






Ce guide fournit une approche étape par étape pour utiliser SnapLogic afin d'extraire des données à partir de formats tels que PDF, CSV, JSON et HTML. Que vous soyez novice dans l'utilisation de SnapLogic ou que vous cherchiez à affiner vos processus d'extraction de données, ce guide vous aidera à créer et à gérer des pipelines efficaces.
Formats de données dans SnapLogic
SnapLogic est capable de lire des données provenant d'un large éventail de sources et peut convertir ces données en deux formats principaux :
- Format du document:
- Un document dans SnapLogic est un format de type JSON utilisé pour le traitement interne des données. Ce format permet aux utilisateurs d'interagir avec les attributs des données d'une manière similaire à JSON. Il prend également en charge les fonctions internes de SnapLogic, telles que le traitement de texte, permettant aux utilisateurs d'appliquer des expressions pour la manipulation et la transformation des données. Ces transformations peuvent être effectuées avant que les données ne soient envoyées aux connecteurs en aval, garantissant ainsi que les données sont correctement structurées et formatées pour le traitement ultérieur.
- Format binaire:
- Le format binaire dans SnapLogic est utilisé pour traiter les flux de données brutes, telles que les images, les PDF ou tout autre type de fichier qui ne correspond pas aux formats de données structurés. Ce format est particulièrement utile lorsqu'il s'agit de données non textuelles ou lorsque les données doivent être transmises via le pipeline sans modification. SnapLogic peut convertir les données binaires vers d'autres formats si nécessaire, ce qui permet leur traitement, leur stockage ou leur transformation avant leur transmission aux composants en aval. Cela garantit flexibilité et efficacité dans le traitement de différents types de données au sein du pipeline.
Extraction de données à partir de fichiers dans SnapLogic
SnapLogic offre des fonctionnalités robustes pour extraire des données à partir de divers types de fichiers, ce qui en fait un outil polyvalent dans les workflows d'intégration de données. Pour faciliter ce processus, SnapLogic fournit le SnapLogic File System (SLFS), une solution de stockage intégrée où les utilisateurs peuvent télécharger et gérer des fichiers directement dans l'environnement SnapLogic. Cependant, il existe des considérations importantes et des bonnes pratiques à garder à l'esprit lors de l'utilisation du SLFS pour l'extraction de données.
Utilisation du système de fichiers SnapLogic (SLFS)
Le système de fichiers SnapLogic (SLFS) permet aux utilisateurs de stocker et d'accéder à des fichiers pour les traiter dans leurs pipelines. Pour extraire des données d'un fichier à l'aide de SnapLogic, les utilisateurs doivent d'abord télécharger le fichier vers SLFS. Une fois téléchargé, le fichier peut être consulté et traité par divers Snaps conçus pour lire et manipuler le contenu des fichiers.
Cependant, SLFS impose une limite de taille de fichier, les utilisateurs pouvant télécharger des fichiers d'une taille maximale de 100 Mo par fichier. Cette limitation peut poser des difficultés lorsqu'il s'agit de traiter des ensembles de données ou des fichiers plus volumineux. Si le fichier dépasse cette limite de taille, les utilisateurs doivent diviser le contenu en plusieurs fichiers plus petits avant de les télécharger vers SLFS. Si cette approche peut fonctionner pour des données plus petites ou segmentées, elle n'est généralement pas recommandée pour les tâches de traitement de données à grande échelle.
Meilleures pratiques pour la gestion des fichiers volumineux
Pour traiter des fichiers de plus de 100 Mo, il est conseillé d'utiliser des systèmes de stockage externes plutôt que de se fier au SLFS. Les systèmes de fichiers externes offrent une plus grande flexibilité et évolutivité, vous permettant de traiter des fichiers beaucoup plus volumineux sans avoir à les segmenter manuellement. SnapLogic s'intègre de manière transparente à diverses solutions de stockage externes, permettant une extraction et un traitement efficaces des données.
- Serveurs SFTP: les utilisateurs peuvent utiliser des serveurs SFTP (Secure File Transfer Protocol) pour stocker et accéder à des fichiers volumineux. SnapLogic prend en charge l'intégration SFTP, ce qui vous permet de lire et de traiter en toute sécurité des fichiers directement à partir du serveur au sein de vos pipelines.
- Services de stockage d'objets (par exemple, Amazon S3): les services de stockage d'objets Cloud, tels qu'Amazon S3, offrent une capacité de stockage pratiquement illimitée, ce qui les rend idéaux pour la gestion de grands ensembles de données. La prise en charge native de S3 par SnapLogic permet aux utilisateurs de lire, d'écrire et de gérer des fichiers stockés dans des compartiments S3, garantissant ainsi un traitement fluide des données sans les contraintes du SLFS.
En intégrant SnapLogic à ces solutions de stockage externes, les utilisateurs peuvent gérer efficacement les fichiers volumineux, rationaliser les workflows d'extraction de données et maintenir des performances optimales sur l'ensemble de leurs pipelines. Cette approche permet non seulement de surmonter les limites du SLFS, mais aussi de s'aligner sur les meilleures pratiques en matière de traitement de données évolutif et fiable.
Lecture des données et traitement des fichiers dans SnapLogic
Dans cette section, nous allons nous intéresser au processus de lecture des données à partir de différents formats de fichiers à l'aide de SnapLogic. Ce guide décrit les étapes clés, les options de configuration et les meilleures pratiques pour garantir une extraction efficace et performante des données. Pour lire les données d'un fichier à l'aide de SnapLogic, vous pouvez suivre ces deux étapes essentielles :
1. Configuration du Snap Lecteur de fichiers
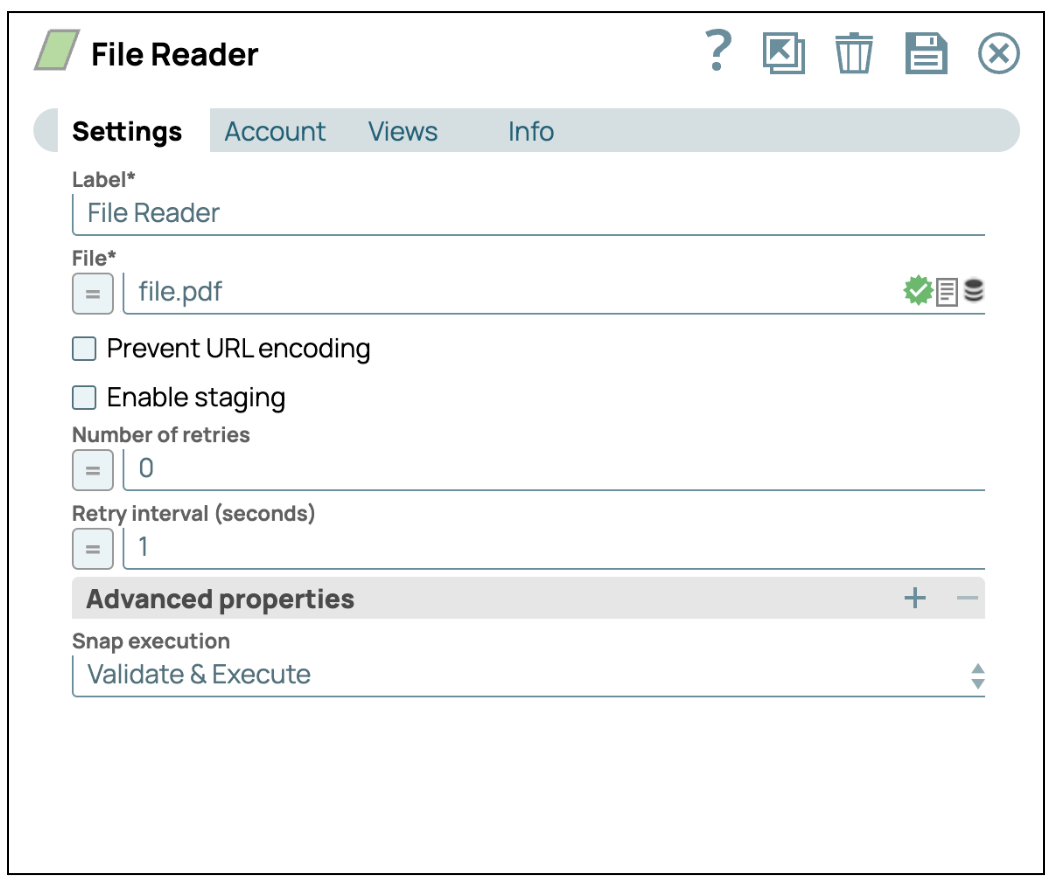
La configuration du Snap File Reader est essentielle pour mettre en place un pipeline SnapLogic capable d'accéder avec précision et efficacité aux données provenant de divers systèmes de fichiers et solutions de stockage. Ce Snap sert de passerelle pour intégrer les données dans votre pipeline, et sa configuration adéquate est essentielle pour une extraction fluide des données.
Considérations clés :
- Identification de l'emplacement du fichier :
SnapLogic prend en charge un large éventail de protocoles de stockage de fichiers, permettant ainsi d'accéder aux fichiers stockés à la fois localement et dans des environnements distants.- SLFS (SnapLogic File System) : idéal pour les fichiers de petite taille stockés temporairement dans SnapLogic.
- Amazon S3 : un service cloud évolutif, optimisé pour des performances et une facilité d'utilisation accrues grâce au Snap S3 File Reader.
- Serveurs SFTP : pour des transferts de fichiers sécurisés sur un réseau à l'aide du protocole SFTP.
- HTTP/HTTPS : Permet l'accès direct aux fichiers hébergés sur des serveurs web.
- Azure Blob Storage : optimisé pour traiter de grandes quantités de données non structurées dans le cloud.
- Sélection du protocole approprié :
Le choix du protocole approprié garantit un accès efficace aux fichiers en fonction de leur emplacement de stockage. Chaque protocole nécessite des configurations spécifiques pour permettre une récupération sécurisée et précise des données. Vous trouverez ci-dessous les directives pour configurer différents protocoles de stockage.- SLFS : Spécifiez le chemin d'accès au fichier par rapport à la racine SLFS.
- Amazon S3 : il est recommandé d'utiliser le Snap S3 File Reader pour les fonctionnalités spécifiques à S3. Si vous utilisez le Snap File Reader, assurez-vous que le nom du compartiment, le chemin d'accès au fichier et les informations d'identification AWS sont corrects.
- SFTP : saisissez l'adresse du serveur, le chemin d'accès au fichier et les informations d'authentification (nom d'utilisateur, mot de passe ou clé SSH).
- HTTP/HTTPS : entrez l'URL complète, y compris les jetons d'authentification nécessaires.
- Stockage Blob Azure : indiquez le nom du conteneur, le chemin d'accès au blob et les informations d'identification pertinentes.
- Configuration du chemin d'accès au fichier :
Il est essentiel de formater correctement le chemin d'accès au fichier pour garantir un accès réussi aux données. Chaque protocole nécessite des structures de chemin d'accès spécifiques.- SLFS : Utilisez un chemin relatif (par exemple, /myfiles/data.csv).
- S3 : formatez le chemin d'accès aux compartiments S3 (par exemple, s3://mybucket/data/myfile.csv) et envisagez d'utiliser le Snap S3 File Reader pour plus de simplicité.
- SFTP : Indiquez le chemin d'accès complet relatif à la racine SFTP (par exemple, /home/user/data/myfile.csv).
- HTTP/HTTPS : utilisez l'URL complète (par exemple, https://www.example.com/files/myfile.csv).
- Stockage Blob Azure : spécifiez le chemin d'accès au blob dans le conteneur.
- Authentification et identifiants :
L'accès sécurisé aux systèmes de stockage externes nécessite une authentification robuste. Selon le type de stockage, différentes méthodes sont utilisées pour garantir un accès autorisé aux données sensibles. Une configuration adéquate de ces méthodes est essentielle pour maintenir l'intégrité et la sécurité des données.
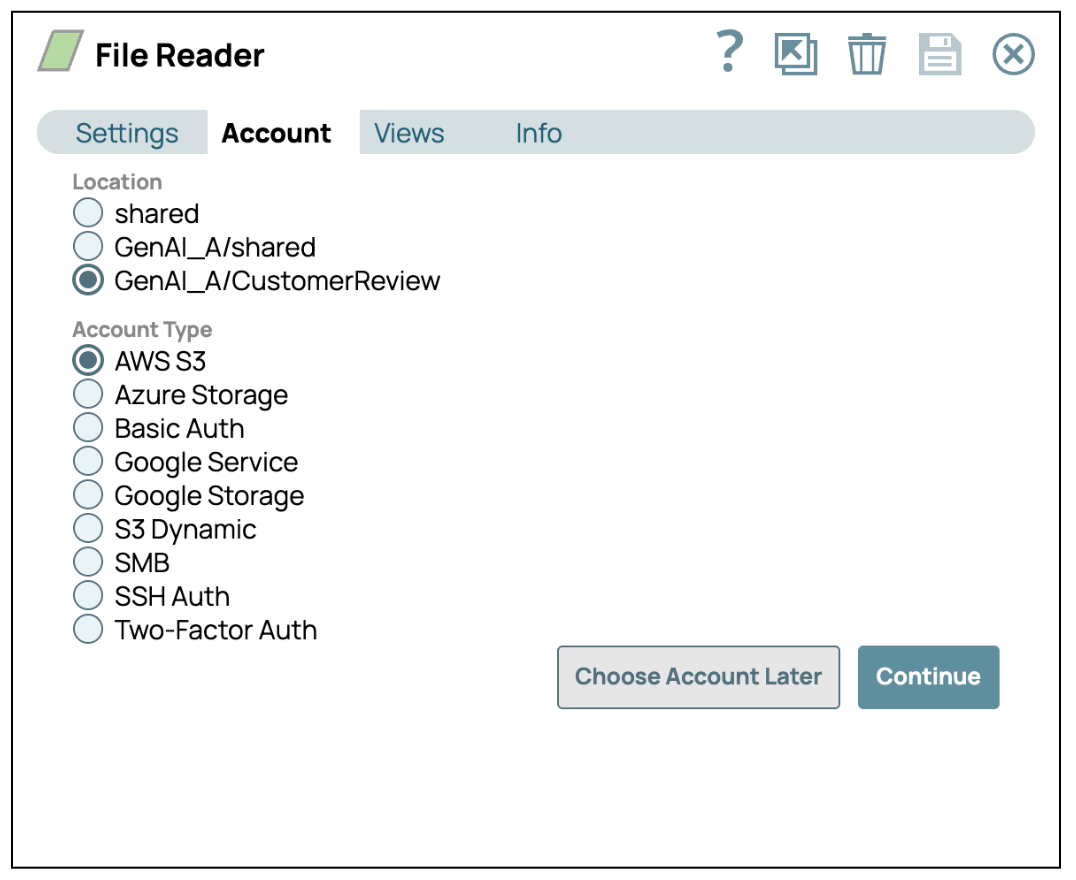
- S3 : utilisez l'ID de clé d'accès AWS et la clé d'accès secrète, ou les rôles IAM pour les environnements AWS. Le Snap S3 File Reader simplifie ce processus.
- SFTP : Configurez avec un nom d'utilisateur/mot de passe ou des clés SSH, en vous assurant que le fichier de clé correct est spécifié.
- HTTP/HTTPS : saisissez les informations d'authentification de base ou les jetons porteurs selon les besoins.
- Stockage Blob Azure : utilisez des jetons SAS ou des informations d'identification AAD en fonction de vos exigences de sécurité.
2. Sélectionner le snap de parseur approprié
Une fois le Snap File Reader configuré, l'étape suivante consiste à sélectionner le Snap Parser approprié pour traiter les données du fichier :
- Fichiers CSV : utilisez le Snap CSV Parser pour lire et analyser les fichiers CSV (valeurs séparées par des virgules). Ce Snap prend en charge divers délimiteurs et lignes d'en-tête, ce qui permet un mappage direct des données CSV vers les processus en aval.
- Fichiers JSON : le Snap JSON Parser est idéal pour analyser les structures JSON plates et imbriquées, et les convertir au format Document de SnapLogic en vue d'un traitement ultérieur.
- Fichiers XML : le composant XML Parser Snap gère efficacement les données XML et prend en charge l'analyse syntaxique de structures XML complexes, y compris les attributs et les éléments imbriqués.
- Fichiers HTML : utilisez le composant HTML Parser Snap pour extraire des données à partir de documents HTML, avec prise en charge des sélecteurs XPath ou CSS afin d'identifier avec précision des éléments spécifiques dans le code HTML.
- Fichiers PDF : le Snap PDF Parser est conçu pour convertir les fichiers PDF en un format structuré tel que JSON, ce qui permet de les manipuler davantage dans SnapLogic.
Exemple de lecture d'un fichier dans Snaplogic
Lecture d'un fichier CSV
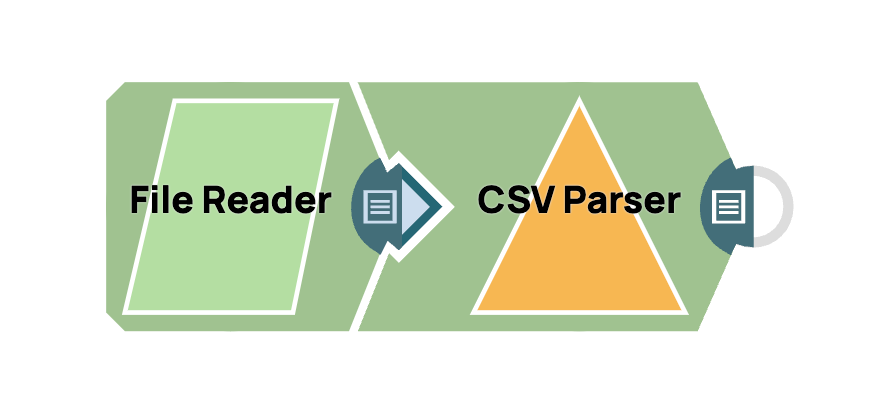
- Ajouter le Snap File Reader: glissez-déposez le Snap « File Reader » dans l'espace de travail du concepteur.
- Configurer le Snap Lecteur de fichiers: Cliquez sur le Snap « Lecteur de fichiers » pour accéder à son panneau de configuration.
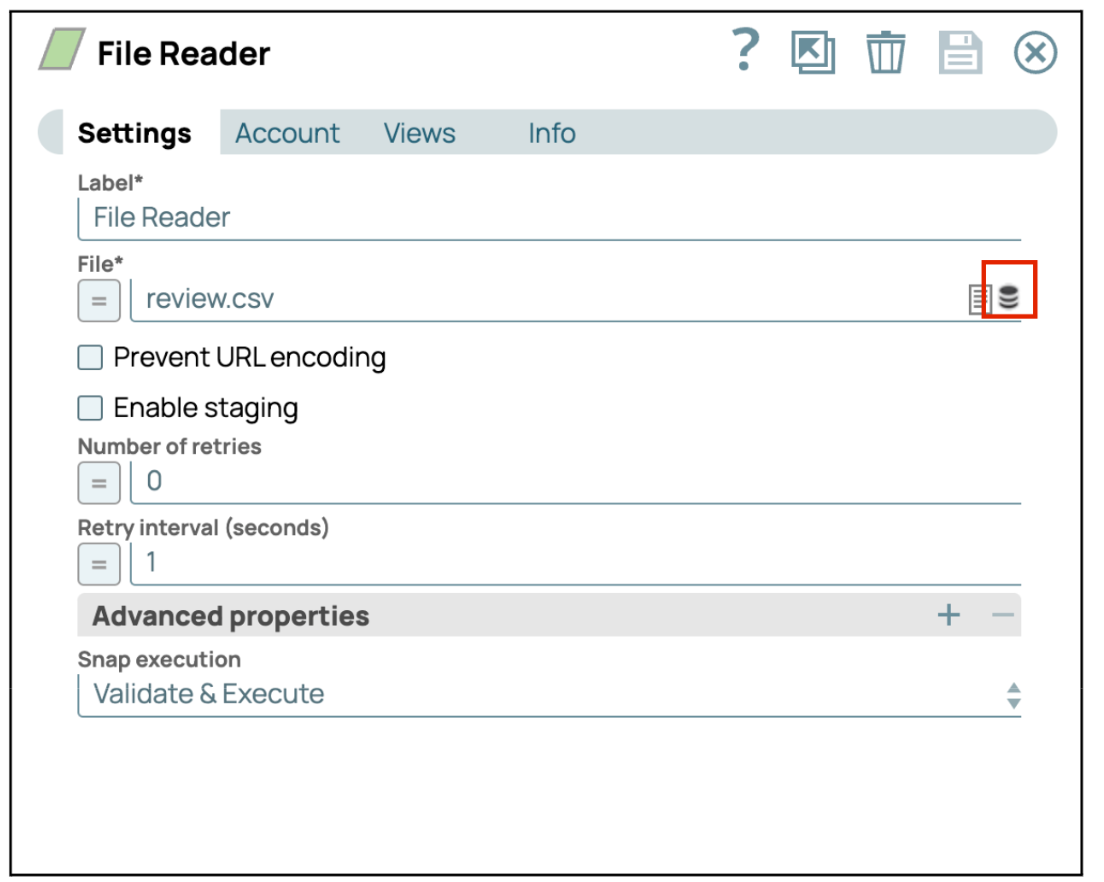
- Sélectionner ou télécharger un fichierDans les paramètres du fichier, cliquez sur l'icône du dossier pour télécharger un nouveau fichier ou sélectionner un fichier existant dans le répertoire.
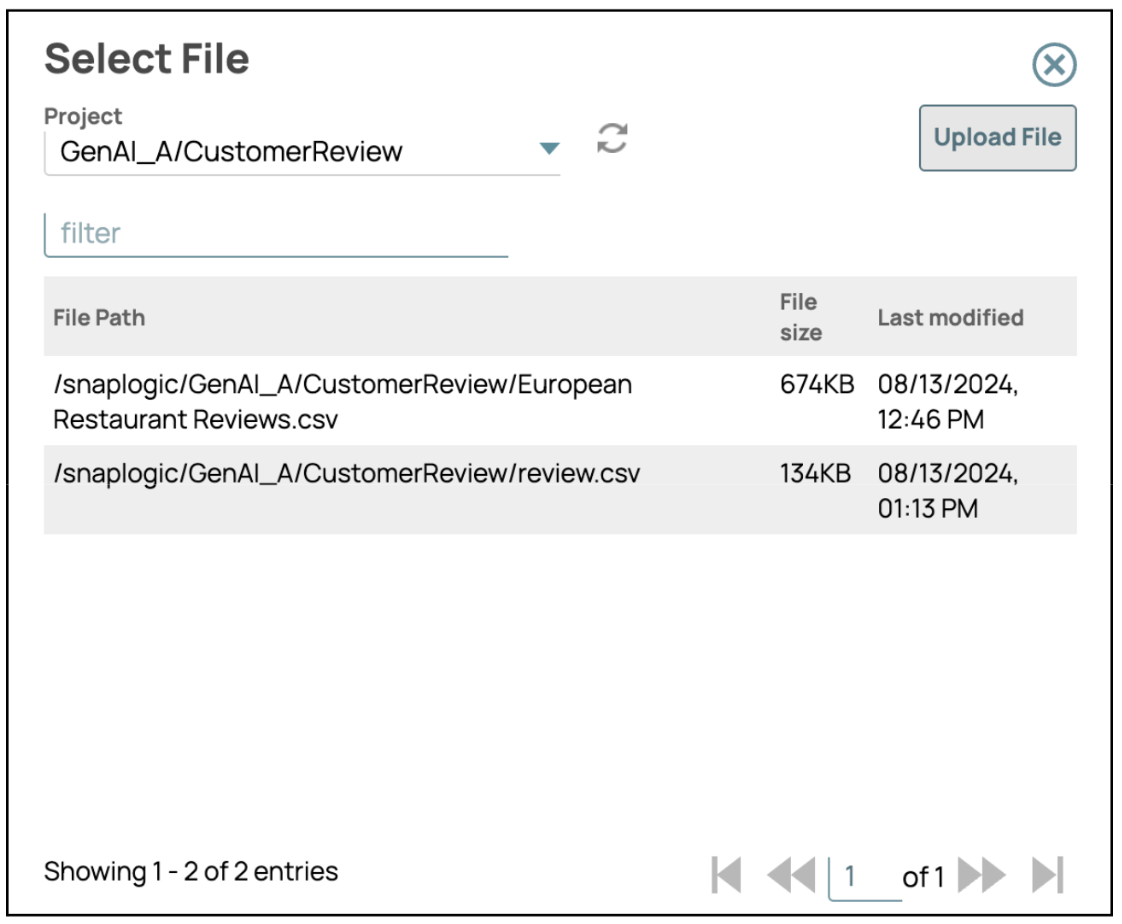
- Enregistrer la configuration: après avoir sélectionné ou téléchargé le fichier souhaité, cliquez sur « Enregistrer », puis fermez le panneau des paramètres.
- Ajoutez le Snap CSV Parser: glissez-déposez le Snap « CSV Parser » dans l'espace de travail, en le positionnant après le File Reader. Les paramètres par défaut du CSV Parser sont généralement suffisants pour la plupart des cas d'utilisation.
- Valider ou exécuter le pipeline: valider ou exécuter le pipeline pour traiter et lire le contenu du fichier CSV.
Lecture de contenu HTML avec File Reader
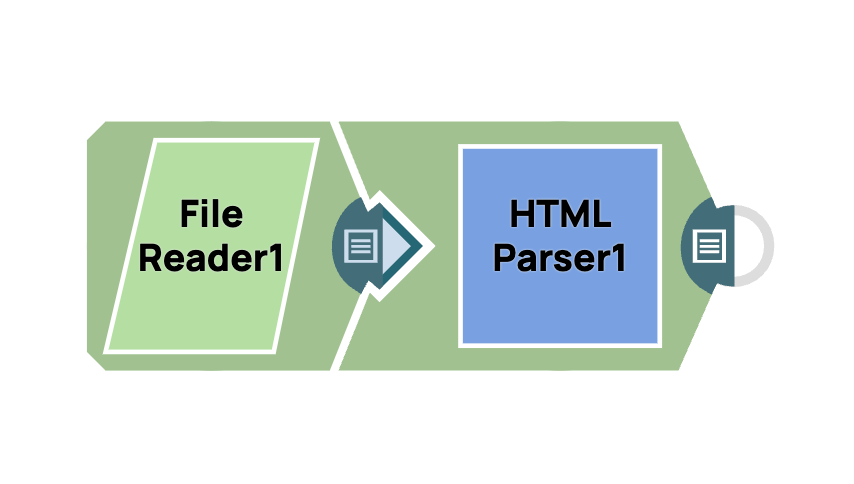
- Ajouter le Snap File Reader: glissez-déposez le Snap « File Reader » dans l'espace de travail du concepteur.
- Configurer le Snap Lecteur de fichiers: Cliquez sur le Snap « File Reader » pour accéder à son panneau de paramètres. Ensuite, entrez l'URL à laquelle vous souhaitez vous connecter dans les paramètres.
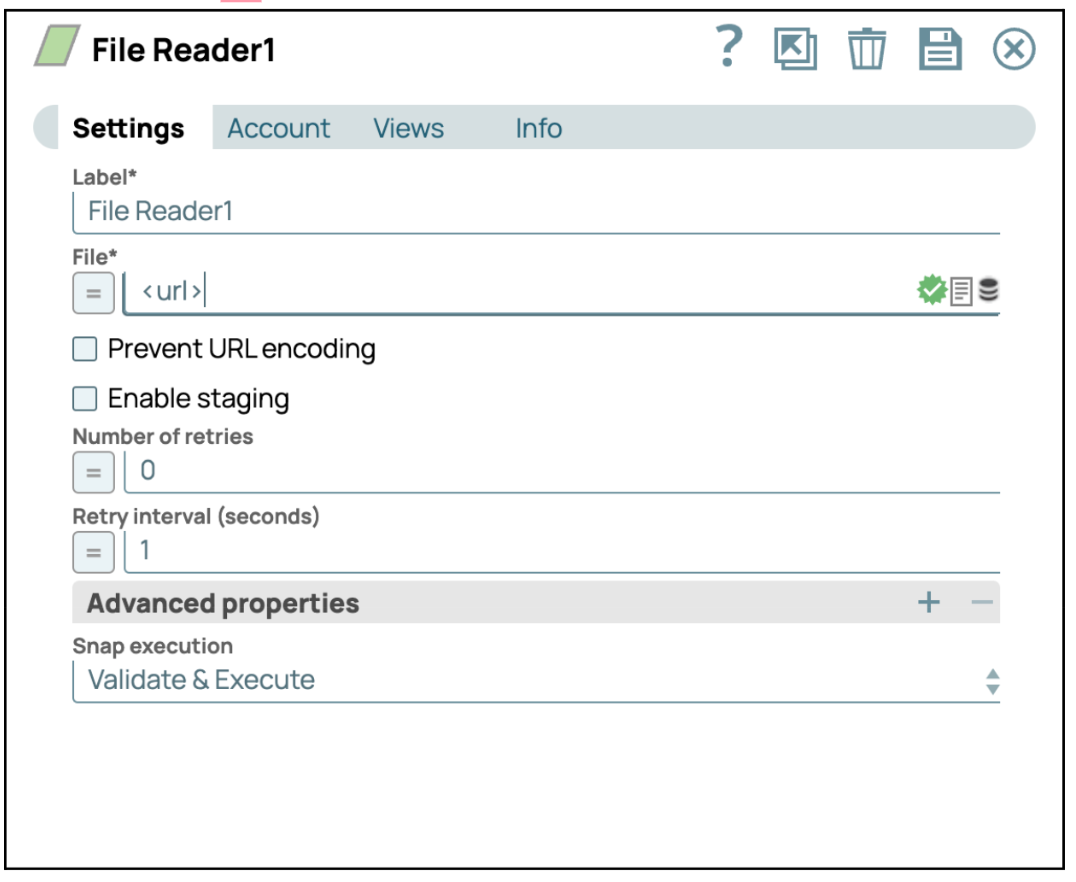
- Enregistrer la configuration: cliquez sur « Enregistrer » et fermez les paramètres.
- Ajoutez le module HTML Parser: faites glisser le module « HTML Parser » vers le Designer, connectez-le au module File Reader et conservez la configuration par défaut.
- Configurer le Snap HTML Parser: Ouvrez les paramètres du parseur HTML et accédez à l'onglet « Vues ». Choisissez d'afficher le résultat sous forme de document ou de fichier binaire.
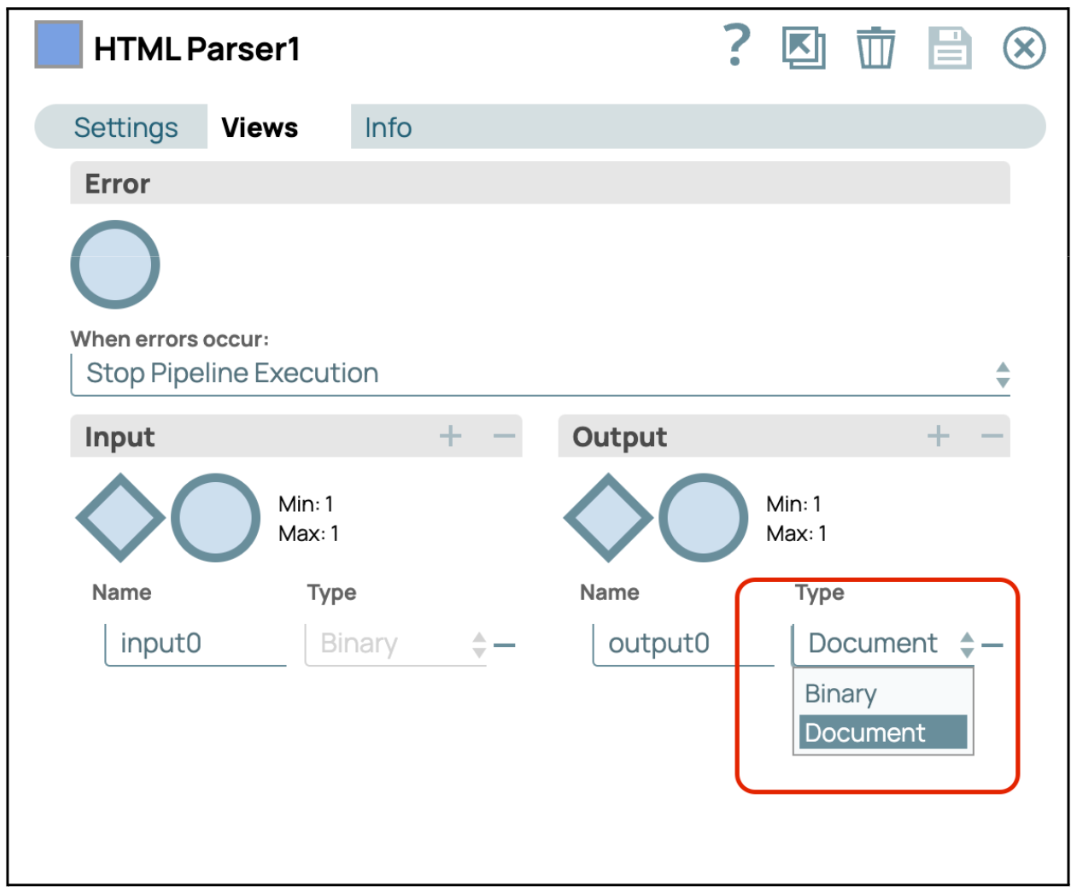
- Valider ou exécuter le pipeline: validez ou exécutez le pipeline pour récupérer le contenu textuel de l'URL fournie.
Lecture de contenu HTML avec un client HTTP
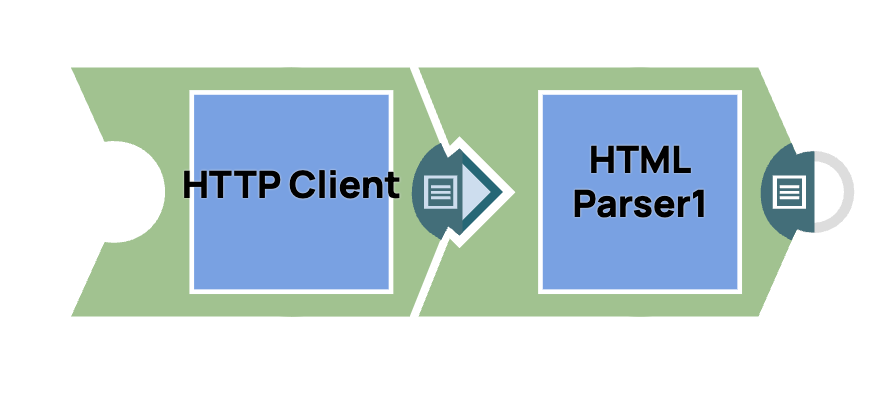
- Ajouter le Snap HTTP Client: glissez-déposez le Snap « HTTP Client » dans l'espace de travail du concepteur.
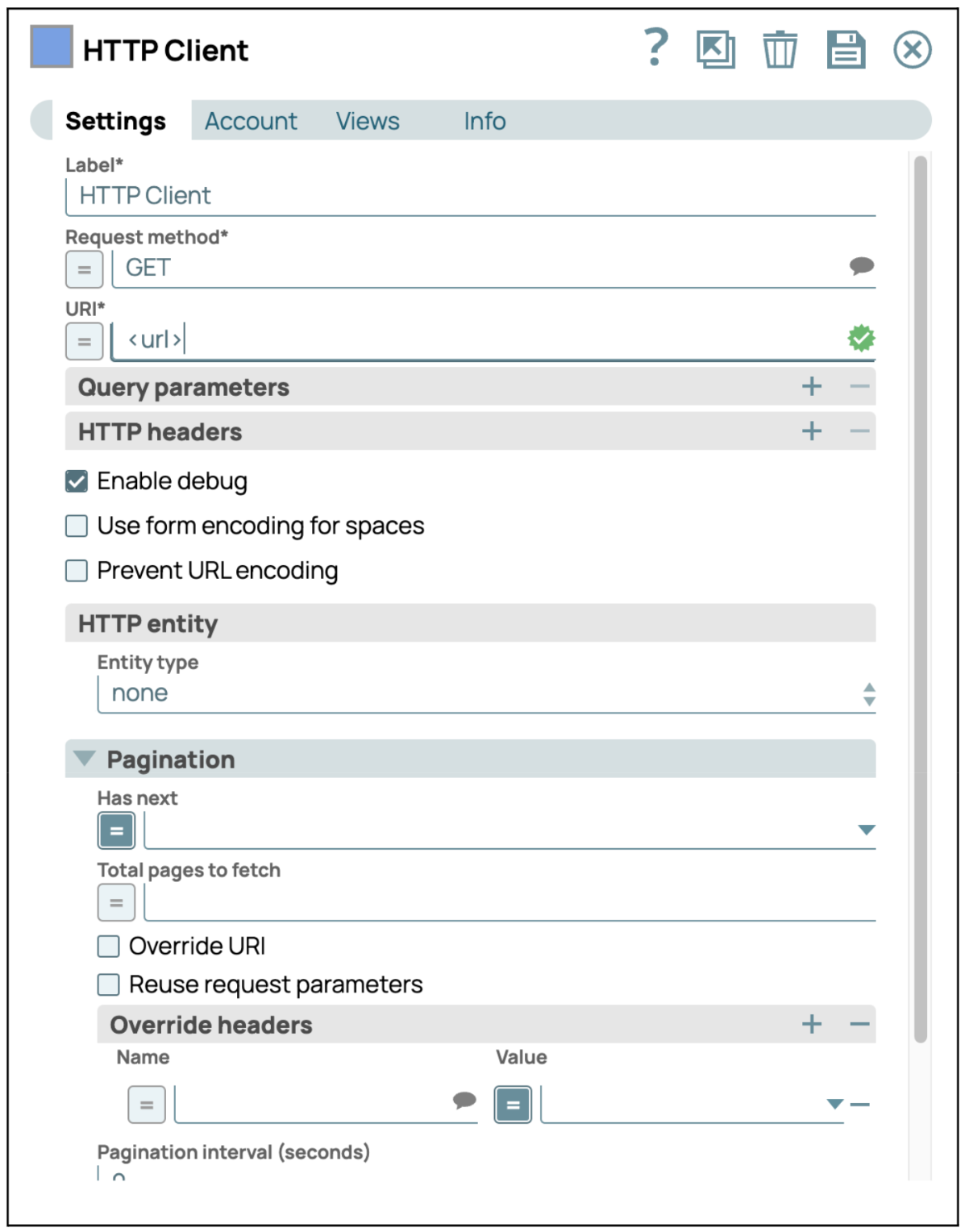
- Configurer le client HTTP Snap: Cliquez sur le Snap « HTTP Client » pour accéder à son panneau de configuration. Entrez ensuite l'URL à laquelle vous souhaitez vous connecter dans les paramètres. Le Snap HTTP Client permet à l'utilisateur d'effectuer des appels HTML complexes avec diverses configurations. Les utilisateurs peuvent sélectionner « Request Methods » (Méthodes de requête) ou fournir le mécanisme « Pagination » (Pagination) pour obtenir un contenu continu.
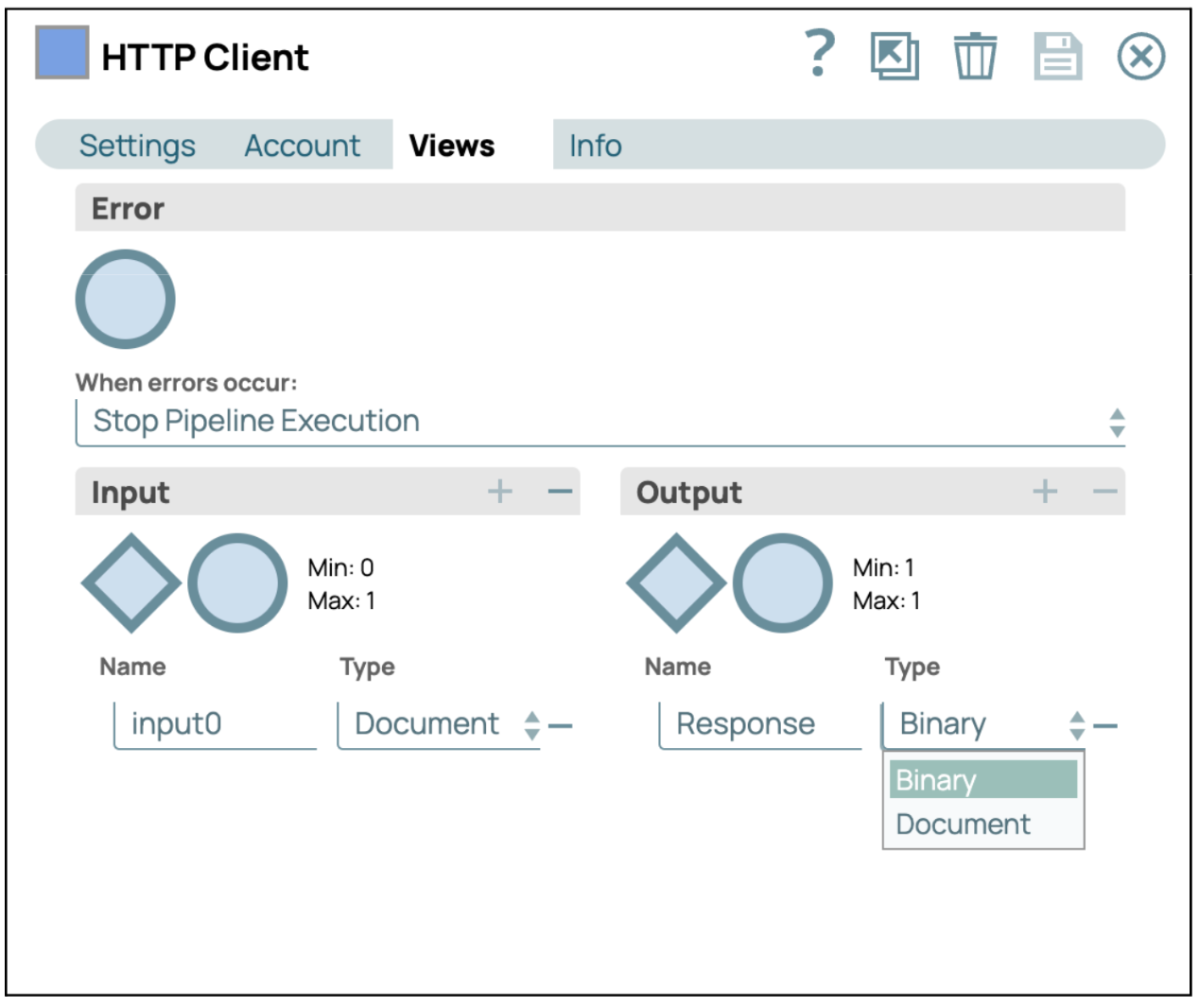
- Configurer les vues instantanées du client HTTP : Cliquez sur l'onglet « Vues » et sélectionnez « Binaire » comme format de sortie. Enregistrez ensuite les paramètres et fermez la fenêtre.
- Ajoutez le composant HTML Parser: faites glisser le composant « HTML Parser » vers le Designer, puis connectez-le au composant File Reader et conservez la configuration par défaut.
- Valider ou exécuter le pipeline: validez ou exécutez le pipeline pour récupérer le contenu textuel de l'URL fournie.
- Afficher la sortie : La sortie affichera le contenu au format texte.
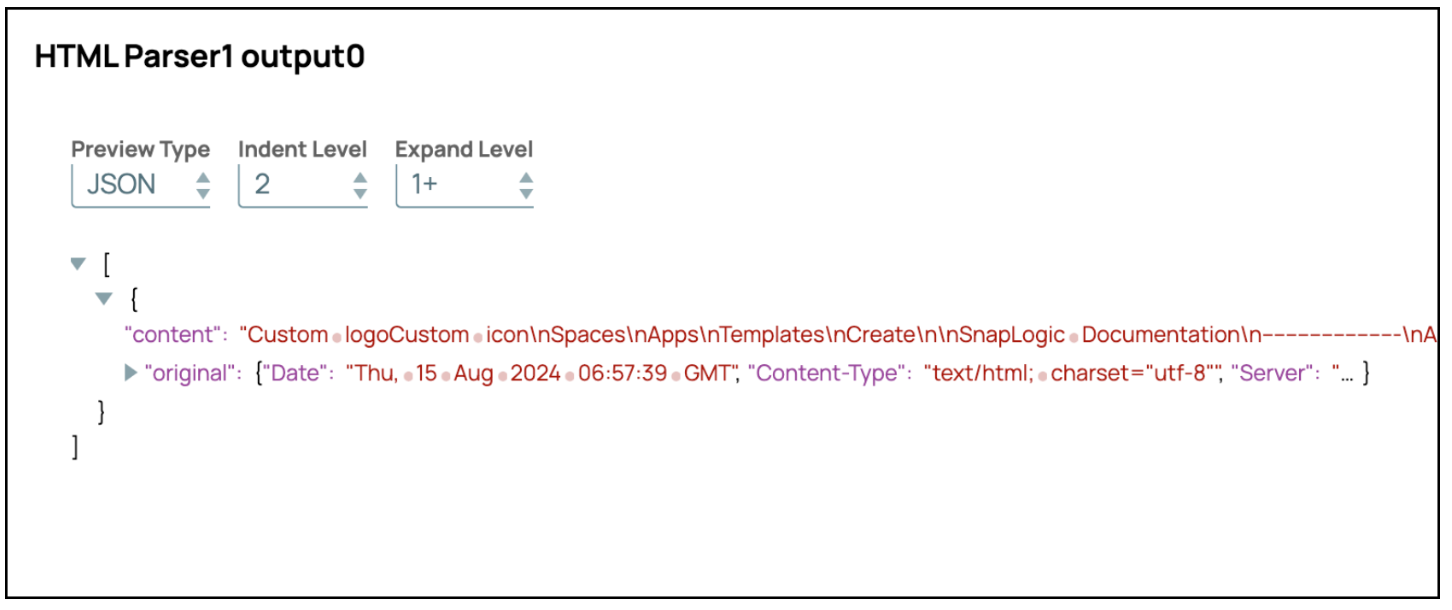
Lecture d'un fichier PDF
Pour lire et extraire efficacement des informations d'un fichier PDF, les utilisateurs doivent d'abord comprendre la nature du contenu du fichier. Les fichiers PDF peuvent généralement être classés en deux catégories : ceux qui contiennent du contenu textuel et ceux qui contiennent du contenu image.
Pour les fichiers PDF contenant du texte, les utilisateurs peuvent utiliser un analyseur PDF standard, conçu pour extraire et restituer les informations textuelles dans un format lisible. Ces analyseurs sont largement disponibles et permettent de convertir efficacement le texte intégré dans un document PDF en un format texte pouvant être traité ou analysé ultérieurement.
Cependant, si le PDF contient du contenu sous forme d'images, tel que des documents numérisés ou des images de texte, une approche différente est nécessaire. Dans ce cas, il faut recourir à la technologie de reconnaissance optique de caractères (OCR). Les services OCR sont des outils spécialisés qui analysent les images contenues dans le PDF et convertissent les représentations visuelles du texte en texte lisible par machine. Ce processus est essentiel pour rendre le contenu accessible et modifiable, en particulier lorsqu'il s'agit de documents numérisés ou d'autres fichiers contenant beaucoup d'images.
En comprenant ces distinctions et en choisissant l'outil approprié au type de contenu d'un fichier PDF, les utilisateurs peuvent extraire efficacement les informations nécessaires, garantissant ainsi la précision et l'efficacité de leur flux de travail.
Lecture d'un fichier PDF avec PDF Parser snap

- Ajouter le Snap File Reader: glissez-déposez le Snap « File Reader » dans l'espace de travail du concepteur.
- Configurer le Snap Lecteur de fichiers: Cliquez sur le Snap « File Reader » pour accéder à son panneau de paramètres. Sélectionnez ou téléchargez ensuite le fichier PDF que vous souhaitez lire.
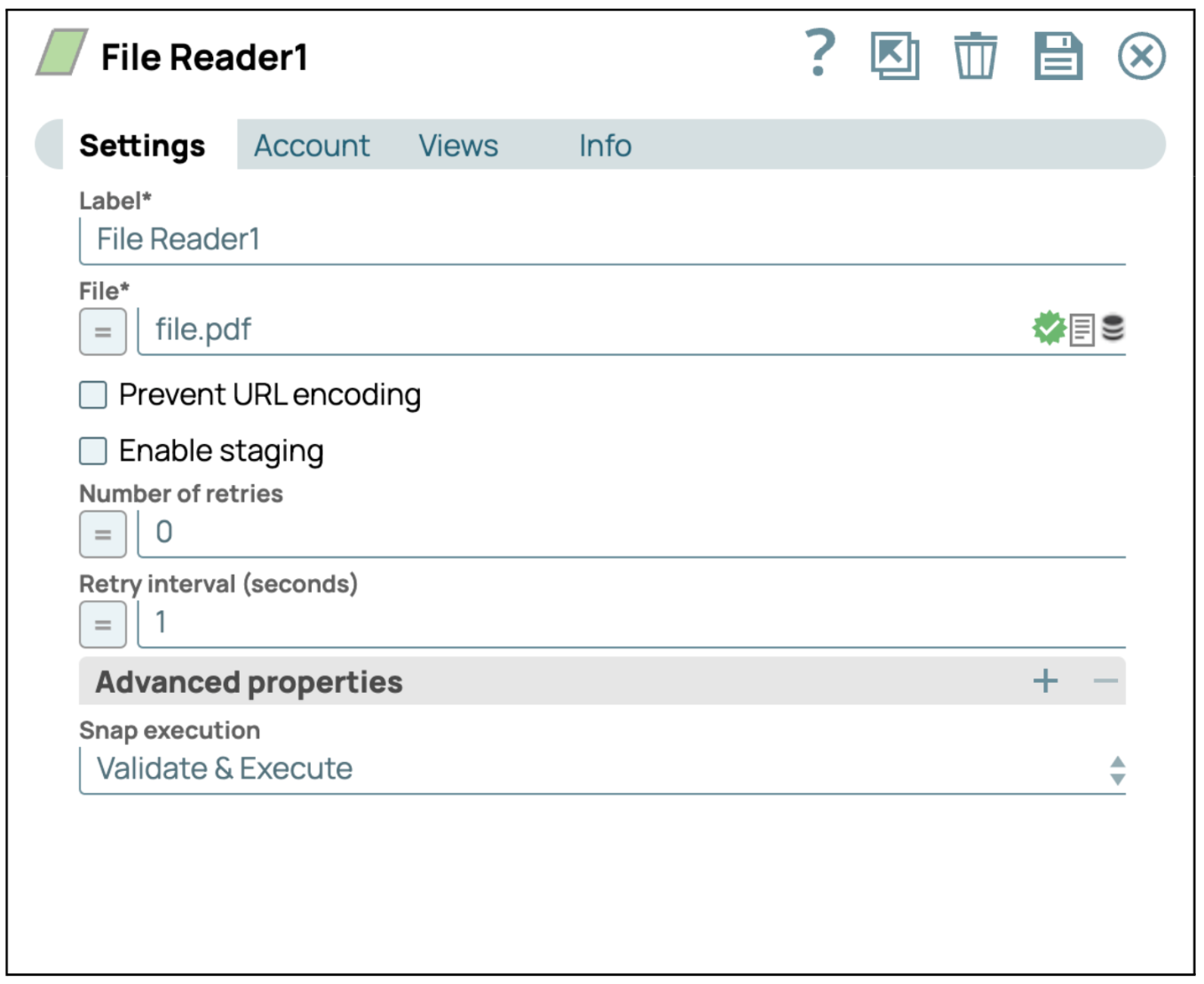
- Enregistrer la configuration: cliquez sur « Enregistrer » et fermez les paramètres.
- Ajouter le module complémentaire PDF Parser : le module complémentaire PDF Parser permet d'analyser le fichier PDF et de le convertir en texte.
- Configurer le composant PDF Parser Snap: Les utilisateurs peuvent sélectionner un « type d'analyseur » approprié pour analyser le fichier PDF. Dans ce cas, nous sélectionnons « Extracteur de texte » afin de pouvoir extraire tout le texte du fichier PDF.
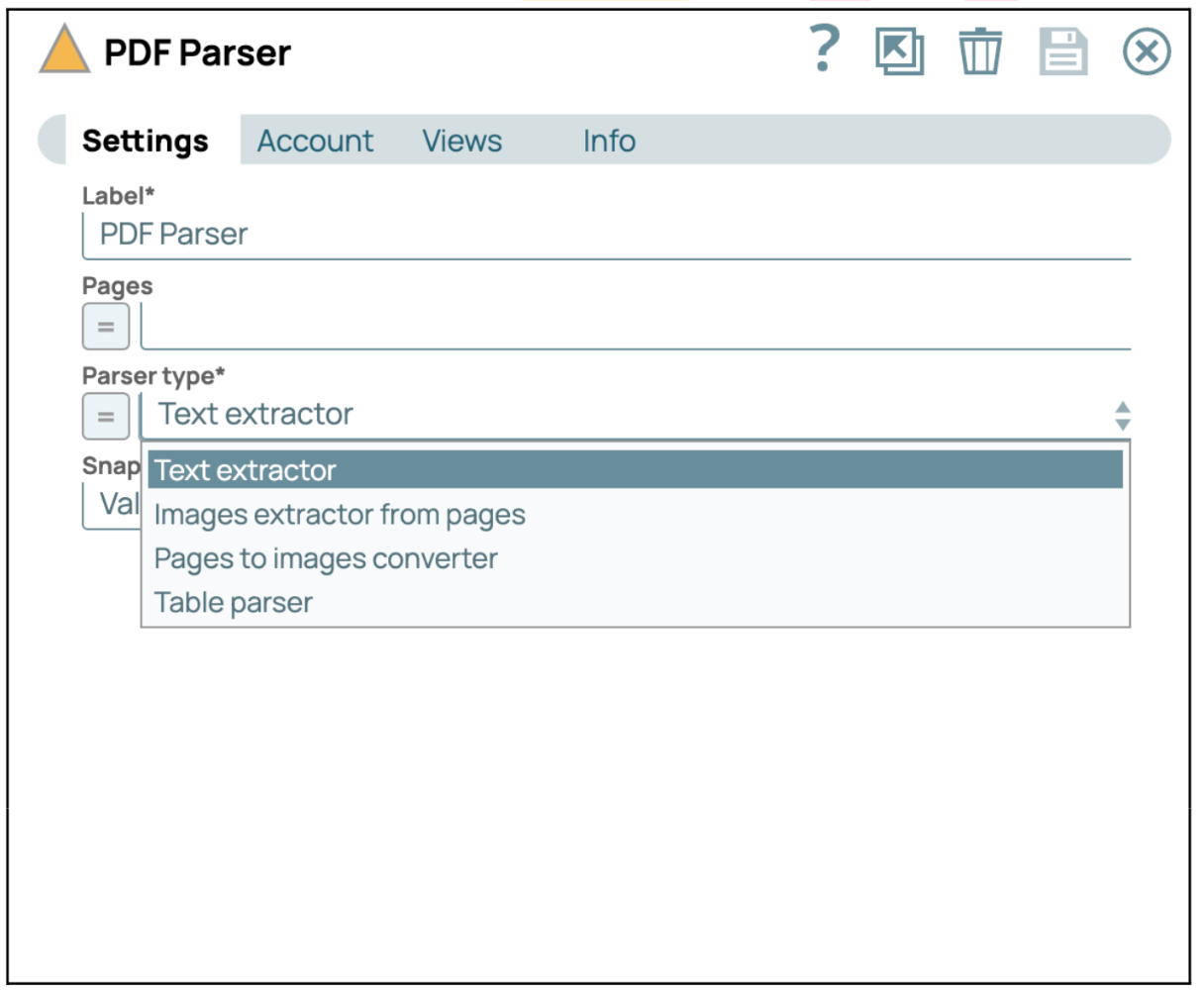
- Valider ou exécuter le pipeline: Validez ou exécutez le pipeline pour récupérer le contenu textuel du fichier PDF donné. La réponse contient le texte extrait du fichier PDF.

Lecture de fichiers PDF non structurés

Condition préalable : les utilisateurs doivent disposer d'une clé API non structurée pour accéder au service non structuré ou déployer l'instance non structurée localement pour utiliser l'API non structurée.
Ajouter le Snap File Reader: glissez-déposez le Snap « File Reader » dans l'espace de travail du concepteur.
Configurer le Snap Lecteur de fichiers: cliquez sur le Snap « Lecteur de fichiers » pour accéder à son panneau de configuration. Sélectionnez ou téléchargez ensuite le fichier PDF que vous souhaitez lire.
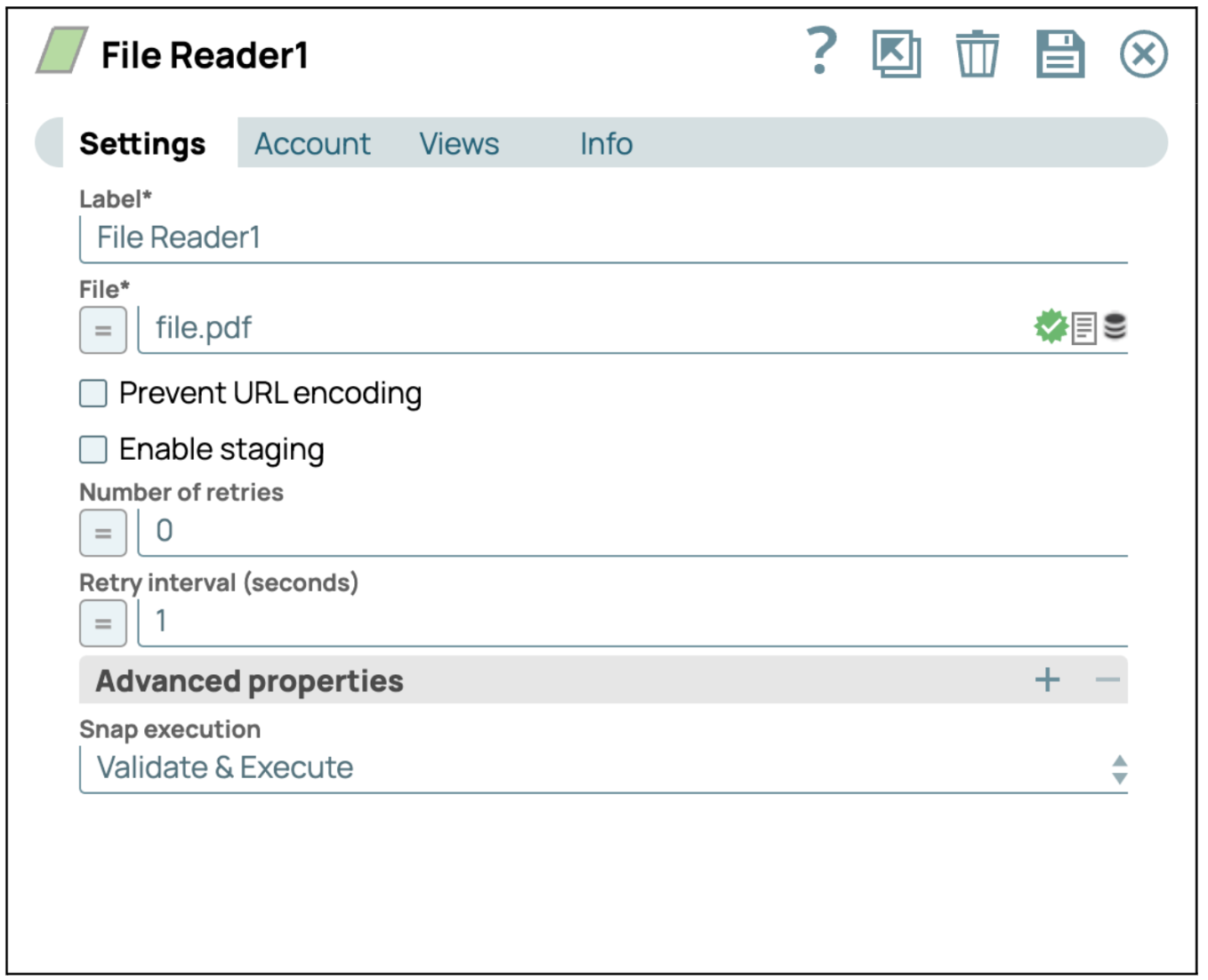
- Enregistrer la configuration: cliquez sur « Enregistrer » et fermez les paramètres.
- Ajouter le Snap API de partition : L'API de partition snap utilise l'API de partition non structurée pour analyser un fichier PDF.
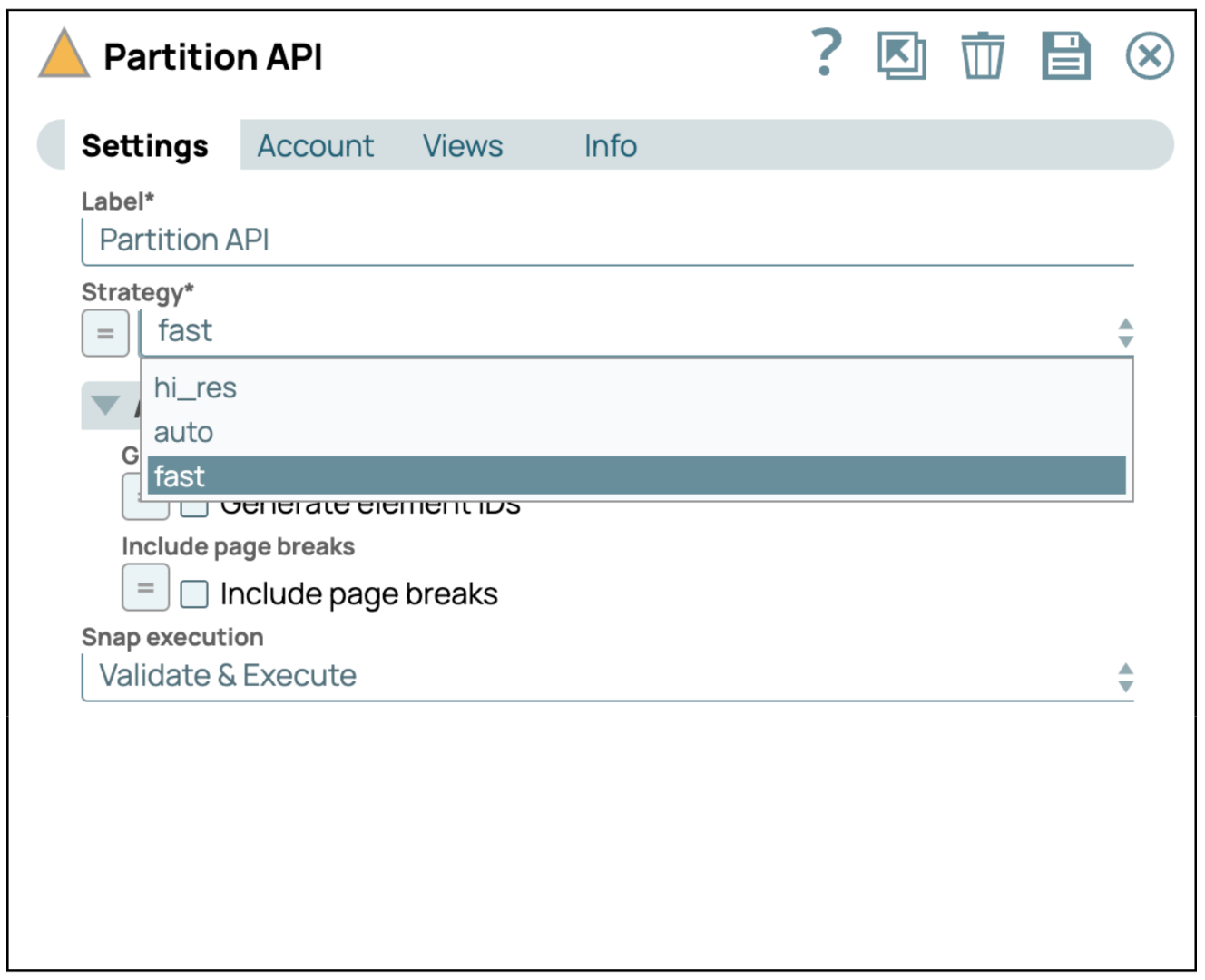
- Configurer l'API Snap de partition: les utilisateurs peuvent sélectionner une stratégie pour analyser un fichier PDF. Dans ce cas, nous utilisons la stratégie « rapide » pour analyser uniquement le texte et ne pas inclure les images et les tableaux. Si vous sélectionnez hi_res, l'image et le tableau seront analysés en base64.
- Valider ou exécuter le pipeline: Validez ou exécutez le pipeline pour récupérer le contenu textuel du fichier PDF donné. La réponse contient également le type de contenu analysé à partir du PDF. Les utilisateurs peuvent donc utiliser l'attribut « type » pour poursuivre le traitement. Par exemple, ils peuvent traiter le titre et le contenu séparément du pied de page.

Lecture d'un fichier PDF avec le service Adobe
Les utilisateurs peuvent exploiter l'API Adobe pour les tâches d'analyse syntaxique des fichiers PDF. SnapLogic propose le module Adobe Extract Snap pour extraire du texte à partir de documents PDF, ainsi que le module Adobe OCR Snap pour traiter le contenu PDF basé sur des images. Lorsque vous traitez des fichiers PDF contenant du contenu basé sur des images, le module Adobe OCR Snap est l'outil approprié, car il permet d'extraire avec précision le texte des images contenues dans le document.
Lecture d'un fichier PDF avec Adobe OCR
Condition préalable : les utilisateurs doivent disposer d'une clé Adobe pour accéder au service Adobe OCR avant d'utiliser le snap Adobe OCR.
- Ajouter le Snap File Reader: glissez-déposez le Snap « File Reader » dans l'espace de travail du concepteur.
- Configurer le Snap Lecteur de fichiers: Cliquez sur le Snap « File Reader » pour accéder à son panneau de paramètres. Sélectionnez ou téléchargez ensuite le fichier PDF que vous souhaitez lire.
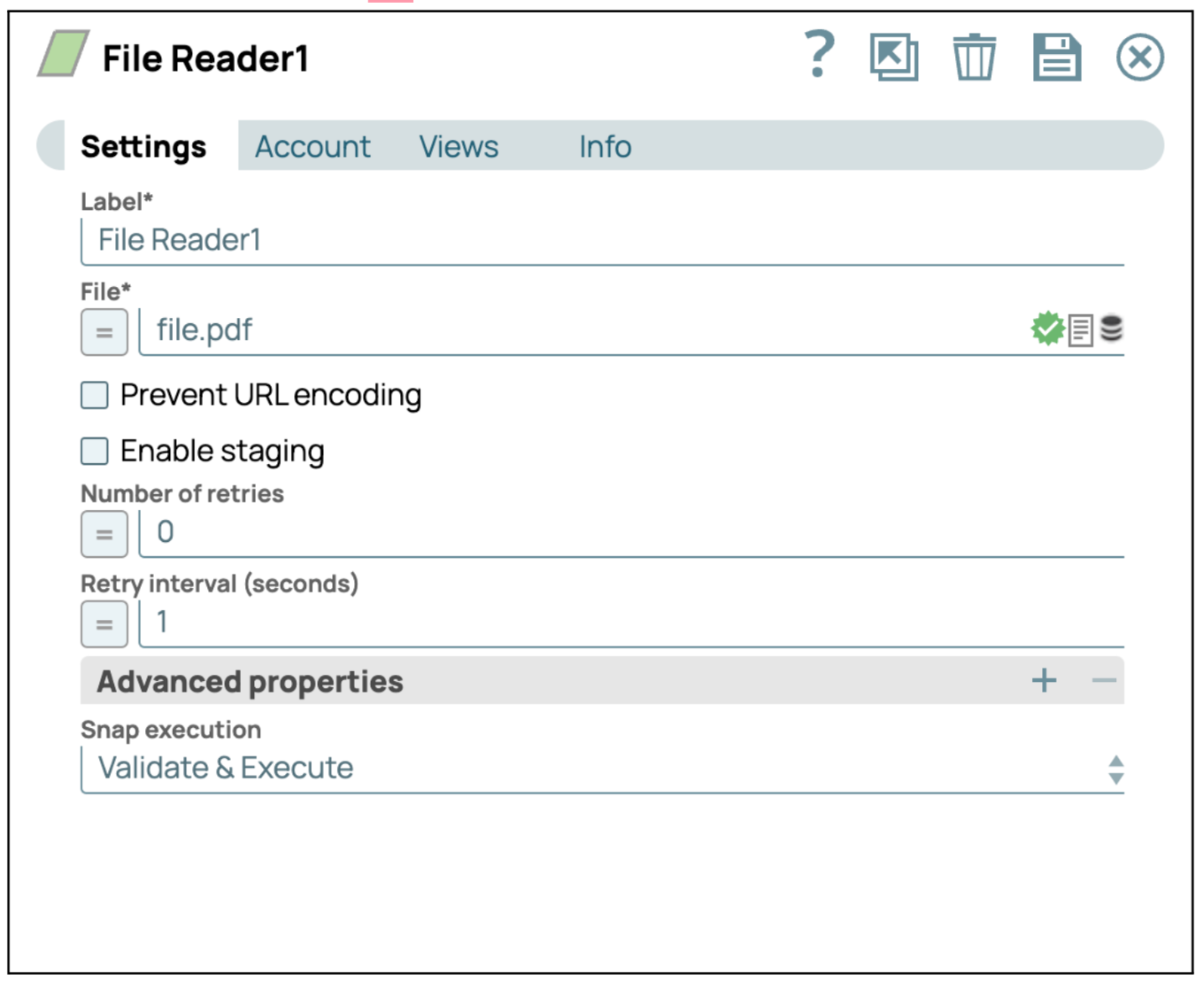
- Enregistrer la configuration: cliquez sur « Enregistrer » et fermez les paramètres.
- Ajouter le module Adobe OCR Snap: le module Adobe OCR Snap utilise l'API Adobe pour analyser efficacement les fichiers PDF contenant des images. Les utilisateurs peuvent s'appuyer sur les paramètres par défaut fournis dans le module Adobe OCR Snap pour extraire avec précision le texte des images intégrées dans le PDF.
- Valider ou exécuter le pipeline: validez ou exécutez le pipeline pour récupérer le contenu textuel du fichier PDF donné. La réponse contient un contenu binaire qui contient les informations extraites.







