






Perché abbiamo bisogno dell'osservabilità LLM?
Le applicazioni GenAI sono fantastiche, rispondono proprio come farebbe un essere umano. Ma come si fa a sapere se GPT non sta essendo "troppo creativo" quando i risultati dell'LLM mostrano che "le finanze dell'azienda stanno affrontando problemi a causa di una copertura solare insufficiente"?
Man mano che l'ambito delle app GenAI si amplia, la vulnerabilità aumenta e, poiché i risultati dell'LLM non sono deterministici, una configurazione che una volta funzionava non è garantita che funzioni sempre. Ecco un esempio di confronto tra i motivi per cui un prompt LLM fallisce e quelli per cui un'applicazione RAG fallisce.
Cosa potrebbe andare storto nella configurazione?
Suggerimenti LLM
- Parametri del modello non ottimali
- Temperatura troppo alta / gettoni troppo piccoli
- Messaggi di sistema non informativi
RAG
- Indicizzazione
- I dati non sono stati suddivisi in blocchi della dimensione corretta, le informazioni sono scarse e la finestra è piccola.
- È stata utilizzata una distanza errata. È stata utilizzata la distanza euclidea invece della distanza coseno.
- La dimensione era troppo piccola / troppo grande
- Recupero
- Top K troppo grande, troppo contesto irrilevante recuperato
- Top K troppo piccolo, contesto non abbastanza rilevante per generare risultati
- Filtro utilizzato in modo improprio
- E tutto ciò che è contenuto nei prompt LLM
Sebbene l'osservabilità non risolva magicamente tutti i problemi, ci offre una buona opportunità per capire cosa potrebbe essere andato storto. LLM Observability fornisce metodologie che aiutano gli sviluppatori a comprendere meglio le applicazioni LLM, le prestazioni dei modelli e i bias, e può aiutare a risolvere i problemi prima che raggiungano gli utenti finali.
Quali sono i problemi più comuni e in che modo l'osservabilità può essere d'aiuto?
L'osservabilità aiuta la comprensione in molti modi, dai colli di bottiglia delle prestazioni al rilevamento degli errori, alla sicurezza e al debug. Ecco un elenco di domande comuni che potremmo porci e come l'osservabilità può tornare utile.
- Quanto tempo occorre per generare una risposta?
- Monitorare i tempi di risposta dell'LLM e i tempi di query del database aiuta a identificare potenziali colli di bottiglia dell'applicazione.
- Il contesto recuperato dal database vettoriale è pertinente?
- La registrazione delle query del database e dei risultati recuperati aiuta a identificare le query più performanti.
- Può fornire assistenza nella configurazione delle dimensioni dei blocchi in base ai risultati recuperati.
- Quanti token vengono utilizzati in una chiamata?
- Il monitoraggio dell'utilizzo dei token può aiutare a determinare il costo di ogni chiamata LLM.
- Quanto è migliore/peggiore la mia nuova configurazione?
- Il monitoraggio dei parametri e la registrazione delle risposte aiutano a confrontare le prestazioni di diversi modelli e configurazioni di modelli.
- Come sta funzionando complessivamente l'applicazione GenAI?
- Il monitoraggio delle fasi di applicazione e valutazione aiuta a identificare le prestazioni dell'applicazione.
- Cosa chiedono gli utenti?
- La registrazione e l'analisi dei prompt degli utenti aiutano a comprendere le loro esigenze e possono contribuire a valutare se è possibile introdurre ottimizzazioni per ridurre i costi.
- Aiuta a identificare le vulnerabilità di sicurezza monitorando i tentativi dannosi e contribuisce a rispondere in modo proattivo per mitigare le minacce.
Cosa dovrebbe essere monitorato?
Le applicazioni GenAI coinvolgono componenti concatenati tra loro. A seconda del caso d'uso, ci sono eventi e parametri di input/output che vogliamo acquisire e analizzare.
Elenco dei componenti da considerare:
Metadati del database vettoriale
- Dimensione vettoriale: la dimensione vettoriale utilizzata nel database vettoriale.
- Funzione di distanza: il modo in cui vengono confrontati due vettori nel database vettoriale
Parametri di indicizzazione vettoriale
- Configurazione dei blocchi: come è configurato un blocco, comprese le dimensioni del blocco, l'unità dei blocchi, ecc. Ciò influisce sulla densità delle informazioni in un blocco.
Parametri di query vettoriale
- Query: query utilizzata per recuperare il contesto dal database vettoriale.
- Top K: il numero massimo di vettori da recuperare dal database dei vettori
Modelli di prompt
- Richiesta di sistema: la richiesta da utilizzare nell'intera applicazione
- Modello di prompt: il modello utilizzato per costruire un prompt. I prompt funzionano in modo diverso a seconda dei modelli e dei fornitori di LLM.
Metadati della richiesta LLM
- Prompt: L'input inviato al modello LLM da ciascun utente finale, combinato con il modello.
- Nome del modello: il modello LLM utilizzato per la generazione, che influisce sulle capacità dell'applicazione.
- Token: il numero massimo di token consentiti per una singola richiesta
- Temperatura: il parametro per impostare la creatività e la casualità del modello
- Top P: La gamma di selezione delle parole, minore è il valore, più ristretta è la selezione delle parole campionate.
Metadati di risposta LLM
- Token: il numero di token utilizzati nella generazione di input e output influisce sui costi.
- Dettagli della richiesta: possono includere informazioni quali guardrail, ID della richiesta, ecc.
Metriche di esecuzione
- Tempo di esecuzione: tempo impiegato per elaborare le singole richieste
Esempi di pipeline
Registrazione di una pipeline di completamenti chat

Utilizziamo MongoDB per archiviare i parametri del modello e le risposte LLM come documenti JSON per facilitarne l'elaborazione.
Registrazione di una pipeline RAG
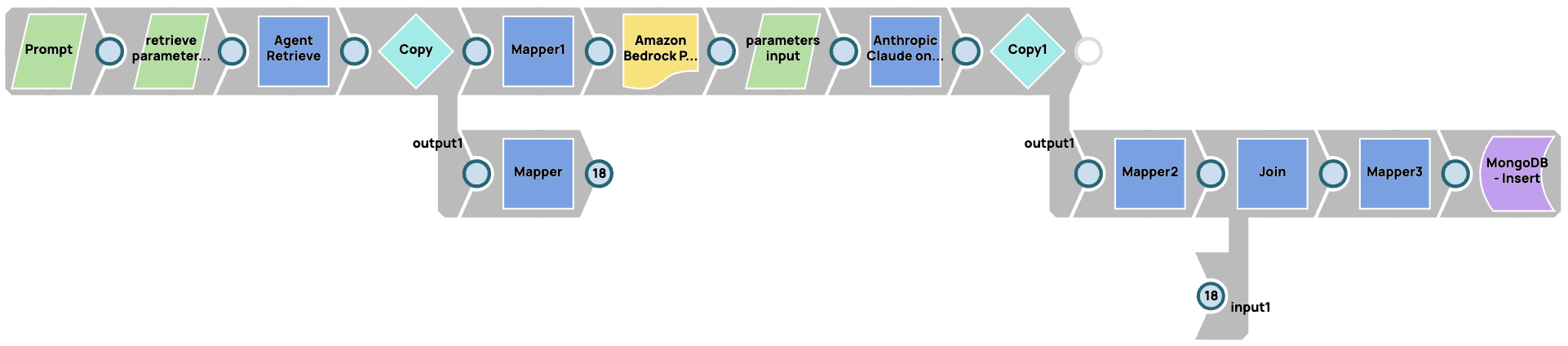
In questo caso, stiamo memorizzando i parametri nel sistema RAG (Agent Retrieve in questo caso) e nel modello. Stiamo utilizzando JSON Generator Snaps per parametrizzare tutti i parametri di input nel sistema RAG e nei modelli LLM. Quindi concateniamo la risposta dal database vettoriale, dal modello LLM e dai parametri che abbiamo fornito per le richieste.






