






Pourquoi avons-nous besoin de l'observabilité LLM ?
Les applications GenAI sont formidables, elles répondent comme le ferait un être humain. Mais comment savoir si GPT n'est pas « trop créatif » lorsque les résultats du LLM indiquent que « les finances de l'entreprise sont en difficulté en raison d'une couverture solaire insuffisante » ?
À mesure que le champ d'application des applications GenAI s'élargit, leur vulnérabilité augmente, et comme les résultats du LLM ne sont pas déterministes, une configuration qui fonctionnait auparavant n'est pas garantie de toujours fonctionner. Voici un exemple comparant les raisons pour lesquelles une invite LLM échoue et celles pour lesquelles une application RAG échoue.
Qu'est-ce qui pourrait mal tourner dans la configuration ?
Invites LLM
- Paramètres de modèle sous-optimaux
- Température trop élevée / jetons trop petits
- Messages système peu informatifs
RAG
- Indexation
- Les données n'étaient pas fragmentées à la bonne taille, les informations sont rares et la fenêtre est petite.
- Une distance incorrecte a été utilisée. Utilisation de la distance euclidienne au lieu de la distance cosinus.
- La dimension était trop petite / trop grande
- Récupération
- Top K trop grand, trop de contexte non pertinent récupéré
- Top K trop petit, contexte pertinent insuffisant pour générer un résultat
- Filtre mal utilisé
- Et tout ce qui se trouve dans LLM Prompts
Bien que l'observabilité ne résolve pas comme par magie tous les problèmes, elle nous offre une bonne occasion de comprendre ce qui a pu mal tourner. LLM Observability fournit des méthodologies qui aident les développeurs à mieux comprendre les applications LLM, les performances des modèles et les biais, et peut aider à résoudre les problèmes avant qu'ils n'atteignent les utilisateurs finaux.
Quels sont les problèmes courants et comment l'observabilité peut-elle aider ?
L'observabilité facilite la compréhension à bien des égards, qu'il s'agisse des goulots d'étranglement au niveau des performances, de la détection des erreurs, de la sécurité ou du débogage. Voici une liste de questions courantes que nous pourrions nous poser et comment l'observabilité peut s'avérer utile.
- Combien de temps faut-il pour générer une réponse ?
- La surveillance des temps de réponse LLM et des temps de requête de base de données permet d'identifier les goulots d'étranglement potentiels de l'application.
- Le contexte extrait de la base de données vectorielle est-il pertinent ?
- L'enregistrement des requêtes et des résultats récupérés dans la base de données permet d'identifier les requêtes les plus performantes.
- Peut aider à configurer la taille des blocs en fonction des résultats récupérés.
- Combien de jetons sont utilisés dans un appel ?
- La surveillance de l'utilisation des jetons peut aider à déterminer le coût de chaque appel LLM.
- Ma nouvelle configuration est-elle plus performante ou moins performante ?
- La surveillance des paramètres et l'enregistrement des réponses permettent de comparer les performances de différents modèles et configurations de modèles.
- Comment fonctionne l'application GenAI dans l'ensemble ?
- Le suivi des étapes de l'application et de l'évaluation permet d'identifier les performances de l'application.
- Que demandent les utilisateurs ?
- L'enregistrement et l'analyse des invites utilisateur permettent de comprendre les besoins des utilisateurs et peuvent aider à évaluer si des optimisations peuvent être mises en place pour réduire les coûts.
- Aide à identifier les failles de sécurité en surveillant les tentatives malveillantes et aide à réagir de manière proactive pour atténuer les menaces.
Que faut-il suivre ?
Les applications GenAI impliquent des composants reliés entre eux. Selon le cas d'utilisation, il existe des événements et des paramètres d'entrée/sortie que nous souhaitons capturer et analyser.
Liste des éléments à prendre en considération :
Métadonnées de la base de données vectorielle
- Dimension vectorielle: dimension vectorielle utilisée dans la base de données vectorielle.
- Fonction de distance: la manière dont deux vecteurs sont comparés dans la base de données vectorielle.
Paramètres d'indexation vectorielle
- Configuration des blocs: comment un bloc est configuré, y compris sa taille, l'unité des blocs, etc. Cela affecte la densité d'informations dans un bloc.
Paramètres de requête vectorielle
- Requête: requête utilisée pour récupérer le contexte à partir de la base de données vectorielle.
- Top K: nombre maximal de vecteurs à extraire de la base de données vectorielle.
Modèles de messages
- Invite système: invite à utiliser dans toute l'application.
- Modèle d'invite: modèle utilisé pour créer une invite. Les invites fonctionnent différemment selon les modèles et les fournisseurs de LLM.
Métadonnées de demande LLM
- Invite: les données envoyées au modèle LLM par chaque utilisateur final, combinées au modèle.
- Nom du modèle: modèle LLM utilisé pour la génération, qui influe sur les capacités de l'application.
- Jetons: nombre maximal de jetons pour une seule requête
- Température: paramètre permettant de définir la créativité et le caractère aléatoire du modèle.
- Top P: Plage de sélection des mots. Plus la valeur est petite, plus la sélection de mots échantillonnée est restreinte.
Métadonnées de réponse LLM
- Jetons: le nombre de jetons utilisés dans la génération d'entrées et de sorties influe sur les coûts.
- Détails de la demande: peuvent inclure des informations telles que les garde-corps, l'identifiant de la demande, etc.
Indicateurs d'exécution
- Temps d'exécution: temps nécessaire pour traiter chaque requête
Exemples de pipelines
Enregistrement d'un pipeline de terminaisons de chat

Nous utilisons MongoDB pour stocker les paramètres du modèle et les réponses LLM sous forme de documents JSON afin de faciliter leur traitement.
Enregistrement d'un pipeline RAG
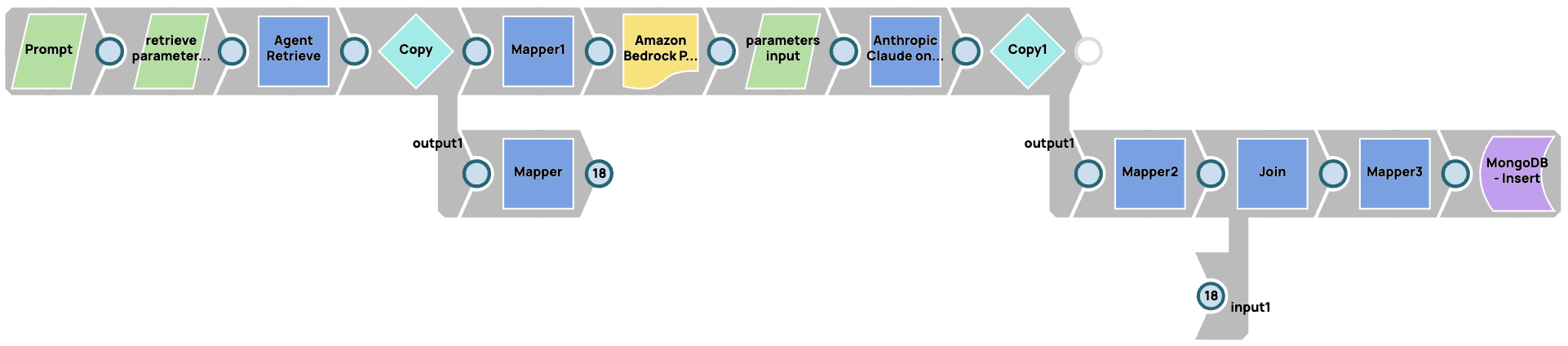
Dans ce cas, nous stockons les paramètres dans le système RAG (Agent Retrieve dans ce cas) et le modèle. Nous utilisons JSON Generator Snaps pour paramétrer tous les paramètres d'entrée du système RAG et des modèles LLM. Nous concaténons ensuite la réponse de la base de données vectorielle, du modèle LLM et des paramètres que nous avons fournis pour les requêtes.






