






Data is increasingly being recognized as the corporate currency of the digital age. Companies want to leverage data to achieve deeper insights leading to competitive advantage over their peers. According to IDC projections, total worldwide data will surge to 163 zettabytes (ZB) by 2025, an increase of 10x the amount of what exists today. The potential digital data gold mine is poised to unleash a new era of innovation, opening up additional revenue streams, empowering next-generation products, and affording companies the insights to garner efficiencies and boost productivity. This data explosion has led enterprises to go beyond the world of traditional data warehousing and explore how to successfully build data lakes in the cloud to gain access to and analyze data that they have not been able to get to in the past.
The key to innovation is data management
The key to unlocking all this data-driven innovation lies with how data is captured, processed, managed, and analyzed. But today’s volume, variety, and velocity of data make having the enterprise data warehouse the center of a data architecture almost impossible. The enterprise data warehouse just doesn’t have the scalability or performance characteristics to handle the deluge of structured and unstructured information culled from existing enterprise applications and streaming in from real-time sources like sensors, videos, weblogs, and the Internet of Things (IoT). A data warehouse can handle unstructured data but it doesn’t do so in the most efficient manner. With so much data out there, it can get very expensive to store all of your data in a traditional data warehouse. A data lake is a place to store your structured and unstructured data, as well as a method for organizing large volumes of highly diverse data from diverse sources. The data lake tends to ingest data very quickly and prepare it later, on the fly, as people access it.
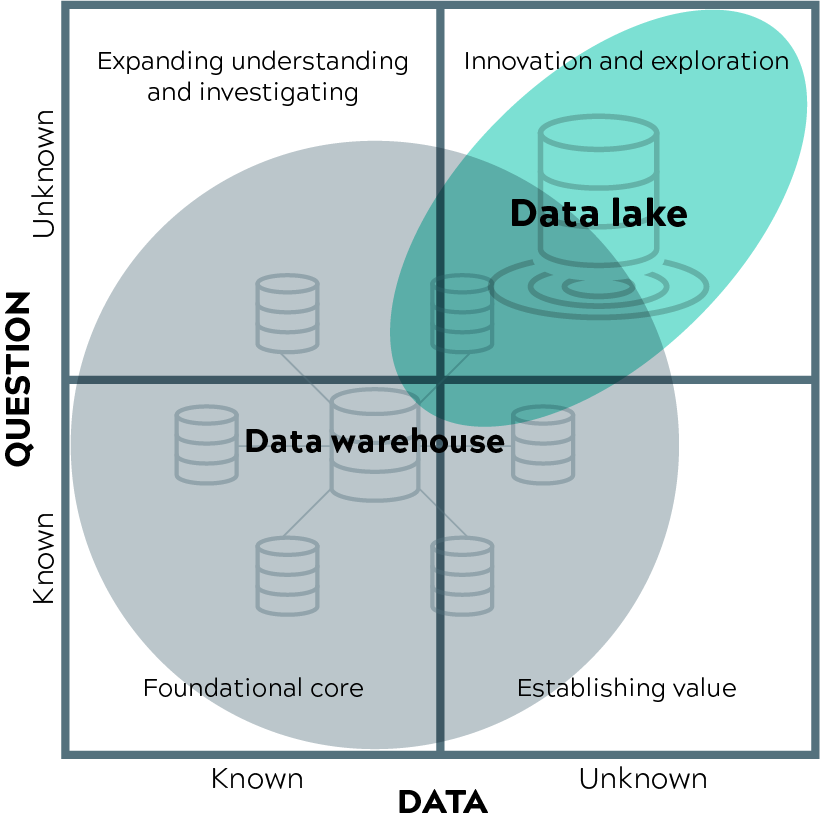
Here is a framework inspired by Gartner, as a way to think about where a traditional data warehouse or a data lake makes the most sense. It depends on whether you know what you need and whether the data you need is known or not.
How do you determine if a data lake can meet the data management challenges of your organization and how do you prepare for one if it is indeed in the cards? Here are five questions to keep in mind:
What is the makeup of the data mix? If an organization’s business needs are met by aggregating and analyzing tabular, mostly structured information stored in transaction-based systems like enterprise resource planning (ERP), traditional data warehouses are still likely the best approach. However, if the data mix starts to encompass unstructured or even semi-structured material and most importantly, is accumulating at a rapid pace – think real-time and streaming data – then a data lake should be on the table as a more economical way to handle the volume at scale.
Is there a well-defined strategy for the data lake? Much of the appeal of a data lake is its near insatiable appetite for ingesting all sorts of data and the flexibility that you can hold on to for later usage without necessarily knowing what you want to do with it. At the same time, without an upfront strategy encompassing where the data comes from, who the data serves, and some specific governance practices, IT organizations could find themselves right back where they started: Saddled with a series of siloed systems that don’t adequately meet the needs of business and can’t effectively scale.
Do you have ready access to big data skills? Organizations flush with data warehouse experts, and business analysts aren’t necessarily fluent in what it takes to work with the big data universe, specifically data lakes. Familiarity with new open source technologies like Hadoop, MapReduce, Flink, Flume, Kafka, or Spark is now critical, as is the need for data engineers who can write code to process data at scale using programming languages such as Scala, Java, and Python. There’s also a need for data scientists who can harness programming languages like Python, and R to prepare data and build analytical models for achieving deeper insights. On top of this whole new ballgame of techniques and tools, organizations also need to reorient data management practices to embrace agile methodologies to maximize the benefits of a data lake architecture.
What time constraints should be considered? Data that gets populated into an enterprise data warehouse needs to be cleansed and prepared before it gets stored. And with today’s unstructured data getting generated in various raw formats at a rapid pace, it can be an arduous process to get to cleansed and prepared stages when you’re not even completely sure how the data is going to be used. The data lake is designed to handle unstructured data in the most cost-effective manner possible where compute and storage layers can be scaled independently in an elastic manner. With a data lake approach, users can get their data in there as quickly as possible so that they can address operational use cases around operational reporting, analytics, and business monitoring.
How will you address the data integration needs? A Cap Gemini report on the big data payoff identified integration challenges as one of the big inhibitors to big data success (cited by 35 percent of respondents). Another report, by TDWI, found the lack of data integration tools a barrier to successful data lake implementation for 32 percent of respondents. Before moving forward, there needs to be a data acquisition and integration roadmap for data ingestion that is optimally suited to the new paradigm.
The enterprise data warehouse will continue to remain a mission-critical component of an overall modern enterprise data architecture (MEDA), but it should now be viewed as a “downstream” application, a destination, but not the center of your data universe. Data lakes, while not a panacea, have huge potential to not only enable a broader audience to gain access to data that they have not been able to get to in the past but support that in a cost-effective way. It’s not enough to jump on the latest high-tech bandwagon – rather, be sure to ask the right questions and work through all considerations to ensure a data lake is a right approach for your organization’s data needs.






