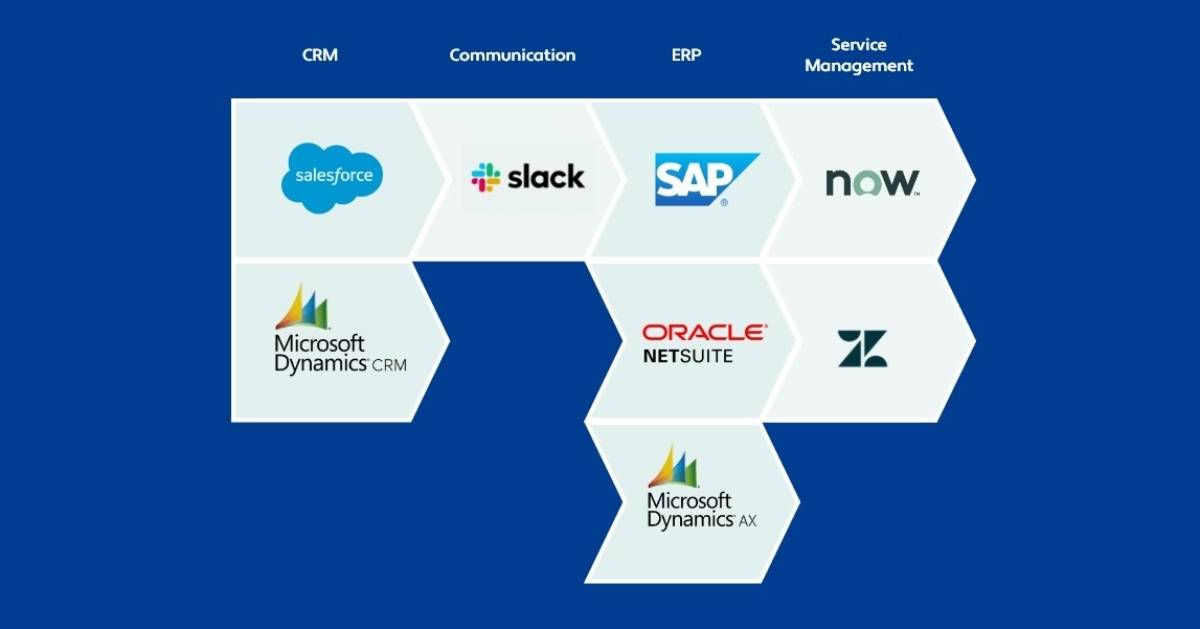
Once an organization scales to a certain point, in-house developers and IT leaders need to find a way to connect applications, tools, data, and databases. Connecting these tools allows for data to flow freely from siloed applications within departments, enabling things such as workflow automation and real-time business insights.
To connect these applications, tools, data, and databases, in-house developers and IT leaders use third-party software(s) called, “Middleware” The name middleware is a contraction of the words ‘middle’ and ‘software’ — it is software in the middle.
Industry insiders go so far as to call middleware, “software glue.”
In this article, we’ll cover the definition of middleware, the origin of middleware, the difference between middleware and APIs, examples of middleware, as well as how it works.
What is middleware?
Middleware is an essential software component that acts as a dynamic conduit facilitating communication and connectivity among various applications, tools, data, and databases, beyond the confines of the operating system. Its role transcends mere data transfer, bringing together disparate apps and data sources, often not originally designed to interact. This capability is crucial in accelerating and refining the process of application development and data management.
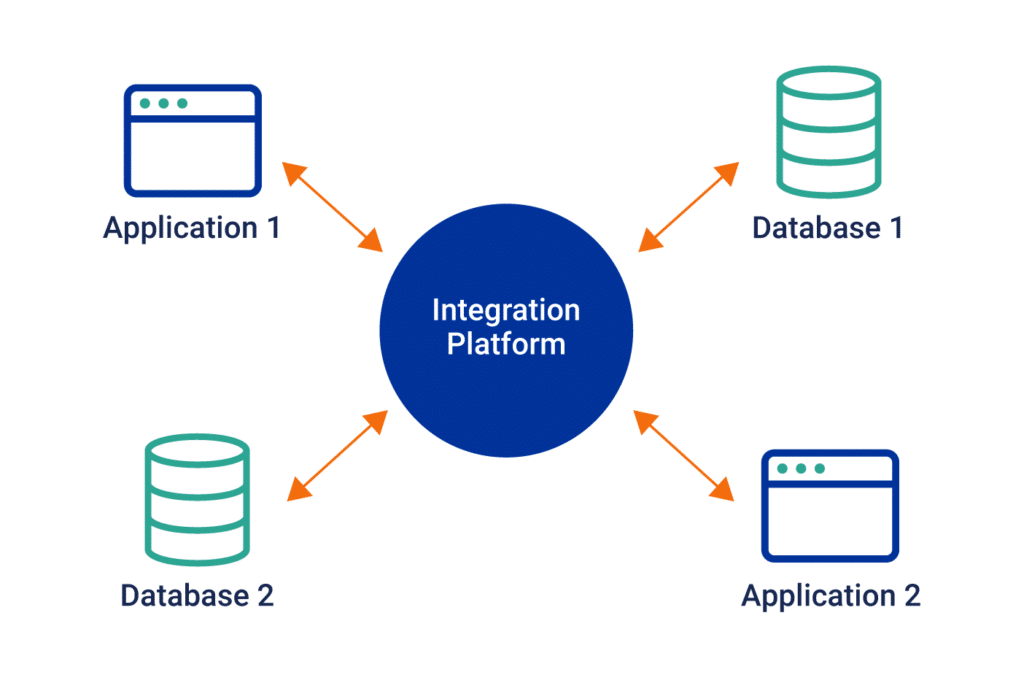
In the ever-evolving landscape of enterprise computing, middleware is instrumental in bridging the gap between cloud-based services and on-premises systems. It enables businesses to effectively integrate and leverage data across their diverse environments. A common scenario might involve using middleware to seamlessly connect an enterprise’s ERP system with its CRM platform. This integration allows for a synergistic use of data, enhancing the overall functionality and efficiency of both systems.
Middleware’s functionality is further enriched by incorporating a variety of advanced features and technologies:
- Open Source and Cloud Services: Many middleware solutions are open source, offering flexibility and customization. Integration with cloud services, like AWS, extends middleware’s capabilities, enabling serverless architectures and efficient in-memory processing.
- Asynchronous Operations and JavaScript: Middleware often supports asynchronous operations, enhancing real-time data processing capabilities. Integration with popular programming languages like JavaScript facilitates the development of responsive and interactive web applications.
- Linux Compatibility and Providers: Most middleware software is compatible with a variety of operating systems, including Linux, ensuring broad applicability. Middleware often interfaces with various service providers, streamlining the integration of different enterprise services.
- Notifications and Caching Mechanisms: Middleware can handle notifications, aiding in real-time alerting and event-driven programming. Efficient caching mechanisms within middleware improve performance by reducing data retrieval times.
- Abstractions and Templates: Middleware provides abstractions that simplify complex underlying processes, making them more accessible to developers. It may also offer templates for common integration patterns, simplifying the development process for startups and established enterprises alike.
- Middleware Functions and Data Centers: Advanced middleware functions include managing communications between distributed applications in data centers, ensuring robust data exchange and system integration.
In summary, middleware serves as a multifaceted tool in the technology stack of modern enterprises, blending diverse features like open-source flexibility, asynchronous processing, and cloud integration to optimize application development, data management, and system integration.
What is the history of middleware?

First appearing in a report at a 1968 NATO Software Engineering conference in Garmisch-Partenkirchen, Germany (a German ski resort in Bavaria), the term “middleware” had a pretty simple use case: to exchange data between monolithic applications. This middleware layer sat between Application programs and service routines. In other words, middleware took the form of massive software components that collected data from one application and delivered it to another.
In the 1980s and 1990s, the rise of distributed computing and the increasing popularity of the internet led to the development of new middleware technologies that were specifically designed to support distributed systems. These technologies included distributed object systems, which allowed objects to be accessed and manipulated across a network, and remote procedure call systems, which allowed applications to call functions on remote systems as if they were local.
Today, middleware is an essential component of many computer systems, providing a wide range of services that are essential for building complex, distributed applications. These services include communication, security, data management, and transaction processing, among others. The continued development of new middleware technologies is driven by the need to support increasingly complex and distributed systems, as well as the growing demand for mobile and cloud-based applications.
Overall, the history of middleware is closely tied to the development of computing itself, and the need for software that can provide interoperability and support for complex, distributed systems. As computing continues to evolve, the role of middleware will continue to be an important one, providing the essential services that enable applications to communicate and share data across a wide range of platforms and devices.
How big is the middleware market size?
The global middleware market stood at US$ 66.68 billion at the end of 2021 and looks to reach over $71 billion by the end of 2022. In the next four years, the market is projected to grow at a compound annual growth rate (CAGR) of 4.5% to reach US$ 89.94.1 billion by 2026 (source). In comparison, the iPaaS market is expected to grow at a CAGR of 21.2% from 2021 to 2028.
What is the difference between API and middleware?
APIs typically refer to callable services while middleware usually refers to the product that does the integration work.
An Application Programming Interface (API) is a series of commands and protocols that let two unrelated software programs communicate with each other. Many marketing technology integrations, order processing systems, and website platforms provide their own APIs so developers can easily integrate the software.
For example, the Google Maps API lets people easily integrate and customize Google Maps for their own use. For the user, integrating this feature is far less costly and time-consuming than building a map from scratch. For Google, providing the API gets more people using Google Maps.
While APIs and middleware perform similar functions, an API can only connect two pieces of software – it can’t be used to create a network. If a developer needs their application to process messages and perform work across multiple systems, they will likely need middleware.
Examples of middleware
Web application servers. A web server is a subset of an application server. It delivers static web content in response to HTTP requests from a web browser. Application servers also do this, but their main job is interacting between end-user clients and server-side application code. Typically, web servers support business logic transactions, decisions, and real-time a
Message-oriented middleware (MOM). A MOM solution enables systems, applications, and services (like microservices) to communicate and exchange information by translating messages between formal messaging protocols. It enables communication regardless of programming language or platform. Message-oriented middleware helps software developers standardize the flow of data between an application’s components. Message queues and message brokers are MOMs.Database middleware. Database-oriented middleware provides access to databases, regardless of their model or platform (SQL, NoSQL, graph, distributed, etc.). Access is typically created through a single common interface like ODBC or JDBC. Information stored in different databases can be accessed through a single interface and this allows integration to be far easier.
Database middleware. Database-oriented middleware provides access to databases, regardless of their model or platform (SQL, NoSQL, graph, distributed, etc.). Access is typically created through a single common interface like ODBC or JDBC. Information stored in different databases can be accessed through a single interface and this allows integration to be far easier.
Enterprise service bus (ESB). An enterprise service bus (ESB) is an architecture that allows communication between environments, such as software applications. Different software components (known as services) run independently to integrate and communicate with each other. This happens as each application talks to the bus, which modulates the communication, ensuring it arrives in the right place and says the right thing in the right way. An ESB is typically implemented using a specialized integration runtime and toolkit.
Integration platform as a service (iPaaS). An iPaaS is a platform that simplifies and automates the integration process, enabling technical and business users to create integration flows between data, SaaS, PaaS, or on-premise applications. It standardizes the integration process and provides API (application programming interface) management to make enterprise application integrations and data integrations easy and fast across the organization and its ecosystems.
How middleware works
Middleware is a cornerstone in modern application development, acting as the connective tissue between disparate applications and services. It’s not just a bridge, but a sophisticated facilitator that enhances interoperability, security, and efficiency.
Easing the Development Process: Middleware liberates developers from the tedium of creating custom integrations for every new app or service. By providing standardized protocols like JSON, REST, XML, SOAP, or web services, middleware creates a universal language for different applications to communicate. This standardization is vital, especially when dealing with applications developed in diverse programming languages such as PHP, Java, C++, or Python.
Interoperability Across Diverse Systems: In today’s digital landscape, where systems are increasingly distributed and varied, middleware ensures seamless interoperability. Whether it’s bridging cloud-based services with on-premises applications or connecting software running on different operating systems, middleware makes these interactions possible and efficient.
Enhancing Security and Authentication: Security is paramount in any application integration, and middleware excels here. By embedding network security protocols and robust authentication mechanisms, middleware secures the critical connection between front-end applications and back-end data sources. This security is especially crucial in sensitive areas such as SaaS platforms and enterprise applications, where data integrity and privacy are non-negotiable.
Scalability and Traffic Management in Distributed Systems: Middleware is adept at handling the dynamic demands of distributed systems, particularly in cloud computing environments. It enables applications to scale up or down based on real-time demands and efficiently manages traffic across different nodes. Tools like Kubernetes are often used in conjunction with middleware to optimize resource utilization in these complex, distributed environments.
Real-time Data Integration and Management: In scenarios where immediate data access and processing are essential, middleware stands out. It facilitates real-time data integration, crucial in high-performance computing environments or financial transactions. Middleware solutions like message-oriented middleware (MOM) and transaction processing monitors ensure consistent and timely data flow across applications.
Supporting DevOps and Continuous Deployment: In the realm of DevOps and CI/CD, middleware is invaluable. It streamlines workflow automation, integrates seamlessly with tools like GitHub, and supports continuous integration and deployment processes. This integration is critical for maintaining the agility and efficiency required in modern software development cycles.
Customizing Application Servers for Specific Needs: Middleware provides the flexibility to tailor application servers to meet specific business requirements and use cases. Whether it’s optimizing backend processes or managing data flows, middleware offers customizable solutions that align with various business strategies.
SnapLogic’s Innovative Approach with Generative Integration: SnapLogic, a key player in the middleware landscape, brings unique capabilities to this domain. With its focus on generative integration, SnapLogic allows for more intelligent, automated connections between different systems and applications. This approach leverages advanced algorithms and machine learning to predict and suggest the most effective integrations, significantly reducing the manual effort and complexity involved in connecting diverse systems. SnapLogic’s platform, renowned for its user-friendly interface and automation capabilities, demonstrates a commitment to evolving middleware technologies, making integration more accessible and efficient for businesses of all sizes.
In essence, middleware is the unsung hero in the complex orchestra of application development and integration. It not only connects but also enhances, secures, and streamlines the myriad components of modern computing systems. As we look ahead, the role of middleware will only grow in importance, adapting to new challenges and technologies in the ever-evolving digital landscape.
How does middleware help with business app development?
In modern business apps, middleware is the key to assembling an application environment with unified capabilities. Within an application, middleware commonly handles things such as data management, messaging, API management, application services, and authentication.
As we already know, middleware is a software layer between two separate applications that allows them to interact with one another. It’s a powerful tool in the world of web development, but it’s not always easy to understand how and why middleware helps in the real world.
The best way to illustrate how middleware works is with an example. Let’s say you have a company that sells widgets online and has a great website where customers can browse products and place orders. You also have a warehouse where deliveries are made and inventory is stored.
In this scenario, you could create an interface between your website and your warehouse so that when a customer places an order on your website, it automatically gets sent to the warehouse for fulfillment. The interface would then notify your customer when their order has been fulfilled and shipped out from the warehouse.
Why is middleware important?
Middleware’s significance in the modern technological arena is profound, touching on numerous aspects crucial for sophisticated and secure digital ecosystems. Its capabilities resonate deeply with the core needs of contemporary computing.
A Catalyst for Seamless Interoperability: Middleware stands as a pivotal facilitator for communication and data exchange. It bridges diverse software applications, enabling them to interact seamlessly across varied platforms and operating systems. This interoperability, essential in the complex world of distributed applications and cloud computing, enhances system coherence and functionality.
Elevating Efficiency and Developer Agility: By offering standardized integration protocols like JSON, REST, XML, and SOAP, middleware expedites the development process. This efficiency allows developers, working on everything from backend systems to front-end applications, to devote more time to innovation rather than the intricacies of connectivity. This acceleration is particularly crucial for rapid deployment in SaaS and enterprise application environments.
Fortifying Security and Data Integrity: In an era rife with data vulnerabilities, middleware fortifies system security. It integrates sophisticated network security protocols and robust authentication mechanisms, safeguarding the vital links between applications. This security is imperative for maintaining data integrity and privacy, especially in sectors where data protection is of utmost importance.
Supporting Scalable and Agile Infrastructures: Middleware’s role in ensuring scalability and flexibility is invaluable, particularly in environments dominated by microservices and cloud computing. It provides the necessary framework for adapting to fluctuating workloads and managing data flow, often leveraging Kubernetes for enhanced containerized application management. Such scalability is essential for businesses seeking agile and efficient operational models.
Real-Time Data Management and Integration: Middleware excels in enabling real-time data integration and management. In high-performance and transaction-oriented systems, middleware technologies like message-oriented middleware (MOM) and various data integration tools ensure a consistent and smooth data flow. This capability is key to enabling real-time analytics and informed decision-making.
Enabling DevOps and Continuous Innovation: In the sphere of DevOps and continuous deployment, middleware is a cornerstone. It underpins the continuous integration and deployment (CI/CD) workflows, essential for modern software development. This support is critical for sustaining the agility and responsiveness that contemporary application development and data management practices demand.
In summary, middleware is not just a component but a strategic enabler in modern computing. It addresses essential aspects like interoperability, security, scalability, and efficiency, while supporting cutting-edge development practices. As the digital landscape evolves, the role of middleware, in aligning with technologies like cloud computing, microservices, and DevOps, becomes increasingly central to business success and innovation.
What is enterprise application integration middleware?
Enterprise application integration middleware enables businesses to standardize integrations across the entire enterprise and ecosystem.
Until cloud computing and cloud-based middleware technology emerged, enterprise service bus (ESB) was the standard way to accomplish this task. Today, integration platform as a service (iPaaS) is the leading enterprise middleware for integrating apps, data, processes, services, and legacy systems – whether on-premise or in public, private, or hybrid clouds.
An iPaaS removes the work and cost of installing and maintaining integration middleware. It provides an API gateway and integration platform that is secure, reliable, and scalable. And the low-code/no-code software helps organizations build custom integrations across teams, enabling automation and digital transformation in the modern enterprise.
Learn more about the SnapLogic Intelligent Integration Platform.
Looking for middleware jobs?
Middleware Engineers are key members of the organization who are responsible for designing and configuring middleware technologies, software, and hardware. Their charter is to provide efficient ways to connect software components and applications, and typically sit within a larger IT or data team. Additionally, Middleware Engineers most commonly have some basic programming knowledge with an understanding of Java, Python, and scripting technologies.
While “Middleware Engineer” is more of a general job title, other common job titles who work in middleware might include:
- Middleware Systems Analyst
- Middleware Solutions Architect
- Middleware Support Specialist
- Application Integration Engineer
- Middleware Infrastructure Engineer
- Cloud Middleware Specialist
- Middleware Operations Engineer
- API and Middleware Developer
- Middleware Security Engineer
- Integration and Middleware Consultant
- Enterprise Middleware Specialist
- Middleware Technical Lead
- Middleware Platform Engineer
- Data Integration Developer
- Middleware Quality Assurance Engineer
- Systems Integration Engineer
- Middleware DevOps Engineer
- Enterprise Application Integration (EAI) Developer
- Middleware Configuration Manager
- Cloud Integration Engineer
If you’re looking for a career in the middleware field, check out the open roles here at SnapLogic.
Frequently Asked Questions (FAQs) on Middleware
1. How does middleware address the challenges of integrating cloud-based services with on-premises systems, and what are the benefits of using middleware in such scenarios?
Middleware plays a crucial role in integrating cloud-based services with on-premises systems by acting as a dynamic conduit between various applications, tools, data, and databases. Its ability to transcend operating system boundaries facilitates seamless communication and connectivity, enabling businesses to effectively integrate and leverage data across diverse environments. This is particularly significant in scenarios where an enterprise’s ERP system needs to be seamlessly connected with its CRM platform, resulting in a synergistic use of data and improved overall functionality and efficiency for both systems.
2. How does middleware contribute to the scalability and agility of modern business infrastructures?
Middleware is instrumental in supporting the scalability and agility of modern business infrastructures. In environments dominated by microservices and cloud computing, middleware provides a foundational framework for adapting to fluctuating workloads and efficiently managing data flow. Leveraging technologies like Kubernetes, middleware enables applications to scale up or down based on real-time demands, optimizing resource utilization in complex, distributed environments. This scalability is essential for businesses seeking agile and efficient operational models, allowing them to respond dynamically to changing requirements and ensuring optimal performance across diverse systems and platforms.
3. How does middleware address security concerns in application integration, especially in sensitive areas like SaaS platforms and enterprise applications?
Middleware ensures robust security in application integration by embedding sophisticated network security protocols and authentication mechanisms. In sensitive areas such as SaaS platforms and enterprise applications, where data integrity and privacy are paramount, middleware acts as a secure layer. It provides standardized integration protocols like JSON, REST, XML, SOAP, and web services. This not only fortifies the critical connections between front-end applications and back-end data sources but also ensures that data is transmitted securely. In essence, middleware plays a pivotal role in maintaining a secure and trustworthy environment for data exchange and communication in the digital landscape.