





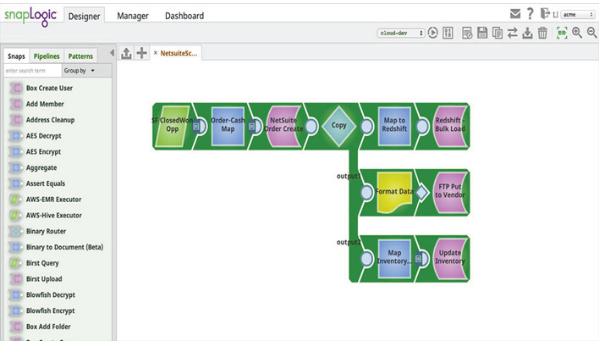
SnapLogic provides a big data integration platform as a service (iPaaS) for business customers to process data in a simple, intuitive and powerful way. SnapLogic provides a number of different modules called Snaps. An individual Snap provides a convenient way to get, manipulate or output data, and each Snap corresponds to a specific data operation. All the customer needs to do is to drag the corresponding Snaps together and configure them, which creates a data pipeline. Customers execute pipelines to handle specific data integration flows.
SnapLogic Spark Snap Script: Introduction

The Spark Script Snap allows customers to extend the functionality of the SnapLogic platform to handle Spark jobs by either adding customized scripts for their proprietary business logic that are not a part of SnapLogic’s extensive standard Snap collection or reusing existing scripts. The SnapLogic system runs the Spark Script Snap as a separate Spark job. Basically the Spark Script Snap allows the customer to write Spark scripts within the SnapLogic Designer.
The Spark Script Snap also supports passing Spark properties to the Spark Python script via environment variables. This enables users to create reusable Spark scripts and configurations, such as App name, Memory size and Spark master.
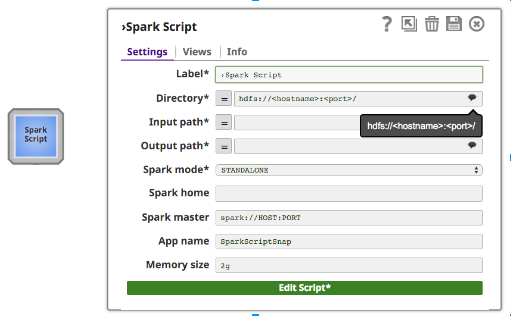
Properties:
In addition to regular Snap fields, the Spark Script Snap provides suggestion for hdfs “Directory”, “Input Path” and “Output Path”. The “Directory” field only shows Directory, but “Input path” and “Output path” can show both files and directories.
To run the Spark Script Snap on a cluster, customers can choose from two types of cluster manager (either Spark’s own standalone cluster manager or YARN), which allocates resources across applications.
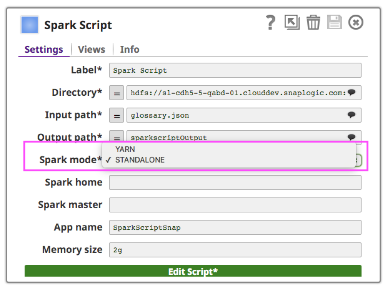
- Standalone – a simple cluster management associated with the Spark ecosystem
- Hadooop YARN – the resource manager in Hadoop Ecosystem
If you use Standalone mode, put the Master URL in the master field and set Master inside your Spark Script, or leave it as blank. If you use YARN mode, there is no need to set Master.
The “Spark home” field is optional. If it is empty, Spark Script Snap will use the default “Spark home” value, the path where customers installed spark in their cluster. Otherwise, users can specify their cluster Spark home.
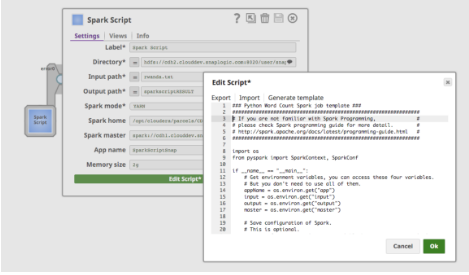
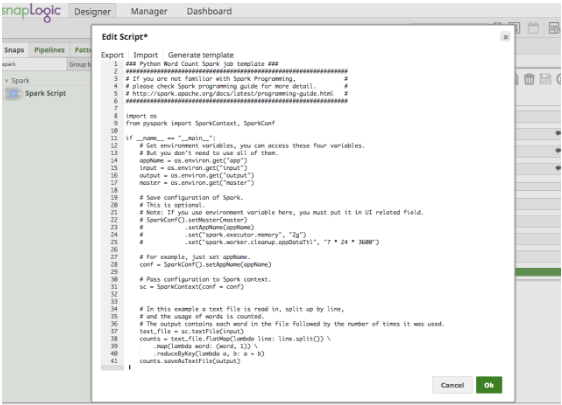
When you click “Edit Script”, the Spark Script Snap will provide a template to run the wordcount example. It also includes how to use environment variables as Figure 4 shows. A user can edit the script directly in the box, or paste a script provided by a data scientist colleague.
Links
There is a step-by-step demonstration video of the Spark Script Snap here.
There’s lots of information about SnapLogic big data integration and integrated cloud services on our website, as well as big data integration blog posts, iPaaS information, and whitepapers.



