There’s a common situation that often occurs with enterprise AI deployments. A team connects an AI agent to Salesforce. They ask the agent a question about the sales pipeline. The agent writes a query, runs it, and returns nothing. Or worse, returns the wrong data confidently.
The problem is not the model. The problem is that the agent guessed your schema.
Every Salesforce org is different. Custom fields, custom objects, and custom naming conventions built up over the years by people who have since left. Forecast_Category__c in your org may not exist at all in the next. An agent that does not know your specific schema will make a guess, resulting in a failure rate.
This is the problem that MCP (Model Context Protocol) addresses, and it is worth understanding before evaluating any AI agent for enterprise use.
What MCP actually does
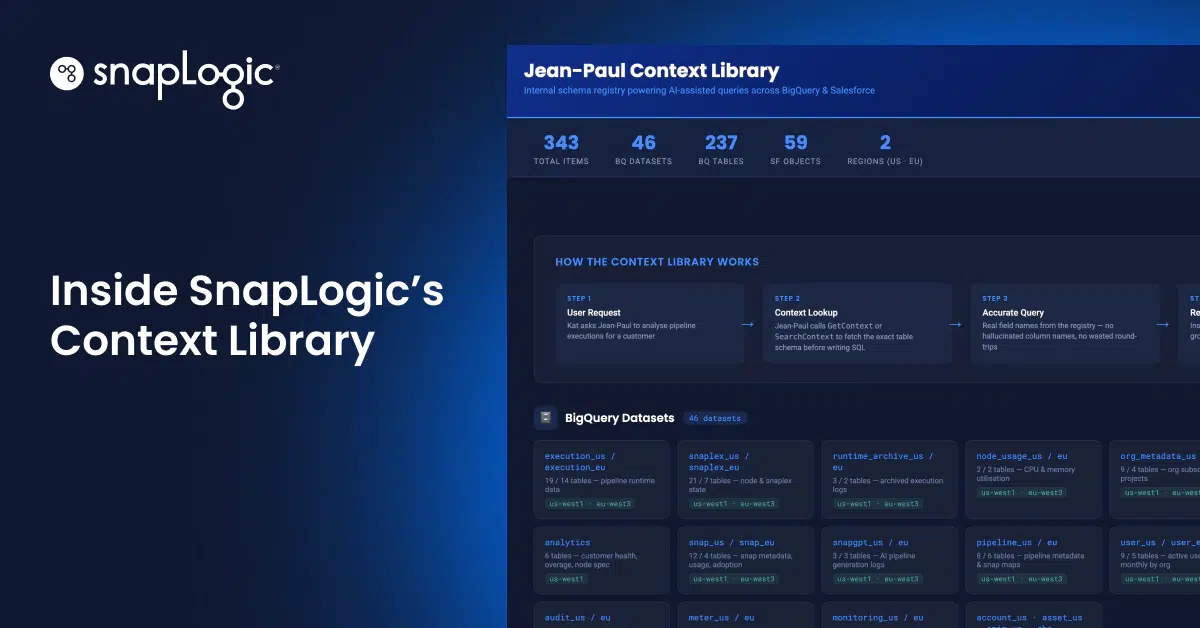
MCP is a standard for giving AI agents structured, queryable access to the context they need before they act.
In a well-built agentic system, the agent does not go straight to Salesforce when you ask a question. It reads first. It retrieves the relevant schema from a context library, checks what objects and fields actually exist in your environment, and then writes the query.
The result: queries succeed because they are written against your actual data structure, not a generic assumption about what Salesforce looks like.
When the agent encounters something it does not recognize, it says so. That matters as much as the queries that work. An agent that knows what it does not know is more useful than one that fills gaps with confident guesses.
A concrete example
At a recent SnapLogic User Group, we ran a live demo of a sales manager preparing for a rep 1:1. The ask was entirely in plain English: pipeline by stage, closed won deals for the quarter, open opportunities closing in the next 30 days, weighted Q3 forecast.
Before any of those queries ran, Jean-Paul read the Salesforce schema for that org. It retrieved the object definitions, the field names, and the custom forecast categories. That took a few seconds.
Then it ran four queries in parallel, all of which returned accurate data on the first attempt.
No trial and error. No hallucinated field names. No “I couldn’t find that” after 90 seconds of waiting.
The context read is what made that possible. It looks invisible in a demo because it happens before the answer appears. That invisibility is the point.
Why this matters for your evaluation
When you evaluate an AI agent for enterprise use, ask specifically about schema handling.
Questions worth asking:
- Does the agent read your actual schema before querying, or does it rely on training data and assumptions?
- What happens when a query fails? Does the agent retry with corrections, or does it surface the error?
- How is context kept current when your schema changes?
An agent without structured context access will work well in demos built on clean, familiar data structures. It will struggle in production, where the data is yours and the field names are anything but obvious.
MCP gives agents a reliable way to answer that first question correctly every time.Jean-Paul is SnapLogic’s enterprise AI agent platform. Contact us today for a demo.