






You’ve decided to move your data warehouse to the cloud, and want to get started. Great! It’s easy to see why – in addition to the core benefits I wrote about in my last blog post, there are many more benefits associated with cloud data warehousing: incredibly fast processing, speedy deployment, built-in fault tolerance and disaster recovery and, depending on your cloud provider, strong security and governance.
A six-step reality check
But before you get too excited, it’s time to take a reality check; moving an existing data warehouse to the cloud is not quick, and it isn’t easy. It is definitely not as simple as exporting data from one platform and loading to another. Data is only one of the six warehouse components to be migrated.
Tactically and technically, data warehouse migration is an iterative process and needs many steps to migrate all of the components, as illustrated below. Here’s everything you need to consider in migrating your data warehouse to the cloud.
1) Migrating schema: Before moving warehouse data, you’ll need to migrate table structures and specifications. You may need to make structural changes as part of the migration, including indexing or partitioning – do they need to be rethought?
Data Warehouse Migration Process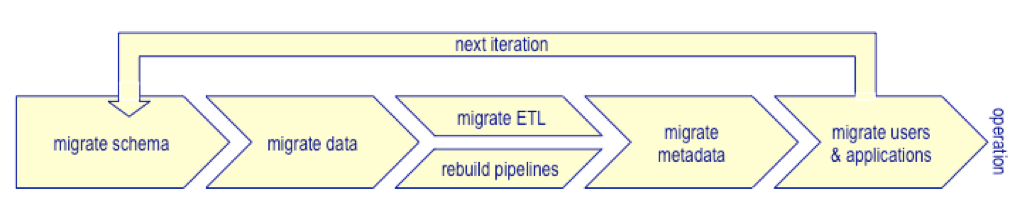
2) Migrating data: Moving very large volumes of data is process intensive, network intensive, and time-consuming. You’ll need to map out how long will it take to migrate and if you can accelerate that process. You may need to restructure as part of schema migration and transform data as part of the data migration? Alternatively, can you transform in-stream or should you pre-process and then migrate?
3) Migrating ETL: Moving data may be the easy part when compared to migrating ETL processes. You may need to change the code base to optimize for platform performance and change data transformations to sync with data restructuring. You’ll need to determine if data flows should remain intact or be reorganized. As part of the migration, you may need to reduce data latency and deliver near real-time data. If that’s the case, would it make sense to migrate ETL processing to the cloud, as well? Is there a utility to convert your ETL code?
4) Rebuilding data pipelines: With any substantive change to data flow or data transformation, rebuilding data pipelines may be a better choice than migrating existing ETL. You may be able to isolate individual data transformations and package them as executable modules. You’ll need to understand the dependencies among data transformations to construct optimum workflow and the advantages you may gain – performance, agility, reusability, and maintainability – by rebuilding ETL as modular data pipelines using modern, cloud-friendly technology.
5) Migrating metadata: Source-to-target metadata is a crucial part of managing a data warehouse; knowing data lineage, and tracing and troubleshooting is critical when problems occur. How readily will this metadata transfer to a new cloud platform? Are all of the mappings, transform logic, dataflow, and workflow locked in proprietary tools or buried in SQL code? You’ll need to determine if you’ll be able to export and import by either reverse engineering the metadata or rebuilding it from scratch.
6) Migrating users and applications: The final step in the process is migrating users and applications to the new cloud data warehouse, without interrupting business operations. Security and access authorizations may need to be created or changed, and BI and analytics tools should be connected. To do this, what communication is needed and with whom?
Don’t try to do everything at once
A typical enterprise data warehouse contains a large amount of data describing many business subject areas. Migrating an entire data warehouse in a single pass is usually not realistic. Incremental migration is the smart approach when “big bang” migration isn’t practical. Migrating incrementally is a must when undertaking significant design changes as part of the effort.
However, incremental migration brings new considerations. Data location should be transparent from a user point of view throughout the period when some data resides in the legacy data warehouse and some in the new cloud data warehouse. Consider a virtual layer as a point of access to decouple queries from data storage location.
A hybrid strategy is another viable option. With a hybrid approach, your on-premises data warehouse can remain operating as the cloud data warehouse comes online. During this transition phase, you’ll need to synchronize the data between the old on-premises data warehouse and the new one that’s in the cloud.
Cloud migration tools to the rescue
The good news is, there are many tools and services that can be invaluable when migrating your legacy data warehouse to the cloud. In my next post, the third and final in this series, I’ll explore the tools for data integration, data warehouse automation, and data virtualization, and system integrator resources that can speed and de-risk the process.
Check out the webcast, “Traditional Data Warehousing is Dead: How digital enterprises are scaling their data to infinity and beyond in the Cloud,” featuring Dave Wells, Data Management Practice Lead, Eckerson Group, which highlights the tangible business benefits that your organization can achieve by moving your data to the cloud. You’ll learn:
-
-
- Practical best practices, key technologies to consider, and case studies to get you started
- The potential pitfalls of “cloud-washed” legacy data integration solutions
- Cloud data warehousing market trends
- How SnapLogic’s Enterprise Integration Cloud delivers up to a 10X improvement in the speed and ease of data integration
-






