





Agentic
Integration
Tips and Tricks
Join the agentic integration movement around the world and receive the SnapLogic Blog Newsletter.
By clicking on the button above, you agree to SnapLogic’s Terms, Privacy and Cookie Policies. You also agree to receive future communications from SnapLogic. You can unsubscribe anytime.
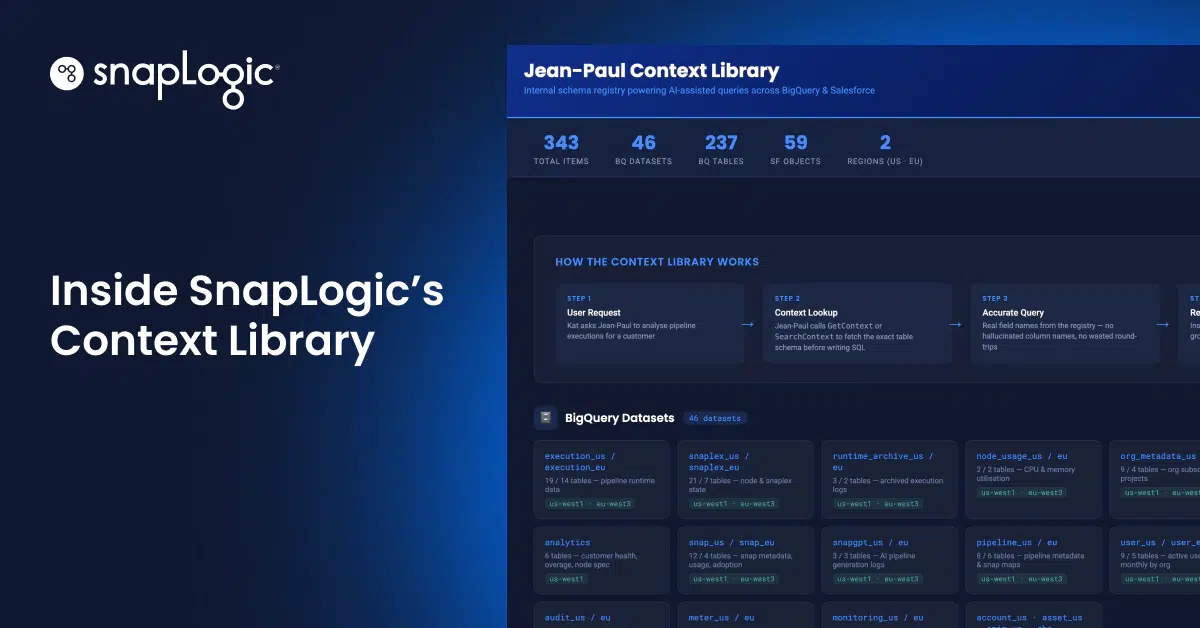


Search Results
-

5 min read
When To Use SnapLogic MCP Server vs. Enterprise MCP

-

4 min read
Build Enterprise Integrations Without Leaving Your AI Coding Environment
-

5 min read
10 Agentic Workflows Transforming Enterprise Automation in 2026

-

5 min read
The AI Agent Pre-Launch Checklist for Tech Leaders in Pharmaceuticals and Biotech
-

10 min read
SnapCode, SnapLogic MCP Server, and What’s New This Month
-

7 min read
Unstructured ETL: The Integration Approach Enterprise AI Demands
-
6 min read
Top 5 Benefits of Using an iPaaS with Native MCP Support
-
7 min read
The iPaaS Buyer’s Guide for Compliance-Driven Integration
-

6 min read
What It Takes to Build AI Agents for Production
-

5 min read
Why Higher Education AI Initiatives Stall (and How to Break the Cycle)
-
8 min read
The iPaaS Landscape for OEM and Embedded Integration: A Product Leader’s Guide
-

6 min read
What’s New in SnapLogic: June 2026 Release
Latest Posts
AI Posts
Data Posts



Product Posts
Company Update Posts


Integration Posts
-
4 min read
Build Enterprise Integrations Without Leaving Your AI Coding Environment
-

7 min read
AI Workflow Orchestration for Supply Chain Disruption in High-Tech Manufacturing

-

8 min read
From AI Experiments to Business Outcomes: Reflections from Gartner Application Innovation & Business Solutions Summit





Subscribe to our blog to get the latest posts in your inbox
By clicking on the button above, you agree to SnapLogic’s Terms, Privacy and Cookie Policies. You also agree to receive future communications from SnapLogic. You can unsubscribe anytime.