






![]()
In today’s business world big data is generating a big buzz. Besides the searching, storing and scaling, one thing that clearly stands out is – stream processing. That’s where Apache Kafka comes in.
Kafka at a high level can be described as a publish and subscribe messaging system. Like any other messaging system, Kafka maintains feeds of messages into topics. Producers write data into topics and consumers read data out of these topics. For the sake of simplicity, I have linked to the Kafka documentation here.
In this blog post, I will demonstrate a simple use case where Twitter feeds to a Kafka topic and the data is written to Hadoop. Below are the detailed instructions of how users can build pipelines using the SnapLogic Elastic Integration Platform.
In the Spring 2016 release, SnapLogic introduced Kafka Snaps for both producer and consumer. Kafka reader is the Kafka consumer Snap and Kafka writer is the Kafka producer Snap.
SnapLogic Pipeline: Twitter Feed Publishing to a Kafka Topic
In order to build this pipeline, I need a Twitter Snap to get Twitter feeds and publish that data into a topic in the Kafka Writer Snap (Kafka Producer). Let’s choose a topic, say “Regions”, and configure the Kafka Writer Snap to write to this topic.
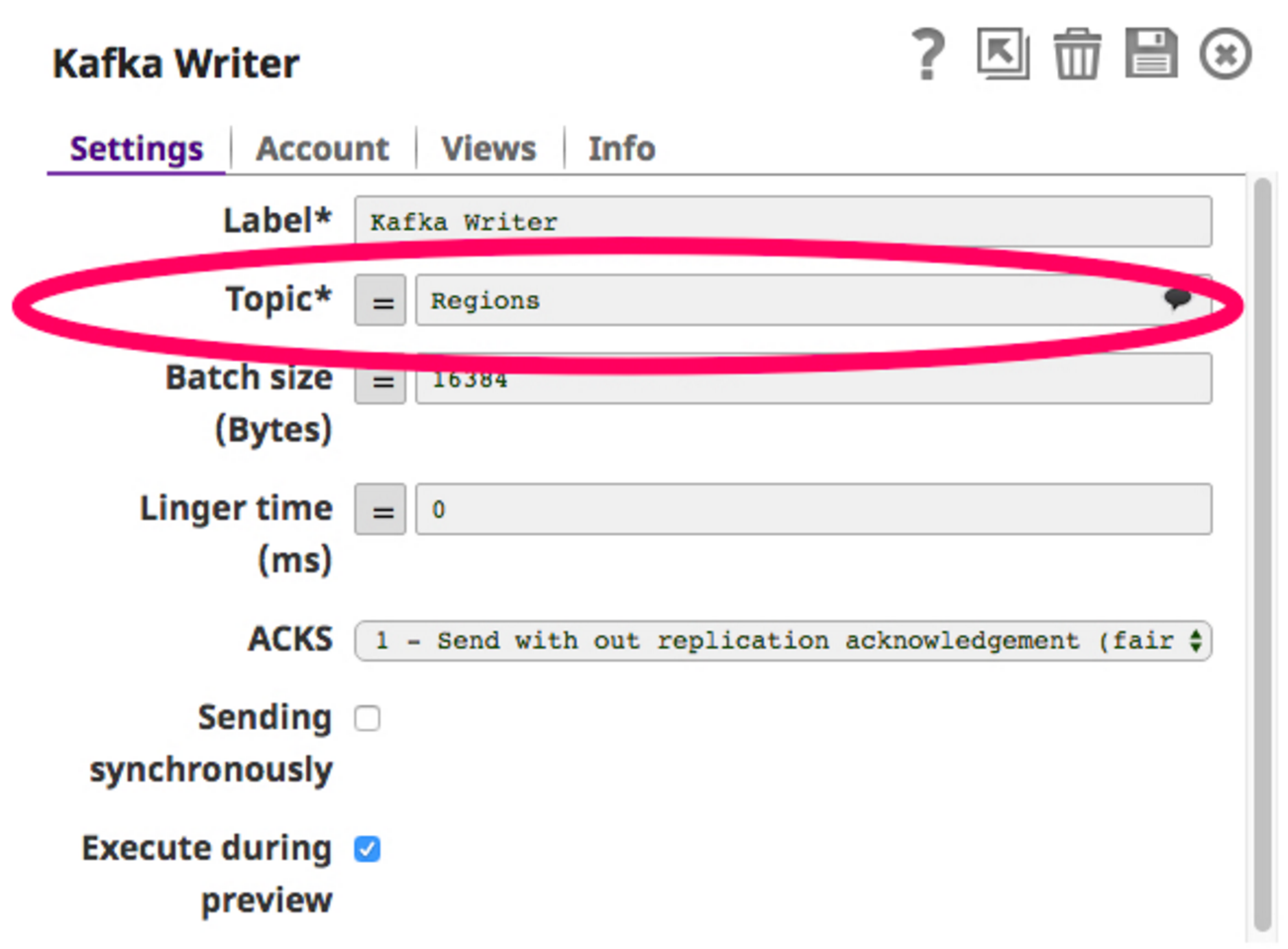 Now that the writer Snap is configured, we can build the pipeline and run it. Here is how the pipeline looks:
Now that the writer Snap is configured, we can build the pipeline and run it. Here is how the pipeline looks:
 Lets save and run it. On run, the Twitter feed will publish data to the “Regions” topic selected in the Kafka Writer Snap and this is what the output will look like:
Lets save and run it. On run, the Twitter feed will publish data to the “Regions” topic selected in the Kafka Writer Snap and this is what the output will look like:
 The Kafka topic “Regions” now has all the Regions-related Twitter feeds as shown above. Our next step is to read from the same topic using the Kafka Reader (Kafka consumer) Snap and finally to write to HDFS.
The Kafka topic “Regions” now has all the Regions-related Twitter feeds as shown above. Our next step is to read from the same topic using the Kafka Reader (Kafka consumer) Snap and finally to write to HDFS.
For that, I drag and drop a Kafka Reader Snap on to the canvas. The Kafka Reader Snap acts as a consumer by constantly polling on the selected topic. Below is a screenshot for Kafka Reader Snap:
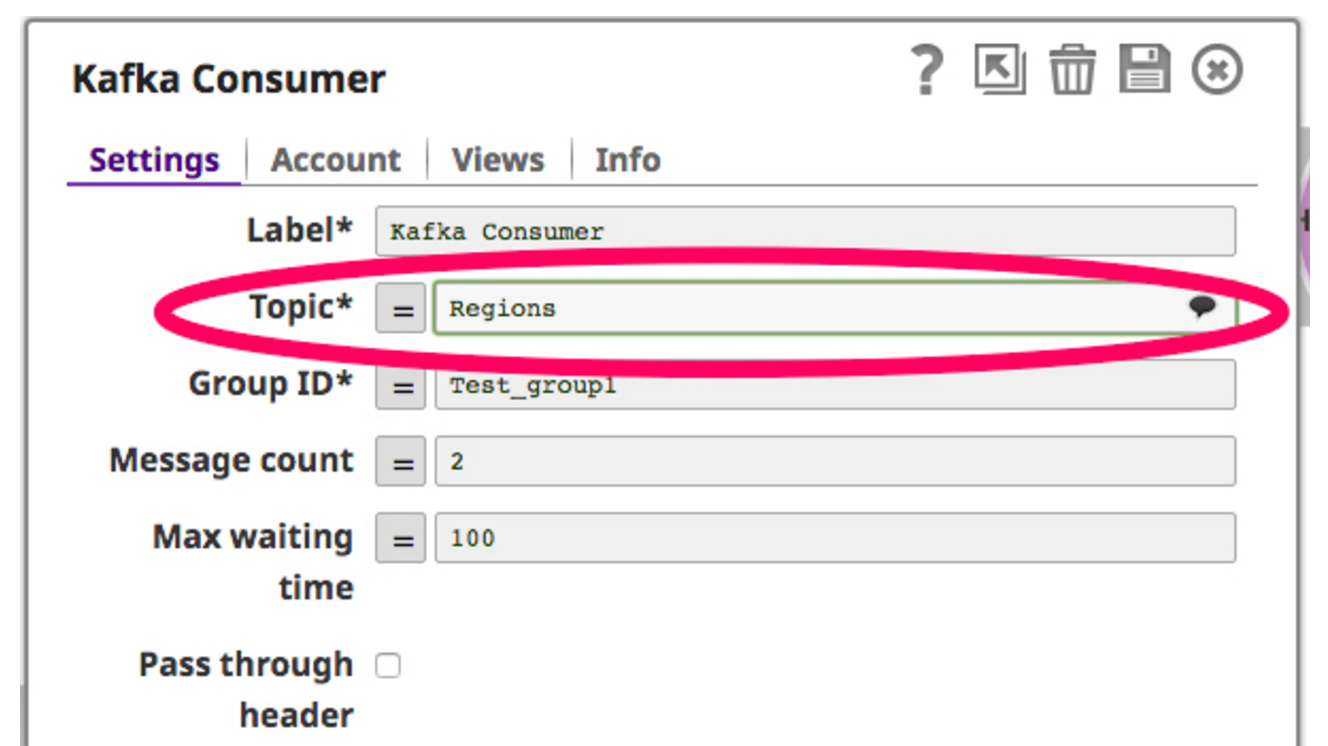 Now that the consumer is set to read on the topic, I filter the data retrieved from the Kafka consumer and write to HDFS through the HDFS Writer Snap. Below is a screenshot of this pipeline:
Now that the consumer is set to read on the topic, I filter the data retrieved from the Kafka consumer and write to HDFS through the HDFS Writer Snap. Below is a screenshot of this pipeline:
 Now, when I run this pipeline, the Kafka Consumer Snap reads data from the topic “Regions” , filters the data to a specific region “China” and finally writes into HDFS using the HDFS Writer Snap.
Now, when I run this pipeline, the Kafka Consumer Snap reads data from the topic “Regions” , filters the data to a specific region “China” and finally writes into HDFS using the HDFS Writer Snap.
Kafka can also be combined with Ultra by running the Twitter producer pipeline as an Ultra Pipeline so it is constantly running, pushing the Twitter stream into Kafka. The consumer pipeline in turn can be executed as a scheduled pipeline consuming batches of data from the Kafka broker on a regular basis.
The Kafka Writer Snap can write to multiple topics like this and data from these topics can feed into multiple services for various use cases. The SnapLogic Elastic Integration Platform as a service (iPaaS) enables all of these use cases in a much easier and faster way.
Next Steps:
- Learn more about our Spring 2016 release
- Watch a demonstration or Contact Us
- Let us know what topics you’d like us to write about next in the comments below






