






By now, we all know about and are experiencing the rise in the volume of data generated and available to an organization and the issues it can cause. One can see that there is little end in sight to the data tsunami which is largely in part due to the increased variety of data from mobile, social media, and IoT sources.
So, it’s no surprise that organizations find themselves drowning in data. In a recent survey from independent market research firm Vanson Bourne, they discovered that up to 80 percent of respondents believe legacy technology is holding their organization back from taking advantage of data-driven opportunities. The same survey also stated that only 50 percent of the data collected is analyzed for business insight. Couple all this with organizations needing insights from the data at a faster and faster rate is a recipe for disaster or, at best, represents potentially lost revenue.
To collect and analyze the data for hidden business insight and truly embrace a data-driven culture, organizations need the tools to empower data engineers and business users with domain knowledge to operate more efficiently in this environment without requiring them to have deep, technical skills.
The rise of big data technologies
To collect and analyze all types of data, organizations continue to adopt big data technologies and are increasingly building cloud-based data lakes. This allows them to take advantage of the benefits that the cloud offers such as significantly lower CapEx.
However, operating the big data environment is often challenging as specialized skills are required to install, configure, and maintain the environment. Once the environment is up and ready and employees are ready to embark on their project, they’ll need Spark developers to write code to perform the data engineering tasks. Next, they will need to develop a mechanism for Spark pipeline job submission to the processing cluster. Once this is done, and employees want to take advantage of the transient capability that Big Data as a Service (BDaaS) clusters offer, they will need to develop their lifecycle management.
All of this takes many hundreds, if not thousands, of lines of code which is complex, error-prone, and typically takes months to write. At the same time, Spark developers are in high demand and there is a tremendous shortage of this talent overall.
When big data meets eXtreme
SnapLogic eXtreme addresses the data engineering talent shortage by enhancing the Enterprise Integration Cloud and its visual design paradigm allowing organizations to build Spark pipelines without the need for writing Spark jobs in Scala, Python, or Java, therefore dramatically reducing the skill set required. A project that would typically span multiple developers and multiple months can be reduced to just hours.
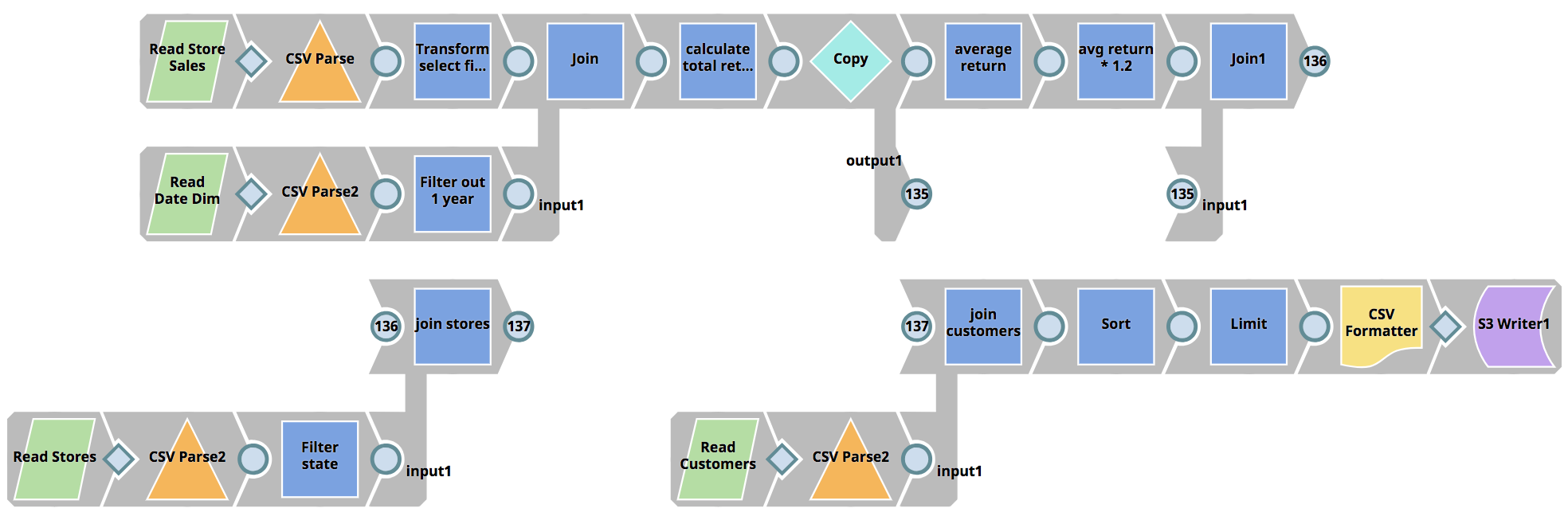
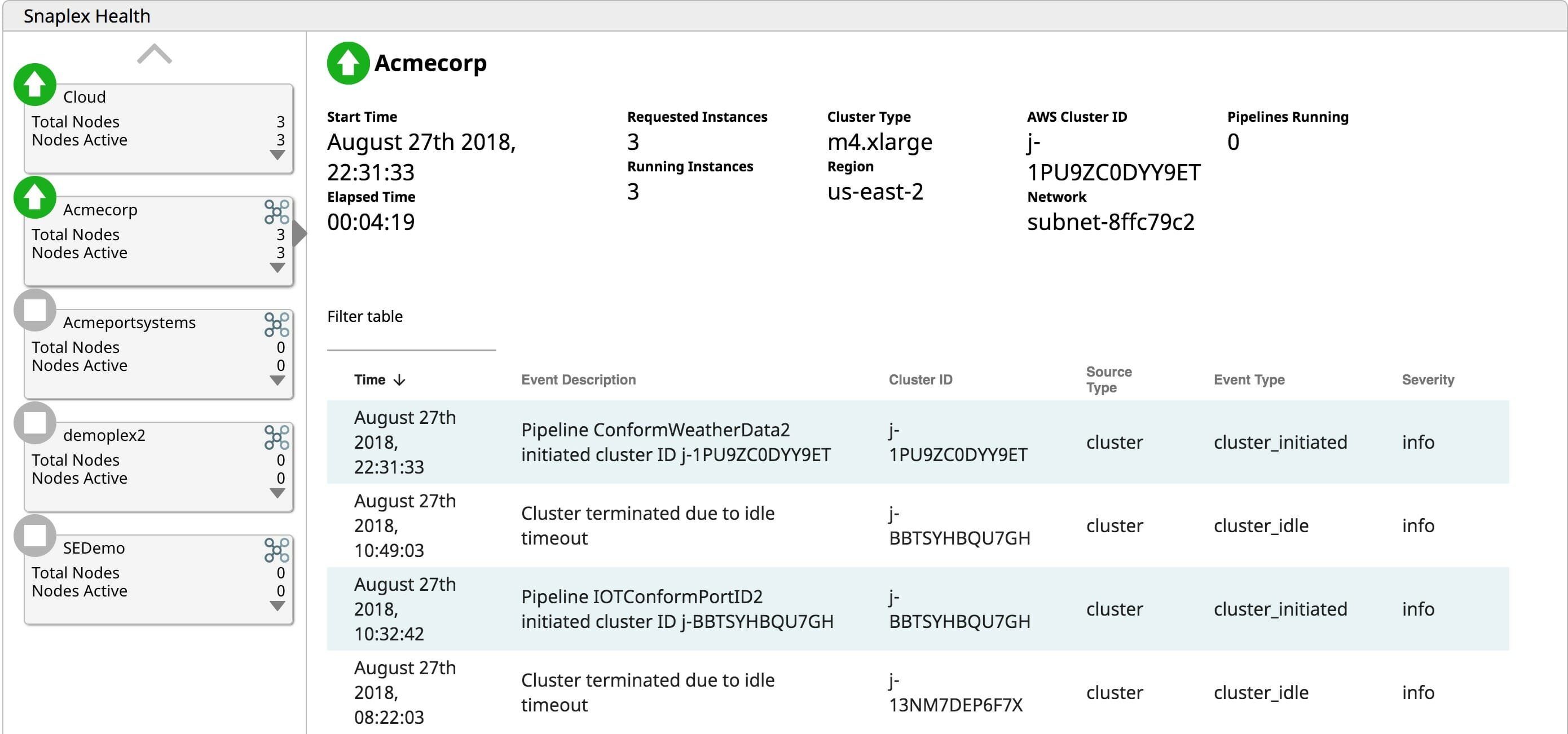
Through SnapLogic eXtreme’s lifecycle management capability, users can spin up clusters on demand when processing is required. If no jobs need to run, paying for an idle cluster is just wasted OpEx. SnapLogic eXtreme elastically scales clusters when needed as processing ramps up. Providing the elastic scale capability eliminates the need to size clusters for peak loads. Increasing the processing capability as required allows organizations to only pay for what they use, preventing wasted OpEx on servers that are idle. Finally, eXtreme terminates running cluster when there are no pending jobs to process. Why pay for keeping servers running when they are not adding business value? Providing a fully-managed, automated cloud-based big data runtime environment saves organizations valuable OpEx.
Big data initiatives get help
The features in eXtreme provide speed and agility to an organization. SnapLogic eXtreme allows organizations to do more with fewer resources through the use of its visual design interface. Allowing self-service capabilities allows technical business users to launch initiatives faster to the market and obtain meaningful insights quickly, which is critical in today’s fast-paced environment. After all, Forrester predicts that “by 2021, insights-driven business will steal $1.8 trillion a year in revenue from competitors that are not insights-driven.”
The continued rise in the volume and variety of data and analyzing it for hidden business insights show no sign of abating. While big data technologies provide the right tools for the job, they offer a challenging operating environment that requires a specialized, hard-to-find skill set to be successful. SnapLogic eXtreme provides the means to reduce the time, resources, and expertise needed to build and operate big data architectures in the cloud. If your organization is struggling with its big data initiative, check out SnapLogic eXtreme.








