





How SnapLogic simplifies the complex process of loading Salesforce data into Amazon Redshift
While working on a complex Salesforce data integration project, I started to build something that, to me, morphed into a work of art. Why do I think this? I’ll explain. I’ve worked with many data and application integration tools, but none give me the same kind of artistic satisfaction as the SnapLogic Intelligent Integration Platform. There is no code involved – it’s all drag and drop and simple scripting. And yet, the solution solves the very complex problem of loading Salesforce data into the Amazon Redshift cloud data warehouse.
From my experience with other integration tools, none could solve this problem in such a simple, elegant, and artistic fashion. In fact, I have printed out and framed the SnapLogic integration pipeline I built for this use case and hung it on my study room wall.
Before delving into the details of how I constructed the pipeline, let me first define the problem.
The challenge: Move Salesforce data into Redshift
A while back, I helped Box, a leading cloud content management company and SnapLogic customer, with a hefty integration project. The team at Box issued these requirements.
“We want to extract Salesforce data into a data warehouse, in this case, Amazon Redshift. But the Salesforce Data Objects are frequently updated and new Fields are regularly added. Thus, the Redshift ‘Load’ Table Schemas need to be modified and new fields extracted from Salesforce. Additionally, in Redshift, we have numerous Database Views defined, which depend on the “Load” Table Schemas. All Views will need updating.”
Currently, it’s a manual process to alter the Redshift table schemas to match the Salesforce entities, update the Salesforce SOQL script to retrieve the new Salesforce Data Fields, load data into Redshift Tables, and, finally, update the dependent Redshift View Schemas. Multiply this by the number of Salesforce Entities, then this becomes a very tedious task.
And now the art!
SnapLogic pipeline: Low-code integration of Salesforce data
The first pipeline compares Salesforce Entity Fields with the associated Redshift ‘Load’ Table Schema to determine differences, performs an update to the Redshift ‘Load’ Table, and finally builds the Salesforce SOQL statement.
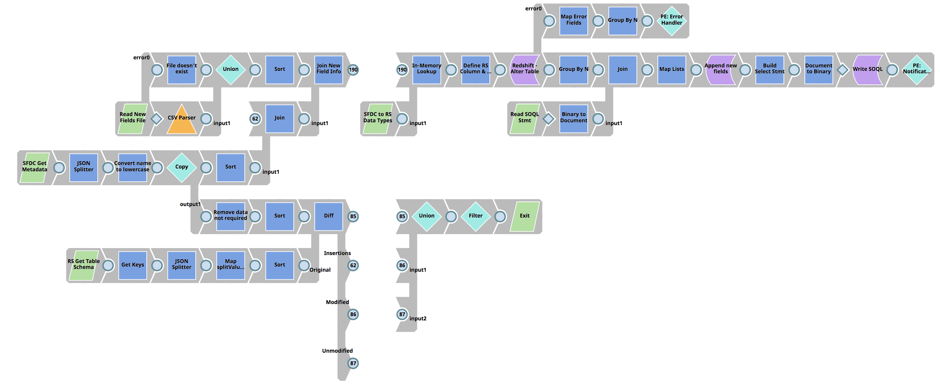
More detailed steps:
- Consumes the Salesforce Metadata API to return all fields for a Salesforce Entity
- Retrieve table schema for the Redshift Load Table of the associated Salesforce Entity
- Utilize the Diff Snap to determine differences between Salesforce Entity Fields and Redshift Load Table columns
- With the output of the Diff Snap (the differences between Salesforce Entity and Redshift Load Table), join with the Salesforce Metadata to obtain all Salesforce Entity Field information
- Use the In-memory Snap, and perform a lookup, to match Salesforce Field Type with the Redshift Data Type
- Add the new Column(s) to the Redshift Load Table Schema, using the Redshift Execute Snap
- Load the previous version of the Salesforce SOQL Statement File, and join with the list of new Salesforce Data Fields
- Update the SOQL Statement File to include new fields and write to the SLDB
Next, extract the data from Salesforce using the SOQL Statement and bulk load into Redshift:
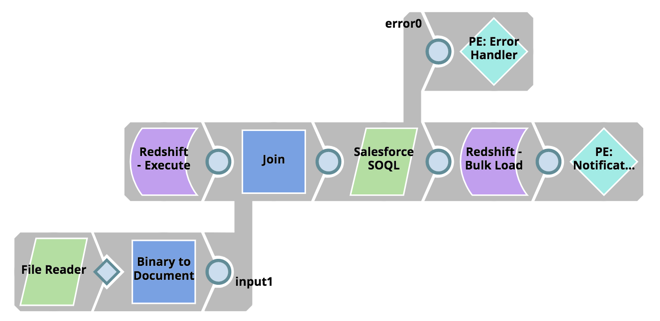
- Read the updated SOQL Statement Script from the SLDB
- Retrieve the last modified date from the Redshift Load Table
- Consume the Salesforce SOQL API, using the Salesforce SOQL Snap, and retrieve all records from last modified date
- Using the Redshift Bulk Load Snap, bulk load the data into Redshift
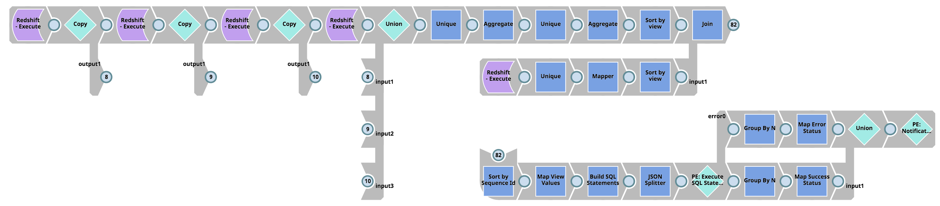
And finally, determine the Redshift ‘Load’ Table View dependencies, retrieve View schemas from Redshift (that is, the pg_views table), build the SQL scripts to Drop, Create and Grant Permissions for the Views, and execute the SQL statements on Redshift:
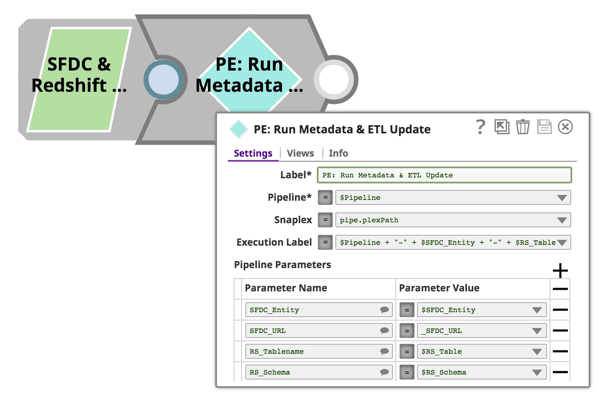
All Pipelines described above accept Pipeline Parameters, so we can use an Object-Orientated approach and reuse these pipelines for all Salesforce Entities and Redshift Tables. This is achieved by simply using the Pipeline Execute Snap and passing in the Salesforce Entity names, Redshift Table Names, Pipeline Names, etc. Again, this is achieved via configuration of the Pipeline Execute Snap:
To my eyes, the art here is all this functionality is achieved quickly and with zero coding. The pipelines visually appeal with a technical beauty when considering the underlying logic and heavy lifting the SnapLogic runtime is performing.
Want to explore SnapLogic’s 1,000+ pre-built connectors (Snaps) to integrate all your disparate data and applications? Book your demo with an expert.






