendungsfälle ausreichend.
- Pipeline validieren oder ausführen: Validieren oder führen Sie die Pipeline aus, um den Inhalt der CSV-Datei zu verarbeiten und zu lesen.
HTML-Inhalte mit File Reader lesen
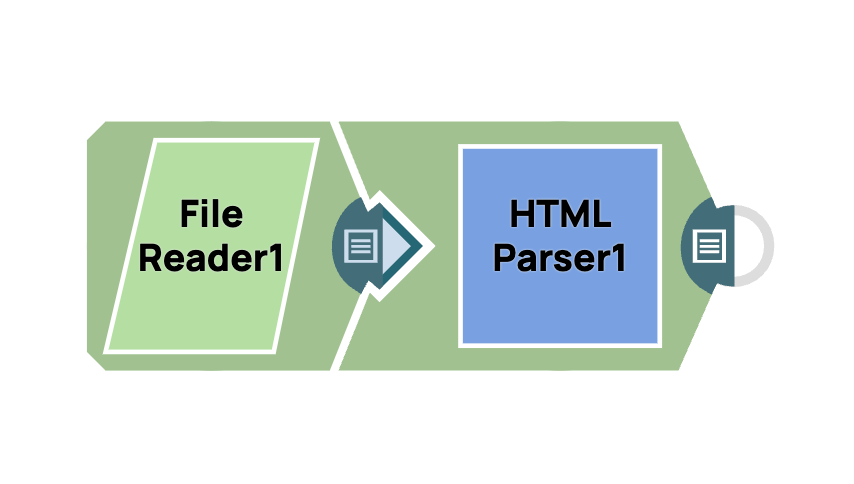
- Fügen Sie den Snap „Datei-Reader“ hinzu: Ziehen Sie den Snap „Datei-Reader“ per Drag & Drop in den Designer-Arbeitsbereich.
- Konfigurieren Sie den Dateileser-SnapKlicken Sie auf das Snap „Dateileser“, um dessen Einstellungsfeld aufzurufen. Geben Sie dann die URL, mit der Sie sich verbinden möchten, in die Einstellungen ein.
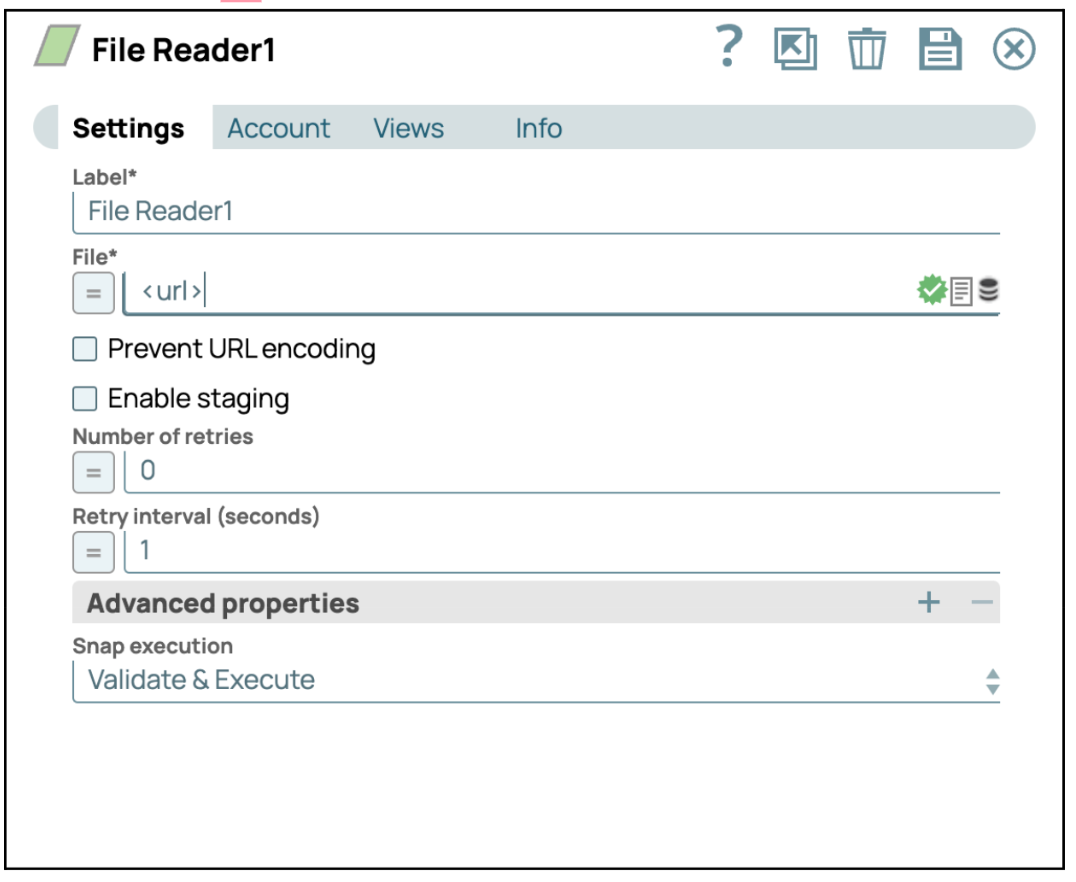
- Konfiguration speichern: Klicken Sie auf „Speichern“ und schließen Sie die Einstellungen.
- Fügen Sie den HTML-Parser-Snap hinzu: Ziehen Sie den „HTML-Parser”-Snap in den Designer, verbinden Sie ihn mit dem Dateileser-Snap und belassen Sie die Konfiguration auf den Standardeinstellungen.
- Konfigurieren Sie den HTML-Parser-SnapÖffnen Sie die Einstellungen des HTML-Parsers und gehen Sie zur Registerkarte „Ansichten“. Wählen Sie aus, ob die Ausgabe als Dokument oder als Binärdatei erfolgen soll.
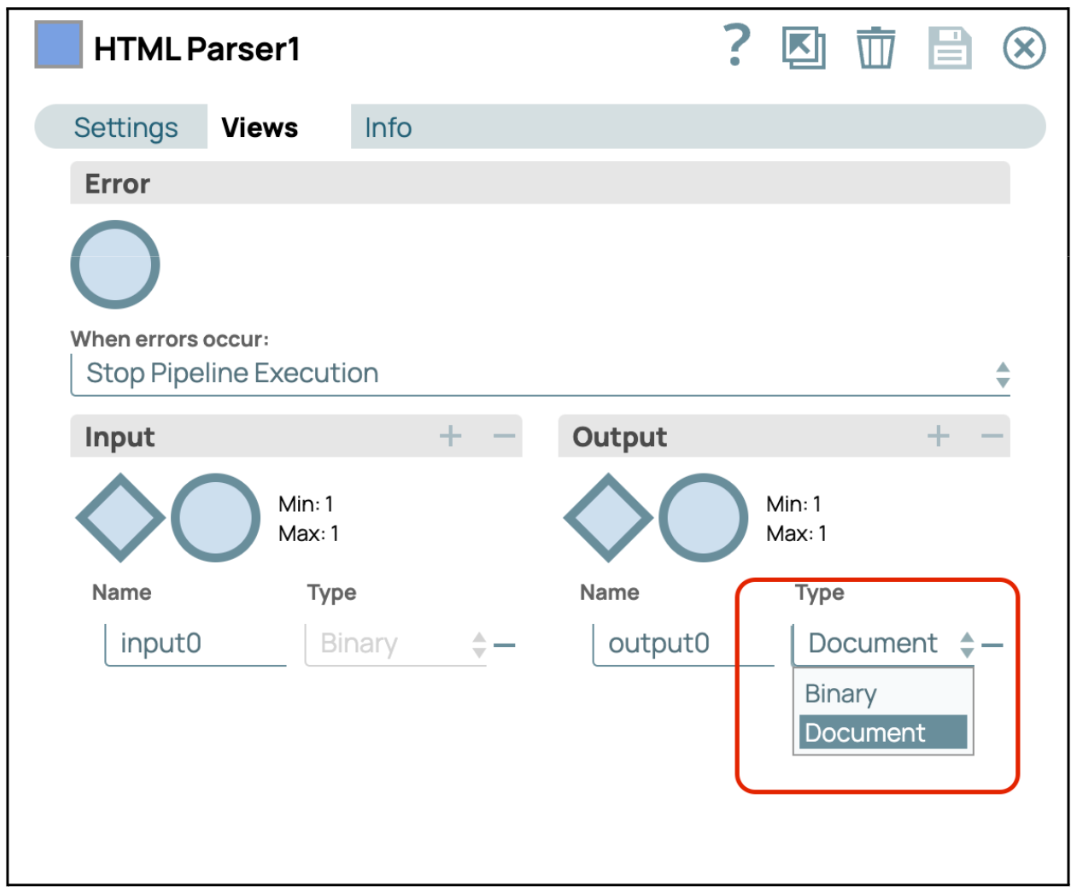
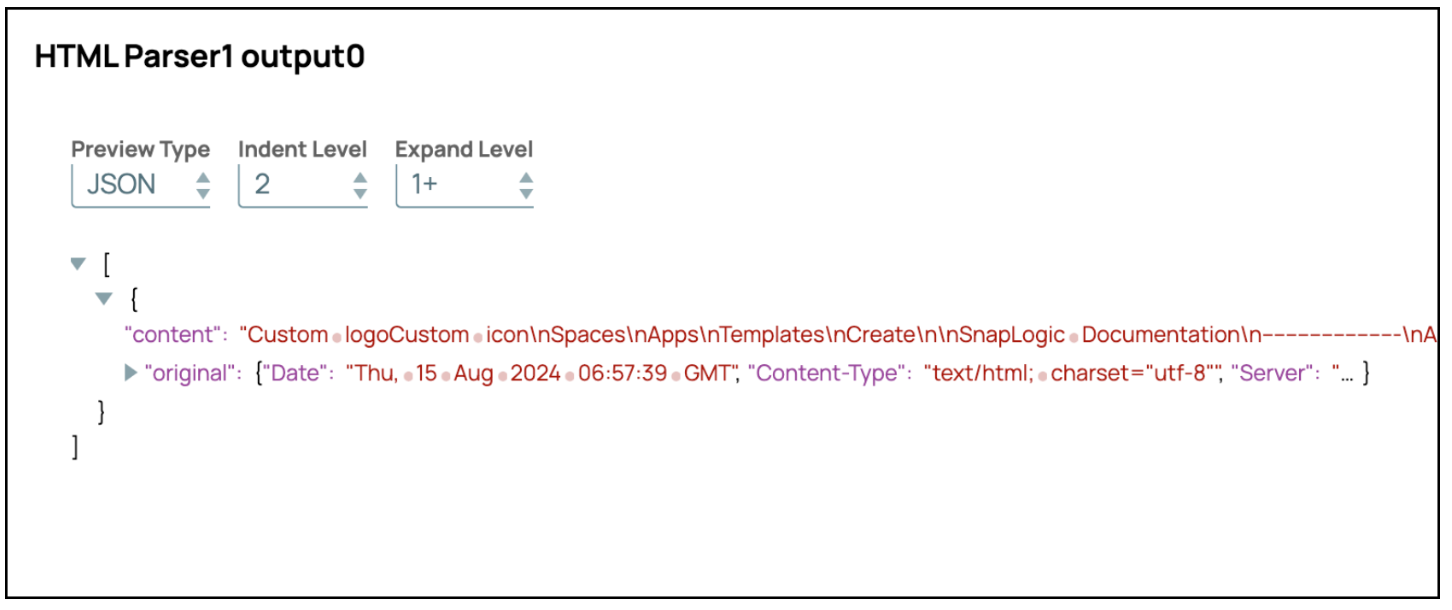
- Pipeline validieren oder ausführen: Validieren oder führen Sie die Pipeline aus, um den Textinhalt von der angegebenen URL abzurufen.
Lesen von HTML-Inhalten mit HTTP-Client
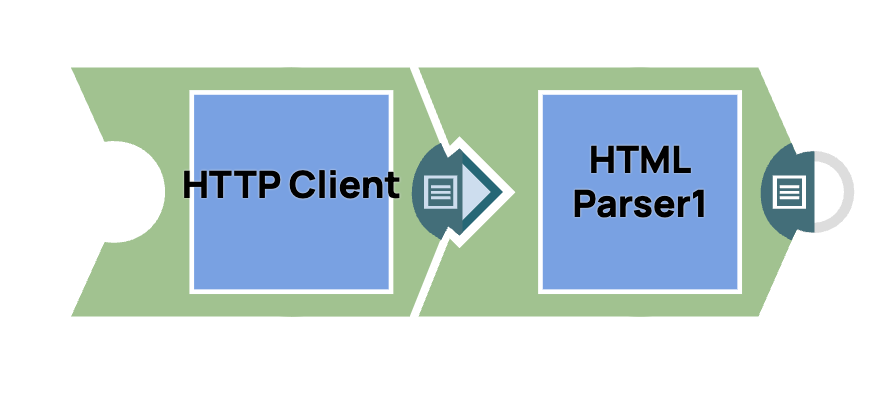
- Fügen Sie den HTTP-Client-Snap hinzu: Ziehen Sie den „HTTP-Client”-Snap per Drag & Drop in den Designer-Arbeitsbereich.
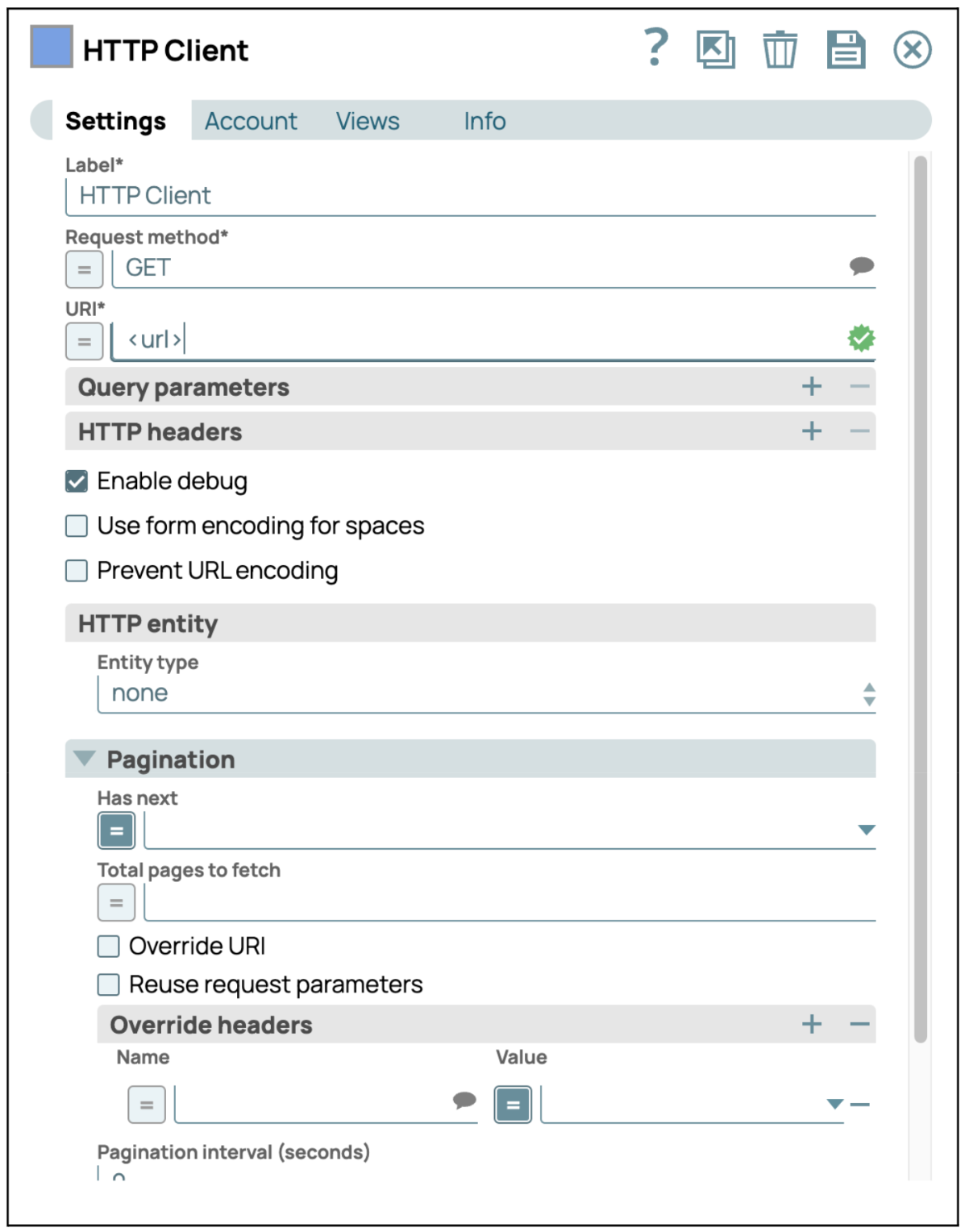
- Konfigurieren Sie den HTTP-Client-SnapKlicken Sie auf den Snap „HTTP-Client“, um dessen Einstellungsfeld aufzurufen. Geben Sie dann die URL, mit der Sie sich verbinden möchten, in die Einstellungen ein. Der HTTP-Client-Snap ermöglicht es Benutzern, komplexe HTML-Aufrufe mit verschiedenen Konfigurationen durchzuführen. Benutzer können „Anforderungsmethoden“ auswählen oder den „Paginierungsmechanismus“ bereitstellen, um fortlaufende Inhalte zu erhalten.
- Konfigurieren Sie die HTTP-Client-Snap-Ansichten: Klicken Sie auf die Registerkarte „Ansichten“ und wählen Sie als Ausgabe „Binär“. Speichern und schließen Sie anschließend die Einstellungen.
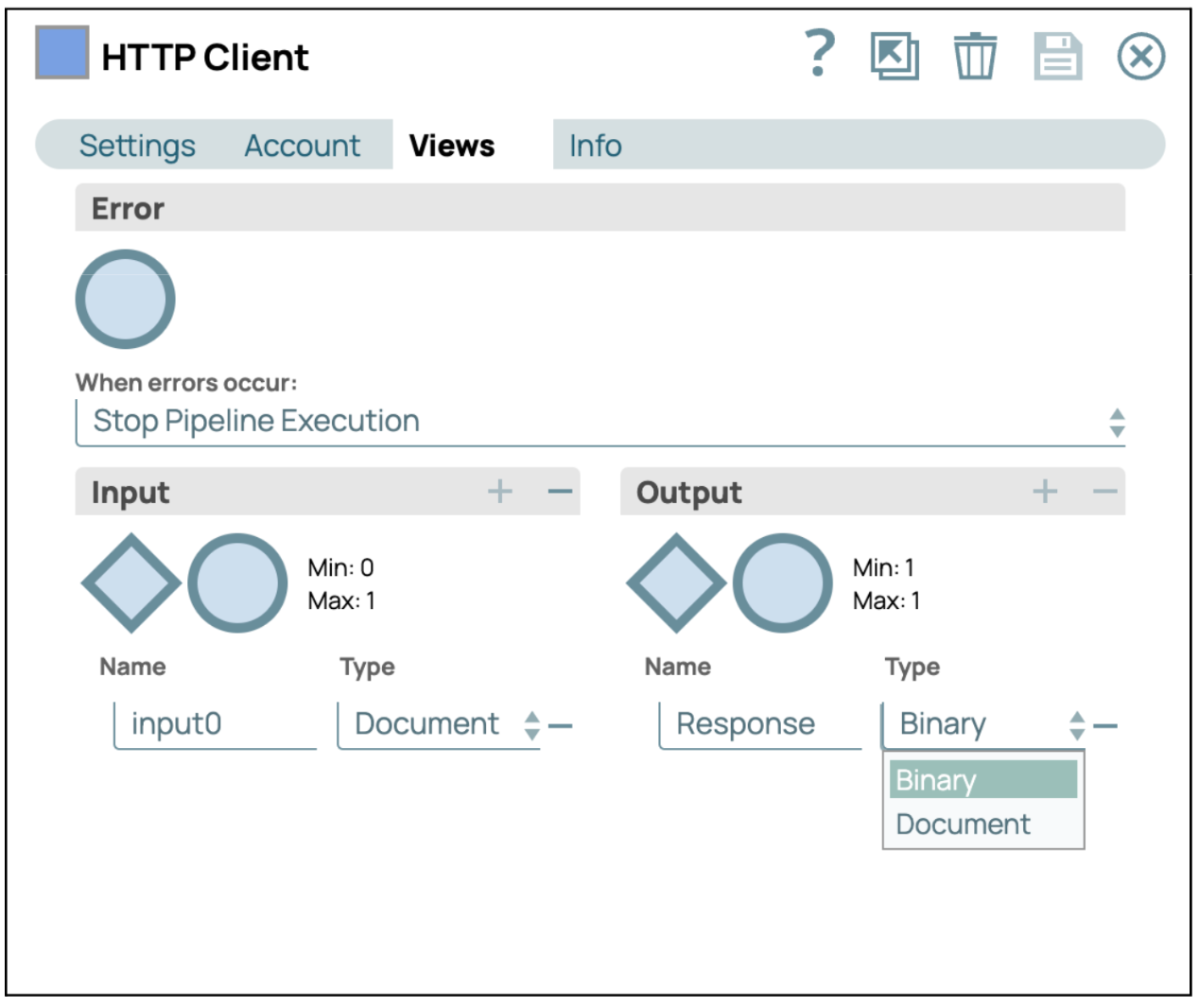
- Fügen Sie den HTML-Parser-Snap hinzu: Ziehen Sie den „HTML-Parser”-Snap in den Designer, verbinden Sie ihn dann mit dem Dateileser-Snap und belassen Sie die Konfiguration auf den Standardeinstellungen.
- Pipeline validieren oder ausführen: Validieren oder führen Sie die Pipeline aus, um den Textinhalt von der angegebenen URL abzurufen.
- Ausgabe anzeigen: Die Ausgabe zeigt den Inhalt im Textformat an.
PDF-Datei lesen
Um Informationen aus einer PDF-Datei effektiv lesen und extrahieren zu können, müssen Benutzer zunächst die Art des Inhalts der Datei verstehen. PDF-Dateien lassen sich im Allgemeinen in zwei Kategorien einteilen: solche mit textbasierten Inhalten und solche mit bildbasierten Inhalten.
Bei PDF-Dateien mit textbasierten Inhalten können Benutzer einen Standard-PDF-Parser verwenden, der dafür ausgelegt ist, die Textinformationen zu extrahieren und in einem lesbaren Format auszugeben. Diese Parser sind weit verbreitet und wandeln den in einem PDF-Dokument eingebetteten Text effizient in ein Textformat um, das weiterverarbeitet oder analysiert werden kann.
Wenn die PDF-Datei jedoch bildbasierte Inhalte wie gescannte Dokumente oder Textbilder enthält, ist ein anderer Ansatz erforderlich. In diesem Fall muss die Technologie der optischen Zeichenerkennung (OCR) zum Einsatz kommen. OCR-Dienste sind spezielle Tools, die die Bilder in der PDF-Datei analysieren und die visuellen Darstellungen von Text in maschinenlesbaren Text umwandeln. Dieser Prozess ist entscheidend, um den Inhalt zugänglich und bearbeitbar zu machen, insbesondere bei gescannten Dokumenten oder anderen bildlastigen Dateien.
Durch das Verständnis dieser Unterschiede und die Auswahl des geeigneten Tools für die Art des Inhalts innerhalb einer PDF-Datei können Benutzer die erforderlichen Informationen effektiv extrahieren und so die Genauigkeit und Effizienz ihres Arbeitsablaufs sicherstellen.
PDF-Datei mit PDF Parser snap lesen

- Fügen Sie den Snap „Datei-Reader“ hinzu: Ziehen Sie den Snap „Datei-Reader“ per Drag & Drop in den Designer-Arbeitsbereich.
- Konfigurieren Sie den Dateileser-SnapKlicken Sie auf das Snap „Dateireader“, um dessen Einstellungsfenster zu öffnen. Wählen Sie dann eine PDF-Datei aus, die Sie lesen möchten, oder laden Sie sie hoch.
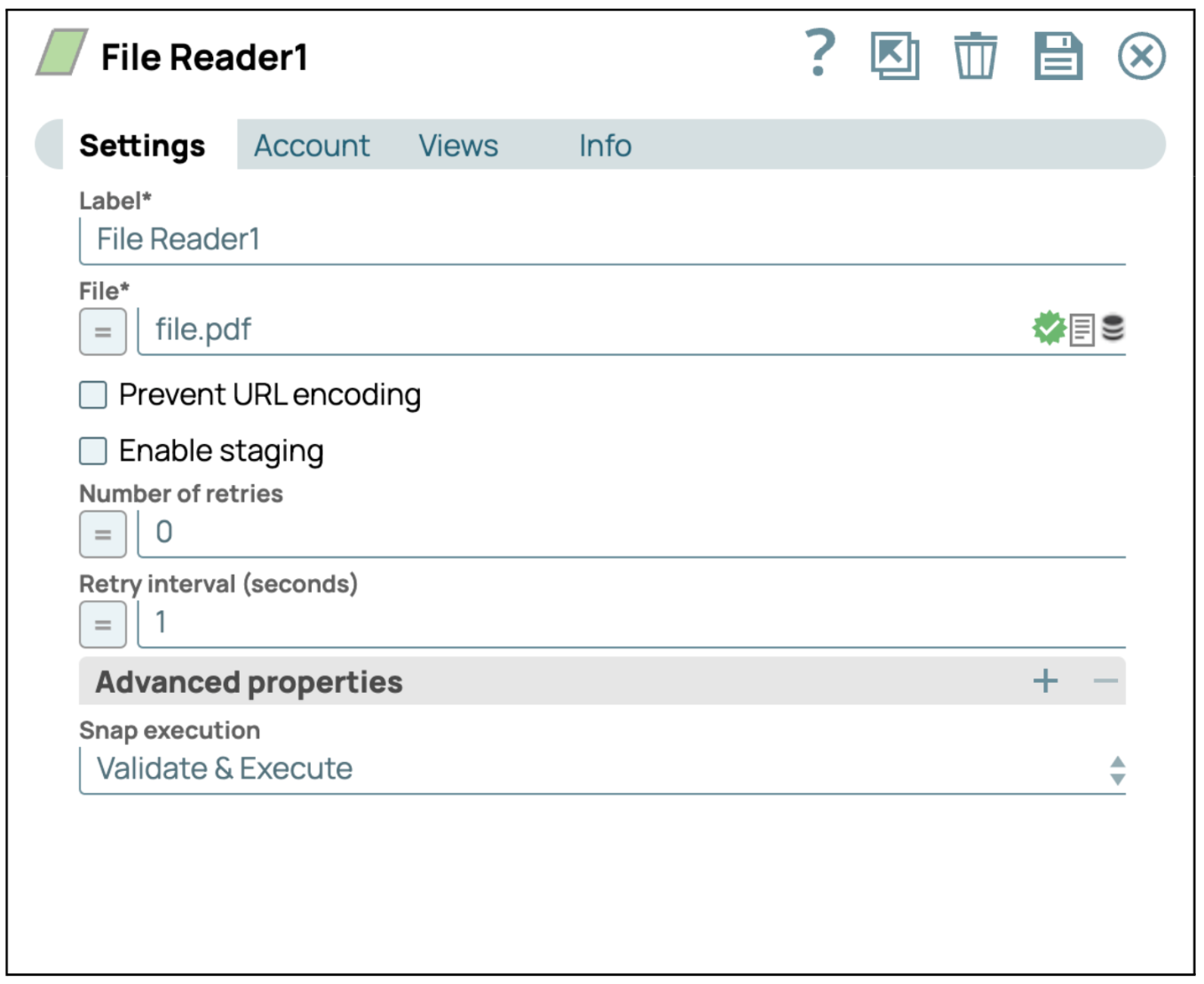
- Konfiguration speichern: Klicken Sie auf „Speichern“ und schließen Sie die Einstellungen.
- Fügen Sie den PDF-Parser-Snap hinzu: Der PDF-Parser-Snap kann die PDF-Datei in einen Text umwandeln.
- Konfigurieren Sie den PDF-Parser-SnapBenutzer können einen geeigneten „Parser-Typ“ auswählen, um die PDF-Datei zu analysieren. In diesem Fall wählen wir „Textextraktor“, damit wir den gesamten Text aus der PDF-Datei extrahieren können.
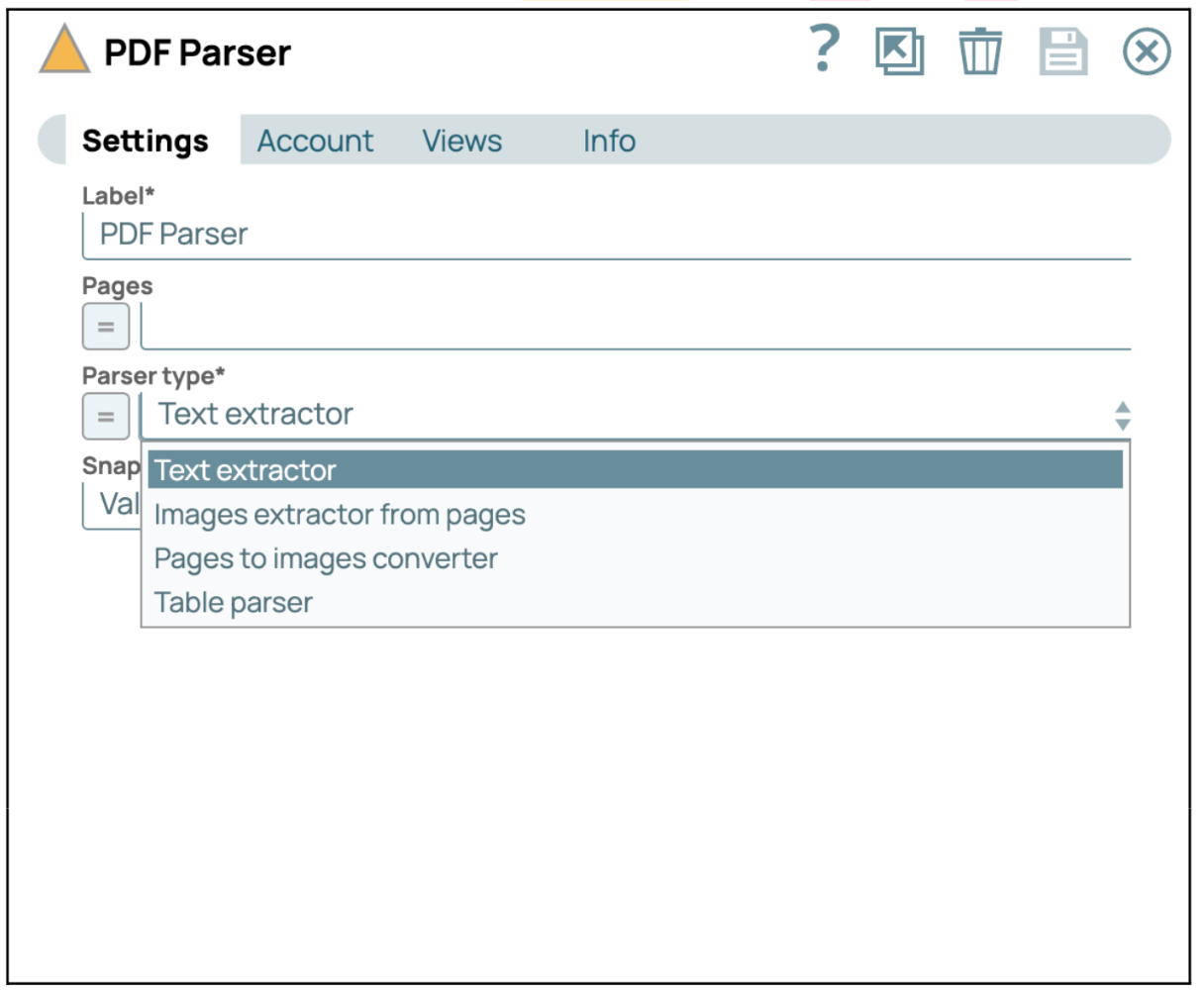
- Pipeline validieren oder ausführenValidieren oder führen Sie die Pipeline aus, um den Textinhalt aus der angegebenen PDF-Datei abzurufen. Die Antwort enthält den aus der PDF-Datei extrahierten PDF-Text.

Lesen von PDF-Dateien mit unstrukturierten Daten

Voraussetzung: Benutzer müssen über einen unstrukturierten API-Schlüssel verfügen, um auf den unstrukturierten Dienst zugreifen zu können, oder die unstrukturierte Instanz lokal bereitstellen, um die unstrukturierte API nutzen zu können.
Fügen Sie den Snap „Datei-Reader“ hinzu: Ziehen Sie den Snap „Datei-Reader“ per Drag & Drop in den Designer-Arbeitsbereich.
Konfigurieren Sie den Datei-Reader-Snap: Klicken Sie auf den „Datei-Reader”-Snap, um das Einstellungsfenster zu öffnen. Wählen Sie dann eine PDF-Datei aus, die Sie lesen möchten, oder laden Sie sie hoch.
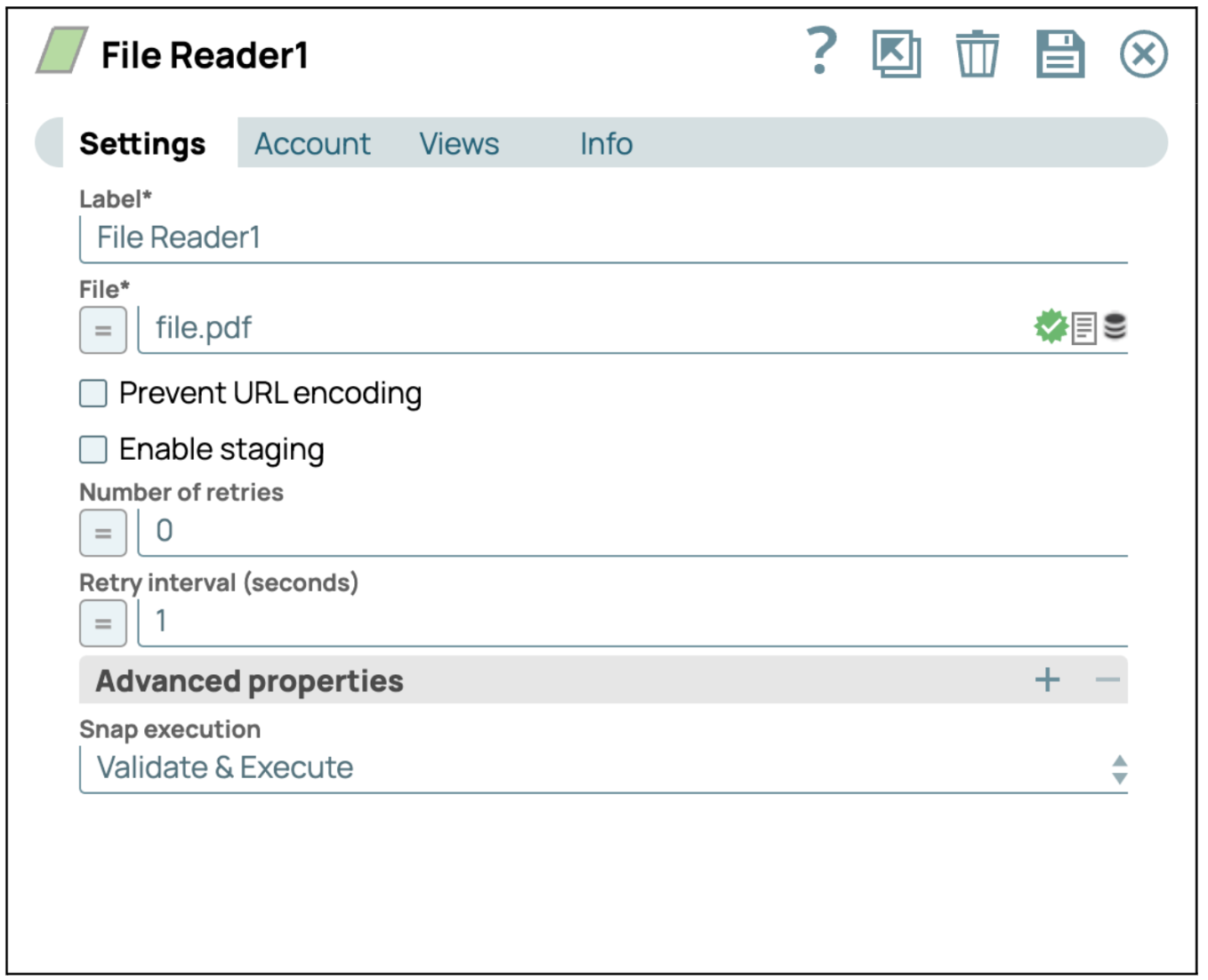
- Konfiguration speichern: Klicken Sie auf „Speichern“ und schließen Sie die Einstellungen.
- Fügen Sie den Partition API Snap hinzu: Die Partition-API-Snap-Funktion nutzt die unstrukturierte Partition-API, um eine PDF-Datei zu analysieren.
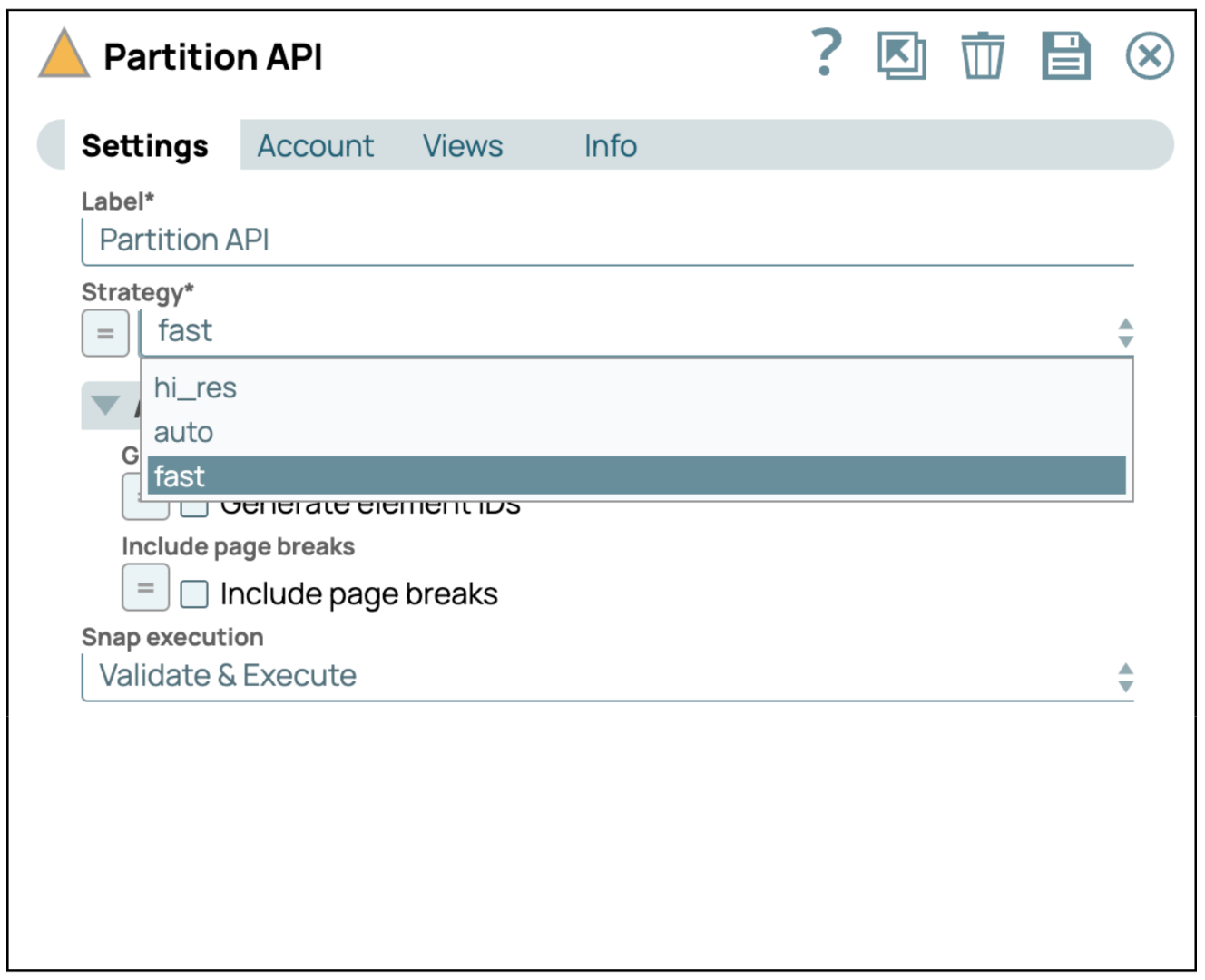
- Konfigurieren Sie die Partition-API Snap: Benutzer können eine Strategie zum Parsen einer PDF-Datei auswählen. In diesem Fall verwenden wir die Strategie „fast“, um nur Text zu parsen und keine Bilder und Tabellen einzubeziehen. Wenn Sie „hi_res“ auswählen, werden die Bilder und Tabellen als Base64 geparst.
- Pipeline validieren oder ausführenValidieren oder führen Sie die Pipeline aus, um den Textinhalt aus der angegebenen PDF-Datei abzurufen. Die Antwort enthält auch den Typ des Inhalts, der aus der PDF-Datei geparst wird. So können Benutzer das Attribut „type“ für die weitere Verarbeitung verwenden, beispielsweise können Benutzer den Titel und den Inhalt getrennt von der Fußzeile verarbeiten.

Lesen einer PDF-Datei mit Adobe Service
Benutzer können die Adobe-API für PDF-Parsing-Aufgaben nutzen. SnapLogic bietet den Adobe Extract Snap zum Extrahieren von Text aus PDF-Dokumenten sowie den Adobe OCR Snap zum Verarbeiten von bildbasierten PDF-Inhalten. Bei PDF-Dateien mit bildbasierten Inhalten ist der Adobe OCR Snap das geeignete Tool, da er eine genaue Extraktion von Text aus Bildern innerhalb des Dokuments ermöglicht.
PDF-Datei mit Adobe OCR lesen
Voraussetzung: Benutzer müssen über einen Adobe-Schlüssel verfügen, um auf den Adobe OCR-Dienst zugreifen zu können, bevor sie das Adobe OCR-Snap verwenden können.
- Fügen Sie den Snap „Datei-Reader“ hinzu: Ziehen Sie den Snap „Datei-Reader“ per Drag & Drop in den Designer-Arbeitsbereich.
- Konfigurieren Sie den Dateileser-SnapKlicken Sie auf das Snap „Dateireader“, um dessen Einstellungsfenster zu öffnen. Wählen Sie dann eine PDF-Datei aus, die Sie lesen möchten, oder laden Sie sie hoch.
- Konfiguration speichern: Klicken Sie auf „Speichern“ und schließen Sie die Einstellungen.
- Adobe OCR Snap hinzufügen: Adobe OCR Snap nutzt die Adobe-API, um PDF-Dateien mit bildbasierten Inhalten effizient zu analysieren. Benutzer können sich auf die Standardeinstellungen von Adobe OCR Snap verlassen, um Text aus den in der PDF-Datei eingebetteten Bildern präzise zu extrahieren.
- Pipeline validieren oder ausführen: Validieren oder führen Sie die Pipeline aus, um den Textinhalt aus der angegebenen PDF-Datei abzurufen. Die Antwort enthält einen Binärinhalt, der die extrahierten Informationen enthält.








