






Questa guida tratterà alcune tecniche avanzate di prompt engineering e come applicarle in Snaplogic GenAI App Builder per aiutarti ad affrontare compiti più complessi e migliorare le prestazioni complessive. Imparerai come utilizzare i prompt di sistema, strutturare le risposte in JSON, creare prompt complessi, gestire i token e considerare la dimensione dei prompt e del contesto. Innanzitutto, chiariamo cosa sia esattamente il prompt engineering e perché sia importante.
Che cos'è l'ingegneria dei prompt?
Fondamentalmente, il prompt engineering consiste nel progettare l'input (il "prompt") che si fornisce a un modello di IA. Il modo in cui si formula il prompt può influire in modo significativo sulla qualità e sulla pertinenza dell'output del modello. Non si tratta solo di cosa si chiede all'IA di fare, ma anche di come lo si chiede.
Perché è importante l'ingegneria tempestiva?
Anche i modelli di IA più avanzati dipendono fortemente dai prompt che ricevono. Un prompt ben strutturato può portare a risposte approfondite, accurate e altamente pertinenti, mentre un prompt mal strutturato può portare a risposte vaghe, inaccurate o irrilevanti. Comprendere le sfumature della progettazione dei prompt può aiutarti a massimizzare l'efficacia delle tue applicazioni di IA.
Prerequisiti
- Nozioni di base su Snaplogic
- OpenAI, Azure OpenAI, Amazon Bedrock Anthropic Claude o account Google Gemini
Richiesta di sistema
Il prompt di sistema è un input speciale che definisce il comportamento, il tono e i limiti dell'LLM prima che interagisca con gli utenti. Stabilisce il contesto e definisce le regole per le interazioni, assicurando che le risposte dell'assistente siano in linea con la personalità e gli obiettivi desiderati.
Immagina di essere un assistente di un agente di viaggio. Il tuo compito è fornire ai clienti consigli di viaggio personalizzati e precisi. Per farlo in modo efficace, è essenziale stabilire il comportamento dell'LLM attraverso il prompt del sistema: definire il ruolo dell'assistente, impostare il tono e lo stile appropriati e includere istruzioni importanti.

- Trascina "OpenAI Chat Completion", "Azure OpenAI Chat Completion", "Anthropic Claude on AWS Messages" o "Google Gemini Generate" sulla tela.
- Seleziona la scheda "Account" e seleziona l'account configurato.
- Selezionare la scheda "Impostazioni" per configurare questi campi.
- Seleziona un modello: clicca sull'icona della nuvoletta della chat per visualizzare l'elenco dei modelli disponibili e selezionare quello che preferisci.
- Imposta "Prompt"
"Sto organizzando una luna di miele di 3 giorni in Giappone. Siamo interessati alle esperienze culturali e alla natura."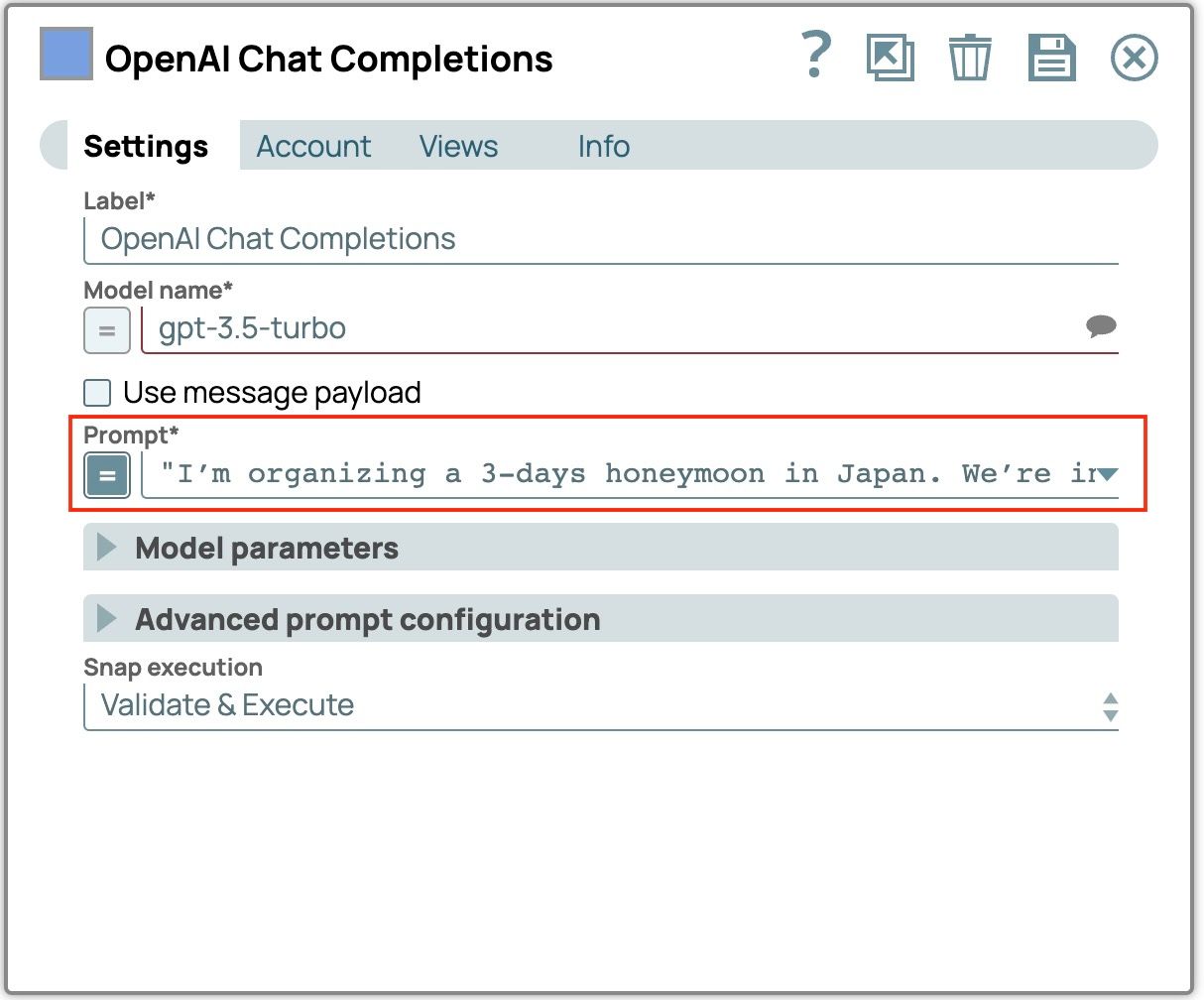
- Imposta "Richiesta di sistema": espandere "Configurazione avanzata prompt" e inserire il prompt di sistema
"Sei un assistente di un agente di viaggio. Fornisci consigli di viaggio personalizzati in base alle preferenze dell'utente. Mantieni un tono amichevole e colloquiale. Se ti viene chiesto del programma di viaggio, includi alloggi e ristoranti."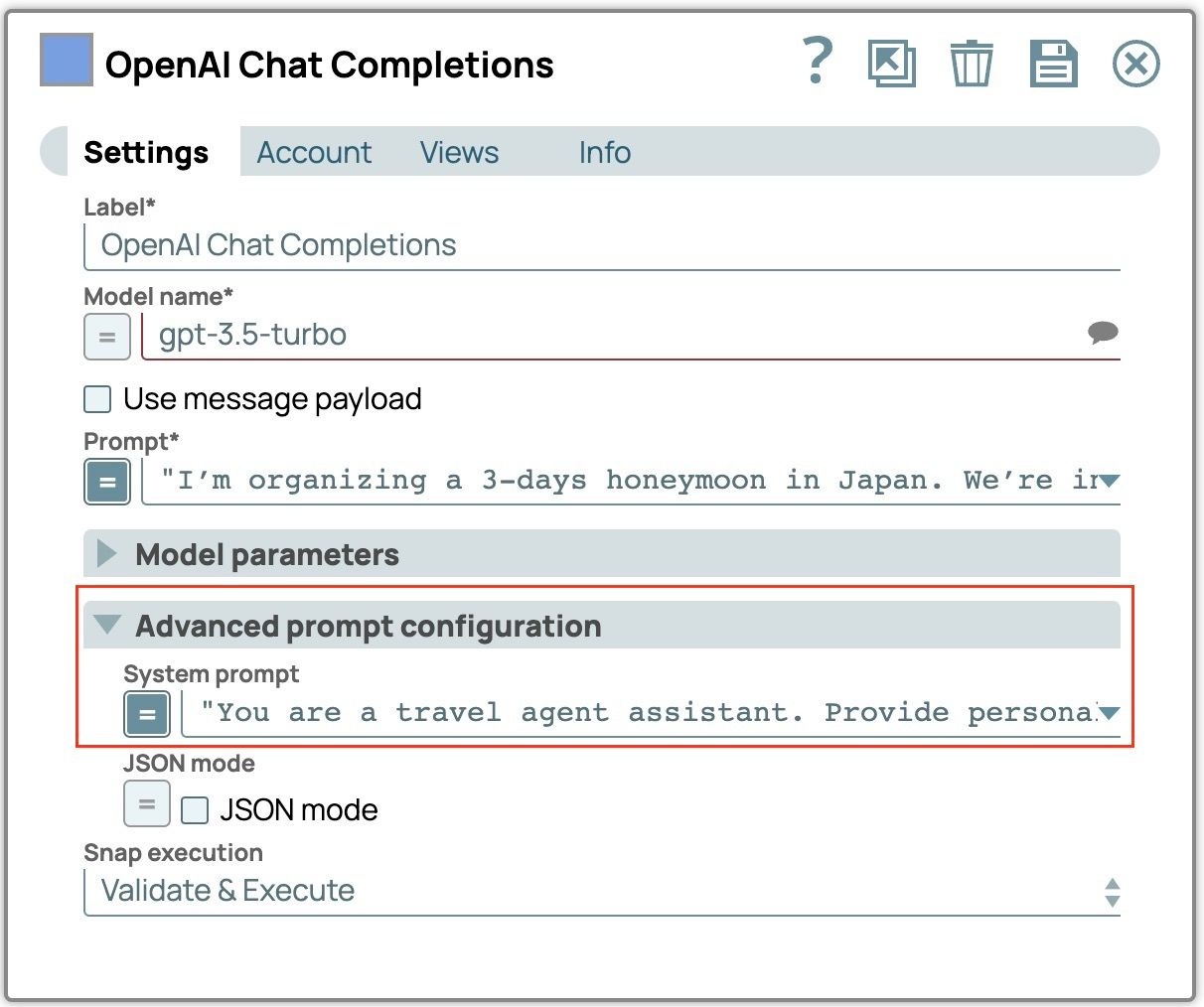
- Salva e chiudi il pannello delle impostazioni di snap
- Convalida la pipeline e vediamo il risultato cliccando sull'anteprima dell'output dei dati.
- Seleziona un modello: clicca sull'icona della nuvoletta della chat per visualizzare l'elenco dei modelli disponibili e selezionare quello che preferisci.
Per riassumere l'esempio sopra riportato
Richiesta di sistema:
Sei un assistente di un'agenzia di viaggi.
Fornisci consigli di viaggio personalizzati in base alle preferenze dell'utente.
Mantieni un tono amichevole e colloquiale.
Se ti viene chiesto del programma di viaggio, includi alloggi e ristoranti.
Domanda:
Sto organizzando una luna di miele di 3 giorni in Giappone. Siamo interessati alle esperienze culturali e alla natura.
Risposta:
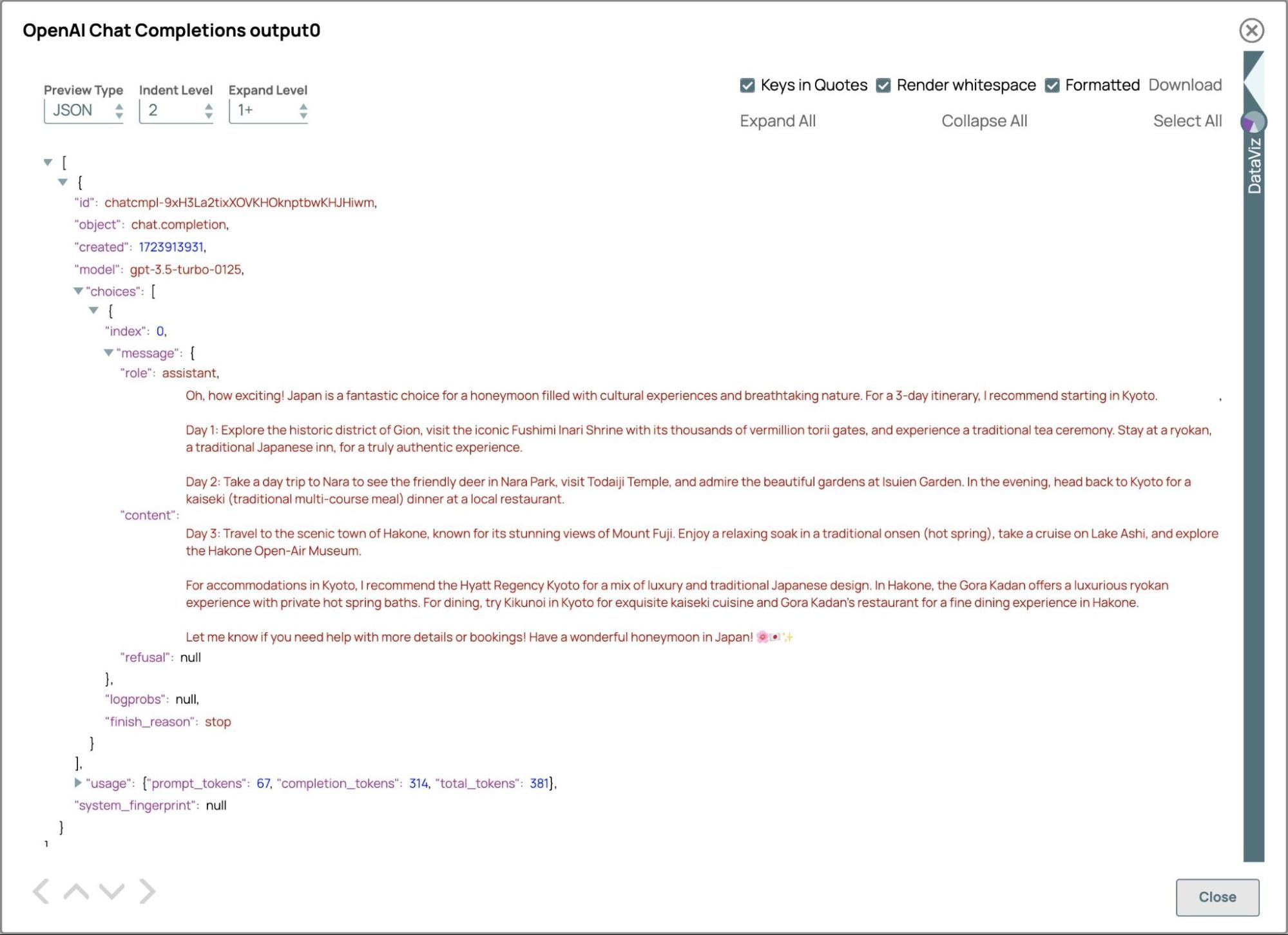
Che emozione! Il Giappone è la destinazione perfetta per una luna di miele ricca di esperienze culturali e paesaggi meravigliosi.
Per il vostro viaggio di 3 giorni, vi consiglio di iniziare da Kyoto, famosa per i suoi templi e giardini tradizionali. Potrete visitare luoghi iconici come il Santuario Fushimi Inari, il Boschetto di bambù di Arashiyama e il Tempio Kinkaku-ji. Non perdetevi la tradizionale cerimonia del tè e provate a indossare un kimono per un'esperienza davvero coinvolgente.
Successivamente, dirigiti a Hakone per ammirare la straordinaria bellezza naturale del Giappone. Puoi esplorare il Museo all'aperto di Hakone, fare un bagno rilassante in un onsen (sorgente termale) e goderti una crociera panoramica sul lago Ashi con vista sul Monte Fuji.
Per l'alloggio, ti consiglio di soggiornare in un ryokan tradizionale per un'autentica esperienza giapponese. I ryokan offrono camere con tatami, letti futon e cene kaiseki con piatti stagionali.
Per quanto riguarda i ristoranti, assicuratevi di provare le specialità locali come il sushi, il ramen e il tempura. E non perdetevi il sake, il famoso vino di riso giapponese!
Fatemi sapere se desiderate maggiori dettagli o assistenza per la prenotazione di alloggi e ristoranti. Vi auguro una meravigliosa luna di miele in Giappone!
La risposta aderisce alle indicazioni del sistema fornendo consigli personalizzati in tono amichevole, inclusi dettagli su alloggi e opzioni ristorative.
Risposta JSON
Strutturare la risposta in formato JSON è una tecnica fondamentale per migliorare la chiarezza, mantenere la coerenza e garantire una perfetta integrazione con vari sistemi, tra cui applicazioni front-end, API e database. Ad esempio, se è necessario presentare le informazioni dell'esempio sopra riportato relativo all'assistente dell'agenzia di viaggi in un formato predefinito su un sito web, generare un PDF o connettersi con altri servizi che facilitano la prenotazione di hotel e attività, è essenziale formattare la risposta immediata come JSON. Questo approccio garantisce la compatibilità e l'interazione fluida tra diverse piattaforme e servizi.
Proviamo a modificare il prompt di sistema dell'esempio precedente per produrre un output in un formato JSON specifico.
- Fai clic sullo snap Chat completata per aprire le impostazioni.
- Aggiorna il prompt di sistema per istruire l'LLM a produrre la risposta JSON:
"Sei un assistente di un agente di viaggio. Fornisci una risposta JSON che includa destinazione, durata del viaggio, elenco delle attività, elenco degli hotel (con campi per nome e descrizione) ed elenco dei ristoranti (con campi per nome, posizione e descrizione)". - Seleziona la casella di controllo "Modalità JSON". Lo snap genererà un campo denominato json_output contenente l'oggetto JSON analizzato della risposta.
- Salva e chiudi il pannello delle impostazioni di snap.
- Convalida la pipeline e vediamo il risultato.
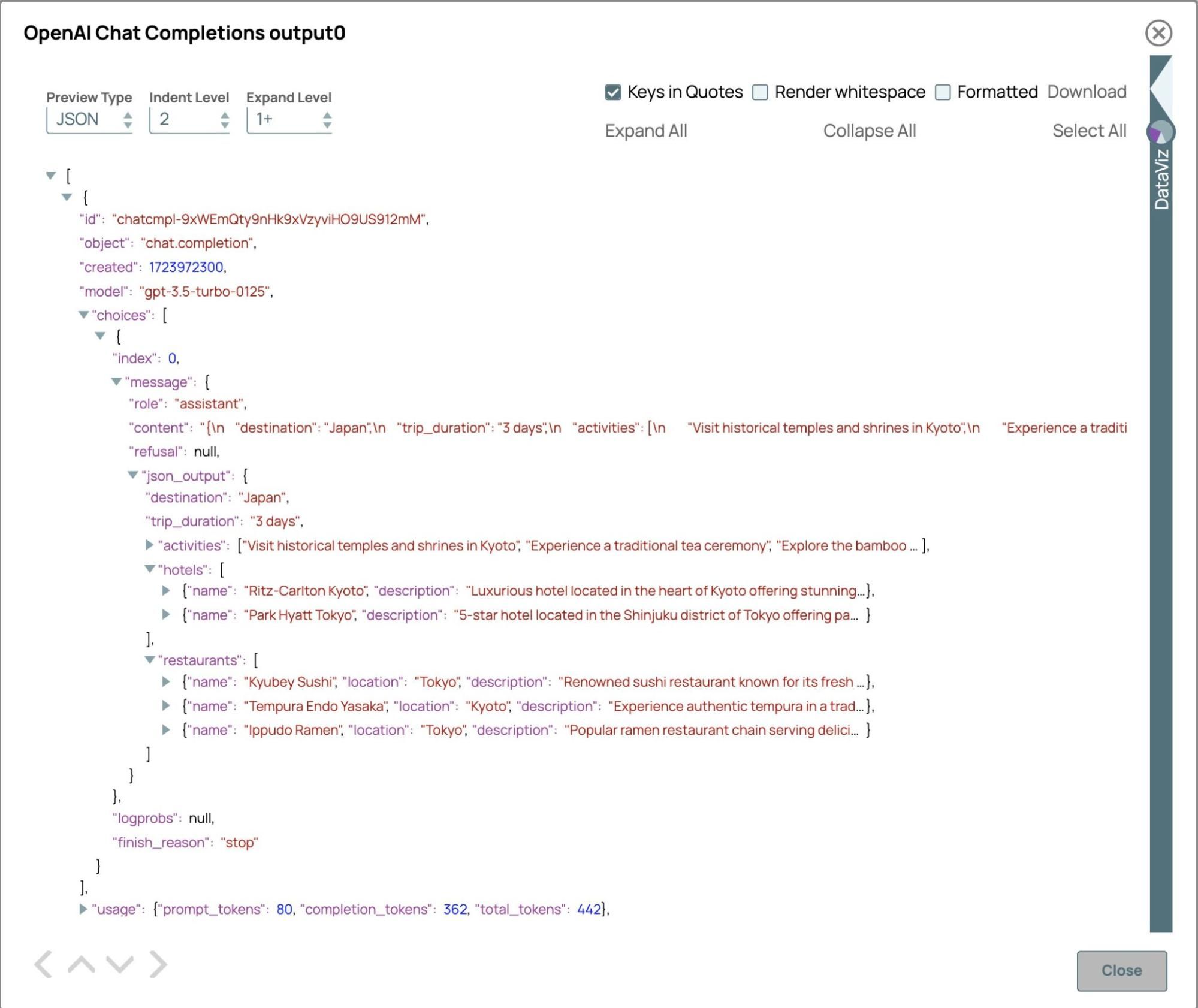
La risposta immediata è la stringa JSON e l'oggetto JSON analizzato si trova nel campo "json_output", poiché la modalità JSON è abilitata. La risposta JSON è conforme alla struttura specificata nel prompt di sistema, garantendo che tutti i campi necessari siano inclusi. Il formato strutturato supporta una perfetta integrazione con le applicazioni a valle. Per un'agenzia di viaggi, questa funzionalità consente la generazione efficiente di itinerari personalizzati, che possono essere utilizzati per popolare pagine web, generare documenti PDF o Excel, inviare e-mail o aggiornare direttamente i sistemi di prenotazione dei viaggi, comprese le richieste di disponibilità dei voli e la verifica delle opzioni alberghiere.
Prompt complesso
L'utilizzo di un elenco di messaggi per incorporare la cronologia delle conversazioni aiuta a mantenere il contesto nei dialoghi in corso. Questo approccio garantisce che le risposte siano pertinenti e coerenti, migliorando il flusso complessivo della conversazione. Inoltre, questi messaggi possono essere forniti come esempi di risposte degli utenti per guidare il modello nell'interazione efficace. Includendo le interazioni precedenti, migliora la continuità e il coinvolgimento degli utenti, facilitando la capacità del modello di gestire scambi complessi e multi-turno. Questa tecnica consente al modello di generare risposte più naturali e accurate, soprattutto quando si basa su dettagli precedenti, con il risultato di una conversazione più fluida e intuitiva. Inoltre, possono essere utilizzati come esempio di risposta per far sapere al modello come dovrebbe interagire con l'utente.
Ogni messaggio contiene un ruolo e un contenuto. I ruoli comuni sono:
- Sistema: fornisce il contesto iniziale, definendo il tono e il comportamento dell'LLM.
- Utente: rappresenta l'input dell'utente, guidando la conversazione in base alle sue domande o ai suoi comandi.
- Assistente/Modello: contiene risposte precedenti fornite dal LLM o esempi di comportamenti desiderati.
Questa sezione ti guiderà attraverso il processo di creazione di un elenco di messaggi e il suo utilizzo come input per l'LLM. Creeremo la seguente pipeline per consentire a un assistente di agenzia di viaggi di rispondere alle domande sfruttando il contesto delle conversazioni precedenti. In questo esempio, l'utente chiede informazioni sulle attrazioni del Giappone nel mese di aprile e successivamente chiede informazioni sul tempo senza specificare un luogo o un orario. Creiamo la pipeline e vediamo come funziona.

- Trascina lo snap "Generatore JSON" sulla tela.
- Clicca su "Generatore JSON" per aprirlo, quindi clicca sul pulsante "Modifica JSON" nella scheda Impostazioni principale.
- Evidenzia tutto il testo dal modello ed eliminalo.
- Incolla questo testo. Questo messaggio verrà utilizzato come domanda dell'utente.
{
"prompt": "Can you tell me what the weather’s going to be like?"
}Il "Generatore JSON" dovrebbe ora apparire così

- Fai clic su "OK" nell'angolo in basso a destra per salvare il messaggio.
- Salva le impostazioni e chiudi lo snap
- Trascina "OpenAI Prompt Generator" o "Azure OpenAI Prompt Generator" sulla tela.
- Collega il generatore di prompt al "Generatore JSON"
- Clicca su "Generatore di prompt" per aprire le impostazioni.
- Cambia l'etichetta in "Richiesta di sistema"
- Clicca su "Modifica prompt" per aprire l'editor dei prompt.
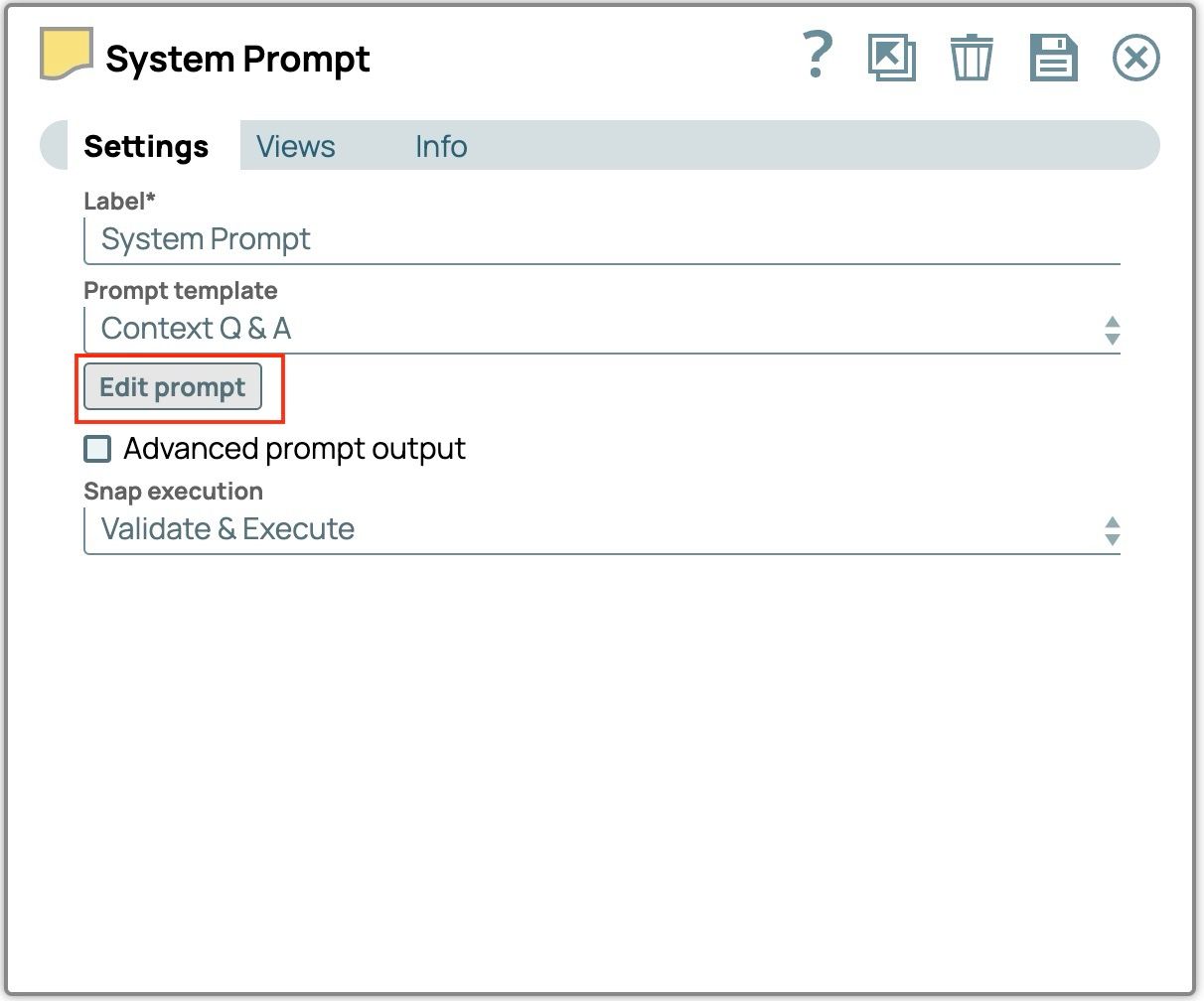
- Evidenzia tutto il testo dal modello ed eliminalo.
- Incolla questo testo. Lo useremo come prompt di sistema.
Sei un assistente di un agente di viaggio.
Fornire consigli di viaggio personalizzati in base alle preferenze dell'utente.L'editor di prompt dovrebbe ora apparire così
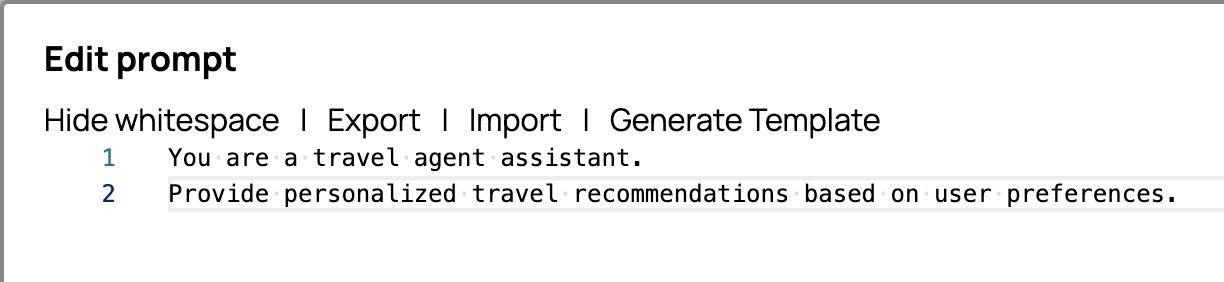
- Fai clic su "OK" nell'angolo in basso a destra per salvare il messaggio.
- Selezionare la casella di controllo "Output prompt avanzato". Il campo "Ruolo utente" verrà compilato automaticamente.
- Imposta il campo "Ruolo utente" su "SISTEMA"
Le impostazioni finali del "Prompt di sistema" dovrebbero ora apparire come segue.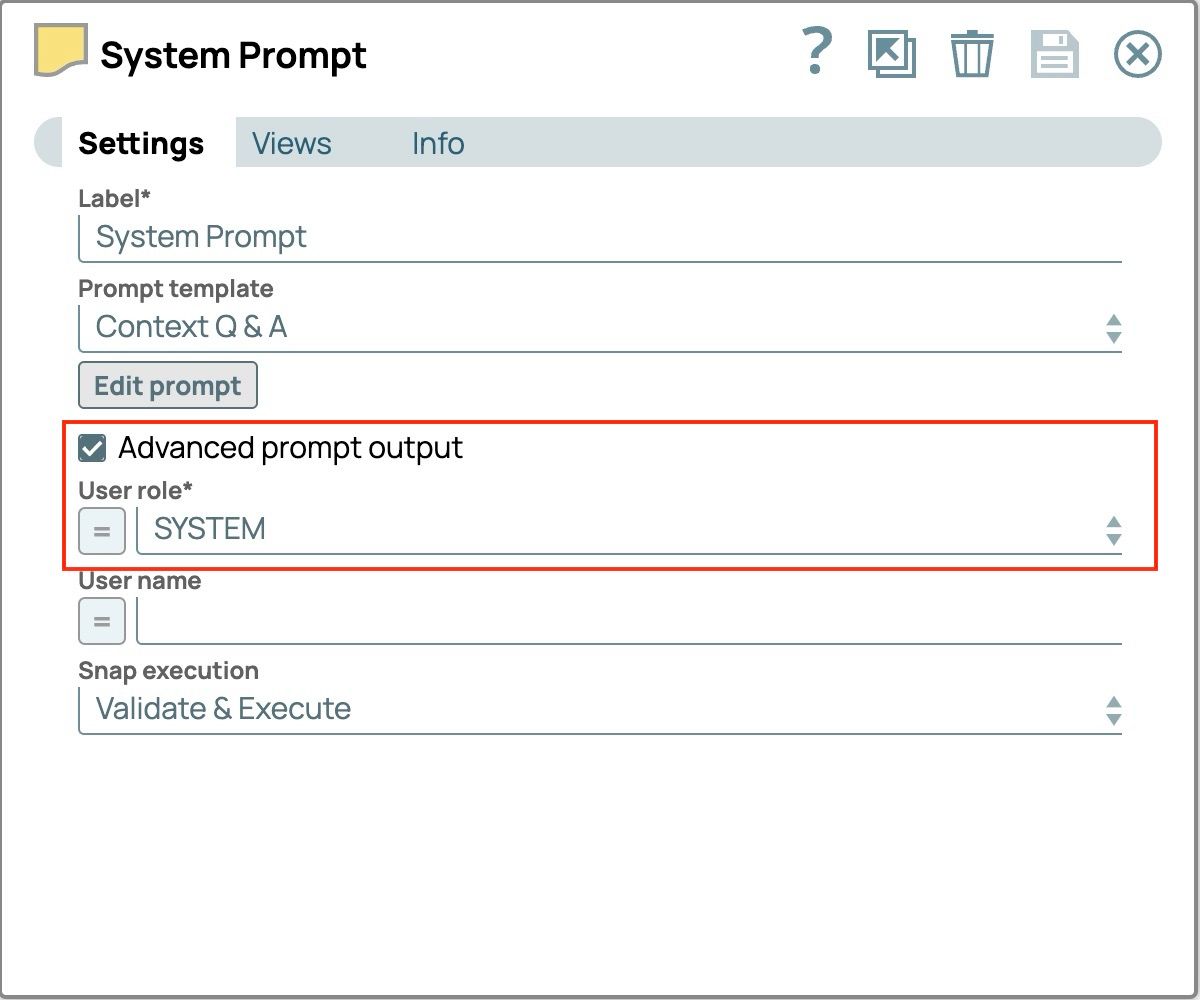
- Salva le impostazioni e chiudi lo snap
- Trascina il secondo "Generatore di prompt" sulla tela e collegalo allo snap precedente. Questo snap gestirà le domande dell'utente precedente.
- Seguire i passaggi da 9 a 17 come guida per configurare i seguenti campi
- Etichetta:Messaggio utente1 Prompt editor:
Sto programmando un viaggio in Giappone ad aprile. Potete aiutarmi a trovare alcune attrazioni turistiche?Ruolo utente:UTENTE Le impostazioni finali del "Messaggio utente 1" dovrebbero essere come segue.

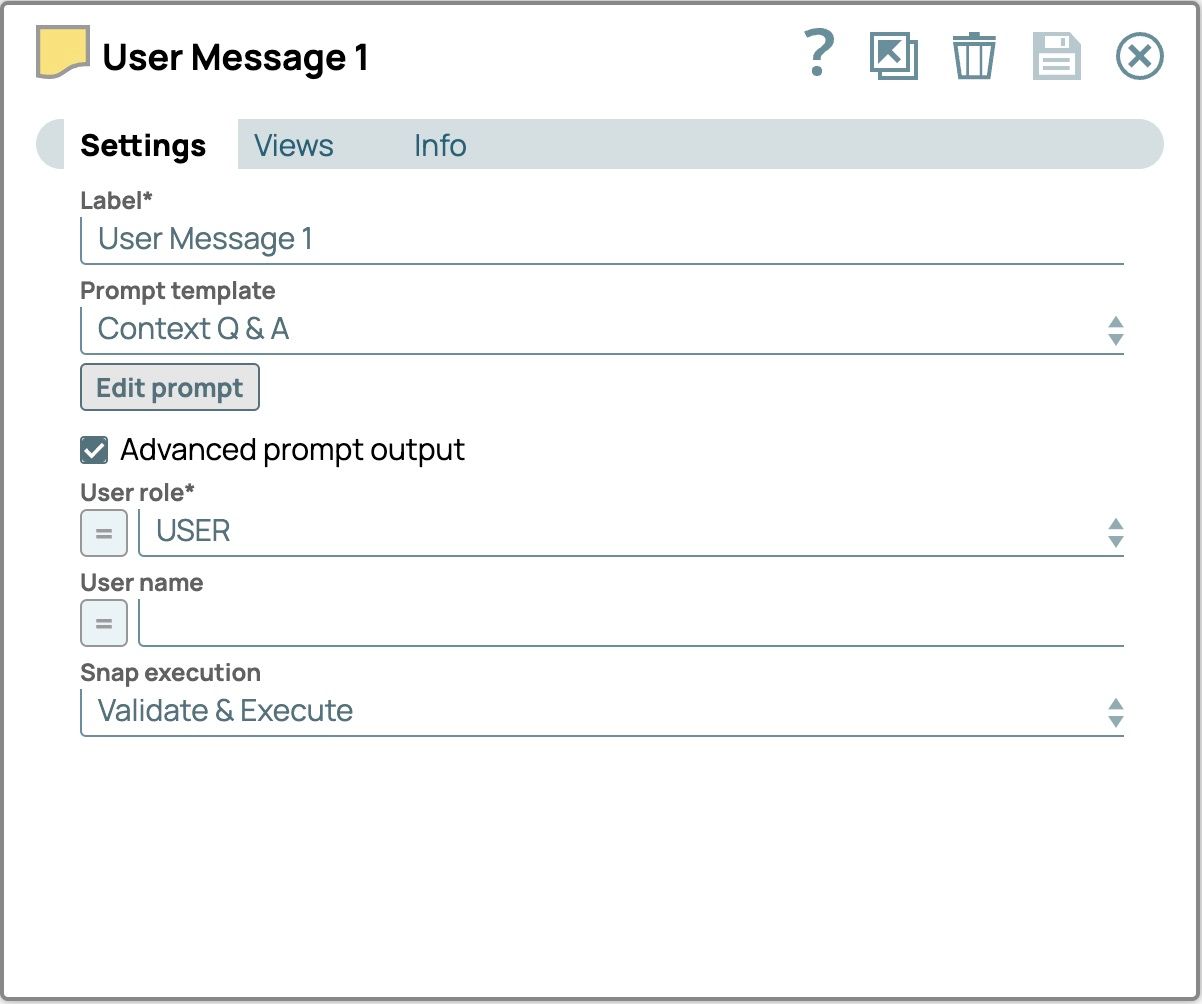
- Etichetta:Messaggio utente1 Prompt editor:
- Trascina il terzo "Prompt Generator" sulla tela e collegalo allo snap precedente. Questo snap gestirà la risposta precedente dell'LLM.
- Seguire i passaggi da 9 a 17 come guida per configurare i seguenti campi
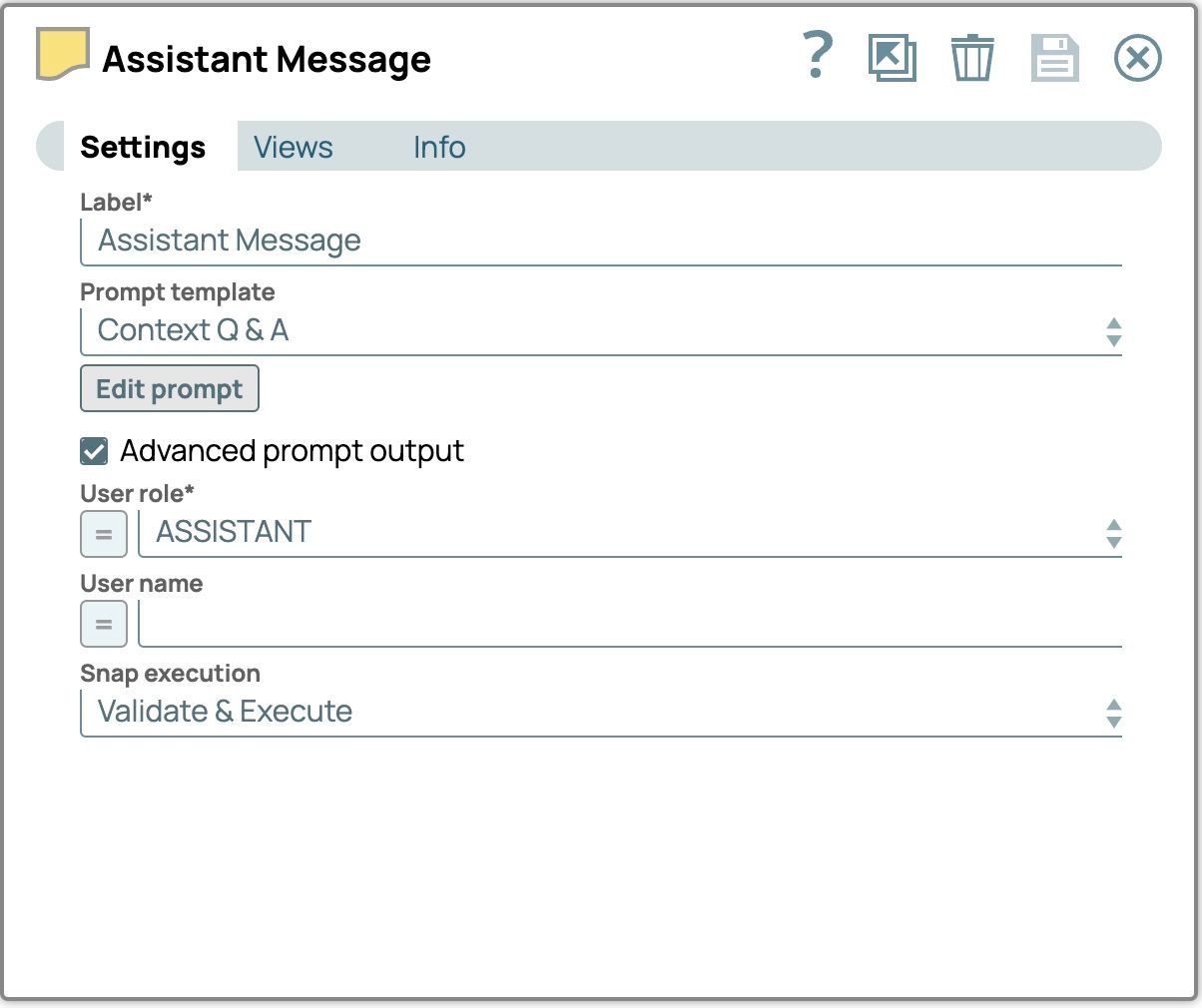
- Etichetta: Messaggio dell'assistenteEditor di prompt:
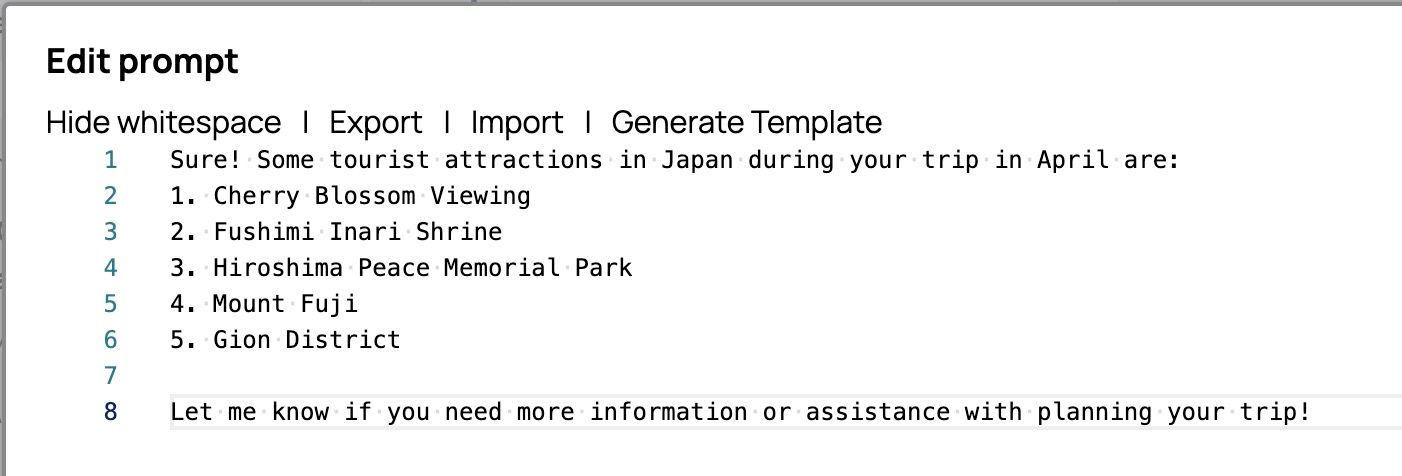
Certo! Alcune attrazioni turistiche in Giappone durante il tuo viaggio ad aprile sono:1. Ammirare i ciliegi in fiore 2. Santuario Fushimi Inari 3. Parco Memoriale della Pace di Hiroshima 4. Monte Fuji 5. Quartiere Gion Fammi sapere se hai bisogno di ulteriori informazioni o assistenza per pianificare il tuo viaggio!
Ruolo utente: ASSISTENTE Le impostazioni finali dell'«Assistente messaggi» dovrebbero essere come segue.
- Etichetta: Messaggio dell'assistenteEditor di prompt:
- Trascinare il quarto "Generatore di prompt" sulla tela e collegarlo allo snap precedente. Questo snap gestirà la domanda dell'utente.
- Segui i passaggi da 9 a 17 come guida per configurare i seguenti campi:
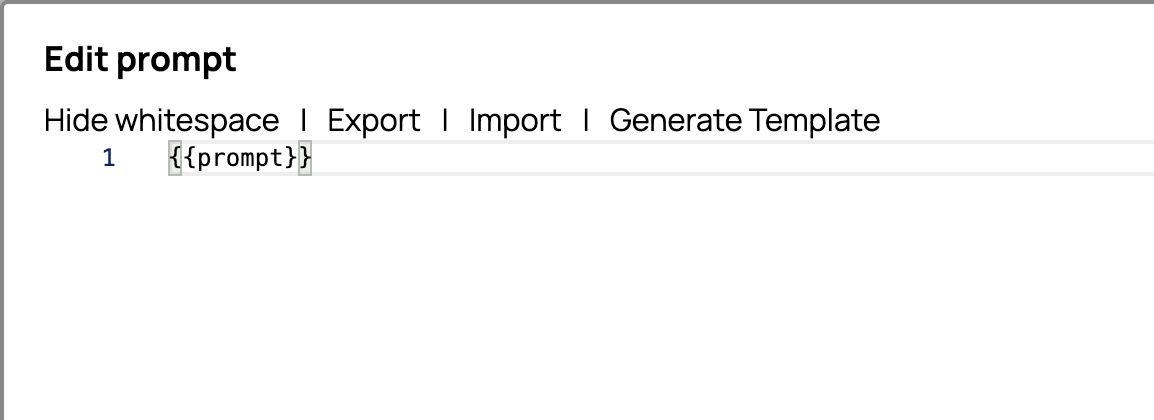
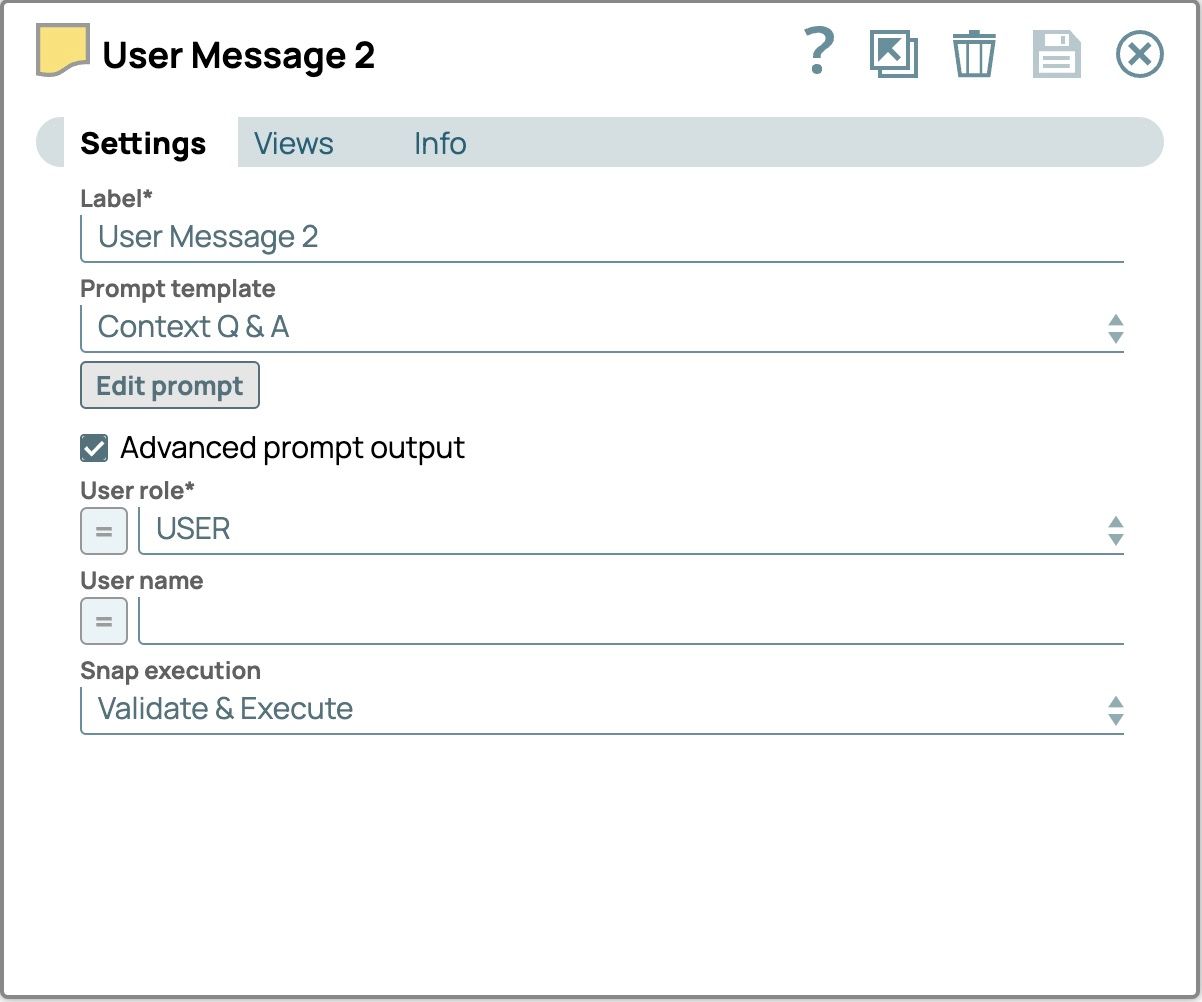
- Label: User Message 2Prompt editor:
{{prompt}} User role: USER Le impostazioni finali del "Messaggio utente 2" dovrebbero essere le seguenti.
- Label: User Message 2Prompt editor:
- Trascina "Chat Completion" sulla tela e collegalo a "User Message 2".
- Clicca su "Completamento chat" per aprire le impostazioni.
- Seleziona l'account nella scheda Account.
- Seleziona la scheda Impostazioni.
- Selezionare il nome del modello.
- Selezionare la casella di controllo "Usa payload messaggio". Il generatore di prompt creerà un elenco di messaggi nel campo "messaggi". È necessario abilitare "Usa payload messaggio" per utilizzare questo elenco di messaggi come input.
- Viene visualizzato il campo "Message payload" (Carico utile del messaggio). Impostare il valore su $messages.
Le impostazioni di Chat Completion dovrebbero ora apparire come segue
- Salva e chiudi il pannello delle impostazioni
- Convalida la pipeline e vediamo il risultato.
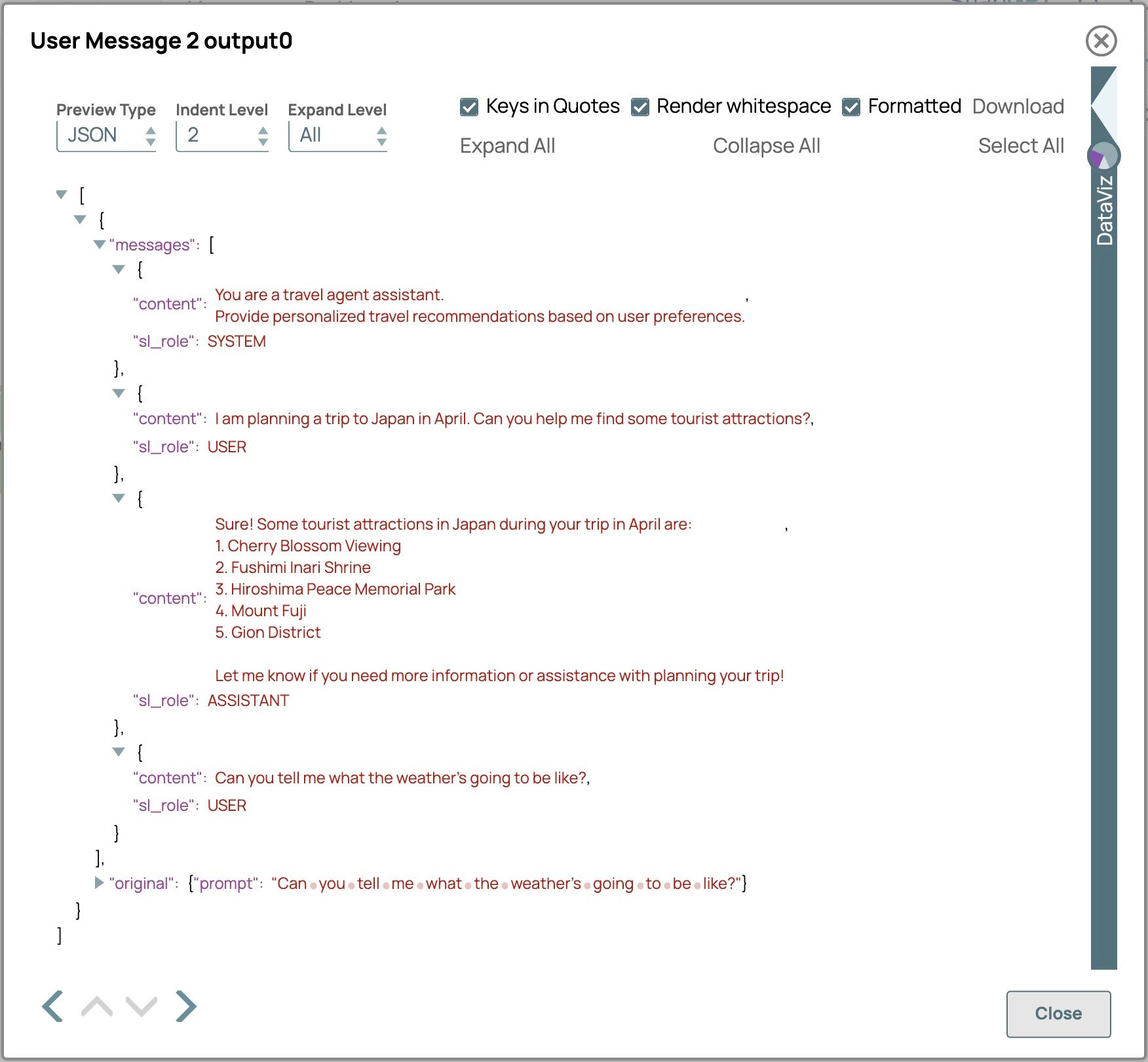
- Clicca sulla vista di output di "Messaggio utente 2" per visualizzare il payload del messaggio, che abbiamo creato utilizzando la modalità avanzata dello snap generatore di prompt.
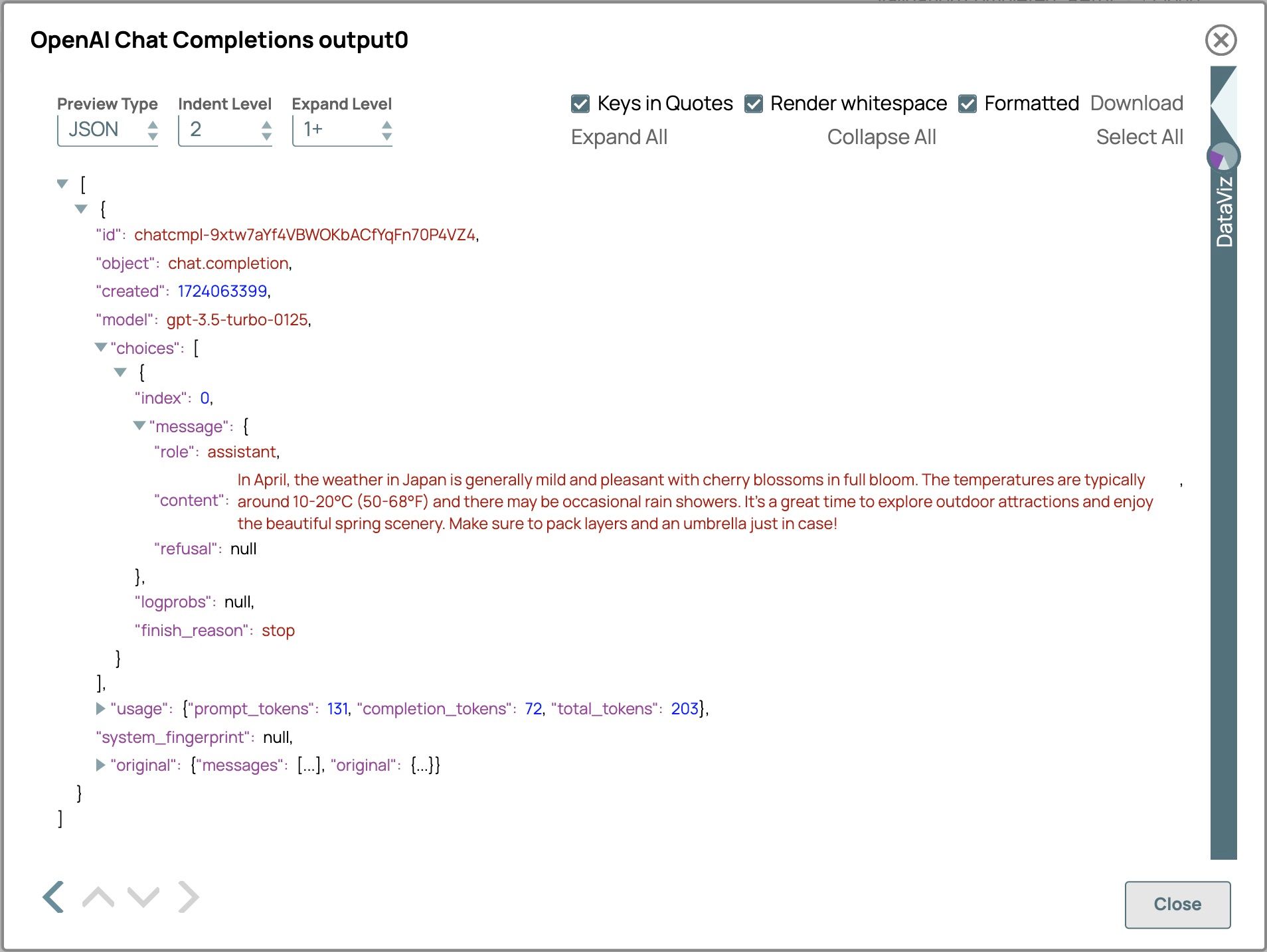
- Clicca sulla vista di output dello snap "Chat Completion" per vedere la risposta LLM.
- Clicca sulla vista di output di "Messaggio utente 2" per visualizzare il payload del messaggio, che abbiamo creato utilizzando la modalità avanzata dello snap generatore di prompt.
Il risultato è:
Ad aprile, il clima in Giappone è generalmente mite e piacevole, con i ciliegi in piena fioritura. Le temperature si aggirano solitamente intorno ai 10-20 °C (50-68 °F) e possono verificarsi occasionali rovesci di pioggia. È un ottimo periodo per esplorare le attrazioni all'aperto e godersi lo splendido scenario primaverile. Assicuratevi di portare con voi indumenti a strati e un ombrello, per ogni evenienza!
Il modello ha fornito informazioni meteorologiche efficaci per il Giappone nel mese di aprile, anche se l'ultima richiesta dell'utente non specificava né il luogo né l'ora. Ciò è possibile perché il modello utilizza l'intera cronologia delle conversazioni per comprendere il contesto e il flusso del dialogo. Inoltre, il modello ha ripetuto la domanda dell'utente prima di rispondere, mantenendo uno stile di conversazione coerente. Per ottenere i migliori risultati, assicurati che l'elenco dei messaggi sia completo e ben organizzato, poiché ciò aiuterà l'LLM a generare risposte più pertinenti e coerenti, migliorando la qualità dell'interazione.
Gettoni
I token sono unità di testo, incluse parole, set di caratteri o combinazioni di parole e punteggiatura, che i modelli linguistici utilizzano per elaborare e generare il linguaggio. Possono variare da singoli caratteri o segni di punteggiatura a parole intere o parti di parole, a seconda del modello. Ad esempio, la parola "artificial" potrebbe essere suddivisa in token come "art", "ifi" e "cial". Il numero totale di token in un prompt influisce sulla capacità di risposta del modello. Ogni modello ha un limite massimo di token, che include sia l'input che l'output. Ad esempio, GPT-3.5-Turbo ha un limite di 4.096 token, mentre GPT-4 ha limiti di 8.192 token e 32.768 token per la versione con contesto 32k. Una gestione efficace dei token garantisce che le risposte rimangano entro questi limiti, migliorando l'efficienza, riducendo i costi e aumentando la precisione.
Per gestire efficacemente l'utilizzo dei token, il parametro dei token massimi è essenziale. Esso imposta un limite al numero di token che il modello può generare, garantendo che il totale combinato di input e output rimanga entro la capacità del modello. L'impostazione di un parametro di token massimi offre diversi vantaggi: impedisce che le risposte diventino eccessivamente lunghe, riduce i tempi di risposta generando output più concisi, ottimizza le prestazioni e minimizza i costi controllando l'utilizzo dei token. Inoltre, migliora l'esperienza dell'utente fornendo risposte chiare, mirate e più rapide.
Esempi di casi d'uso:
- Chatbot per l'assistenza clienti:impostando un numero massimo di token, è possibile garantire che le risposte del chatbot siano concise e mirate, fornendo risposte rapide e pertinenti alle richieste degli utenti senza sovraccaricarli con dettagli eccessivi. Ciò migliora l'esperienza dell'utente e mantiene efficienti le interazioni.
- Sintesi dei contenuti:aiuta a generare sintesi concise di testi lunghi, adatte ad applicazioni con limiti di spazio, come app mobili o notifiche.
- Narrazione interattiva:controlla la lunghezza dei segmenti narrativi o delle opzioni di dialogo, mantenendo una narrazione coinvolgente e ben ritmata.
- Descrizioni dei prodotti:generare descrizioni dei prodotti concise ed efficaci per le piattaforme di e-commerce, mantenendo la pertinenza e rispettando i limiti di spazio.
Vediamo come configurare il numero massimo di token nello snap SnapLogic Chat Completion utilizzando il prompt: "Descrivi la fotosintesi in termini semplici". Vedremo come si comporta l'LLM con e senza l'impostazione del numero massimo di token.
- Trascina "OpenAI Chat Completion" o "Azure OpenAI Chat Completion" o "Google Gemini Generate" sulla tela.
- Seleziona la scheda "Account" e seleziona l'account configurato.
- Selezionare la scheda "Impostazioni"
- Seleziona il modello che preferisci utilizzare
- Imposta il prompt sul messaggio "Descrivi la fotosintesi in termini semplici".
Le impostazioni di completamento chat dovrebbero ora apparire così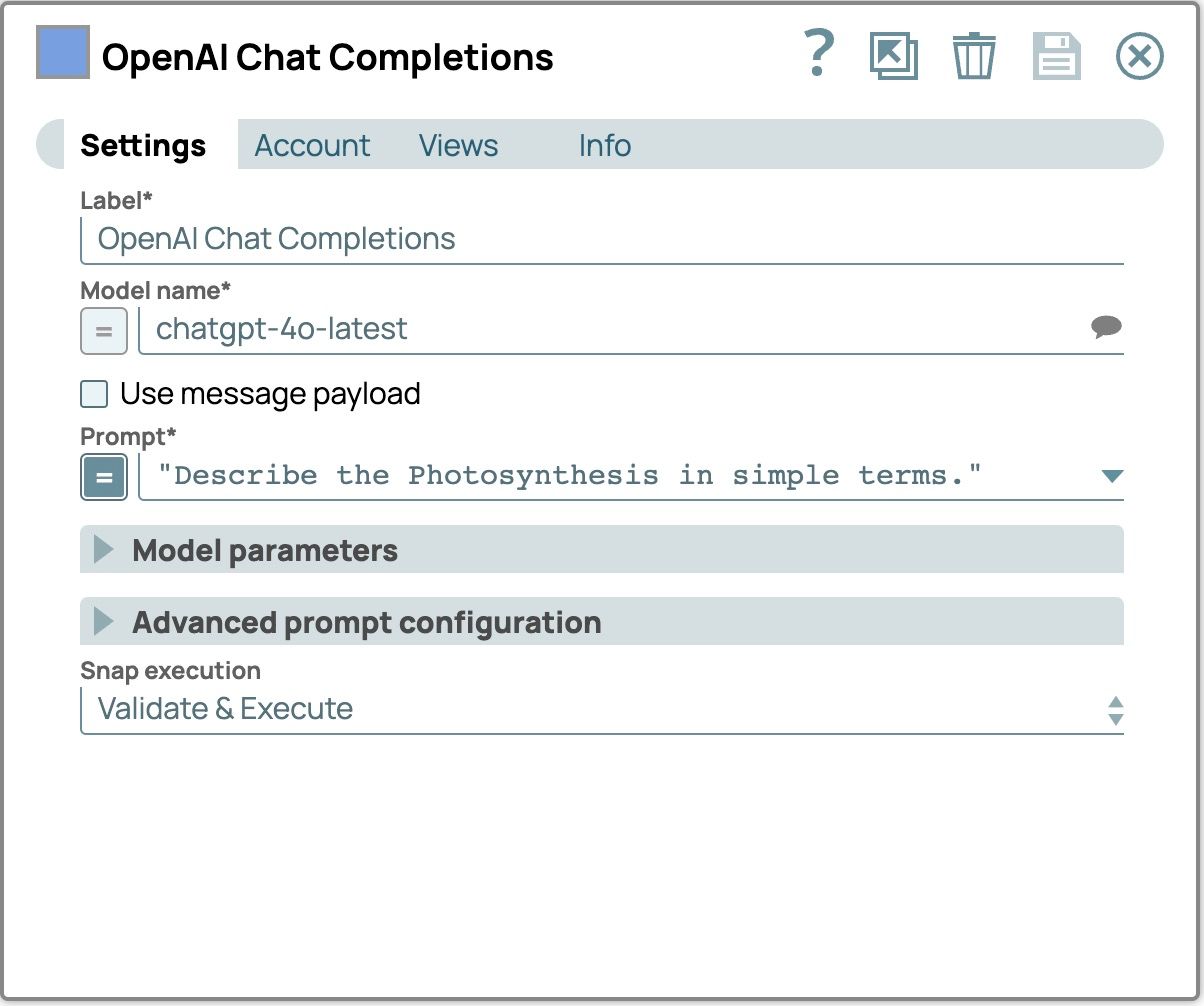
- Salva le impostazioni dello snap e convalida la pipeline per vedere il risultato.

Di conseguenza, il campo "utilizzo" ci fornisce i dettagli relativi al consumo dei token.
- Espandi i "Parametri del modello"
- Imposta "Token massimi" su 100
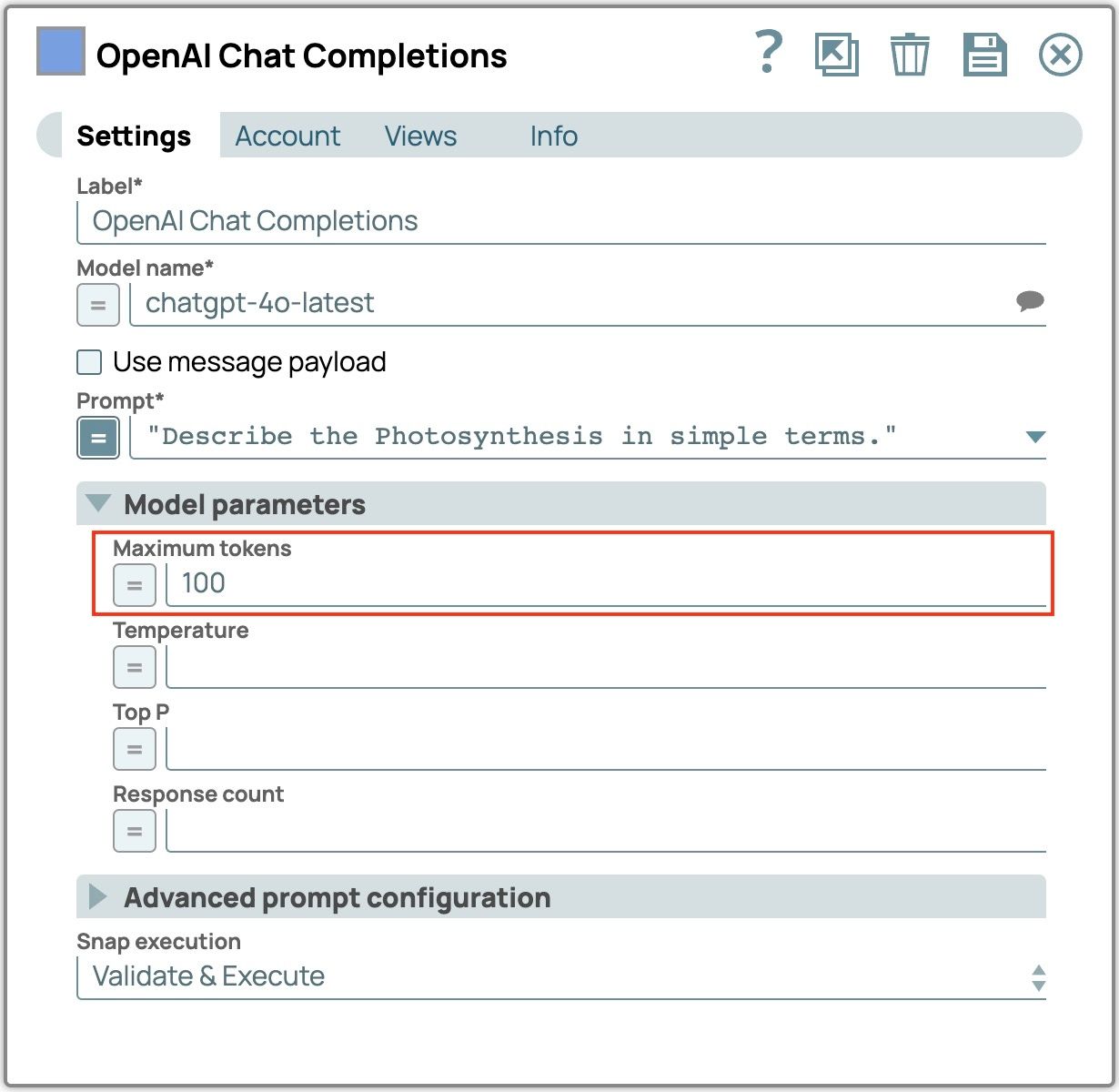
- Salva le impostazioni dello snap e convalida la pipeline per vedere il risultato.
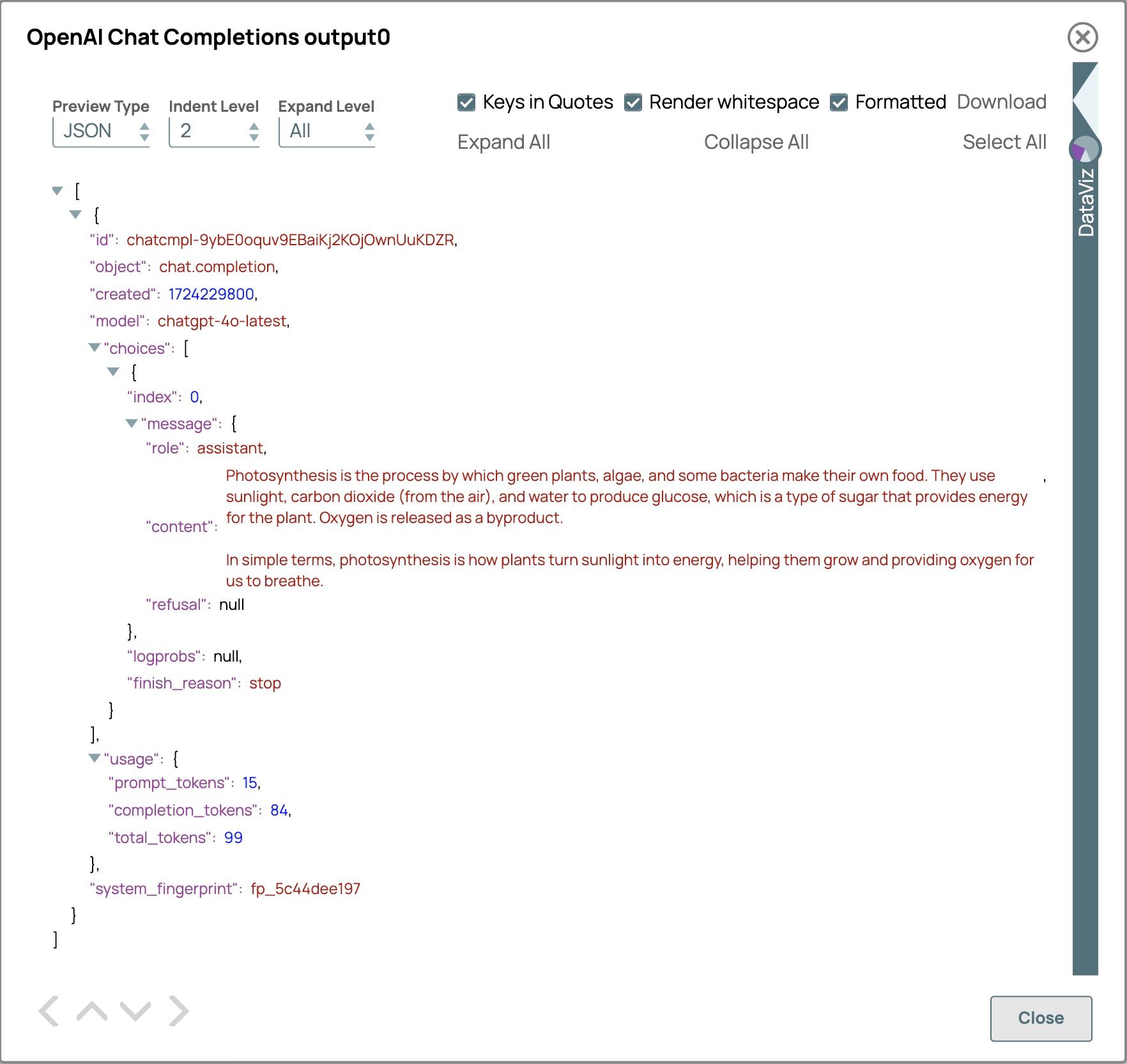
Il risultato è più conciso rispetto all'output ottenuto quando non è stato impostato il numero massimo di token. In questo caso, il numero di completion_tokens utilizzati è solo 84, il che indica una risposta più breve e mirata.
L'uso efficace dei token massimi garantisce che le risposte siano concise e pertinenti, ottimizzando sia le prestazioni che l'efficienza in termini di costi. Impostando questo limite, è possibile evitare output eccessivamente lunghi, ridurre i tempi di risposta e mantenere la chiarezza dei contenuti generati. Per ottenere risultati ottimali, allineare l'impostazione dei token massimi alle proprie esigenze specifiche, come la lunghezza desiderata della risposta e i requisiti dell'applicazione. Rivedere e regolare regolarmente questo parametro per bilanciare la brevità con la completezza, assicurando che gli output rimangano utili e rientrino nei vincoli operativi.
Considerazioni sulle dimensioni del prompt
Nella sezione precedente abbiamo trattato le tecniche per gestire la dimensione delle risposte in modo da rimanere entro i limiti dei token. Ora ci concentreremo sulle considerazioni relative alla dimensione dei prompt e al contesto. Assicurandovi che sia i prompt che il contesto abbiano dimensioni adeguate, potrete migliorare l'accuratezza e la pertinenza delle risposte del modello rimanendo entro i limiti dei token.
Ecco alcune tecniche per gestire la dimensione dei prompt e del contesto:
- Mantieni le istruzioni chiare e concise
Rendendo i prompt chiari e diretti, si riduce l'utilizzo dei token, il che aiuta a mantenere il prompt entro i limiti del modello. Concentrarsi sulle informazioni essenziali e rimuovere le parole superflue migliora l'accuratezza e la pertinenza delle risposte del modello. Inoltre, specificare la lunghezza desiderata dell'output ottimizza ulteriormente l'interazione, evitando risposte eccessivamente lunghe e migliorando l'efficienza complessiva.Esempio di prompt:"Potresti fornire una spiegazione dettagliata di come funziona il processo di fotosintesi nelle piante, compresi i ruoli della clorofilla, della luce solare e dell'acqua?"Promptmigliore:"Spiega il processo di fotosintesi nelle piante, compresi i ruoli della clorofilla, della luce solare e dell'acqua, in circa 50 parole."
- Suddividere compiti complessi in istruzioni più semplici
Suddividere compiti complessi in sotto-compiti più piccoli e gestibili non solo riduce la dimensione di ogni singolo prompt, ma consente anche al modello di elaborare ogni parte in modo più efficiente. Questo approccio garantisce che ogni prompt rimanga entro i limiti dei token, con conseguenti risposte più chiare e accurate.Esempio di compito complesso:
Prompt semplificati:
"Scrivi una relazione dettagliata sull'impatto economico dei cambiamenti climatici nei paesi in via di sviluppo, includendo analisi statistiche, casi di studio e raccomandazioni politiche".Riassumi l'impatto economico dei cambiamenti climatici nei paesi in via di sviluppo.
- "Fornire un'analisi statistica di come i cambiamenti climatici influenzano l'agricoltura nei paesi in via di sviluppo".
- "Elenca casi di studio che dimostrano le conseguenze economiche dei cambiamenti climatici nei paesi in via di sviluppo".
- "Proporre raccomandazioni politiche per mitigare l'impatto economico dei cambiamenti climatici nei paesi in via di sviluppo".
- Utilizza una finestra scorrevole per la cronologia delle chat
Dalla sezione dedicata ai prompt complessi, sappiamo che includere l'intera cronologia delle chat aiuta a mantenere il contesto, ma può anche esaurire rapidamente i token disponibili. Per ottimizzare le dimensioni del prompt, utilizza un approccio a finestra scorrevole. Questa tecnica prevede di includere solo una parte della cronologia delle chat, concentrandosi sugli scambi recenti e rilevanti, per mantenere il prompt entro i limiti dei token. - Riassumi i contesti
Utilizza una tecnica di sintesi per condensare il contesto in un breve riassunto. Invece di includere una cronologia dettagliata della conversazione, crea un riassunto conciso che catturi le informazioni essenziali. Questo approccio riduce l'utilizzo di token, pur conservando i dettagli chiave per generare risposte accurate.
Applicando queste tecniche, è possibile gestire in modo efficace la dimensione dei prompt e del contesto, garantendo che le interazioni rimangano efficienti e pertinenti, ottimizzando al contempo l'utilizzo dei token.




