






Warum brauchen wir LLM-Beobachtbarkeit?
GenAI-Anwendungen sind großartig, sie antworten wie ein Mensch. Aber woher wissen Sie, ob GPT nicht „zu kreativ” für Sie ist, wenn die Ergebnisse des LLM zeigen, dass „die Finanzen des Unternehmens aufgrund unzureichender Sonneneinstrahlung Probleme haben”?
Mit der Erweiterung des Anwendungsbereichs von GenAI-Apps wächst auch die Anfälligkeit, und da die Ergebnisse des LLM nicht deterministisch sind, ist nicht garantiert, dass eine einmal funktionierende Konfiguration immer funktioniert. Hier ist ein Beispiel für einen Vergleich der Gründe, warum eine LLM-Eingabe fehlschlägt, mit den Gründen, warum eine RAG-Anwendung fehlschlägt.
Was könnte bei der Konfiguration schiefgehen?
LLM-Eingabeaufforderungen
- Suboptimale Modellparameter
- Temperatur zu hoch / Token zu klein
- Uninformative Systemaufforderungen
RAG
- Indizierung
- Die Daten wurden nicht in der richtigen Größe aufgeteilt, die Informationen sind spärlich, und das Fenster ist klein.
- Es wurde die falsche Distanz verwendet. Es wurde die euklidische Distanz anstelle der Kosinusdistanz verwendet.
- Die Abmessungen waren zu klein/zu groß.
- Wiederauffinden
- Top K zu groß, zu viel irrelevanter Kontext abgerufen
- Top K zu klein, nicht genügend relevanter Kontext, um ein Ergebnis zu generieren
- Filter missbräuchlich verwendet
- Und alles in LLM-Prompts
Obwohl Observability nicht alle Probleme auf magische Weise löst, bietet es uns eine gute Möglichkeit, herauszufinden, was möglicherweise schiefgelaufen ist. LLM Observability bietet Methoden, die Entwicklern helfen, LLM-Anwendungen, Modellleistungen und Verzerrungen besser zu verstehen, und kann dazu beitragen, Probleme zu lösen, bevor sie die Endbenutzer erreichen.
Was sind häufige Probleme und wie hilft Observability dabei?
Beobachtbarkeit hilft in vielerlei Hinsicht beim Verständnis, von Leistungsengpässen bis hin zur Fehlererkennung, Sicherheit und Fehlerbehebung. Hier ist eine Liste häufig gestellter Fragen, die wir uns stellen könnten, und wie Beobachtbarkeit dabei hilfreich sein kann.
- Wie lange dauert es, bis eine Antwort generiert wird?
- Die Überwachung der LLM-Reaktionszeiten und Datenbankabfragezeiten hilft dabei, potenzielle Engpässe der Anwendung zu identifizieren.
- Ist der aus der Vektordatenbank abgerufene Kontext relevant?
- Das Protokollieren von Datenbankabfragen und den abgerufenen Ergebnissen hilft dabei, leistungsstärkere Abfragen zu identifizieren.
- Kann bei der Konfiguration der Chunk-Größe auf Grundlage der abgerufenen Ergebnisse helfen.
- Wie viele Token werden bei einem Anruf verwendet?
- Die Überwachung der Token-Nutzung kann dabei helfen, die Kosten für jeden LLM-Aufruf zu ermitteln.
- Wie viel besser/schlechter ist meine neue Konfiguration?
- Die Parameterüberwachung und Protokollierung von Reaktionen hilft beim Vergleich der Leistung verschiedener Modelle und Modellkonfigurationen.
- Wie ist die Gesamtleistung der GenAI-Anwendung?
- Das Verfolgen der Phasen der Anwendung und Bewertung hilft dabei, die Leistung der Anwendung zu ermitteln.
- Was fragen die Nutzer?
- Das Protokollieren und Analysieren von Benutzeraufforderungen hilft dabei, die Bedürfnisse der Benutzer zu verstehen, und kann dabei helfen, zu beurteilen, ob Optimierungen zur Kostensenkung eingeführt werden können.
- Hilft bei der Identifizierung von Sicherheitslücken, indem es böswillige Versuche überwacht und dabei hilft, proaktiv zu reagieren, um Bedrohungen zu mindern.
Was sollte nachverfolgt werden?
GenAI-Anwendungen bestehen aus miteinander verketteten Komponenten. Je nach Anwendungsfall gibt es Ereignisse und Eingabe-/Ausgabeparameter, die wir erfassen und analysieren möchten.
Eine Liste der zu berücksichtigenden Komponenten:
Metadaten der Vektordatenbank
- Vektordimension: Die in der Vektordatenbank verwendete Vektordimension
- Distanzfunktion: Die Art und Weise, wie zwei Vektoren in der Vektordatenbank verglichen werden
Vektor-Indizierungsparameter
- Chunk-Konfiguration: Wie ein Chunk konfiguriert ist, einschließlich der Größe des Chunks, der Einheit der Chunks usw. Dies wirkt sich auf die Informationsdichte in einem Chunk aus.
Vektorabfrageparameter
- Abfrage: Die Abfrage, die zum Abrufen des Kontexts aus der Vektordatenbank verwendet wird.
- Top K: Die maximale Anzahl von Vektoren, die aus der Vektordatenbank abgerufen werden sollen.
Eingabeaufforderungsvorlagen
- Systemaufforderung: Die Aufforderung, die in der gesamten Anwendung verwendet werden soll.
- Prompt-Vorlage: Die Vorlage, die zum Erstellen eines Prompts verwendet wird. Prompts funktionieren in verschiedenen Modellen und bei verschiedenen LLM-Anbietern unterschiedlich.
LLM-Anfrage-Metadaten
- Eingabeaufforderung: Die von jedem Endbenutzer an das LLM-Modell gesendete Eingabe, kombiniert mit der Vorlage
- Modellname: Das für die Generierung verwendete LLM-Modell, das die Leistungsfähigkeit der Anwendung beeinflusst.
- Tokens: Die Anzahl der Tokens, die für eine einzelne Anfrage begrenzt sind
- Temperatur: Der Parameter zum Einstellen der Kreativität und Zufälligkeit des Modells
- Top P: Der Bereich der Wortauswahl. Je kleiner der Wert, desto enger ist die Wortauswahl, aus der ausgewählt wird.
LLM-Antwort-Metadaten
- Tokens: Die Anzahl der bei der Eingabe- und Ausgabegenerierung verwendeten Tokens beeinflusst die Kosten.
- Anfragedetails: Kann Informationen wie Leitplanken, ID der Anfrage usw. enthalten.
Ausführungsmetriken
- Ausführungszeit: Zeit, die zur Bearbeitung einzelner Anfragen benötigt wird
Beispiele für Pipelines
Protokollierung einer Pipeline für abgeschlossene Chats

Wir verwenden MongoDB, um Modellparameter und LLM-Antworten als JSON-Dokumente zu speichern, um die Verarbeitung zu vereinfachen.
Protokollierung einer RAG-Pipeline
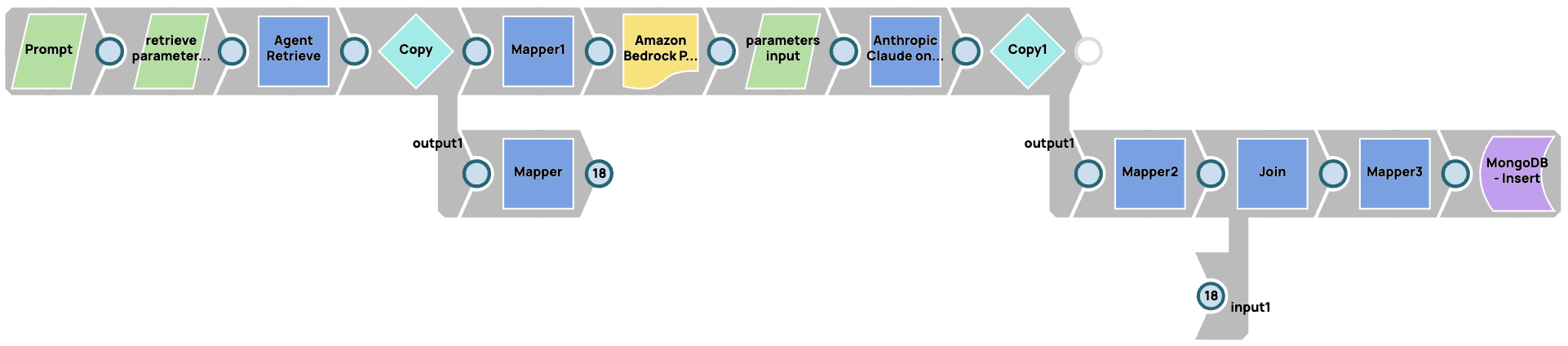
In diesem Fall speichern wir Parameter für das RAG-System (in diesem Fall Agent Retrieve) und das Modell. Wir verwenden JSON Generator Snaps, um alle Eingabeparameter für das RAG-System und die LLM-Modelle zu parametrisieren. Anschließend verknüpfen wir die Antwort aus der Vektordatenbank, dem LLM-Modell und den Parametern, die wir für die Anfragen bereitgestellt haben.






