





What is Apache Hive? Hive provides a mechanism to query, create and manage large datasets that are stored on Hadoop, using SQL like statements. It also enables adding a structure to existing data that resides on HDFS. In this post I’ll describe a practical approach on how to ingest data into Hive, with the SnapLogic Elastic Integration Platform, without the need to write code.
Data flow pipelines, also referred to as SnapLogic Pipelines, are created in a highly intuitive visual designer, using a drag & drop approach. A data flow pipeline consists of one or more Snaps that are connected to orchestrate the flow of enterprise data integration between sources and targets. Snaps are the building blocks of a pipeline that perform a single function such as read, write, or act on data. SnapLogic Snaps support reading and writing using various formats including CSV, AVRO, Parquet, RCFile, ORCFile, delimited text, JSON. Compression schemes supported include LZO, Snappy, gzip.
So here’s a scenario: Let’s say we have contact data that is obtained from multiple sources that needs to be ingested into Hive. We need to combine data from multiple sources; say, raw files on HDFS, data on S3 (AWS), data from databases and data from the cloud applications like Salesforce or Workday. How does one then get started with ingesting data from these disparate sources into Hive?
The first step would be to create a Hive database and/or tables. Using the SnapLogic Hive Integration Snap, you can execute any Hive DML/DDL , including creating databases & tables.
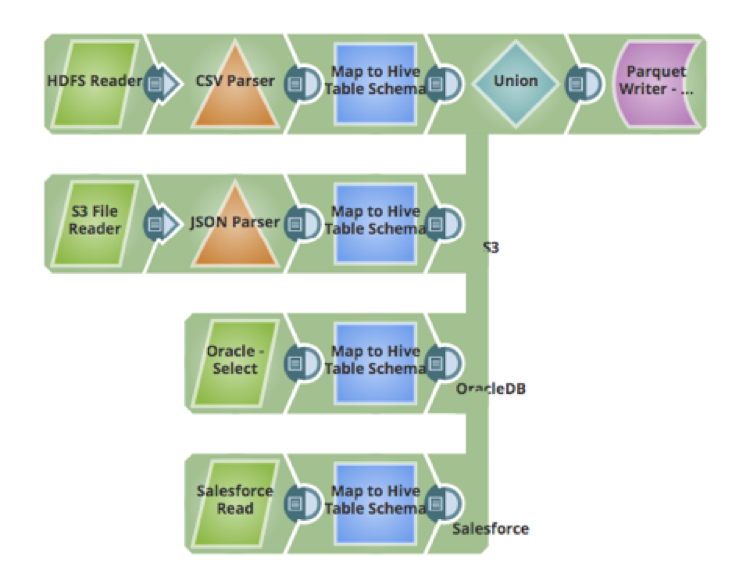
The next step is about ingesting the data. One of the challenges faced with ingesting data from multiple sources is how to map, transform and cleanse data. Using the Mapper snap, one would be able to map fields from source schema to the target schema, cleanse data, perform transformations on the data, add new attributes to the schema, and other actions. Below is a pipeline that gets data from 4 sources, transforms the data to map to the Hive table and inserts the data into the Hive Table (that uses Parquet data format):
- CSV raw data files on HDFS
- JSON files hosted on Amazon S3
- Data from a table in an Oracle database
- Data hosted in a cloud application like Salesforce
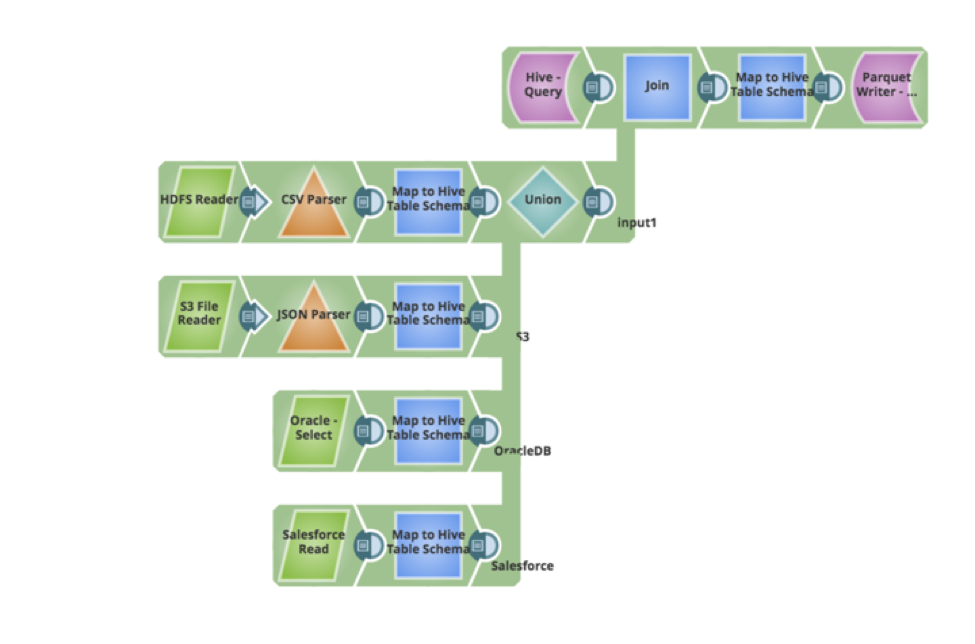
Let’s say we have a new requirement from your business users – that the existing data in the Hive table needs to be updated and new data records needs to be inserted. The pipeline can be easily updated to query for the existing data, perform a full outer join and write the data back as parquet. Below is the pipeline that implemented the new requirements, all performed in a visual manner, without writing any code or script.
In my next post, I will go over additional Ingestion Patterns and how to implement them using the SnapLogic Platform.





