






The ability to manage vast amounts of data is critical to the success of any organization, although most remain behind the curve and struggle to get to data-driven results. Even with information-rich data at hand, according to a May 2017 article published in Harvard Business Review, “more than 70% of employees have access to data they should not, and 80% of analysts’ time is spent simply discovering and preparing data.”
Where does machine learning come in? As the need for better insights from data exploded, we spoke to customers who were looking to machine learning for help and found that their data engineers were spending 70 to 80 percent of their time in data acquisition, data exploration, and data preparation as part of their machine learning lifecycle. We also heard about the scarcity of data science experts and not very helpful non-integrated, unwieldy data preparation tools. Fast-forward to now and the conclusion that machine learning (ML) is really an integration problem, making SnapLogic a natural platform for ML. So, in November, we launched SnapLogic Data Science to manage and control the entire machine learning lifecycle.
In this blog post, as we walk through some of the capabilities of the SnapLogic Data Science offering, you will see how data preparation and machine learning can be easy to use, fun, and simple.
A new self-service machine learning solution
SnapLogic Data Science – introduced our latest release as an extension of SnapLogic’s intelligent integration platform – is a new self-service solution that accelerates the development and deployment of machine learning with minimal coding along the entire machine learning lifecycle as shown below.
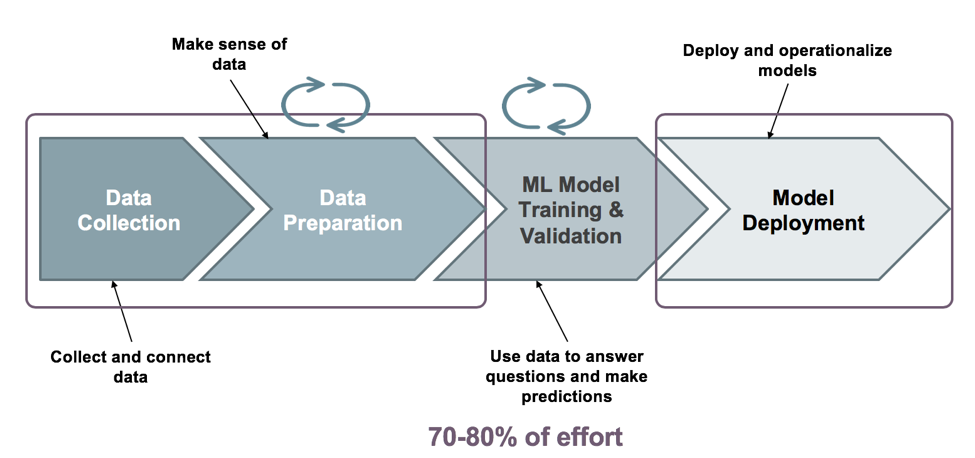
Data collection and preparation
Let’s walk through Data Collection and Preparation and the set of capabilities SnapLogic Data Science brings to this ML bucket. This is where a data engineer accesses and assembles the data for use by machine learning models and performs feature engineering. You can also perform preparatory operations on datasets such as data type transformation, data cleanup, sampling, shuffling, and scaling. These capabilities eliminate redundancy in data preparation that is sometimes introduced through a disconnect between data science and IT/DevOps teams.
The SnapLogic Data Science offering provides three Snap Packs – the ML Data Preparation Snap Pack, the ML Core Snap Pack, and the ML Analytics Snap Pack to support data collection and preparation.
- The ML Data Preparation Snap Pack enables data engineers and data scientists to perform preparatory operations on datasets such as data type transformation, data cleanup, sampling, shuffling, and scaling. It provides key Snaps like the Clean Missing Values Snap that replace missing values in datasets by dropping or imputing values. We also have the Date Time Extractor Snap that extracts components from datetime objects to be put into result fields for further analysis. The Sample Snap helps generate sample datasets from an input dataset using various kinds of sampling algorithms like Stratified Sampling, Weighted Stratified Sampling, etc. The Scale Snap helps scale values in columns to specify ranges or apply statistical transformations. The Shuffle Snap randomizes the order of the row data in the dataset.
- The ML Core Snap Pack enables data engineers to perform operations on machine learning data sets such as model training, cross-validation, and model-based predictions.
- The ML Analytics Snap Pack helps data engineers perform analytic operations such as data profiling and data type inspection.
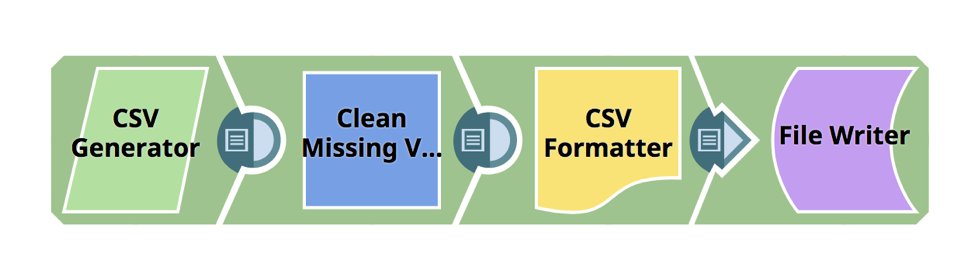
The example below showcases how the Clean Missing Values Snap can be used in a pipeline for data preparation. The Clean Missing Values is a Transform-type Snap used to handle missing values in an incoming dataset by dropping or imputing values and supports four approaches: Drop Row, Impute with Average, Impute with Popular, and Impute with Custom Value.
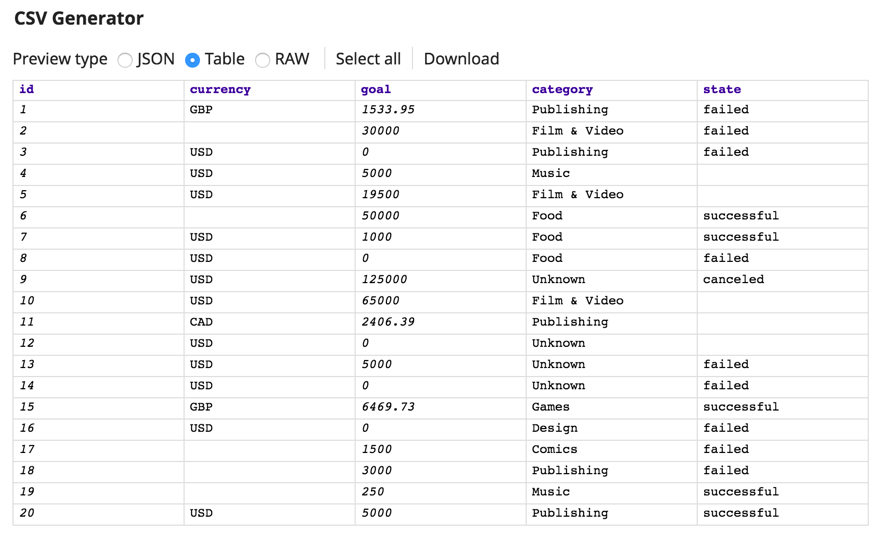
First, using the CSV Generator Snap, we have a simple csv file that has missing values for currency – you will see that in the third row.
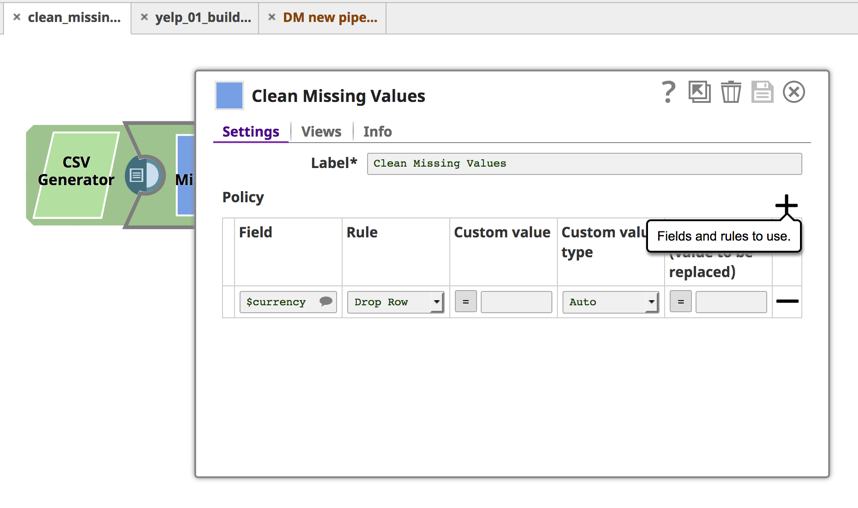
The next Snap in the pipeline, Clean Missing Values, lets you define a rule that will drop the row if the currency value is null.
And once I go ahead and run the pipeline, the screenshot below shows what the cleansed file looks like. You see that row was specifically dropped and the file is now cleansed.
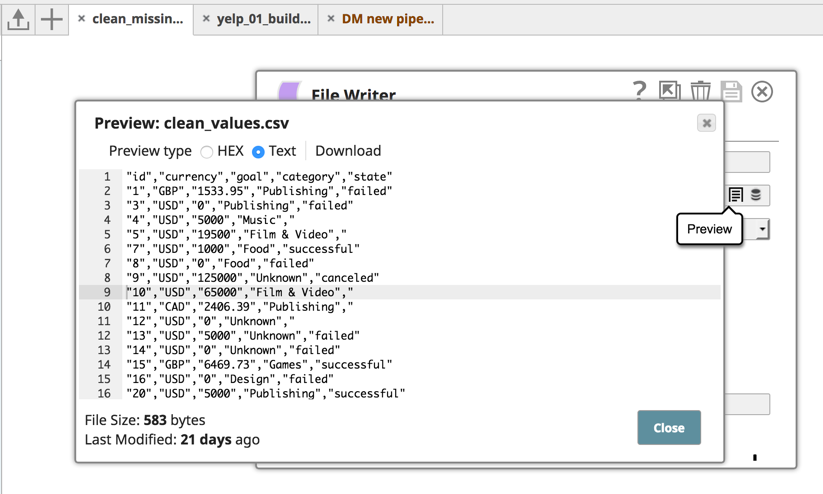
Once the data is cleansed, you can use the Profile Snap to profile the data and compute statistics of the incoming data.
Here’s a pipeline showing this part of the process.

Looking at the file that is used store various kinds of assets, you can see how the source data is structured.
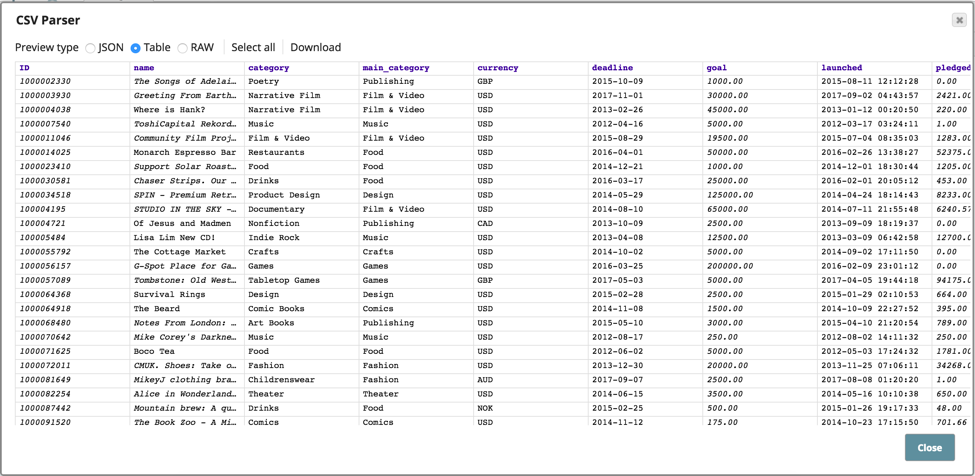
The pipeline shown above has been set up to parse and profile the CSV data, and then have the profile output written to a JSON output file. Here is what the profile output looks like with the value distribution, etc.
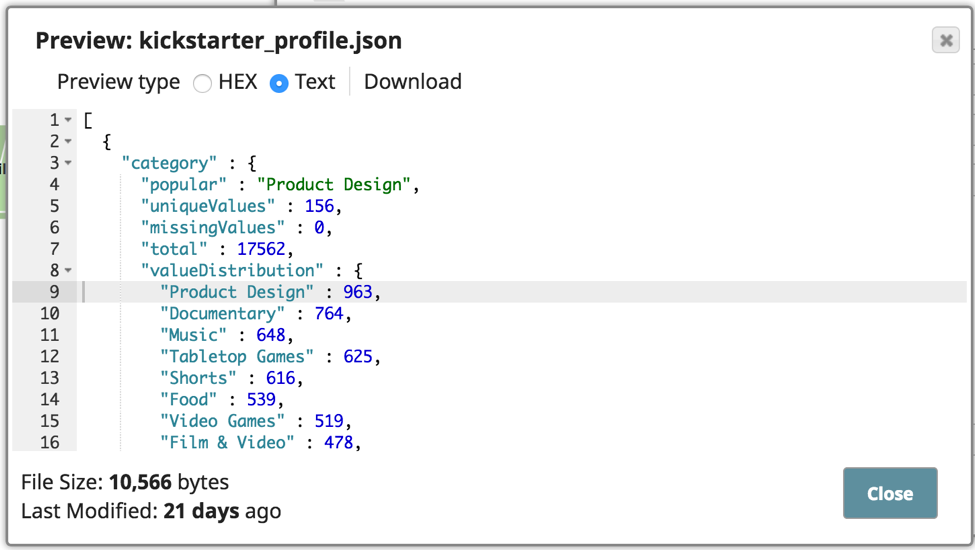
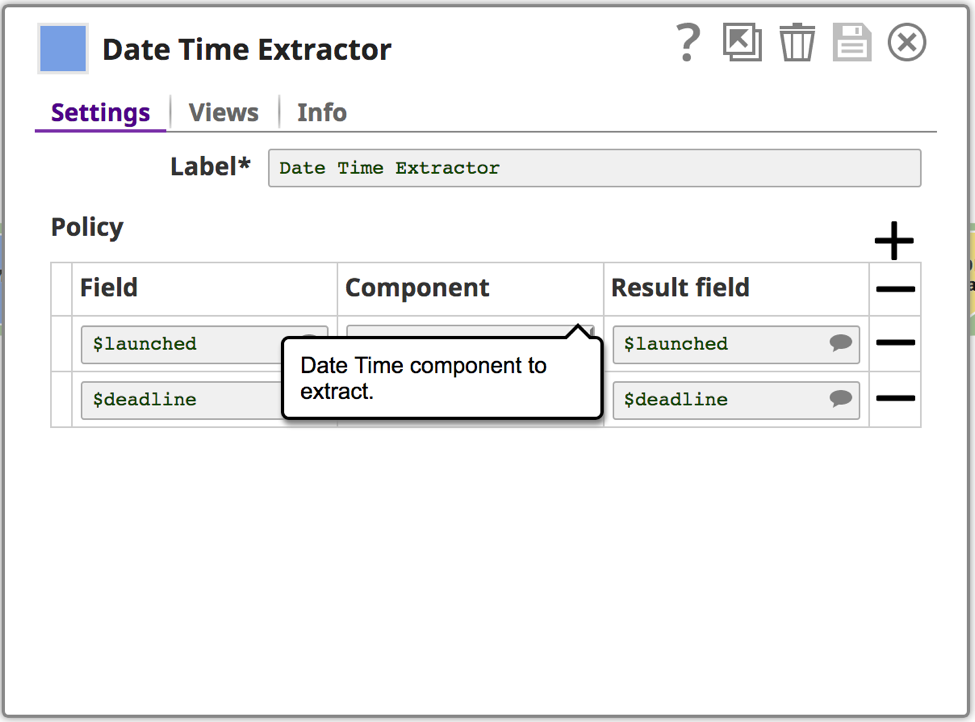
This will help determine what further data cleansing needs to happen. One more thing to point out is that I am also using the Date Extractor Snap, which is a Transform type Snap that extracts components from datetime data and adds them to the result field. In this case, I am extracting the epoch value into the result field. You can use the Snap to prepare the data before performing aggregation or analysis.
Empower the data scientist in you
I hope this quick step-by-step of SnapLogic Data Science shows that performing data preparation tasks can be both fun and simple. Now, data scientists can start their work of analyzing the problem and building ML-based models faster than before. And data engineers can get the data ready to go – integrating it from multiple sources and getting the data into a usable form – in a self-service manner.
Don’t believe me? Request a customized demo.








