






Questa guida fornisce un approccio dettagliato all'utilizzo di SnapLogic per l'estrazione di dati da formati quali PDF, CSV, JSON e HTML. Che tu sia un nuovo utente di SnapLogic o desideri perfezionare i tuoi processi di estrazione dei dati, questa guida ti aiuterà a creare e gestire pipeline efficaci.
Formati dei dati in SnapLogic
SnapLogic è in grado di leggere dati provenienti da un'ampia gamma di fonti e di convertirli in due formati principali:
- Formato del documento:
- Un documento in SnapLogic è un formato simile a JSON utilizzato per l'elaborazione interna dei dati. Questo formato consente agli utenti di interagire con gli attributi dei dati in modo simile a JSON. Supporta anche le funzioni interne di SnapLogic, come l'elaborazione del testo, consentendo agli utenti di applicare espressioni per la manipolazione e la trasformazione dei dati. Queste trasformazioni possono essere eseguite prima che i dati vengano inviati ai connettori a valle, garantendo che i dati siano strutturati e formattati in modo appropriato per la successiva elaborazione.
- Formato binario:
- Il formato binario in SnapLogic viene utilizzato per gestire flussi di dati grezzi, come immagini, PDF o qualsiasi altro tipo di file non conforme ai formati di dati strutturati. Questo formato è particolarmente utile quando si tratta di dati non testuali o quando i dati devono essere trasmessi attraverso la pipeline senza alterazioni. SnapLogic può convertire i dati binari in altri formati quando necessario, consentendo l'elaborazione, l'archiviazione o la trasformazione prima della trasmissione ai componenti a valle. Ciò garantisce flessibilità ed efficienza nella gestione di vari tipi di dati all'interno della pipeline.
Estrazione dei dati dai file in SnapLogic
SnapLogic offre solide funzionalità per l'estrazione di dati da vari tipi di file, rendendolo uno strumento versatile nei flussi di lavoro di integrazione dei dati. Per facilitare questo processo, SnapLogic fornisce SnapLogic File System (SLFS), una soluzione di archiviazione integrata che consente agli utenti di caricare e gestire i file direttamente nell'ambiente SnapLogic. Tuttavia, ci sono alcune considerazioni importanti e best practice da tenere a mente quando si utilizza SLFS per l'estrazione dei dati.
Utilizzo del file system SnapLogic (SLFS)
Il sistema di file SnapLogic (SLFS) consente agli utenti di archiviare e accedere ai file per l'elaborazione all'interno delle loro pipeline. Per estrarre dati da un file utilizzando SnapLogic, gli utenti devono prima caricare il file su SLFS. Una volta caricato, il file può essere consultato ed elaborato da vari Snap progettati per leggere e manipolare il contenuto dei file.
Tuttavia, SLFS ha una limitazione delle dimensioni dei file, consentendo agli utenti di caricare file fino a un massimo di 100 MB per file. Questa limitazione può rappresentare una sfida quando si ha a che fare con set di dati o file di grandi dimensioni. Se il file supera questo limite di dimensione, gli utenti dovrebbero dividere il contenuto in più file più piccoli prima di caricarli su SLFS. Sebbene questo approccio possa funzionare per dati più piccoli o segmentati, in genere non è consigliabile per gestire attività di elaborazione dati su larga scala.
Migliori pratiche per la gestione di file di grandi dimensioni
Per elaborare file di dimensioni superiori a 100 MB, è consigliabile utilizzare sistemi di archiviazione esterni anziché affidarsi a SLFS. I file system esterni offrono maggiore flessibilità e scalabilità, consentendo di gestire file di dimensioni notevolmente maggiori senza la necessità di segmentazione manuale. SnapLogic si integra perfettamente con varie soluzioni di archiviazione esterne, consentendo un'estrazione e un'elaborazione efficiente dei dati.
- Server SFTP: gli utenti possono utilizzare i server SFTP (Secure File Transfer Protocol) per archiviare e accedere a file di grandi dimensioni. SnapLogic supporta l'integrazione SFTP, consentendo di leggere ed elaborare in modo sicuro i file direttamente dal server all'interno delle pipeline.
- Servizi di archiviazione oggetti (ad esempio Amazon S3): i servizi di archiviazione oggetti Cloud come Amazon S3 offrono una capacità di archiviazione praticamente illimitata, rendendoli ideali per la gestione di grandi set di dati. Il supporto nativo di SnapLogic per S3 consente agli utenti di leggere, scrivere e gestire i file archiviati nei bucket S3, garantendo un'elaborazione dei dati fluida senza i vincoli di SLFS.
Integrando SnapLogic con queste soluzioni di archiviazione esterne, gli utenti possono gestire in modo efficiente file di grandi dimensioni, semplificare i flussi di lavoro di estrazione dei dati e mantenere prestazioni ottimali in tutte le loro pipeline. Questo approccio non solo supera i limiti di SLFS, ma è anche in linea con le best practice per un'elaborazione dei dati scalabile e affidabile.
Lettura dei dati dei file e processo in SnapLogic
In questa sezione approfondiremo il processo di lettura dei dati da vari formati di file utilizzando SnapLogic. Questa guida illustra i passaggi chiave, le opzioni di configurazione e le best practice per garantire un'estrazione dei dati efficiente ed efficace. Per leggere i dati da un file utilizzando SnapLogic, è possibile seguire questi due passaggi essenziali:
1. Configurazione dello Snap File Reader
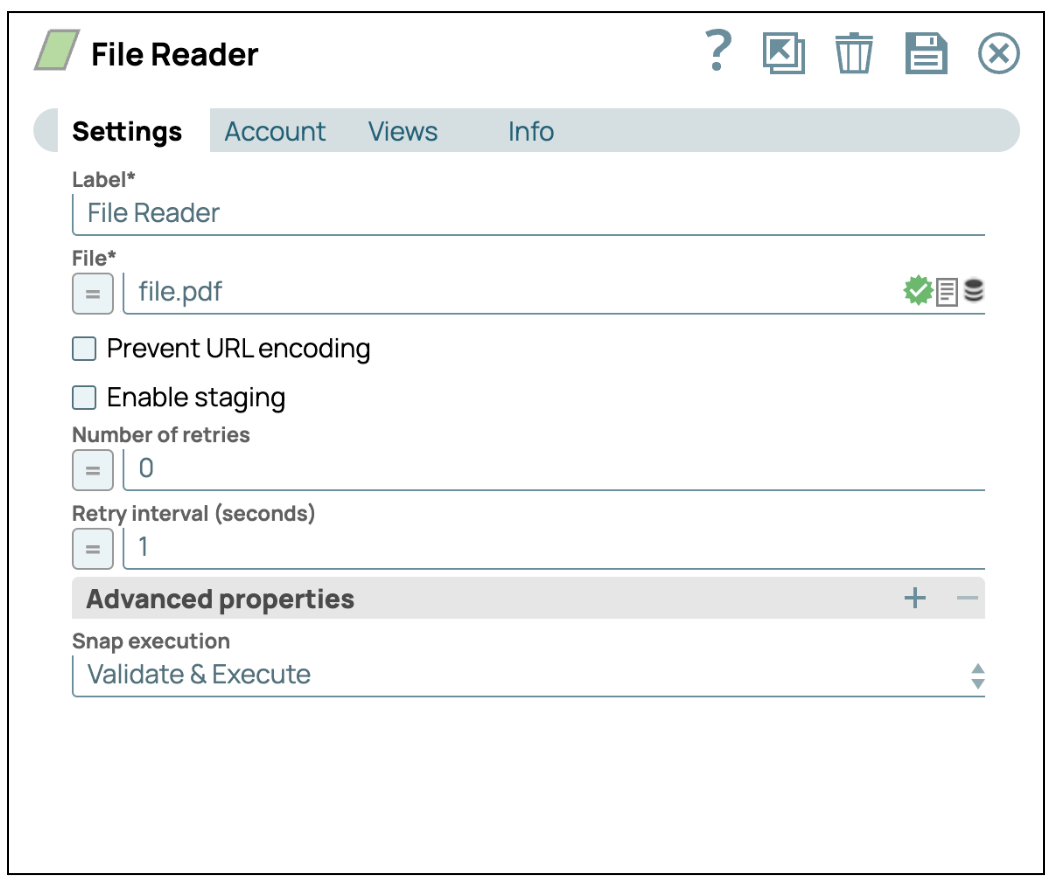
La configurazione dello Snap File Reader è fondamentale per impostare una pipeline SnapLogic in grado di accedere in modo accurato ed efficiente ai dati provenienti da vari file system e soluzioni di archiviazione. Questo Snap funge da gateway per l'inserimento dei dati nella pipeline e la sua corretta configurazione è fondamentale per un'estrazione dei dati senza interruzioni.
Considerazioni chiave:
- Identificazione della posizione del file:
SnapLogic supporta un'ampia gamma di protocolli di archiviazione dei file, consentendo l'accesso ai file archiviati sia in locale che in ambienti remoti.- SLFS (SnapLogic File System): ideale per file di piccole dimensioni archiviati temporaneamente in SnapLogic.
- Amazon S3: un servizio cloud scalabile gestito al meglio con S3 File Reader Snap per prestazioni ottimizzate e facilità d'uso.
- Server SFTP: per trasferimenti sicuri di file su una rete tramite SFTP.
- HTTP/HTTPS: consente l'accesso diretto ai file ospitati sui server web.
- Azure Blob Storage: ottimizzato per la gestione di grandi quantità di dati non strutturati nel cloud.
- Selezione del protocollo appropriato:
La scelta del protocollo corretto garantisce un accesso efficiente ai file in base alla posizione di archiviazione. Ogni protocollo richiede configurazioni specifiche per consentire un recupero dei dati sicuro e accurato. Di seguito sono riportate le linee guida per la configurazione dei vari protocolli di archiviazione.- SLFS: specificare il percorso del file relativo alla radice SLFS.
- Amazon S3: si consiglia di utilizzare lo Snap File Reader S3 per le funzionalità specifiche di S3. Se si utilizza lo Snap File Reader, assicurarsi di fornire il nome corretto del bucket, il percorso del file e le credenziali AWS.
- SFTP: inserisci l'indirizzo del server, il percorso del file e i dettagli di autenticazione (nome utente, password o chiave SSH).
- HTTP/HTTPS: inserisci l'URL completo, inclusi eventuali token di autenticazione necessari.
- Azure Blob Storage: fornire il nome del contenitore, il percorso del blob e le credenziali pertinenti.
- Configurazione del percorso del file:
La corretta formattazione del percorso del file è fondamentale per un accesso corretto ai dati. Ogni protocollo richiede strutture di percorso specifiche.- SLFS: Utilizzare un percorso relativo (ad esempio, /myfiles/data.csv).
- S3: formatta il percorso per i bucket S3 (ad esempio, s3://mybucket/data/myfile.csv) e valuta l'utilizzo dello Snap S3 File Reader per semplificare l'operazione.
- SFTP: fornire il percorso completo relativo alla radice SFTP (ad esempio, /home/user/data/myfile.csv).
- HTTP/HTTPS: utilizzare l'URL completo (ad esempio, https://www.example.com/files/myfile.csv).
- Azure Blob Storage: specificare il percorso del blob all'interno del contenitore.
- Autenticazione e credenziali:
L'accesso sicuro ai sistemi di archiviazione esterni richiede un'autenticazione robusta. A seconda del tipo di archiviazione, vengono utilizzati diversi metodi per garantire l'accesso autorizzato ai dati sensibili. La corretta configurazione di questi metodi è essenziale per mantenere l'integrità e la sicurezza dei dati.
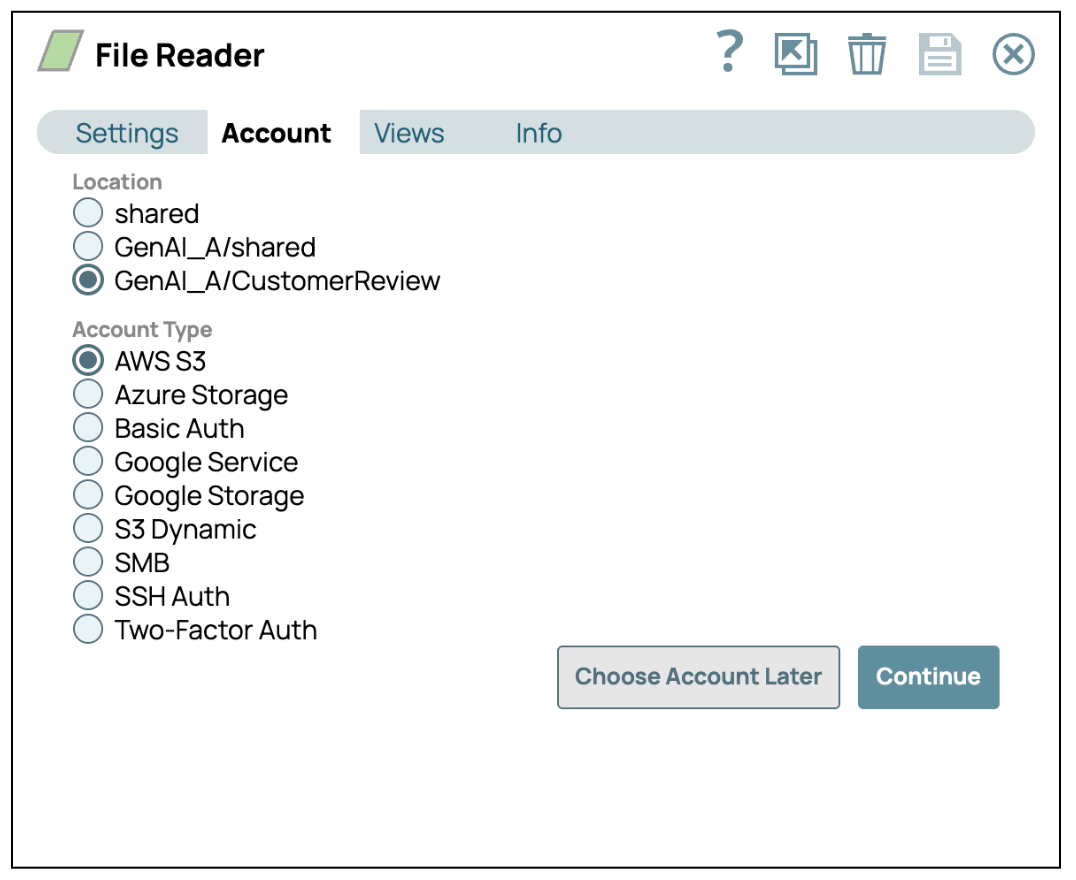
- S3: Utilizza l'ID chiave di accesso AWS e la chiave di accesso segreta o i ruoli IAM per gli ambienti AWS. Lo Snap S3 File Reader semplifica questo processo.
- SFTP: configurare con nome utente/password o chiavi SSH, assicurandosi che sia specificato il file chiave corretto.
- HTTP/HTTPS: inserire le credenziali di autenticazione di base o i token bearer secondo necessità.
- Azure Blob Storage: utilizza token SAS o credenziali AAD a seconda dei tuoi requisiti di sicurezza.
2. Selezione dello snap parser appropriato
Una volta configurato lo Snap File Reader, il passo successivo consiste nel selezionare lo Snap Parser appropriato per l'elaborazione dei dati del file:
- File CSV: utilizza lo Snap CSV Parser per leggere e analizzare i file con valori separati da virgola (CSV). Questo Snap gestisce vari delimitatori e righe di intestazione, consentendo la mappatura diretta dei dati CSV ai processi a valle.
- File JSON: lo Snap JSON Parser è ideale per analizzare strutture JSON sia piatte che nidificate, convertendole nel formato documento di SnapLogic per ulteriori elaborazioni.
- File XML: lo Snap XML Parser gestisce efficacemente i dati XML, supportando l'analisi di strutture XML complesse, inclusi attributi ed elementi nidificati.
- File HTML: utilizza lo Snap HTML Parser per estrarre dati dai documenti HTML, con supporto per selettori XPath o CSS per individuare con precisione elementi specifici all'interno dell'HTML.
- File PDF: lo Snap PDF Parser è progettato per convertire i PDF in un formato strutturato come JSON, consentendo un'ulteriore manipolazione all'interno di SnapLogic.
Esempio di lettura di un file in Snaplogic
Lettura di file CSV
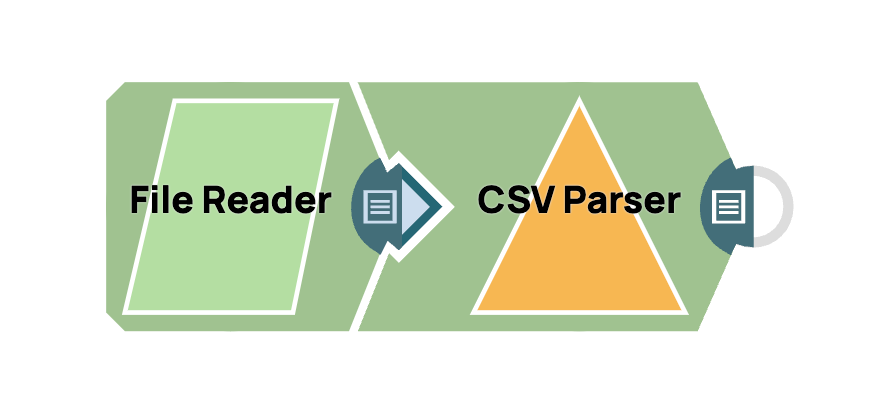
- Aggiungi lo Snap File Reader: trascina e rilascia lo Snap "File Reader" nell'area di lavoro del designer.
- Configurare lo Snap File Reader: Fare clic sullo Snap "File Reader" per accedere al pannello delle impostazioni.
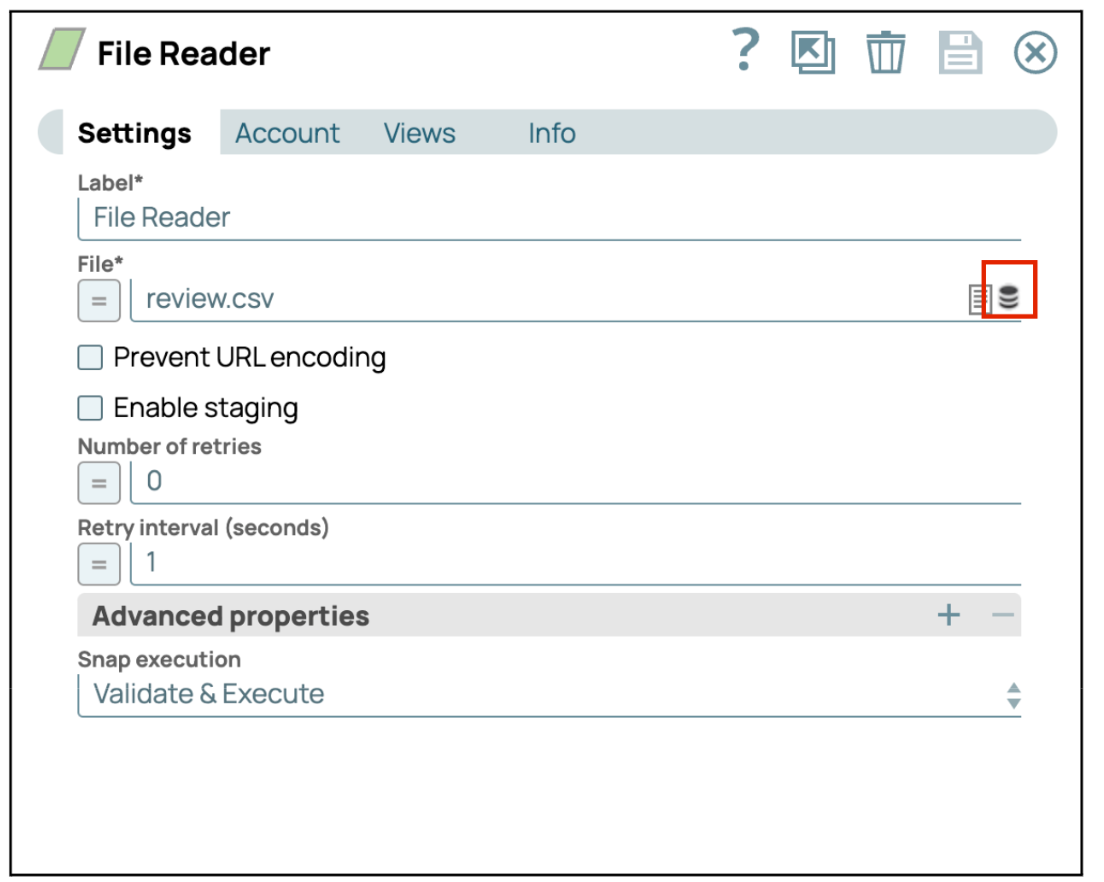
- Seleziona o carica un file: Nelle impostazioni del file, clicca sull'icona della cartella per caricare un nuovo file o selezionarne uno esistente dalla directory.
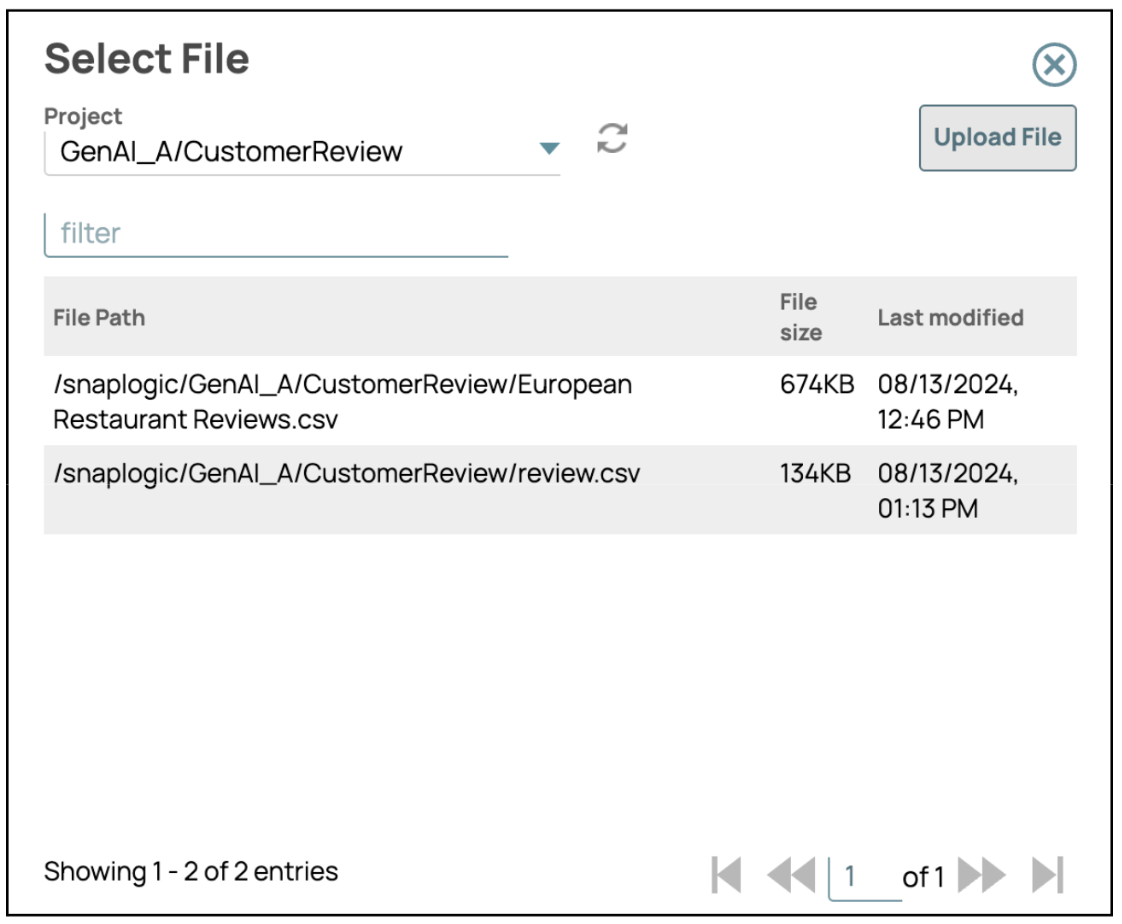
- Salva configurazione: dopo aver selezionato o caricato il file desiderato, clicca su "Salva" e poi chiudi il pannello delle impostazioni.
- Aggiungi lo Snap CSV Parser: trascina e rilascia lo Snap "CSV Parser" nell'area di lavoro, posizionandolo dopo il File Reader. Le impostazioni predefinite per CSV Parser sono in genere sufficienti per la maggior parte dei casi d'uso.
- Convalida o esegui la pipeline: convalida o esegui la pipeline per elaborare e leggere il contenuto del file CSV.
Lettura di contenuti HTML con File Reader
- Aggiungi lo Snap File Reader: trascina e rilascia lo Snap "File Reader" nell'area di lavoro del designer.
- Configurare lo Snap File Reader: Clicca sullo Snap "File Reader" per accedere al pannello delle impostazioni. Quindi inserisci l'URL a cui desideri collegarti nelle impostazioni.
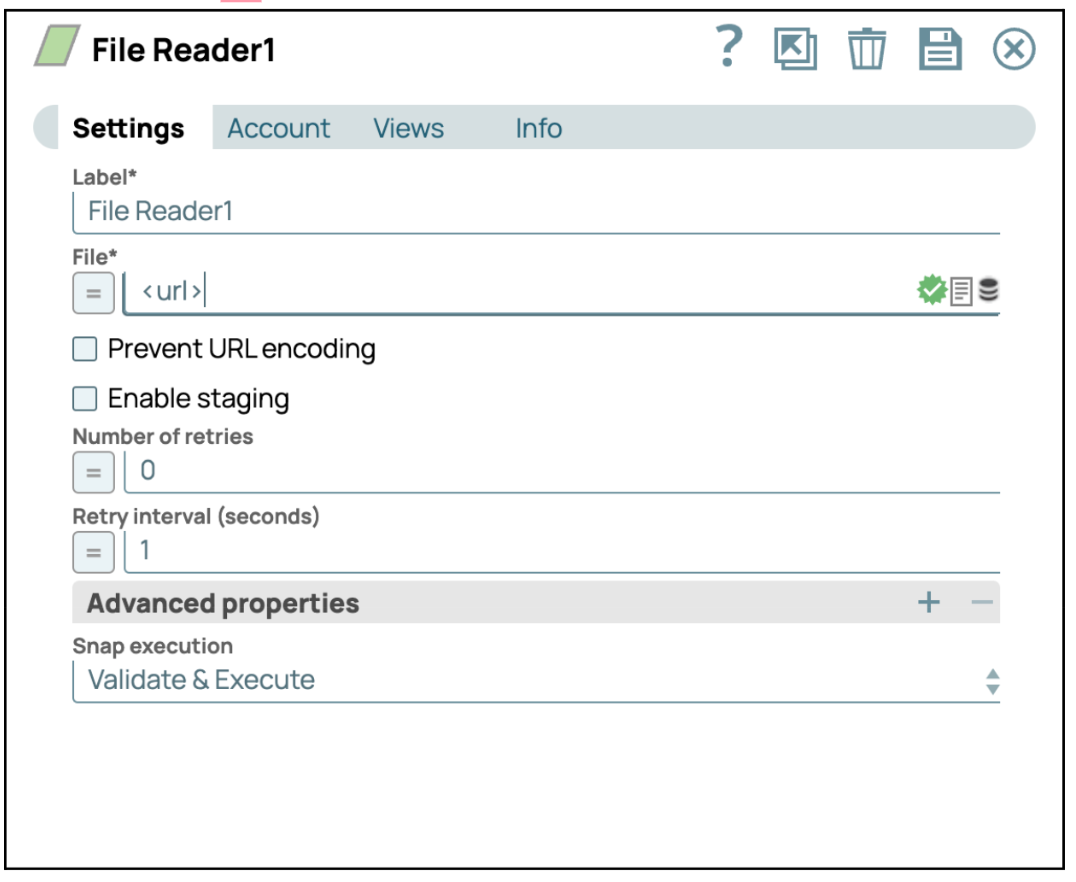
- Salva configurazione: clicca su "Salva" e chiudi le impostazioni.
- Aggiungi lo snap HTML Parser: trascina lo snap "HTML Parser" nel Designer, collegalo allo snap File Reader e lascia la configurazione predefinita.
- Configurare lo Snap HTML Parser: Apri le impostazioni dell'HTML Parser e vai alla scheda "Visualizzazioni". Scegli se generare un documento o un file binario.
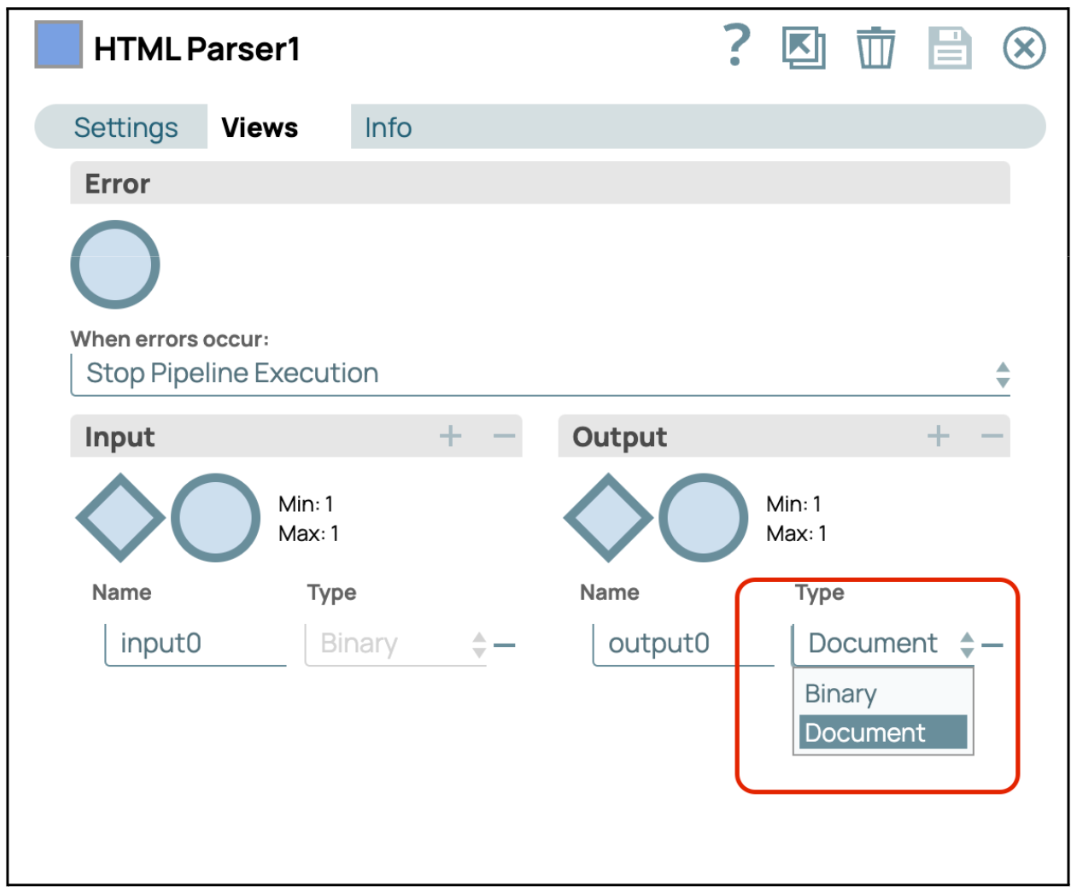
- Convalida o esegui la pipeline: convalida o esegui la pipeline per recuperare il contenuto testuale dall'URL specificato.
Lettura di contenuti HTML con client HTTP
- Aggiungere lo Snap HTTP Client: trascinare lo Snap "HTTP Client" nell'area di lavoro del designer.
- Configurare lo Snap Client HTTP: Fare clic sullo Snap "HTTP Client" per accedere al pannello delle impostazioni. Quindi inserire l'URL a cui si desidera connettersi nelle impostazioni. Lo Snap HTTP Client consente all'utente di eseguire chiamate html complesse con varie configurazioni. Gli utenti possono selezionare "Request Methods" (Metodi di richiesta) o fornire il meccanismo "Pagination" (Impaginazione) per ottenere contenuti continui.
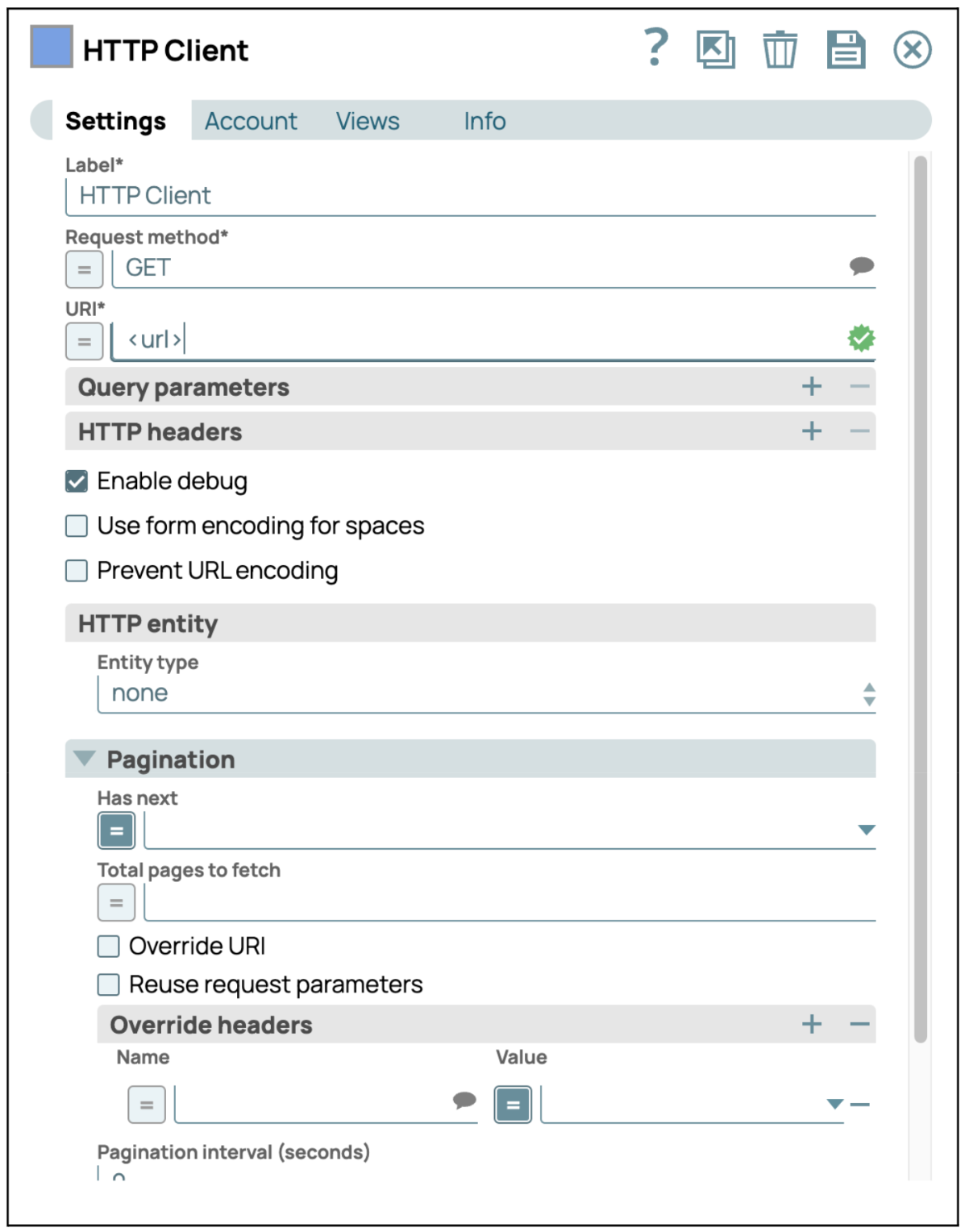
- Configurare le viste Snap del client HTTP: Fai clic sulla scheda "Visualizzazioni" e seleziona l'output su "Binario". Quindi salva e chiudi le impostazioni.
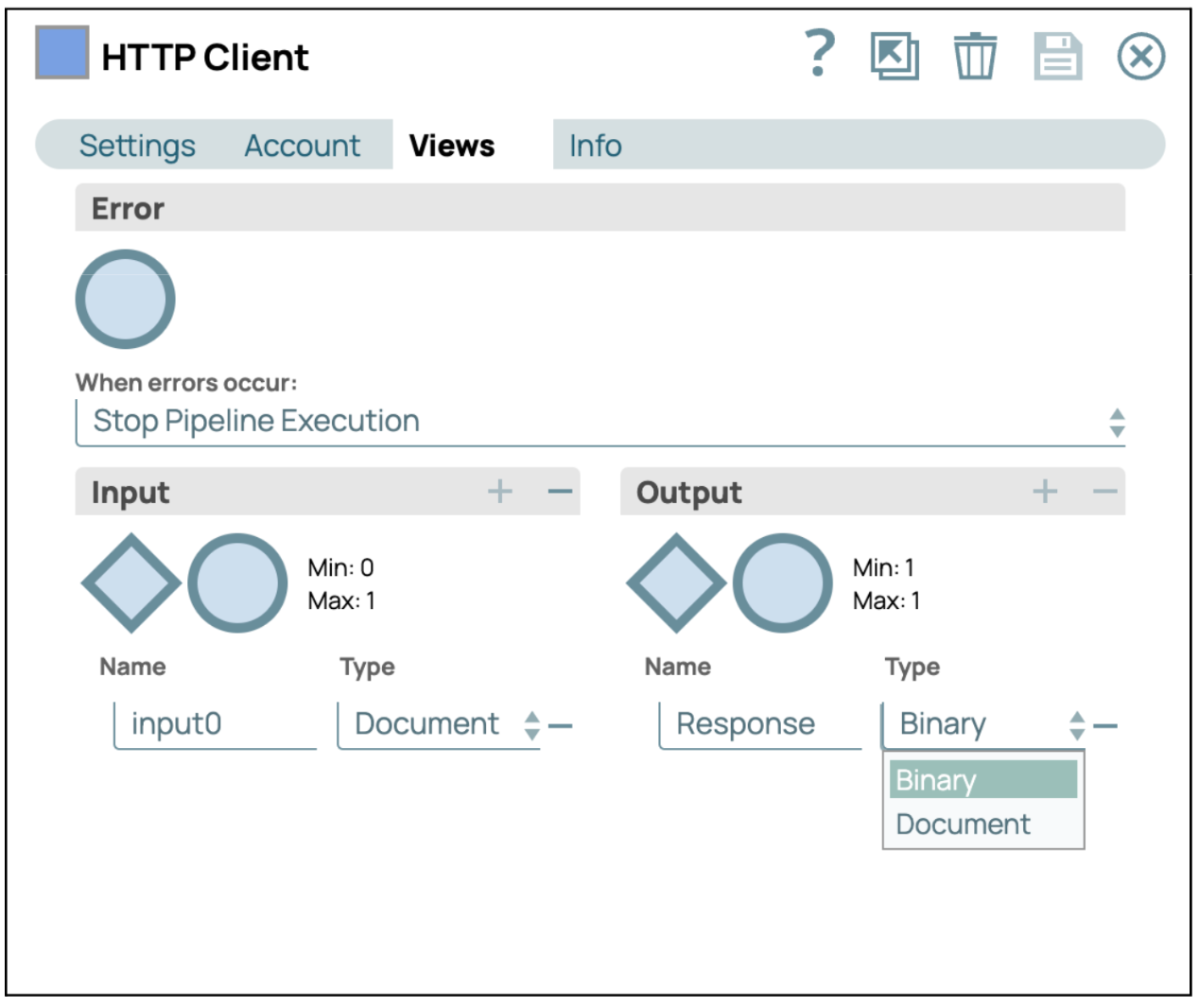
- Aggiungi lo snap HTML Parser: trascina lo snap "HTML Parser" nel Designer, quindi collegalo allo snap File Reader e lascia la configurazione predefinita.
- Convalida o esegui la pipeline: convalida o esegui la pipeline per recuperare il contenuto testuale dall'URL specificato.
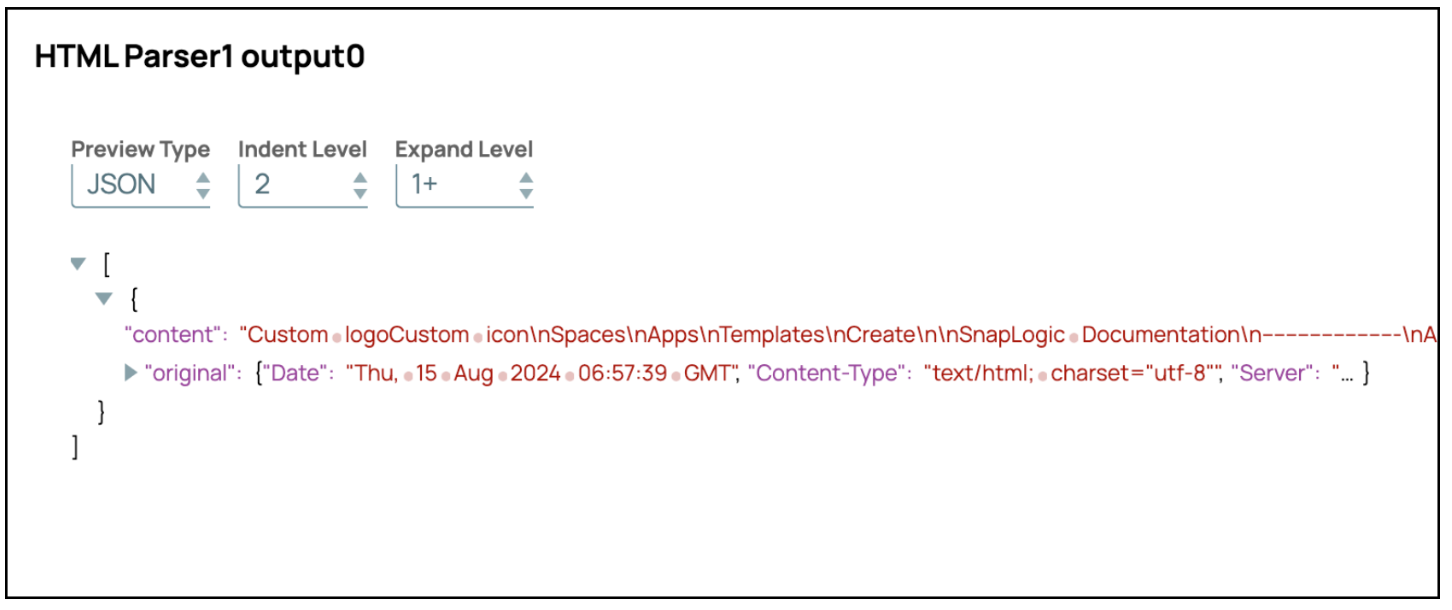
- Visualizza output: L'output mostrerà il contenuto in formato testo.
Lettura di file PDF
Per leggere ed estrarre efficacemente le informazioni da un file PDF, gli utenti devono prima comprendere la natura dei contenuti presenti nel file. I file PDF possono essere generalmente classificati in due categorie: quelli che contengono contenuti testuali e quelli che contengono contenuti grafici.
Per i PDF con contenuti testuali, gli utenti possono utilizzare un parser PDF standard, progettato per estrarre e produrre le informazioni testuali in un formato leggibile. Questi parser sono ampiamente disponibili ed efficienti nel convertire il testo incorporato in un documento PDF in un formato testuale che può essere ulteriormente elaborato o analizzato.
Tuttavia, se il PDF contiene contenuti basati su immagini, come documenti scansionati o immagini di testo, è necessario un approccio diverso. In questo caso, è necessario ricorrere alla tecnologia di riconoscimento ottico dei caratteri (OCR). I servizi OCR sono strumenti specializzati che analizzano le immagini all'interno del PDF e convertono le rappresentazioni visive del testo in testo leggibile dal computer. Questo processo è fondamentale per rendere il contenuto accessibile e modificabile, soprattutto quando si tratta di documenti scansionati o altri file ricchi di immagini.
Comprendendo queste differenze e scegliendo lo strumento appropriato per il tipo di contenuto all'interno di un PDF, gli utenti possono estrarre in modo efficace le informazioni necessarie, garantendo accuratezza ed efficienza nel loro flusso di lavoro.
Lettura di file PDF con PDF Parser snap

- Aggiungi lo Snap File Reader: trascina e rilascia lo Snap "File Reader" nell'area di lavoro del designer.
- Configurare lo Snap File Reader: Clicca sullo Snap "File Reader" per accedere al pannello delle impostazioni. Quindi, seleziona o carica il file pdf che desideri leggere.
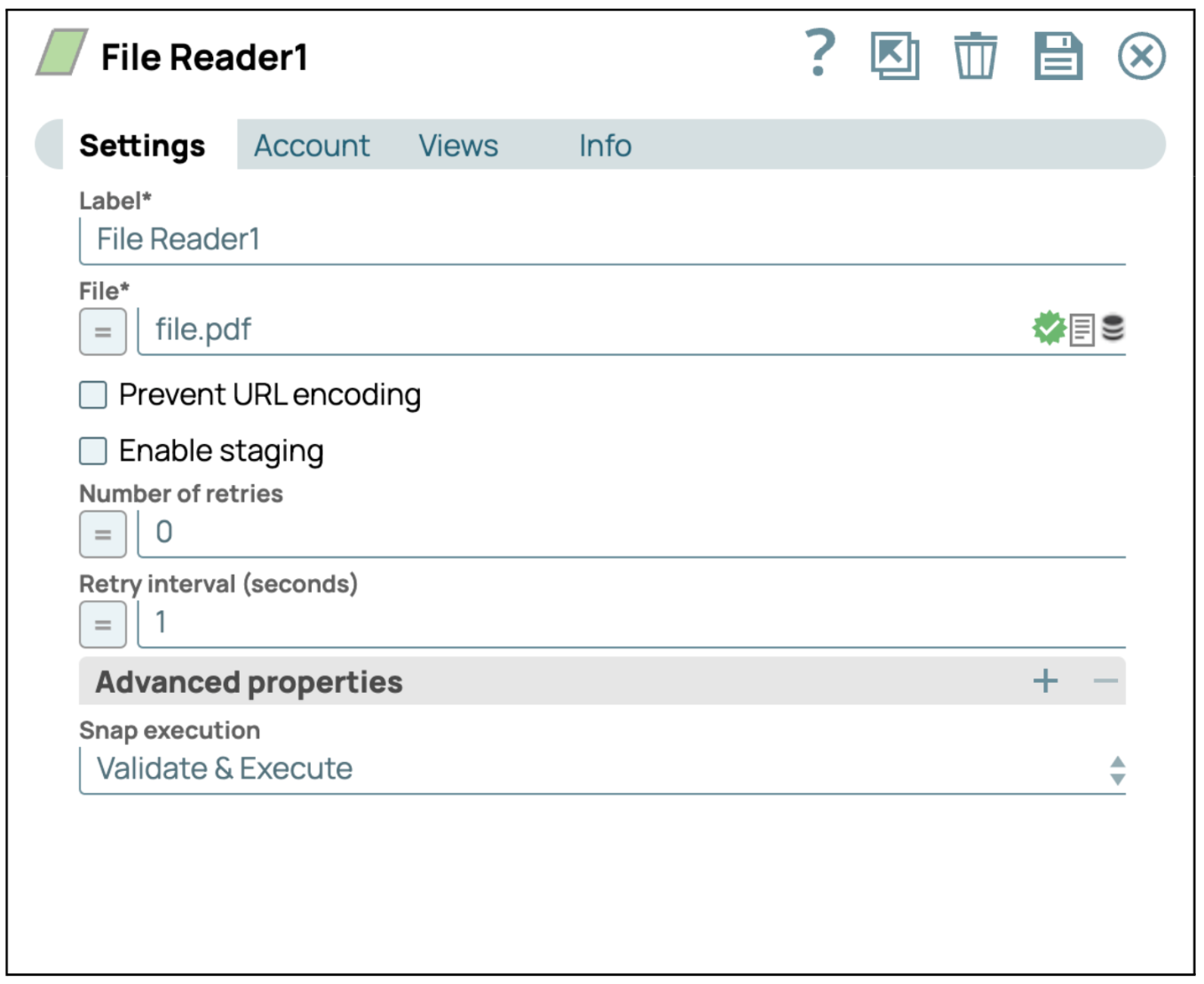
- Salva configurazione: clicca su "Salva" e chiudi le impostazioni.
- Aggiungi lo Snap PDF Parser: lo Snap PDF Parser è in grado di analizzare il file PDF e convertirlo in testo.
- Configurare lo Snap PDF Parser: Gli utenti possono selezionare un "tipo di parser" adeguato per analizzare il file pdf. In questo caso, selezioniamo "Estrazione testo" in modo da poter ottenere tutto il testo dal file pdf.
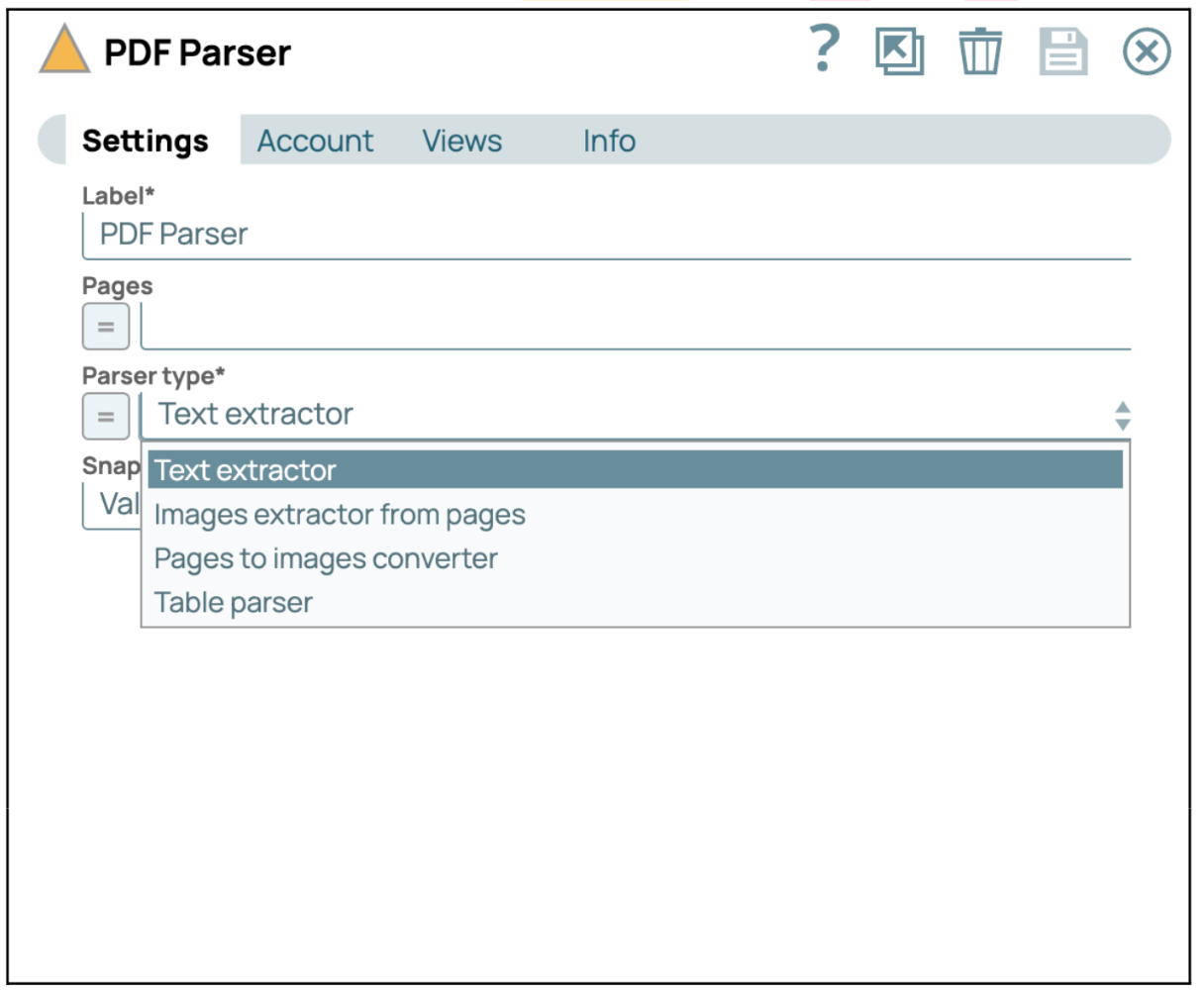
- Convalida o esegui la pipeline: Convalida o esegui la pipeline per recuperare il contenuto testuale dal file PDF specificato. La risposta contiene il testo PDF estratto dal file PDF.

Lettura di file PDF con dati non strutturati

Prerequisito: gli utenti devono disporre di una chiave API non strutturata per accedere al servizio non strutturato oppure devono disporre dell'istanza non strutturata distribuita localmente per utilizzare l'API non strutturata.
Aggiungi lo Snap File Reader: trascina e rilascia lo Snap "File Reader" nell'area di lavoro del designer.
Configura lo Snap File Reader: clicca sullo Snap "File Reader" per accedere al pannello delle impostazioni. Quindi, seleziona o carica un file pdf che desideri leggere.
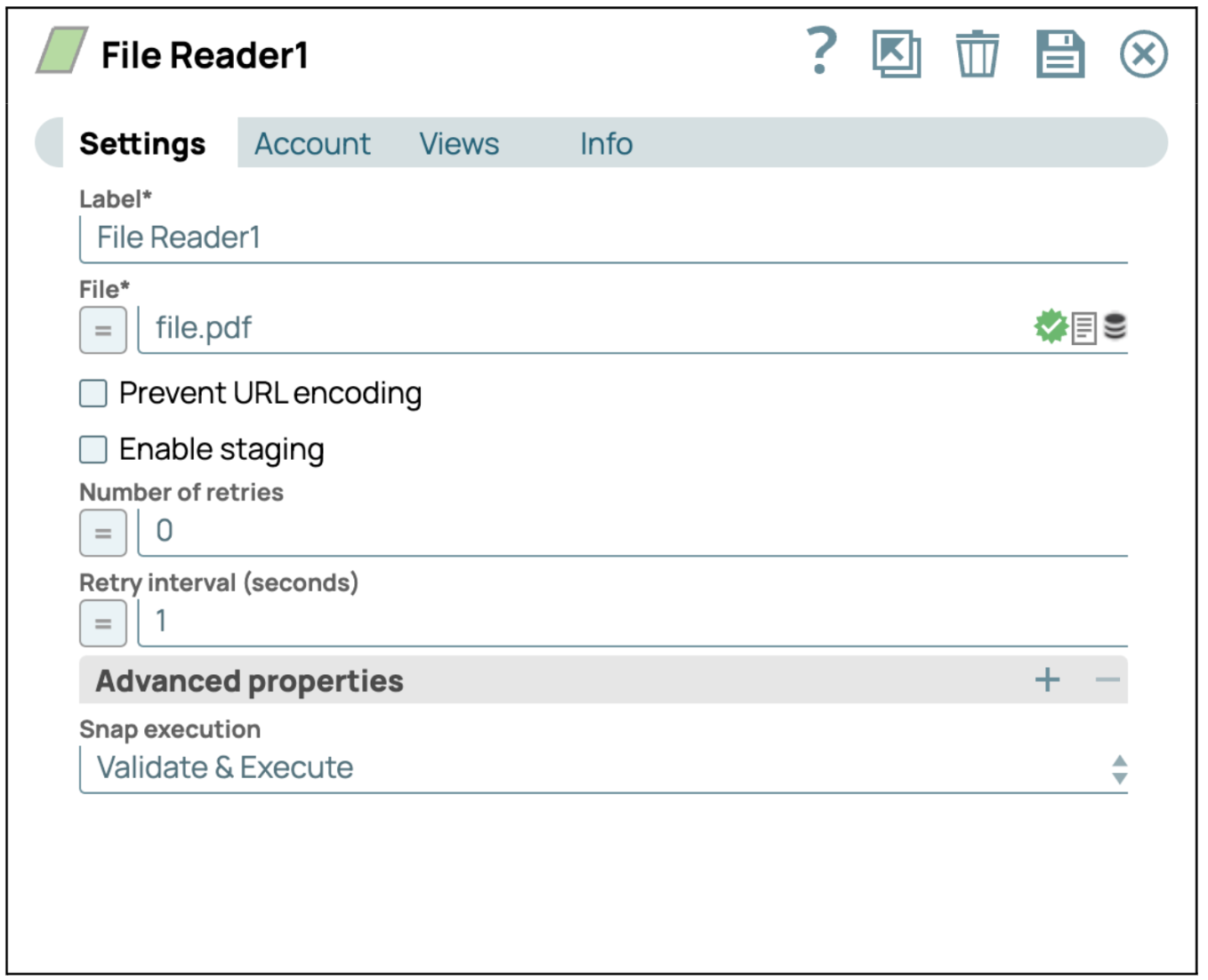
- Salva configurazione: clicca su "Salva" e chiudi le impostazioni.
- Aggiungi lo Snap API di partizione: L'API di partizione snap utilizza l'API di partizione non strutturata per analizzare un file pdf.
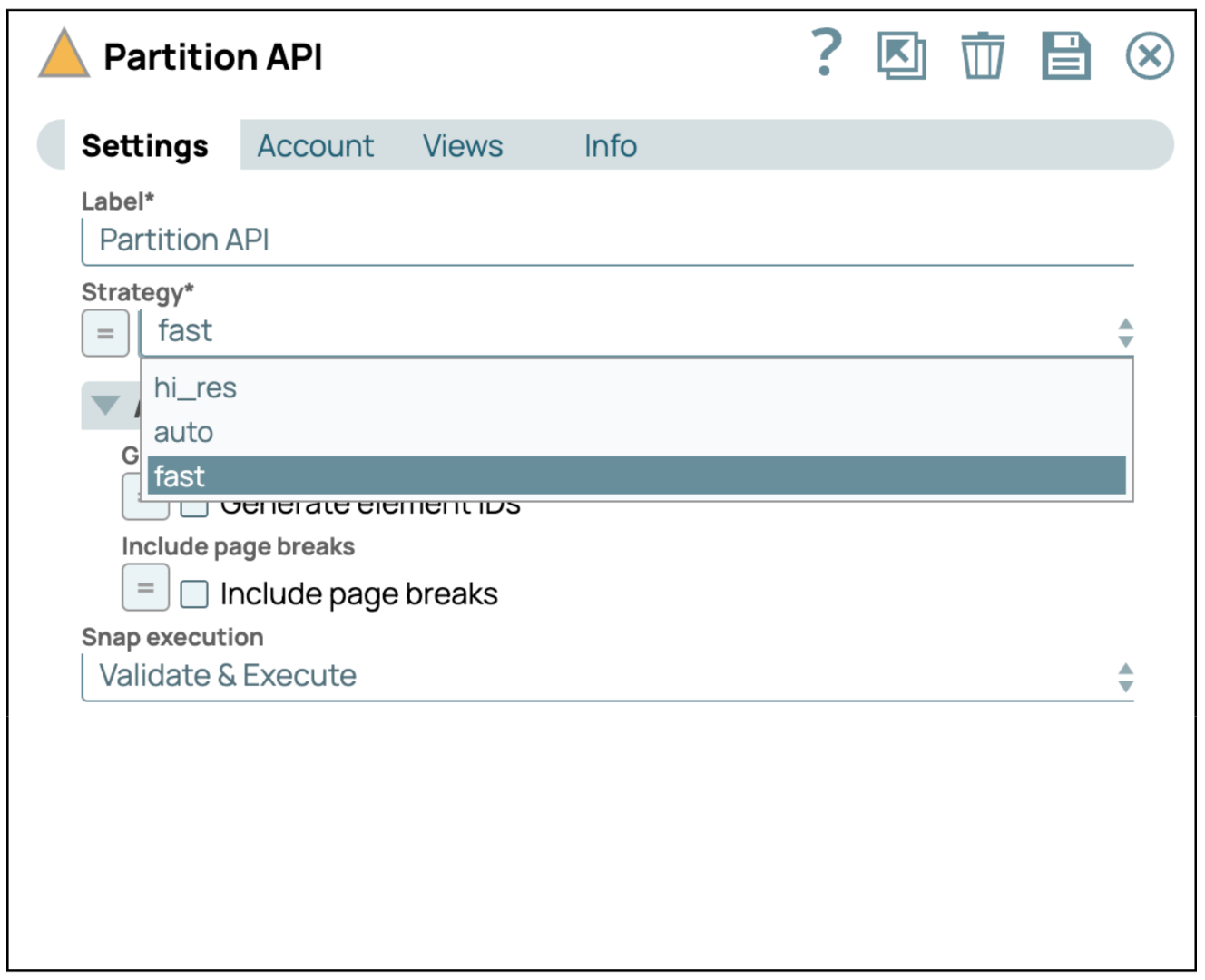
- Configura lo Snap API Partition: gli utenti possono selezionare una strategia per analizzare un file pdf. In questo caso, utilizziamo la strategia "fast" per analizzare solo il testo e non includere immagini e tabelle. Se selezioni hi_res, l'immagine e la tabella verranno analizzate come base64.
- Convalida o esegui la pipeline: Convalida o esegui la pipeline per recuperare il contenuto testuale dal file PDF specificato. La risposta contiene anche il tipo di contenuto analizzato dal PDF. Gli utenti possono quindi utilizzare l'attributo "type" per ulteriori elaborazioni, ad esempio per elaborare separatamente il titolo e il contenuto dal piè di pagina.

Lettura di file PDF con Adobe Service
Gli utenti possono sfruttare l'API Adobe per le attività di analisi dei PDF. SnapLogic offre Adobe Extract Snap per l'estrazione di testo dai documenti PDF e Adobe OCR Snap per l'elaborazione dei contenuti PDF basati su immagini. Quando si ha a che fare con PDF che contengono contenuti basati su immagini, Adobe OCR Snap è lo strumento appropriato, in quanto consente l'estrazione accurata del testo dalle immagini all'interno del documento.
Lettura di file PDF con Adobe OCR
Prerequisito: gli utenti devono disporre di una chiave Adobe per accedere al servizio Adobe OCR prima di utilizzare lo snap Adobe OCR.
- Aggiungi lo Snap File Reader: trascina e rilascia lo Snap "File Reader" nell'area di lavoro del designer.
- Configurare lo Snap File Reader: Clicca sullo Snap "File Reader" per accedere al pannello delle impostazioni. Quindi, seleziona o carica il file pdf che desideri leggere.
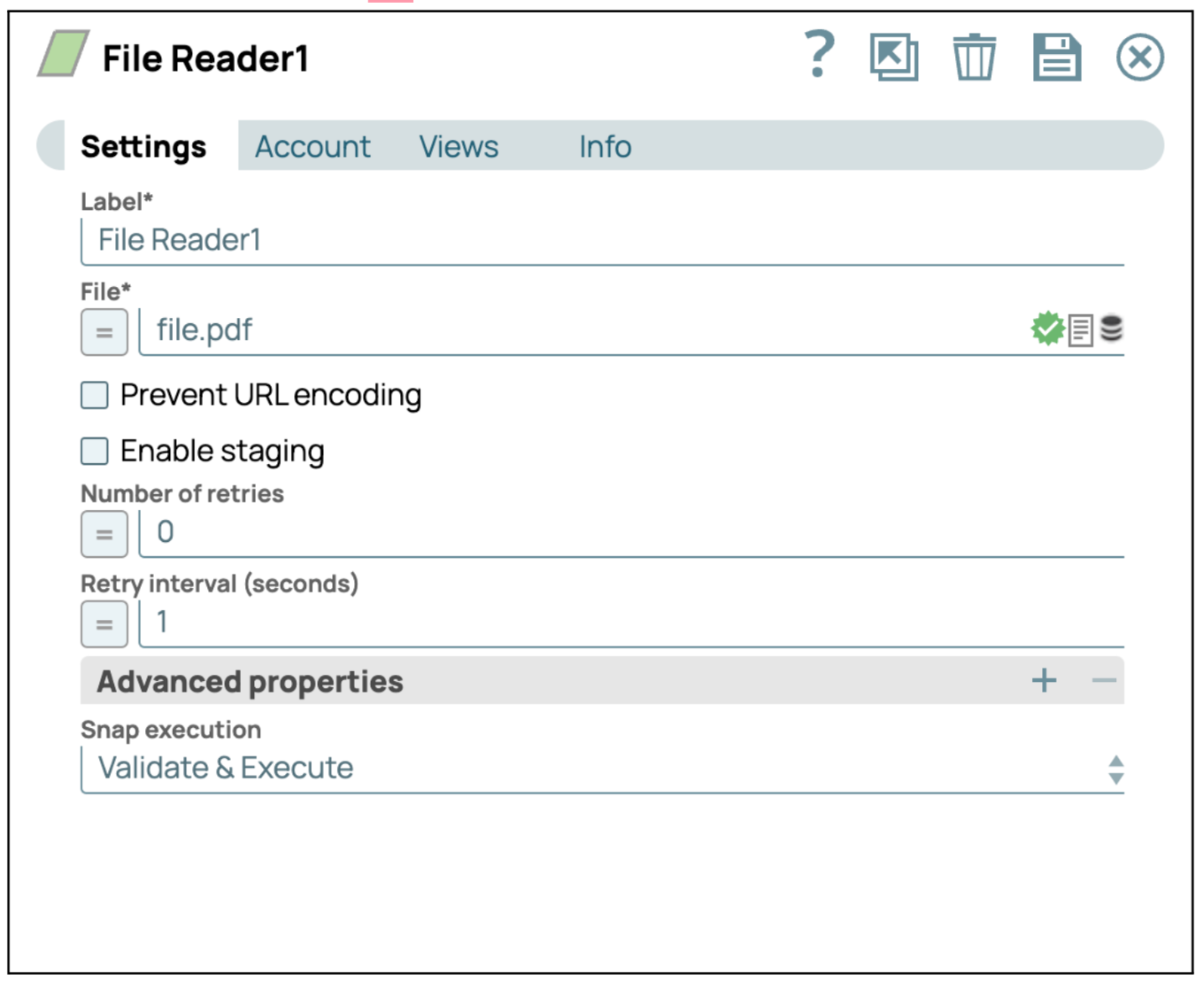
- Salva configurazione: clicca su "Salva" e chiudi le impostazioni.
- Aggiungi Adobe OCR Snap: Adobe OCR Snap utilizza l'API Adobe per analizzare in modo efficiente i file PDF con contenuti basati su immagini. Gli utenti possono fare affidamento sulle impostazioni predefinite fornite in Adobe OCR Snap per estrarre con precisione il testo dalle immagini incorporate nel PDF.
- Convalida o esegui la pipeline: convalida o esegui la pipeline per recuperare il contenuto testuale dal file PDF specificato. La risposta contiene un contenuto binario che include le informazioni estratte.







