





Failovers can be a nightmare for organizations if not properly managed. Failover is a backup operational mode in which the functions of a system component such as a processor, server, network, or database are assumed by secondary system components when the primary component becomes unavailable through either failure or scheduled downtime. The failover procedure is conceptually simple – it involves automatically offloading tasks to a standby system component so that the procedure is as seamless as possible to the final end user. Failover is an integral part of mission-critical systems that must be constantly available and is used to make systems more fault tolerant. When failover is not designed properly, business processes are disrupted, leading to missed revenues goals and dissatisfied customers.
Keep failover top of mind
For system designers and those who manage the various components of a system’s network topology, failover is a core consideration that should be top-of-mind, and not an afterthought. Not only do business systems need to support the stated uptime requirement, but the underlying support of the business systems (infrastructure, integration, etc.) will need to work together to help achieve the business defined service level agreement (SLA) with the necessary stakeholders.
While there is no silver bullet failover solution, there are multiple ways that SnapLogic enables failover for a given system or application. Today in SnapLogic, standard executions will failover to other nodes in the cluster when one node goes down. In SnapLogic Ultra Pipelines, where multiple thread instances (parallelize) increase throughput, thread failover is handled natively within Ultra executions. The aforementioned high availability (HA) support is within a given Snaplex.
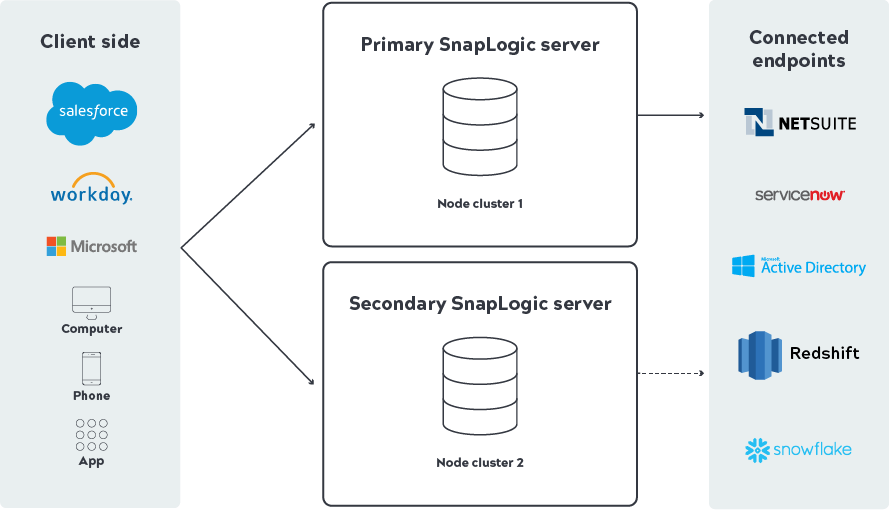
For cross datacenter failover support when an entire data HA support, SnapLogic has the following capabilities:
With HA Ultra tasks, we support deployments of tasks to multiple Snaplexes via aliasing (see Ultra Pipeline Tasks documentation) for the different load balancing technologies and methodologies available today.
HA for regular tasks has been supported since the November 2018 (4.15) release and allows tasks that are called via Override URL (see How to Run a Pipeline from a URL (Triggered Task) documentation) to execute seamlessly on any Snaplex that they have permissions to.
System designers and similar stakeholders now have multiple ways to support HA cases within a given Snaplex and across different Snaplexes in different data-centers.
For more information about how you can benefit from HA, please visit SnapLogic documentation or watch the November 2018 4.15 release webinar.





