





By Pavan Venkatesh
Data streams with Confluent and migration to Hadoop: In my previous blog post, I explained how future data movement trends will look. In this post, I’ll dig into some of the exciting things we announced as part of the Winter 2017 (4.8) Snaps release. This will also address future data movement trends for customers who want to move data to the cloud from different systems or migrate to Hadoop.
Major highlights in 2017 Winter release (4.8) include:
- Support of Confluent Kafka – A distributed messaging system for streaming data
- Teradata to Hadoop – A quick and easy way to migrate data
- Enhancements to the Teradata Snap Pack: On the TPT front, customers can quickly load/update/delete data in Teradata
- The RedShift Multi-Execute Snap – Allows multiple statements to be sequentially executed, so customers can maintain business logic
- Enhancements to the MongoDB Snap pack (Delete and Update) and the DynamoDB Snap pack (Delete and Delete-item)
- Workday Read output enhancements – Now it’s easier for the downstream systems to consume
- Netsuite Snap Pack improvements -Users can now submit asynchronous operations
- Security feature enhancements – Including SSL for MongoDB Snap Pack and invalidating database connection pools when account properties are modified
- Major performance improvement while writing to an S3 bucket using S3 File Writer – Users can now configure a buffer size in the Snap so larger blocks are sent to S3 quickly
Kafka is a distributed messaging system based on publish/subscribe model with high throughput and scalability. It is mainly used for ingestion from multiple sources and then sent to multiple downstream systems. Use cases include website activity tracking, fraud analytics, log aggregation, sales analytics, and others. Confluent is the company that provides the enterprise capability and offering for open source Kafka.
Here at SnapLogic we have built Kafka Producer and Consumer Snaps as part of the Confluent Snap Pack. A deep dive into Kafka architecture and its working will be a good segue before going into the Snap Pack or pipeline details.
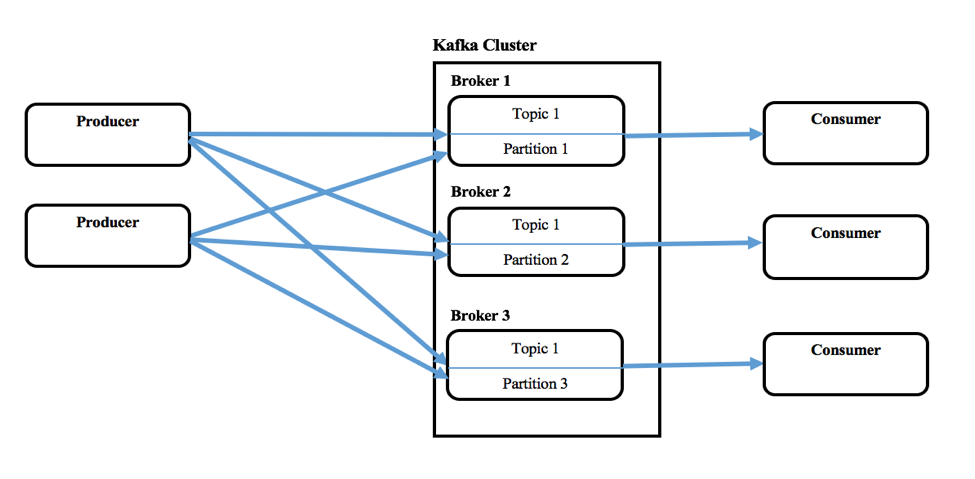
Kafka consists of single or multiple Producers that can produce messages from a single or multiple upstream systems, and single or multiple Consumers that consume messages as part of downstream systems. A Kafka cluster constitutes one or more servers called Brokers. Messages (key and value or just the value) will be fed into higher level abstraction called Topics. Each Topic can have multiple messages from different Producers. User can also define different Topics for new category of messages. These Producers write messages to Topics and Consumers consume from one or more Topics. Also Topics are partitioned, replicated, and persisted across Brokers. Messages in the Topics are ordered within a partition and each of these will have a sequential ID number called offset. Zookeeper usually maintains these offsets but Confluent calls it coordination kernel.
Kafka also allows configuring a Consumer group where multiple Consumers are part of it, when consuming from a Topic.
With over 400 Snaps supporting various on-prem (relational databases, files, nosql databases, and others) and cloud products (Netsuite, SalesForce, Workday, RedShift, Anaplan, and others), the Snaplogic Elastic Integration Cloud in combination with the Confluent Kafka Snap Pack will be a powerful combination for moving data to different systems in a fast and streaming manner. Customers can realize benefits and generate business outcomes in a quick manner.
With respect to the Confluent Kafka Snap Pack, we support Confluent Version 3.0.1 (Kafka v0.9). These Snaps abstract the complexities and users only have to provide configuration details to build a pipeline which moves data easily. One thing to note is that when multiple Consumer Snaps are used in a pipeline and have been configured with the same consumer group, then each Consumer Snap will be assigned a different subset of partitions in the Topic.
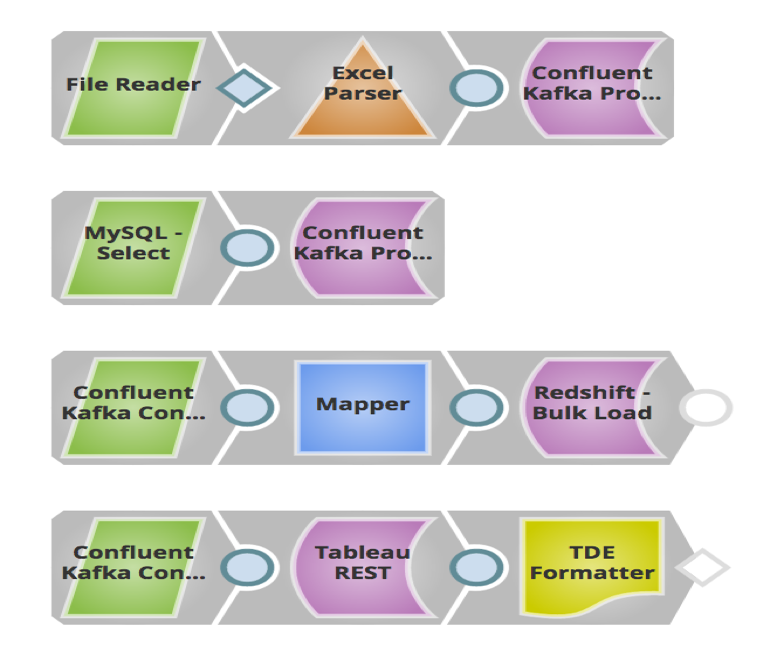
In the above example, I built a pipeline where sales leads (messages) stored in local files and MySQL are sent to a Topic in Confluent Kafka via Confluent Kafka Producer Snaps. The downstream system Redshift will consume these messages from that Topic via the Confluent Kafka Consumer Snap and bulk load it to RedShift for historical or auditing needs. These messages are also sent to Tableau as another Consumer to run analytics on how many leads were generated this year, so customer can compare this against last year.
Easy migrations from Teradata to Hadoop
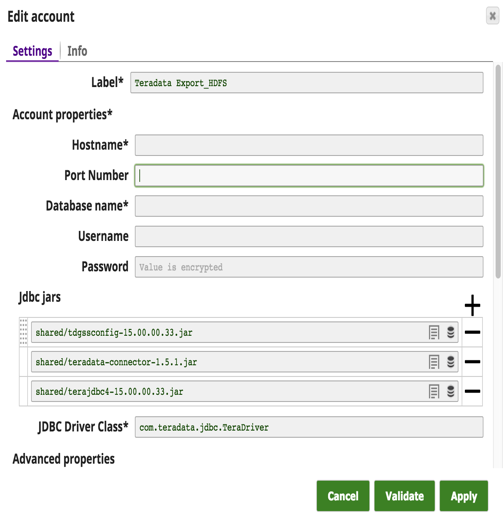
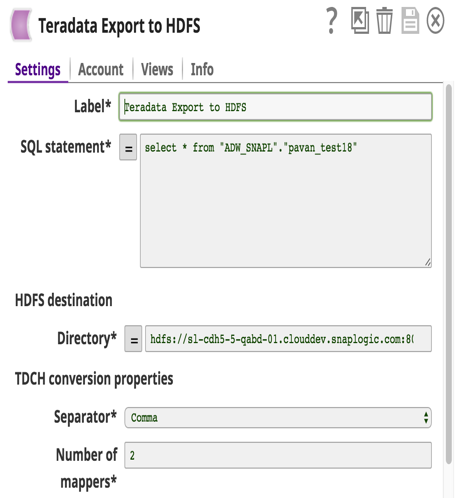
There has been a major shift where customers are moving from expensive Teradata solutions to Hadoop or other data warehouse. Until now, there has not been an easy solution in transferring large amounts of data from Teradata to big data Hadoop. With this release we have developed a Teradata Export to HDFS Snap with two goals in mind: 1) ease of use and 2) high performance. This Snap uses the Teradata Connector for Hadoop (TDCH v1.5.1). Customers just have to download this connector from the Teradata website in addition to the regular jdbc jars. No installation required on either Teradata or Hadoop nodes.
TDCH utilizes MapReduce (MR) as its execution engine where the queries gets submitted to this framework, and the distributed processes launched by the MapReduce framework make JDBC connections to the Teradata database. The data fetched will be directly loaded into the defined HDFS location. The degree of parallelism for these TDCH jobs is defined by the number of mappers (a Snap configuration) used by the MapReduce job. The number of mappers also defines the number of files created in HDFS location.
The Snap account details with a sample query to extract data from Teradata and load it to HDFS is shown below.
The pipeline to this effect is as follows:
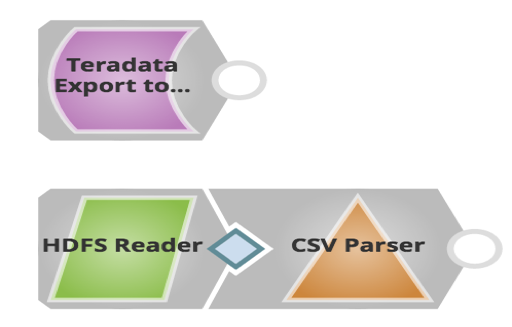
As you can see above, you use just one Snap to export data from Teradata and load it into HDFS. Customers can later use HDFS Reader Snap to read files that are exported.
Winter 2017 release has equipped customers with lots of benefits, from data streams, easy migrations, to enhancing security functionality, and performance benefits. More information on the SnapLogic Winter 2017 (4.8) release can be found in the release notes.
Pavan Venkatesh is Senior Product Manager at SnapLogic. Follow him on Twitter @pavankv.



